 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Identifying Exoplanets with Machine Learning Methods: A Preliminary Study
Apr 01, 2022
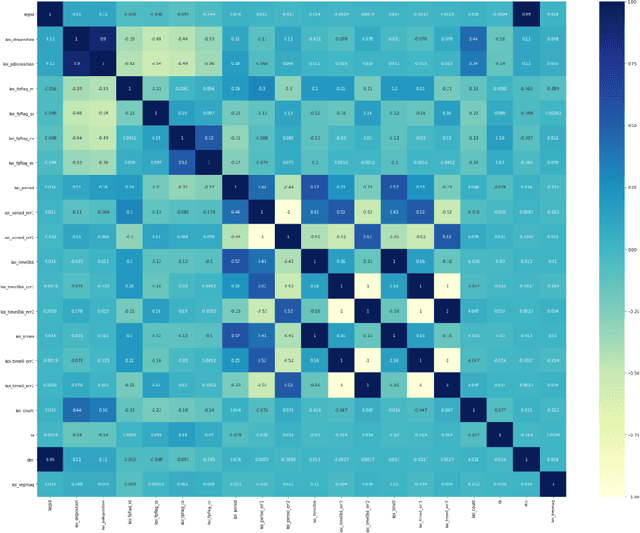

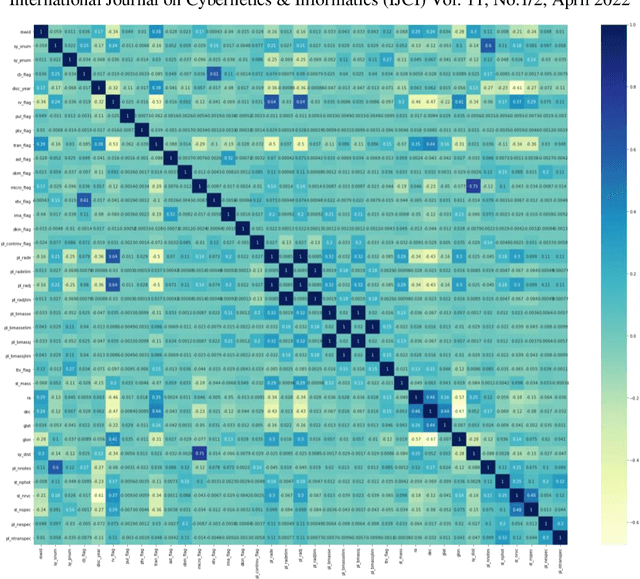
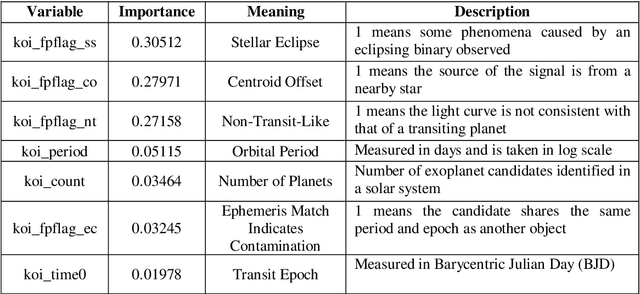
The discovery of habitable exoplanets has long been a heated topic in astronomy. Traditional methods for exoplanet identification include the wobble method, direct imaging, gravitational microlensing, etc., which not only require a considerable investment of manpower, time, and money, but also are limited by the performance of astronomical telescopes. In this study, we proposed the idea of using machine learning methods to identify exoplanets. We used the Kepler dataset collected by NASA from the Kepler Space Observatory to conduct supervised learning, which predicts the existence of exoplanet candidates as a three-categorical classification task, using decision tree, random forest, na\"ive Bayes, and neural network; we used another NASA dataset consisted of the confirmed exoplanets data to conduct unsupervised learning, which divides the confirmed exoplanets into different clusters, using k-means clustering. As a result, our models achieved accuracies of 99.06%, 92.11%, 88.50%, and 99.79%, respectively, in the supervised learning task and successfully obtained reasonable clusters in the unsupervised learning task.
* 12 pages with 9 figures and 2 tables
NASA/GSFC's Flight Software Core Flight System Implementation For A Lunar Surface Imaging Mission
Apr 14, 2022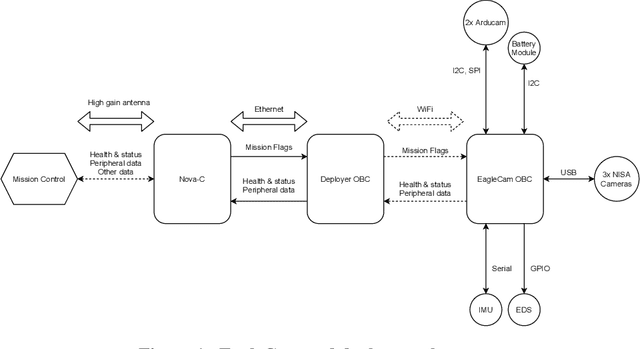

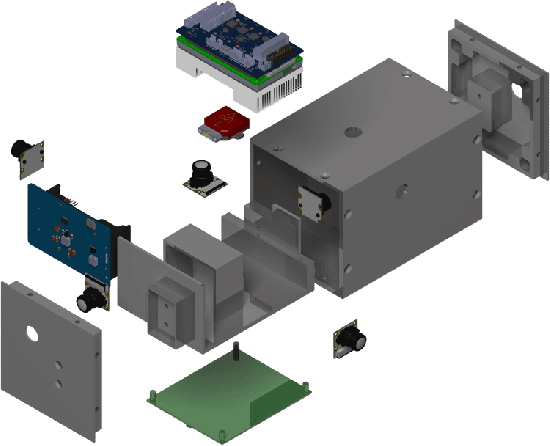
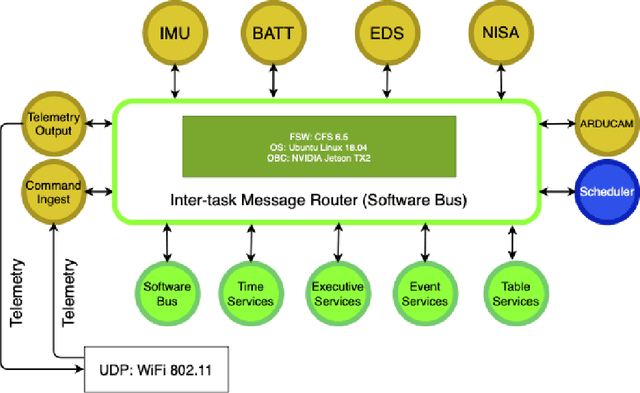
The interest in returning to the Moon for research and exploration has increased as new tipping point technologies are providing the possibility to do so. One of these initiatives is the Artemis program by NASA, which plans to return humans by 2024 to the lunar surface and study water deposits on the surface. This program will also serve as a practice run to plan the logistics of sending humans to explore Mars. To return humans safely to the Moon, multiple technological advances and diverse knowledge about the nature of the lunar surface are needed. This paper will discuss the design and implementation of the flight software of EagleCam, a CubeSat camera system based on the free open-source core Flight System (cFS) architecture developed by NASA's Goddard Space Flight Center. EagleCam is a payload transported to the Moon by the Commercial Lunar Payload Services Nova-C lander developed by Intuitive Machines. The camera system will capture the first third-person view of a spacecraft performing a Moon landing and collect other scientific data such as plume interaction with the surface. The complete system is composed of the CubeSat and the deployer that will eject it. This will be the first time WiFi protocol is used on the Moon to establish a local communication network.
Centralized Adversarial Learning for Robust Deep Hashing
Apr 18, 2022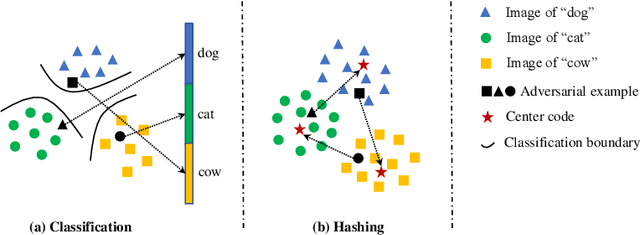
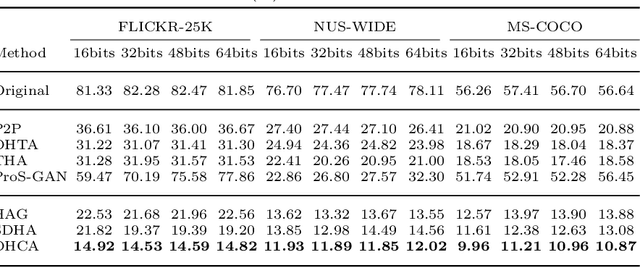
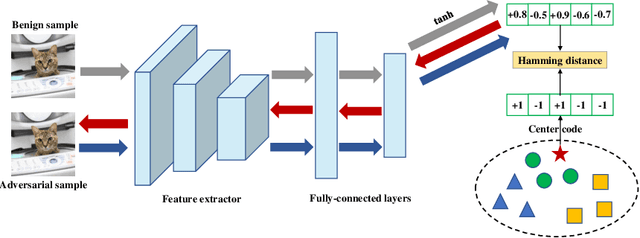
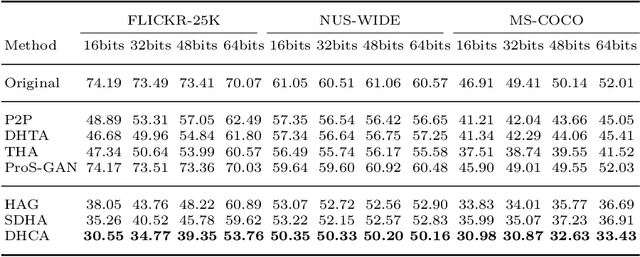
Deep hashing has been extensively utilized in massive image retrieval because of its efficiency and effectiveness. Recently, it becomes a hot issue to study adversarial examples which poses a security challenge to deep hashing models. However, there is still a critical bottleneck: how to find a superior and exact semantic representative as the guide to further enhance the adversarial attack and defense in deep hashing based retrieval. We, for the first time, attempt to design an effective adversarial learning with the min-max paradigm to improve the robustness of hashing networks by using the generated adversarial samples. Specifically, we obtain the optimal solution (called center code) through a proved Continuous Hash Center Method (CHCM), which preserves the semantic similarity with positive samples and dissimilarity with negative samples. On one hand, we propose the Deep Hashing Central Attack (DHCA) for efficient attack on hashing retrieval by maximizing the Hamming distance between the hash code of adversarial example and the center code. On the other hand, we present the Deep Hashing Central Adversarial Training (DHCAT) to optimize the hashing networks for defense, by minimizing the Hamming distance to the center code. Extensive experiments on the benchmark datasets verify that our attack method can achieve better performance than the state-of-the-arts, and our defense algorithm can effectively mitigate the effects of adversarial perturbations.
APPLADE: Adjustable Plug-and-play Audio Declipper Combining DNN with Sparse Optimization
Feb 16, 2022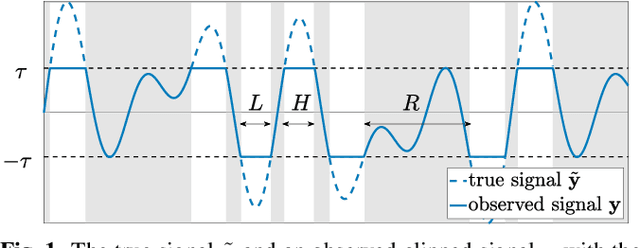
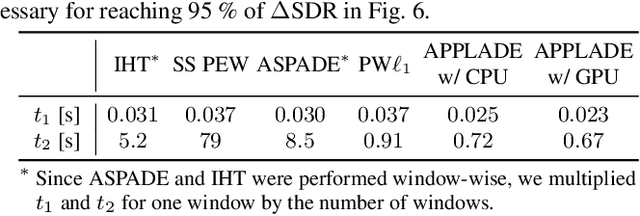
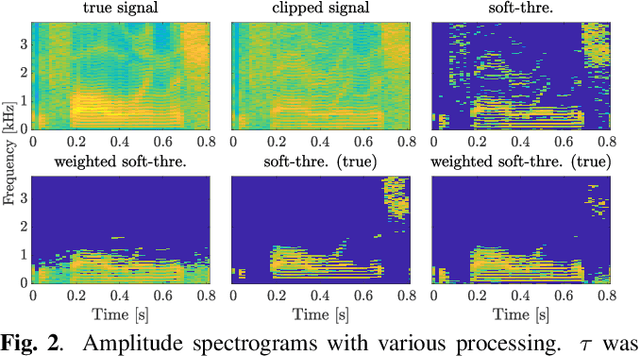
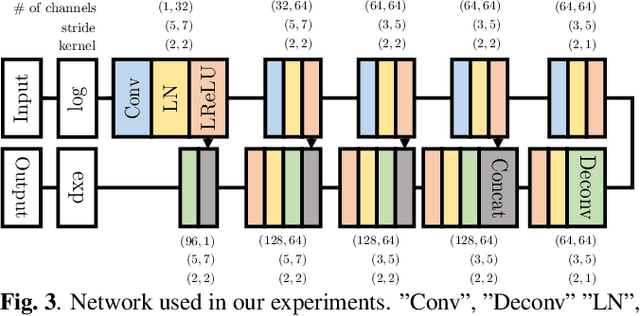
In this paper, we propose an audio declipping method that takes advantages of both sparse optimization and deep learning. Since sparsity-based audio declipping methods have been developed upon constrained optimization, they are adjustable and well-studied in theory. However, they always uniformly promote sparsity and ignore the individual properties of a signal. Deep neural network (DNN)-based methods can learn the properties of target signals and use them for audio declipping. Still, they cannot perform well if the training data have mismatches and/or constraints in the time domain are not imposed. In the proposed method, we use a DNN in an optimization algorithm. It is inspired by an idea called plug-and-play (PnP) and enables us to promote sparsity based on the learned information of data, considering constraints in the time domain. Our experiments confirmed that the proposed method is stable and robust to mismatches between training and test data.
SDR-based Testbed for Real-time CQI Prediction for URLLC
Mar 05, 2021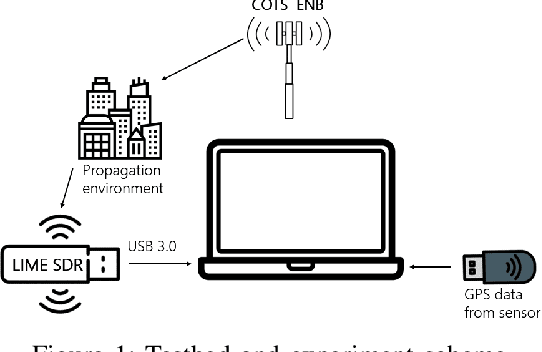

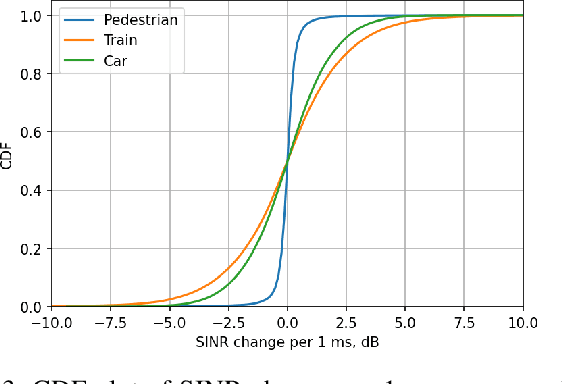
Ultra-reliable Low-Latency Communication (URLLC) is a key feature of 5G systems. The quality of service (QoS) requirements imposed by URLLC are less than 10ms delay and less than $10^{-5}$ packet loss rate (PLR). To satisfy such strict requirements with minimal channel resource consumption, the devices need to accurately predict the channel quality and select Modulation and Coding Scheme (MCS) for URLLC in a proper way. This paper presents a novel real-time channel prediction system based on Software-Defined Radio that uses a neural network. The paper also describes and shares an open channel measurement dataset that can be used to compare various channel prediction approaches in different mobility scenarios in future research on URLLC
Efficient Argument Structure Extraction with Transfer Learning and Active Learning
Apr 01, 2022
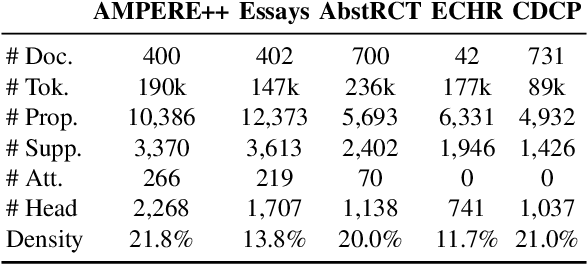
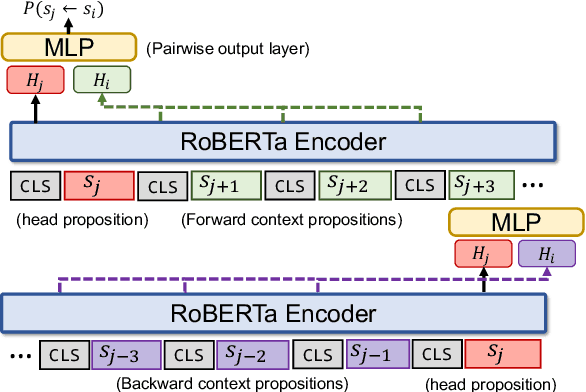
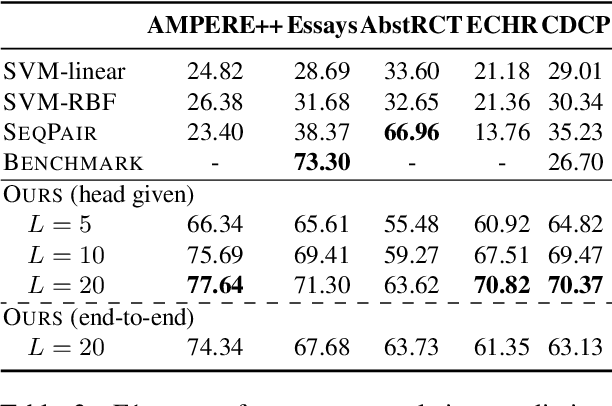
The automation of extracting argument structures faces a pair of challenges on (1) encoding long-term contexts to facilitate comprehensive understanding, and (2) improving data efficiency since constructing high-quality argument structures is time-consuming. In this work, we propose a novel context-aware Transformer-based argument structure prediction model which, on five different domains, significantly outperforms models that rely on features or only encode limited contexts. To tackle the difficulty of data annotation, we examine two complementary methods: (i) transfer learning to leverage existing annotated data to boost model performance in a new target domain, and (ii) active learning to strategically identify a small amount of samples for annotation. We further propose model-independent sample acquisition strategies, which can be generalized to diverse domains. With extensive experiments, we show that our simple-yet-effective acquisition strategies yield competitive results against three strong comparisons. Combined with transfer learning, substantial F1 score boost (5-25) can be further achieved during the early iterations of active learning across domains.
Fast algorithm for overcomplete order-3 tensor decomposition
Feb 14, 2022
We develop the first fast spectral algorithm to decompose a random third-order tensor over R^d of rank up to O(d^{3/2}/polylog(d)). Our algorithm only involves simple linear algebra operations and can recover all components in time O(d^{6.05}) under the current matrix multiplication time. Prior to this work, comparable guarantees could only be achieved via sum-of-squares [Ma, Shi, Steurer 2016]. In contrast, fast algorithms [Hopkins, Schramm, Shi, Steurer 2016] could only decompose tensors of rank at most O(d^{4/3}/polylog(d)). Our algorithmic result rests on two key ingredients. A clean lifting of the third-order tensor to a sixth-order tensor, which can be expressed in the language of tensor networks. A careful decomposition of the tensor network into a sequence of rectangular matrix multiplications, which allows us to have a fast implementation of the algorithm.
Visual Mechanisms Inspired Efficient Transformers for Image and Video Quality Assessment
Apr 06, 2022

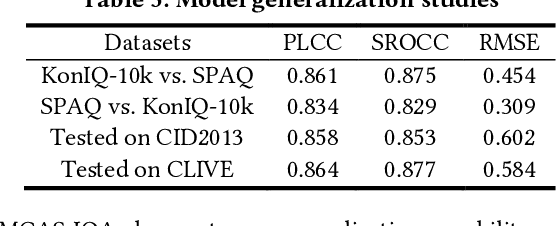
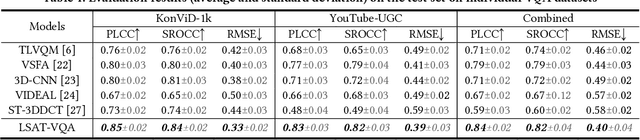
Visual (image, video) quality assessments can be modelled by visual features in different domains, e.g., spatial, frequency, and temporal domains. Perceptual mechanisms in the human visual system (HVS) play a crucial role in generation of quality perception. This paper proposes a general framework for no-reference visual quality assessment using efficient windowed transformer architectures. A lightweight module for multi-stage channel attention is integrated into Swin (shifted window) Transformer. Such module can represent appropriate perceptual mechanisms in image quality assessment (IQA) to build an accurate IQA model. Meanwhile, representative features for image quality perception in the spatial and frequency domains can also be derived from the IQA model, which are then fed into another windowed transformer architecture for video quality assessment (VQA). The VQA model efficiently reuses attention information across local windows to tackle the issue of expensive time and memory complexities of original transformer. Experimental results on both large-scale IQA and VQA databases demonstrate that the proposed quality assessment models outperform other state-of-the-art models by large margins. The complete source code will be published on Github.
Bringing Rolling Shutter Images Alive with Dual Reversed Distortion
Mar 12, 2022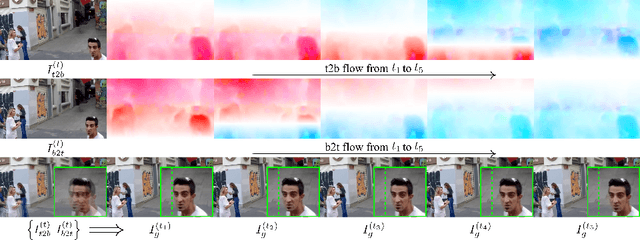

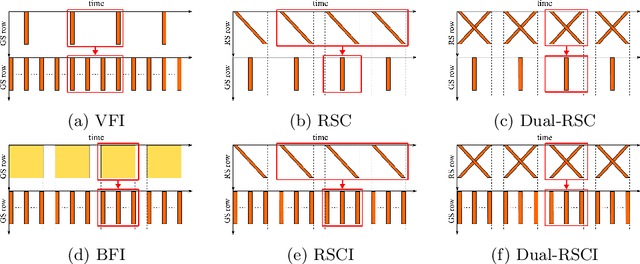
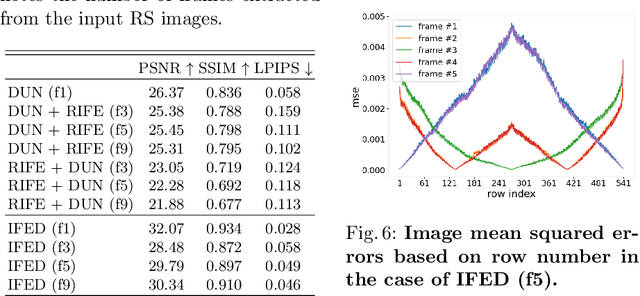
Rolling shutter (RS) distortion can be interpreted as the result of picking a row of pixels from instant global shutter (GS) frames over time during the exposure of the RS camera. This means that the information of each instant GS frame is partially, yet sequentially, embedded into the row-dependent distortion. Inspired by this fact, we address the challenging task of reversing this process, i.e., extracting undistorted GS frames from images suffering from RS distortion. However, since RS distortion is coupled with other factors such as readout settings and the relative velocity of scene elements to the camera, models that only exploit the geometric correlation between temporally adjacent images suffer from poor generality in processing data with different readout settings and dynamic scenes with both camera motion and object motion. In this paper, instead of two consecutive frames, we propose to exploit a pair of images captured by dual RS cameras with reversed RS directions for this highly challenging task. Grounded on the symmetric and complementary nature of dual reversed distortion, we develop a novel end-to-end model, IFED, to generate dual optical flow sequence through iterative learning of the velocity field during the RS time. Extensive experimental results demonstrate that IFED is superior to naive cascade schemes, as well as the state-of-the-art which utilizes adjacent RS images. Most importantly, although it is trained on a synthetic dataset, IFED is shown to be effective at retrieving GS frame sequences from real-world RS distorted images of dynamic scenes.
Microstructure Surface Reconstruction from SEM Images: An Alternative to Digital Image Correlation (DIC)
Mar 25, 2022
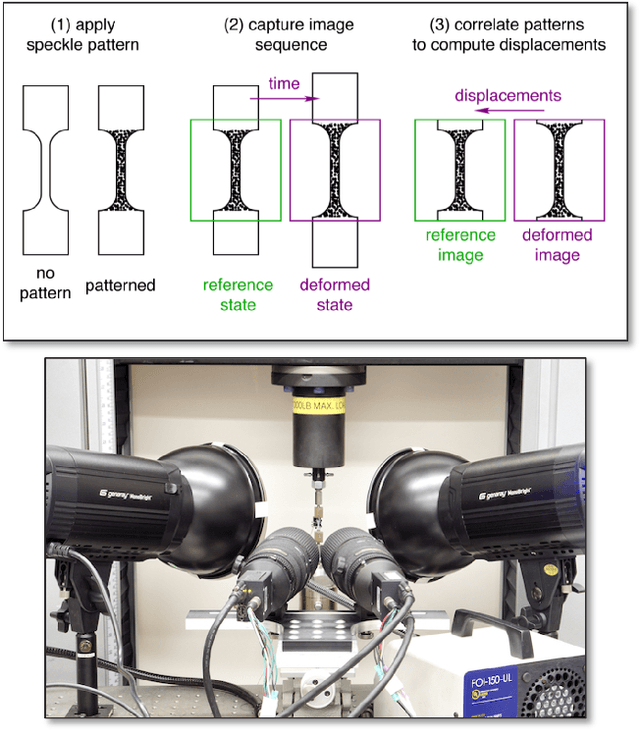


We reconstruct a 3D model of the surface of a material undergoing fatigue testing and experiencing cracking. Specifically we reconstruct the surface depth (out of plane intrusions and extrusions) and lateral (in-plane) motion from multiple views of the sample at the end of the experiment, combined with a reverse optical flow propagation backwards in time that utilizes interim single view images. These measurements can be mapped to a material strain tensor which helps to understand material life and predict failure. This approach offers an alternative to the commonly used Digital Image Correlation (DIC) technique which relies on tracking a speckle pattern applied to the material surface. DIC only produces in-plane (2D) measurements whereas our approach is 3D and non-invasive (requires no pattern being applied to the material).