 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GriTS: Grid table similarity metric for table structure recognition
Mar 23, 2022
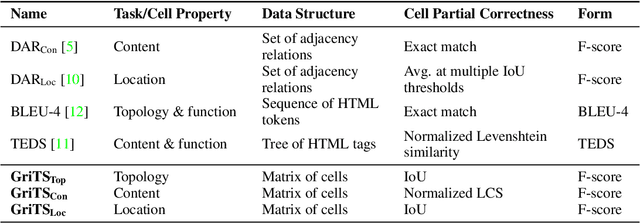
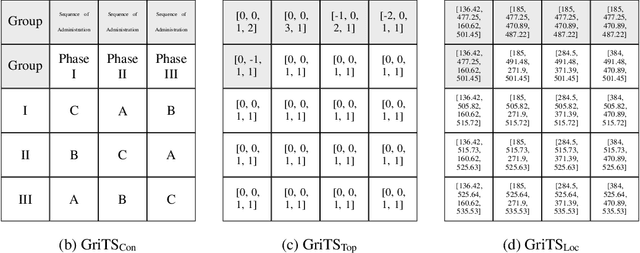
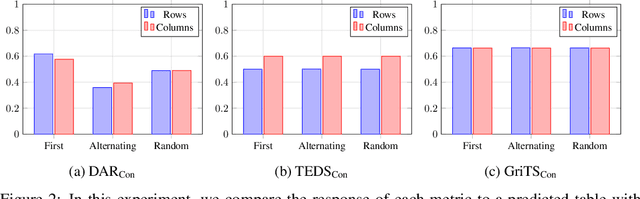
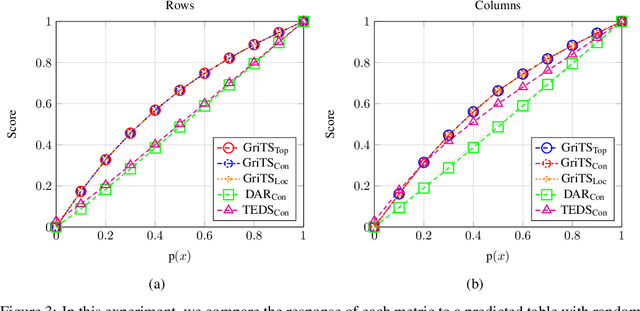
In this paper, we propose a new class of evaluation metric for table structure recognition, grid table similarity (GriTS). Unlike prior metrics, GriTS evaluates the correctness of a predicted table directly in its natural form as a matrix. To create a similarity measure between matrices, we generalize the two-dimensional largest common substructure (2D-LCS) problem, which is NP-hard, to the 2D most similar substructures (2D-MSS) problem and propose a polynomial-time heuristic for solving it. We validate empirically using the PubTables-1M dataset that comparison between matrices exhibits more desirable behavior than alternatives for table structure recognition evaluation. GriTS also unifies all three subtasks of cell topology recognition, cell location recognition, and cell content recognition within the same framework, which simplifies the evaluation and enables more meaningful comparisons across different types of structure recognition approaches. Code will be released at https://github.com/microsoft/table-transformer.
Finite-sample analysis of identification of switched linear systems with arbitrary or restricted switching
Mar 18, 2022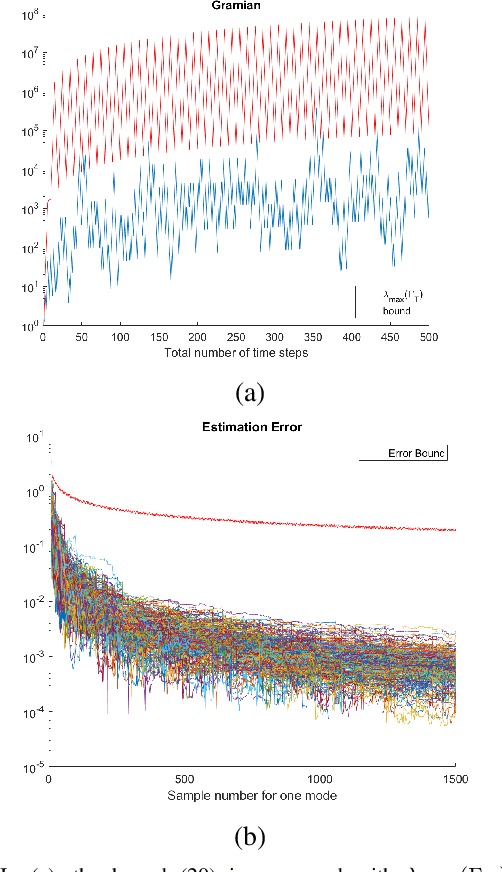
This work aims to derive a data-independent finite-sample error bound for the least-squares (LS) estimation error of switched linear systems when the state and the switching signal are measured. While the existing finite-sample bounds for linear system identification extend to the problem under consideration, the Gramian of the switched system, an essential term in the error bound, depends on the measured switching signal. Therefore, data-independent bounds on the spectrum of the Gramian are developed for globally asymptotically and marginally stable switched systems when the switching is arbitrary or subject to an average dwell time constraint. Combining the bounds on the spectrum of the Gramian and the preliminary error bound extended from linear system identification leads to the error bound for the LS estimate of the switched system.
Allocating Duplicate Copies for IoT Data in Cloud Computing Based on Harmony Search Algorithm
Feb 09, 2022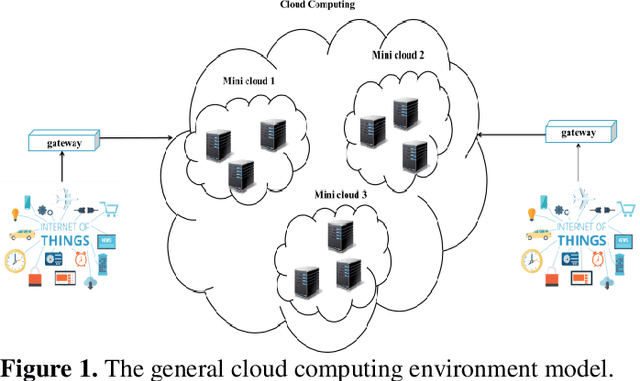
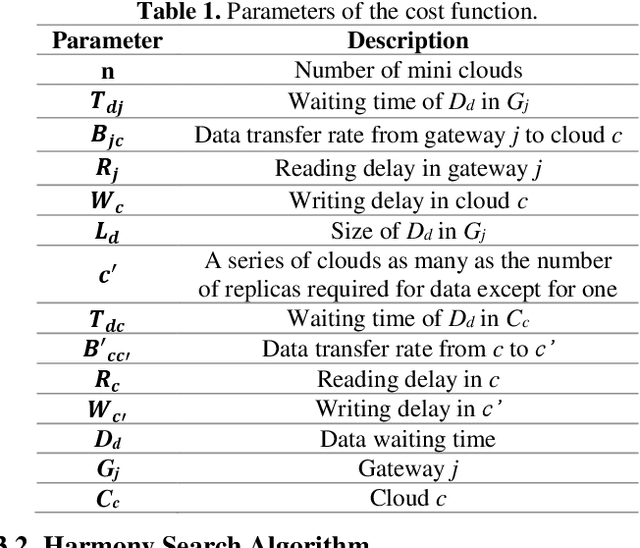
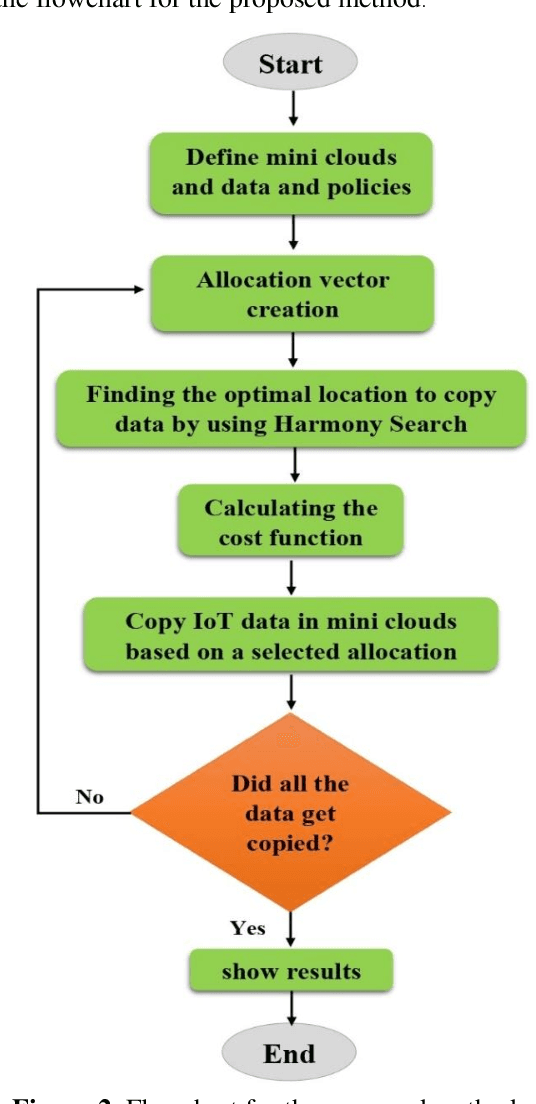
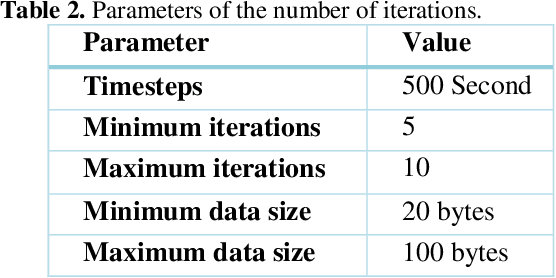
The Internet of things (IoT) generates a plethora of data nowadays, and cloud computing has been introduced as an efficient solution to IoT data management. A cloud resource administrator usually adopts the replication strategy to guarantee the reliability of IoT data. This mechanism can significantly reduce data access time, and evidently, more replicas of data increase the data storage cost. Furthermore, the process of selecting mini clouds for replica allocation and sorting replicas in mini clouds is considered an NP-hard problem. Therefore, this paper proposes an approach based on the harmony search (HS) algorithm to allocate replicas to the IoT data in the cloud computing environment in order to mitigate the data access cost. The HS algorithm was employed in the proposed approach to determine the best location for data replication in the cloud computing environment. According to the implementation results, the proposed approach outperformed the other methods and managed to significantly decrease data access time and delay as well as energy consumption.
Global Sentiment Analysis Of COVID-19 Tweets Over Time
Oct 27, 2020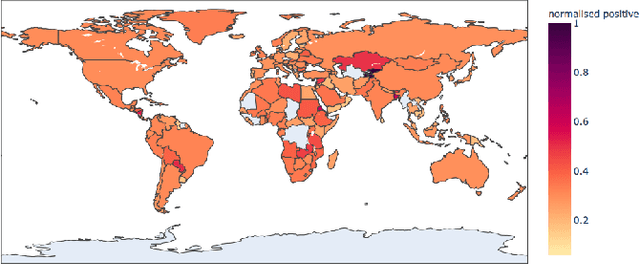
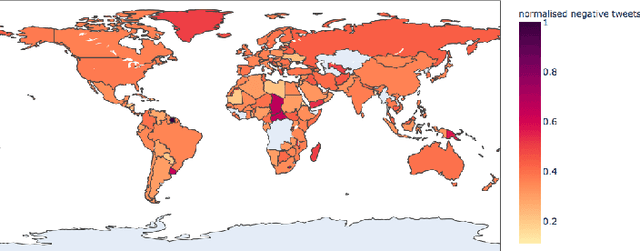
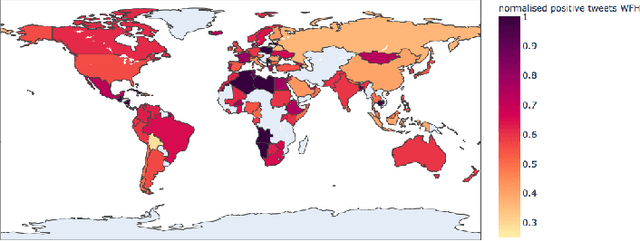
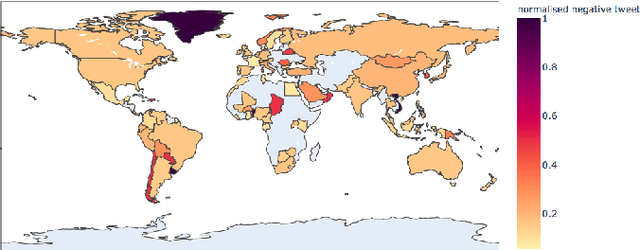
The Coronavirus pandemic has affected the normal course of life. People around the world have taken to social media to express their opinions and general emotions regarding this phenomenon that has taken over the world by storm. The social networking site, Twitter showed an unprecedented increase in tweets related to the novel Coronavirus in a very short span of time. This paper presents the global sentiment analysis of tweets related to Coronavirus and how the sentiment of people in different countries has changed over time. Furthermore, to determine the impact of Coronavirus on daily aspects of life, tweets related to Work From Home (WFH) and Online Learning were scraped and the change in sentiment over time was observed. In addition, various Machine Learning models such as Long Short Term Memory (LSTM) and Artificial Neural Networks (ANN) were implemented for sentiment classification and their accuracies were determined. Exploratory data analysis was also performed for a dataset providing information about the number of confirmed cases on a per-day basis in a few of the worst-hit countries to provide a comparison between the change in sentiment with the change in cases since the start of this pandemic till June 2020.
RFNet-4D: Joint Object Reconstruction and Flow Estimation from 4D Point Clouds
Mar 30, 2022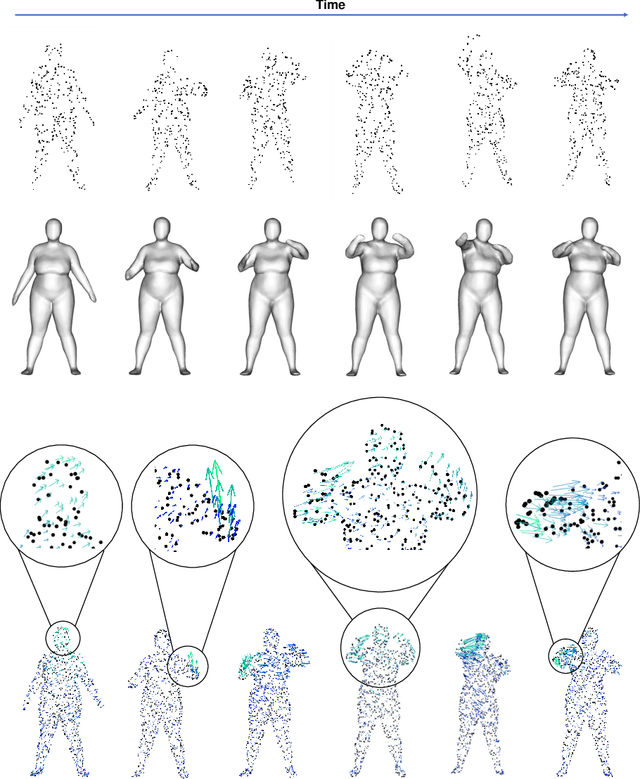
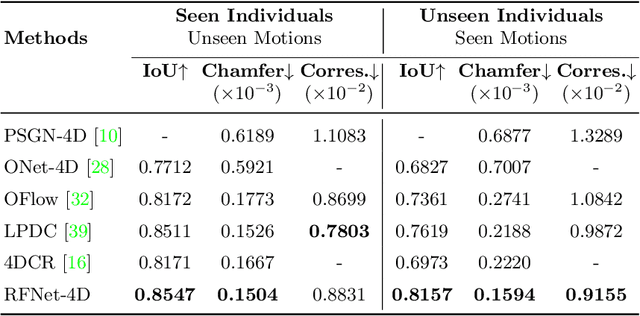
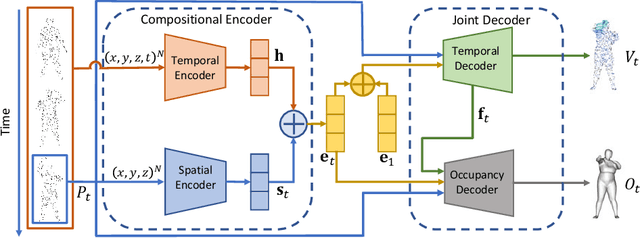
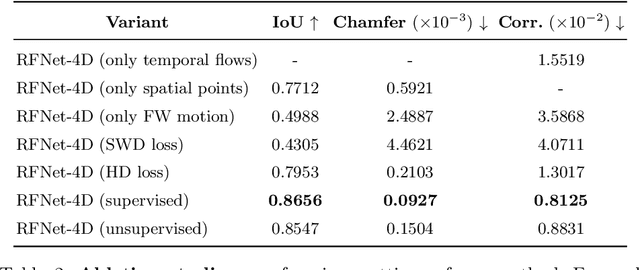
Object reconstruction from 3D point clouds has achieved impressive progress in the computer vision and computer graphics research field. However, reconstruction from time-varying point clouds (a.k.a. 4D point clouds) is generally overlooked. In this paper, we propose a new network architecture, namely RFNet-4D, that jointly reconstructs objects and their motion flows from 4D point clouds. The key insight is that simultaneously performing both tasks via learning spatial and temporal features from a sequence of point clouds can leverage individual tasks and lead to improved overall performance. The proposed network can be trained using both supervised and unsupervised learning. To prove this ability, we design a temporal vector field learning module using an unsupervised learning approach for flow estimation, leveraged by supervised learning of spatial structures for object reconstruction. Extensive experiments and analyses on benchmark dataset validated the effectiveness and efficiency of our method. As shown in experimental results, our method achieves state-of-the-art performance on both flow estimation and object reconstruction while performing much faster than existing methods in both training and inference.
Proactive Anomaly Detection for Robot Navigation with Multi-Sensor Fusion
Apr 03, 2022

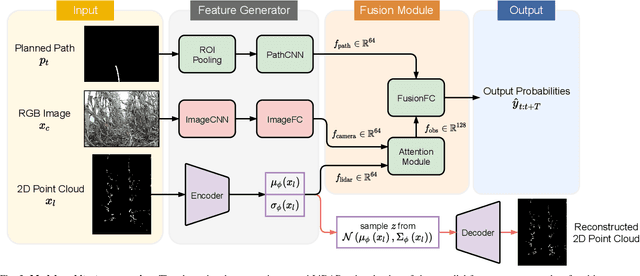

Despite the rapid advancement of navigation algorithms, mobile robots often produce anomalous behaviors that can lead to navigation failures. The ability to detect such anomalous behaviors is a key component in modern robots to achieve high-levels of autonomy. Reactive anomaly detection methods identify anomalous task executions based on the current robot state and thus lack the ability to alert the robot before an actual failure occurs. Such an alert delay is undesirable due to the potential damage to both the robot and the surrounding objects. We propose a proactive anomaly detection network (PAAD) for robot navigation in unstructured and uncertain environments. PAAD predicts the probability of future failure based on the planned motions from the predictive controller and the current observation from the perception module. Multi-sensor signals are fused effectively to provide robust anomaly detection in the presence of sensor occlusion as seen in field environments. Our experiments on field robot data demonstrates superior failure identification performance than previous methods, and that our model can capture anomalous behaviors in real-time while maintaining a low false detection rate in cluttered fields. Code, dataset, and video are available at https://github.com/tianchenji/PAAD
A Worrying Analysis of Probabilistic Time-series Models for Sales Forecasting
Nov 21, 2020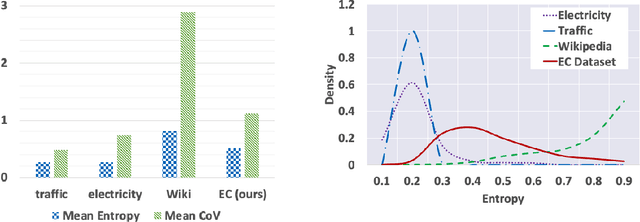
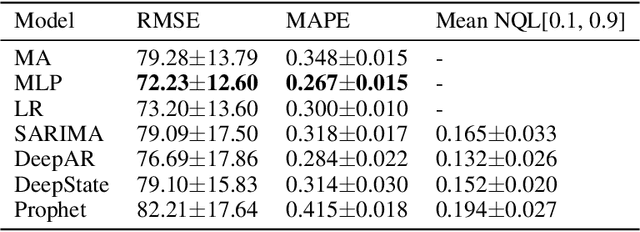
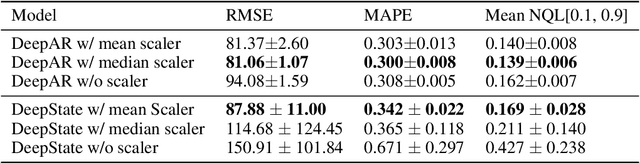

Probabilistic time-series models become popular in the forecasting field as they help to make optimal decisions under uncertainty. Despite the growing interest, a lack of thorough analysis hinders choosing what is worth applying for the desired task. In this paper, we analyze the performance of three prominent probabilistic time-series models for sales forecasting. To remove the role of random chance in architecture's performance, we make two experimental principles; 1) Large-scale dataset with various cross-validation sets. 2) A standardized training and hyperparameter selection. The experimental results show that a simple Multi-layer Perceptron and Linear Regression outperform the probabilistic models on RMSE without any feature engineering. Overall, the probabilistic models fail to achieve better performance on point estimation, such as RMSE and MAPE, than comparably simple baselines. We analyze and discuss the performances of probabilistic time-series models.
Conditional Approximate Normalizing Flows for Joint Multi-Step Probabilistic Electricity Demand Forecasting
Jan 08, 2022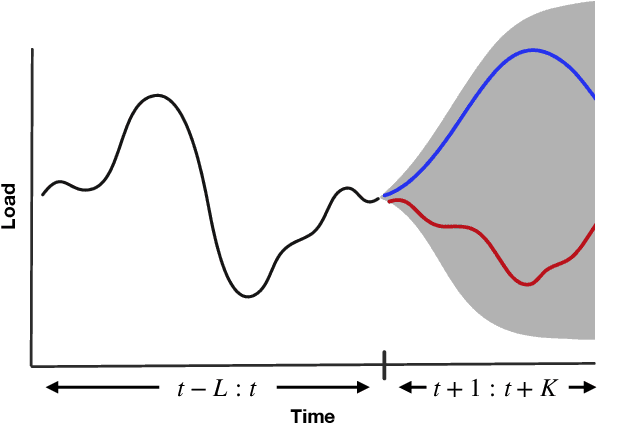
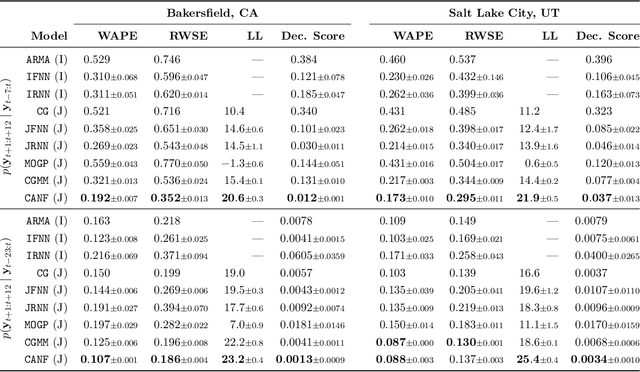
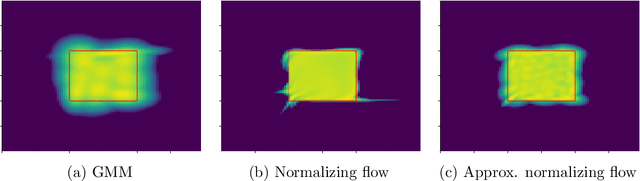
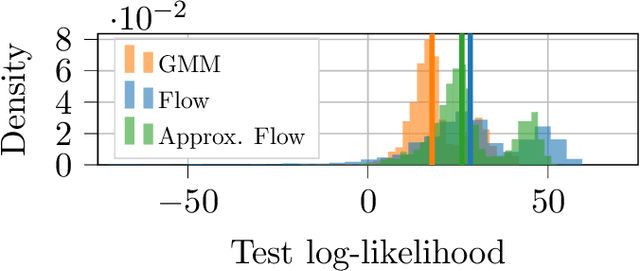
Some real-world decision-making problems require making probabilistic forecasts over multiple steps at once. However, methods for probabilistic forecasting may fail to capture correlations in the underlying time-series that exist over long time horizons as errors accumulate. One such application is with resource scheduling under uncertainty in a grid environment, which requires forecasting electricity demand that is inherently noisy, but often cyclic. In this paper, we introduce the conditional approximate normalizing flow (CANF) to make probabilistic multi-step time-series forecasts when correlations are present over long time horizons. We first demonstrate our method's efficacy on estimating the density of a toy distribution, finding that CANF improves the KL divergence by one-third compared to that of a Gaussian mixture model while still being amenable to explicit conditioning. We then use a publicly available household electricity consumption dataset to showcase the effectiveness of CANF on joint probabilistic multi-step forecasting. Empirical results show that conditional approximate normalizing flows outperform other methods in terms of multi-step forecast accuracy and lead to up to 10x better scheduling decisions. Our implementation is available at https://github.com/sisl/JointDemandForecasting.
Strong Admissibility, a Tractable Algorithmic Approach (proofs)
Apr 07, 2022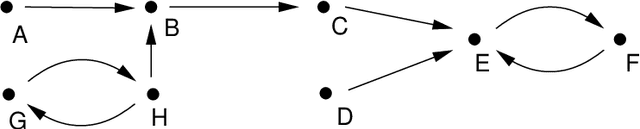
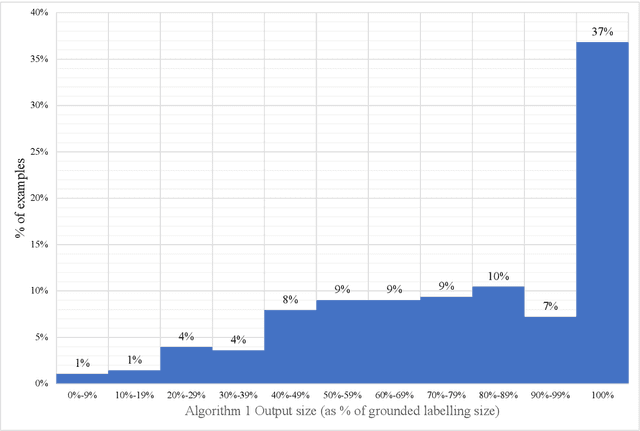
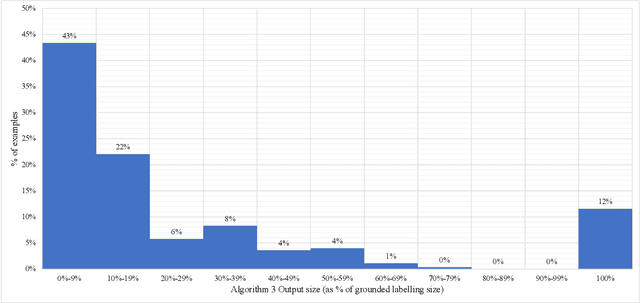
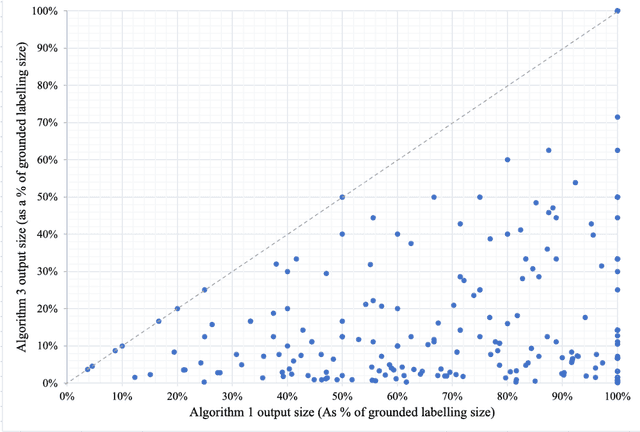
Much like admissibility is the key concept underlying preferred semantics, strong admissibility is the key concept underlying grounded semantics, as membership of a strongly admissible set is sufficient to show membership of the grounded extension. As such, strongly admissible sets and labellings can be used as an explanation of membership of the grounded extension, as is for instance done in some of the proof procedures for grounded semantics. In the current paper, we present two polynomial algorithms for constructing relatively small strongly admissible labellings, with associated min-max numberings, for a particular argument. These labellings can be used as relatively small explanations for the argument's membership of the grounded extension. Although our algorithms are not guaranteed to yield an absolute minimal strongly admissible labelling for the argument (as doing do would have implied an exponential complexity), our best performing algorithm yields results that are only marginally bigger. Moreover, the runtime of this algorithm is an order of magnitude smaller than that of the existing approach for computing an absolute minimal strongly admissible labelling for a particular argument. As such, we believe that our algorithms can be of practical value in situations where the aim is to construct a minimal or near-minimal strongly admissible labelling in a time-efficient way.
Region of Interest focused MRI to Synthetic CT Translation using Regression and Classification Multi-task Network
Mar 30, 2022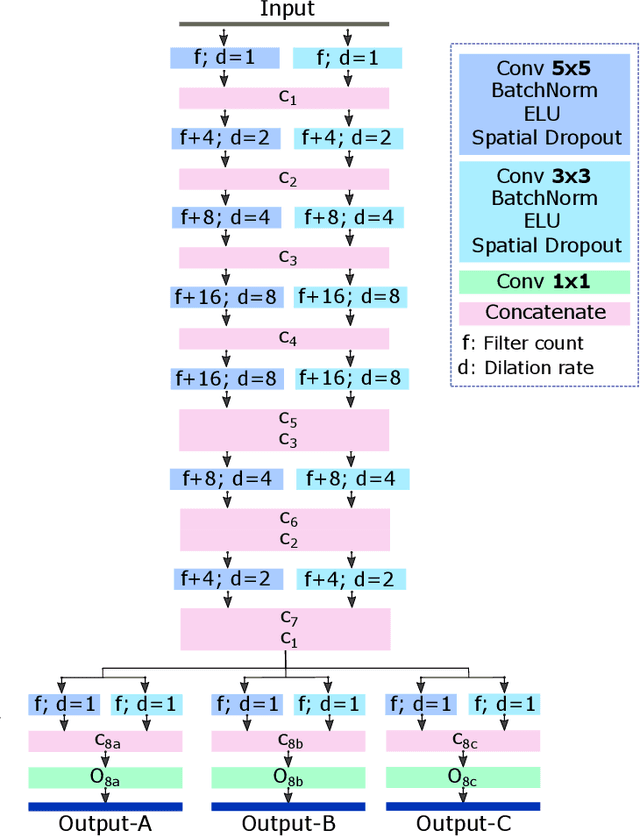
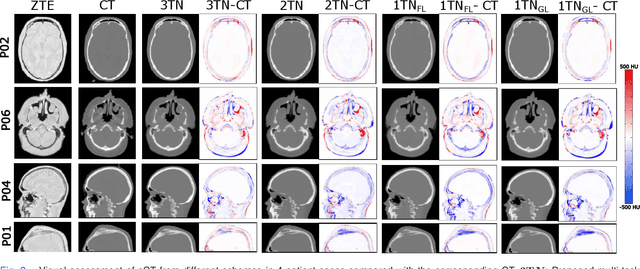
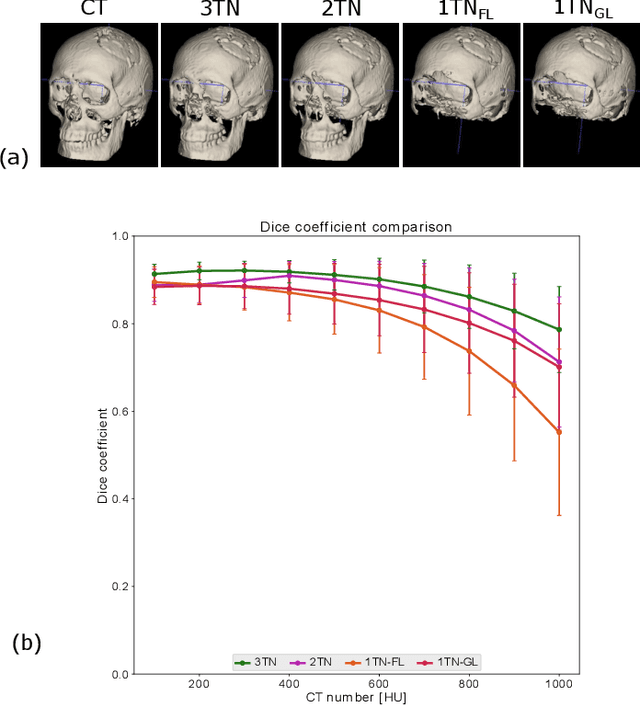
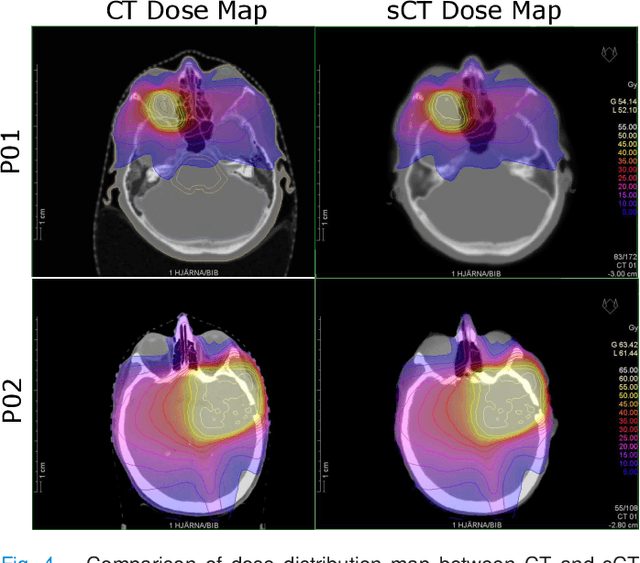
In this work, we present a method for synthetic CT (sCT) generation from zero-echo-time (ZTE) MRI aimed at structural and quantitative accuracies of the image, with a particular focus on the accurate bone density value prediction. We propose a loss function that favors a spatially sparse region in the image. We harness the ability of a multi-task network to produce correlated outputs as a framework to enable localisation of region of interest (RoI) via classification, emphasize regression of values within RoI and still retain the overall accuracy via global regression. The network is optimized by a composite loss function that combines a dedicated loss from each task. We demonstrate how the multi-task network with RoI focused loss offers an advantage over other configurations of the network to achieve higher accuracy of performance. This is relevant to sCT where failure to accurately estimate high Hounsfield Unit values of bone could lead to impaired accuracy in clinical applications. We compare the dose calculation maps from the proposed sCT and the real CT in a radiation therapy treatment planning setup.