 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Temporal-oriented Broadcast ResNet for COVID-19 Detection
Mar 31, 2022
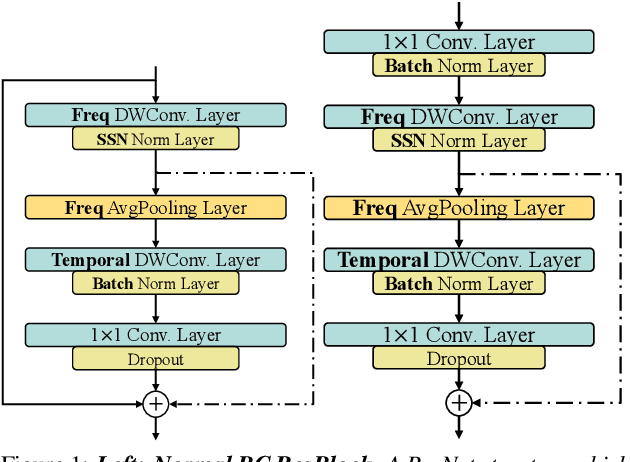


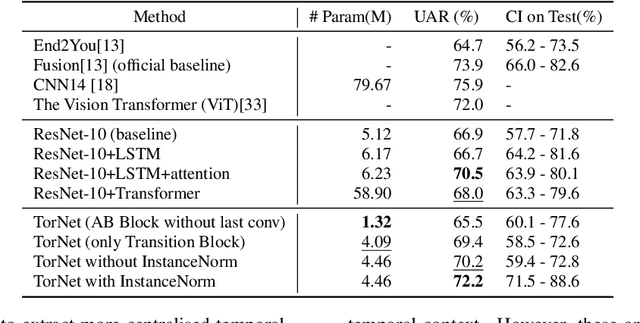
Detecting COVID-19 from audio signals, such as breathing and coughing, can be used as a fast and efficient pre-testing method to reduce the virus transmission. Due to the promising results of deep learning networks in modelling time sequences, and since applications to rapidly identify COVID in-the-wild should require low computational effort, we present a temporal-oriented broadcasting residual learning method that achieves efficient computation and high accuracy with a small model size. Based on the EfficientNet architecture, our novel network, named Temporal-oriented ResNet~(TorNet), constitutes of a broadcasting learning block, i.e. the Alternating Broadcast (AB) Block, which contains several Broadcast Residual Blocks (BC ResBlocks) and a convolution layer. With the AB Block, the network obtains useful audio-temporal features and higher level embeddings effectively with much less computation than Recurrent Neural Networks~(RNNs), typically used to model temporal information. TorNet achieves 72.2% Unweighted Average Recall (UAR) on the INTERPSEECH 2021 Computational Paralinguistics Challenge COVID-19 cough Sub-Challenge, by this showing competitive results with a higher computational efficiency than other state-of-the-art alternatives.
Reproducibility and Baseline Reporting for Dynamic Multi-objective Benchmark Problems
Apr 08, 2022
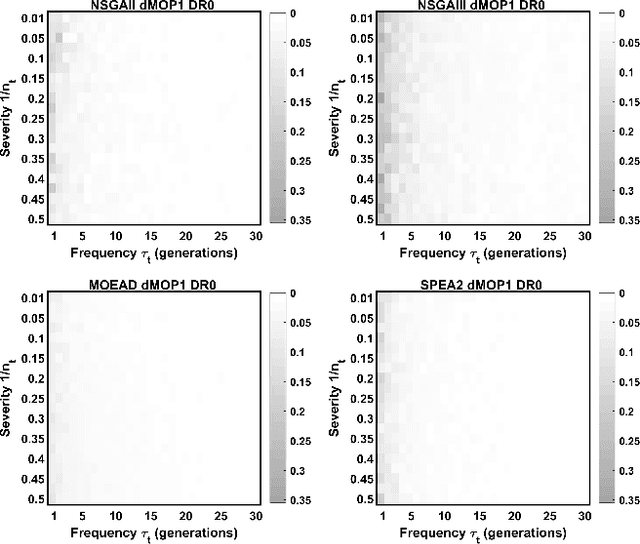
Dynamic multi-objective optimization problems (DMOPs) are widely accepted to be more challenging than stationary problems due to the time-dependent nature of the objective functions and/or constraints. Evaluation of purpose-built algorithms for DMOPs is often performed on narrow selections of dynamic instances with differing change magnitude and frequency or a limited selection of problems. In this paper, we focus on the reproducibility of simulation experiments for parameters of DMOPs. Our framework is based on an extension of PlatEMO, allowing for the reproduction of results and performance measurements across a range of dynamic settings and problems. A baseline schema for dynamic algorithm evaluation is introduced, which provides a mechanism to interrogate performance and optimization behaviours of well-known evolutionary algorithms that were not designed specifically for DMOPs. Importantly, by determining the maximum capability of non-dynamic multi-objective evolutionary algorithms, we can establish the minimum capability required of purpose-built dynamic algorithms to be useful. The simplest modifications to manage dynamic changes introduce diversity. Allowing non-dynamic algorithms to incorporate mutated/random solutions after change events determines the improvement possible with minor algorithm modifications. Future expansion to include current dynamic algorithms will enable reproduction of their results and verification of their abilities and performance across DMOP benchmark space.
Learning Neural Acoustic Fields
Apr 04, 2022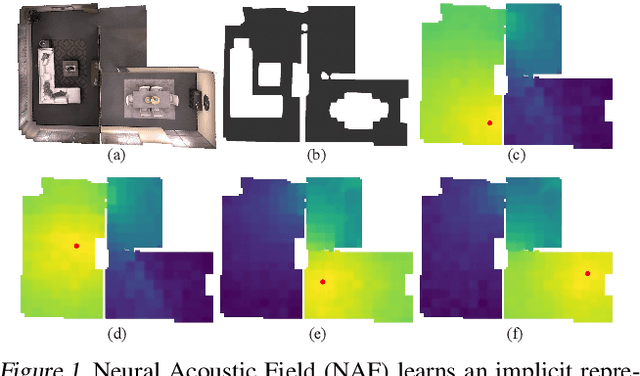
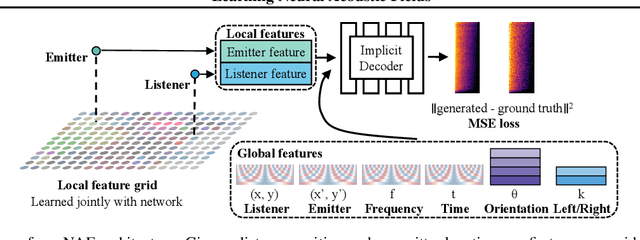
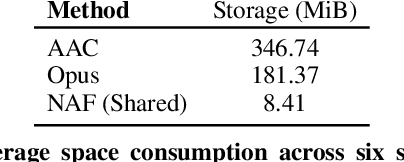
Our environment is filled with rich and dynamic acoustic information. When we walk into a cathedral, the reverberations as much as appearance inform us of the sanctuary's wide open space. Similarly, as an object moves around us, we expect the sound emitted to also exhibit this movement. While recent advances in learned implicit functions have led to increasingly higher quality representations of the visual world, there have not been commensurate advances in learning spatial auditory representations. To address this gap, we introduce Neural Acoustic Fields (NAFs), an implicit representation that captures how sounds propagate in a physical scene. By modeling acoustic propagation in a scene as a linear time-invariant system, NAFs learn to continuously map all emitter and listener location pairs to a neural impulse response function that can then be applied to arbitrary sounds. We demonstrate that the continuous nature of NAFs enables us to render spatial acoustics for a listener at an arbitrary location, and can predict sound propagation at novel locations. We further show that the representation learned by NAFs can help improve visual learning with sparse views. Finally, we show that a representation informative of scene structure emerges during the learning of NAFs.
Multi-Agent Spatial Predictive Control with Application to Drone Flocking (Extended Version)
Mar 31, 2022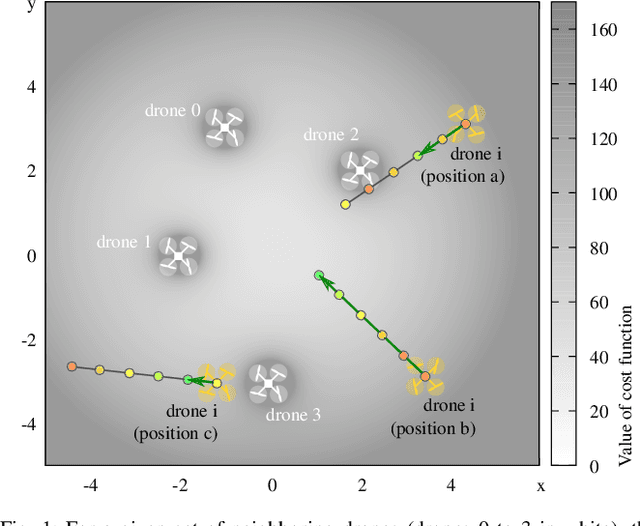
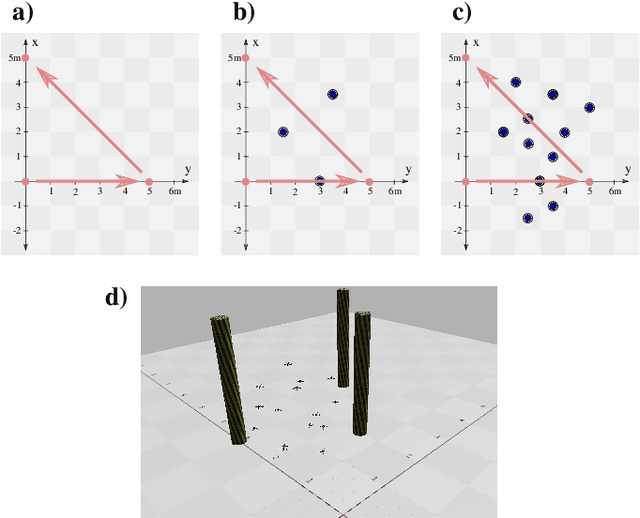
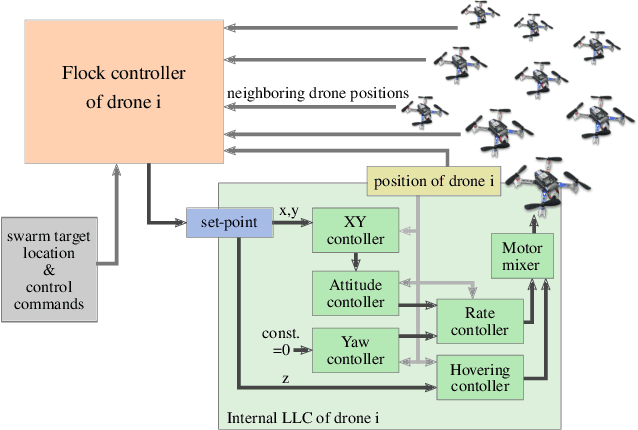
We introduce the novel concept of Spatial Predictive Control (SPC) to solve the following problem: given a collection of agents (e.g., drones) with positional low-level controllers (LLCs) and a mission-specific distributed cost function, how can a distributed controller achieve and maintain cost-function minimization without a plant model and only positional observations of the environment? Our fully distributed SPC controller is based strictly on the position of the agent itself and on those of its neighboring agents. This information is used in every time-step to compute the gradient of the cost function and to perform a spatial look-ahead to predict the best next target position for the LLC. Using a high-fidelity simulation environment, we show that SPC outperforms the most closely related class of controllers, Potential Field Controllers, on the drone flocking problem. We also show that SPC is able to cope with a potential sim-to-real transfer gap by demonstrating its performance on real hardware, namely our implementation of flocking using nine Crazyflie 2.1 drones.
Generalised Latent Assimilation in Heterogeneous Reduced Spaces with Machine Learning Surrogate Models
Apr 08, 2022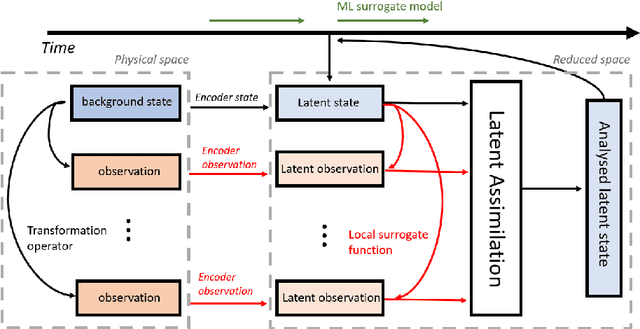
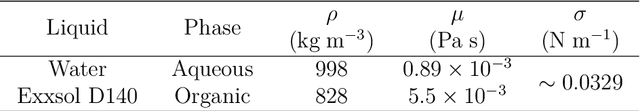
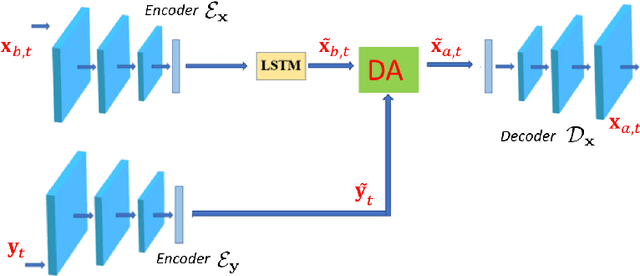

Reduced-order modelling and low-dimensional surrogate models generated using machine learning algorithms have been widely applied in high-dimensional dynamical systems to improve the algorithmic efficiency. In this paper, we develop a system which combines reduced-order surrogate models with a novel data assimilation (DA) technique used to incorporate real-time observations from different physical spaces. We make use of local smooth surrogate functions which link the space of encoded system variables and the one of current observations to perform variational DA with a low computational cost. The new system, named Generalised Latent Assimilation can benefit both the efficiency provided by the reduced-order modelling and the accuracy of data assimilation. A theoretical analysis of the difference between surrogate and original assimilation cost function is also provided in this paper where an upper bound, depending on the size of the local training set, is given. The new approach is tested on a high-dimensional CFD application of a two-phase liquid flow with non-linear observation operators that current Latent Assimilation methods can not handle. Numerical results demonstrate that the proposed assimilation approach can significantly improve the reconstruction and prediction accuracy of the deep learning surrogate model which is nearly 1000 times faster than the CFD simulation.
General Incremental Learning with Domain-aware Categorical Representations
Apr 08, 2022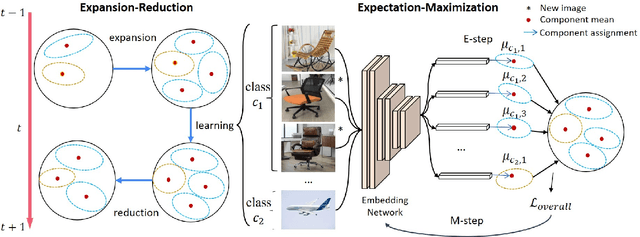
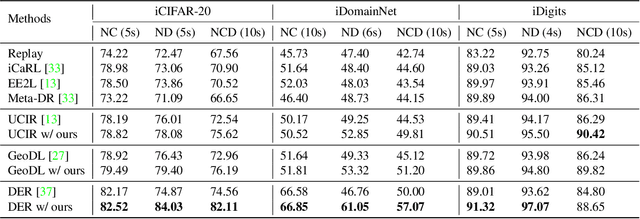
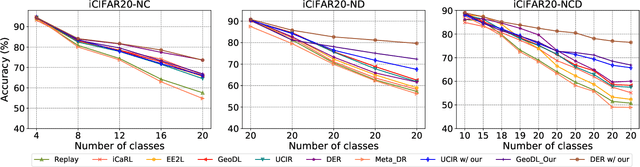

Continual learning is an important problem for achieving human-level intelligence in real-world applications as an agent must continuously accumulate knowledge in response to streaming data/tasks. In this work, we consider a general and yet under-explored incremental learning problem in which both the class distribution and class-specific domain distribution change over time. In addition to the typical challenges in class incremental learning, this setting also faces the intra-class stability-plasticity dilemma and intra-class domain imbalance problems. To address above issues, we develop a novel domain-aware continual learning method based on the EM framework. Specifically, we introduce a flexible class representation based on the von Mises-Fisher mixture model to capture the intra-class structure, using an expansion-and-reduction strategy to dynamically increase the number of components according to the class complexity. Moreover, we design a bi-level balanced memory to cope with data imbalances within and across classes, which combines with a distillation loss to achieve better inter- and intra-class stability-plasticity trade-off. We conduct exhaustive experiments on three benchmarks: iDigits, iDomainNet and iCIFAR-20. The results show that our approach consistently outperforms previous methods by a significant margin, demonstrating its superiority.
LiveMap: Real-Time Dynamic Map in Automotive Edge Computing
Dec 16, 2020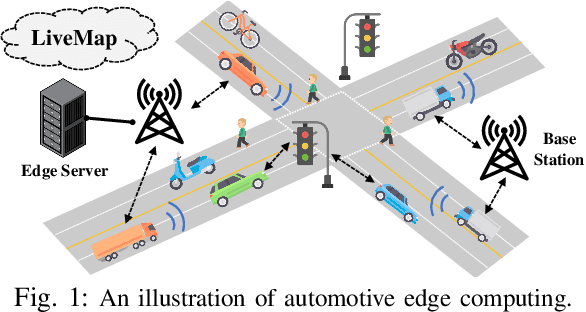
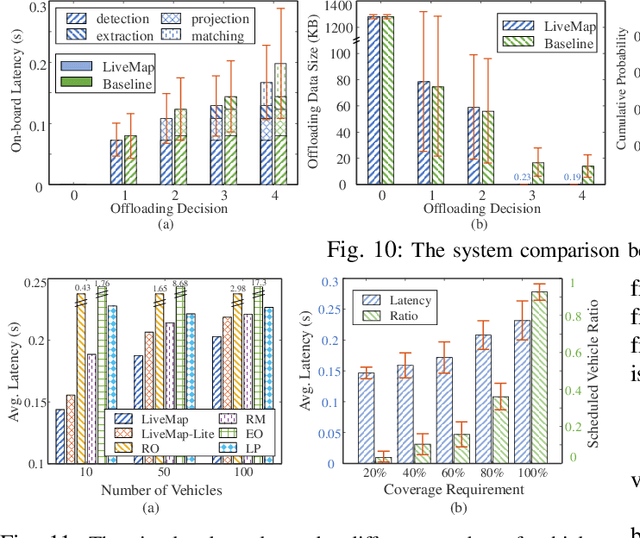
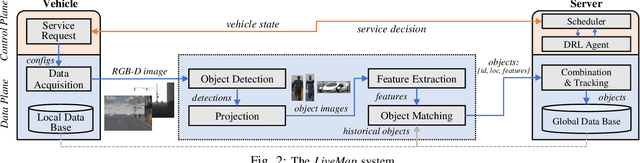
Autonomous driving needs various line-of-sight sensors to perceive surroundings that could be impaired under diverse environment uncertainties such as visual occlusion and extreme weather. To improve driving safety, we explore to wirelessly share perception information among connected vehicles within automotive edge computing networks. Sharing massive perception data in real time, however, is challenging under dynamic networking conditions and varying computation workloads. In this paper, we propose LiveMap, a real-time dynamic map, that detects, matches, and tracks objects on the road with crowdsourcing data from connected vehicles in sub-second. We develop the data plane of LiveMap that efficiently processes individual vehicle data with object detection, projection, feature extraction, object matching, and effectively integrates objects from multiple vehicles with object combination. We design the control plane of LiveMap that allows adaptive offloading of vehicle computations, and develop an intelligent vehicle scheduling and offloading algorithm to reduce the offloading latency of vehicles based on deep reinforcement learning (DRL) techniques. We implement LiveMap on a small-scale testbed and develop a large-scale network simulator. We evaluate the performance of LiveMap with both experiments and simulations, and the results show LiveMap reduces 34.1% average latency than the baseline solution.
Sequential Doppler Shift based Optimal Localization and Synchronization with TOA
Feb 14, 2022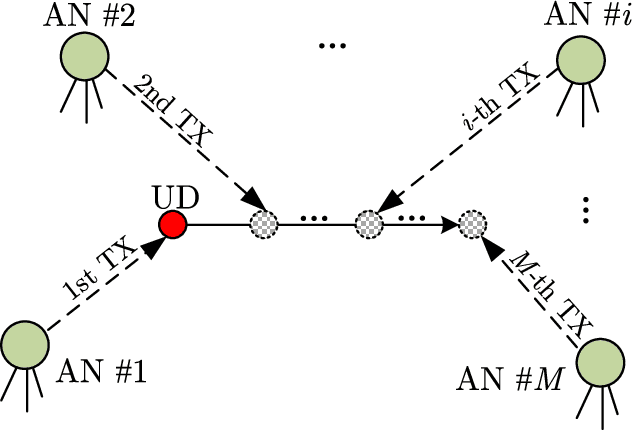
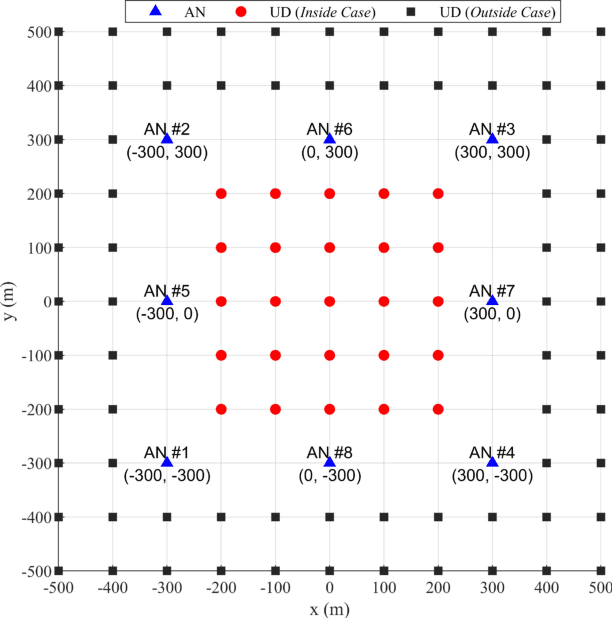
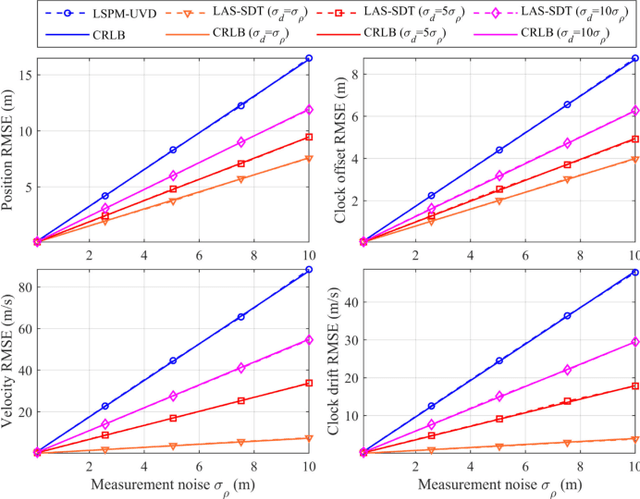
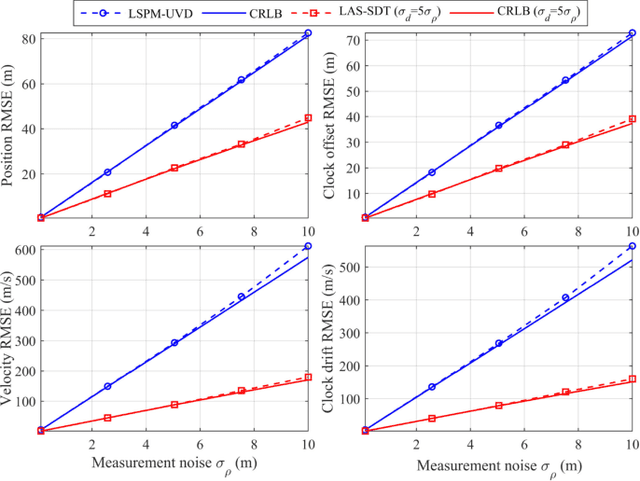
Doppler shift is an important measurement for localization and synchronization (LAS), and is available in various practical systems. Existing studies on LAS techniques in a time division broadcast LAS system (TDBS) only use sequential time-of-arrival (TOA) measurements from the broadcast signals. In this paper, we develop a new optimal LAS method in the TDBS, namely LAS-SDT, by taking advantage of the sequential Doppler shift and TOA measurements. It achieves higher accuracy compared with the conventional TOA-only method for user devices (UDs) with motion and clock drift. Another two variant methods, LAS-SDT-v for the case with UD velocity aiding, and LAS-SDT-k for the case with UD clock drift aiding, are developed. We derive the Cramer-Rao lower bound (CRLB) for these different cases. We show analytically that the accuracies of the estimated UD position, clock offset, velocity and clock drift are all significantly higher than those of the conventional LAS method using TOAs only. Numerical results corroborate the theoretical analysis and show the optimal estimation performance of the LAS-SDT.
Real-Time Resource Allocation for Tracking Systems
Sep 21, 2020
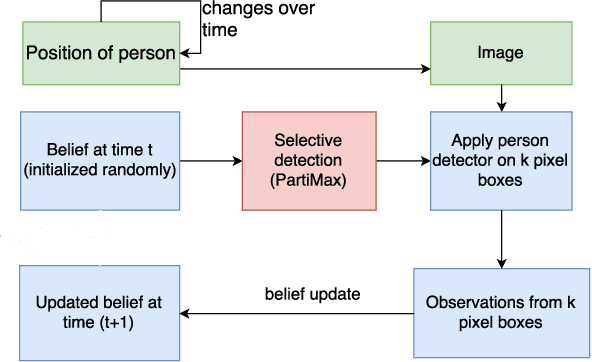

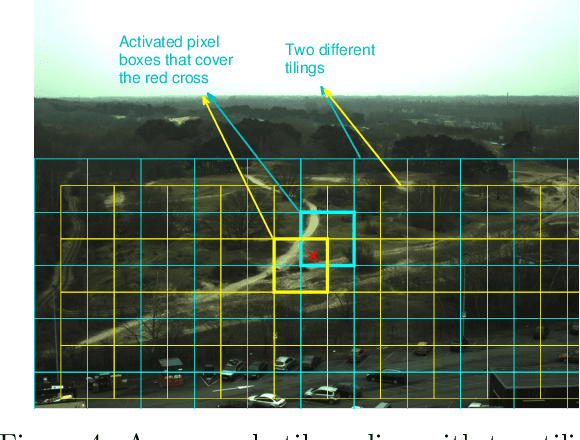
Automated tracking is key to many computer vision applications. However, many tracking systems struggle to perform in real-time due to the high computational cost of detecting people, especially in ultra high resolution images. We propose a new algorithm called \emph{PartiMax} that greatly reduces this cost by applying the person detector only to the relevant parts of the image. PartiMax exploits information in the particle filter to select $k$ of the $n$ candidate \emph{pixel boxes} in the image. We prove that PartiMax is guaranteed to make a near-optimal selection with error bounds that are independent of the problem size. Furthermore, empirical results on a real-life dataset show that our system runs in real-time by processing only 10\% of the pixel boxes in the image while still retaining 80\% of the original tracking performance achieved when processing all pixel boxes.
* http://auai.org/uai2017/proceedings/papers/130.pdf
Real-Time Semantic Background Subtraction
Feb 12, 2020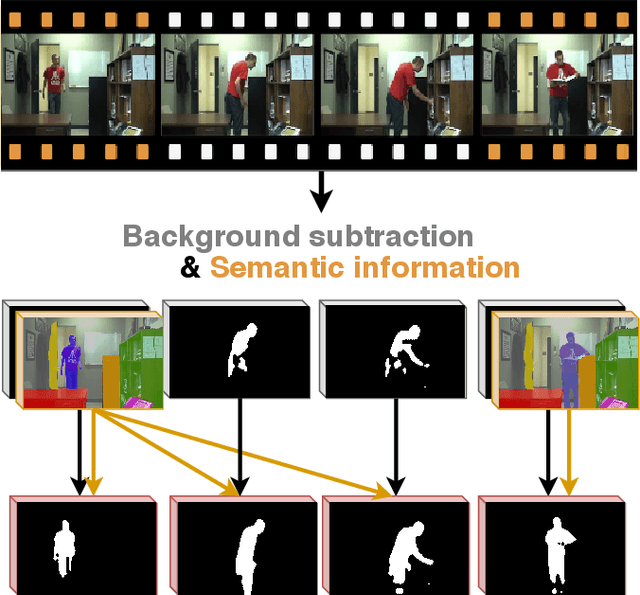
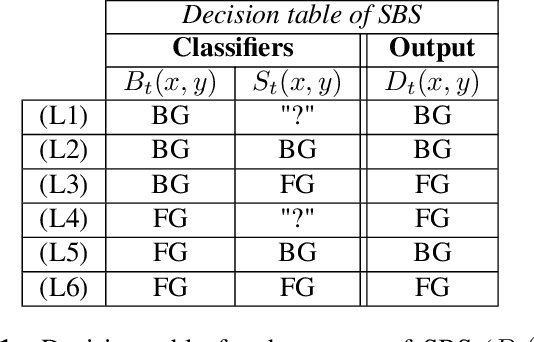
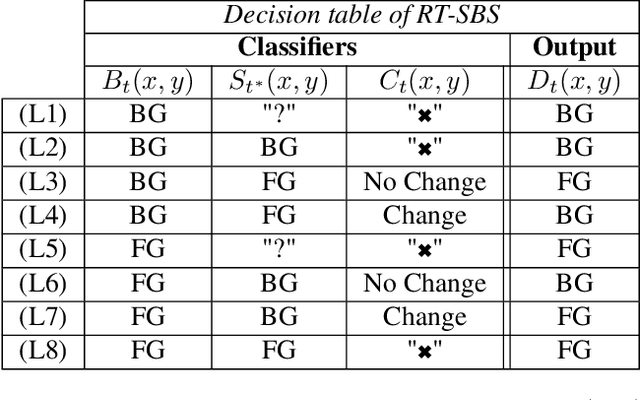
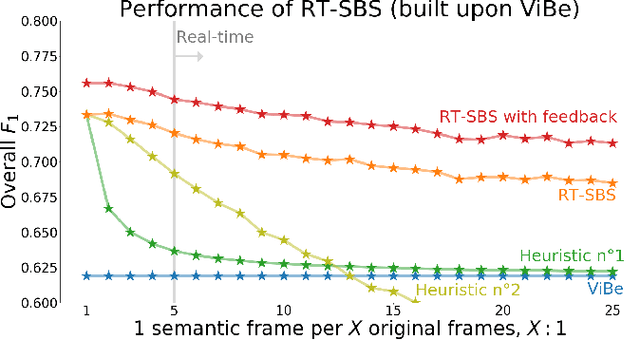
Semantic background subtraction SBS has been shown to improve the performance of most background subtraction algorithms by combining them with semantic information, derived from a semantic segmentation network. However, SBS requires high-quality semantic segmentation masks for all frames, which are slow to compute. In addition, most state-of-the-art background subtraction algorithms are not real-time, which makes them unsuitable for real-world applications. In this paper, we present a novel background subtraction algorithm called Real-Time Semantic Background Subtraction (denoted RT-SBS) which extends SBS for real-time constrained applications while keeping similar performances. RT-SBS effectively combines a real-time background subtraction algorithm with high-quality semantic information which can be provided at a slower pace, independently for each pixel. We show that RT-SBS coupled with ViBe sets a new state of the art for real-time background subtraction algorithms and even competes with the non real-time state-of-the-art ones. Note that python CPU and GPU implementations of RT-SBS will be released soon.