 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DEVO: Depth-Event Camera Visual Odometry in Challenging Conditions
Feb 05, 2022
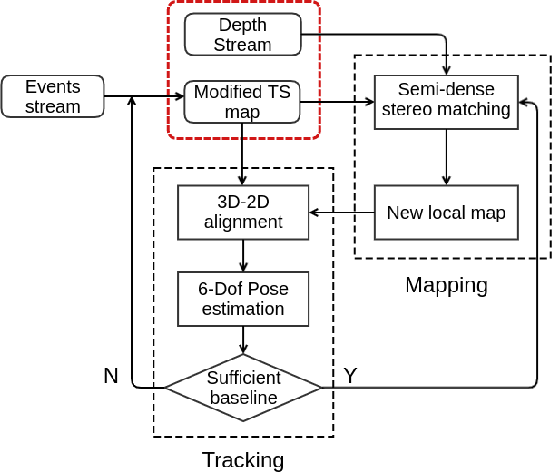
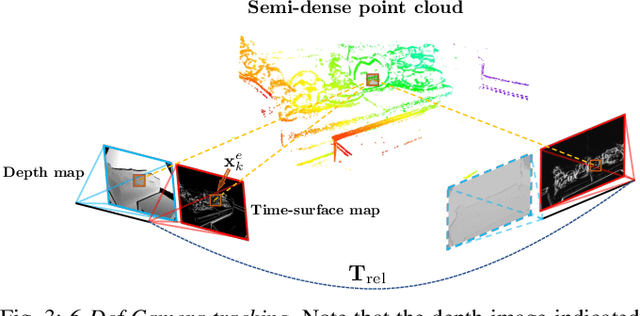

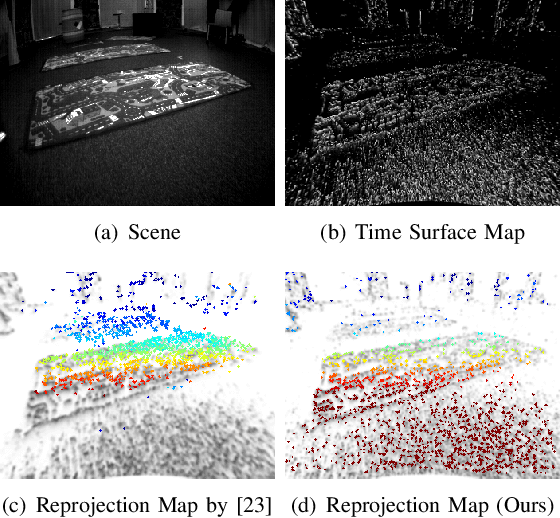
We present a novel real-time visual odometry framework for a stereo setup of a depth and high-resolution event camera. Our framework balances accuracy and robustness against computational efficiency towards strong performance in challenging scenarios. We extend conventional edge-based semi-dense visual odometry towards time-surface maps obtained from event streams. Semi-dense depth maps are generated by warping the corresponding depth values of the extrinsically calibrated depth camera. The tracking module updates the camera pose through efficient, geometric semi-dense 3D-2D edge alignment. Our approach is validated on both public and self-collected datasets captured under various conditions. We show that the proposed method performs comparable to state-of-the-art RGB-D camera-based alternatives in regular conditions, and eventually outperforms in challenging conditions such as high dynamics or low illumination.
Optimized cost function for demand response coordination of multiple EV charging stations using reinforcement learning
Mar 03, 2022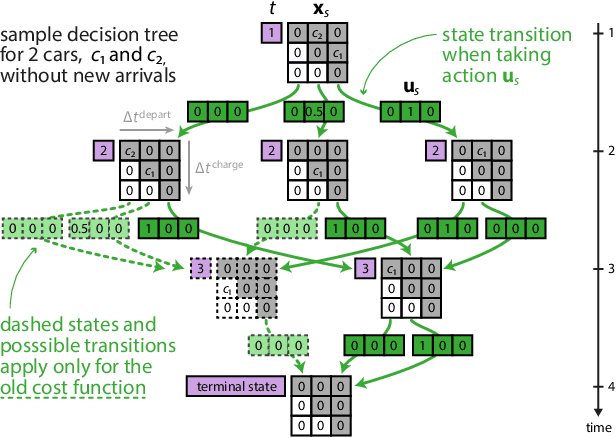
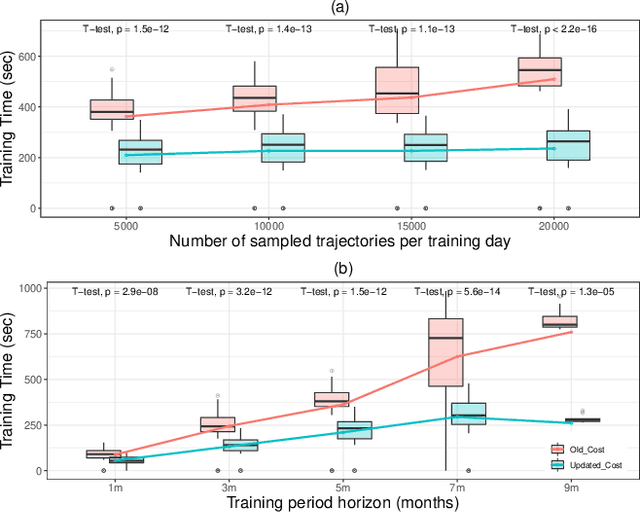
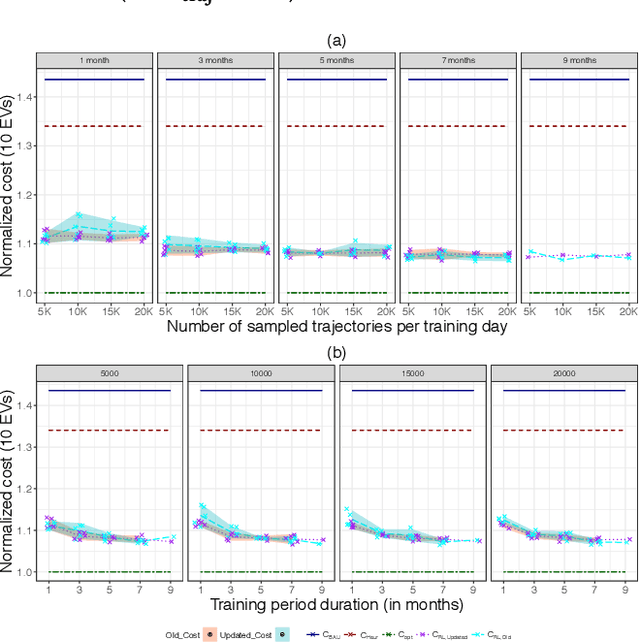
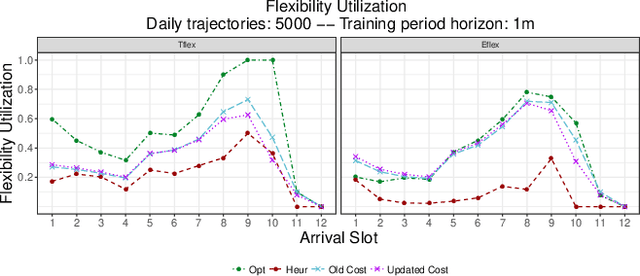
Electric vehicle (EV) charging stations represent a substantial load with significant flexibility. The exploitation of that flexibility in demand response (DR) algorithms becomes increasingly important to manage and balance demand and supply in power grids. Model-free DR based on reinforcement learning (RL) is an attractive approach to balance such EV charging load. We build on previous research on RL, based on a Markov decision process (MDP) to simultaneously coordinate multiple charging stations. However, we note that the computationally expensive cost function adopted in the previous research leads to large training times, which limits the feasibility and practicality of the approach. We, therefore, propose an improved cost function that essentially forces the learned control policy to always fulfill any charging demand that does not offer any flexibility. We rigorously compare the newly proposed batch RL fitted Q-iteration implementation with the original (costly) one, using real-world data. Specifically, for the case of load flattening, we compare the two approaches in terms of (i) the processing time to learn the RL-based charging policy, as well as (ii) the overall performance of the policy decisions in terms of meeting the target load for unseen test data. The performance is analyzed for different training periods and varying training sample sizes. In addition to both RL policies performance results, we provide performance bounds in terms of both (i) an optimal all-knowing strategy, and (ii) a simple heuristic spreading individual EV charging uniformly over time
A Survey of Non-Rigid 3D Registration
Mar 16, 2022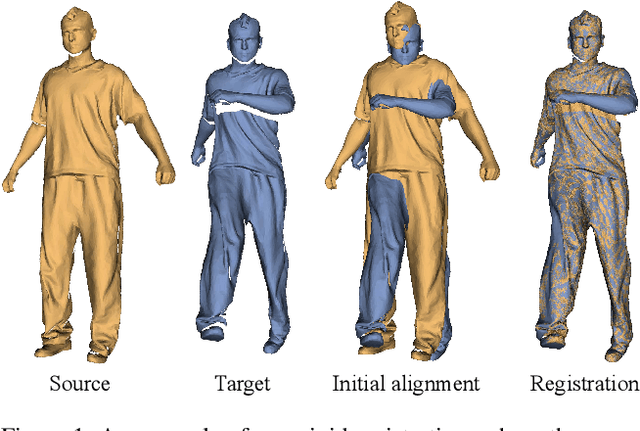
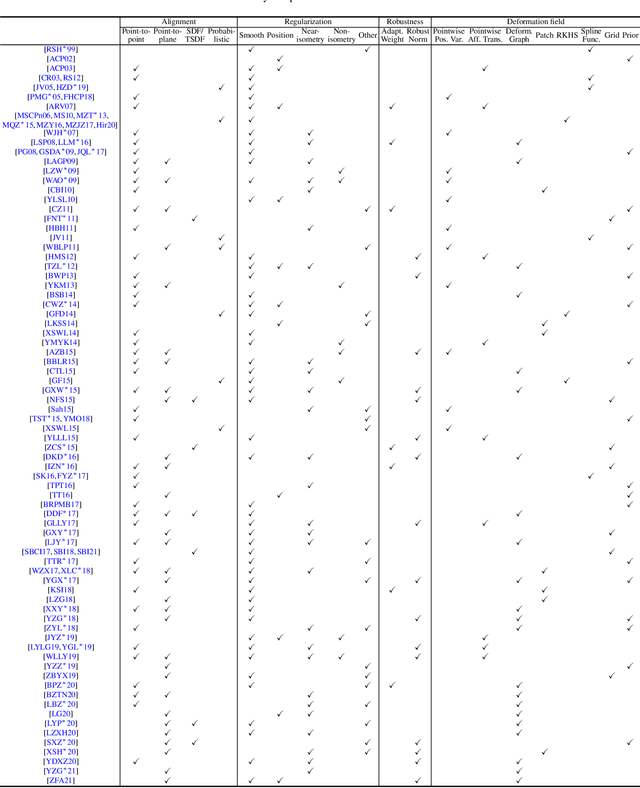

Non-rigid registration computes an alignment between a source surface with a target surface in a non-rigid manner. In the past decade, with the advances in 3D sensing technologies that can measure time-varying surfaces, non-rigid registration has been applied for the acquisition of deformable shapes and has a wide range of applications. This survey presents a comprehensive review of non-rigid registration methods for 3D shapes, focusing on techniques related to dynamic shape acquisition and reconstruction. In particular, we review different approaches for representing the deformation field, and the methods for computing the desired deformation. Both optimization-based and learning-based methods are covered. We also review benchmarks and datasets for evaluating non-rigid registration methods, and discuss potential future research directions.
Combined Pruning for Nested Cross-Validation to Accelerate Automated Hyperparameter Optimization for Embedded Feature Selection in High-Dimensional Data with Very Small Sample Sizes
Feb 01, 2022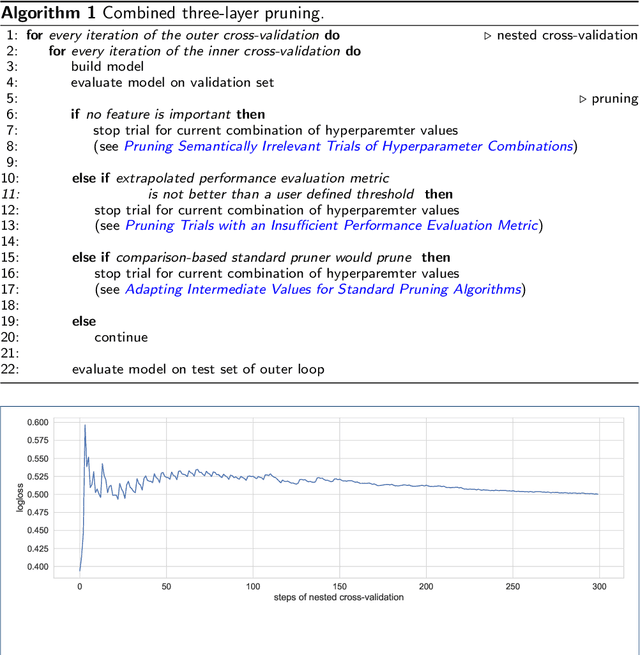
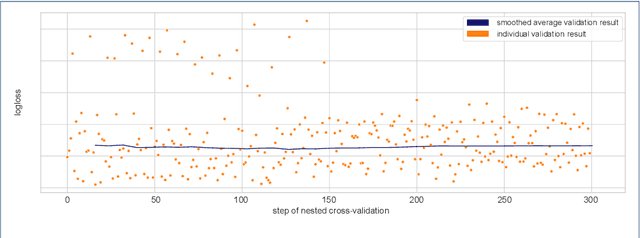
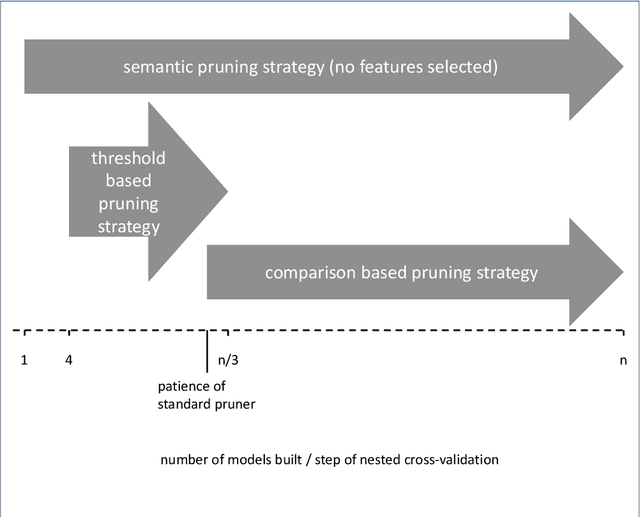
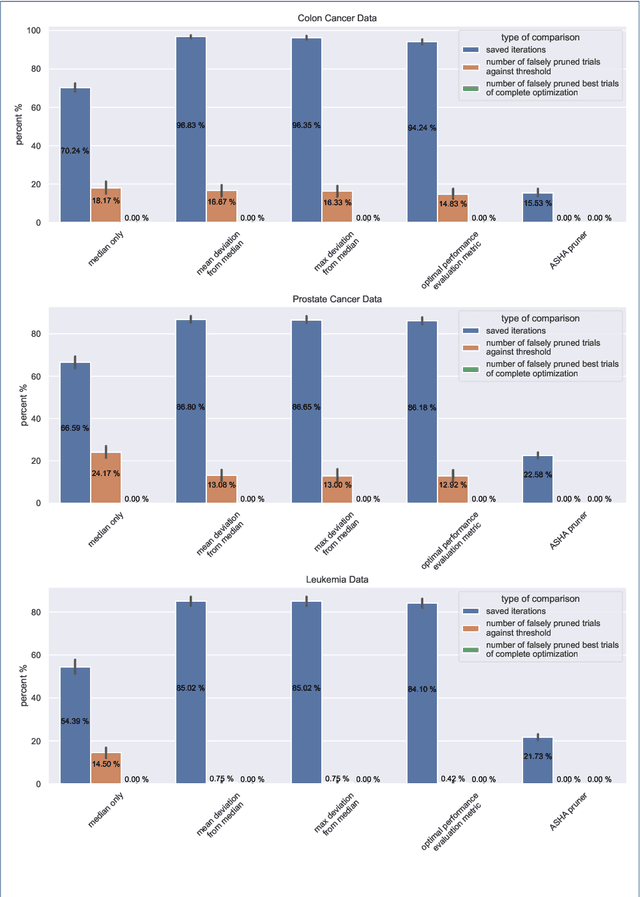
Applying tree-based embedded feature selection to exclude irrelevant features in high-dimensional data with very small sample sizes requires optimized hyperparameters for the model building process. In addition, nested cross-validation must be applied for this type of data to avoid biased model performance. The resulting long computation time can be accelerated with pruning. However, standard pruning algorithms must prune late or risk aborting calculations of promising hyperparameter sets due to high variance in the performance evaluation metric. To address this, we adapt the usage of a state-of-the-art successive halving pruner and combine it with two new pruning strategies based on domain or prior knowledge. One additional pruning strategy immediately stops the computation of trials with semantically meaningless results for the selected hyperparameter combinations. The other is an extrapolating threshold pruning strategy suitable for nested-cross-validation with high variance. Our proposed combined three-layer pruner keeps promising trials while reducing the number of models to be built by up to 81,3% compared to using a state-of-the-art asynchronous successive halving pruner alone. Our three-layer pruner implementation(available at https://github.com/sigrun-may/cv-pruner) speeds up data analysis or enables deeper hyperparameter search within the same computation time. It consequently saves time, money and energy, reducing the CO2 footprint.
Compressing 1D Time-Channel Separable Convolutions using Sparse Random Ternary Matrices
Apr 01, 2021
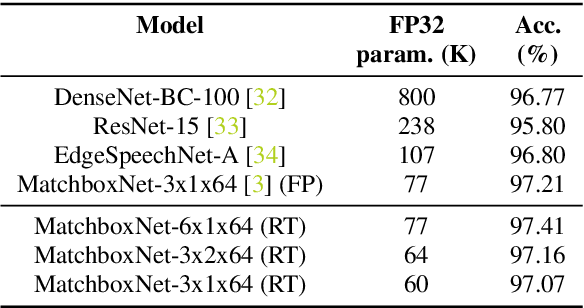

We demonstrate that 1x1-convolutions in 1D time-channel separable convolutions may be replaced by constant, sparse random ternary matrices with weights in $\{-1,0,+1\}$. Such layers do not perform any multiplications and do not require training. Moreover, the matrices may be generated on the chip during computation and therefore do not require any memory access. With the same parameter budget, we can afford deeper and more expressive models, improving the Pareto frontiers of existing models on several tasks. For command recognition on Google Speech Commands v1, we improve the state-of-the-art accuracy from $97.21\%$ to $97.41\%$ at the same network size. Alternatively, we can lower the cost of existing models. For speech recognition on Librispeech, we half the number of weights to be trained while only sacrificing about $1\%$ of the floating-point baseline's word error rate.
A single Long Short-Term Memory network for enhancing the prediction of path-dependent plasticity with material heterogeneity and anisotropy
Apr 05, 2022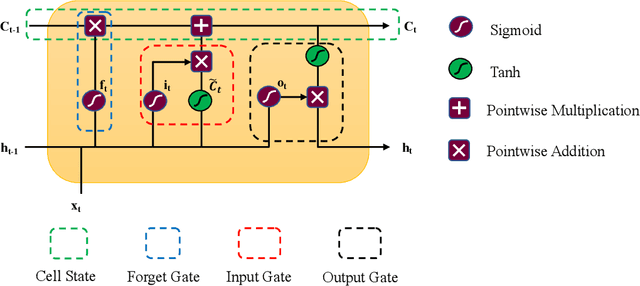

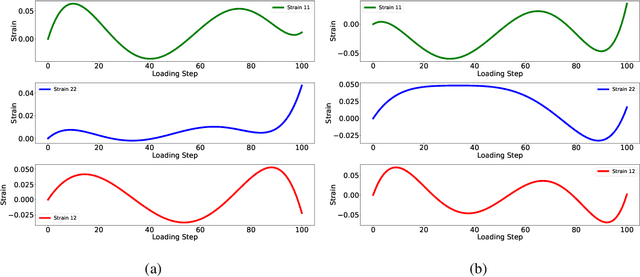

This study presents the applicability of conventional deep recurrent neural networks (RNN) to predict path-dependent plasticity associated with material heterogeneity and anisotropy. Although the architecture of RNN possesses inductive biases toward information over time, it is still challenging to learn the path-dependent material behavior as a function of the loading path considering the change from elastic to elastoplastic regimes. Our attempt is to develop a simple machine-learning-based model that can replicate elastoplastic behaviors considering material heterogeneity and anisotropy. The basic Long-Short Term Memory Unit (LSTM) is adopted for the modeling of plasticity in the two-dimensional space by enhancing the inductive bias toward the past information through manipulating input variables. Our results find that a single LSTM based model can capture the J2 plasticity responses under both monotonic and arbitrary loading paths provided the material heterogeneity. The proposed neural network architecture is then used to model elastoplastic responses of a two-dimensional transversely anisotropic material associated with computational homogenization (FE2). It is also found that a single LSTM model can be used to accurately and effectively capture the path-dependent responses of heterogeneous and anisotropic microstructures under arbitrary mechanical loading conditions.
Automatic Calibration Framework of Agent-Based Models for Dynamic and Heterogeneous Parameters
Mar 07, 2022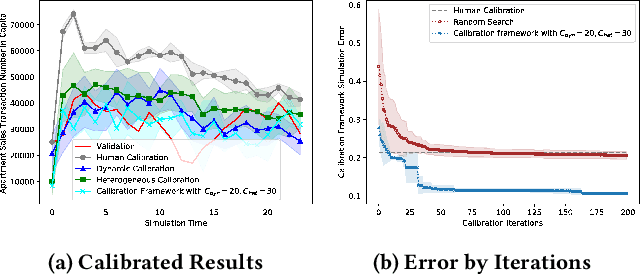
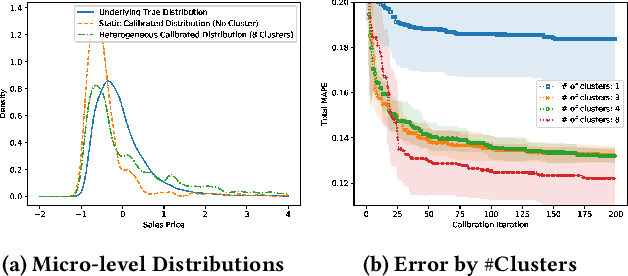
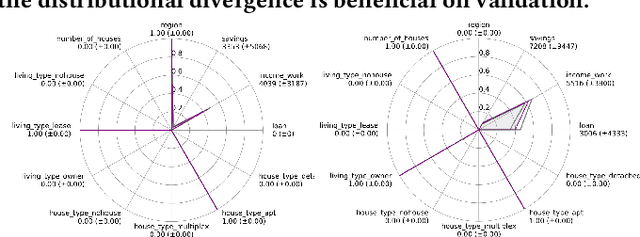
Agent-based models (ABMs) highlight the importance of simulation validation, such as qualitative face validation and quantitative empirical validation. In particular, we focused on quantitative validation by adjusting simulation input parameters of the ABM. This study introduces an automatic calibration framework that combines the suggested dynamic and heterogeneous calibration methods. Specifically, the dynamic calibration fits the simulation results to the real-world data by automatically capturing suitable simulation time to adjust the simulation parameters. Meanwhile, the heterogeneous calibration reduces the distributional discrepancy between individuals in the simulation and the real world by adjusting agent related parameters cluster-wisely.
Scalable Whitebox Attacks on Tree-based Models
Mar 31, 2022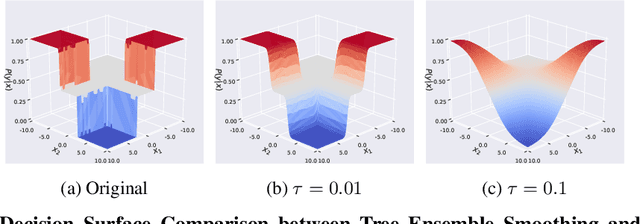
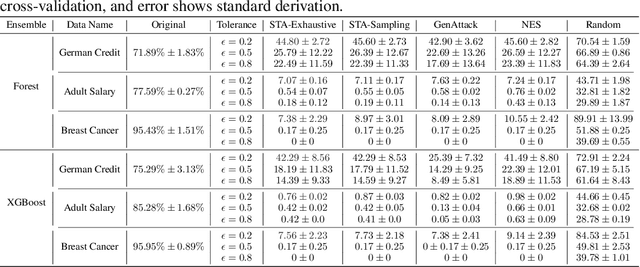
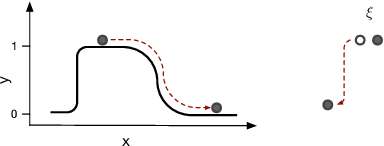
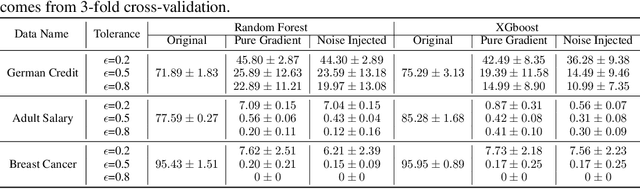
Adversarial robustness is one of the essential safety criteria for guaranteeing the reliability of machine learning models. While various adversarial robustness testing approaches were introduced in the last decade, we note that most of them are incompatible with non-differentiable models such as tree ensembles. Since tree ensembles are widely used in industry, this reveals a crucial gap between adversarial robustness research and practical applications. This paper proposes a novel whitebox adversarial robustness testing approach for tree ensemble models. Concretely, the proposed approach smooths the tree ensembles through temperature controlled sigmoid functions, which enables gradient descent-based adversarial attacks. By leveraging sampling and the log-derivative trick, the proposed approach can scale up to testing tasks that were previously unmanageable. We compare the approach against both random perturbations and blackbox approaches on multiple public datasets (and corresponding models). Our results show that the proposed method can 1) successfully reveal the adversarial vulnerability of tree ensemble models without causing computational pressure for testing and 2) flexibly balance the search performance and time complexity to meet various testing criteria.
Real-Time Semantic Background Subtraction
Feb 12, 2020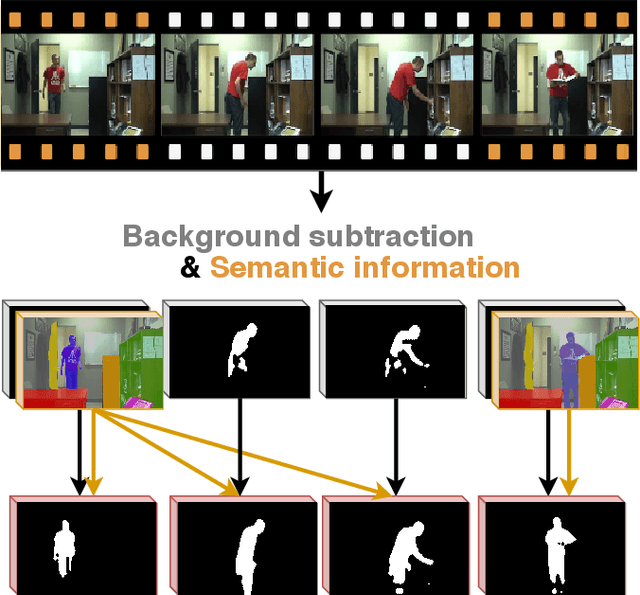
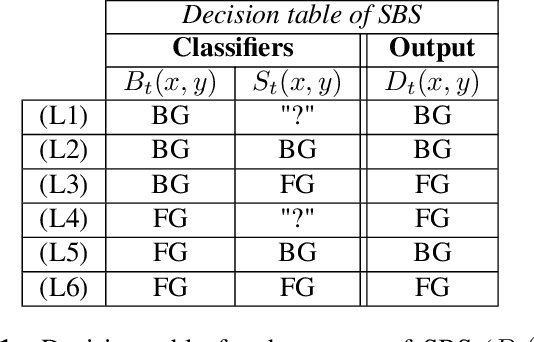
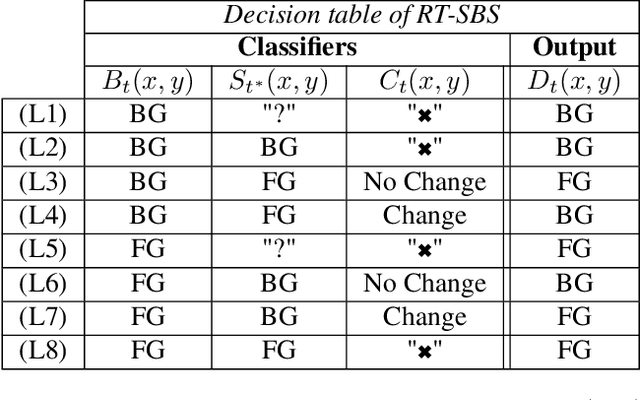
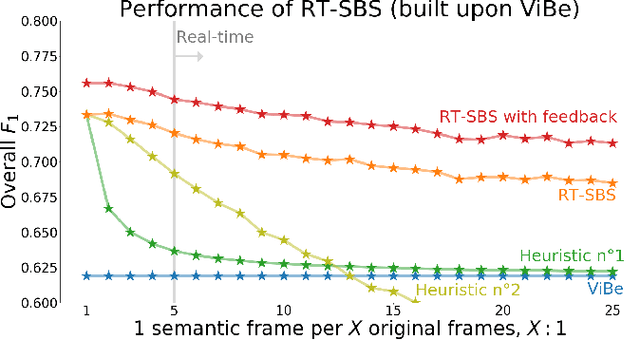
Semantic background subtraction SBS has been shown to improve the performance of most background subtraction algorithms by combining them with semantic information, derived from a semantic segmentation network. However, SBS requires high-quality semantic segmentation masks for all frames, which are slow to compute. In addition, most state-of-the-art background subtraction algorithms are not real-time, which makes them unsuitable for real-world applications. In this paper, we present a novel background subtraction algorithm called Real-Time Semantic Background Subtraction (denoted RT-SBS) which extends SBS for real-time constrained applications while keeping similar performances. RT-SBS effectively combines a real-time background subtraction algorithm with high-quality semantic information which can be provided at a slower pace, independently for each pixel. We show that RT-SBS coupled with ViBe sets a new state of the art for real-time background subtraction algorithms and even competes with the non real-time state-of-the-art ones. Note that python CPU and GPU implementations of RT-SBS will be released soon.
Colon Nuclei Instance Segmentation using a Probabilistic Two-Stage Detector
Mar 01, 2022
Cancer is one of the leading causes of death in the developed world. Cancer diagnosis is performed through the microscopic analysis of a sample of suspicious tissue. This process is time consuming and error prone, but Deep Learning models could be helpful for pathologists during cancer diagnosis. We propose to change the CenterNet2 object detection model to also perform instance segmentation, which we call SegCenterNet2. We train SegCenterNet2 in the CoNIC challenge dataset and show that it performs better than Mask R-CNN in the competition metrics.