 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AudioTagging Done Right: 2nd comparison of deep learning methods for environmental sound classification
Apr 03, 2022
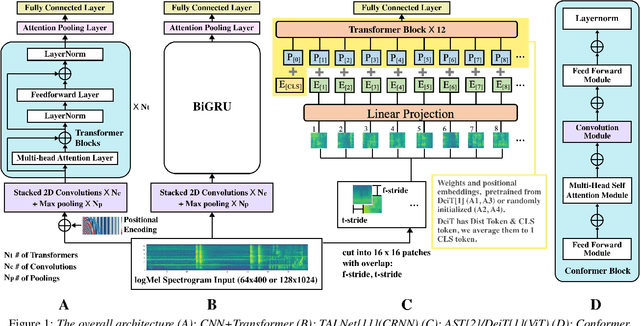
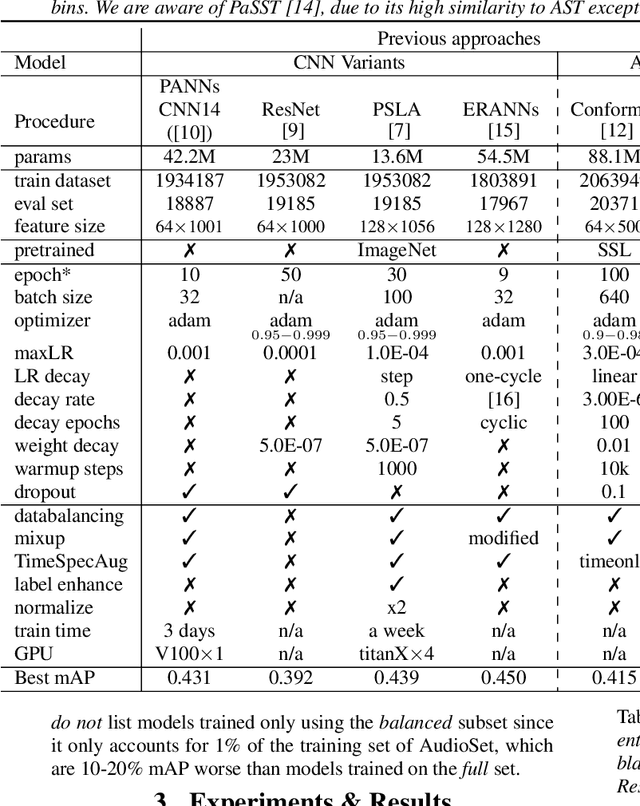
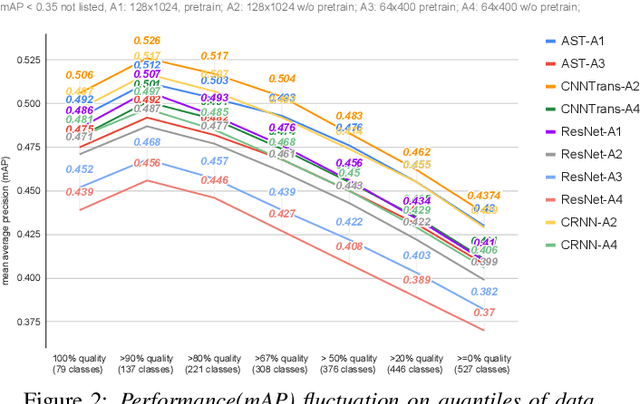

After its sweeping success in vision and language tasks, pure attention-based neural architectures (e.g. DeiT) are emerging to the top of audio tagging (AT) leaderboards, which seemingly obsoletes traditional convolutional neural networks (CNNs), feed-forward networks or recurrent networks. However, taking a closer look, there is great variability in published research, for instance, performances of models initialized with pretrained weights differ drastically from without pretraining, training time for a model varies from hours to weeks, and often, essences are hidden in seemingly trivial details. This urgently calls for a comprehensive study since our 1st comparison is half-decade old. In this work, we perform extensive experiments on AudioSet which is the largest weakly-labeled sound event dataset available, we also did an analysis based on the data quality and efficiency. We compare a few state-of-the-art baselines on the AT task, and study the performance and efficiency of 2 major categories of neural architectures: CNN variants and attention-based variants. We also closely examine their optimization procedures. Our opensourced experimental results provide insights to trade-off between performance, efficiency, optimization process, for both practitioners and researchers. Implementation: https://github.com/lijuncheng16/AudioTaggingDoneRight
Explaining a Deep Reinforcement Learning Docking Agent Using Linear Model Trees with User Adapted Visualization
Mar 01, 2022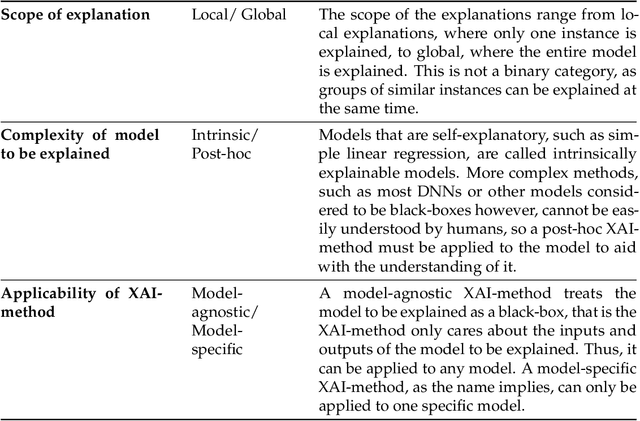
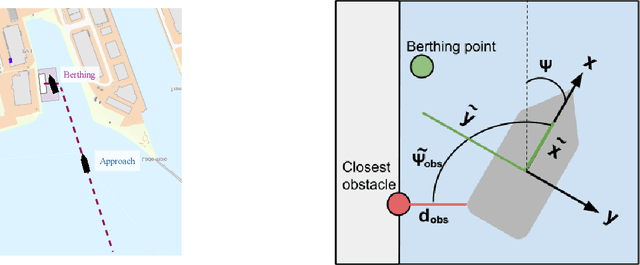
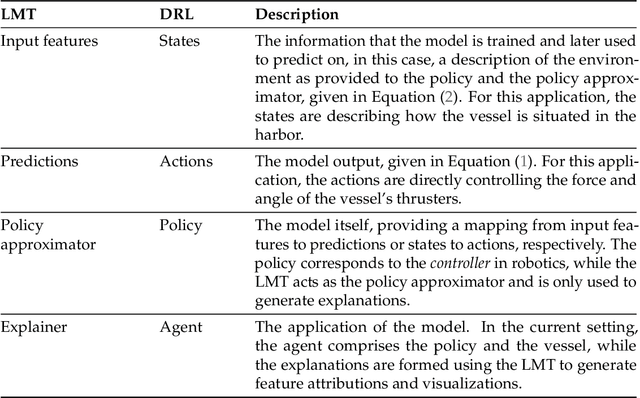
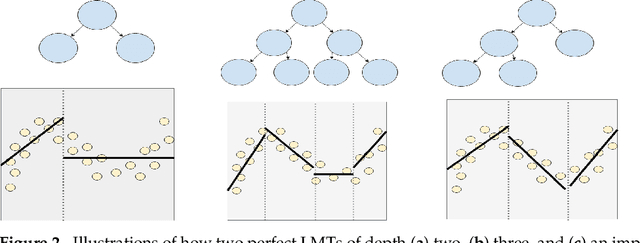
Deep neural networks (DNNs) can be useful within the marine robotics field, but their utility value is restricted by their black-box nature. Explainable artificial intelligence methods attempt to understand how such black-boxes make their decisions. In this work, linear model trees (LMTs) are used to approximate the DNN controlling an autonomous surface vessel (ASV) in a simulated environment and then run in parallel with the DNN to give explanations in the form of feature attributions in real-time. How well a model can be understood depends not only on the explanation itself, but also on how well it is presented and adapted to the receiver of said explanation. Different end-users may need both different types of explanations, as well as different representations of these. The main contributions of this work are (1) significantly improving both the accuracy and the build time of a greedy approach for building LMTs by introducing ordering of features in the splitting of the tree, (2) giving an overview of the characteristics of the seafarer/operator and the developer as two different end-users of the agent and receiver of the explanations, and (3) suggesting a visualization of the docking agent, the environment, and the feature attributions given by the LMT for when the developer is the end-user of the system, and another visualization for when the seafarer or operator is the end-user, based on their different characteristics.
Late multimodal fusion for image and audio music transcription
Apr 06, 2022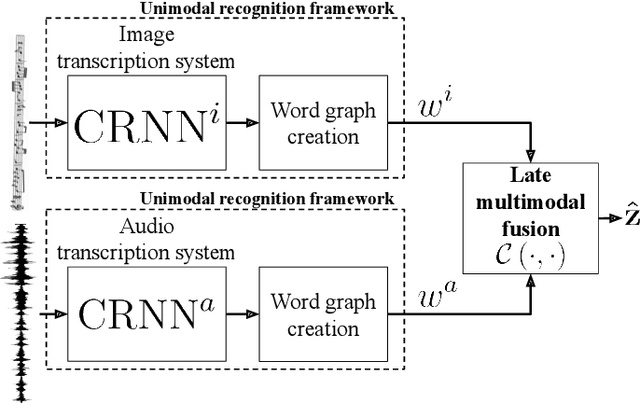
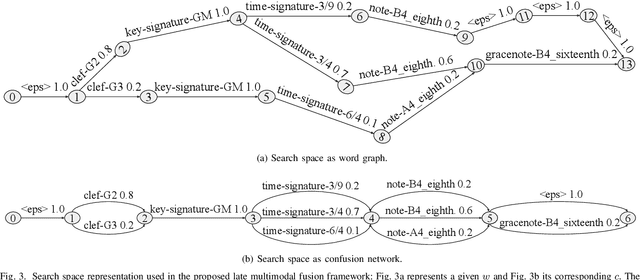
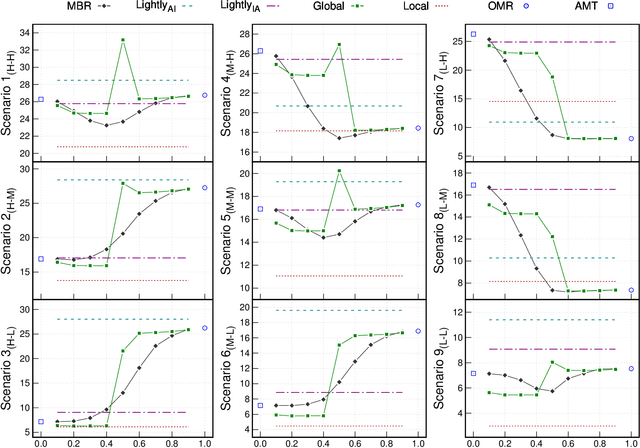

Music transcription, which deals with the conversion of music sources into a structured digital format, is a key problem for Music Information Retrieval (MIR). When addressing this challenge in computational terms, the MIR community follows two lines of research: music documents, which is the case of Optical Music Recognition (OMR), or audio recordings, which is the case of Automatic Music Transcription (AMT). The different nature of the aforementioned input data has conditioned these fields to develop modality-specific frameworks. However, their recent definition in terms of sequence labeling tasks leads to a common output representation, which enables research on a combined paradigm. In this respect, multimodal image and audio music transcription comprises the challenge of effectively combining the information conveyed by image and audio modalities. In this work, we explore this question at a late-fusion level: we study four combination approaches in order to merge, for the first time, the hypotheses regarding end-to-end OMR and AMT systems in a lattice-based search space. The results obtained for a series of performance scenarios -- in which the corresponding single-modality models yield different error rates -- showed interesting benefits of these approaches. In addition, two of the four strategies considered significantly improve the corresponding unimodal standard recognition frameworks.
Learning Transferable Reward for Query Object Localization with Policy Adaptation
Mar 08, 2022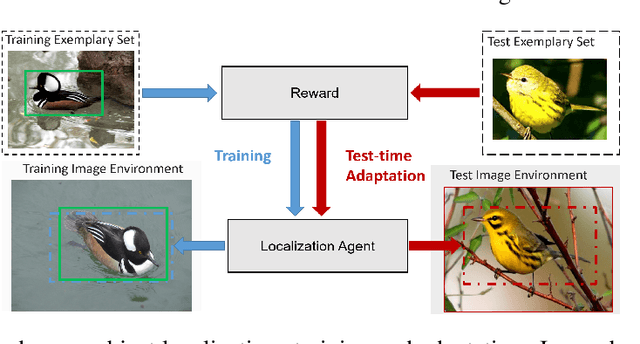
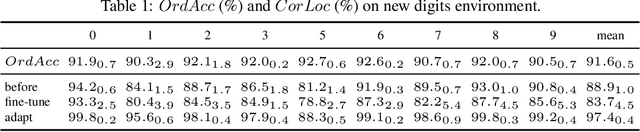
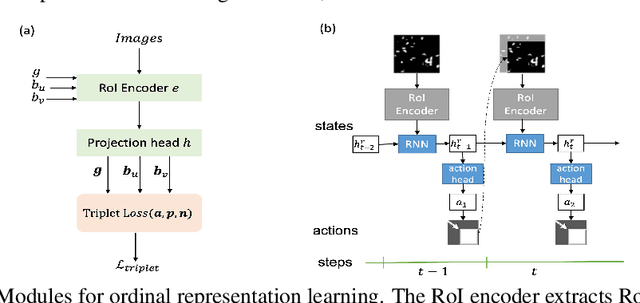

We propose a reinforcement learning based approach to query object localization, for which an agent is trained to localize objects of interest specified by a small exemplary set. We learn a transferable reward signal formulated using the exemplary set by ordinal metric learning. Our proposed method enables test-time policy adaptation to new environments where the reward signals are not readily available, and outperforms fine-tuning approaches that are limited to annotated images. In addition, the transferable reward allows repurposing the trained agent from one specific class to another class. Experiments on corrupted MNIST, CU-Birds, and COCO datasets demonstrate the effectiveness of our approach.
Text-Driven Video Acceleration: A Weakly-Supervised Reinforcement Learning Method
Mar 29, 2022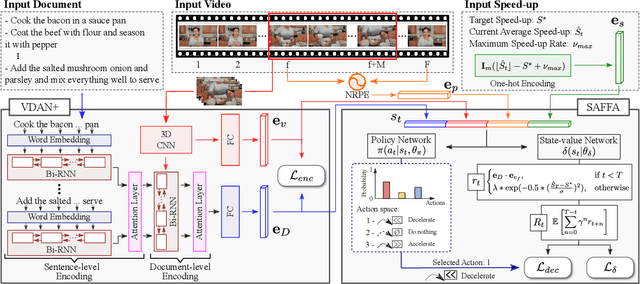

The growth of videos in our digital age and the users' limited time raise the demand for processing untrimmed videos to produce shorter versions conveying the same information. Despite the remarkable progress that summarization methods have made, most of them can only select a few frames or skims, creating visual gaps and breaking the video context. This paper presents a novel weakly-supervised methodology based on a reinforcement learning formulation to accelerate instructional videos using text. A novel joint reward function guides our agent to select which frames to remove and reduce the input video to a target length without creating gaps in the final video. We also propose the Extended Visually-guided Document Attention Network (VDAN+), which can generate a highly discriminative embedding space to represent both textual and visual data. Our experiments show that our method achieves the best performance in Precision, Recall, and F1 Score against the baselines while effectively controlling the video's output length. Visit https://www.verlab.dcc.ufmg.br/semantic-hyperlapse/tpami2022/ for code and extra results.
Tackling System and Statistical Heterogeneity for Federated Learning with Adaptive Client Sampling
Dec 21, 2021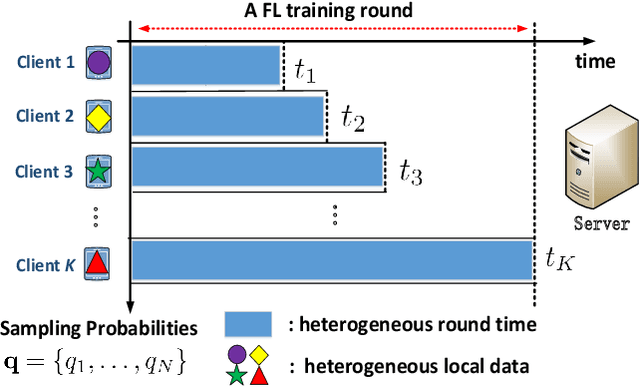
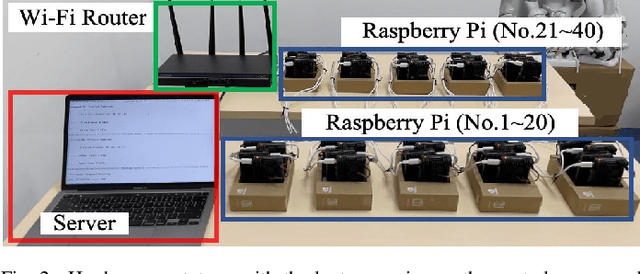
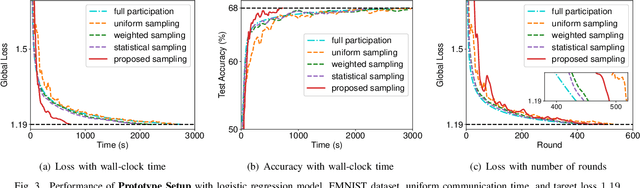
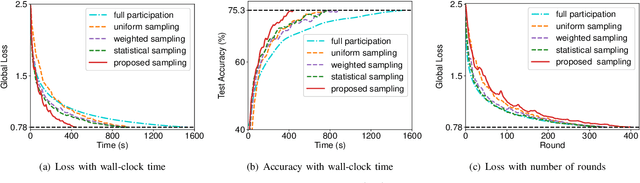
Federated learning (FL) algorithms usually sample a fraction of clients in each round (partial participation) when the number of participants is large and the server's communication bandwidth is limited. Recent works on the convergence analysis of FL have focused on unbiased client sampling, e.g., sampling uniformly at random, which suffers from slow wall-clock time for convergence due to high degrees of system heterogeneity and statistical heterogeneity. This paper aims to design an adaptive client sampling algorithm that tackles both system and statistical heterogeneity to minimize the wall-clock convergence time. We obtain a new tractable convergence bound for FL algorithms with arbitrary client sampling probabilities. Based on the bound, we analytically establish the relationship between the total learning time and sampling probabilities, which results in a non-convex optimization problem for training time minimization. We design an efficient algorithm for learning the unknown parameters in the convergence bound and develop a low-complexity algorithm to approximately solve the non-convex problem. Experimental results from both hardware prototype and simulation demonstrate that our proposed sampling scheme significantly reduces the convergence time compared to several baseline sampling schemes. Notably, our scheme in hardware prototype spends 73% less time than the uniform sampling baseline for reaching the same target loss.
Event Based Time-Vectors for auditory features extraction: a neuromorphic approach for low power audio recognition
Dec 13, 2021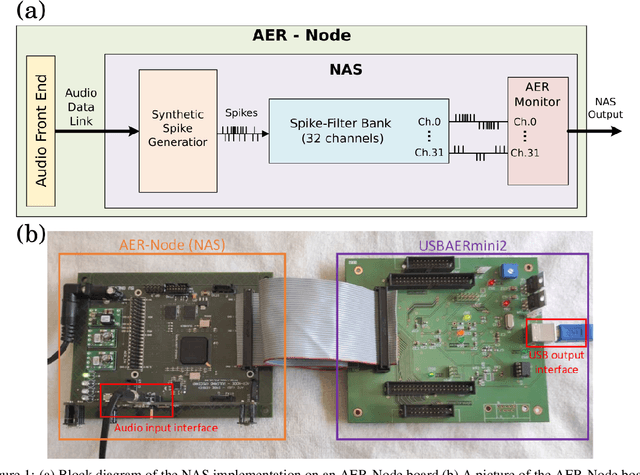
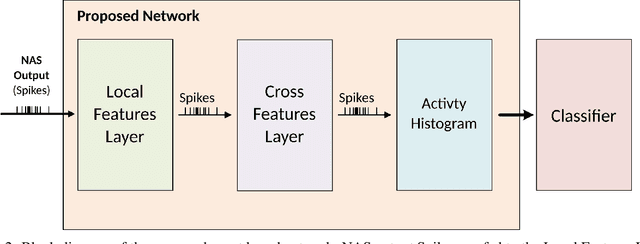
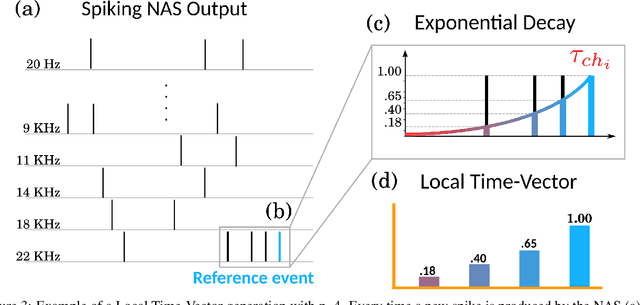
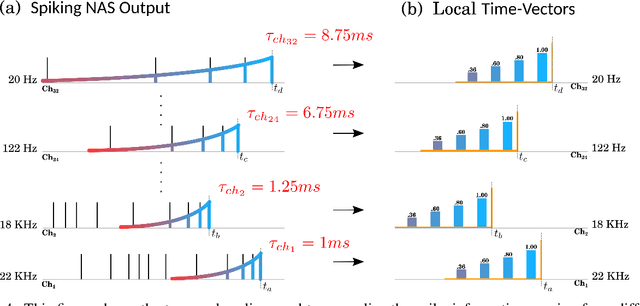
In recent years tremendous efforts have been done to advance the state of the art for Natural Language Processing (NLP) and audio recognition. However, these efforts often translated in increased power consumption and memory requirements for bigger and more complex models. These solutions falls short of the constraints of IoT devices which need low power, low memory efficient computation, and therefore they fail to meet the growing demand of efficient edge computing. Neuromorphic systems have proved to be excellent candidates for low-power low-latency computation in a multitude of applications. For this reason we present a neuromorphic architecture, capable of unsupervised auditory feature recognition. We then validate the network on a subset of Google's Speech Commands dataset.
Global Sentiment Analysis Of COVID-19 Tweets Over Time
Oct 27, 2020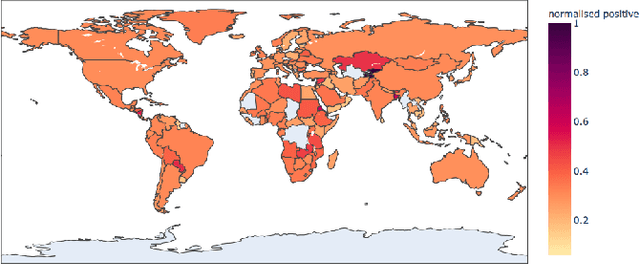
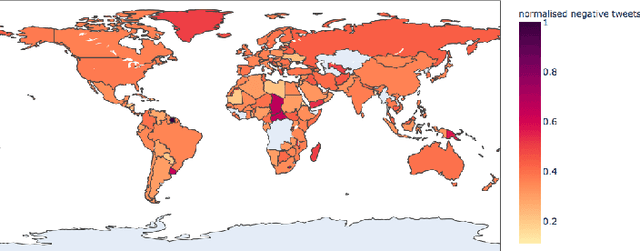
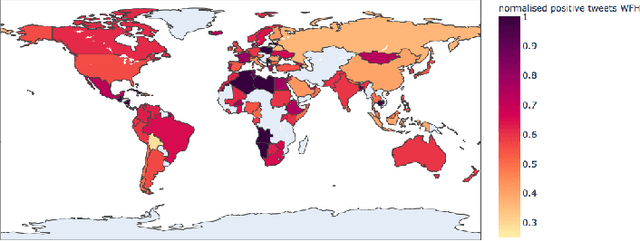
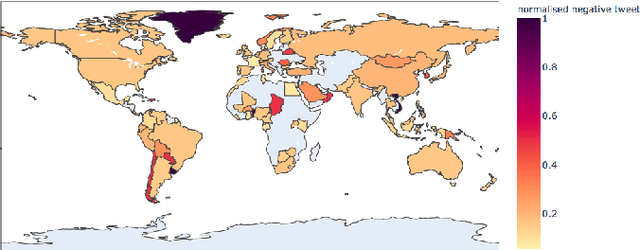
The Coronavirus pandemic has affected the normal course of life. People around the world have taken to social media to express their opinions and general emotions regarding this phenomenon that has taken over the world by storm. The social networking site, Twitter showed an unprecedented increase in tweets related to the novel Coronavirus in a very short span of time. This paper presents the global sentiment analysis of tweets related to Coronavirus and how the sentiment of people in different countries has changed over time. Furthermore, to determine the impact of Coronavirus on daily aspects of life, tweets related to Work From Home (WFH) and Online Learning were scraped and the change in sentiment over time was observed. In addition, various Machine Learning models such as Long Short Term Memory (LSTM) and Artificial Neural Networks (ANN) were implemented for sentiment classification and their accuracies were determined. Exploratory data analysis was also performed for a dataset providing information about the number of confirmed cases on a per-day basis in a few of the worst-hit countries to provide a comparison between the change in sentiment with the change in cases since the start of this pandemic till June 2020.
A Review of Machine Learning Methods Applied to Structural Dynamics and Vibroacoustic
Apr 13, 2022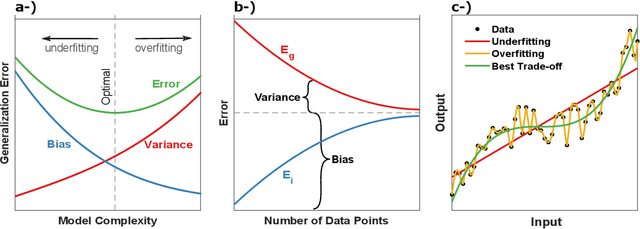
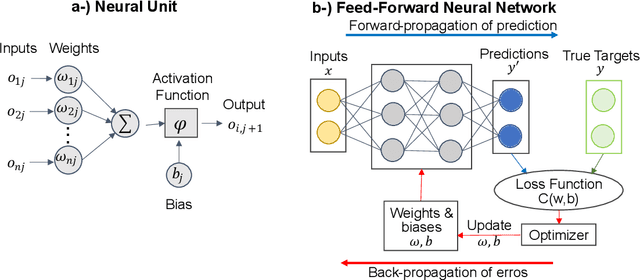
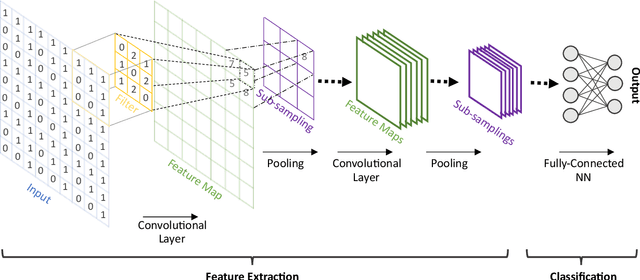
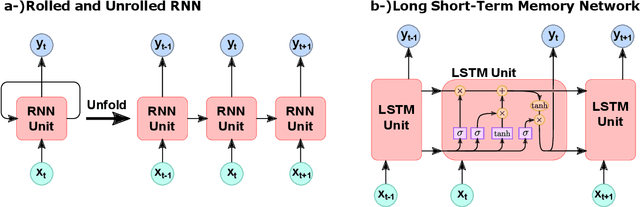
The use of Machine Learning (ML) has rapidly spread across several fields, having encountered many applications in Structural Dynamics and Vibroacoustic (SD\&V). The increasing capabilities of ML to unveil insights from data, driven by unprecedented data availability, algorithms advances and computational power, enhance decision making, uncertainty handling, patterns recognition and real-time assessments. Three main applications in SD\&V have taken advantage of these benefits. In Structural Health Monitoring, ML detection and prognosis lead to safe operation and optimized maintenance schedules. System identification and control design are leveraged by ML techniques in Active Noise Control and Active Vibration Control. Finally, the so-called ML-based surrogate models provide fast alternatives to costly simulations, enabling robust and optimized product design. Despite the many works in the area, they have not been reviewed and analyzed. Therefore, to keep track and understand this ongoing integration of fields, this paper presents a survey of ML applications in SD\&V analyses, shedding light on the current state of implementation and emerging opportunities. The main methodologies, advantages, limitations, and recommendations based on scientific knowledge were identified for each of the three applications. Moreover, the paper considers the role of Digital Twins and Physics Guided ML to overcome current challenges and power future research progress. As a result, the survey provides a broad overview of the present landscape of ML applied in SD\&V and guides the reader to an advanced understanding of progress and prospects in the field.
Where Is My Training Bottleneck? Hidden Trade-Offs in Deep Learning Preprocessing Pipelines
Feb 17, 2022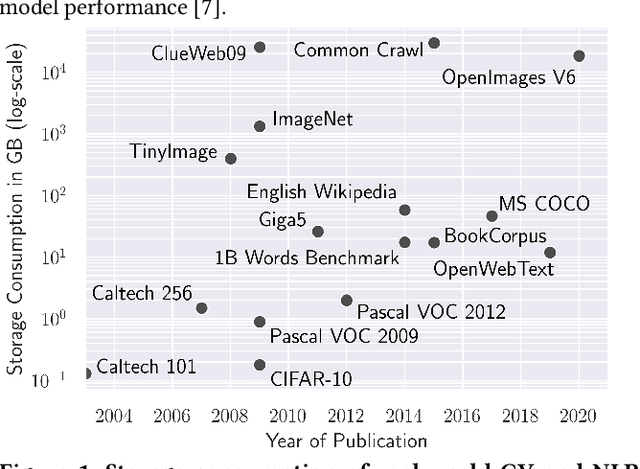

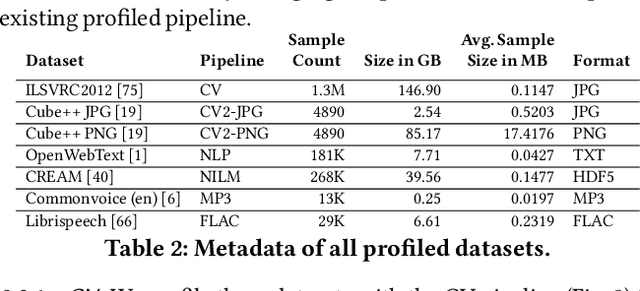
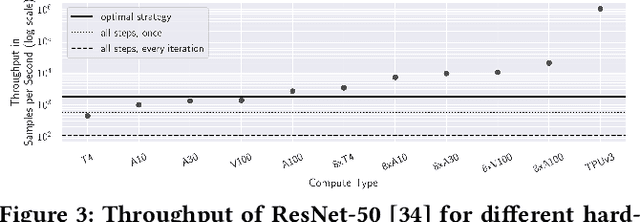
Preprocessing pipelines in deep learning aim to provide sufficient data throughput to keep the training processes busy. Maximizing resource utilization is becoming more challenging as the throughput of training processes increases with hardware innovations (e.g., faster GPUs, TPUs, and inter-connects) and advanced parallelization techniques that yield better scalability. At the same time, the amount of training data needed in order to train increasingly complex models is growing. As a consequence of this development, data preprocessing and provisioning are becoming a severe bottleneck in end-to-end deep learning pipelines. In this paper, we provide an in-depth analysis of data preprocessing pipelines from four different machine learning domains. We introduce a new perspective on efficiently preparing datasets for end-to-end deep learning pipelines and extract individual trade-offs to optimize throughput, preprocessing time, and storage consumption. Additionally, we provide an open-source profiling library that can automatically decide on a suitable preprocessing strategy to maximize throughput. By applying our generated insights to real-world use-cases, we obtain an increased throughput of 3x to 13x compared to an untuned system while keeping the pipeline functionally identical. These findings show the enormous potential of data pipeline tuning.