 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Space-time Neural Irradiance Fields for Free-Viewpoint Video
Nov 25, 2020
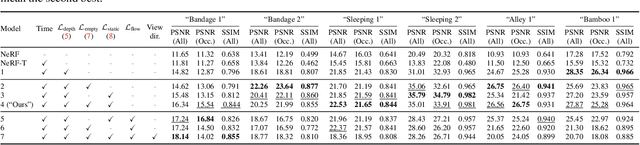

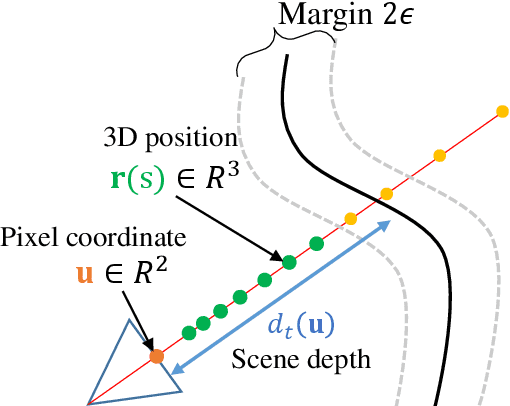

We present a method that learns a spatiotemporal neural irradiance field for dynamic scenes from a single video. Our learned representation enables free-viewpoint rendering of the input video. Our method builds upon recent advances in implicit representations. Learning a spatiotemporal irradiance field from a single video poses significant challenges because the video contains only one observation of the scene at any point in time. The 3D geometry of a scene can be legitimately represented in numerous ways since varying geometry (motion) can be explained with varying appearance and vice versa. We address this ambiguity by constraining the time-varying geometry of our dynamic scene representation using the scene depth estimated from video depth estimation methods, aggregating contents from individual frames into a single global representation. We provide an extensive quantitative evaluation and demonstrate compelling free-viewpoint rendering results.
A Unified Light Framework for Real-time Fault Detection of Freight Train Images
Jan 31, 2021
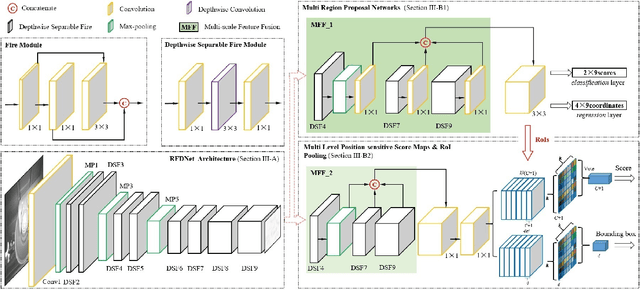


Real-time fault detection for freight trains plays a vital role in guaranteeing the security and optimal operation of railway transportation under stringent resource requirements. Despite the promising results for deep learning based approaches, the performance of these fault detectors on freight train images, are far from satisfactory in both accuracy and efficiency. This paper proposes a unified light framework to improve detection accuracy while supporting a real-time operation with a low resource requirement. We firstly design a novel lightweight backbone (RFDNet) to improve the accuracy and reduce computational cost. Then, we propose a multi region proposal network using multi-scale feature maps generated from RFDNet to improve the detection performance. Finally, we present multi level position-sensitive score maps and region of interest pooling to further improve accuracy with few redundant computations. Extensive experimental results on public benchmark datasets suggest that our RFDNet can significantly improve the performance of baseline network with higher accuracy and efficiency. Experiments on six fault datasets show that our method is capable of real-time detection at over 38 frames per second and achieves competitive accuracy and lower computation than the state-of-the-art detectors.
Refined Hardness of Distance-Optimal Multi-Agent Path Finding
Mar 14, 2022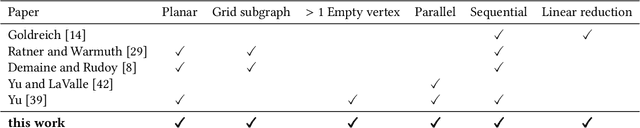

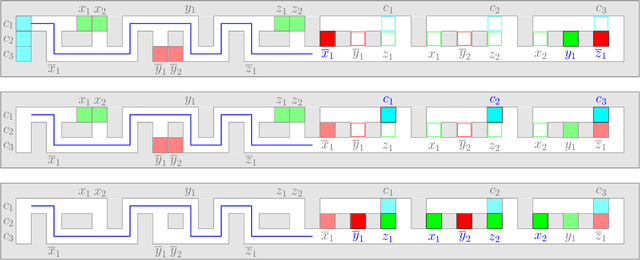

We study the computational complexity of multi-agent path finding (MAPF). Given a graph $G$ and a set of agents, each having a start and target vertex, the goal is to find collision-free paths minimizing the total distance traveled. To better understand the source of difficulty of the problem, we aim to study the simplest and least constrained graph class for which it remains hard. To this end, we restrict $G$ to be a 2D grid, which is a ubiquitous abstraction, as it conveniently allows for modeling well-structured environments (e.g., warehouses). Previous hardness results considered highly constrained 2D grids having only one vertex unoccupied by an agent, while the most restricted hardness result that allowed multiple empty vertices was for (non-grid) planar graphs. We therefore refine previous results by simultaneously considering both 2D grids and multiple empty vertices. We show that even in this case distance-optimal MAPF remains NP-hard, which settles an open problem posed by Banfi et al. (2017). We present a reduction directly from 3-SAT using simple gadgets, making our proof arguably more informative than previous work in terms of potential progress towards positive results. Furthermore, our reduction is the first linear one for the case where $G$ is planar, appearing nearly four decades after the first related result. This allows us to go a step further and exploit the Exponential Time Hypothesis (ETH) to obtain an exponential lower bound for the running time of the problem. Finally, as a stepping stone towards our main results, we prove the NP-hardness of the monotone case, in which agents move one by one with no intermediate stops.
Parameter-Efficient Tuning by Manipulating Hidden States of Pretrained Language Models For Classification Tasks
Apr 13, 2022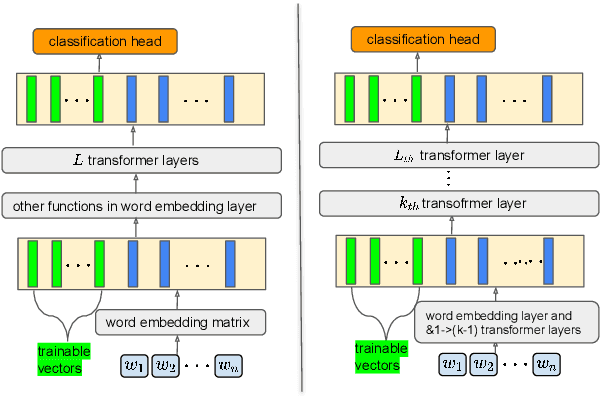
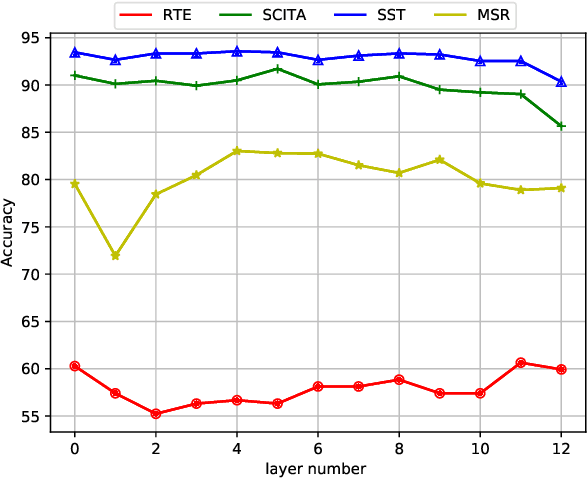
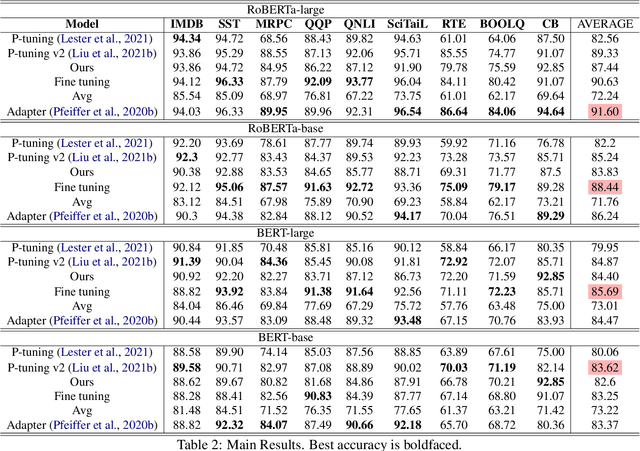
Parameter-efficient tuning aims to distill knowledge for downstream tasks by optimizing a few introduced parameters while freezing the pretrained language models (PLMs). Continuous prompt tuning which prepends a few trainable vectors to the embeddings of input is one of these methods and has drawn much attention due to its effectiveness and efficiency. This family of methods can be illustrated as exerting nonlinear transformations of hidden states inside PLMs. However, a natural question is ignored: can the hidden states be directly used for classification without changing them? In this paper, we aim to answer this question by proposing a simple tuning method which only introduces three trainable vectors. Firstly, we integrate all layers hidden states using the introduced vectors. And then, we input the integrated hidden state(s) to a task-specific linear classifier to predict categories. This scheme is similar to the way ELMo utilises hidden states except that they feed the hidden states to LSTM-based models. Although our proposed tuning scheme is simple, it achieves comparable performance with prompt tuning methods like P-tuning and P-tuning v2, verifying that original hidden states do contain useful information for classification tasks. Moreover, our method has an advantage over prompt tuning in terms of time and the number of parameters.
On the throughput of the common target area for robotic swarm strategies -- extended version
Jan 23, 2022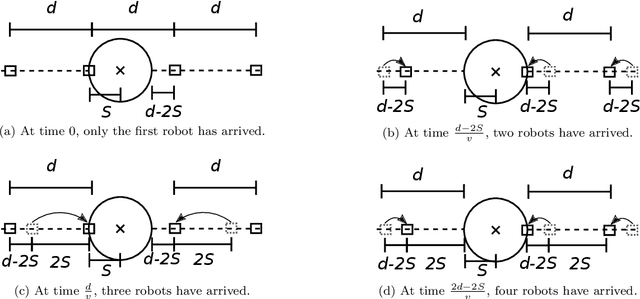
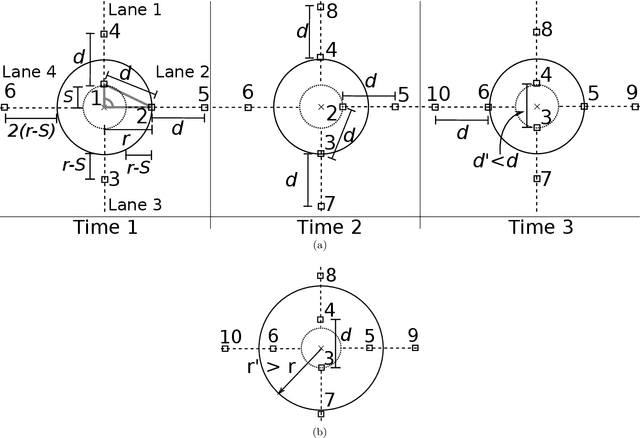
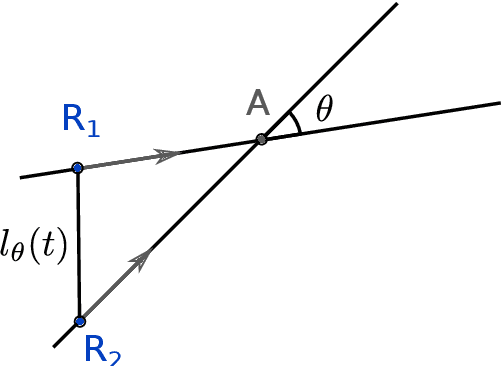
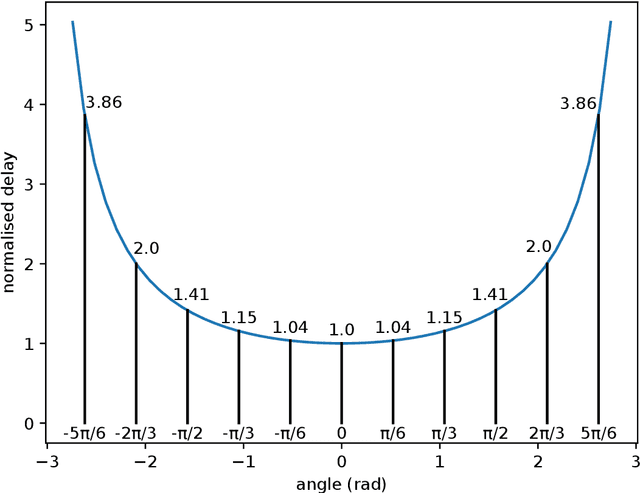
A robotic swarm may encounter traffic congestion when many robots simultaneously attempt to reach the same area. For solving that efficiently, robots must execute decentralised traffic control algorithms. In this work, we propose a measure for evaluating the access efficiency of a common target area as the number of robots in the swarm rises: the common target area throughput. We demonstrate that the throughput of a target region with a limited area as the time tends to infinity -- the asymptotic throughput -- is finite, opposed to the relation arrival time at target per number of robots that tends to infinity. Using this measure, we can analytically compare the effectiveness of different algorithms. In particular, we propose and formally evaluate three different theoretical strategies for getting to a circular target area: (i) forming parallel queues towards the target area, (ii) forming a hexagonal packing through a corridor going to the target, and (iii) making multiple curved trajectories towards the boundary of the target area. We calculate the throughput for a fixed time and the asymptotic throughput for these strategies. Additionally, we corroborate these results by simulations, showing that when an algorithm has higher throughput, its arrival time per number of robots is lower. Thus, we conclude that using throughput is well suited for comparing congestion algorithms for a common target area in robotic swarms even if we do not have their closed asymptotic equation.
Analyzing Wrap-Up Effects through an Information-Theoretic Lens
Mar 31, 2022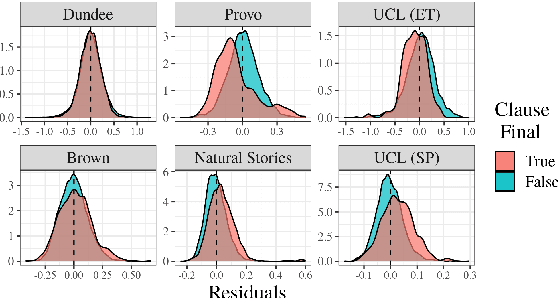
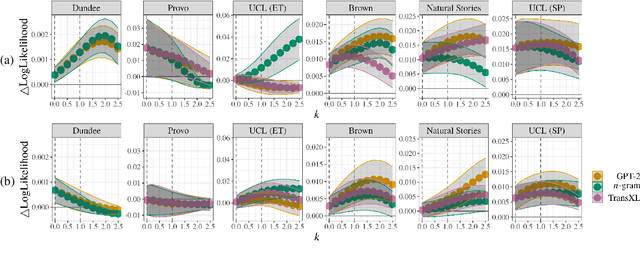
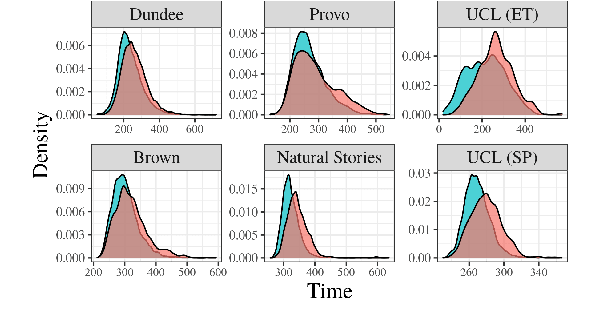
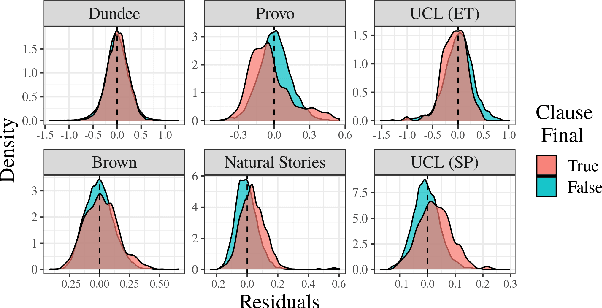
Numerous analyses of reading time (RT) data have been implemented -- all in an effort to better understand the cognitive processes driving reading comprehension. However, data measured on words at the end of a sentence -- or even at the end of a clause -- is often omitted due to the confounding factors introduced by so-called "wrap-up effects," which manifests as a skewed distribution of RTs for these words. Consequently, the understanding of the cognitive processes that might be involved in these wrap-up effects is limited. In this work, we attempt to learn more about these processes by examining the relationship between wrap-up effects and information-theoretic quantities, such as word and context surprisals. We find that the distribution of information in prior contexts is often predictive of sentence- and clause-final RTs (while not of sentence-medial RTs). This lends support to several prior hypotheses about the processes involved in wrap-up effects.
TangoBERT: Reducing Inference Cost by using Cascaded Architecture
Apr 13, 2022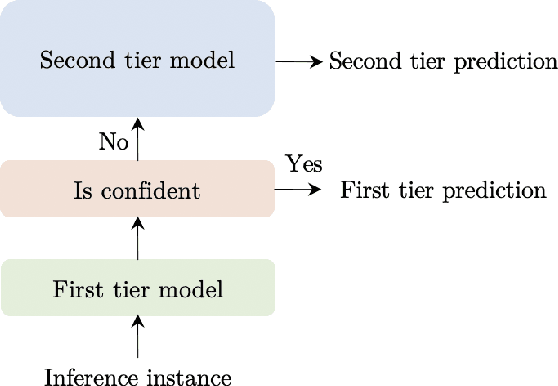

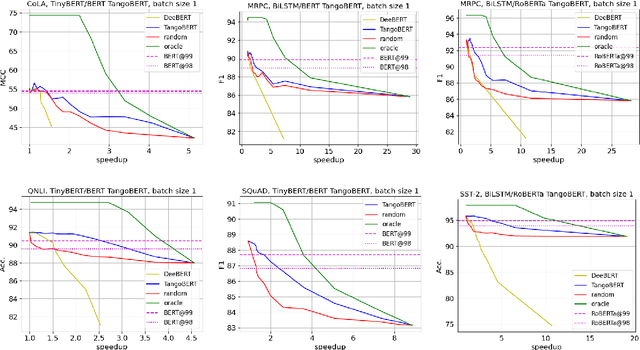
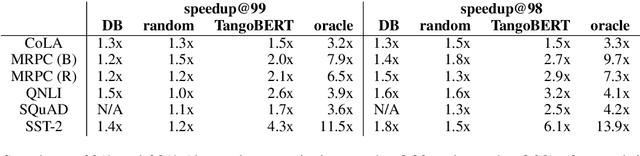
The remarkable success of large transformer-based models such as BERT, RoBERTa and XLNet in many NLP tasks comes with a large increase in monetary and environmental cost due to their high computational load and energy consumption. In order to reduce this computational load in inference time, we present TangoBERT, a cascaded model architecture in which instances are first processed by an efficient but less accurate first tier model, and only part of those instances are additionally processed by a less efficient but more accurate second tier model. The decision of whether to apply the second tier model is based on a confidence score produced by the first tier model. Our simple method has several appealing practical advantages compared to standard cascading approaches based on multi-layered transformer models. First, it enables higher speedup gains (average lower latency). Second, it takes advantage of batch size optimization for cascading, which increases the relative inference cost reductions. We report TangoBERT inference CPU speedup on four text classification GLUE tasks and on one reading comprehension task. Experimental results show that TangoBERT outperforms efficient early exit baseline models; on the the SST-2 task, it achieves an accuracy of 93.9% with a CPU speedup of 8.2x.
An Online Ensemble Learning Model for Detecting Attacks in Wireless Sensor Networks
Apr 28, 2022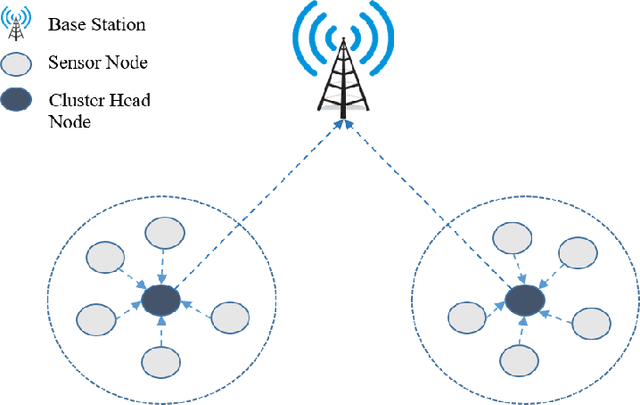
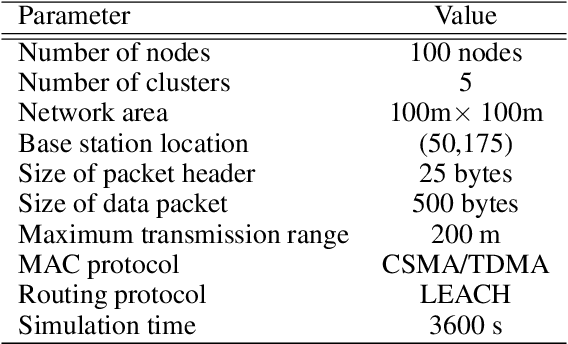
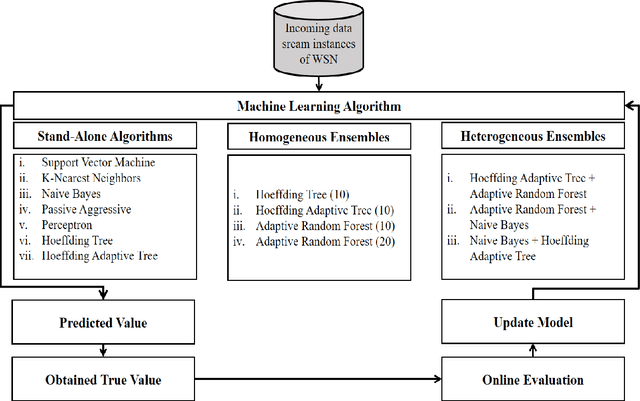
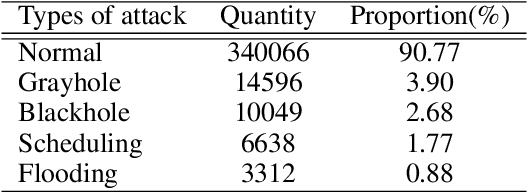
In today's modern world, the usage of technology is unavoidable and the rapid advances in the Internet and communication fields have resulted to expand the Wireless Sensor Network (WSN) technology. A huge number of sensing devices collect and/or generate numerous sensory data throughout time for a wide range of fields and applications. However, WSN has been proven to be vulnerable to security breaches, the harsh and unattended deployment of these networks, combined with their constrained resources and the volume of data generated introduce a major security concern. WSN applications are extremely critical, it is essential to build reliable solutions that involve fast and continuous mechanisms for online data stream analysis enabling the detection of attacks and intrusions. In this context, our aim is to develop an intelligent, efficient, and updatable intrusion detection system by applying an important machine learning concept known as ensemble learning in order to improve detection performance. Although ensemble models have been proven to be useful in offline learning, they have received less attention in streaming applications. In this paper, we examine the application of different homogeneous and heterogeneous online ensembles in sensory data analysis, on a specialized wireless sensor network-detection system (WSN-DS) dataset in order to classify four types of attacks: Blackhole attack, Grayhole, Flooding, and Scheduling among normal network traffic. Among the proposed novel online ensembles, both the heterogeneous ensemble consisting of an Adaptive Random Forest (ARF) combined with the Hoeffding Adaptive Tree (HAT) algorithm and the homogeneous ensemble HAT made up of 10 models achieved higher detection rates of 96.84% and 97.2%, respectively. The above models are efficient and effective in dealing with concept drift, while taking into account the resource constraints of WSNs.
Multi-phase Deformable Registration for Time-dependent Abdominal Organ Variations
Mar 08, 2021
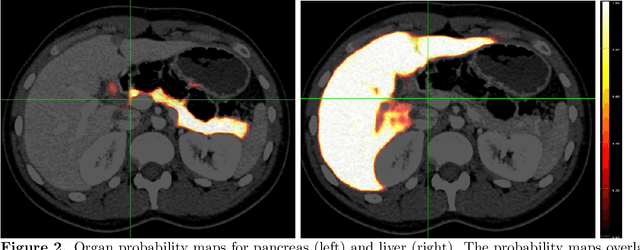
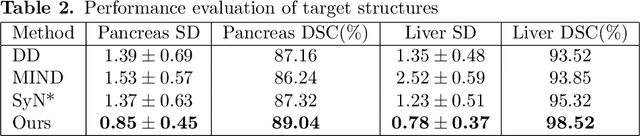
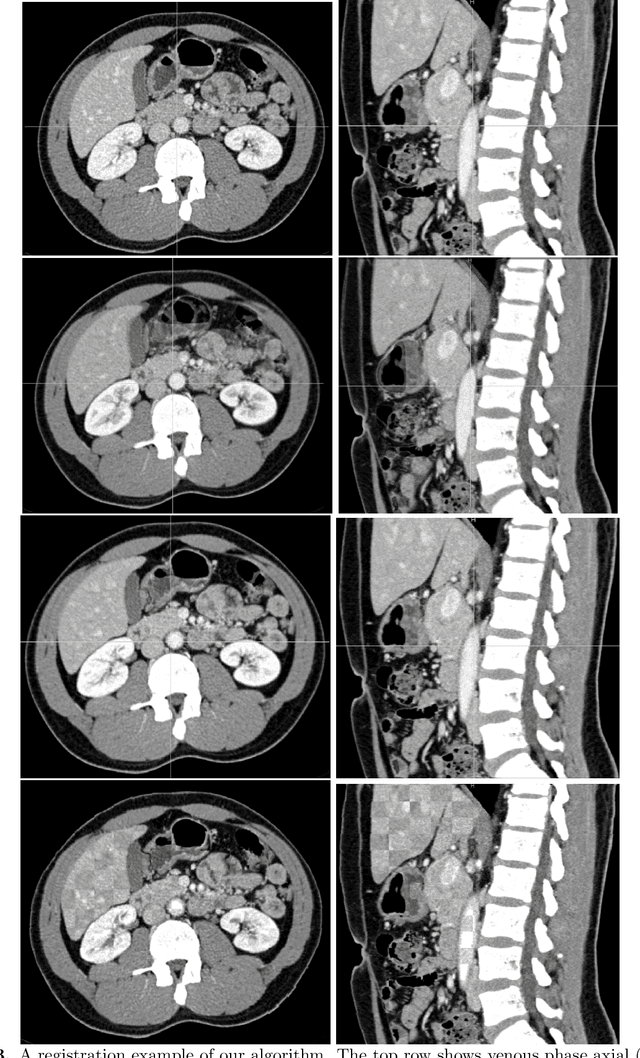
Human body is a complex dynamic system composed of various sub-dynamic parts. Especially, thoracic and abdominal organs have complex internal shape variations with different frequencies by various reasons such as respiration with fast motion and peristalsis with slower motion. CT protocols for abdominal lesions are multi-phase scans for various tumor detection to use different vascular contrast, however, they are not aligned well enough to visually check the same area. In this paper, we propose a time-efficient and accurate deformable registration algorithm for multi-phase CT scans considering abdominal organ motions, which can be applied for differentiable or non-differentiable motions of abdominal organs. Experimental results shows the registration accuracy as 0.85 +/- 0.45mm (mean +/- STD) for pancreas within 1 minute for the whole abdominal region.
Imitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022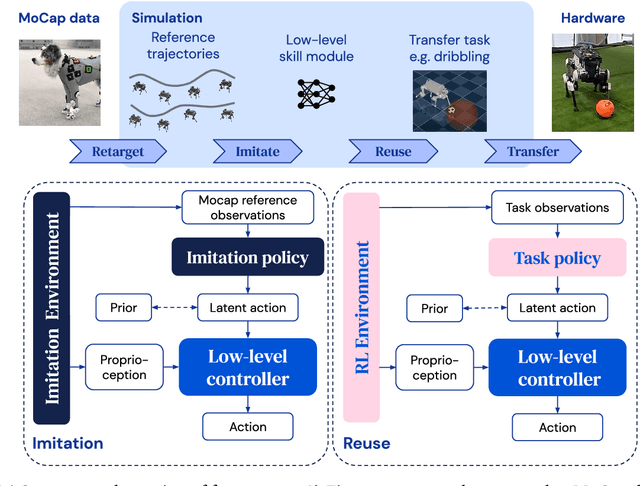

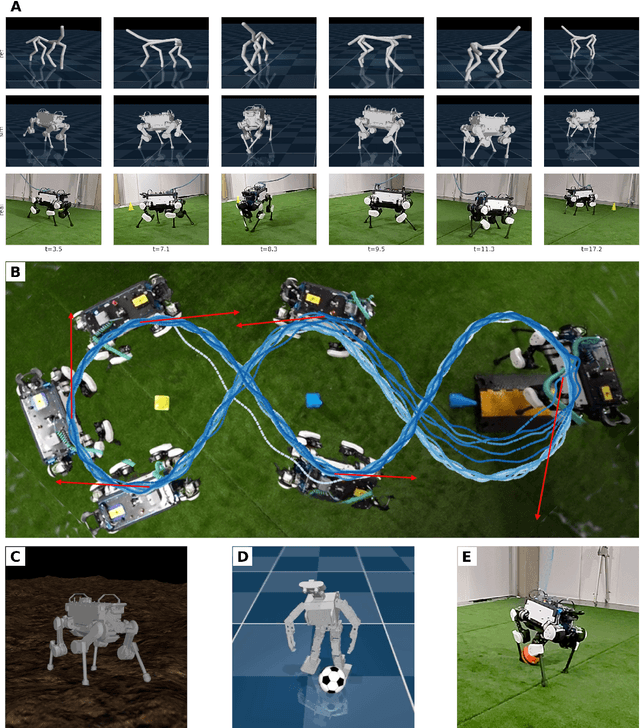
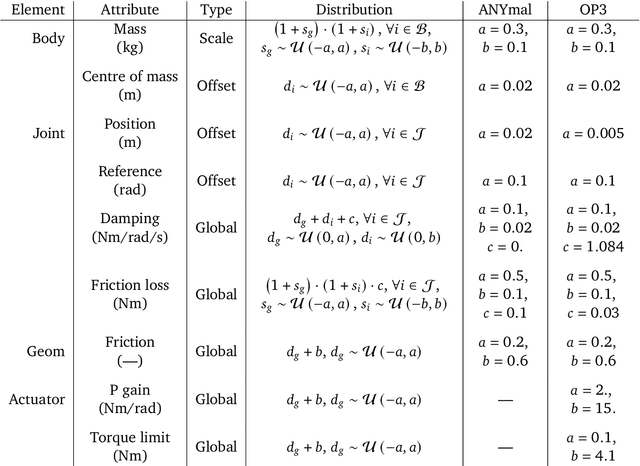
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.