 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Supervised Machine Learning Approach for Sequence Based Protein-protein Interaction (PPI) Prediction
Mar 27, 2022
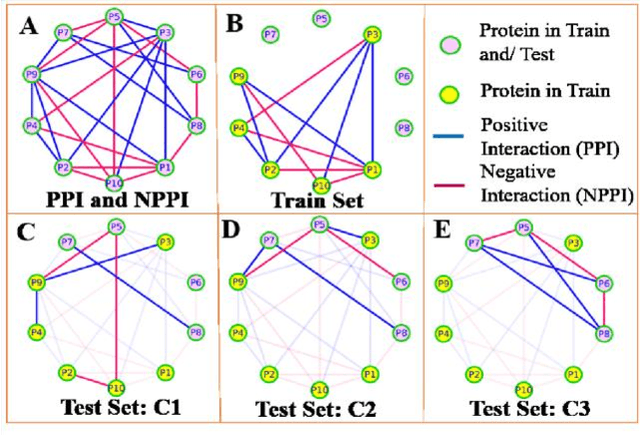
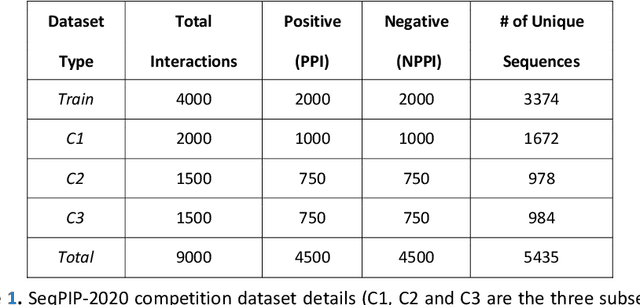
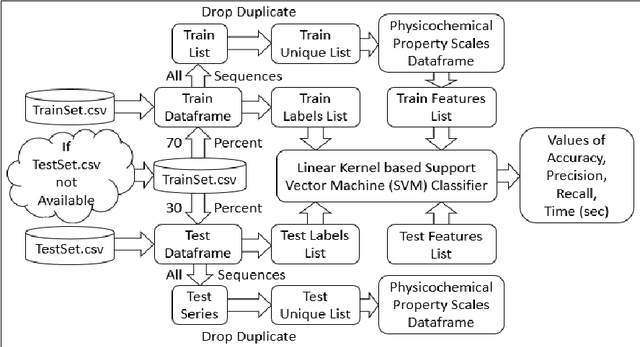
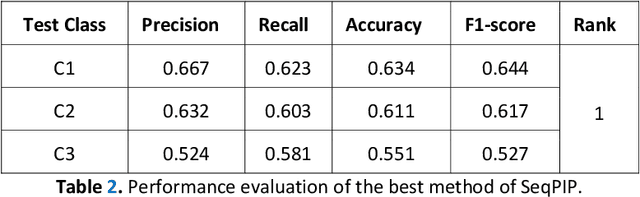
Computational protein-protein interaction (PPI) prediction techniques can contribute greatly in reducing time, cost and false-positive interactions compared to experimental approaches. Sequence is one of the key and primary information of proteins that plays a crucial role in PPI prediction. Several machine learning approaches have been applied to exploit the characteristics of PPI datasets. However, these datasets greatly influence the performance of predicting models. So, care should be taken on both dataset curation as well as design of predictive models. Here, we have described our submitted solution with the results of the SeqPIP competition whose objective was to develop comprehensive PPI predictive models from sequence information with high-quality bias-free interaction datasets. A training set of 2000 positive and 2000 negative interactions with sequences was given to us. Our method was evaluated with three independent high-quality interaction test datasets and with other competitors solutions.
CenterNet++ for Object Detection
Apr 18, 2022

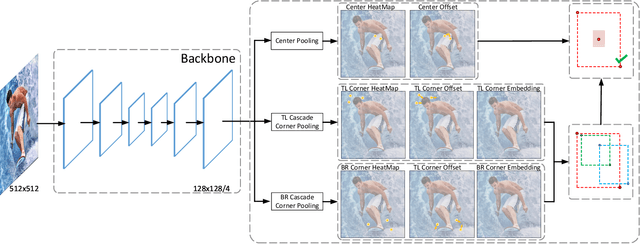
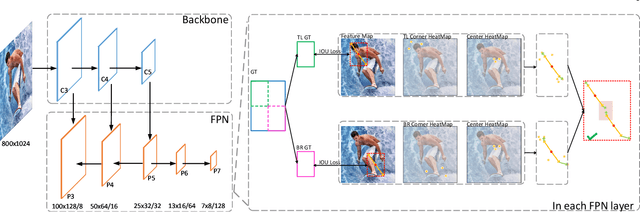
There are two mainstreams for object detection: top-down and bottom-up. The state-of-the-art approaches mostly belong to the first category. In this paper, we demonstrate that the bottom-up approaches are as competitive as the top-down and enjoy higher recall. Our approach, named CenterNet, detects each object as a triplet keypoints (top-left and bottom-right corners and the center keypoint). We firstly group the corners by some designed cues and further confirm the objects by the center keypoints. The corner keypoints equip the approach with the ability to detect objects of various scales and shapes and the center keypoint avoids the confusion brought by a large number of false-positive proposals. Our approach is a kind of anchor-free detector because it does not need to define explicit anchor boxes. We adapt our approach to the backbones with different structures, i.e., the 'hourglass' like networks and the the 'pyramid' like networks, which detect objects on a single-resolution feature map and multi-resolution feature maps, respectively. On the MS-COCO dataset, CenterNet with Res2Net-101 and Swin-Transformer achieves APs of 53.7% and 57.1%, respectively, outperforming all existing bottom-up detectors and achieving state-of-the-art. We also design a real-time CenterNet, which achieves a good trade-off between accuracy and speed with an AP of 43.6% at 30.5 FPS. https://github.com/Duankaiwen/PyCenterNet.
Model2Detector: Widening the Information Bottleneck for Out-of-Distribution Detection using a Handful of Gradient Steps
Feb 22, 2022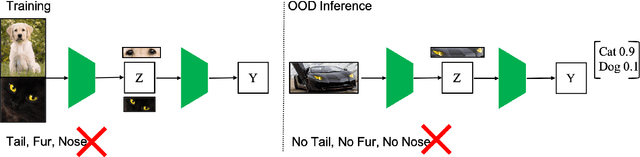
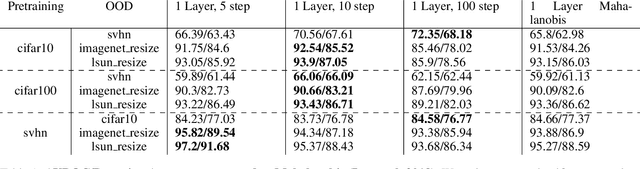
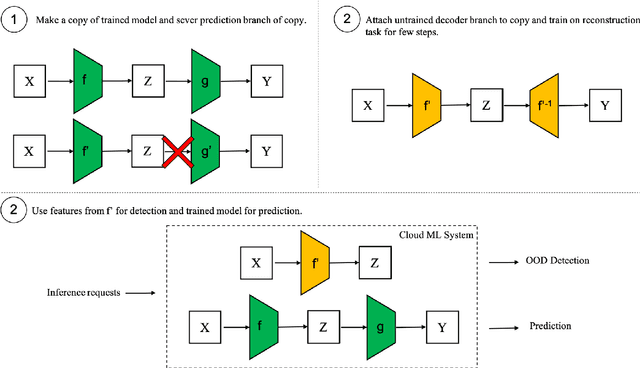
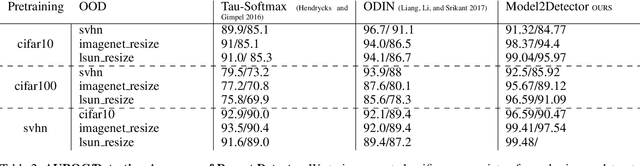
Out-of-distribution detection is an important capability that has long eluded vanilla neural networks. Deep Neural networks (DNNs) tend to generate over-confident predictions when presented with inputs that are significantly out-of-distribution (OOD). This can be dangerous when employing machine learning systems in the wild as detecting attacks can thus be difficult. Recent advances inference-time out-of-distribution detection help mitigate some of these problems. However, existing methods can be restrictive as they are often computationally expensive. Additionally, these methods require training of a downstream detector model which learns to detect OOD inputs from in-distribution ones. This, therefore, adds latency during inference. Here, we offer an information theoretic perspective on why neural networks are inherently incapable of OOD detection. We attempt to mitigate these flaws by converting a trained model into a an OOD detector using a handful of steps of gradient descent. Our work can be employed as a post-processing method whereby an inference-time ML system can convert a trained model into an OOD detector. Experimentally, we show how our method consistently outperforms the state-of-the-art in detection accuracy on popular image datasets while also reducing computational complexity.
Online Learning in Fisher Markets with Unknown Agent Preferences
Apr 27, 2022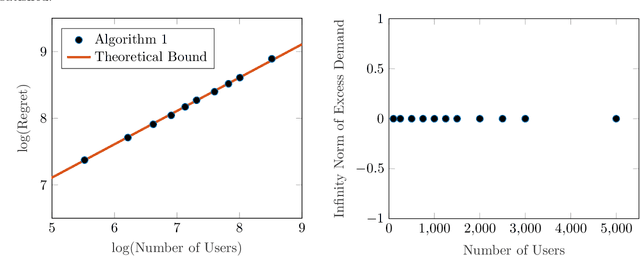
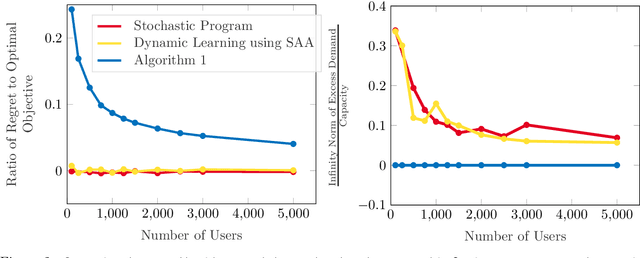
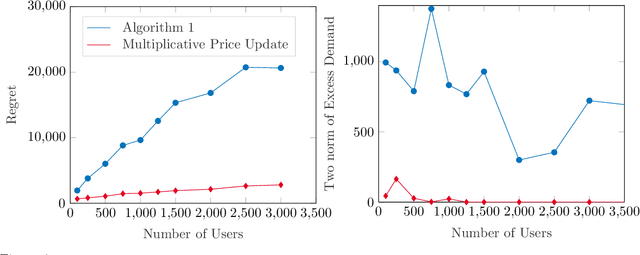
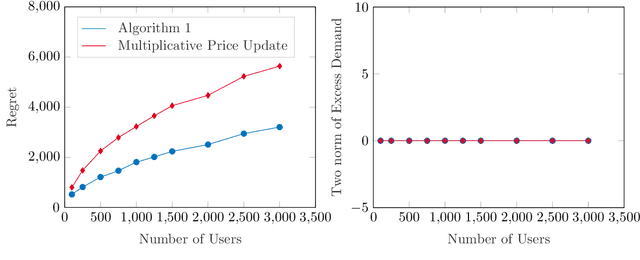
In a Fisher market, agents (users) spend a budget of (artificial) currency to buy goods that maximize their utilities, and producers set prices on capacity-constrained goods such that the market clears. The equilibrium prices in such a market are typically computed through the solution of a convex program, e.g., the Eisenberg-Gale program, that aggregates users' preferences into a centralized social welfare objective. However, the computation of equilibrium prices using convex programs assumes that all transactions happen in a static market wherein all users are present simultaneously and relies on complete information on each user's budget and utility function. Since, in practice, information on users' utilities and budgets is unknown and users tend to arrive over time in the market, we study an online variant of Fisher markets, wherein users enter the market sequentially. We focus on the setting where users have linear utilities with privately known utility and budget parameters drawn i.i.d. from a distribution $\mathcal{D}$. In this setting, we develop a simple yet effective algorithm to set prices that preserves user privacy while achieving a regret and capacity violation of $O(\sqrt{n})$, where $n$ is the number of arriving users and the capacities of the goods scale as $O(n)$. Here, our regret measure represents the optimality gap in the objective of the Eisenberg-Gale program between the online allocation policy and that of an offline oracle with complete information on users' budgets and utilities. To establish the efficacy of our approach, we show that even an algorithm that sets expected equilibrium prices with perfect information on the distribution $\mathcal{D}$ cannot achieve both a regret and constraint violation of better than $\Omega(\sqrt{n})$. Finally, we present numerical experiments to demonstrate the performance of our approach relative to several benchmarks.
Automated Isovist Computation for Minecraft
Apr 07, 2022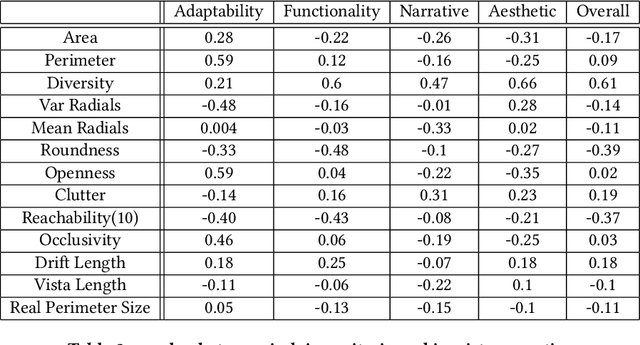
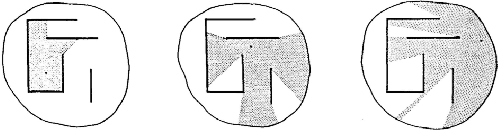
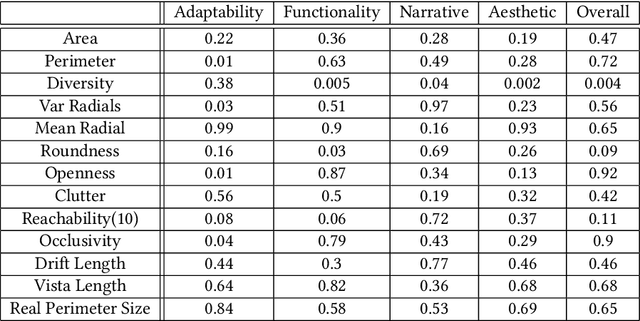
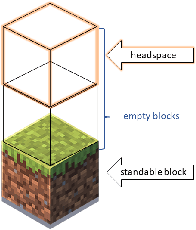
Procedural content generation for games is a growing trend in both research and industry, even though there is no consensus of how good content looks, nor how to automatically evaluate it. A number of metrics have been developed in the past, usually focused on the artifact as a whole, and mostly lacking grounding in human experience. In this study we develop a new set of automated metrics, motivated by ideas from architecture, namely isovists and space syntax, which have a track record of capturing human experience of space. These metrics can be computed for a specific game state, from the player's perspective, and take into account their embodiment in the game world. We show how to apply those metrics to the 3d blockworld of Minecraft. We use a dataset of generated settlements from the GDMC Settlement Generation Challenge in Minecraft and establish several rank-based correlations between the isovist properties and the rating human judges gave those settelements. We also produce a range of heat maps that demonstrate the location based applicability of the approach, which allows for development of those metrics as measures for a game experience at a specific time and space.
Trainable Time Warping: Aligning Time-Series in the Continuous-Time Domain
Mar 21, 2019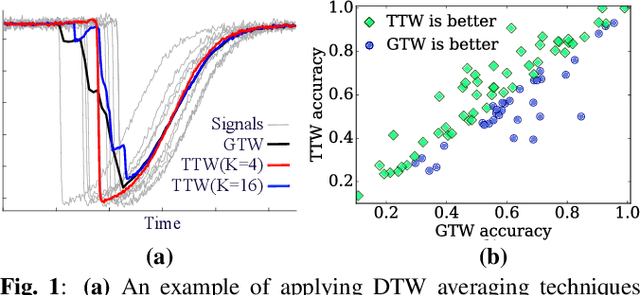
DTW calculates the similarity or alignment between two signals, subject to temporal warping. However, its computational complexity grows exponentially with the number of time-series. Although there have been algorithms developed that are linear in the number of time-series, they are generally quadratic in time-series length. The exception is generalized time warping (GTW), which has linear computational cost. Yet, it can only identify simple time warping functions. There is a need for a new fast, high-quality multisequence alignment algorithm. We introduce trainable time warping (TTW), whose complexity is linear in both the number and the length of time-series. TTW performs alignment in the continuous-time domain using a sinc convolutional kernel and a gradient-based optimization technique. We compare TTW and GTW on 85 UCR datasets in time-series averaging and classification. TTW outperforms GTW on 67.1% of the datasets for the averaging tasks, and 61.2% of the datasets for the classification tasks.
Smart Time-Multiplexing of Quads Solves the Multicamera Interference Problem
Nov 05, 2020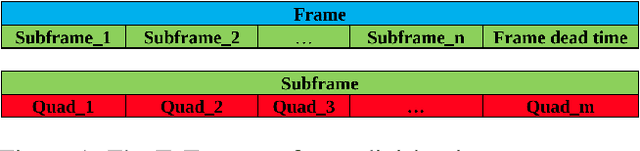
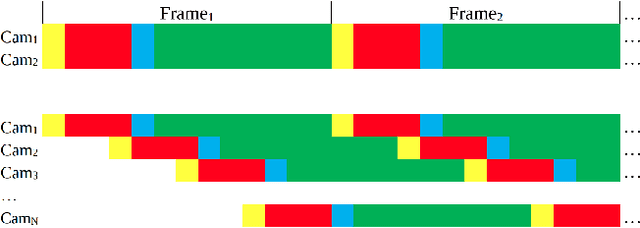
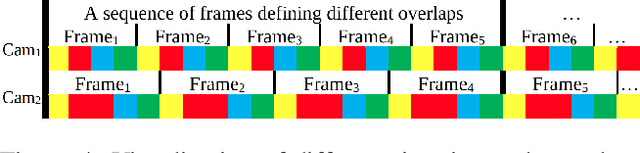
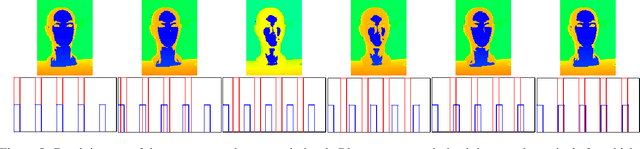
Time-of-flight (ToF) cameras are becoming increasingly popular for 3D imaging. Their optimal usage has been studied from the several aspects. One of the open research problems is the possibility of a multicamera interference problem when two or more ToF cameras are operating simultaneously. In this work we present an efficient method to synchronize multiple operating ToF cameras. Our method is based on the time-division multiplexing, but unlike traditional time multiplexing, it does not decrease the effective camera frame rate. Additionally, for unsynchronized cameras, we provide a robust method to extract from their corresponding video streams, frames which are not subject to multicamera interference problem. We demonstrate our approach through a series of experiments and with a different level of support available for triggering, ranging from a hardware triggering to purely random software triggering.
Understanding COVID-19 News Coverage using Medical NLP
Mar 19, 2022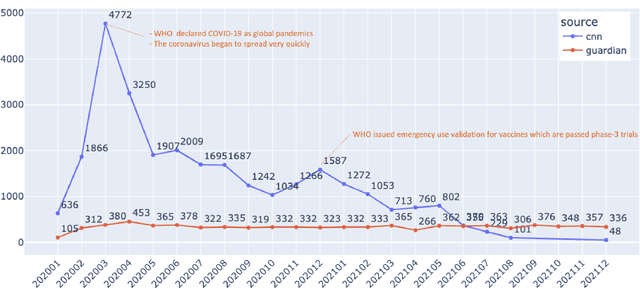
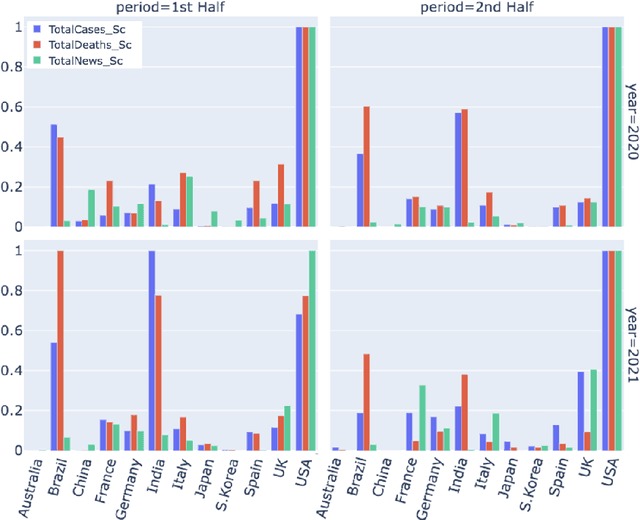
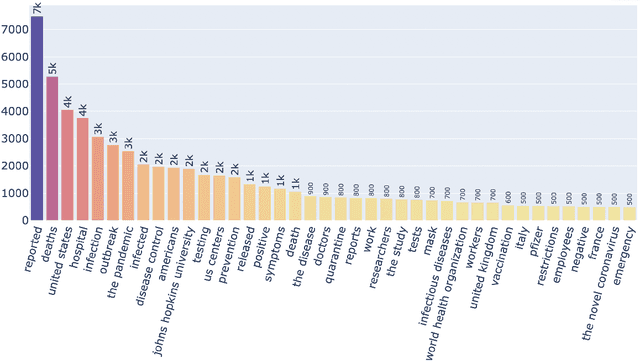
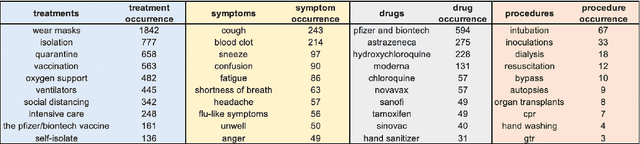
Being a global pandemic, the COVID-19 outbreak received global media attention. In this study, we analyze news publications from CNN and The Guardian - two of the world's most influential media organizations. The dataset includes more than 36,000 articles, analyzed using the clinical and biomedical Natural Language Processing (NLP) models from the Spark NLP for Healthcare library, which enables a deeper analysis of medical concepts than previously achieved. The analysis covers key entities and phrases, observed biases, and change over time in news coverage by correlating mined medical symptoms, procedures, drugs, and guidance with commonly mentioned demographic and occupational groups. Another analysis is of extracted Adverse Drug Events about drug and vaccine manufacturers, which when reported by major news outlets has an impact on vaccine hesitancy.
Resource Allocation for Multiuser Edge Inference with Batching and Early Exiting (Extended Version)
Apr 11, 2022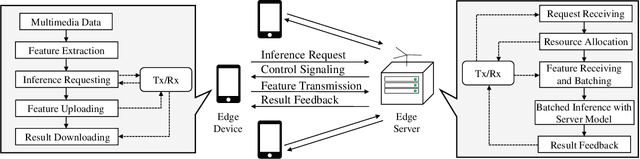

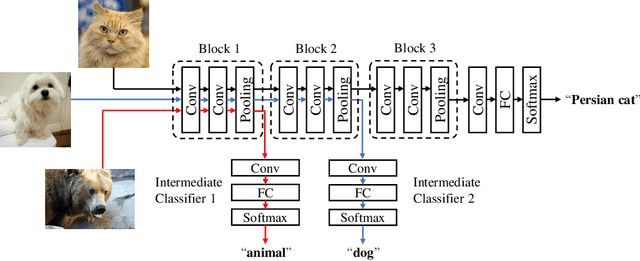
The deployment of inference services at the network edge, called edge inference, offloads computation-intensive inference tasks from mobile devices to edge servers, thereby enhancing the former's capabilities and battery lives. In a multiuser system, the joint allocation of communication-and-computation ($\text{C}^\text{2}$) resources (i.e., scheduling and bandwidth allocation) is made challenging by adopting efficient inference techniques, batching and early exiting, and further complicated by the heterogeneity in users' requirements on accuracy and latency. Batching groups multiple tasks into one batch for parallel processing to reduce time-consuming memory access and thereby boosts the throughput (i.e., completed task per second). On the other hand, early exiting allows a task to exit from a deep-neural network without traversing the whole network to support a tradeoff between accuracy and latency. In this work, we study optimal $\text{C}^\text{2}$ resource allocation with batching and early exiting, which is an NP-complete integer program. A set of efficient algorithms are designed under the criterion of maximum throughput by tackling the challenge. Experimental results demonstrate that both optimal and sub-optimal $\text{C}^\text{2}$ resource allocation algorithms can leverage integrated batching and early exiting to achieve 200% throughput gain over conventional schemes.
Recursive input and state estimation: A general framework for learning from time series with missing data
Apr 17, 2021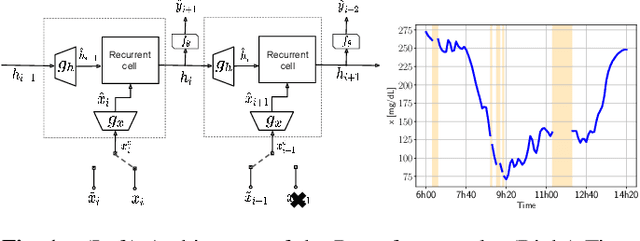


Time series with missing data are signals encountered in important settings for machine learning. Some of the most successful prior approaches for modeling such time series are based on recurrent neural networks that transform the input and previous state to account for the missing observations, and then treat the transformed signal in a standard manner. In this paper, we introduce a single unifying framework, Recursive Input and State Estimation (RISE), for this general approach and reformulate existing models as specific instances of this framework. We then explore additional novel variations within the RISE framework to improve the performance of any instance. We exploit representation learning techniques to learn latent representations of the signals used by RISE instances. We discuss and develop various encoding techniques to learn latent signal representations. We benchmark instances of the framework with various encoding functions on three data imputation datasets, observing that RISE instances always benefit from encoders that learn representations for numerical values from the digits into which they can be decomposed.