 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reinforcement Learning Policy Recommendation for Interbank Network Stability
Apr 14, 2022
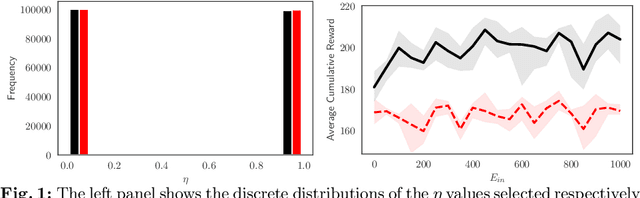
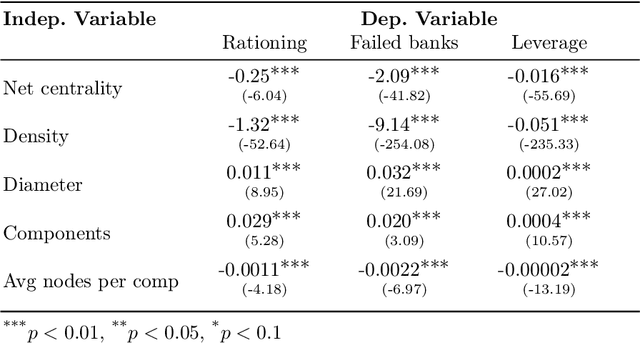
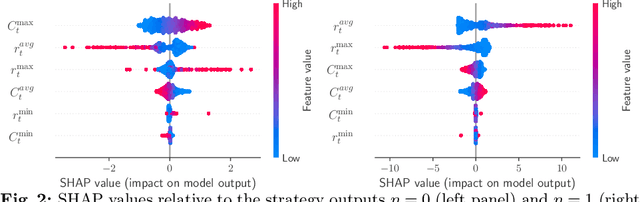
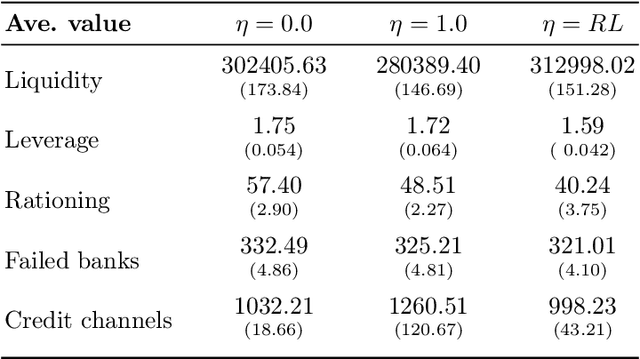
In this paper we analyze the effect of a policy recommendation on the performances of an artificial interbank market. Financial institutions stipulate lending agreements following a public recommendation and their individual information. The former, modeled by a reinforcement learning optimal policy trying to maximize the long term fitness of the system, gathers information on the economic environment and directs economic actors to create credit relationships based on the optimal choice between a low interest rate or high liquidity supply. The latter, based on the agents' balance sheet, allows to determine the liquidity supply and interest rate that the banks optimally offer on the market. Based on the combination between the public and the private signal, financial institutions create or cut their credit connections over time via a preferential attachment evolving procedure able to generate a dynamic network. Our results show that the emergence of a core-periphery interbank network, combined with a certain level of homogeneity on the size of lenders and borrowers, are essential features to ensure the resilience of the system. Moreover, the reinforcement learning optimal policy recommendation plays a crucial role in mitigating systemic risk with respect to alternative policy instruments.
Bayesian dense inverse searching algorithm for real-time stereo matching in minimally invasive surgery
Jun 14, 2021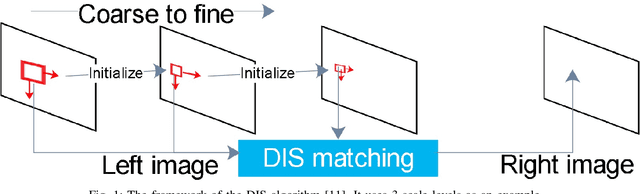
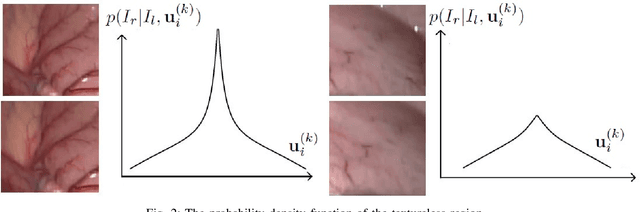
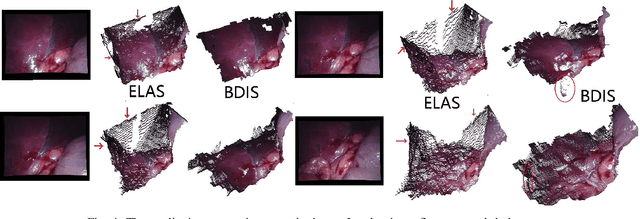

This paper reports a CPU-level real-time stereo matching method for surgical images (10 Hz on 640 * 480 image with a single core of i5-9400). The proposed method is built on the fast ''dense inverse searching'' algorithm, which estimates the disparity of the stereo images. The overlapping image patches (arbitrary squared image segment) from the images at different scales are aligned based on the photometric consistency presumption. We propose a Bayesian framework to evaluate the probability of the optimized patch disparity at different scales. Moreover, we introduce a spatial Gaussian mixed probability distribution to address the pixel-wise probability within the patch. In-vivo and synthetic experiments show that our method can handle ambiguities resulted from the textureless surfaces and the photometric inconsistency caused by the Lambertian reflectance. Our Bayesian method correctly balances the probability of the patch for stereo images at different scales. Experiments indicate that the estimated depth has higher accuracy and fewer outliers than the baseline methods in the surgical scenario.
Service resource allocation problem in the IoT driven personalized healthcare information platform
Apr 05, 2022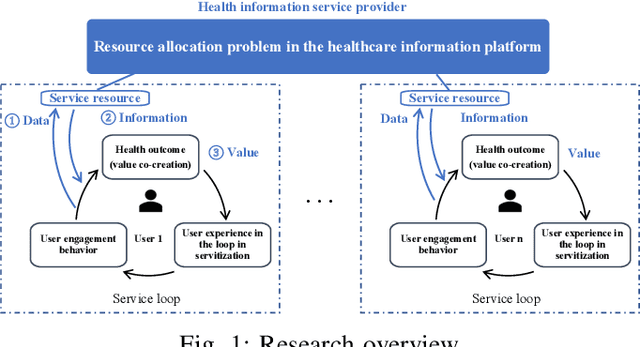
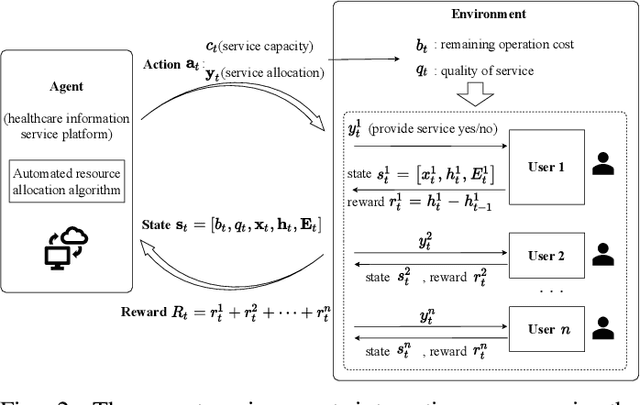
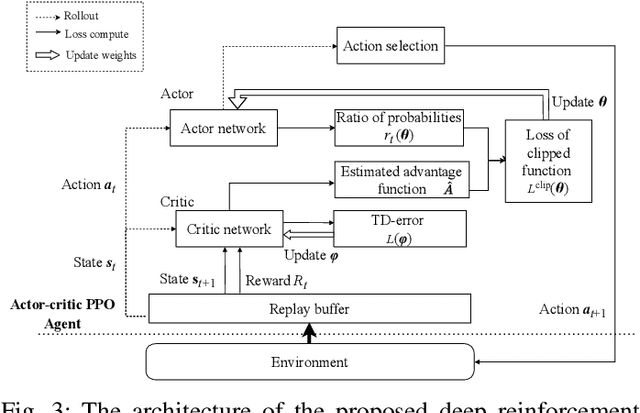
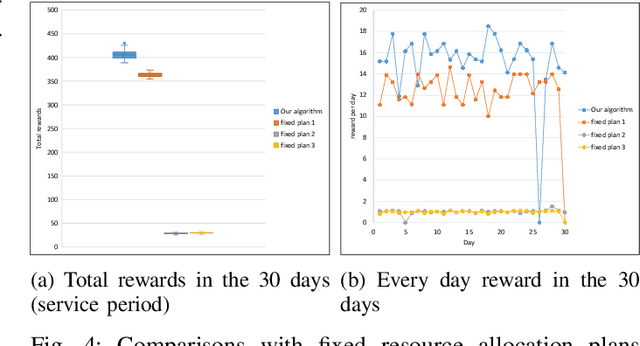
With real-time monitoring of the personalized healthcare condition, the IoT wearables collect the health data and transfer it to the healthcare information platform. The platform processes the data into healthcare recommendations and then delivers them to the users. The IoT structures in the personalized healthcare information service allows the users to engage in the loop in servitization more convenient in the COVID-19 pandemic. However, the uncertainty of the engagement behavior among the individual may result in inefficient of the service resource allocation. This paper seeks an efficient way to allocate the service resource by controlling the service capacity and pushing the service to the active users automatically. In this study, we propose a deep reinforcement learning method to solve the service resource allocation problem based on the proximal policy optimization (PPO) algorithm. Experimental results using the real world (open source) sport dataset reveal that our proposed proximal policy optimization adapts well to the users' changing behavior and with improved performance over fixed service resource policies.
Assessing Dataset Bias in Computer Vision
May 03, 2022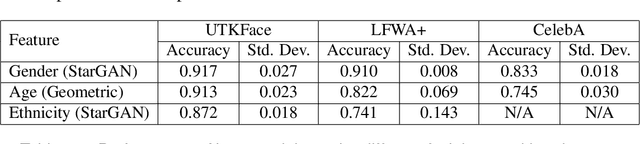

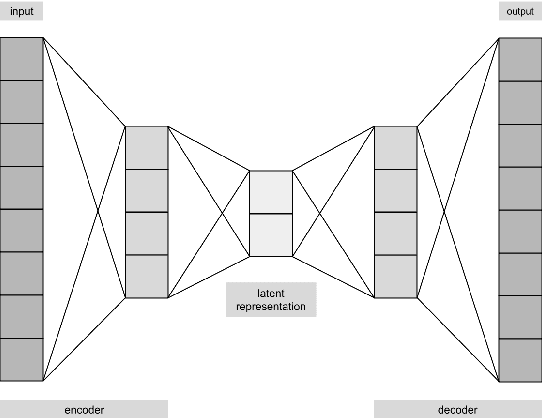
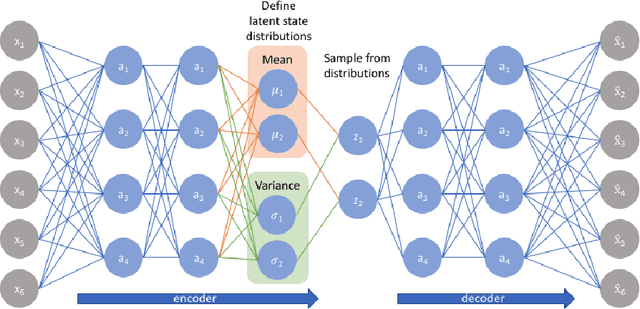
A biased dataset is a dataset that generally has attributes with an uneven class distribution. These biases have the tendency to propagate to the models that train on them, often leading to a poor performance in the minority class. In this project, we will explore the extent to which various data augmentation methods alleviate intrinsic biases within the dataset. We will apply several augmentation techniques on a sample of the UTKFace dataset, such as undersampling, geometric transformations, variational autoencoders (VAEs), and generative adversarial networks (GANs). We then trained a classifier for each of the augmented datasets and evaluated their performance on the native test set and on external facial recognition datasets. We have also compared their performance to the state-of-the-art attribute classifier trained on the FairFace dataset. Through experimentation, we were able to find that training the model on StarGAN-generated images led to the best overall performance. We also found that training on geometrically transformed images lead to a similar performance with a much quicker training time. Additionally, the best performing models also exhibit a uniform performance across the classes within each attribute. This signifies that the model was also able to mitigate the biases present in the baseline model that was trained on the original training set. Finally, we were able to show that our model has a better overall performance and consistency on age and ethnicity classification on multiple datasets when compared with the FairFace model. Our final model has an accuracy on the UTKFace test set of 91.75%, 91.30%, and 87.20% for the gender, age, and ethnicity attribute respectively, with a standard deviation of less than 0.1 between the accuracies of the classes of each attribute.
On the Acquisition of Stationary Signals Using Uniform ADCs
Feb 10, 2022
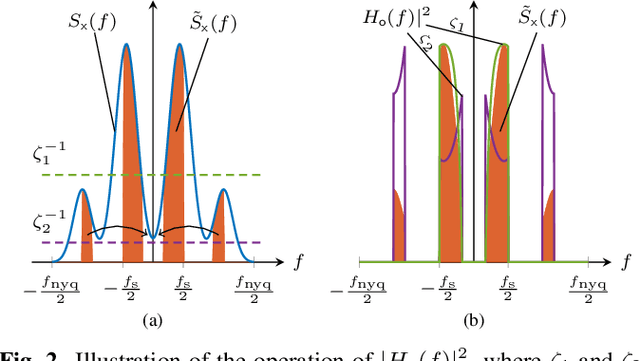
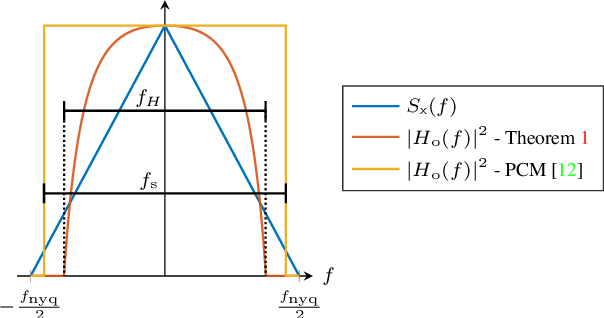
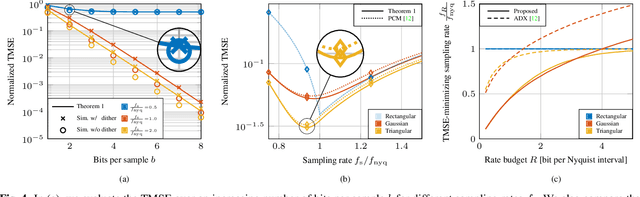
In this work, we consider the acquisition of stationary signals using uniform analog-to-digital converters (ADCs), i.e., employing uniform sampling and scalar uniform quantization. We jointly optimize the pre-sampling and reconstruction filters to minimize the time-averaged mean-squared error (TMSE) in recovering the continuous-time input signal for a fixed sampling rate and quantizer resolution and obtain closed-form expressions for the minimal achievable TMSE. We show that the TMSE-minimizing pre-sampling filter omits aliasing and discards weak frequency components to resolve the remaining ones with higher resolution when the rate budget is small. In our numerical study, we validate our results and show that sub-Nyquist sampling often minimizes the TMSE under tight rate budgets at the output of the ADC.
Improving Makespan in Dynamic Task Allocation for Cloud Robotic Systems with Time Window Constraints
Dec 07, 2020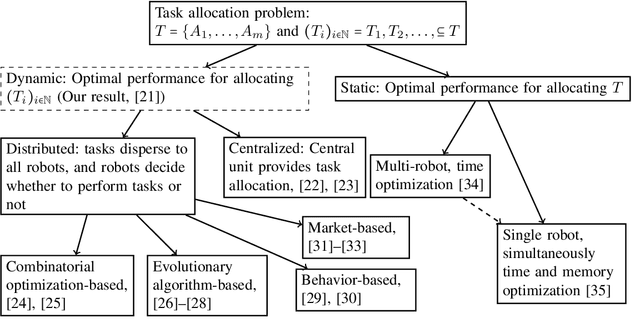
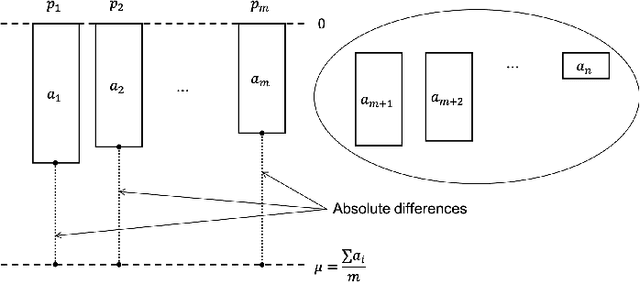
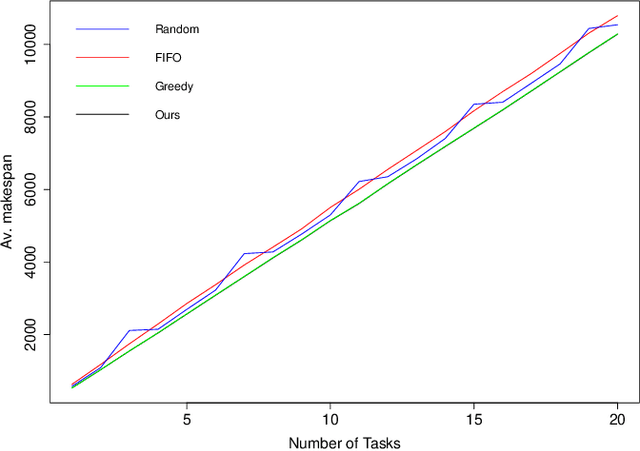
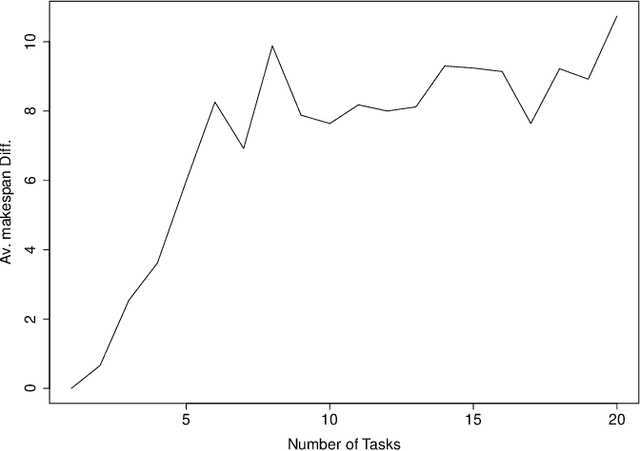
A scheduling method in a robotic network cloud system with minimal makespan is beneficiary in the sense that the system can complete all of its assigned tasks in the fastest way. Robotic network cloud systems can be translated into graphs, with nodes representing hardware with independent computational processing power and edges as data transmissions between nodes. Tasks time windows constraints are a natural way of ordering the tasks. The makespan is the maximum time duration from the time that a node starts to perform its first scheduled task to the time that all the nodes complete their final scheduled tasks. The load balancing scheduling ensures that the time windows from the time that the first node completes its final scheduled tasks to the time that all the other nodes complete their final scheduled tasks are as narrow as possible. We propose a new load balancing algorithm for task scheduling such that the makespan is minimal. We prove the correctness of the proposed algorithm and present simulations illustrating the obtained results.
A Simple Approach to Improve Single-Model Deep Uncertainty via Distance-Awareness
May 01, 2022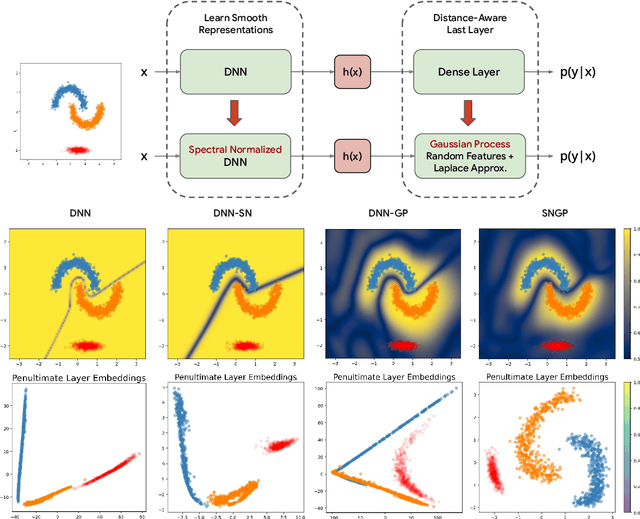
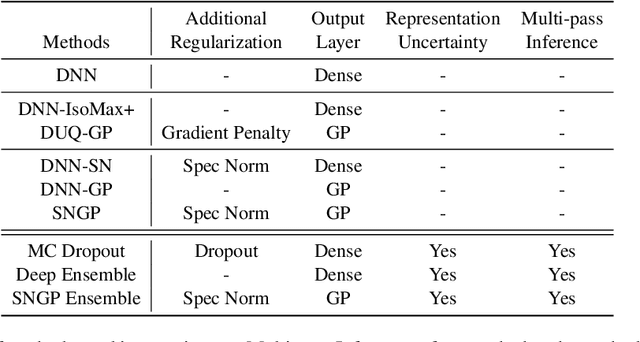
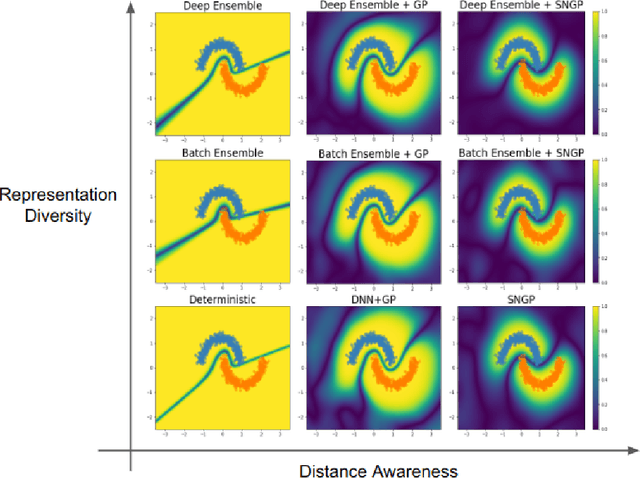
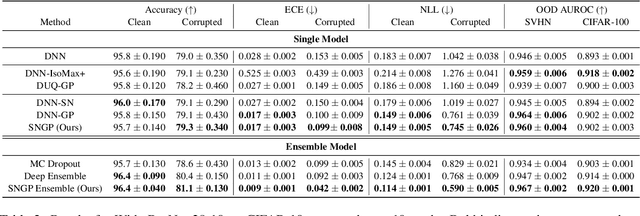
Accurate uncertainty quantification is a major challenge in deep learning, as neural networks can make overconfident errors and assign high confidence predictions to out-of-distribution (OOD) inputs. The most popular approaches to estimate predictive uncertainty in deep learning are methods that combine predictions from multiple neural networks, such as Bayesian neural networks (BNNs) and deep ensembles. However their practicality in real-time, industrial-scale applications are limited due to the high memory and computational cost. Furthermore, ensembles and BNNs do not necessarily fix all the issues with the underlying member networks. In this work, we study principled approaches to improve uncertainty property of a single network, based on a single, deterministic representation. By formalizing the uncertainty quantification as a minimax learning problem, we first identify distance awareness, i.e., the model's ability to quantify the distance of a testing example from the training data, as a necessary condition for a DNN to achieve high-quality (i.e., minimax optimal) uncertainty estimation. We then propose Spectral-normalized Neural Gaussian Process (SNGP), a simple method that improves the distance-awareness ability of modern DNNs with two simple changes: (1) applying spectral normalization to hidden weights to enforce bi-Lipschitz smoothness in representations and (2) replacing the last output layer with a Gaussian process layer. On a suite of vision and language understanding benchmarks, SNGP outperforms other single-model approaches in prediction, calibration and out-of-domain detection. Furthermore, SNGP provides complementary benefits to popular techniques such as deep ensembles and data augmentation, making it a simple and scalable building block for probabilistic deep learning. Code is open-sourced at https://github.com/google/uncertainty-baselines
Lightweight Multi-Drone Detection and 3D-Localization via YOLO
Feb 18, 2022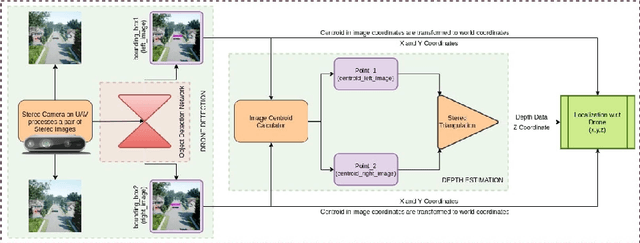
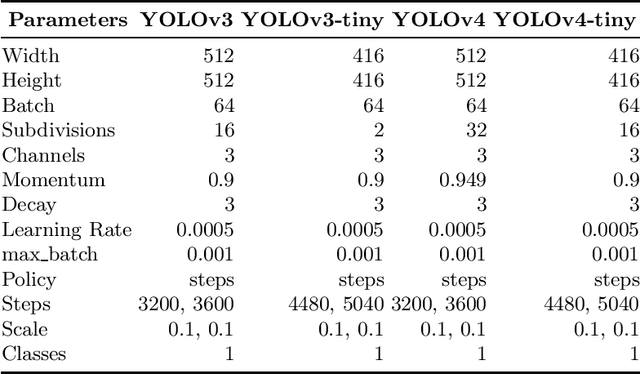
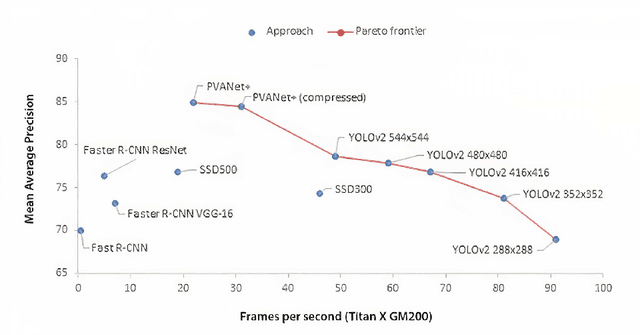
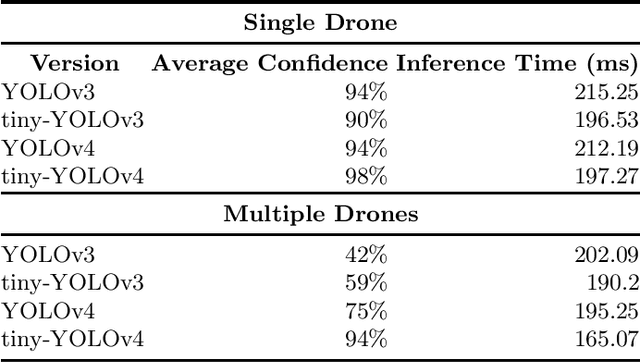
In this work, we present and evaluate a method to perform real-time multiple drone detection and three-dimensional localization using state-of-the-art tiny-YOLOv4 object detection algorithm and stereo triangulation. Our computer vision approach eliminates the need for computationally expensive stereo matching algorithms, thereby significantly reducing the memory footprint and making it deployable on embedded systems. Our drone detection system is highly modular (with support for various detection algorithms) and capable of identifying multiple drones in a system, with real-time detection accuracy of up to 77\% with an average FPS of 332 (on Nvidia Titan Xp). We also test the complete pipeline in AirSim environment, detecting drones at a maximum distance of 8 meters, with a mean error of $23\%$ of the distance. We also release the source code for the project, with pre-trained models and the curated synthetic stereo dataset.
Factual Error Correction for Abstractive Summaries Using Entity Retrieval
Apr 18, 2022
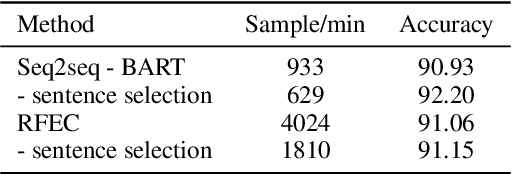
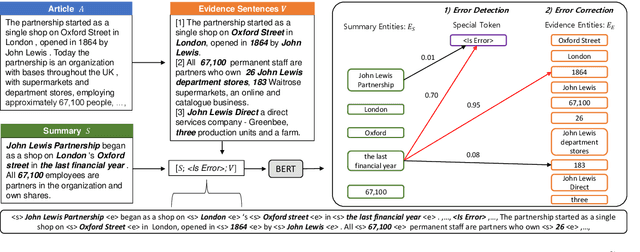
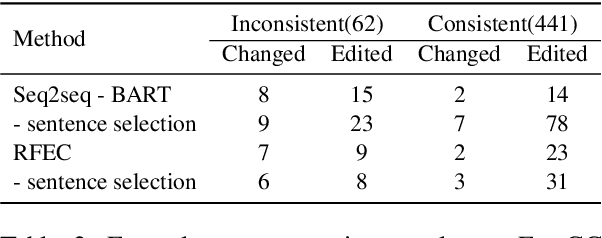
Despite the recent advancements in abstractive summarization systems leveraged from large-scale datasets and pre-trained language models, the factual correctness of the summary is still insufficient. One line of trials to mitigate this problem is to include a post-editing process that can detect and correct factual errors in the summary. In building such a post-editing system, it is strongly required that 1) the process has a high success rate and interpretability and 2) has a fast running time. Previous approaches focus on regeneration of the summary using the autoregressive models, which lack interpretability and require high computing resources. In this paper, we propose an efficient factual error correction system RFEC based on entities retrieval post-editing process. RFEC first retrieves the evidence sentences from the original document by comparing the sentences with the target summary. This approach greatly reduces the length of text for a system to analyze. Next, RFEC detects the entity-level errors in the summaries by considering the evidence sentences and substitutes the wrong entities with the accurate entities from the evidence sentences. Experimental results show that our proposed error correction system shows more competitive performance than baseline methods in correcting the factual errors with a much faster speed.
Asyncval: A Toolkit for Asynchronously Validating Dense Retriever Checkpoints during Training
Feb 25, 2022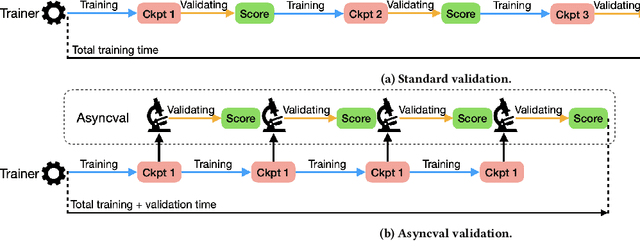
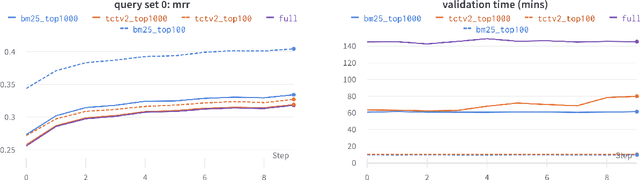
The process of model checkpoint validation refers to the evaluation of the performance of a model checkpoint executed on a held-out portion of the training data while learning the hyperparameters of the model, and is used to avoid over-fitting and determine when the model has converged so as to stop training. A simple and efficient strategy to validate deep learning checkpoints is the addition of validation loops to execute during training. However, the validation of dense retrievers (DR) checkpoints is not as trivial -- and the addition of validation loops is not efficient. This is because, in order to accurately evaluate the performance of a DR checkpoint, the whole document corpus needs to be encoded into vectors using the current checkpoint before any actual retrieval operation for checkpoint validation can be performed. This corpus encoding process can be very time-consuming if the document corpus contains millions of documents (e.g., 8.8m for MS MARCO and 21m for Natural Questions). Thus, a naive use of validation loops during training will significantly increase training time. To address this issue, in this demo paper, we propose Asyncval: a Python-based toolkit for efficiently validating DR checkpoints during training. Instead of pausing the training loop for validating DR checkpoints, Asyncval decouples the validation loop from the training loop, uses another GPU to automatically validate new DR checkpoints and thus permits to perform validation asynchronously from training. Asyncval also implements a range of different corpus subset sampling strategies for validating DR checkpoints; these strategies allow to further speed up the validation process. We provide an investigation of these methods in terms of their impact on validation time and validation fidelity. Asyncval is made available as an open-source project at \url{https://github.com/ielab/asyncval}.