 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Near Real-Time Social Distancing in London
Dec 07, 2020

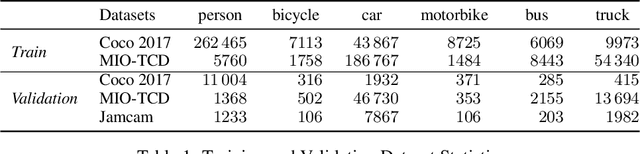
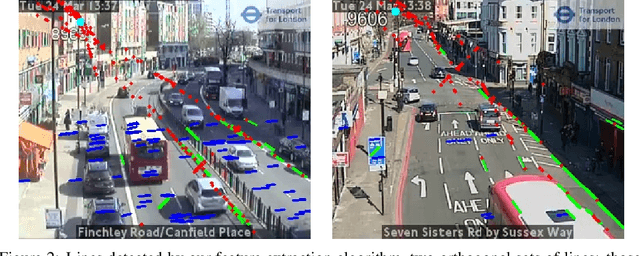
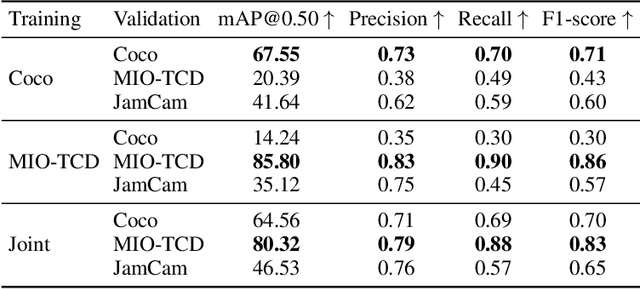
During the COVID-19 pandemic, policy makers at the Greater London Authority, the regional governance body of London, UK, are reliant upon prompt and accurate data sources. Large well-defined heterogeneous compositions of activity throughout the city are sometimes difficult to acquire, yet are a necessity in order to learn 'busyness' and consequently make safe policy decisions. One component of our project within this space is to utilise existing infrastructure to estimate social distancing adherence by the general public. Our method enables near immediate sampling and contextualisation of activity and physical distancing on the streets of London via live traffic camera feeds. We introduce a framework for inspecting and improving upon existing methods, whilst also describing its active deployment on over 900 real-time feeds.
USTED: Improving ASR with a Unified Speech and Text Encoder-Decoder
Feb 12, 2022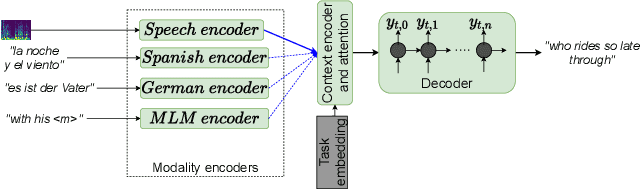
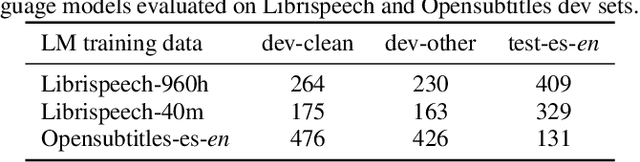
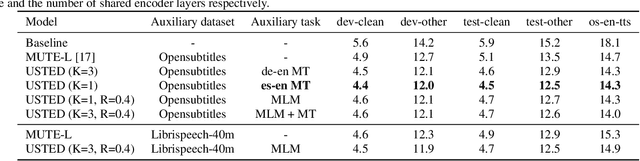
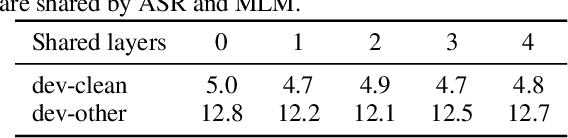
Improving end-to-end speech recognition by incorporating external text data has been a longstanding research topic. There has been a recent focus on training E2E ASR models that get the performance benefits of external text data without incurring the extra cost of evaluating an external language model at inference time. In this work, we propose training ASR model jointly with a set of text-to-text auxiliary tasks with which it shares a decoder and parts of the encoder. When we jointly train ASR and masked language model with the 960-hour Librispeech and Opensubtitles data respectively, we observe WER reductions of 16% and 20% on test-other and test-clean respectively over an ASR-only baseline without any extra cost at inference time, and reductions of 6% and 8% compared to a stronger MUTE-L baseline which trains the decoder with the same text data as our model. We achieve further improvements when we train masked language model on Librispeech data or when we use machine translation as the auxiliary task, without significantly sacrificing performance on the task itself.
On Reinforcement Learning, Effect Handlers, and the State Monad
Mar 29, 2022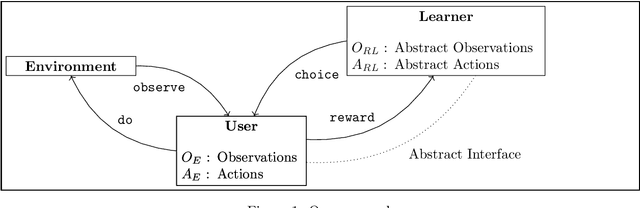


We study the algebraic effects and handlers as a way to support decision-making abstractions in functional programs, whereas a user can ask a learning algorithm to resolve choices without implementing the underlying selection mechanism, and give a feedback by way of rewards. Differently from some recently proposed approach to the problem based on the selection monad [Abadi and Plotkin, LICS 2021], we express the underlying intelligence as a reinforcement learning algorithm implemented as a set of handlers for some of these algebraic operations, including those for choices and rewards. We show how we can in practice use algebraic operations and handlers -- as available in the programming language EFF -- to clearly separate the learning algorithm from its environment, thus allowing for a good level of modularity. We then show how the host language can be taken as a lambda-calculus with handlers, this way showing what the essential linguistic features are. We conclude by hinting at how type and effect systems could ensure safety properties, at the same time pointing at some directions for further work.
Temporal Latent Auto-Encoder: A Method for Probabilistic Multivariate Time Series Forecasting
Jan 25, 2021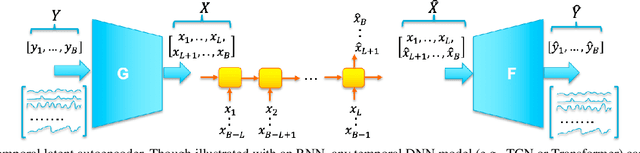
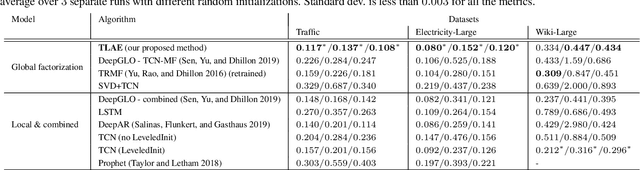
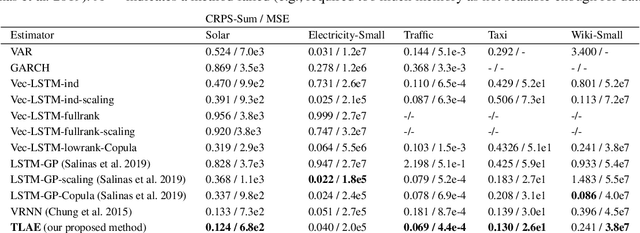
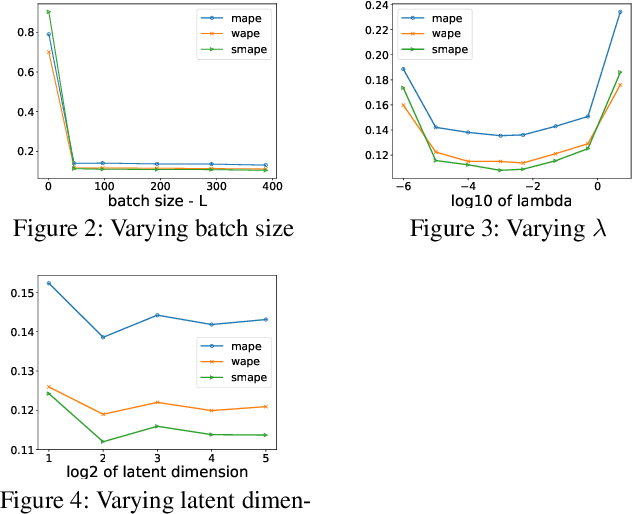
Probabilistic forecasting of high dimensional multivariate time series is a notoriously challenging task, both in terms of computational burden and distribution modeling. Most previous work either makes simple distribution assumptions or abandons modeling cross-series correlations. A promising line of work exploits scalable matrix factorization for latent-space forecasting, but is limited to linear embeddings, unable to model distributions, and not trainable end-to-end when using deep learning forecasting. We introduce a novel temporal latent auto-encoder method which enables nonlinear factorization of multivariate time series, learned end-to-end with a temporal deep learning latent space forecast model. By imposing a probabilistic latent space model, complex distributions of the input series are modeled via the decoder. Extensive experiments demonstrate that our model achieves state-of-the-art performance on many popular multivariate datasets, with gains sometimes as high as $50\%$ for several standard metrics.
Agent-Temporal Attention for Reward Redistribution in Episodic Multi-Agent Reinforcement Learning
Jan 12, 2022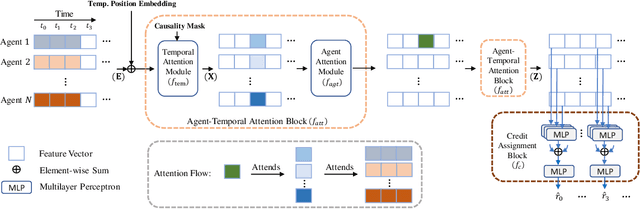
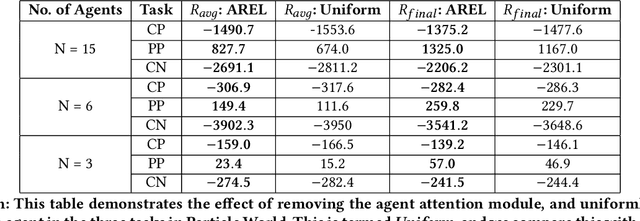
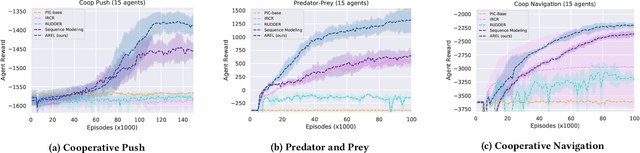
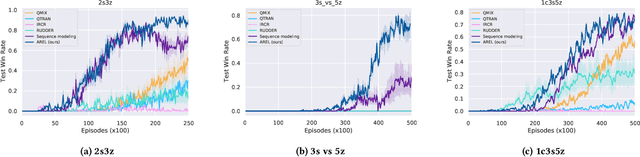
This paper considers multi-agent reinforcement learning (MARL) tasks where agents receive a shared global reward at the end of an episode. The delayed nature of this reward affects the ability of the agents to assess the quality of their actions at intermediate time-steps. This paper focuses on developing methods to learn a temporal redistribution of the episodic reward to obtain a dense reward signal. Solving such MARL problems requires addressing two challenges: identifying (1) relative importance of states along the length of an episode (along time), and (2) relative importance of individual agents' states at any single time-step (among agents). In this paper, we introduce Agent-Temporal Attention for Reward Redistribution in Episodic Multi-Agent Reinforcement Learning (AREL) to address these two challenges. AREL uses attention mechanisms to characterize the influence of actions on state transitions along trajectories (temporal attention), and how each agent is affected by other agents at each time-step (agent attention). The redistributed rewards predicted by AREL are dense, and can be integrated with any given MARL algorithm. We evaluate AREL on challenging tasks from the Particle World environment and the StarCraft Multi-Agent Challenge. AREL results in higher rewards in Particle World, and improved win rates in StarCraft compared to three state-of-the-art reward redistribution methods. Our code is available at https://github.com/baicenxiao/AREL.
A Review of Machine Learning Methods Applied to Structural Dynamics and Vibroacoustic
Apr 13, 2022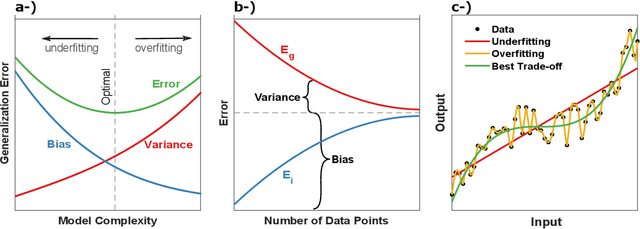
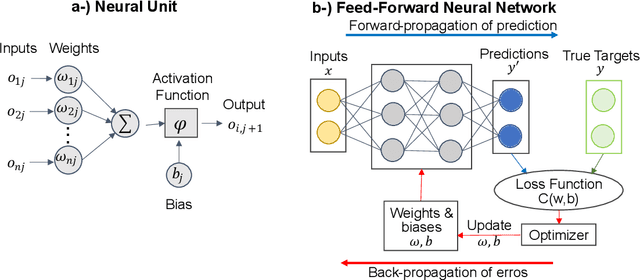
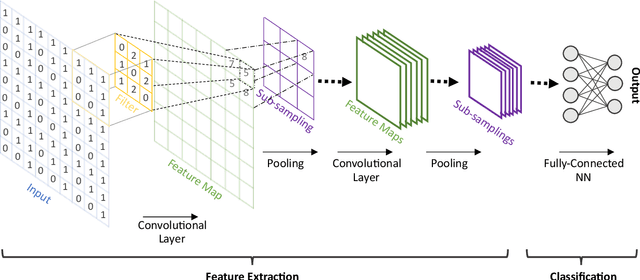
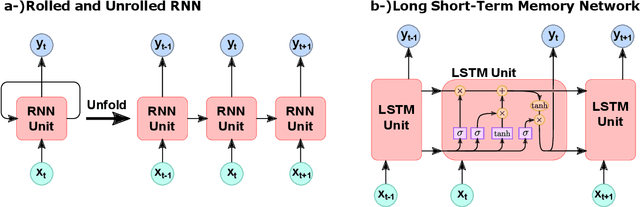
The use of Machine Learning (ML) has rapidly spread across several fields, having encountered many applications in Structural Dynamics and Vibroacoustic (SD\&V). The increasing capabilities of ML to unveil insights from data, driven by unprecedented data availability, algorithms advances and computational power, enhance decision making, uncertainty handling, patterns recognition and real-time assessments. Three main applications in SD\&V have taken advantage of these benefits. In Structural Health Monitoring, ML detection and prognosis lead to safe operation and optimized maintenance schedules. System identification and control design are leveraged by ML techniques in Active Noise Control and Active Vibration Control. Finally, the so-called ML-based surrogate models provide fast alternatives to costly simulations, enabling robust and optimized product design. Despite the many works in the area, they have not been reviewed and analyzed. Therefore, to keep track and understand this ongoing integration of fields, this paper presents a survey of ML applications in SD\&V analyses, shedding light on the current state of implementation and emerging opportunities. The main methodologies, advantages, limitations, and recommendations based on scientific knowledge were identified for each of the three applications. Moreover, the paper considers the role of Digital Twins and Physics Guided ML to overcome current challenges and power future research progress. As a result, the survey provides a broad overview of the present landscape of ML applied in SD\&V and guides the reader to an advanced understanding of progress and prospects in the field.
Automatic inference of fault tree models via multi-objective evolutionary algorithms
Apr 06, 2022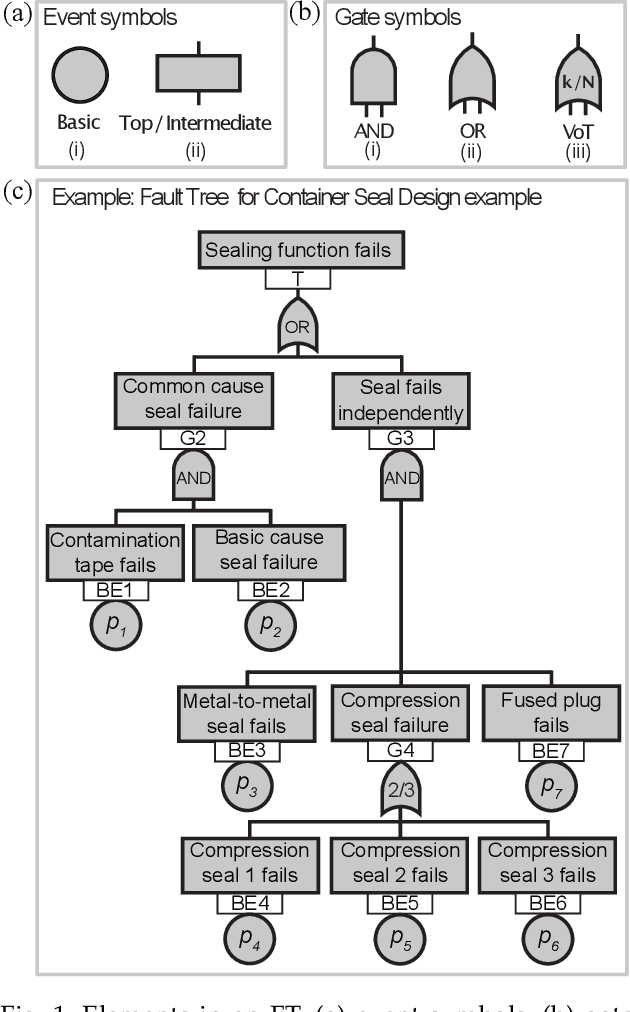


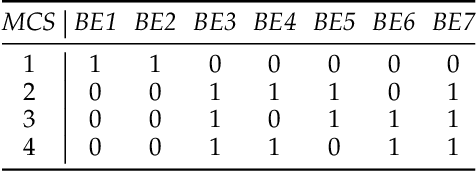
Fault tree analysis is a well-known technique in reliability engineering and risk assessment, which supports decision-making processes and the management of complex systems. Traditionally, fault tree (FT) models are built manually together with domain experts, considered a time-consuming process prone to human errors. With Industry 4.0, there is an increasing availability of inspection and monitoring data, making techniques that enable knowledge extraction from large data sets relevant. Thus, our goal with this work is to propose a data-driven approach to infer efficient FT structures that achieve a complete representation of the failure mechanisms contained in the failure data set without human intervention. Our algorithm, the FT-MOEA, based on multi-objective evolutionary algorithms, enables the simultaneous optimization of different relevant metrics such as the FT size, the error computed based on the failure data set and the Minimal Cut Sets. Our results show that, for six case studies from the literature, our approach successfully achieved automatic, efficient, and consistent inference of the associated FT models. We also present the results of a parametric analysis that tests our algorithm for different relevant conditions that influence its performance, as well as an overview of the data-driven methods used to automatically infer FT models.
Almost Optimal Proper Learning and Testing Polynomials
Feb 07, 2022


We give the first almost optimal polynomial-time proper learning algorithm of Boolean sparse multivariate polynomial under the uniform distribution. For $s$-sparse polynomial over $n$ variables and $\epsilon=1/s^\beta$, $\beta>1$, our algorithm makes $$q_U=\left(\frac{s}{\epsilon}\right)^{\frac{\log \beta}{\beta}+O(\frac{1}{\beta})}+ \tilde O\left(s\right)\left(\log\frac{1}{\epsilon}\right)\log n$$ queries. Notice that our query complexity is sublinear in $1/\epsilon$ and almost linear in $s$. All previous algorithms have query complexity at least quadratic in $s$ and linear in $1/\epsilon$. We then prove the almost tight lower bound $$q_L=\left(\frac{s}{\epsilon}\right)^{\frac{\log \beta}{\beta}+\Omega(\frac{1}{\beta})}+ \Omega\left(s\right)\left(\log\frac{1}{\epsilon}\right)\log n,$$ Applying the reduction in~\cite{Bshouty19b} with the above algorithm, we give the first almost optimal polynomial-time tester for $s$-sparse polynomial. Our tester, for $\beta>3.404$, makes $$\tilde O\left(\frac{s}{\epsilon}\right)$$ queries.
Augmenting Pre-trained Language Models with QA-Memory for Open-Domain Question Answering
Apr 10, 2022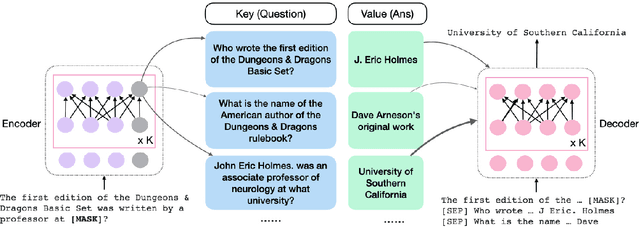
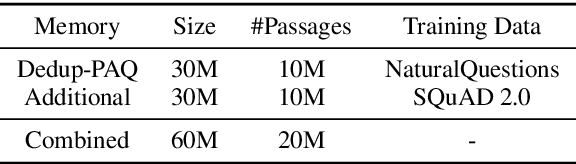
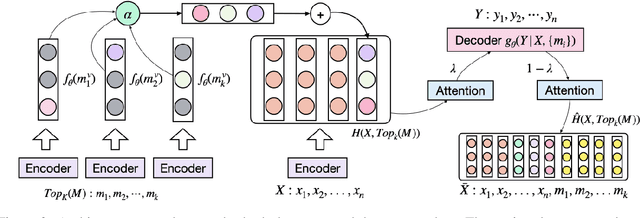
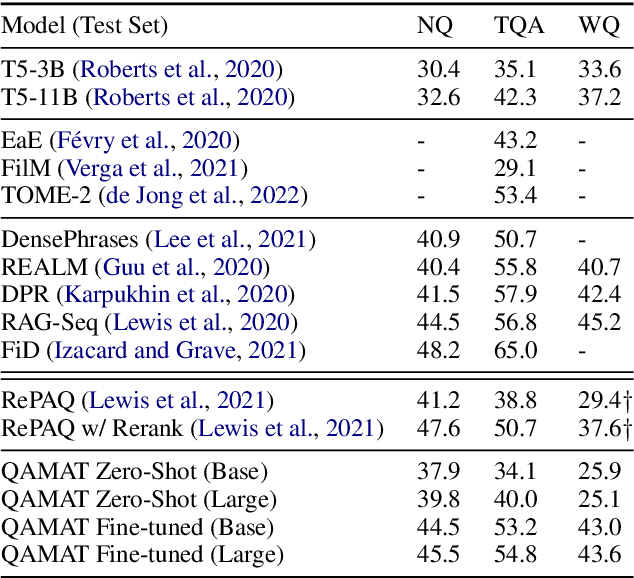
Retrieval augmented language models have recently become the standard for knowledge intensive tasks. Rather than relying purely on latent semantics within the parameters of large neural models, these methods enlist a semi-parametric memory to encode an index of knowledge for the model to retrieve over. Most prior work has employed text passages as the unit of knowledge, which has high coverage at the cost of interpretability, controllability, and efficiency. The opposite properties arise in other methods which have instead relied on knowledge base (KB) facts. At the same time, more recent work has demonstrated the effectiveness of storing and retrieving from an index of Q-A pairs derived from text \citep{lewis2021paq}. This approach yields a high coverage knowledge representation that maintains KB-like properties due to its representations being more atomic units of information. In this work we push this line of research further by proposing a question-answer augmented encoder-decoder model and accompanying pretraining strategy. This yields an end-to-end system that not only outperforms prior QA retrieval methods on single-hop QA tasks but also enables compositional reasoning, as demonstrated by strong performance on two multi-hop QA datasets. Together, these methods improve the ability to interpret and control the model while narrowing the performance gap with passage retrieval systems.
Intelligent Systematic Investment Agent: an ensemble of deep learning and evolutionary strategies
Mar 24, 2022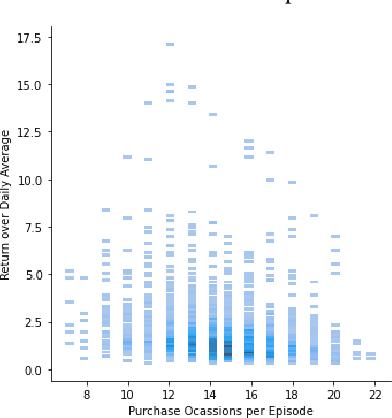
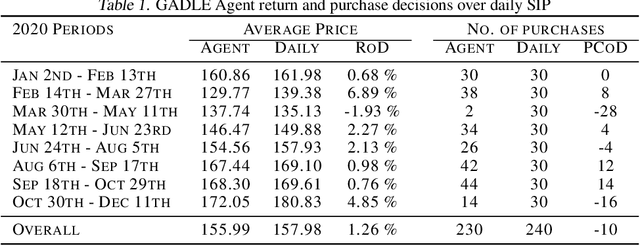
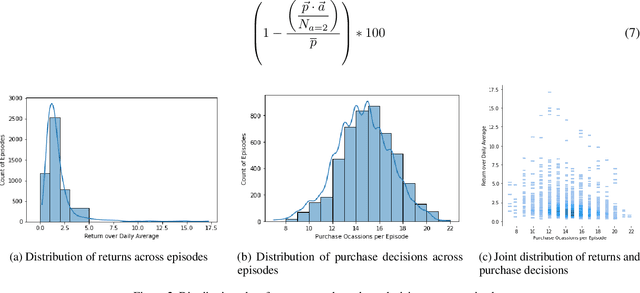
Machine learning driven trading strategies have garnered a lot of interest over the past few years. There is, however, limited consensus on the ideal approach for the development of such trading strategies. Further, most literature has focused on trading strategies for short-term trading, with little or no focus on strategies that attempt to build long-term wealth. Our paper proposes a new approach for developing long-term investment strategies using an ensemble of evolutionary algorithms and a deep learning model by taking a series of short-term purchase decisions. Our methodology focuses on building long-term wealth by improving systematic investment planning (SIP) decisions on Exchange Traded Funds (ETF) over a period of time. We provide empirical evidence of superior performance (around 1% higher returns) using our ensemble approach as compared to the traditional daily systematic investment practice on a given ETF. Our results are based on live trading decisions made by our algorithm and executed on the Robinhood trading platform.