 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Joint brain tumor segmentation from multi MR sequences through a deep convolutional neural network
Mar 07, 2022
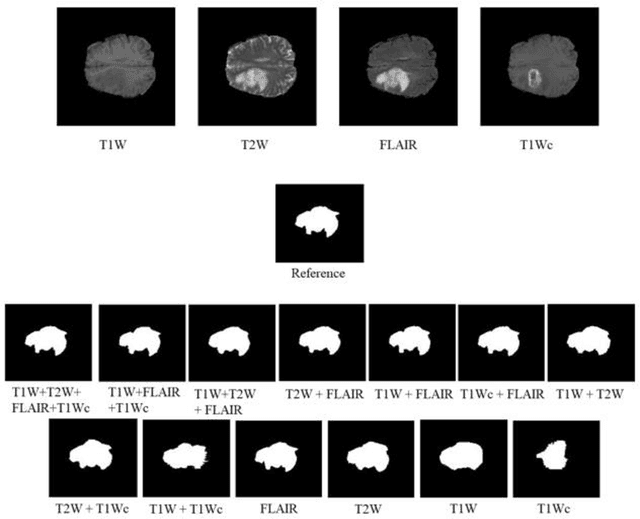
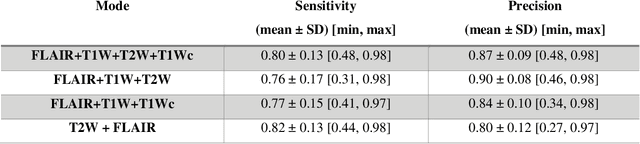
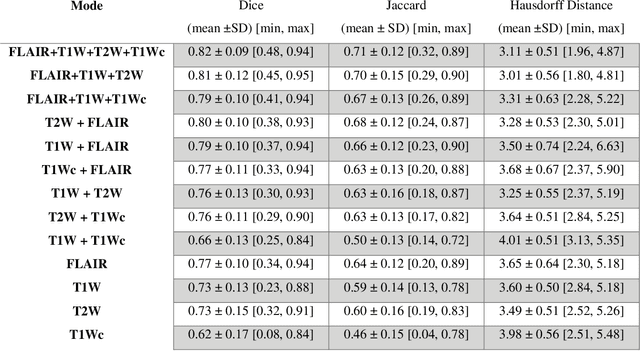
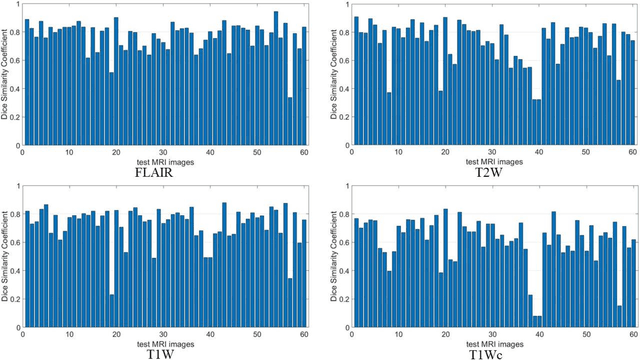
Brain tumor segmentation is highly contributive in diagnosing and treatment planning. The manual brain tumor delineation is a time-consuming and tedious task and varies depending on the radiologists skill. Automated brain tumor segmentation is of high importance, and does not depend on either inter or intra-observation. The objective of this study is to automate the delineation of brain tumors from the FLAIR, T1 weighted, T2 weighted, and T1 weighted contrast-enhanced MR sequences through a deep learning approach, with a focus on determining which MR sequence alone or which combination thereof would lead to the highest accuracy therein.
Learning to modulate random weights can induce task-specific contexts for economical meta and continual learning
Apr 08, 2022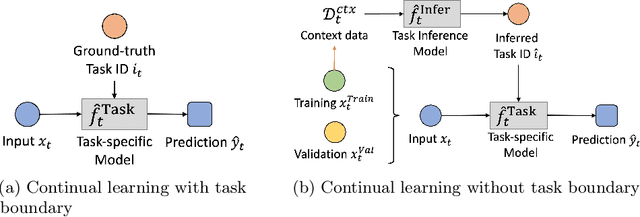
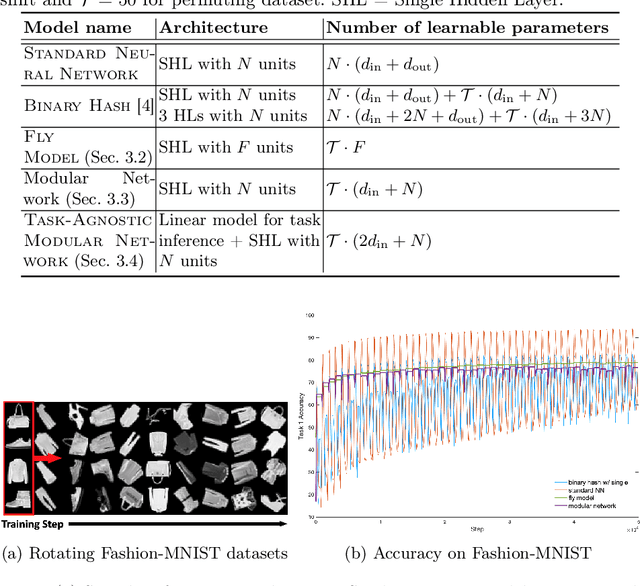
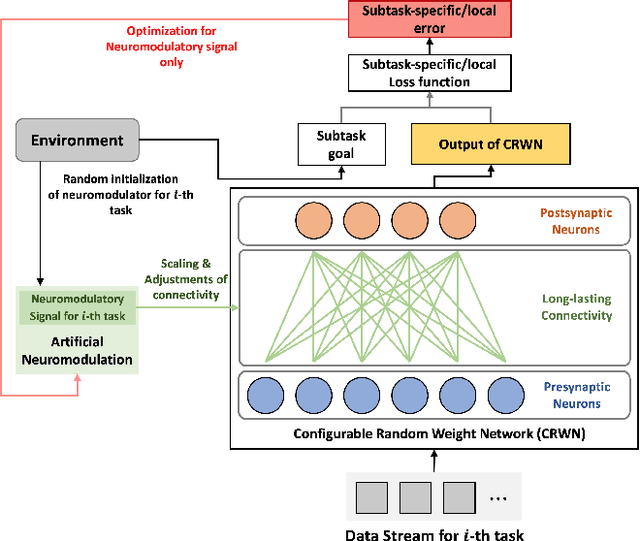
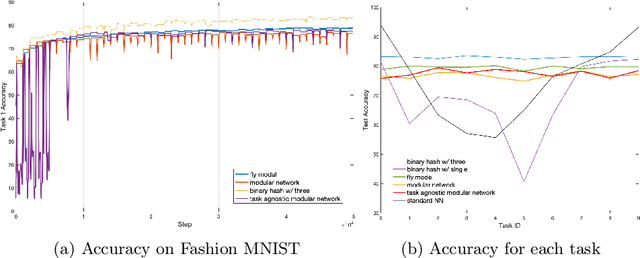
Neural networks are vulnerable to catastrophic forgetting when data distributions are non-stationary during continual online learning; learning of a later task often leads to forgetting of an earlier task. One solution approach is model-agnostic continual meta-learning, whereby both task-specific and meta parameters are trained. Here, we depart from this view and introduce a novel neural-network architecture inspired by neuromodulation in biological nervous systems. Neuromodulation is the biological mechanism that dynamically controls and fine-tunes synaptic dynamics to complement the behavioral context in real-time, which has received limited attention in machine learning. We introduce a single-hidden-layer network that learns only a relatively small context vector per task (task-specific parameters) that neuromodulates unchanging, randomized weights (meta parameters) that transform the input. We show that when task boundaries are available, this approach can eliminate catastrophic forgetting entirely while also drastically reducing the number of learnable parameters relative to other context-vector-based approaches. Furthermore, by combining this model with a simple meta-learning approach for inferring task identity, we demonstrate that the model can be generalized into a framework to perform continual learning without knowledge of task boundaries. Finally, we showcase the framework in a supervised continual online learning scenario and discuss the implications of the proposed formalism.
A Survey of Non-Rigid 3D Registration
Mar 16, 2022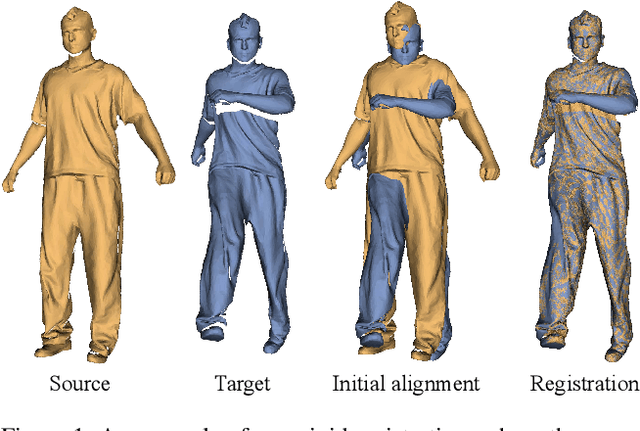
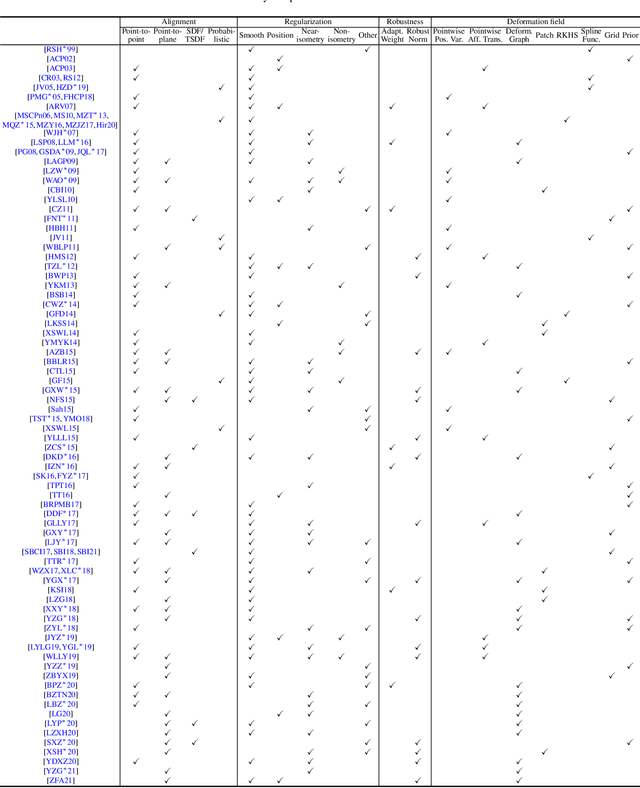

Non-rigid registration computes an alignment between a source surface with a target surface in a non-rigid manner. In the past decade, with the advances in 3D sensing technologies that can measure time-varying surfaces, non-rigid registration has been applied for the acquisition of deformable shapes and has a wide range of applications. This survey presents a comprehensive review of non-rigid registration methods for 3D shapes, focusing on techniques related to dynamic shape acquisition and reconstruction. In particular, we review different approaches for representing the deformation field, and the methods for computing the desired deformation. Both optimization-based and learning-based methods are covered. We also review benchmarks and datasets for evaluating non-rigid registration methods, and discuss potential future research directions.
Reward-Respecting Subtasks for Model-Based Reinforcement Learning
Feb 09, 2022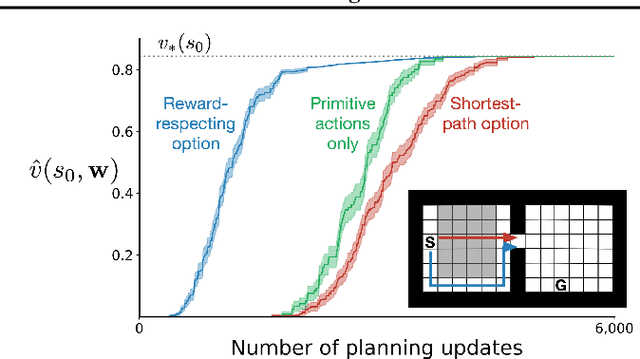
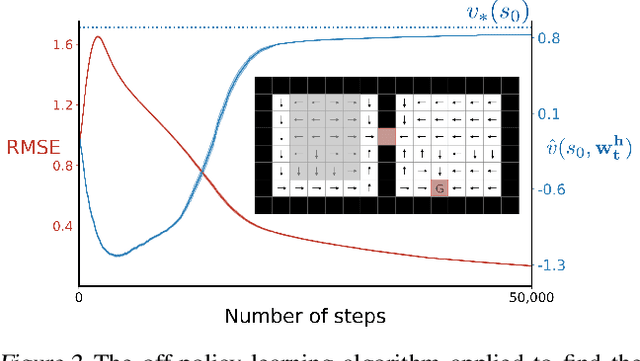
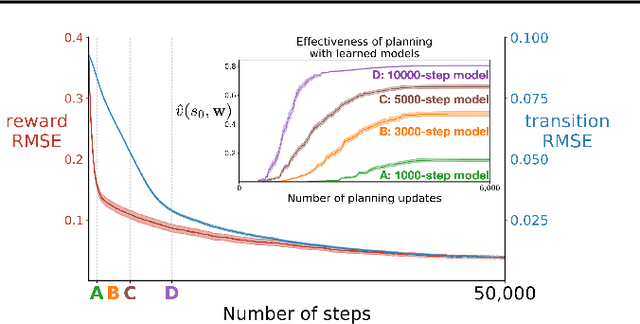
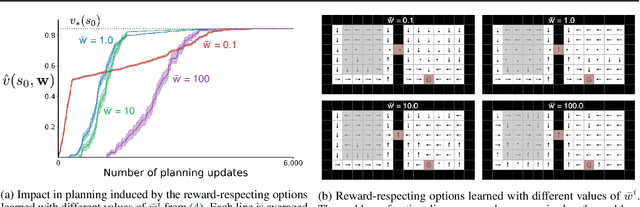
To achieve the ambitious goals of artificial intelligence, reinforcement learning must include planning with a model of the world that is abstract in state and time. Deep learning has made progress in state abstraction, but, although the theory of time abstraction has been extensively developed based on the options framework, in practice options have rarely been used in planning. One reason for this is that the space of possible options is immense and the methods previously proposed for option discovery do not take into account how the option models will be used in planning. Options are typically discovered by posing subsidiary tasks such as reaching a bottleneck state, or maximizing a sensory signal other than the reward. Each subtask is solved to produce an option, and then a model of the option is learned and made available to the planning process. The subtasks proposed in most previous work ignore the reward on the original problem, whereas we propose subtasks that use the original reward plus a bonus based on a feature of the state at the time the option stops. We show that options and option models obtained from such reward-respecting subtasks are much more likely to be useful in planning and can be learned online and off-policy using existing learning algorithms. Reward respecting subtasks strongly constrain the space of options and thereby also provide a partial solution to the problem of option discovery. Finally, we show how the algorithms for learning values, policies, options, and models can be unified using general value functions.
Kartta Labs: Collaborative Time Travel
Oct 07, 2020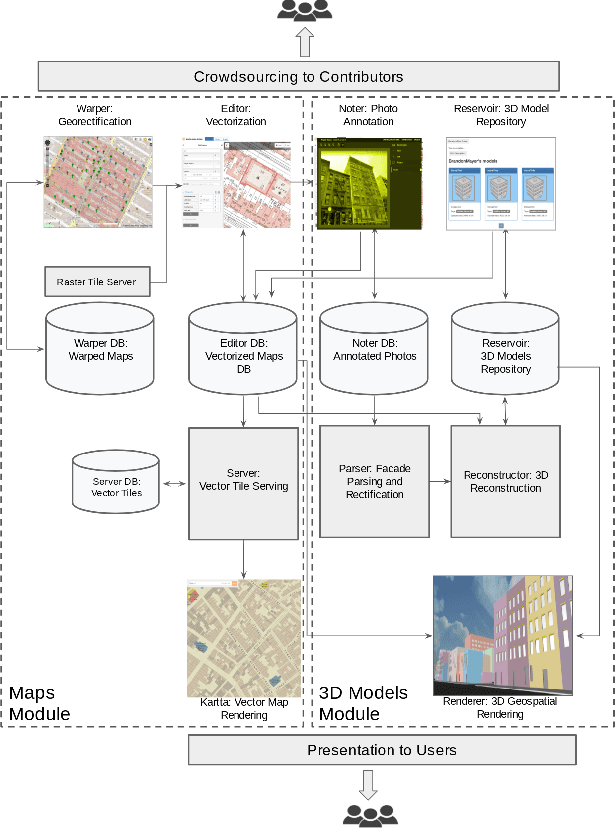
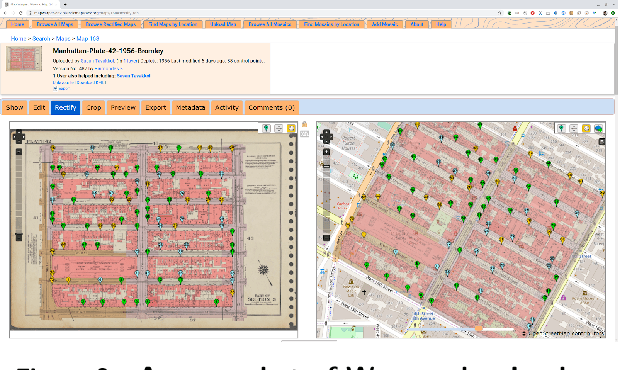
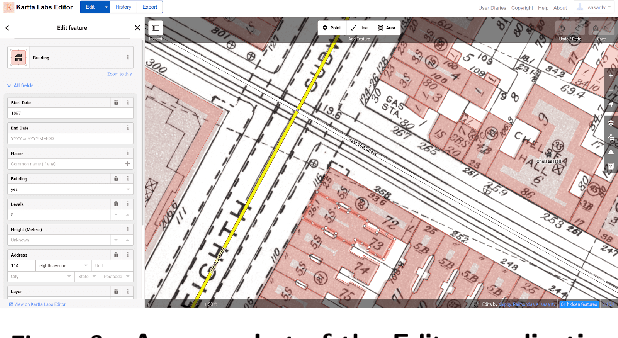
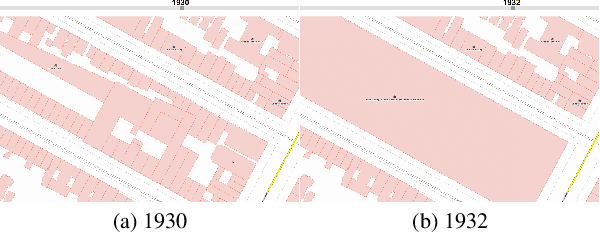
We introduce the modular and scalable design of Kartta Labs, an open source, open data, and scalable system for virtually reconstructing cities from historical maps and photos. Kartta Labs relies on crowdsourcing and artificial intelligence consisting of two major modules: Maps and 3D models. Each module, in turn, consists of sub-modules that enable the system to reconstruct a city from historical maps and photos. The result is a spatiotemporal reference that can be used to integrate various collected data (curated, sensed, or crowdsourced) for research, education, and entertainment purposes. The system empowers the users to experience collaborative time travel such that they work together to reconstruct the past and experience it on an open source and open data platform.
Can Adversarial Training Be Manipulated By Non-Robust Features?
Jan 31, 2022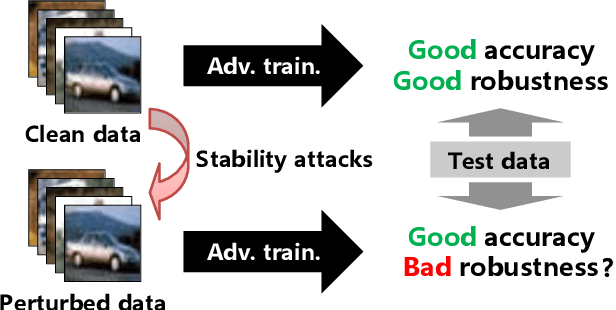
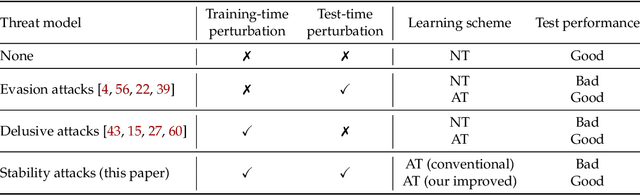
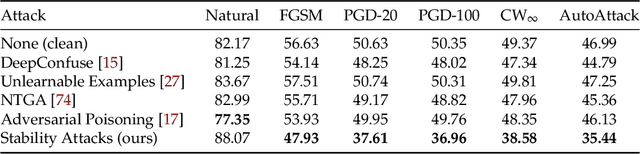
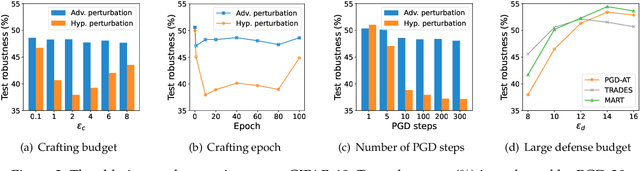
Adversarial training, originally designed to resist test-time adversarial examples, has shown to be promising in mitigating training-time availability attacks. This defense ability, however, is challenged in this paper. We identify a novel threat model named stability attacks, which aims to hinder robust availability by slightly perturbing the training data. Under this threat, we find that adversarial training using a conventional defense budget $\epsilon$ provably fails to provide test robustness in a simple statistical setting when the non-robust features of the training data are reinforced by $\epsilon$-bounded perturbation. Further, we analyze the necessity of enlarging the defense budget to counter stability attacks. Finally, comprehensive experiments demonstrate that stability attacks are harmful on benchmark datasets, and thus the adaptive defense is necessary to maintain robustness.
Proximal Policy Optimization Learning based Control of Congested Freeway Traffic
Apr 12, 2022
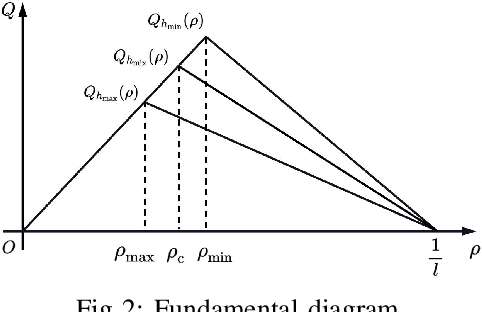
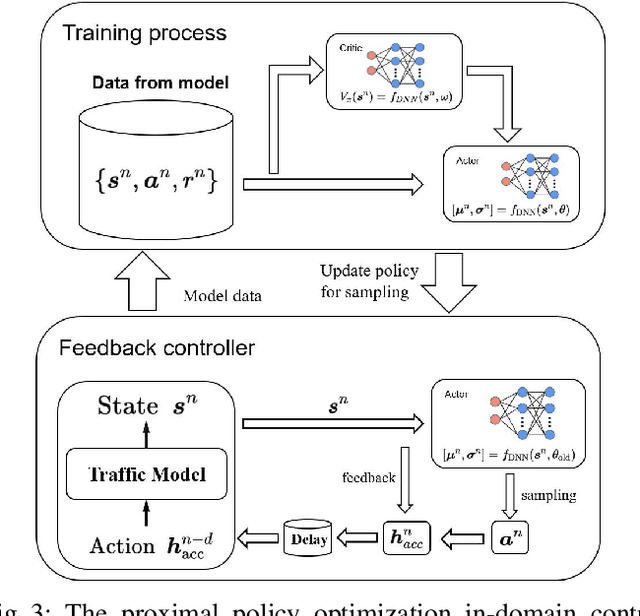
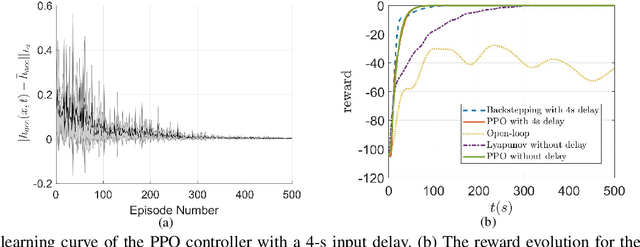
This study proposes a delay-compensated feedback controller based on proximal policy optimization (PPO) reinforcement learning to stabilize traffic flow in the congested regime by manipulating the time-gap of adaptive cruise control-equipped (ACC-equipped) vehicles.The traffic dynamics on a freeway segment are governed by an Aw-Rascle-Zhang (ARZ) model, consisting of $2\times 2$ nonlinear first-order partial differential equations (PDEs).Inspired by the backstepping delay compensator [18] but different from whose complex segmented control scheme, the PPO control is composed of three feedbacks, namely the current traffic flow velocity, the current traffic flow density and previous one step control input. The control gains for the three feedbacks are learned from the interaction between the PPO and the numerical simulator of the traffic system without knowing the system dynamics. Numerical simulation experiments are designed to compare the Lyapunov control, the backstepping control and the PPO control. The results show that for a delay-free system, the PPO control has faster convergence rate and less control effort than the Lyapunov control. For a traffic system with input delay, the performance of the PPO controller is comparable to that of the Backstepping controller, even for the situation that the delay value does not match. However, the PPO is robust to parameter perturbations, while the Backstepping controller cannot stabilize a system where one of the parameters is disturbed by Gaussian noise.
Optimized cost function for demand response coordination of multiple EV charging stations using reinforcement learning
Mar 03, 2022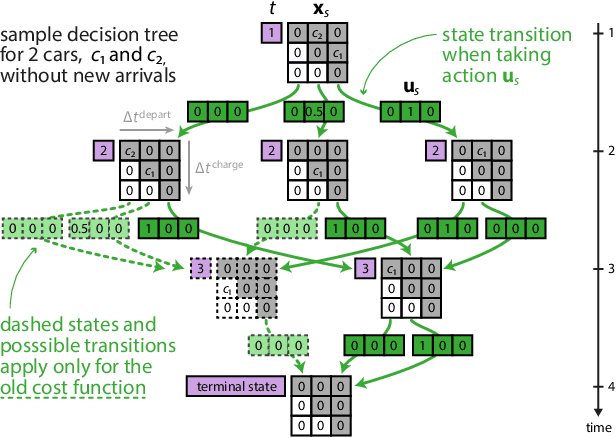
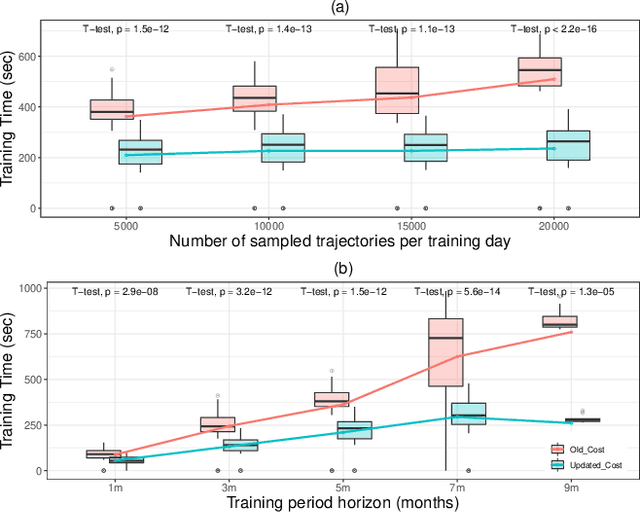
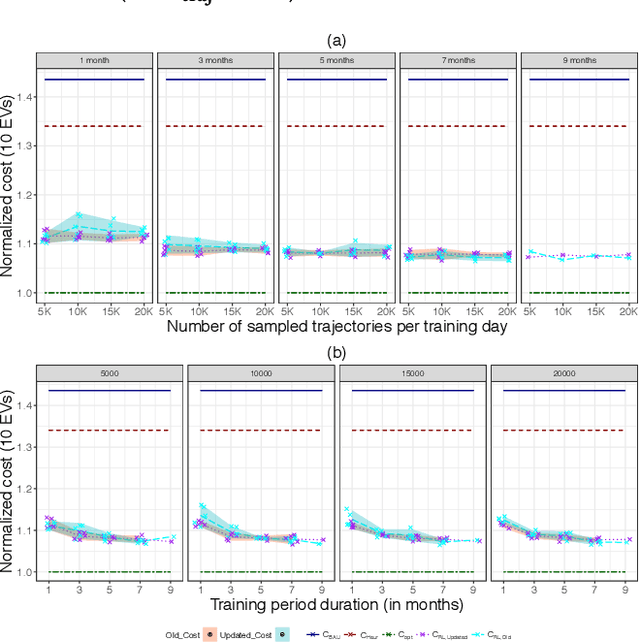
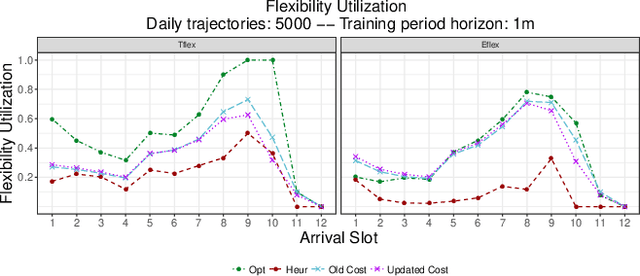
Electric vehicle (EV) charging stations represent a substantial load with significant flexibility. The exploitation of that flexibility in demand response (DR) algorithms becomes increasingly important to manage and balance demand and supply in power grids. Model-free DR based on reinforcement learning (RL) is an attractive approach to balance such EV charging load. We build on previous research on RL, based on a Markov decision process (MDP) to simultaneously coordinate multiple charging stations. However, we note that the computationally expensive cost function adopted in the previous research leads to large training times, which limits the feasibility and practicality of the approach. We, therefore, propose an improved cost function that essentially forces the learned control policy to always fulfill any charging demand that does not offer any flexibility. We rigorously compare the newly proposed batch RL fitted Q-iteration implementation with the original (costly) one, using real-world data. Specifically, for the case of load flattening, we compare the two approaches in terms of (i) the processing time to learn the RL-based charging policy, as well as (ii) the overall performance of the policy decisions in terms of meeting the target load for unseen test data. The performance is analyzed for different training periods and varying training sample sizes. In addition to both RL policies performance results, we provide performance bounds in terms of both (i) an optimal all-knowing strategy, and (ii) a simple heuristic spreading individual EV charging uniformly over time
Online State-Time Trajectory Planning Using Timed-ESDF in Highly Dynamic Environments
Oct 29, 2020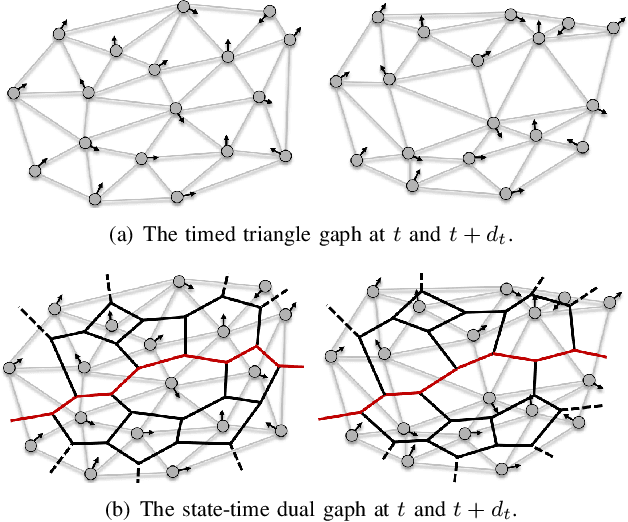
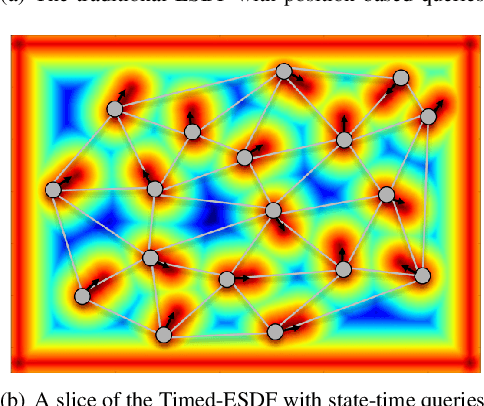

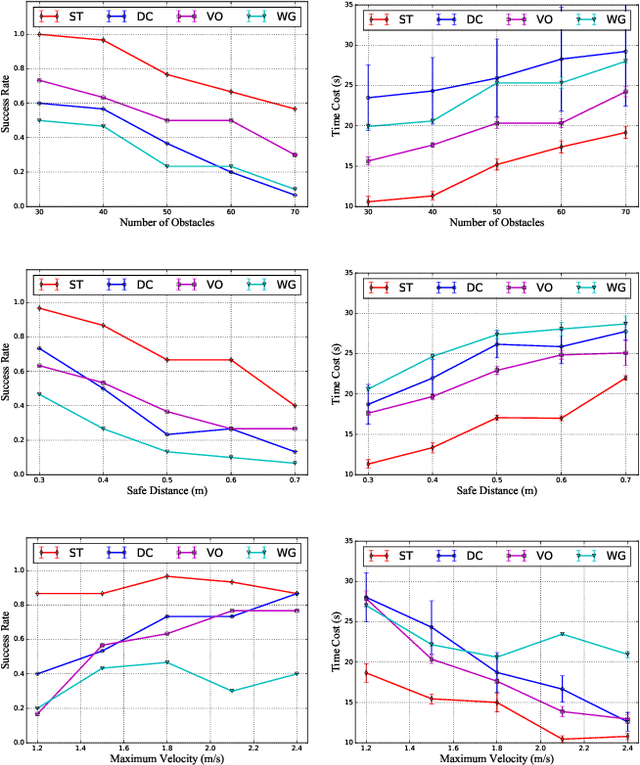
Online state-time trajectory planning in highly dynamic environments remains an unsolved problem due to the unpredictable motions of moving obstacles and the curse of dimensionality from the state-time space. Existing state-time planners are typically implemented based on randomized sampling approaches or path searching on discretized state graph. The smoothness, path clearance, and planning efficiency of these planners are usually not satisfying. In this work, we propose a gradient-based planner over the state-time space for online trajectory generation in highly dynamic environments. To enable the gradient-based optimization, we propose a Timed-ESDT that supports distance and gradient queries with state-time keys. Based on the Timed-ESDT, we also define a smooth prior and an obstacle likelihood function that is compatible with the state-time space. The trajectory planning is then formulated to a MAP problem and solved by an efficient numerical optimizer. Moreover, to improve the optimality of the planner, we also define a state-time graph and then conduct path searching on it to find a better initialization for the optimizer. By integrating the graph searching, the planning quality is significantly improved. Experiment results on simulated and benchmark datasets show that our planner can outperform the state-of-the-art methods, demonstrating its significant advantages over the traditional ones.
DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection
Apr 12, 2022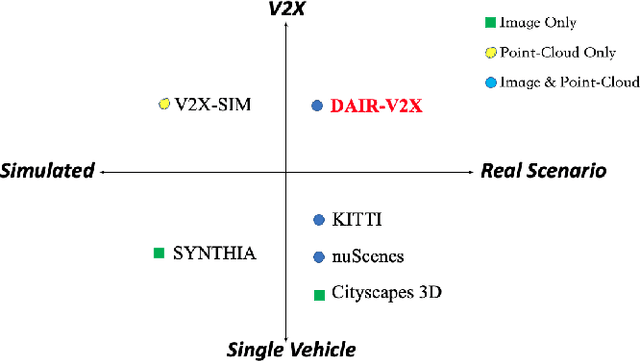
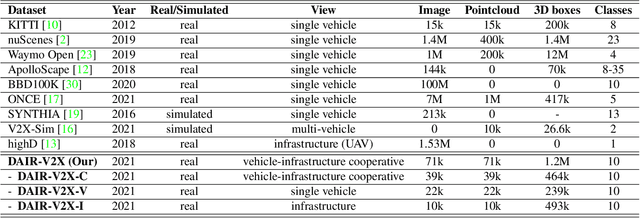
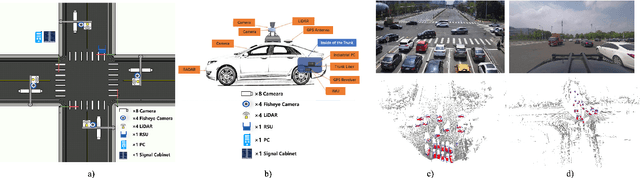
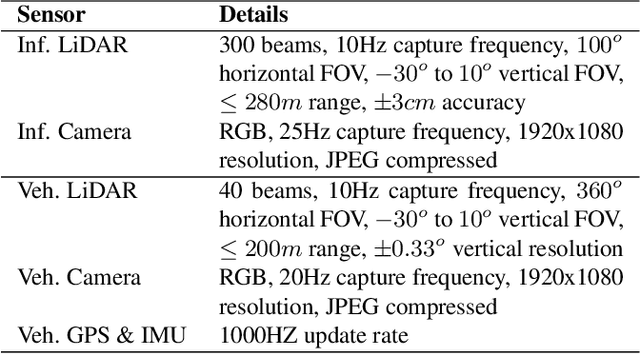
Autonomous driving faces great safety challenges for a lack of global perspective and the limitation of long-range perception capabilities. It has been widely agreed that vehicle-infrastructure cooperation is required to achieve Level 5 autonomy. However, there is still NO dataset from real scenarios available for computer vision researchers to work on vehicle-infrastructure cooperation-related problems. To accelerate computer vision research and innovation for Vehicle-Infrastructure Cooperative Autonomous Driving (VICAD), we release DAIR-V2X Dataset, which is the first large-scale, multi-modality, multi-view dataset from real scenarios for VICAD. DAIR-V2X comprises 71254 LiDAR frames and 71254 Camera frames, and all frames are captured from real scenes with 3D annotations. The Vehicle-Infrastructure Cooperative 3D Object Detection problem (VIC3D) is introduced, formulating the problem of collaboratively locating and identifying 3D objects using sensory inputs from both vehicle and infrastructure. In addition to solving traditional 3D object detection problems, the solution of VIC3D needs to consider the temporal asynchrony problem between vehicle and infrastructure sensors and the data transmission cost between them. Furthermore, we propose Time Compensation Late Fusion (TCLF), a late fusion framework for the VIC3D task as a benchmark based on DAIR-V2X. Find data, code, and more up-to-date information at https://thudair.baai.ac.cn/index and https://github.com/AIR-THU/DAIR-V2X.