 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optical Remote Sensing Image Understanding with Weak Supervision: Concepts, Methods, and Perspectives
Apr 18, 2022
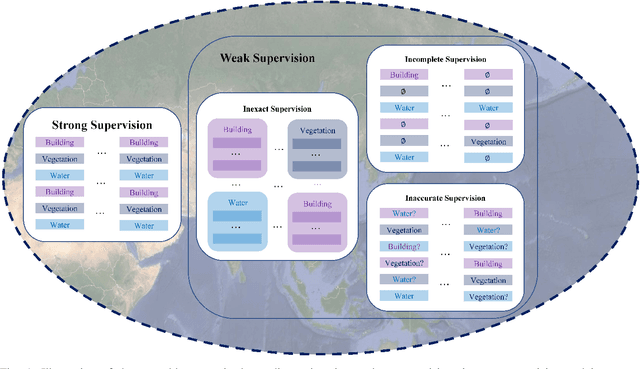
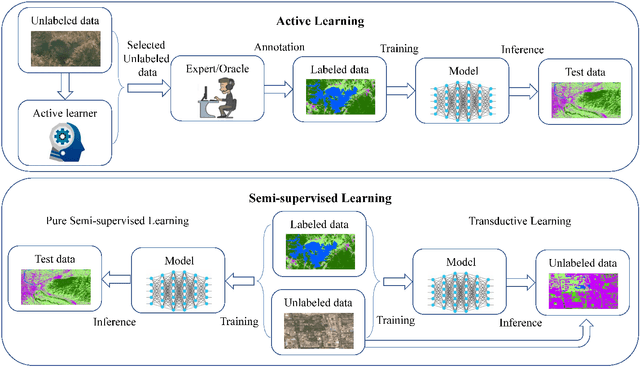
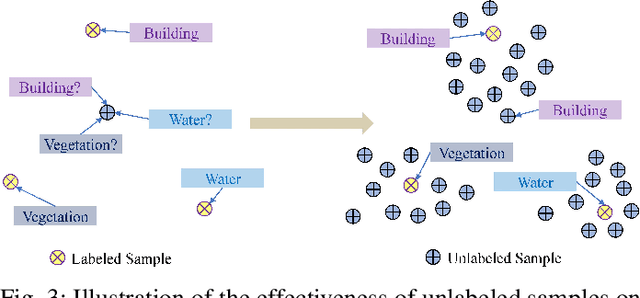

In recent years, supervised learning has been widely used in various tasks of optical remote sensing image understanding, including remote sensing image classification, pixel-wise segmentation, change detection, and object detection. The methods based on supervised learning need a large amount of high-quality training data and their performance highly depends on the quality of the labels. However, in practical remote sensing applications, it is often expensive and time-consuming to obtain large-scale data sets with high-quality labels, which leads to a lack of sufficient supervised information. In some cases, only coarse-grained labels can be obtained, resulting in the lack of exact supervision. In addition, the supervised information obtained manually may be wrong, resulting in a lack of accurate supervision. Therefore, remote sensing image understanding often faces the problems of incomplete, inexact, and inaccurate supervised information, which will affect the breadth and depth of remote sensing applications. In order to solve the above-mentioned problems, researchers have explored various tasks in remote sensing image understanding under weak supervision. This paper summarizes the research progress of weakly supervised learning in the field of remote sensing, including three typical weakly supervised paradigms: 1) Incomplete supervision, where only a subset of training data is labeled; 2) Inexact supervision, where only coarse-grained labels of training data are given; 3) Inaccurate supervision, where the labels given are not always true on the ground.
Using Active Speaker Faces for Diarization in TV shows
Mar 30, 2022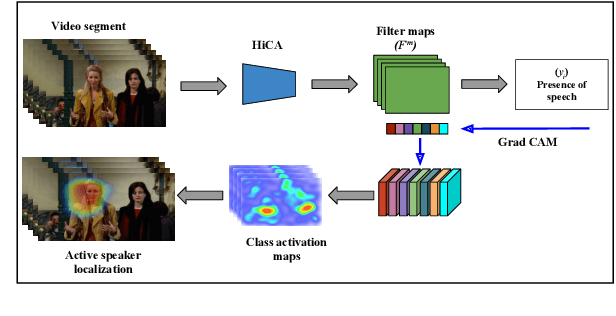
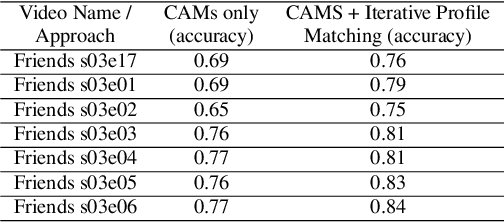
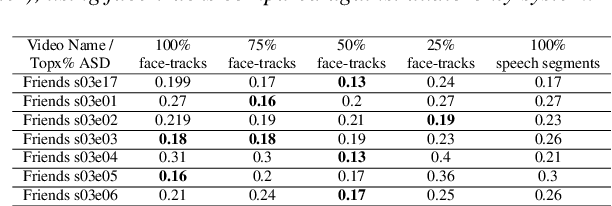
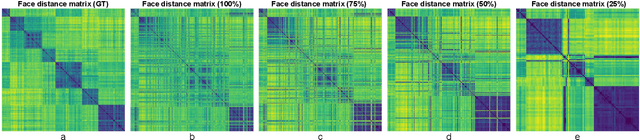
Speaker diarization is one of the critical components of computational media intelligence as it enables a character-level analysis of story portrayals and media content understanding. Automated audio-based speaker diarization of entertainment media poses challenges due to the diverse acoustic conditions present in media content, be it background music, overlapping speakers, or sound effects. At the same time, speaking faces in the visual modality provide complementary information and not prone to the errors seen in the audio modality. In this paper, we address the problem of speaker diarization in TV shows using the active speaker faces. We perform face clustering on the active speaker faces and show superior speaker diarization performance compared to the state-of-the-art audio-based diarization methods. We additionally report a systematic analysis of the impact of active speaker face detection quality on the diarization performance. We also observe that a moderately well-performing active speaker system could outperform the audio-based diarization systems.
Many-to-many Splatting for Efficient Video Frame Interpolation
Apr 07, 2022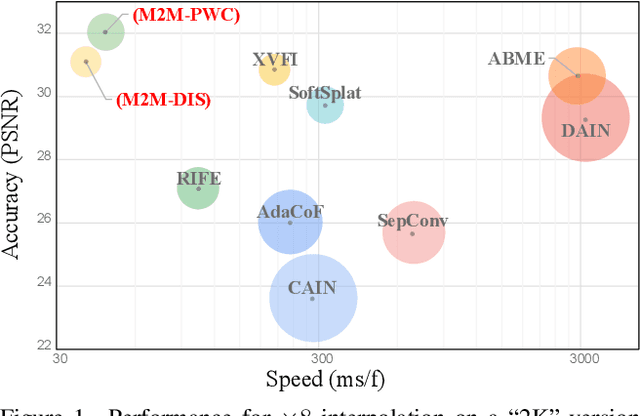
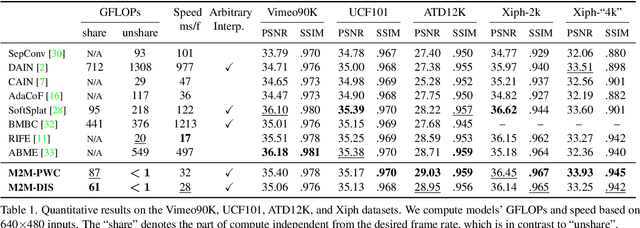
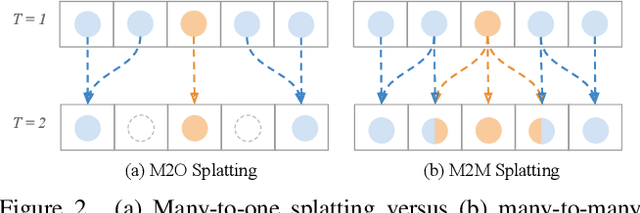
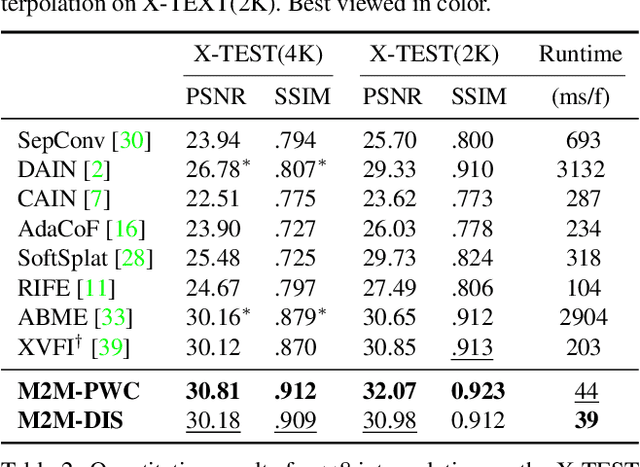
Motion-based video frame interpolation commonly relies on optical flow to warp pixels from the inputs to the desired interpolation instant. Yet due to the inherent challenges of motion estimation (e.g. occlusions and discontinuities), most state-of-the-art interpolation approaches require subsequent refinement of the warped result to generate satisfying outputs, which drastically decreases the efficiency for multi-frame interpolation. In this work, we propose a fully differentiable Many-to-Many (M2M) splatting framework to interpolate frames efficiently. Specifically, given a frame pair, we estimate multiple bidirectional flows to directly forward warp the pixels to the desired time step, and then fuse any overlapping pixels. In doing so, each source pixel renders multiple target pixels and each target pixel can be synthesized from a larger area of visual context. This establishes a many-to-many splatting scheme with robustness to artifacts like holes. Moreover, for each input frame pair, M2M only performs motion estimation once and has a minuscule computational overhead when interpolating an arbitrary number of in-between frames, hence achieving fast multi-frame interpolation. We conducted extensive experiments to analyze M2M, and found that it significantly improves efficiency while maintaining high effectiveness.
ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard-of-Hearing Users
Feb 22, 2022

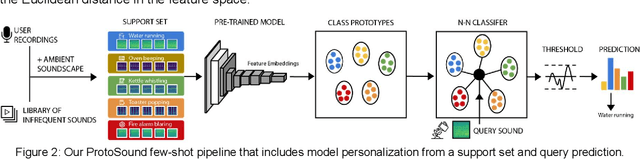
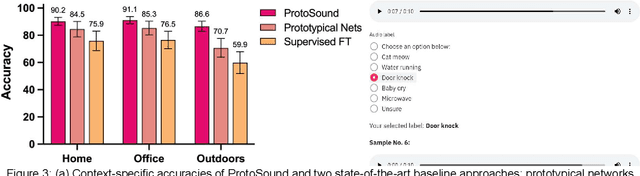
Recent advances have enabled automatic sound recognition systems for deaf and hard of hearing (DHH) users on mobile devices. However, these tools use pre-trained, generic sound recognition models, which do not meet the diverse needs of DHH users. We introduce ProtoSound, an interactive system for customizing sound recognition models by recording a few examples, thereby enabling personalized and fine-grained categories. ProtoSound is motivated by prior work examining sound awareness needs of DHH people and by a survey we conducted with 472 DHH participants. To evaluate ProtoSound, we characterized performance on two real-world sound datasets, showing significant improvement over state-of-the-art (e.g., +9.7% accuracy on the first dataset). We then deployed ProtoSound's end-user training and real-time recognition through a mobile application and recruited 19 hearing participants who listened to the real-world sounds and rated the accuracy across 56 locations (e.g., homes, restaurants, parks). Results show that ProtoSound personalized the model on-device in real-time and accurately learned sounds across diverse acoustic contexts. We close by discussing open challenges in personalizable sound recognition, including the need for better recording interfaces and algorithmic improvements.
SDR-based Testbed for Real-time CQI Prediction for URLLC
Mar 05, 2021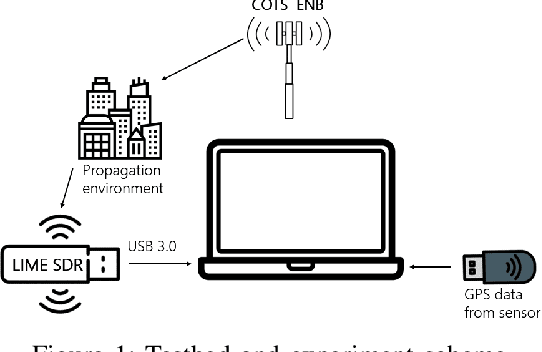

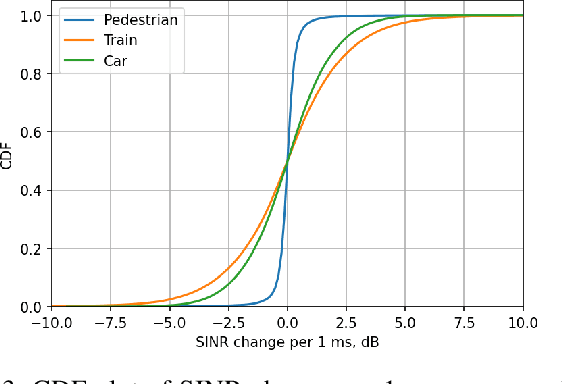
Ultra-reliable Low-Latency Communication (URLLC) is a key feature of 5G systems. The quality of service (QoS) requirements imposed by URLLC are less than 10ms delay and less than $10^{-5}$ packet loss rate (PLR). To satisfy such strict requirements with minimal channel resource consumption, the devices need to accurately predict the channel quality and select Modulation and Coding Scheme (MCS) for URLLC in a proper way. This paper presents a novel real-time channel prediction system based on Software-Defined Radio that uses a neural network. The paper also describes and shares an open channel measurement dataset that can be used to compare various channel prediction approaches in different mobility scenarios in future research on URLLC
Recursive 3D Segmentation of Shoulder Joint with Coarse-scanned MR Image
Mar 13, 2022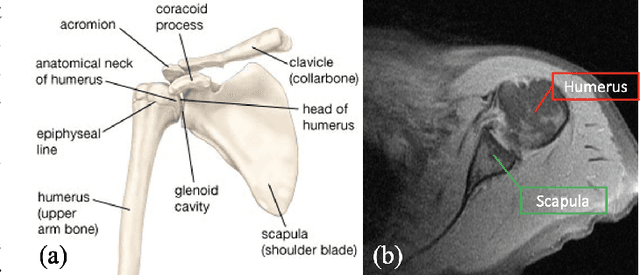
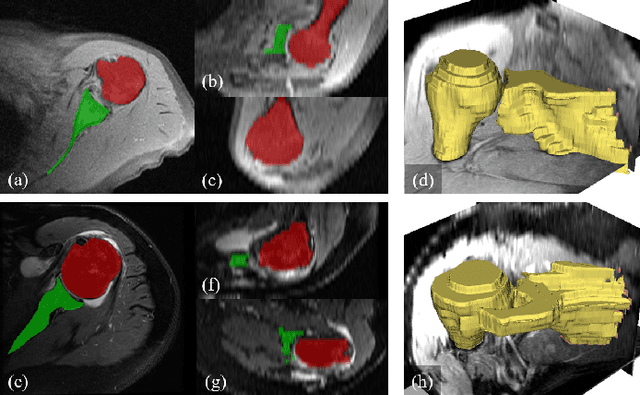
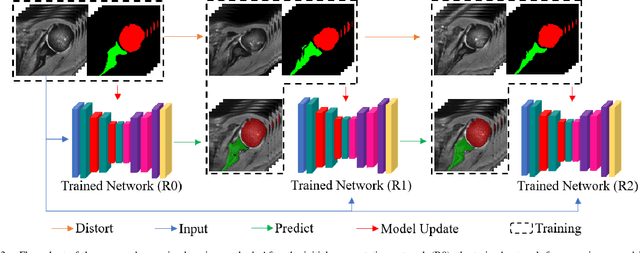
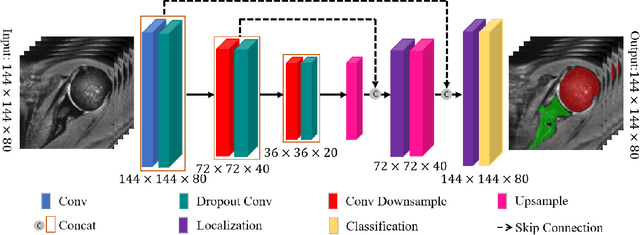
For diagnosis of shoulder illness, it is essential to look at the morphology deviation of scapula and humerus from the medical images that are acquired from Magnetic Resonance (MR) imaging. However, taking high-resolution MR images is time-consuming and costly because the reduction of the physical distance between image slices causes prolonged scanning time. Moreover, due to the lack of training images, images from various sources must be utilized, which creates the issue of high variance across the dataset. Also, there are human errors among the images due to the fact that it is hard to take the spatial relationship into consideration when labeling the 3D image in low resolution. In order to combat all obstacles stated above, we develop a fully automated algorithm for segmenting the humerus and scapula bone from coarsely scanned and low-resolution MR images and a recursive learning framework that iterative utilize the generated labels for reducing the errors among segmentations and increase our dataset set for training the next round network. In this study, 50 MR images are collected from several institutions and divided into five mutually exclusive sets for carrying five-fold cross-validation. Contours that are generated by the proposed method demonstrated a high level of accuracy when compared with ground truth and the traditional method. The proposed neural network and the recursive learning scheme improve the overall quality of the segmentation on humerus and scapula on the low-resolution dataset and reduced incorrect segmentation in the ground truth, which could have a positive impact on finding the cause of shoulder pain and patient's early relief.
ShiftNAS: Towards Automatic Generation of Advanced Mulitplication-Less Neural Networks
Apr 07, 2022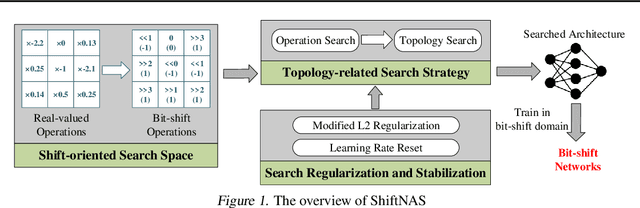
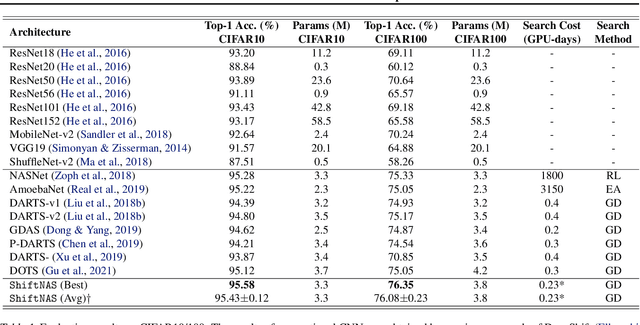
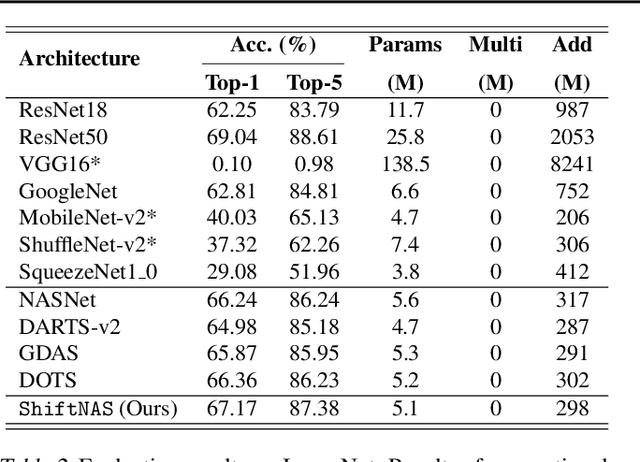
Multiplication-less neural networks significantly reduce the time and energy cost on the hardware platform, as the compute-intensive multiplications are replaced with lightweight bit-shift operations. However, existing bit-shift networks are all directly transferred from state-of-the-art convolutional neural networks (CNNs), which lead to non-negligible accuracy drop or even failure of model convergence. To combat this, we propose ShiftNAS, the first framework tailoring Neural Architecture Search (NAS) to substantially reduce the accuracy gap between bit-shift neural networks and their real-valued counterparts. Specifically, we pioneer dragging NAS into a shift-oriented search space and endow it with the robust topology-related search strategy and custom regularization and stabilization. As a result, our ShiftNAS breaks through the incompatibility of traditional NAS methods for bit-shift neural networks and achieves more desirable performance in terms of accuracy and convergence. Extensive experiments demonstrate that ShiftNAS sets a new state-of-the-art for bit-shift neural networks, where the accuracy increases (1.69-8.07)% on CIFAR10, (5.71-18.09)% on CIFAR100 and (4.36-67.07)% on ImageNet, especially when many conventional CNNs fail to converge on ImageNet with bit-shift weights.
Optimized SC-F-LOAM: Optimized Fast LiDAR Odometry and Mapping Using Scan Context
Apr 11, 2022
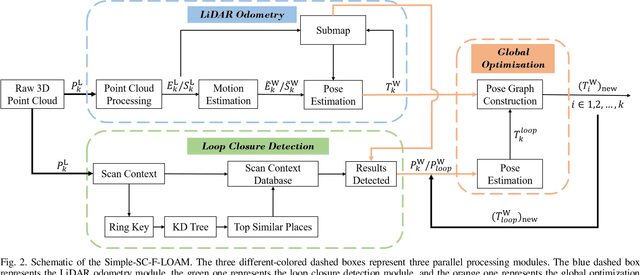
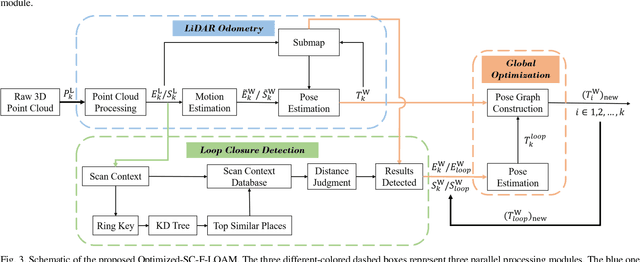

LiDAR odometry can achieve accurate vehicle pose estimation for short driving range or in small-scale environments, but for long driving range or in large-scale environments, the accuracy deteriorates as a result of cumulative estimation errors. This drawback necessitates the inclusion of loop closure detection in a SLAM framework to suppress the adverse effects of cumulative errors. To improve the accuracy of pose estimation, we propose a new LiDAR-based SLAM method which uses F-LOAM as LiDAR odometry, Scan Context for loop closure detection, and GTSAM for global optimization. In our approach, an adaptive distance threshold (instead of a fixed threshold) is employed for loop closure detection, which achieves more accurate loop closure detection results. Besides, a feature-based matching method is used in our approach to compute vehicle pose transformations between loop closure point cloud pairs, instead of using the raw point cloud obtained by the LiDAR sensor, which significantly reduces the computation time. The KITTI dataset and a UGV platform are used for verifications of our method, and the experimental results demonstrate that the proposed method outperforms typical LiDAR odometry/SLAM methods in the literature. Our code is made publicly available for the benefit of the community.
A Deep Learning Approach to Probabilistic Forecasting of Weather
Mar 24, 2022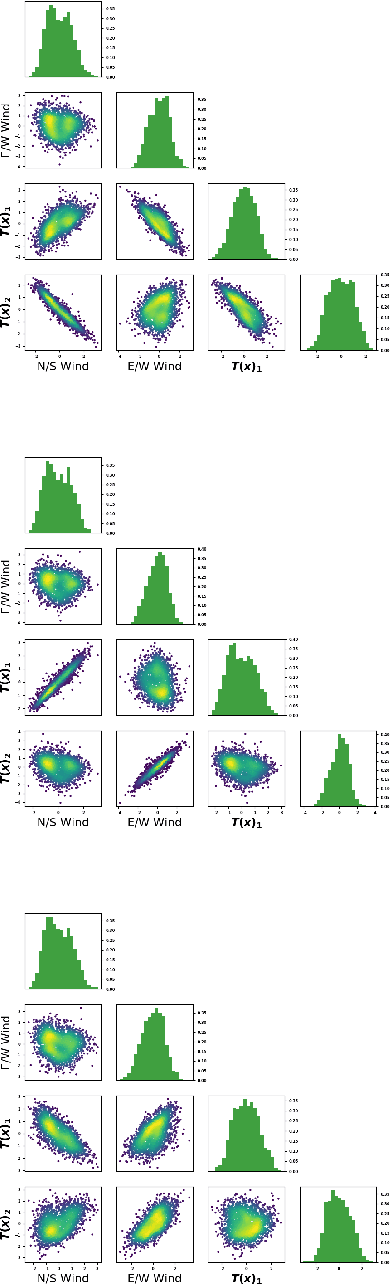
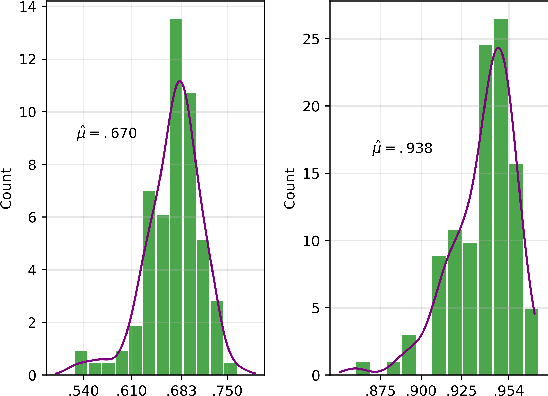
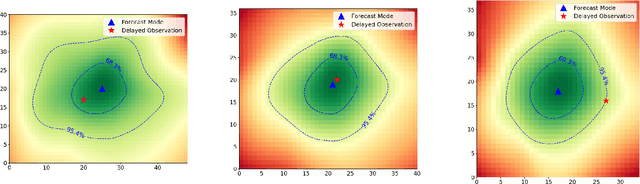
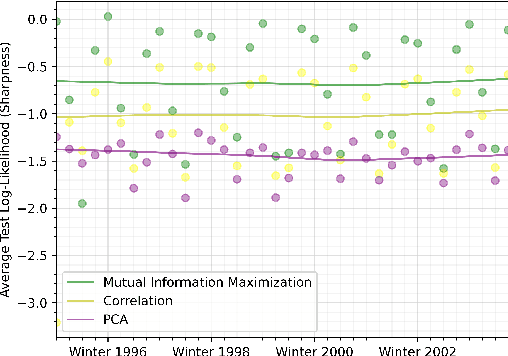
We discuss an approach to probabilistic forecasting based on two chained machine-learning steps: a dimensional reduction step that learns a reduction map of predictor information to a low-dimensional space in a manner designed to preserve information about forecast quantities; and a density estimation step that uses the probabilistic machine learning technique of normalizing flows to compute the joint probability density of reduced predictors and forecast quantities. This joint density is then renormalized to produce the conditional forecast distribution. In this method, probabilistic calibration testing plays the role of a regularization procedure, preventing overfitting in the second step, while effective dimensional reduction from the first step is the source of forecast sharpness. We verify the method using a 22-year 1-hour cadence time series of Weather Research and Forecasting (WRF) simulation data of surface wind on a grid.
NICGSlowDown: Evaluating the Efficiency Robustness of Neural Image Caption Generation Models
Mar 29, 2022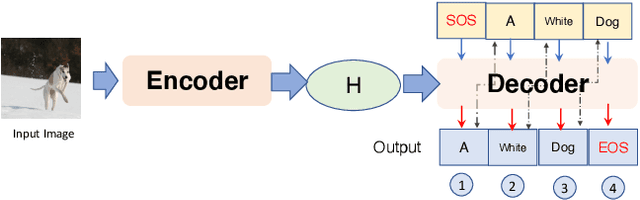
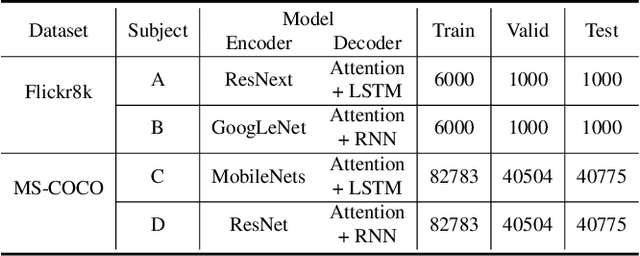

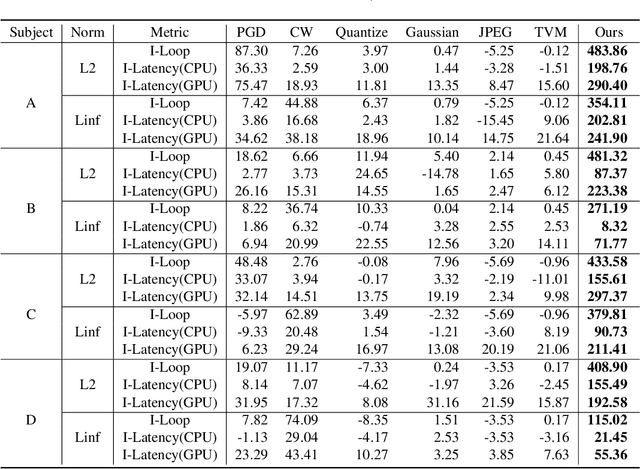
Neural image caption generation (NICG) models have received massive attention from the research community due to their excellent performance in visual understanding. Existing work focuses on improving NICG model accuracy while efficiency is less explored. However, many real-world applications require real-time feedback, which highly relies on the efficiency of NICG models. Recent research observed that the efficiency of NICG models could vary for different inputs. This observation brings in a new attack surface of NICG models, i.e., An adversary might be able to slightly change inputs to cause the NICG models to consume more computational resources. To further understand such efficiency-oriented threats, we propose a new attack approach, NICGSlowDown, to evaluate the efficiency robustness of NICG models. Our experimental results show that NICGSlowDown can generate images with human-unnoticeable perturbations that will increase the NICG model latency up to 483.86%. We hope this research could raise the community's concern about the efficiency robustness of NICG models.