 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Reinforcement Learning
Dec 12, 2019
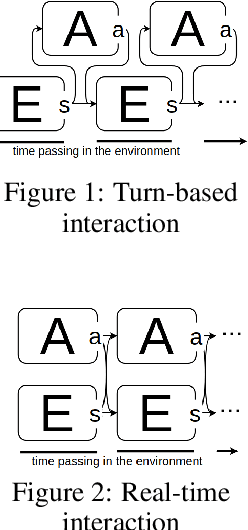
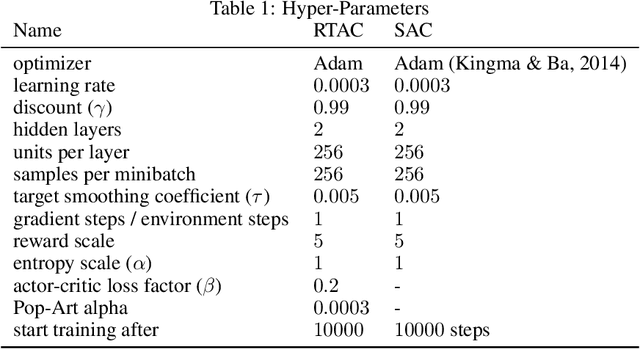
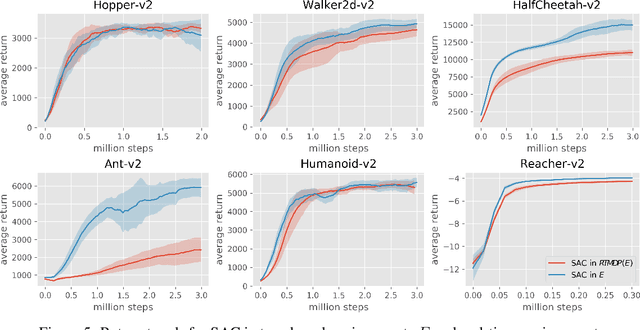
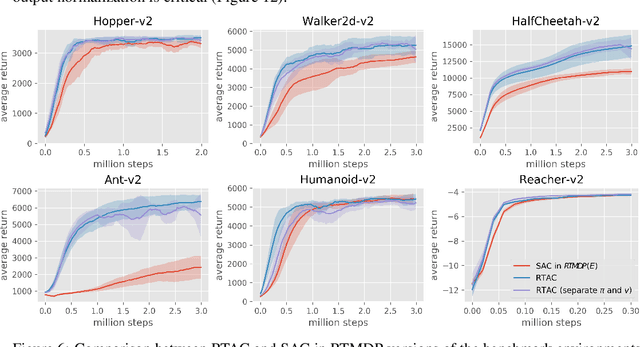
Markov Decision Processes (MDPs), the mathematical framework underlying most algorithms in Reinforcement Learning (RL), are often used in a way that wrongfully assumes that the state of an agent's environment does not change during action selection. As RL systems based on MDPs begin to find application in real-world safety critical situations, this mismatch between the assumptions underlying classical MDPs and the reality of real-time computation may lead to undesirable outcomes. In this paper, we introduce a new framework, in which states and actions evolve simultaneously and show how it is related to the classical MDP formulation. We analyze existing algorithms under the new real-time formulation and show why they are suboptimal when used in real-time. We then use those insights to create a new algorithm Real-Time Actor-Critic (RTAC) that outperforms the existing state-of-the-art continuous control algorithm Soft Actor-Critic both in real-time and non-real-time settings. Code and videos can be found at https://github.com/rmst/rtrl.
MIMO-GAN: Generative MIMO Channel Modeling
Mar 16, 2022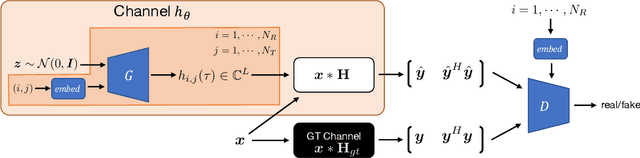
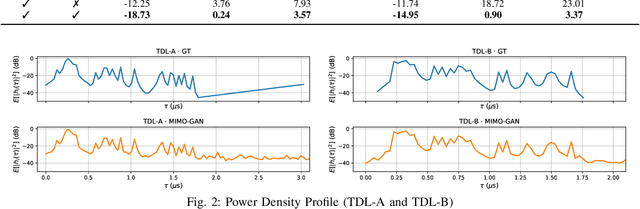
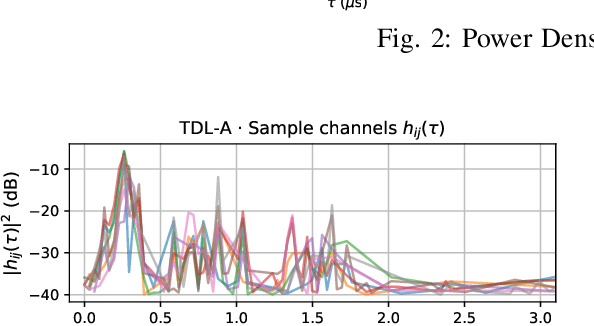
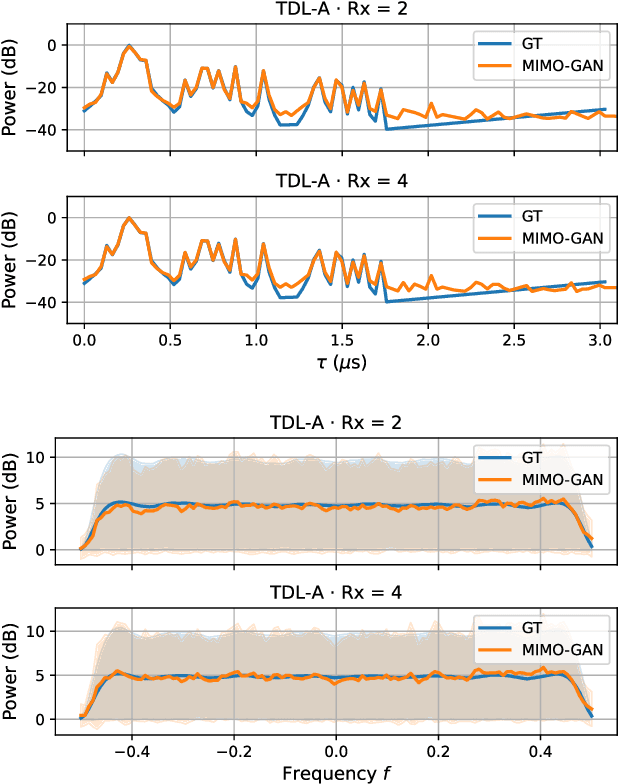
We propose generative channel modeling to learn statistical channel models from channel input-output measurements. Generative channel models can learn more complicated distributions and represent the field data more faithfully. They are tractable and easy to sample from, which can potentially speed up the simulation rounds. To achieve this, we leverage advances in GAN, which helps us learn an implicit distribution over stochastic MIMO channels from observed measurements. In particular, our approach MIMO-GAN implicitly models the wireless channel as a distribution of time-domain band-limited impulse responses. We evaluate MIMO-GAN on 3GPP TDL MIMO channels and observe high-consistency in capturing power, delay and spatial correlation statistics of the underlying channel. In particular, we observe MIMO-GAN achieve errors of under 3.57 ns average delay and -18.7 dB power.
Efficient Classification of Long Documents Using Transformers
Mar 21, 2022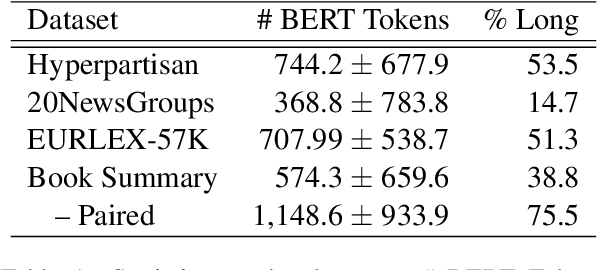
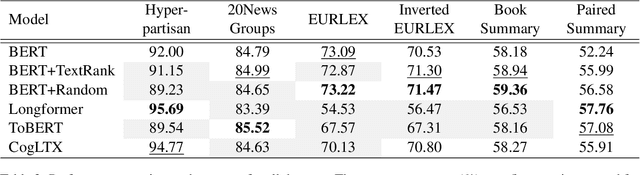
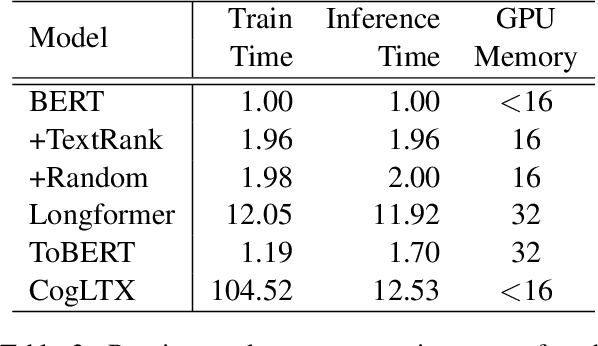
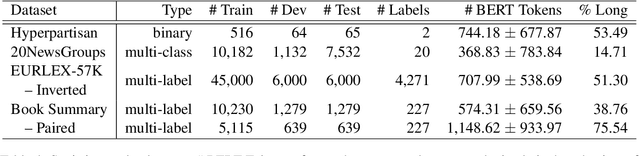
Several methods have been proposed for classifying long textual documents using Transformers. However, there is a lack of consensus on a benchmark to enable a fair comparison among different approaches. In this paper, we provide a comprehensive evaluation of the relative efficacy measured against various baselines and diverse datasets -- both in terms of accuracy as well as time and space overheads. Our datasets cover binary, multi-class, and multi-label classification tasks and represent various ways information is organized in a long text (e.g. information that is critical to making the classification decision is at the beginning or towards the end of the document). Our results show that more complex models often fail to outperform simple baselines and yield inconsistent performance across datasets. These findings emphasize the need for future studies to consider comprehensive baselines and datasets that better represent the task of long document classification to develop robust models.
A two-level machine learning framework for predictive maintenance: comparison of learning formulations
Apr 21, 2022
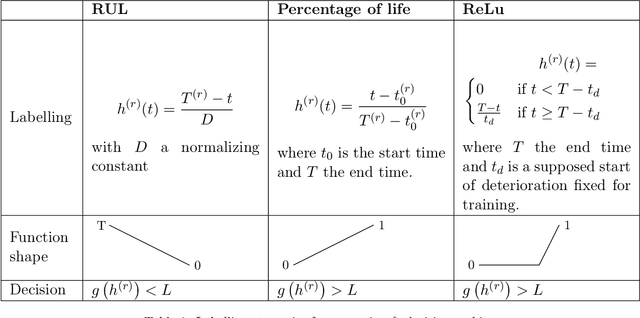
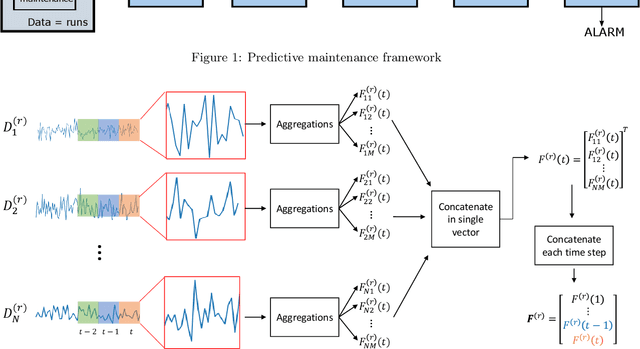
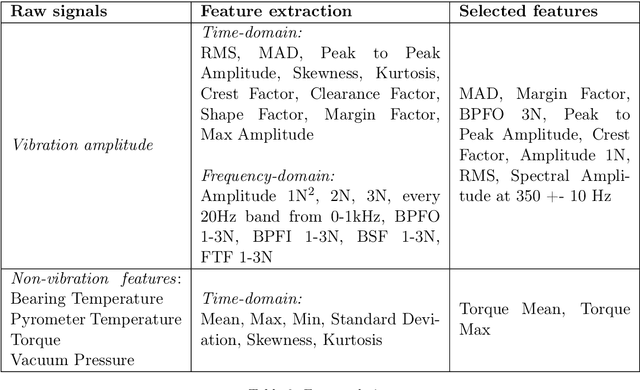
Predicting incoming failures and scheduling maintenance based on sensors information in industrial machines is increasingly important to avoid downtime and machine failure. Different machine learning formulations can be used to solve the predictive maintenance problem. However, many of the approaches studied in the literature are not directly applicable to real-life scenarios. Indeed, many of those approaches usually either rely on labelled machine malfunctions in the case of classification and fault detection, or rely on finding a monotonic health indicator on which a prediction can be made in the case of regression and remaining useful life estimation, which is not always feasible. Moreover, the decision-making part of the problem is not always studied in conjunction with the prediction phase. This paper aims to design and compare different formulations for predictive maintenance in a two-level framework and design metrics that quantify both the failure detection performance as well as the timing of the maintenance decision. The first level is responsible for building a health indicator by aggregating features using a learning algorithm. The second level consists of a decision-making system that can trigger an alarm based on this health indicator. Three degrees of refinements are compared in the first level of the framework, from simple threshold-based univariate predictive technique to supervised learning methods based on the remaining time before failure. We choose to use the Support Vector Machine (SVM) and its variations as the common algorithm used in all the formulations. We apply and compare the different strategies on a real-world rotating machine case study and observe that while a simple model can already perform well, more sophisticated refinements enhance the predictions for well-chosen parameters.
Robust alignment of cross-session recordings of neural population activity by behaviour via unsupervised domain adaptation
Feb 16, 2022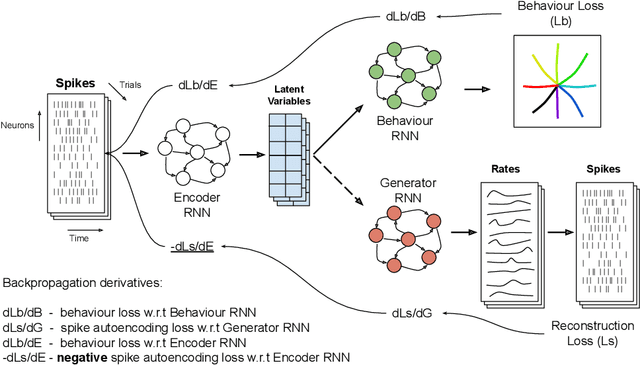
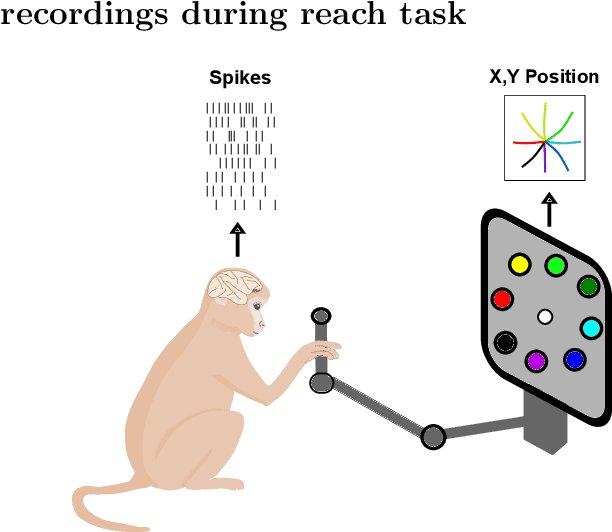
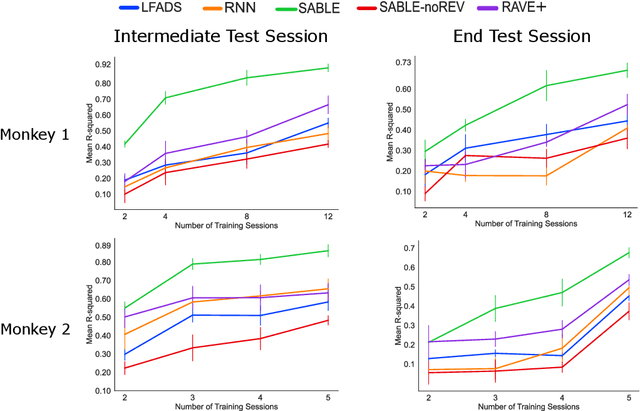
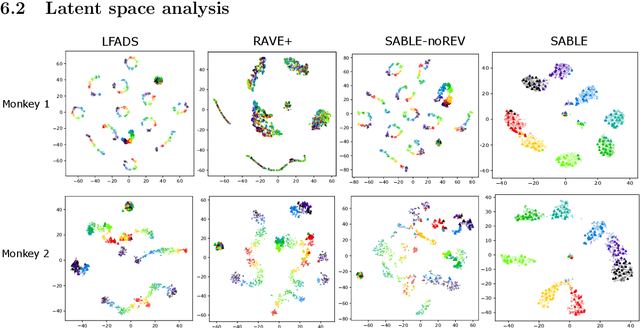
Neural population activity relating to behaviour is assumed to be inherently low-dimensional despite the observed high dimensionality of data recorded using multi-electrode arrays. Therefore, predicting behaviour from neural population recordings has been shown to be most effective when using latent variable models. Over time however, the activity of single neurons can drift, and different neurons will be recorded due to movement of implanted neural probes. This means that a decoder trained to predict behaviour on one day performs worse when tested on a different day. On the other hand, evidence suggests that the latent dynamics underlying behaviour may be stable even over months and years. Based on this idea, we introduce a model capable of inferring behaviourally relevant latent dynamics from previously unseen data recorded from the same animal, without any need for decoder recalibration. We show that unsupervised domain adaptation combined with a sequential variational autoencoder, trained on several sessions, can achieve good generalisation to unseen data and correctly predict behaviour where conventional methods fail. Our results further support the hypothesis that behaviour-related neural dynamics are low-dimensional and stable over time, and will enable more effective and flexible use of brain computer interface technologies.
A distribution-dependent Mumford-Shah model for unsupervised hyperspectral image segmentation
Mar 28, 2022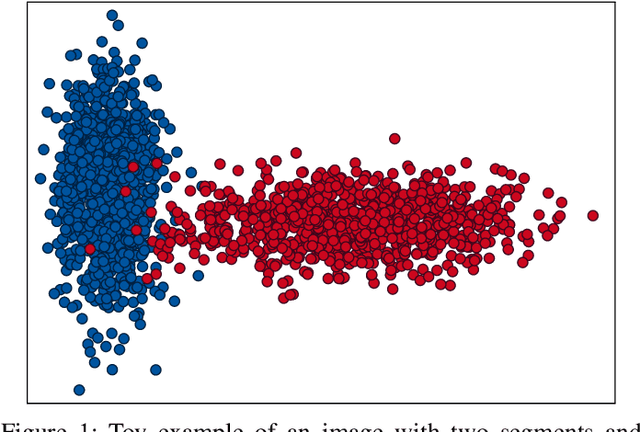
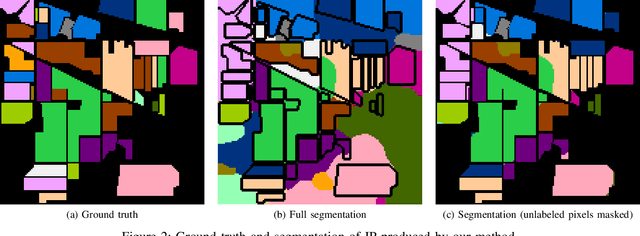
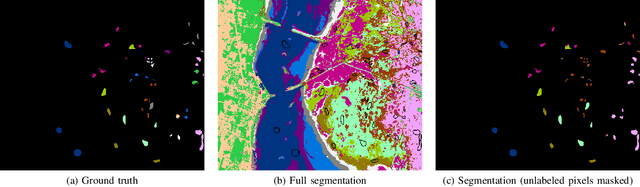
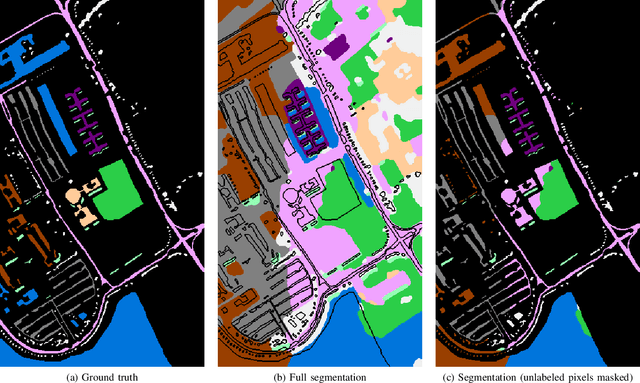
Hyperspectral images provide a rich representation of the underlying spectrum for each pixel, allowing for a pixel-wise classification/segmentation into different classes. As the acquisition of labeled training data is very time-consuming, unsupervised methods become crucial in hyperspectral image analysis. The spectral variability and noise in hyperspectral data make this task very challenging and define special requirements for such methods. Here, we present a novel unsupervised hyperspectral segmentation framework. It starts with a denoising and dimensionality reduction step by the well-established Minimum Noise Fraction (MNF) transform. Then, the Mumford-Shah (MS) segmentation functional is applied to segment the data. We equipped the MS functional with a novel robust distribution-dependent indicator function designed to handle the characteristic challenges of hyperspectral data. To optimize our objective function with respect to the parameters for which no closed form solution is available, we propose an efficient fixed point iteration scheme. Numerical experiments on four public benchmark datasets show that our method produces competitive results, which outperform two state-of-the-art methods substantially on three of these datasets.
Agent-Temporal Attention for Reward Redistribution in Episodic Multi-Agent Reinforcement Learning
Jan 12, 2022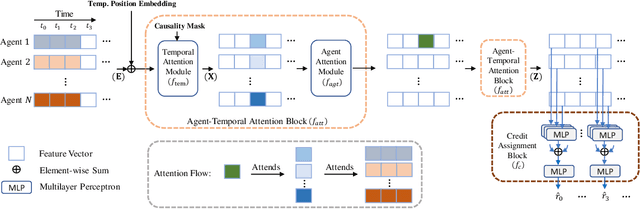
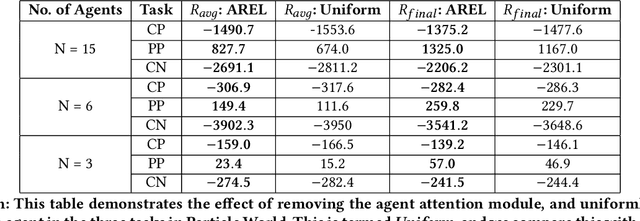
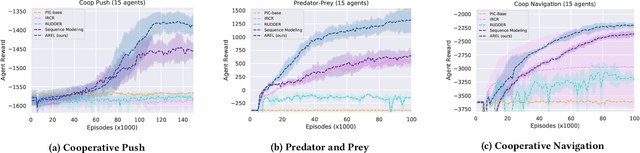
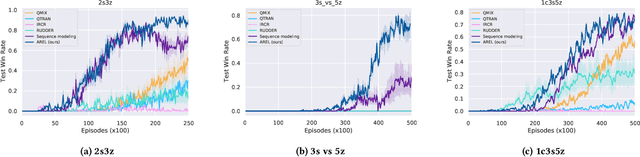
This paper considers multi-agent reinforcement learning (MARL) tasks where agents receive a shared global reward at the end of an episode. The delayed nature of this reward affects the ability of the agents to assess the quality of their actions at intermediate time-steps. This paper focuses on developing methods to learn a temporal redistribution of the episodic reward to obtain a dense reward signal. Solving such MARL problems requires addressing two challenges: identifying (1) relative importance of states along the length of an episode (along time), and (2) relative importance of individual agents' states at any single time-step (among agents). In this paper, we introduce Agent-Temporal Attention for Reward Redistribution in Episodic Multi-Agent Reinforcement Learning (AREL) to address these two challenges. AREL uses attention mechanisms to characterize the influence of actions on state transitions along trajectories (temporal attention), and how each agent is affected by other agents at each time-step (agent attention). The redistributed rewards predicted by AREL are dense, and can be integrated with any given MARL algorithm. We evaluate AREL on challenging tasks from the Particle World environment and the StarCraft Multi-Agent Challenge. AREL results in higher rewards in Particle World, and improved win rates in StarCraft compared to three state-of-the-art reward redistribution methods. Our code is available at https://github.com/baicenxiao/AREL.
Brain-Inspired Hyperdimensional Computing: How Thermal-Friendly for Edge Computing?
Apr 05, 2022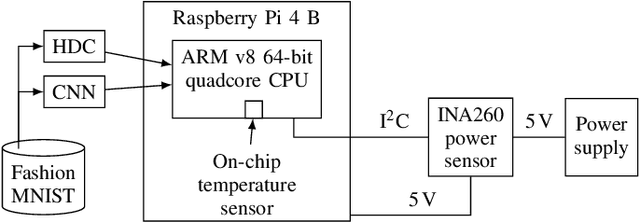
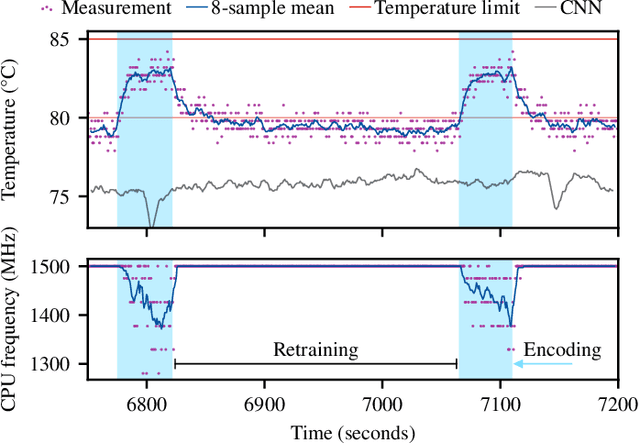
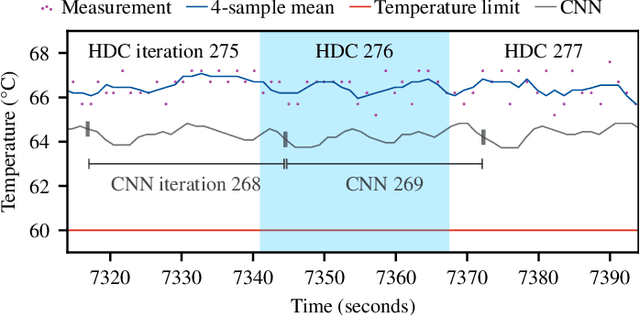
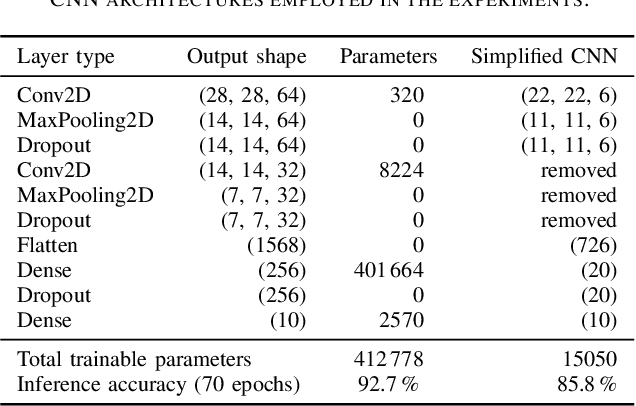
Brain-inspired hyperdimensional computing (HDC) is an emerging machine learning (ML) methods. It is based on large vectors of binary or bipolar symbols and a few simple mathematical operations. The promise of HDC is a highly efficient implementation for embedded systems like wearables. While fast implementations have been presented, other constraints have not been considered for edge computing. In this work, we aim at answering how thermal-friendly HDC for edge computing is. Devices like smartwatches, smart glasses, or even mobile systems have a restrictive cooling budget due to their limited volume. Although HDC operations are simple, the vectors are large, resulting in a high number of CPU operations and thus a heavy load on the entire system potentially causing temperature violations. In this work, the impact of HDC on the chip's temperature is investigated for the first time. We measure the temperature and power consumption of a commercial embedded system and compare HDC with conventional CNN. We reveal that HDC causes up to 6.8{\deg}C higher temperatures and leads to up to 47% more CPU throttling. Even when both HDC and CNN aim for the same throughput (i.e., perform a similar number of classifications per second), HDC still causes higher on-chip temperatures due to the larger power consumption.
Multispectral Satellite Data Classification using Soft Computing Approach
Mar 21, 2022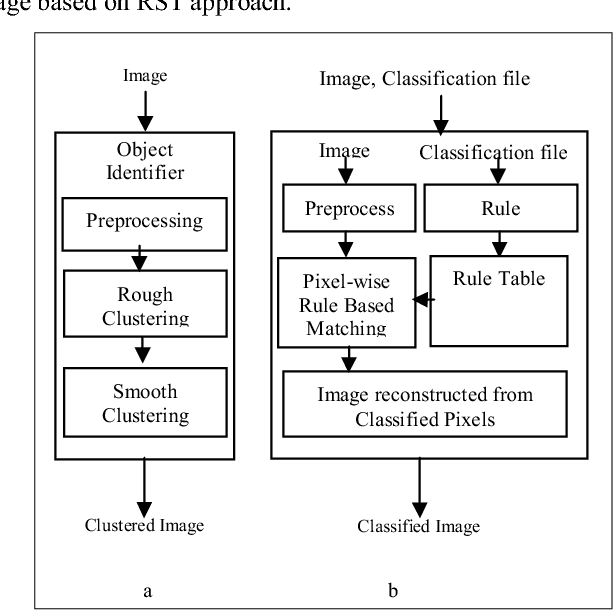

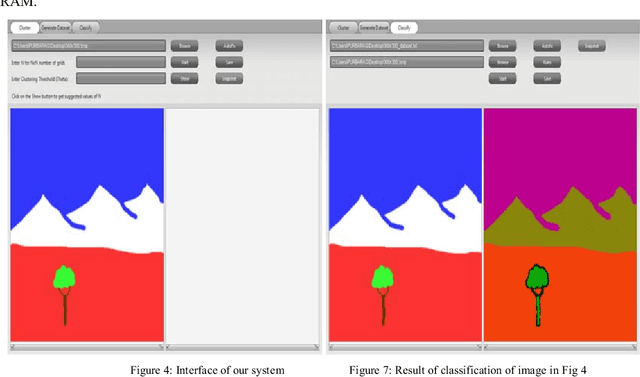

A satellite image is a remotely sensed image data, where each pixel represents a specific location on earth. The pixel value recorded is the reflection radiation from the earth's surface at that location. Multispectral images are those that capture image data at specific frequencies across the electromagnetic spectrum as compared to Panchromatic images which are sensitive to all wavelength of visible light. Because of the high resolution and high dimensions of these images, they create difficulties for clustering techniques to efficiently detect clusters of different sizes, shapes and densities as a trade off for fast processing time. In this paper we propose a grid-density based clustering technique for identification of objects. We also introduce an approach to classify a satellite image data using a rule induction based machine learning algorithm. The object identification and classification methods have been validated using several synthetic and benchmark datasets.
Handling Variable-Dimensional Time Series with Graph Neural Networks
Jul 07, 2020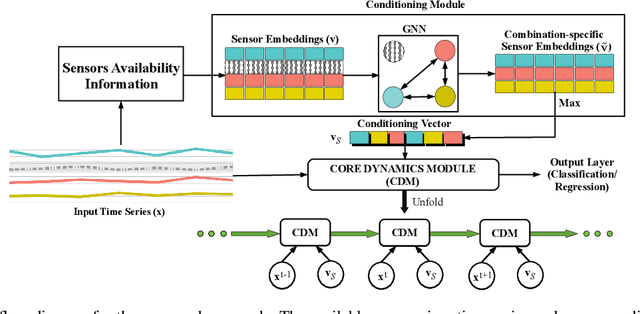
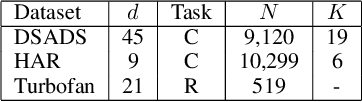
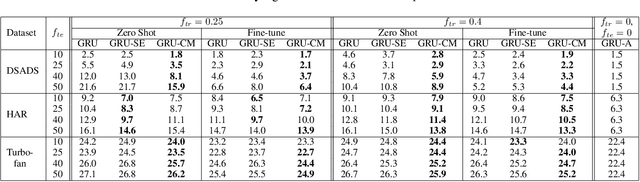
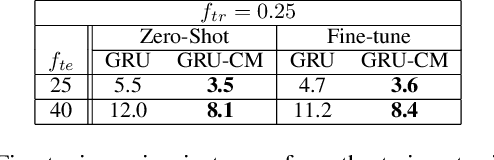
Several applications of Internet of Things (IoT) technology involve capturing data from multiple sensors resulting in multi-sensor time series. Existing neural networks based approaches for such multi-sensor or multivariate time series modeling assume fixed input dimension or number of sensors. Such approaches can struggle in the practical setting where different instances of the same device or equipment such as mobiles, wearables, engines, etc. come with different combinations of installed sensors. We consider training neural network models from such multi-sensor time series, where the time series have varying input dimensionality owing to availability or installation of a different subset of sensors at each source of time series. We propose a novel neural network architecture suitable for zero-shot transfer learning allowing robust inference for multivariate time series with previously unseen combination of available dimensions or sensors at test time. Such a combinatorial generalization is achieved by conditioning the layers of a core neural network-based time series model with a "conditioning vector" that carries information of the available combination of sensors for each time series. This conditioning vector is obtained by summarizing the set of learned "sensor embedding vectors" corresponding to the available sensors in a time series via a graph neural network. We evaluate the proposed approach on publicly available activity recognition and equipment prognostics datasets, and show that the proposed approach allows for better generalization in comparison to a deep gated recurrent neural network baseline.