 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling
Dec 06, 2020


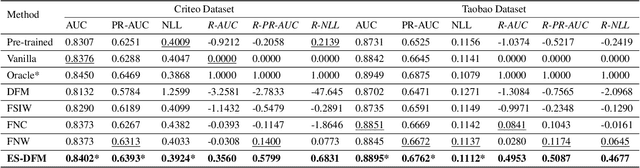

Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling Hide abstract Conversion rate (CVR) prediction is one of the most critical tasks for digital display advertising. Commercial systems often require to update models in an online learning manner to catch up with the evolving data distribution. However, conversions usually do not happen immediately after a user click. This may result in inaccurate labeling, which is called delayed feedback problem. In previous studies, delayed feedback problem is handled either by waiting positive label for a long period of time, or by consuming the negative sample on its arrival and then insert a positive duplicate when a conversion happens later. Indeed, there is a trade-off between waiting for more accurate labels and utilizing fresh data, which is not considered in existing works. To strike a balance in this trade-off, we propose Elapsed-Time Sampling Delayed Feedback Model (ES-DFM), which models the relationship between the observed conversion distribution and the true conversion distribution. Then we optimize the expectation of true conversion distribution via importance sampling under the elapsed-time sampling distribution. We further estimate the importance weight for each instance, which is used as the weight of loss function in CVR prediction. To demonstrate the effectiveness of ES-DFM, we conduct extensive experiments on a public data and a private industrial dataset. Experimental results confirm that our method consistently outperforms the previous state-of-the-art results.
Tweet Emotion Dynamics: Emotion Word Usage in Tweets from US and Canada
Apr 11, 2022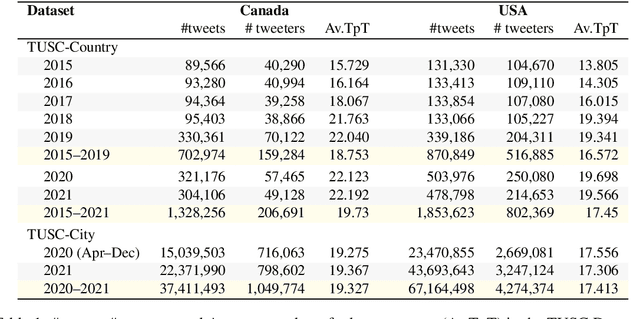
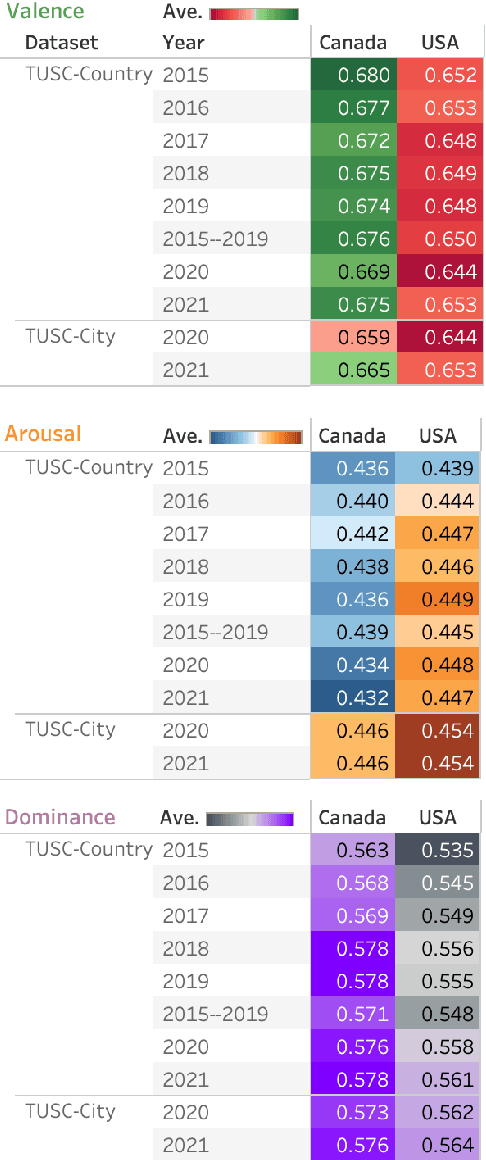
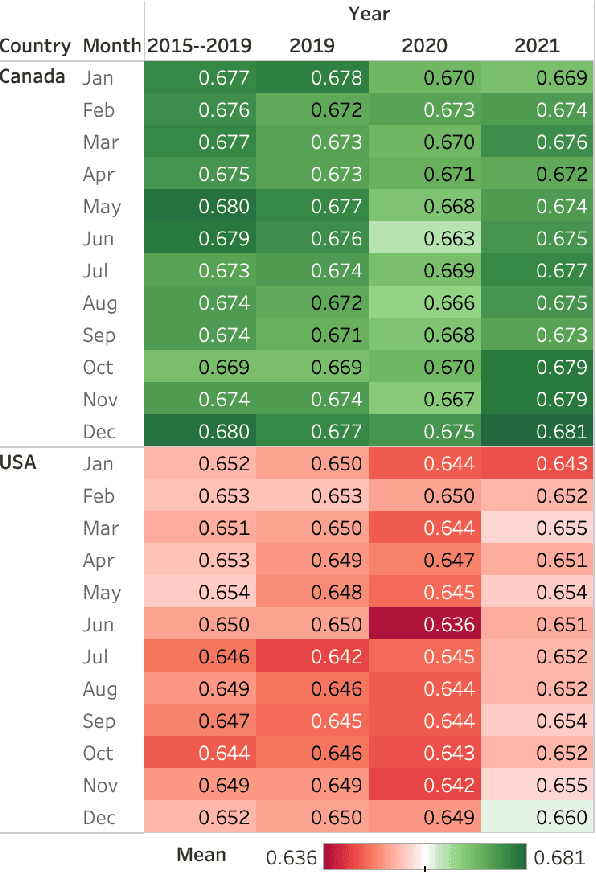
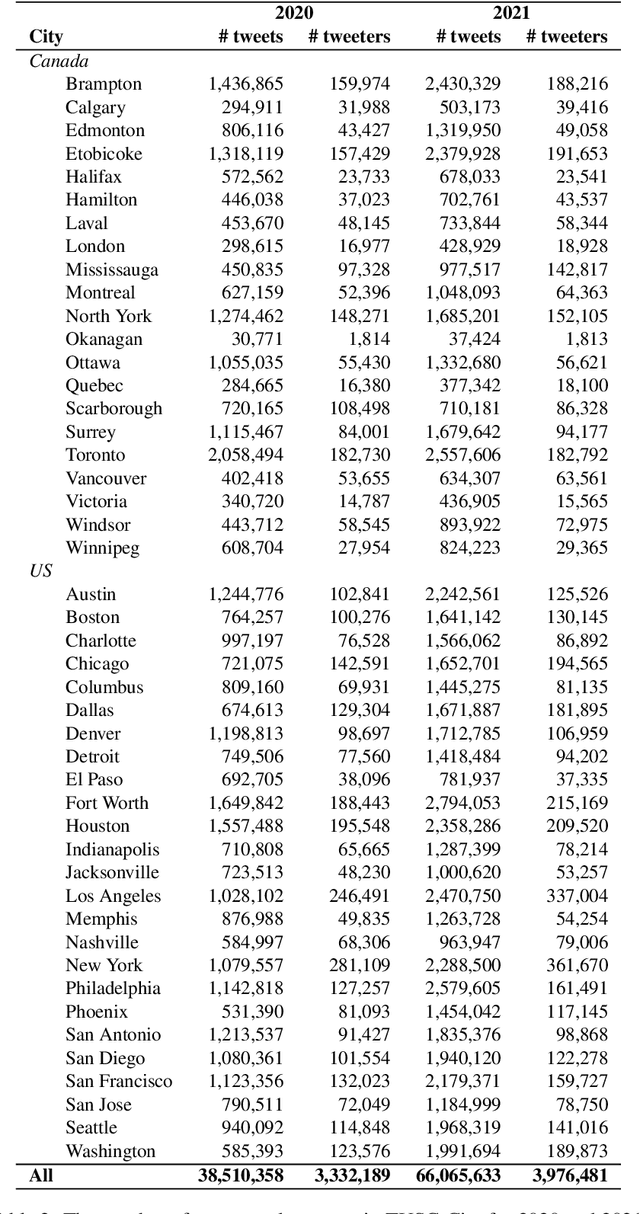
Over the last decade, Twitter has emerged as one of the most influential forums for social, political, and health discourse. In this paper, we introduce a massive dataset of more than 45 million geo-located tweets posted between 2015 and 2021 from US and Canada (TUSC), especially curated for natural language analysis. We also introduce Tweet Emotion Dynamics (TED) -- metrics to capture patterns of emotions associated with tweets over time. We use TED and TUSC to explore the use of emotion-associated words across US and Canada; across 2019 (pre-pandemic), 2020 (the year the pandemic hit), and 2021 (the second year of the pandemic); and across individual tweeters. We show that Canadian tweets tend to have higher valence, lower arousal, and higher dominance than the US tweets. Further, we show that the COVID-19 pandemic had a marked impact on the emotional signature of tweets posted in 2020, when compared to the adjoining years. Finally, we determine metrics of TED for 170,000 tweeters to benchmark characteristics of TED metrics at an aggregate level. TUSC and the metrics for TED will enable a wide variety of research on studying how we use language to express ourselves, persuade, communicate, and influence, with particularly promising applications in public health, affective science, social science, and psychology.
Probing for Labeled Dependency Trees
Mar 24, 2022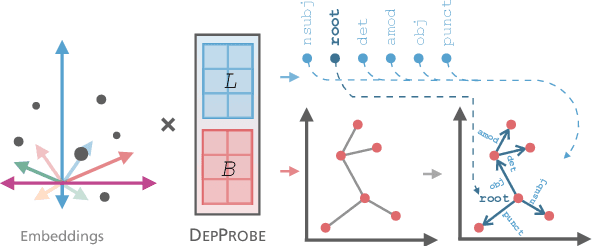

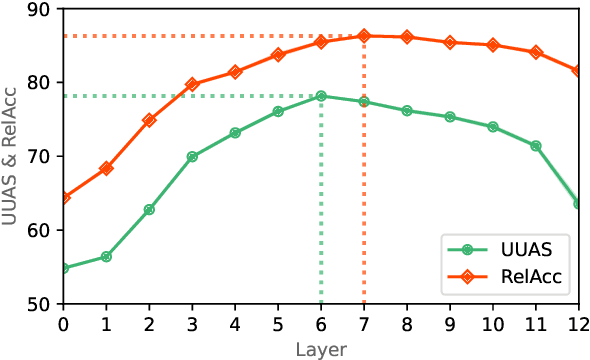
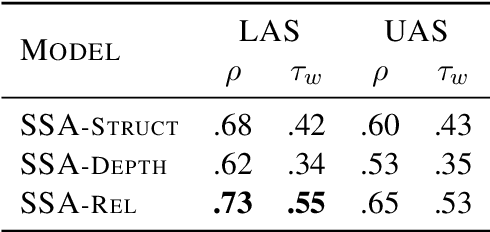
Probing has become an important tool for analyzing representations in Natural Language Processing (NLP). For graphical NLP tasks such as dependency parsing, linear probes are currently limited to extracting undirected or unlabeled parse trees which do not capture the full task. This work introduces DepProbe, a linear probe which can extract labeled and directed dependency parse trees from embeddings while using fewer parameters and compute than prior methods. Leveraging its full task coverage and lightweight parametrization, we investigate its predictive power for selecting the best transfer language for training a full biaffine attention parser. Across 13 languages, our proposed method identifies the best source treebank 94% of the time, outperforming competitive baselines and prior work. Finally, we analyze the informativeness of task-specific subspaces in contextual embeddings as well as which benefits a full parser's non-linear parametrization provides.
Identifying the root cause of cable network problems with machine learning
Mar 15, 2022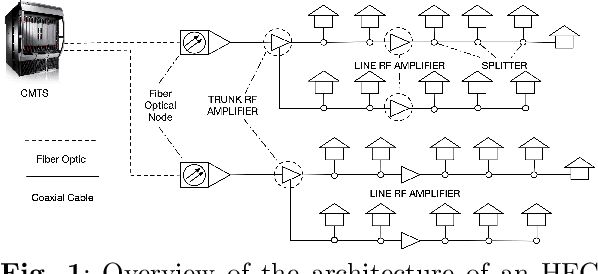
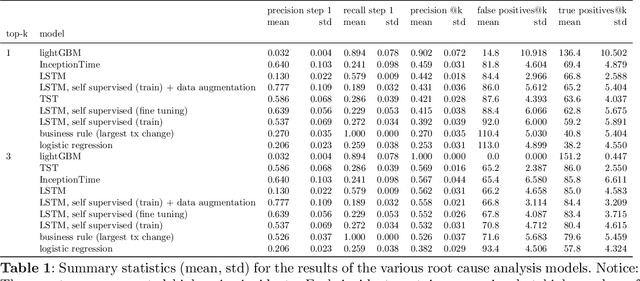
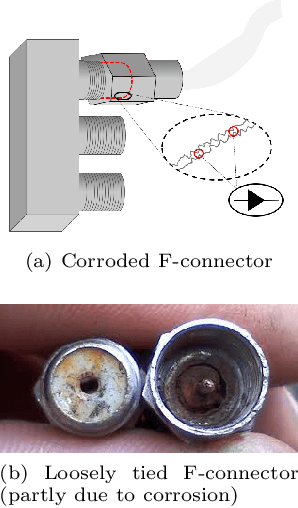
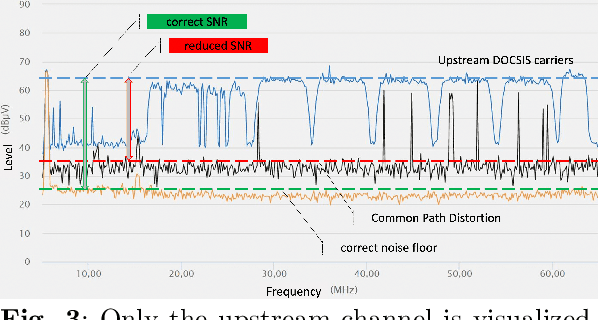
Good quality network connectivity is ever more important. For hybrid fiber coaxial (HFC) networks, searching for upstream high noise in the past was cumbersome and time-consuming. Even with machine learning due to the heterogeneity of the network and its topological structure, the task remains challenging. We present the automation of a simple business rule (largest change of a specific value) and compare its performance with state-of-the-art machine-learning methods and conclude that the precision@1 can be improved by 2.3 times. As it is best when a fault does not occur in the first place, we secondly evaluate multiple approaches to forecast network faults, which would allow performing predictive maintenance on the network.
TGCN: Time Domain Graph Convolutional Network for Multiple Objects Tracking
Jan 06, 2021

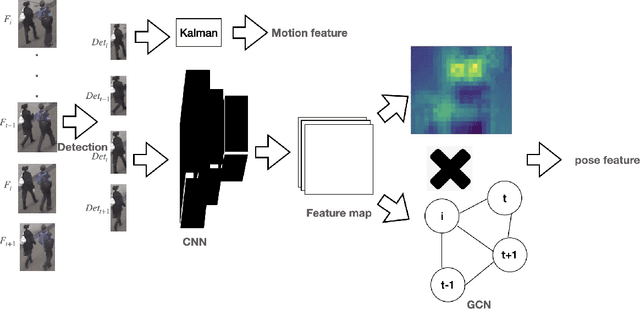

Multiple object tracking is to give each object an id in the video. The difficulty is how to match the predicted objects and detected objects in same frames. Matching features include appearance features, location features, etc. These features of the predicted object are basically based on some previous frames. However, few papers describe the relationship in the time domain between the previous frame features and the current frame features.In this paper, we proposed a time domain graph convolutional network for multiple objects tracking.The model is mainly divided into two parts, we first use convolutional neural network (CNN) to extract pedestrian appearance feature, which is a normal operation processing image in deep learning, then we use GCN to model some past frames' appearance feature to get the prediction appearance feature of the current frame. Due to this extension, we can get the pose features of the current frame according to the relationship between some frames in the past. Experimental evaluation shows that our extensions improve the MOTA by 1.3 on the MOT16, achieving overall competitive performance at high frame rates.
ACuTE: Automatic Curriculum Transfer from Simple to Complex Environments
Apr 11, 2022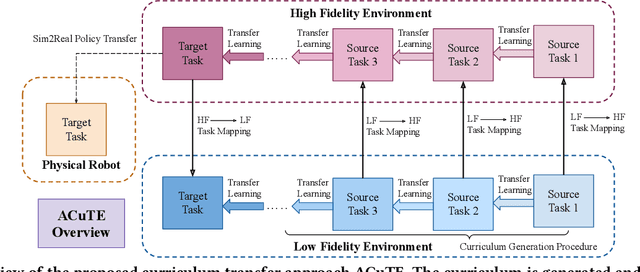
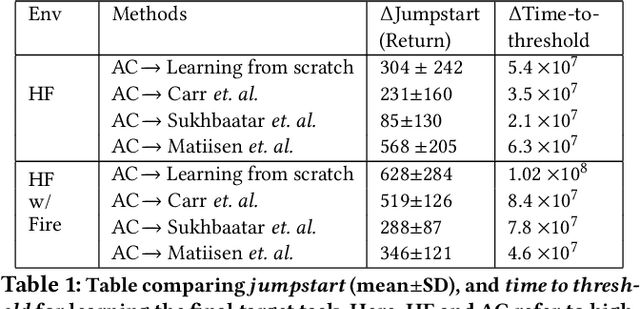
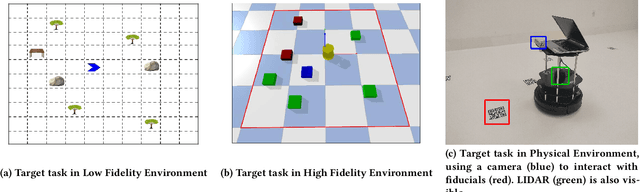
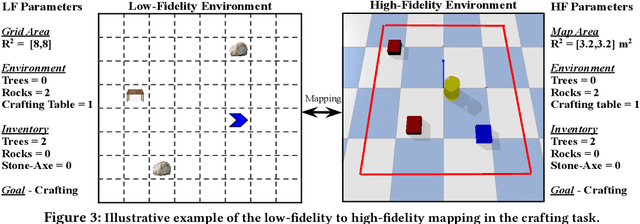
Despite recent advances in Reinforcement Learning (RL), many problems, especially real-world tasks, remain prohibitively expensive to learn. To address this issue, several lines of research have explored how tasks, or data samples themselves, can be sequenced into a curriculum to learn a problem that may otherwise be too difficult to learn from scratch. However, generating and optimizing a curriculum in a realistic scenario still requires extensive interactions with the environment. To address this challenge, we formulate the curriculum transfer problem, in which the schema of a curriculum optimized in a simpler, easy-to-solve environment (e.g., a grid world) is transferred to a complex, realistic scenario (e.g., a physics-based robotics simulation or the real world). We present "ACuTE", Automatic Curriculum Transfer from Simple to Complex Environments, a novel framework to solve this problem, and evaluate our proposed method by comparing it to other baseline approaches (e.g., domain adaptation) designed to speed up learning. We observe that our approach produces improved jumpstart and time-to-threshold performance even when adding task elements that further increase the difficulty of the realistic scenario. Finally, we demonstrate that our approach is independent of the learning algorithm used for curriculum generation, and is Sim2Real transferable to a real world scenario using a physical robot.
Cross-Modality High-Frequency Transformer for MR Image Super-Resolution
Mar 29, 2022
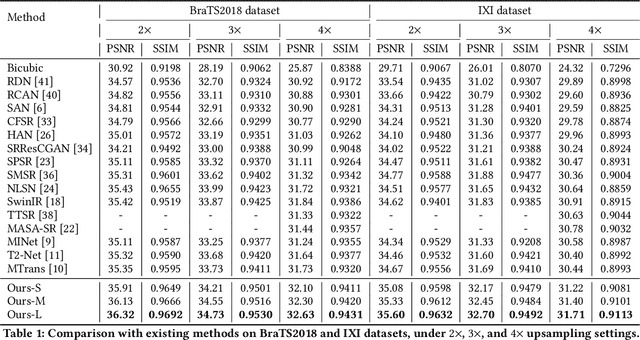
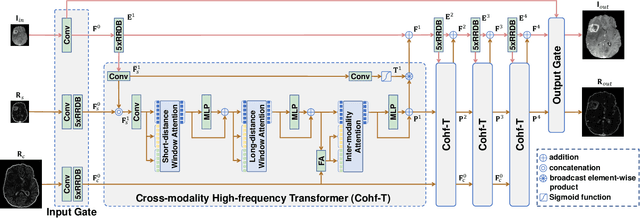
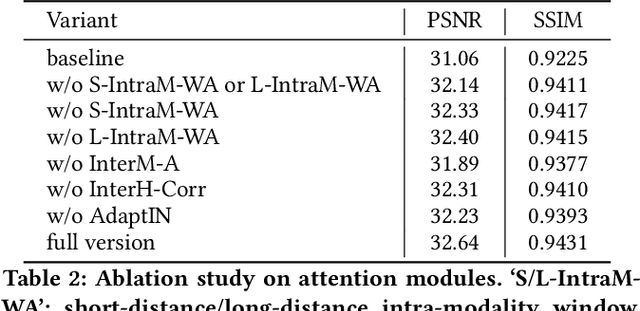
Improving the resolution of magnetic resonance (MR) image data is critical to computer-aided diagnosis and brain function analysis. Higher resolution helps to capture more detailed content, but typically induces to lower signal-to-noise ratio and longer scanning time. To this end, MR image super-resolution has become a widely-interested topic in recent times. Existing works establish extensive deep models with the conventional architectures based on convolutional neural networks (CNN). In this work, to further advance this research field, we make an early effort to build a Transformer-based MR image super-resolution framework, with careful designs on exploring valuable domain prior knowledge. Specifically, we consider two-fold domain priors including the high-frequency structure prior and the inter-modality context prior, and establish a novel Transformer architecture, called Cross-modality high-frequency Transformer (Cohf-T), to introduce such priors into super-resolving the low-resolution (LR) MR images. Comprehensive experiments on two datasets indicate that Cohf-T achieves new state-of-the-art performance.
Accurate Molecular-Orbital-Based Machine Learning Energies via Unsupervised Clustering of Chemical Space
Apr 21, 2022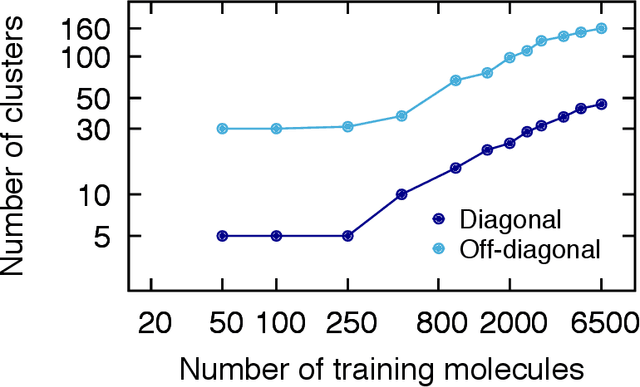
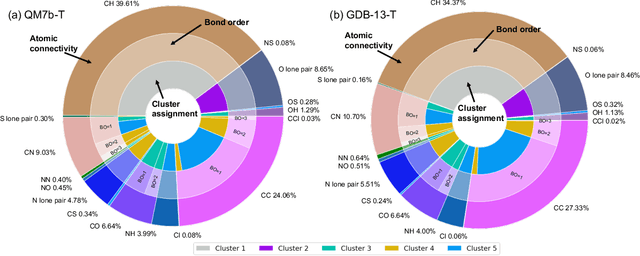
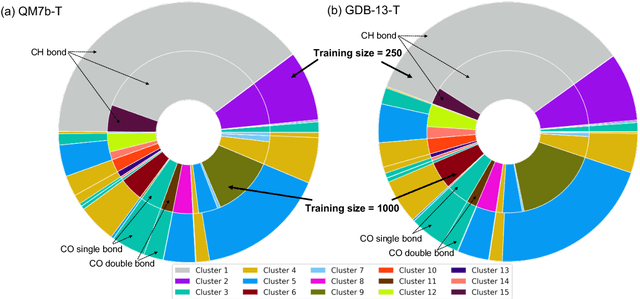
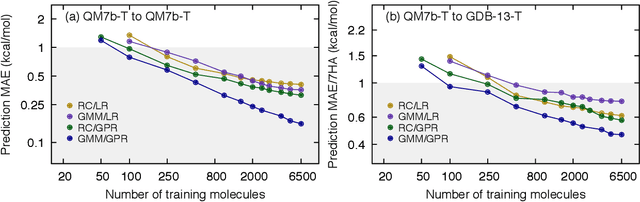
We introduce an unsupervised clustering algorithm to improve training efficiency and accuracy in predicting energies using molecular-orbital-based machine learning (MOB-ML). This work determines clusters via the Gaussian mixture model (GMM) in an entirely automatic manner and simplifies an earlier supervised clustering approach [J. Chem. Theory Comput., 15, 6668 (2019)] by eliminating both the necessity for user-specified parameters and the training of an additional classifier. Unsupervised clustering results from GMM have the advantage of accurately reproducing chemically intuitive groupings of frontier molecular orbitals and having improved performance with an increasing number of training examples. The resulting clusters from supervised or unsupervised clustering is further combined with scalable Gaussian process regression (GPR) or linear regression (LR) to learn molecular energies accurately by generating a local regression model in each cluster. Among all four combinations of regressors and clustering methods, GMM combined with scalable exact Gaussian process regression (GMM/GPR) is the most efficient training protocol for MOB-ML. The numerical tests of molecular energy learning on thermalized datasets of drug-like molecules demonstrate the improved accuracy, transferability, and learning efficiency of GMM/GPR over not only other training protocols for MOB-ML, i.e., supervised regression-clustering combined with GPR(RC/GPR) and GPR without clustering. GMM/GPR also provide the best molecular energy predictions compared with the ones from literature on the same benchmark datasets. With a lower scaling, GMM/GPR has a 10.4-fold speedup in wall-clock training time compared with scalable exact GPR with a training size of 6500 QM7b-T molecules.
Phase Retrieval for Radar Waveform Design
Jan 27, 2022The ability of a radar to discriminate in both range and Doppler velocity is completely characterized by the ambiguity function (AF) of its transmit waveform. Mathematically, it is obtained by correlating the waveform with its Doppler-shifted and delayed replicas. We consider the inverse problem of designing a radar transmit waveform that satisfies the specified AF magnitude. This process can be viewed as a signal reconstruction with some variation of phase retrieval methods. We provide a trust-region algorithm that minimizes a smoothed non-convex least-squares objective function to iteratively recover the underlying signal-of-interest for either time- or band-limited support. The method first approximates the signal using an iterative spectral algorithm and then refines the attained initialization based upon a sequence of gradient iterations. Our theoretical analysis shows that unique signal reconstruction is possible using signal samples no more than thrice the number of signal frequencies or time samples. Numerical experiments demonstrate that our method recovers both time- and band-limited signals from even sparsely and randomly sampled AFs with mean-square-error of $1\times 10^{-6}$ and $9\times 10^{-2}$ for the full noiseless samples and sparse noisy samples, respectively.
An Algorithm for the Labeling and Interactive Visualization of the Cerebrovascular System of Ischemic Strokes
Apr 26, 2022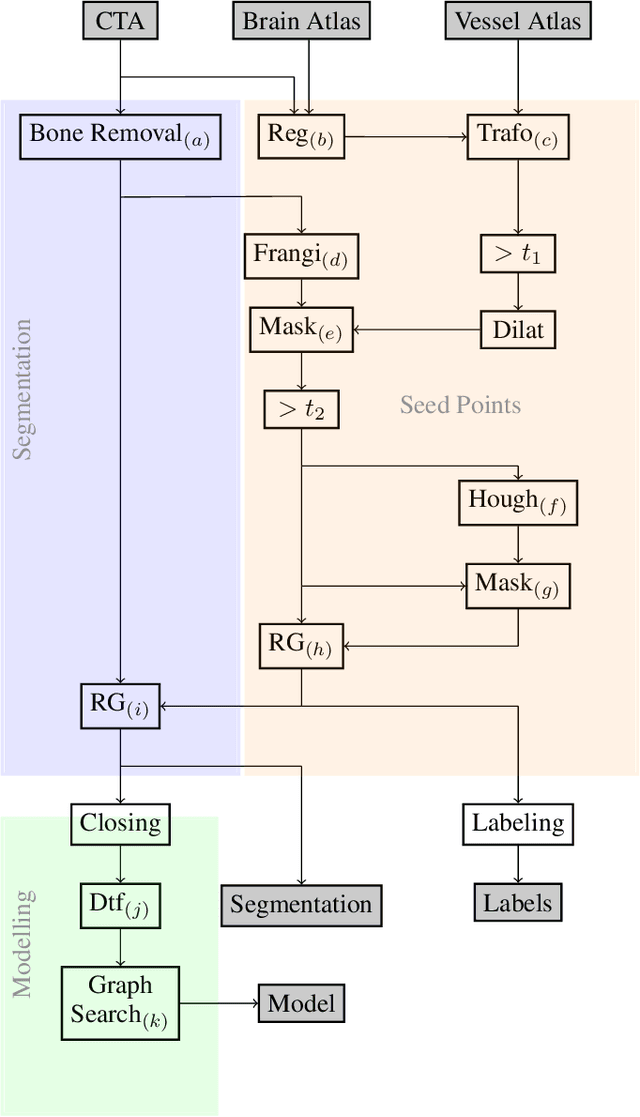
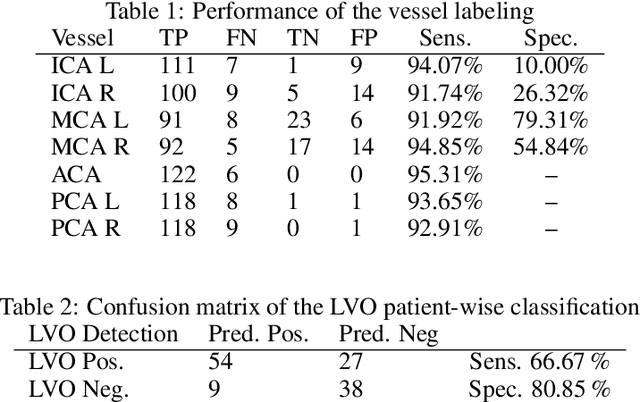
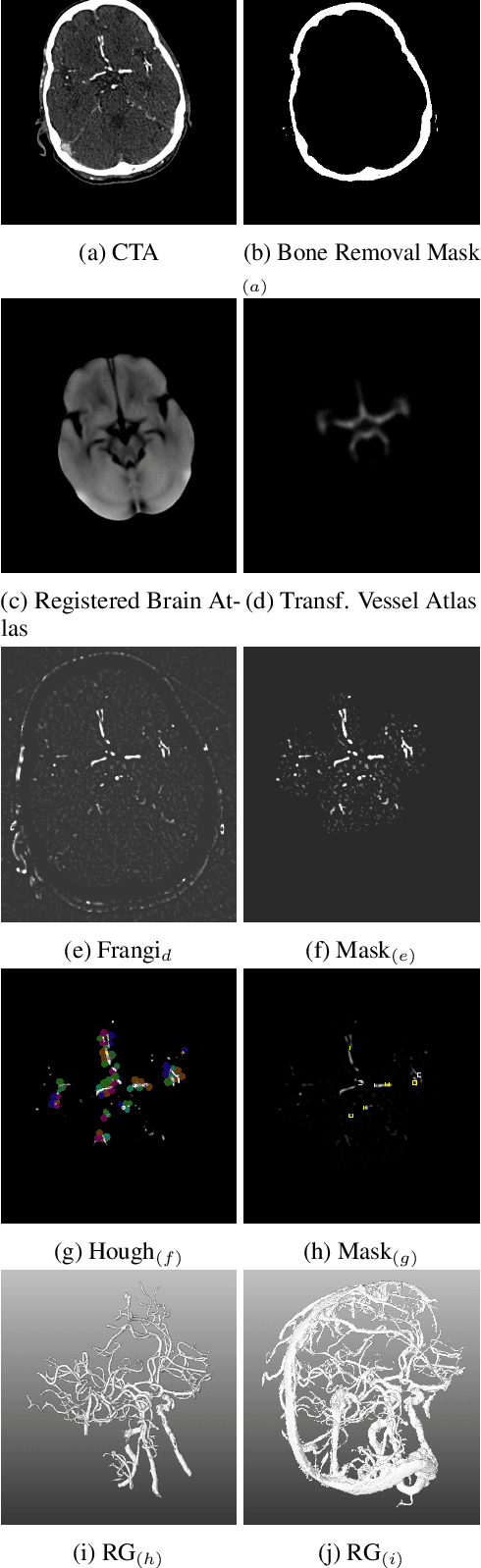
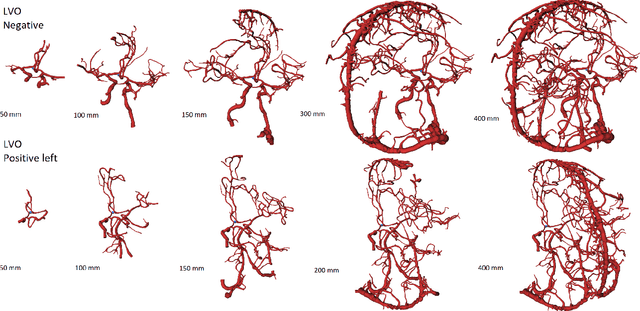
During the diagnosis of ischemic strokes, the Circle of Willis and its surrounding vessels are the arteries of interest. Their visualization in case of an acute stroke is often enabled by Computed Tomography Angiography (CTA). Still, the identification and analysis of the cerebral arteries remain time consuming in such scans due to a large number of peripheral vessels which may disturb the visual impression. In previous work we proposed VirtualDSA++, an algorithm designed to segment and label the cerebrovascular tree on CTA scans. Especially with stroke patients, labeling is a delicate procedure, as in the worst case whole hemispheres may not be present due to impeded perfusion. Hence, we extended the labeling mechanism for the cerebral arteries to identify occluded vessels. In the work at hand, we place the algorithm in a clinical context by evaluating the labeling and occlusion detection on stroke patients, where we have achieved labeling sensitivities comparable to other works between 92\,\% and 95\,\%. To the best of our knowledge, ours is the first work to address labeling and occlusion detection at once, whereby a sensitivity of 67\,\% and a specificity of 81\,\% were obtained for the latter. VirtualDSA++ also automatically segments and models the intracranial system, which we further used in a deep learning driven follow up work. We present the generic concept of iterative systematic search for pathways on all nodes of said model, which enables new interactive features. Exemplary, we derive in detail, firstly, the interactive planning of vascular interventions like the mechanical thrombectomy and secondly, the interactive suppression of vessel structures that are not of interest in diagnosing strokes (like veins). We discuss both features as well as further possibilities emerging from the proposed concept.