 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A System for Interactive Examination of Learned Security Policies
Apr 03, 2022
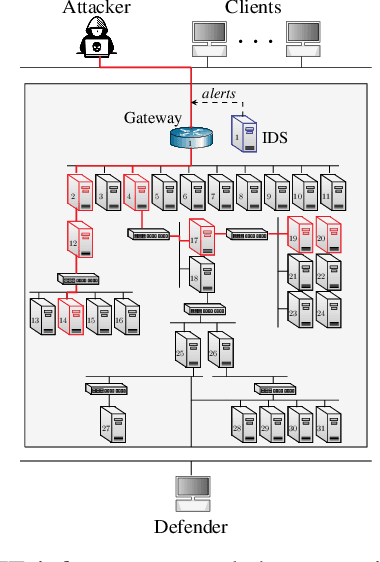
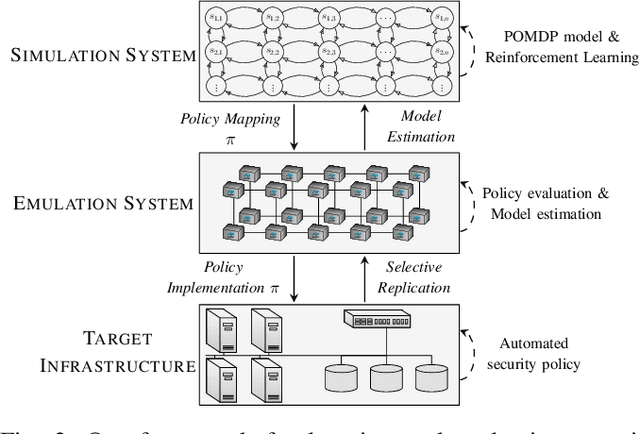
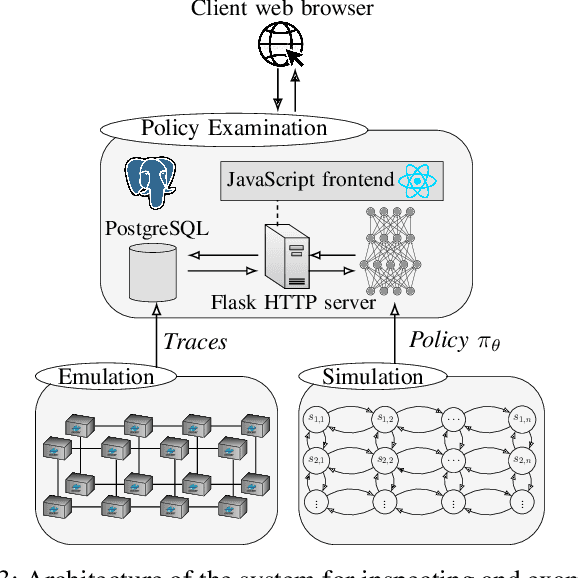
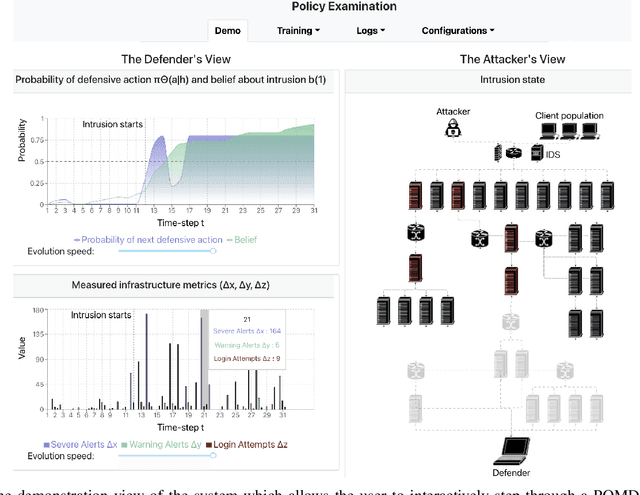
We present a system for interactive examination of learned security policies. It allows a user to traverse episodes of Markov decision processes in a controlled manner and to track the actions triggered by security policies. Similar to a software debugger, a user can continue or or halt an episode at any time step and inspect parameters and probability distributions of interest. The system enables insight into the structure of a given policy and in the behavior of a policy in edge cases. We demonstrate the system with a network intrusion use case. We examine the evolution of an IT infrastructure's state and the actions prescribed by security policies while an attack occurs. The policies for the demonstration have been obtained through a reinforcement learning approach that includes a simulation system where policies are incrementally learned and an emulation system that produces statistics that drive the simulation runs.
Exploratory Hidden Markov Factor Models for Longitudinal Mobile Health Data: Application to Adverse Posttraumatic Neuropsychiatric Sequelae
Feb 25, 2022
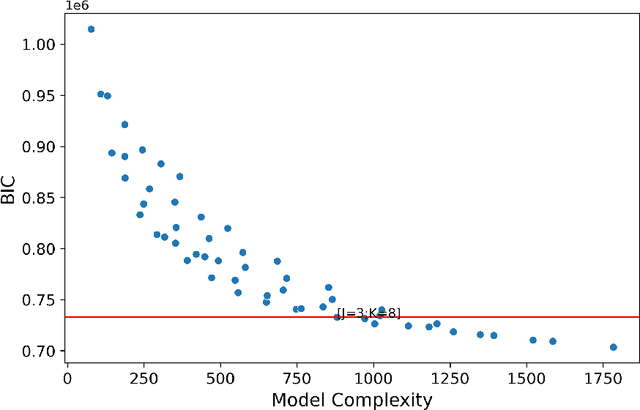
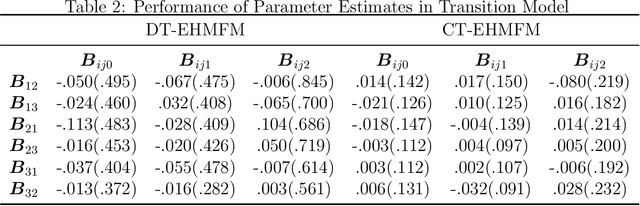
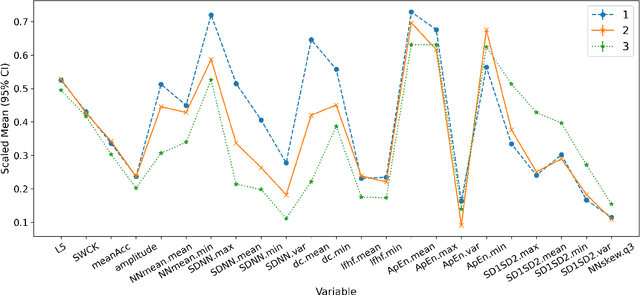
Adverse posttraumatic neuropsychiatric sequelae (APNS) are common among veterans and millions of Americans after traumatic events and cause tremendous burdens for trauma survivors and society. Many studies have been conducted to investigate the challenges in diagnosing and treating APNS symptoms. However, progress has been limited by the subjective nature of traditional measures. This study is motivated by the objective mobile device data collected from the Advancing Understanding of RecOvery afteR traumA (AURORA) study. We develop both discrete-time and continuous-time exploratory hidden Markov factor models to model the dynamic psychological conditions of individuals with either regular or irregular measurements. The proposed models extend the conventional hidden Markov models to allow high-dimensional data and feature-based nonhomogeneous transition probability between hidden psychological states. To find the maximum likelihood estimates, we develop a Stabilized Expectation-Maximization algorithm with Initialization Strategies (SEMIS). Simulation studies with synthetic data are carried out to assess the performance of parameter estimation and model selection. Finally, an application to the AURORA data is conducted, which captures the relationships between heart rate variability, activity, and APNS consistent with existing literature.
Automated Model Selection for Time-Series Anomaly Detection
Aug 25, 2020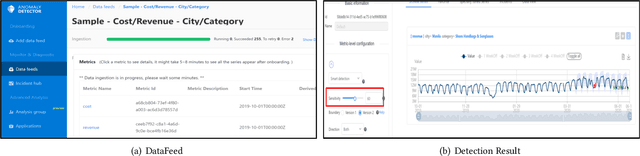
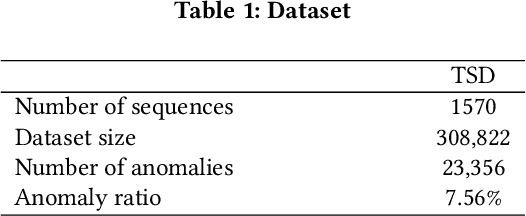
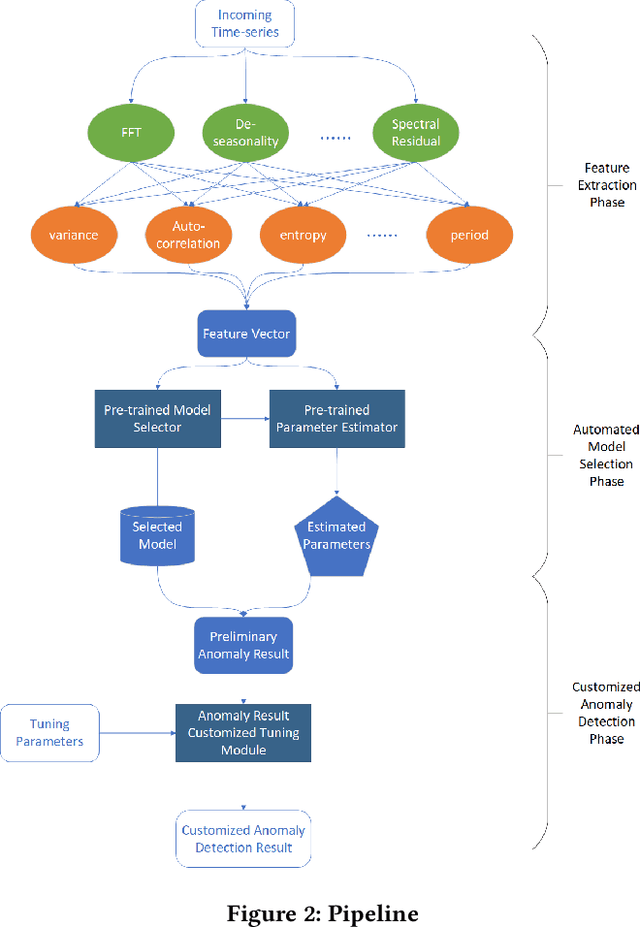
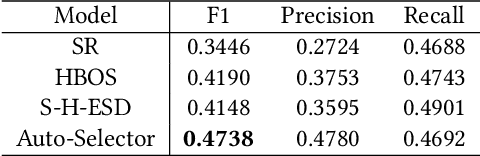
Time-series anomaly detection is a popular topic in both academia and industrial fields. Many companies need to monitor thousands of temporal signals for their applications and services and require instant feedback and alerts for potential incidents in time. The task is challenging because of the complex characteristics of time-series, which are messy, stochastic, and often without proper labels. This prohibits training supervised models because of lack of labels and a single model hardly fits different time series. In this paper, we propose a solution to address these issues. We present an automated model selection framework to automatically find the most suitable detection model with proper parameters for the incoming data. The model selection layer is extensible as it can be updated without too much effort when a new detector is available to the service. Finally, we incorporate a customized tuning algorithm to flexibly filter anomalies to meet customers' criteria. Experiments on real-world datasets show the effectiveness of our solution.
L3Cube-HingCorpus and HingBERT: A Code Mixed Hindi-English Dataset and BERT Language Models
Apr 18, 2022
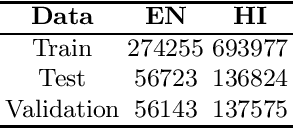

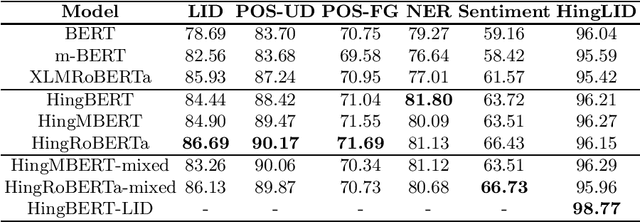
Code-switching occurs when more than one language is mixed in a given sentence or a conversation. This phenomenon is more prominent on social media platforms and its adoption is increasing over time. Therefore code-mixed NLP has been extensively studied in the literature. As pre-trained transformer-based architectures are gaining popularity, we observe that real code-mixing data are scarce to pre-train large language models. We present L3Cube-HingCorpus, the first large-scale real Hindi-English code mixed data in a Roman script. It consists of 52.93M sentences and 1.04B tokens, scraped from Twitter. We further present HingBERT, HingMBERT, HingRoBERTa, and HingGPT. The BERT models have been pre-trained on codemixed HingCorpus using masked language modelling objectives. We show the effectiveness of these BERT models on the subsequent downstream tasks like code-mixed sentiment analysis, POS tagging, NER, and LID from the GLUECoS benchmark. The HingGPT is a GPT2 based generative transformer model capable of generating full tweets. We also release L3Cube-HingLID Corpus, the largest code-mixed Hindi-English language identification(LID) dataset and HingBERT-LID, a production-quality LID model to facilitate capturing of more code-mixed data using the process outlined in this work. The dataset and models are available at https://github.com/l3cube-pune/code-mixed-nlp .
MIPR:Automatic Annotation of Medical Images with Pixel Rearrangement
Apr 22, 2022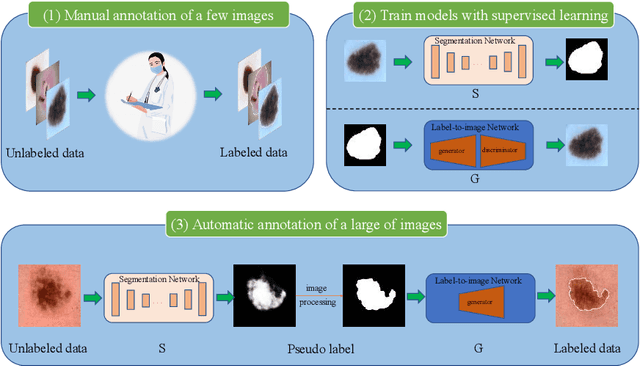
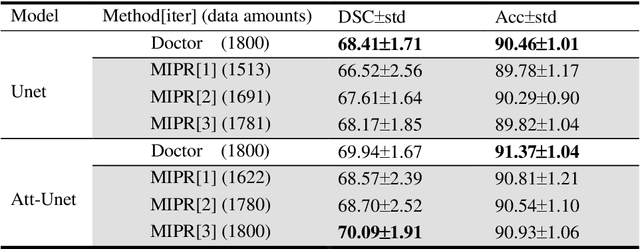
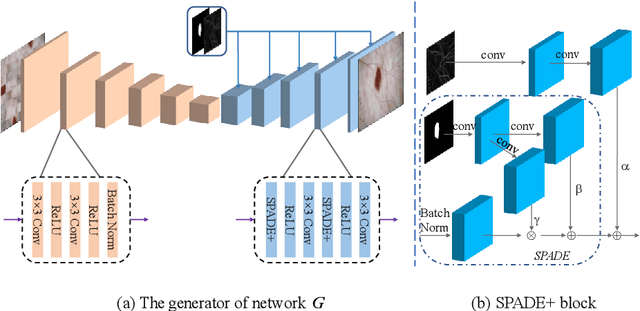
Most of the state-of-the-art semantic segmentation reported in recent years is based on fully supervised deep learning in the medical domain. How?ever, the high-quality annotated datasets require intense labor and domain knowledge, consuming enormous time and cost. Previous works that adopt semi?supervised and unsupervised learning are proposed to address the lack of anno?tated data through assisted training with unlabeled data and achieve good perfor?mance. Still, these methods can not directly get the image annotation as doctors do. In this paper, inspired by self-training of semi-supervised learning, we pro?pose a novel approach to solve the lack of annotated data from another angle, called medical image pixel rearrangement (short in MIPR). The MIPR combines image-editing and pseudo-label technology to obtain labeled data. As the number of iterations increases, the edited image is similar to the original image, and the labeled result is similar to the doctor annotation. Therefore, the MIPR is to get labeled pairs of data directly from amounts of unlabled data with pixel rearrange?ment, which is implemented with a designed conditional Generative Adversarial Networks and a segmentation network. Experiments on the ISIC18 show that the effect of the data annotated by our method for segmentation task is is equal to or even better than that of doctors annotations
Mutation Sensitive Correlation Filter for Real-Time UAV Tracking with Adaptive Hybrid Label
Jun 15, 2021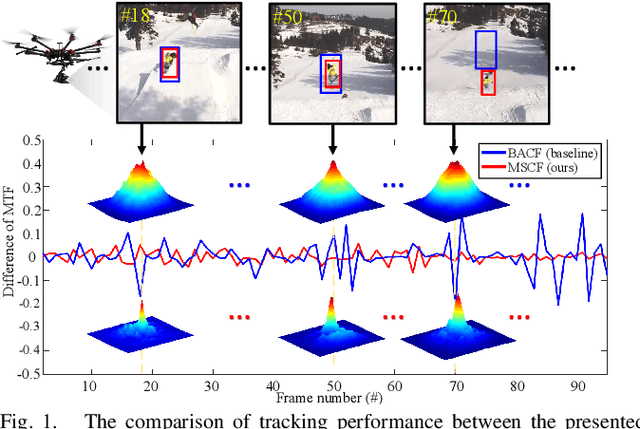
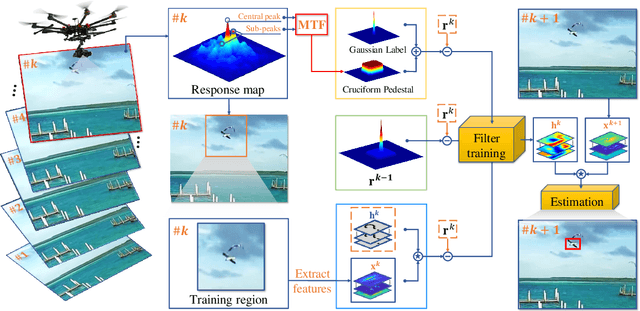
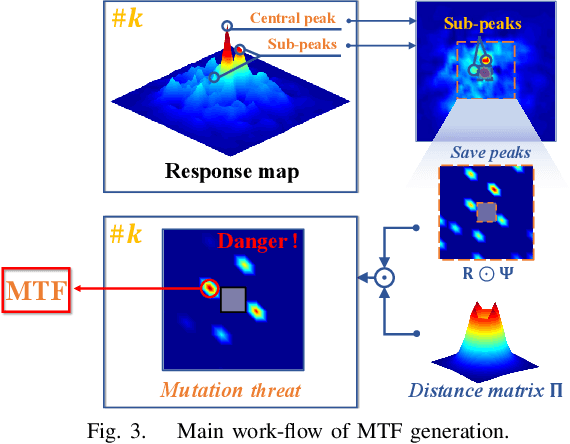
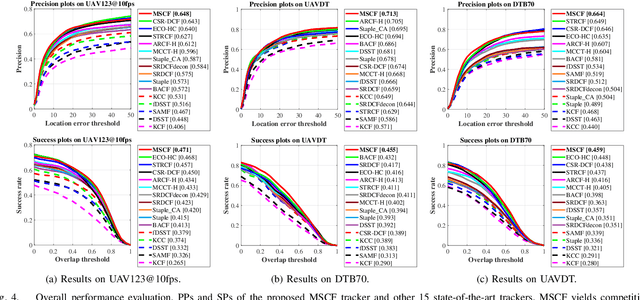
Unmanned aerial vehicle (UAV) based visual tracking has been confronted with numerous challenges, e.g., object motion and occlusion. These challenges generally introduce unexpected mutations of target appearance and result in tracking failure. However, prevalent discriminative correlation filter (DCF) based trackers are insensitive to target mutations due to a predefined label, which concentrates on merely the centre of the training region. Meanwhile, appearance mutations caused by occlusion or similar objects usually lead to the inevitable learning of wrong information. To cope with appearance mutations, this paper proposes a novel DCF-based method to enhance the sensitivity and resistance to mutations with an adaptive hybrid label, i.e., MSCF. The ideal label is optimized jointly with the correlation filter and remains temporal consistency. Besides, a novel measurement of mutations called mutation threat factor (MTF) is applied to correct the label dynamically. Considerable experiments are conducted on widely used UAV benchmarks. The results indicate that the performance of MSCF tracker surpasses other 26 state-of-the-art DCF-based and deep-based trackers. With a real-time speed of _38 frames/s, the proposed approach is sufficient for UAV tracking commissions.
Clean Implicit 3D Structure from Noisy 2D STEM Images
Mar 29, 2022
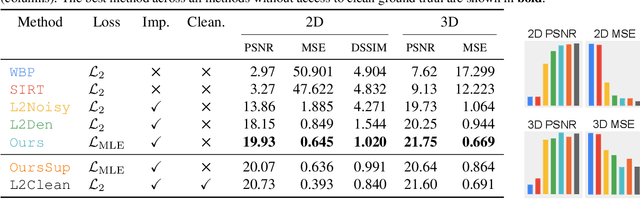
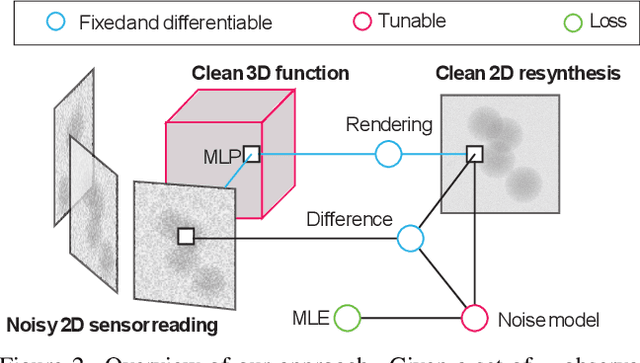

Scanning Transmission Electron Microscopes (STEMs) acquire 2D images of a 3D sample on the scale of individual cell components. Unfortunately, these 2D images can be too noisy to be fused into a useful 3D structure and facilitating good denoisers is challenging due to the lack of clean-noisy pairs. Additionally, representing a detailed 3D structure can be difficult even for clean data when using regular 3D grids. Addressing these two limitations, we suggest a differentiable image formation model for STEM, allowing to learn a joint model of 2D sensor noise in STEM together with an implicit 3D model. We show, that the combination of these models are able to successfully disentangle 3D signal and noise without supervision and outperform at the same time several baselines on synthetic and real data.
What's in your hands? 3D Reconstruction of Generic Objects in Hands
Apr 14, 2022
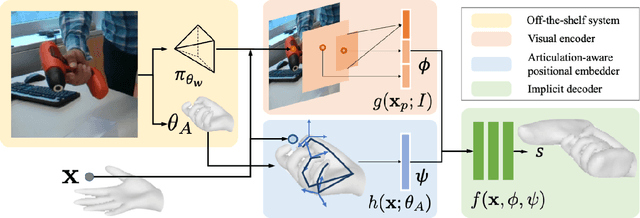

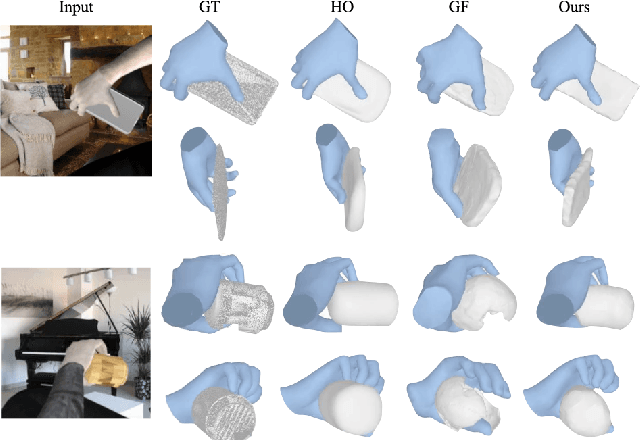
Our work aims to reconstruct hand-held objects given a single RGB image. In contrast to prior works that typically assume known 3D templates and reduce the problem to 3D pose estimation, our work reconstructs generic hand-held object without knowing their 3D templates. Our key insight is that hand articulation is highly predictive of the object shape, and we propose an approach that conditionally reconstructs the object based on the articulation and the visual input. Given an image depicting a hand-held object, we first use off-the-shelf systems to estimate the underlying hand pose and then infer the object shape in a normalized hand-centric coordinate frame. We parameterized the object by signed distance which are inferred by an implicit network which leverages the information from both visual feature and articulation-aware coordinates to process a query point. We perform experiments across three datasets and show that our method consistently outperforms baselines and is able to reconstruct a diverse set of objects. We analyze the benefits and robustness of explicit articulation conditioning and also show that this allows the hand pose estimation to further improve in test-time optimization.
Reinforcement Learning Policy Recommendation for Interbank Network Stability
Apr 14, 2022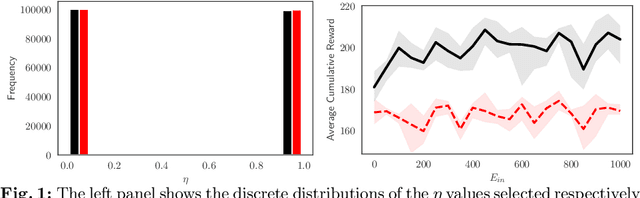
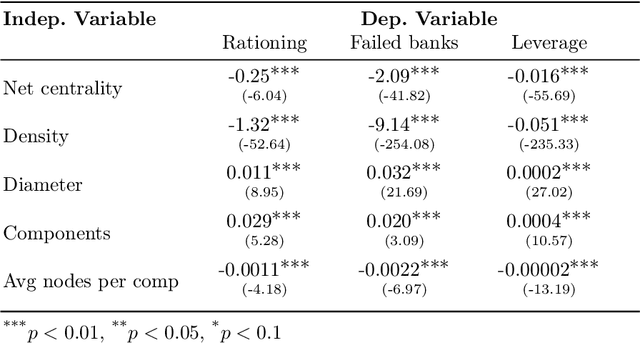
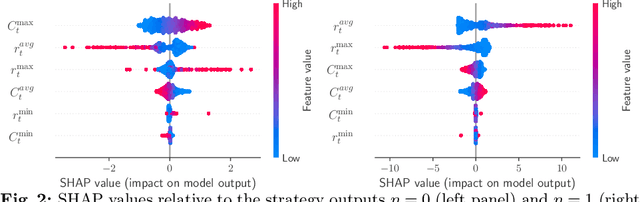
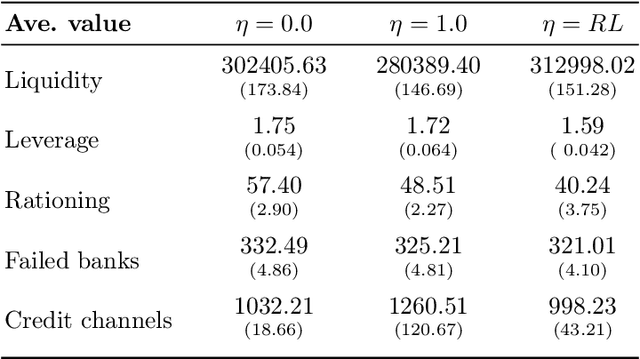
In this paper we analyze the effect of a policy recommendation on the performances of an artificial interbank market. Financial institutions stipulate lending agreements following a public recommendation and their individual information. The former, modeled by a reinforcement learning optimal policy trying to maximize the long term fitness of the system, gathers information on the economic environment and directs economic actors to create credit relationships based on the optimal choice between a low interest rate or high liquidity supply. The latter, based on the agents' balance sheet, allows to determine the liquidity supply and interest rate that the banks optimally offer on the market. Based on the combination between the public and the private signal, financial institutions create or cut their credit connections over time via a preferential attachment evolving procedure able to generate a dynamic network. Our results show that the emergence of a core-periphery interbank network, combined with a certain level of homogeneity on the size of lenders and borrowers, are essential features to ensure the resilience of the system. Moreover, the reinforcement learning optimal policy recommendation plays a crucial role in mitigating systemic risk with respect to alternative policy instruments.
Power-of-Two Quantization for Low Bitwidth and Hardware Compliant Neural Networks
Mar 09, 2022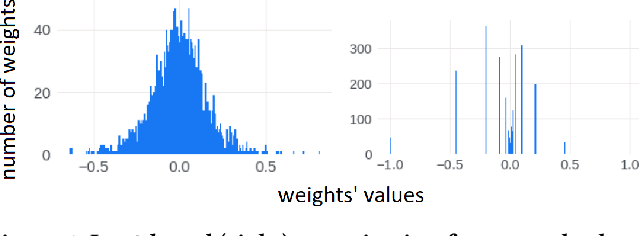
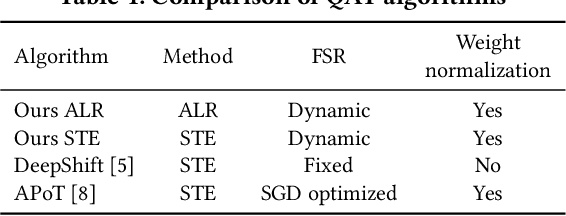
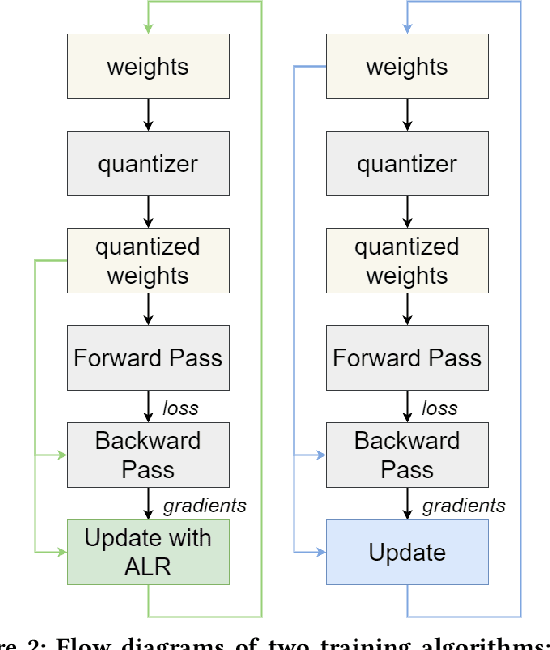
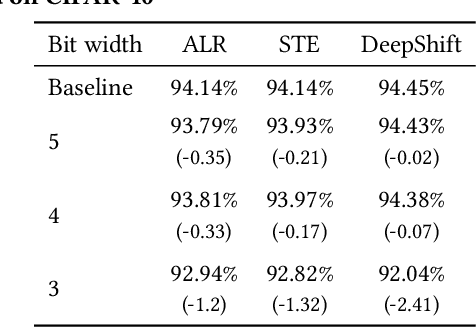
Deploying Deep Neural Networks in low-power embedded devices for real time-constrained applications requires optimization of memory and computational complexity of the networks, usually by quantizing the weights. Most of the existing works employ linear quantization which causes considerable degradation in accuracy for weight bit widths lower than 8. Since the distribution of weights is usually non-uniform (with most weights concentrated around zero), other methods, such as logarithmic quantization, are more suitable as they are able to preserve the shape of the weight distribution more precise. Moreover, using base-2 logarithmic representation allows optimizing the multiplication by replacing it with bit shifting. In this paper, we explore non-linear quantization techniques for exploiting lower bit precision and identify favorable hardware implementation options. We developed the Quantization Aware Training (QAT) algorithm that allowed training of low bit width Power-of-Two (PoT) networks and achieved accuracies on par with state-of-the-art floating point models for different tasks. We explored PoT weight encoding techniques and investigated hardware designs of MAC units for three different quantization schemes - uniform, PoT and Additive-PoT (APoT) - to show the increased efficiency when using the proposed approach. Eventually, the experiments showed that for low bit width precision, non-uniform quantization performs better than uniform, and at the same time, PoT quantization vastly reduces the computational complexity of the neural network.