 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Goal Recognition as Reinforcement Learning
Feb 13, 2022
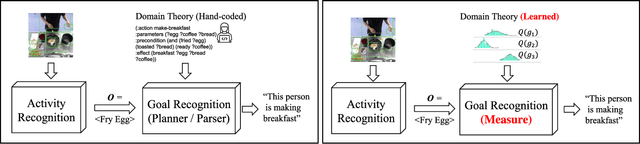
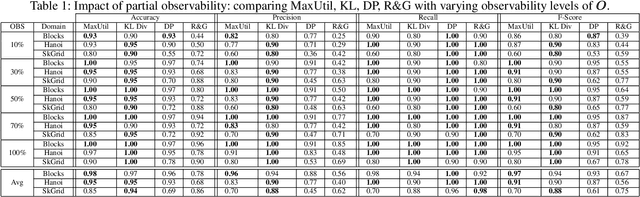
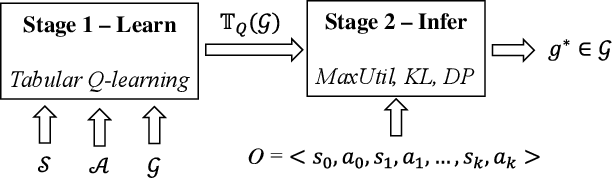

Most approaches for goal recognition rely on specifications of the possible dynamics of the actor in the environment when pursuing a goal. These specifications suffer from two key issues. First, encoding these dynamics requires careful design by a domain expert, which is often not robust to noise at recognition time. Second, existing approaches often need costly real-time computations to reason about the likelihood of each potential goal. In this paper, we develop a framework that combines model-free reinforcement learning and goal recognition to alleviate the need for careful, manual domain design, and the need for costly online executions. This framework consists of two main stages: Offline learning of policies or utility functions for each potential goal, and online inference. We provide a first instance of this framework using tabular Q-learning for the learning stage, as well as three measures that can be used to perform the inference stage. The resulting instantiation achieves state-of-the-art performance against goal recognizers on standard evaluation domains and superior performance in noisy environments.
Unidirectional Thin Adapter for Efficient Adaptation of Deep Neural Networks
Mar 23, 2022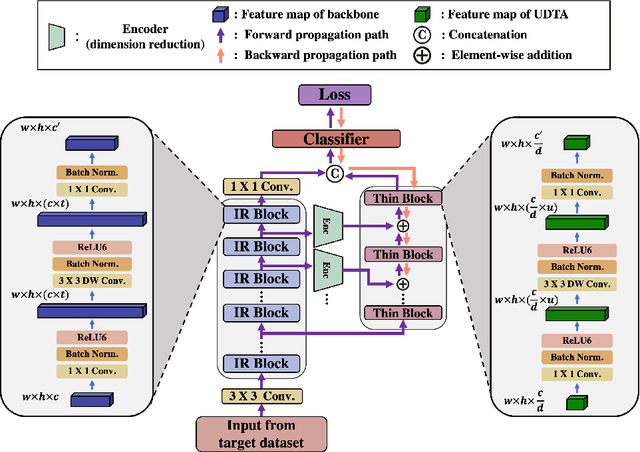
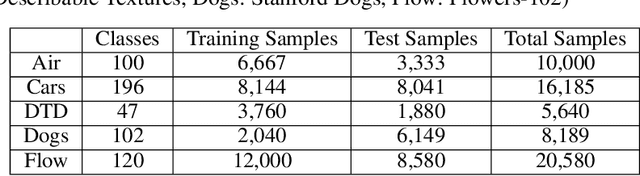
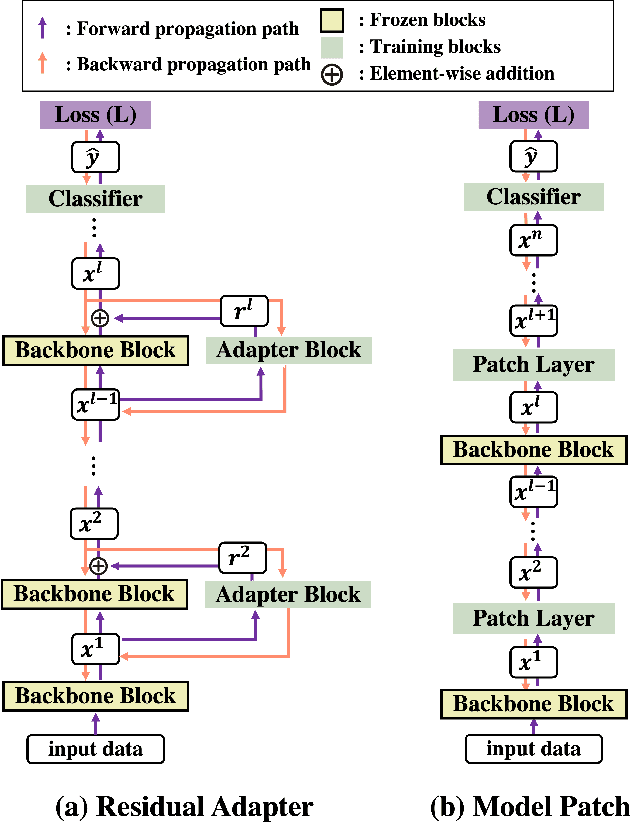
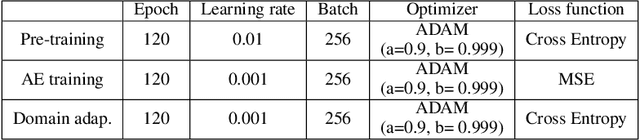
In this paper, we propose a new adapter network for adapting a pre-trained deep neural network to a target domain with minimal computation. The proposed model, unidirectional thin adapter (UDTA), helps the classifier adapt to new data by providing auxiliary features that complement the backbone network. UDTA takes outputs from multiple layers of the backbone as input features but does not transmit any feature to the backbone. As a result, UDTA can learn without computing the gradient of the backbone, which saves computation for training significantly. In addition, since UDTA learns the target task without modifying the backbone, a single backbone can adapt to multiple tasks by learning only UDTAs separately. In experiments on five fine-grained classification datasets consisting of a small number of samples, UDTA significantly reduced computation and training time required for backpropagation while showing comparable or even improved accuracy compared with conventional adapter models.
Proactive Anomaly Detection for Robot Navigation with Multi-Sensor Fusion
Apr 03, 2022

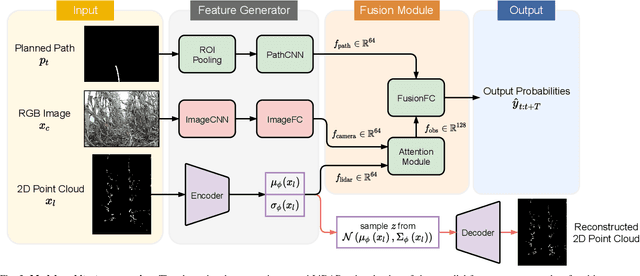

Despite the rapid advancement of navigation algorithms, mobile robots often produce anomalous behaviors that can lead to navigation failures. The ability to detect such anomalous behaviors is a key component in modern robots to achieve high-levels of autonomy. Reactive anomaly detection methods identify anomalous task executions based on the current robot state and thus lack the ability to alert the robot before an actual failure occurs. Such an alert delay is undesirable due to the potential damage to both the robot and the surrounding objects. We propose a proactive anomaly detection network (PAAD) for robot navigation in unstructured and uncertain environments. PAAD predicts the probability of future failure based on the planned motions from the predictive controller and the current observation from the perception module. Multi-sensor signals are fused effectively to provide robust anomaly detection in the presence of sensor occlusion as seen in field environments. Our experiments on field robot data demonstrates superior failure identification performance than previous methods, and that our model can capture anomalous behaviors in real-time while maintaining a low false detection rate in cluttered fields. Code, dataset, and video are available at https://github.com/tianchenji/PAAD
Region of Interest focused MRI to Synthetic CT Translation using Regression and Classification Multi-task Network
Mar 30, 2022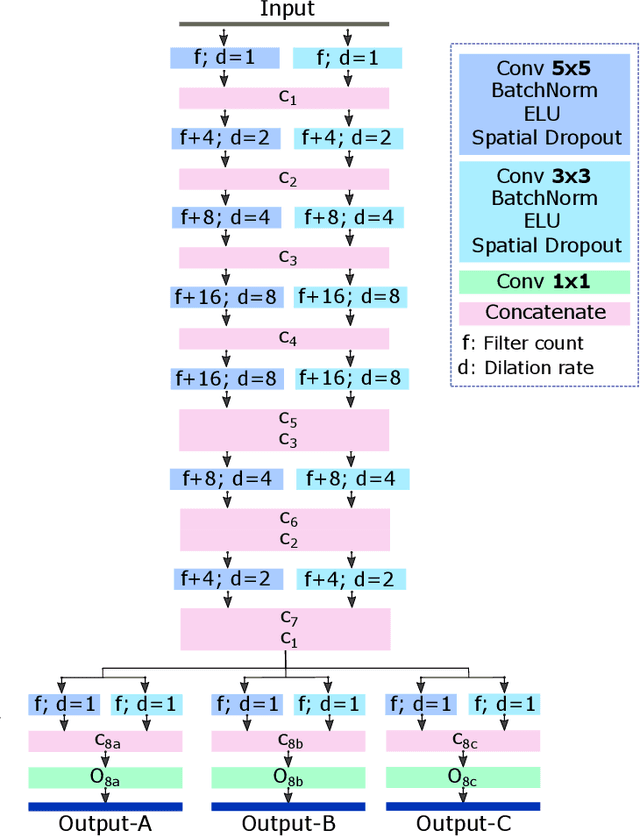
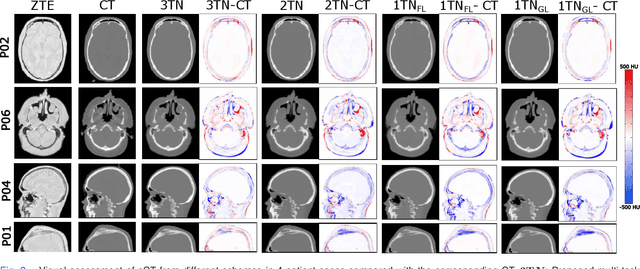
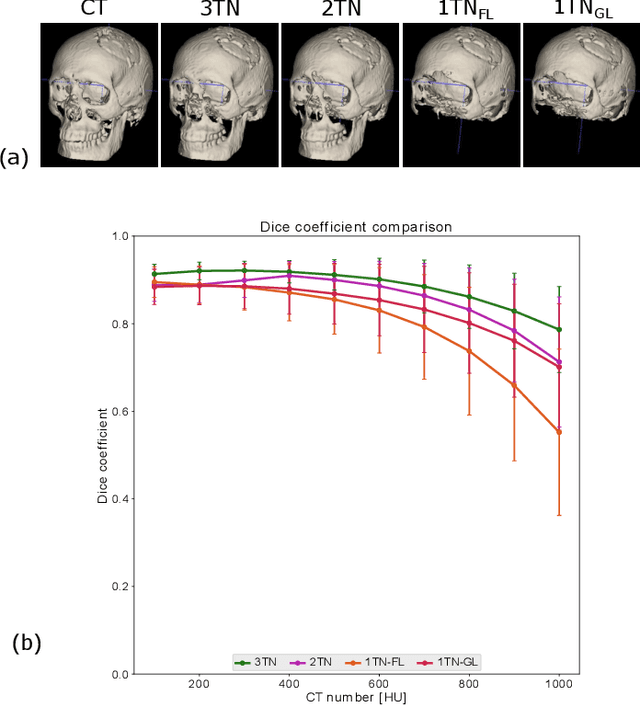
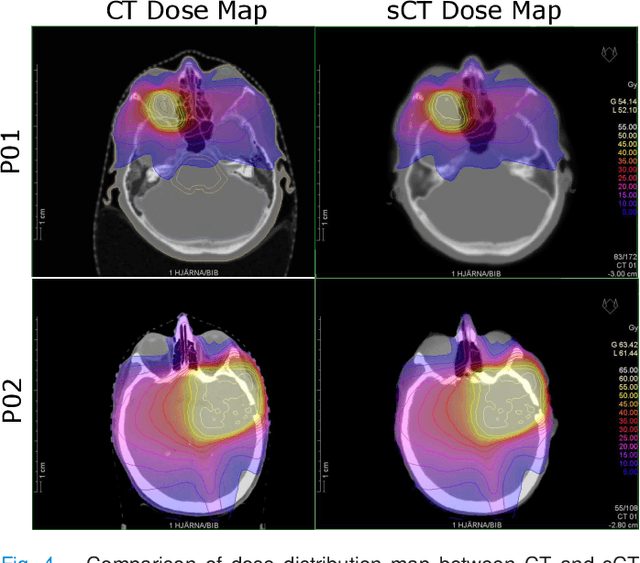
In this work, we present a method for synthetic CT (sCT) generation from zero-echo-time (ZTE) MRI aimed at structural and quantitative accuracies of the image, with a particular focus on the accurate bone density value prediction. We propose a loss function that favors a spatially sparse region in the image. We harness the ability of a multi-task network to produce correlated outputs as a framework to enable localisation of region of interest (RoI) via classification, emphasize regression of values within RoI and still retain the overall accuracy via global regression. The network is optimized by a composite loss function that combines a dedicated loss from each task. We demonstrate how the multi-task network with RoI focused loss offers an advantage over other configurations of the network to achieve higher accuracy of performance. This is relevant to sCT where failure to accurately estimate high Hounsfield Unit values of bone could lead to impaired accuracy in clinical applications. We compare the dose calculation maps from the proposed sCT and the real CT in a radiation therapy treatment planning setup.
HDSDF: Hybrid Directional and Signed Distance Functions for Fast Inverse Rendering
Mar 30, 2022

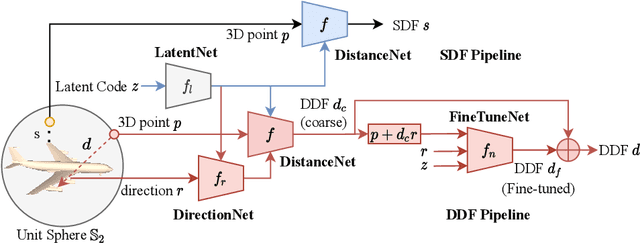
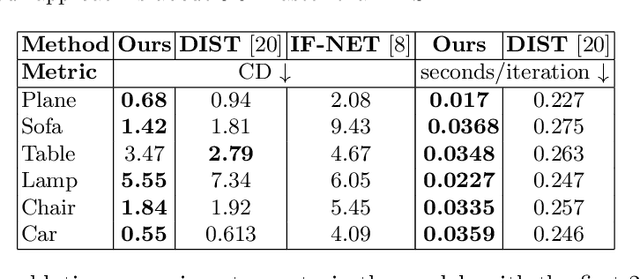
Implicit neural representations of 3D shapes form strong priors that are useful for various applications, such as single and multiple view 3D reconstruction. A downside of existing neural representations is that they require multiple network evaluations for rendering, which leads to high computational costs. This limitation forms a bottleneck particularly in the context of inverse problems, such as image-based 3D reconstruction. To address this issue, in this paper (i) we propose a novel hybrid 3D object representation based on a signed distance function (SDF) that we augment with a directional distance function (DDF), so that we can predict distances to the object surface from any point on a sphere enclosing the object. Moreover, (ii) using the proposed hybrid representation we address the multi-view consistency problem common in existing DDF representations. We evaluate our novel hybrid representation on the task of single-view depth reconstruction and show that our method is several times faster compared to competing methods, while at the same time achieving better reconstruction accuracy.
Learning Classifiers under Delayed Feedback with a Time Window Assumption
Sep 28, 2020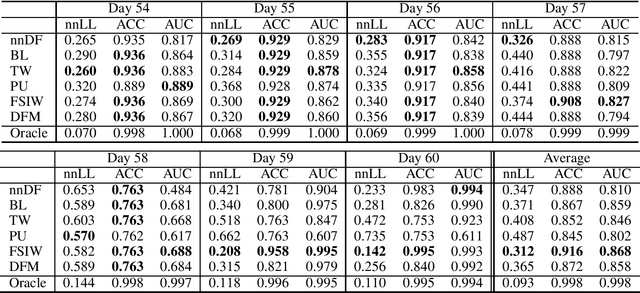

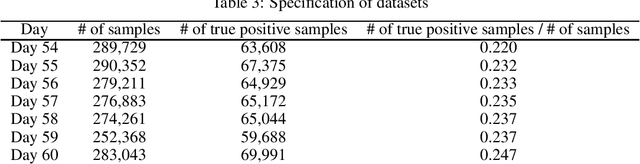
We consider training a binary classifier under delayed feedback (DF Learning). In DF Learning, we first receive negative samples; subsequently, some samples turn positive. This problem is conceivable in various real-world applications such as online advertisements, where the user action takes place long after the first click. Owing to the delayed feedback, simply separating the positive and negative data causes a sample selection bias. One solution is to assume that a long time window after first observing a sample reduces the sample selection bias. However, existing studies report that only using a portion of all samples based on the time window assumption yields suboptimal performance, and the use of all samples along with the time window assumption improves empirical performance. Extending these existing studies, we propose a method with an unbiased and convex empirical risk constructed from the whole samples under the time window assumption. We provide experimental results to demonstrate the effectiveness of the proposed method using a real traffic log dataset.
CycDA: Unsupervised Cycle Domain Adaptation from Image to Video
Mar 30, 2022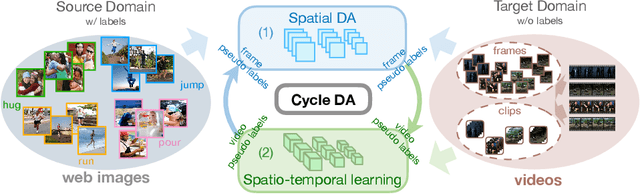
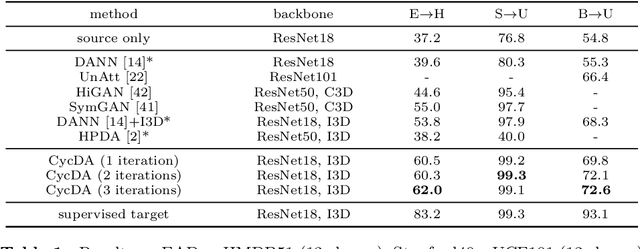
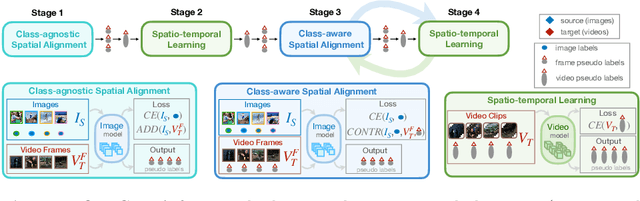
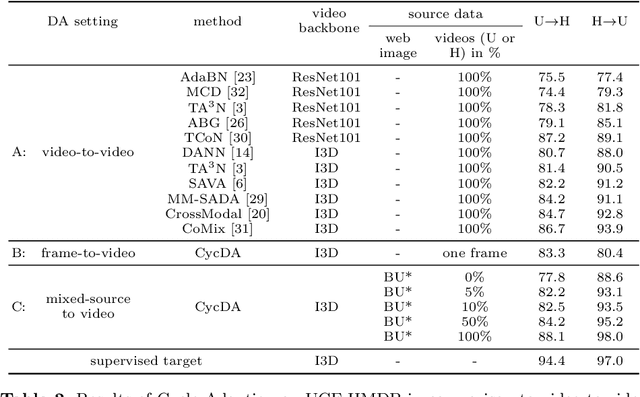
Although action recognition has achieved impressive results over recent years, both collection and annotation of video training data are still time-consuming and cost intensive. Therefore, image-to-video adaptation has been proposed to exploit labeling-free web image source for adapting on unlabeled target videos. This poses two major challenges: (1) spatial domain shift between web images and video frames; (2) modality gap between image and video data. To address these challenges, we propose Cycle Domain Adaptation (CycDA), a cycle-based approach for unsupervised image-to-video domain adaptation by leveraging the joint spatial information in images and videos on the one hand and, on the other hand, training an independent spatio-temporal model to bridge the modality gap. We alternate between the spatial and spatio-temporal learning with knowledge transfer between the two in each cycle. We evaluate our approach on benchmark datasets for image-to-video as well as for mixed-source domain adaptation achieving state-of-the-art results and demonstrating the benefits of our cyclic adaptation.
Strong Admissibility, a Tractable Algorithmic Approach (proofs)
Apr 07, 2022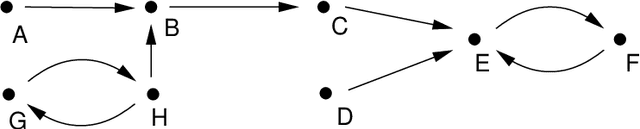
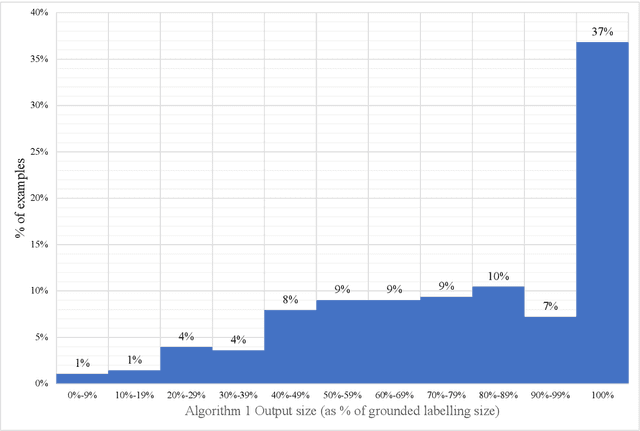
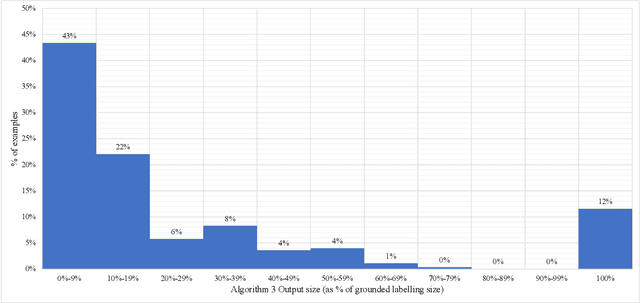
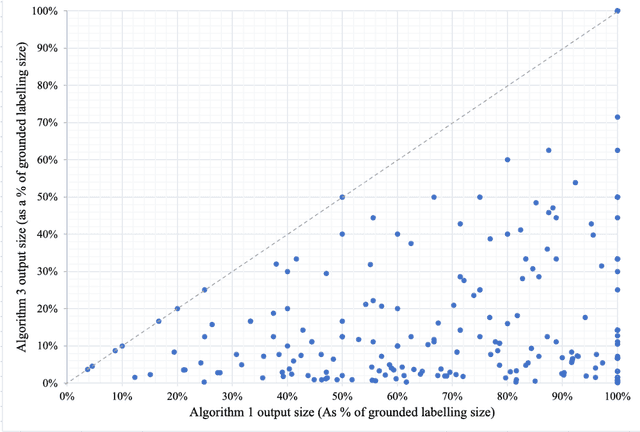
Much like admissibility is the key concept underlying preferred semantics, strong admissibility is the key concept underlying grounded semantics, as membership of a strongly admissible set is sufficient to show membership of the grounded extension. As such, strongly admissible sets and labellings can be used as an explanation of membership of the grounded extension, as is for instance done in some of the proof procedures for grounded semantics. In the current paper, we present two polynomial algorithms for constructing relatively small strongly admissible labellings, with associated min-max numberings, for a particular argument. These labellings can be used as relatively small explanations for the argument's membership of the grounded extension. Although our algorithms are not guaranteed to yield an absolute minimal strongly admissible labelling for the argument (as doing do would have implied an exponential complexity), our best performing algorithm yields results that are only marginally bigger. Moreover, the runtime of this algorithm is an order of magnitude smaller than that of the existing approach for computing an absolute minimal strongly admissible labelling for a particular argument. As such, we believe that our algorithms can be of practical value in situations where the aim is to construct a minimal or near-minimal strongly admissible labelling in a time-efficient way.
Fetal Brain Tissue Annotation and Segmentation Challenge Results
Apr 20, 2022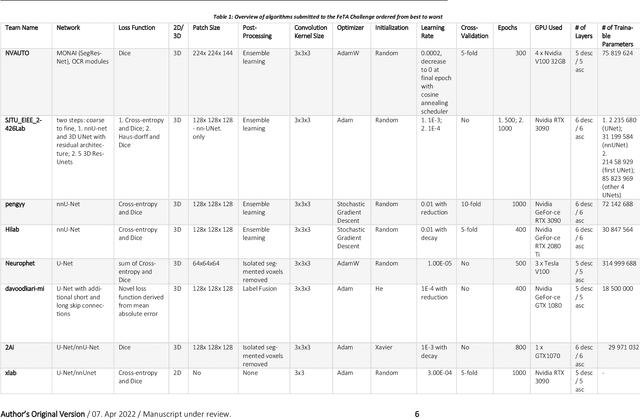
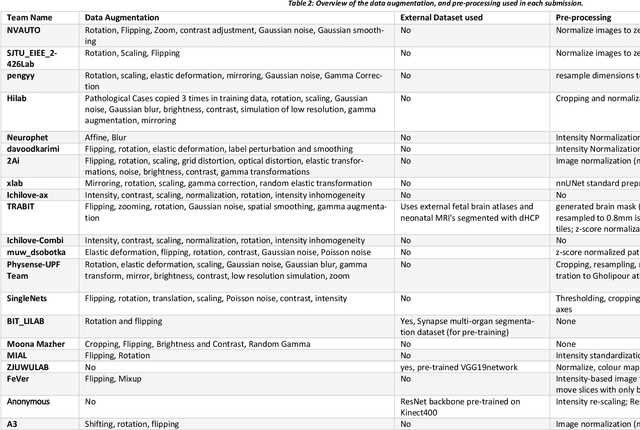
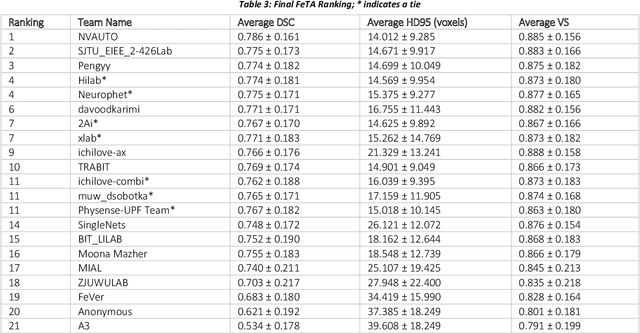
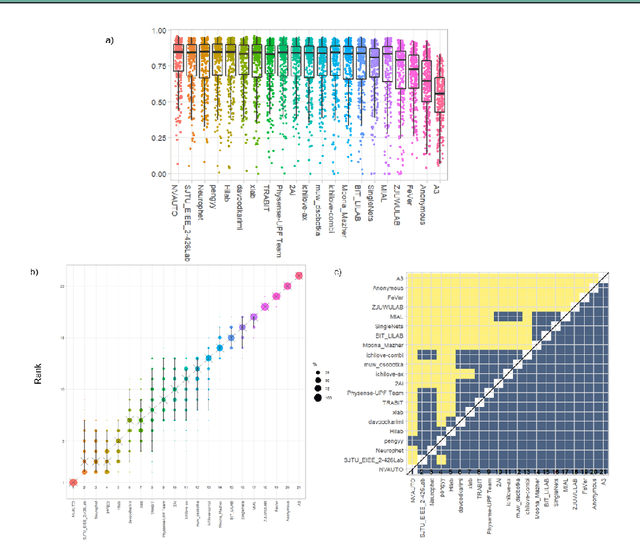
In-utero fetal MRI is emerging as an important tool in the diagnosis and analysis of the developing human brain. Automatic segmentation of the developing fetal brain is a vital step in the quantitative analysis of prenatal neurodevelopment both in the research and clinical context. However, manual segmentation of cerebral structures is time-consuming and prone to error and inter-observer variability. Therefore, we organized the Fetal Tissue Annotation (FeTA) Challenge in 2021 in order to encourage the development of automatic segmentation algorithms on an international level. The challenge utilized FeTA Dataset, an open dataset of fetal brain MRI reconstructions segmented into seven different tissues (external cerebrospinal fluid, grey matter, white matter, ventricles, cerebellum, brainstem, deep grey matter). 20 international teams participated in this challenge, submitting a total of 21 algorithms for evaluation. In this paper, we provide a detailed analysis of the results from both a technical and clinical perspective. All participants relied on deep learning methods, mainly U-Nets, with some variability present in the network architecture, optimization, and image pre- and post-processing. The majority of teams used existing medical imaging deep learning frameworks. The main differences between the submissions were the fine tuning done during training, and the specific pre- and post-processing steps performed. The challenge results showed that almost all submissions performed similarly. Four of the top five teams used ensemble learning methods. However, one team's algorithm performed significantly superior to the other submissions, and consisted of an asymmetrical U-Net network architecture. This paper provides a first of its kind benchmark for future automatic multi-tissue segmentation algorithms for the developing human brain in utero.
Real-Time, Deep Synthetic Aperture Sonar (SAS) Autofocus
Mar 18, 2021
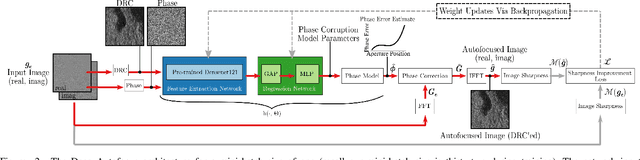
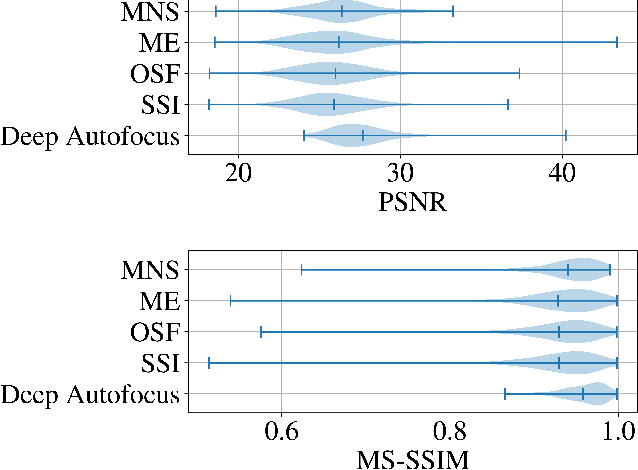

Synthetic aperture sonar (SAS) requires precise time-of-flight measurements of the transmitted/received waveform to produce well-focused imagery. It is not uncommon for errors in these measurements to be present resulting in image defocusing. To overcome this, an \emph{autofocus} algorithm is employed as a post-processing step after image reconstruction to improve image focus. A particular class of these algorithms can be framed as a sharpness/contrast metric-based optimization. To improve convergence, a hand-crafted weighting function to remove "bad" areas of the image is sometimes applied to the image-under-test before the optimization procedure. Additionally, dozens of iterations are necessary for convergence which is a large compute burden for low size, weight, and power (SWaP) systems. We propose a deep learning technique to overcome these limitations and implicitly learn the weighting function in a data-driven manner. Our proposed method, which we call Deep Autofocus, uses features from the single-look-complex (SLC) to estimate the phase correction which is applied in $k$-space. Furthermore, we train our algorithm on batches of training imagery so that during deployment, only a single iteration of our method is sufficient to autofocus. We show results demonstrating the robustness of our technique by comparing our results to four commonly used image sharpness metrics. Our results demonstrate Deep Autofocus can produce imagery perceptually better than common iterative techniques but at a lower computational cost. We conclude that Deep Autofocus can provide a more favorable cost-quality trade-off than alternatives with significant potential of future research.