 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dir-MUSIC Algorithm for DOA Estimation of Partial Discharge Based on Signal Strength represented by Antenna Gain Array Manifold
Apr 19, 2022
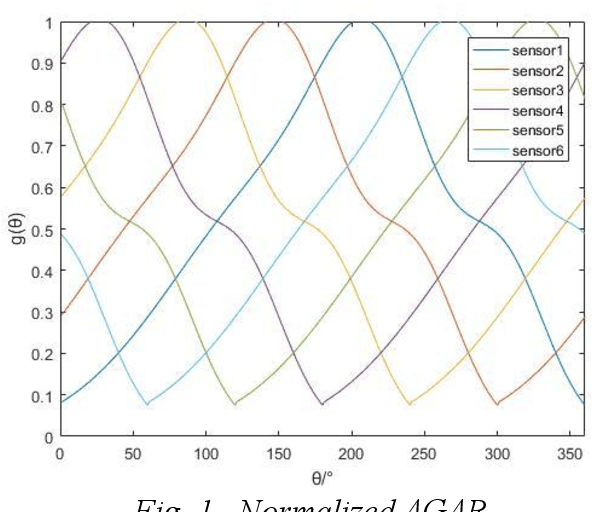
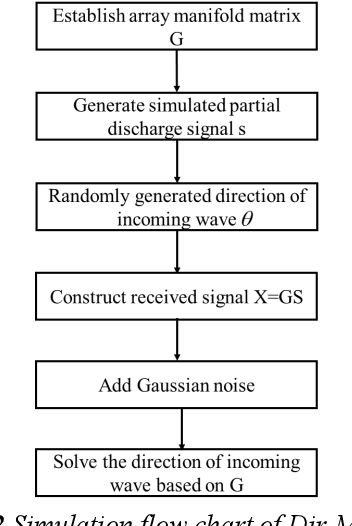

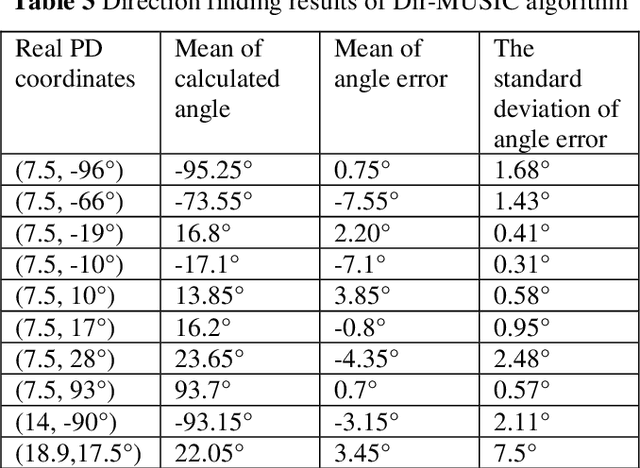
Inspection robots are widely used in the field of smart grid monitoring in substations, and partial discharge (PD) is an important sign of the insulation state of equipments. PD direction of arrival (DOA) algorithms using conventional beamforming and time difference of arrival (TDOA) require large-scale antenna arrays and high computational complexity, which make them difficult to implement on inspection robots. To address this problem, a novel directional multiple signal classification (Dir-MUSIC) algorithm for PD direction finding based on signal strength is proposed, and a miniaturized directional spiral antenna circular array is designed in this paper. First, the Dir-MUSIC algorithm is derived based on the array manifold characteristics. This method uses strength intensity information rather than the TDOA information, which could reduce the computational difficulty and the requirement of array size. Second, the effects of signal-to-noise ratio (SNR) and array manifold error on the performance of the algorithm are discussed through simulations in detail. Then according to the positioning requirements, the antenna array and its arrangement are developed, optimized, and simulation results suggested that the algorithm has reliable direction-finding performance in the form of 6 elements. Finally, the effectiveness of the algorithm is tested by using the designed spiral circular array in real scenarios. The experimental results show that the PD direction-finding error is 3.39{\deg}, which can meet the need for Partial discharge DOA estimation using inspection robots in substations.
3D Magic Mirror: Clothing Reconstruction from a Single Image via a Causal Perspective
Apr 27, 2022
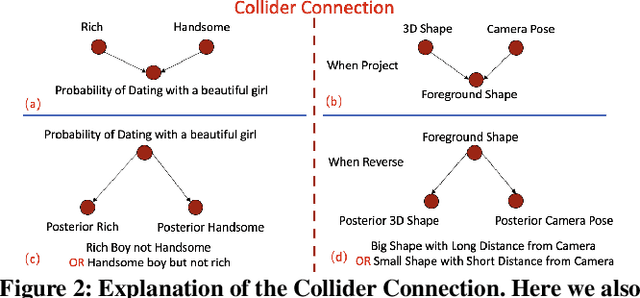

This research aims to study a self-supervised 3D clothing reconstruction method, which recovers the geometry shape, and texture of human clothing from a single 2D image. Compared with existing methods, we observe that three primary challenges remain: (1) the conventional template-based methods are limited to modeling non-rigid clothing objects, e.g., handbags and dresses, which are common in fashion images; (2) 3D ground-truth meshes of clothing are usually inaccessible due to annotation difficulties and time costs. (3) It remains challenging to simultaneously optimize four reconstruction factors, i.e., camera viewpoint, shape, texture, and illumination. The inherent ambiguity compromises the model training, such as the dilemma between a large shape with a remote camera or a small shape with a close camera. In an attempt to address the above limitations, we propose a causality-aware self-supervised learning method to adaptively reconstruct 3D non-rigid objects from 2D images without 3D annotations. In particular, to solve the inherent ambiguity among four implicit variables, i.e., camera position, shape, texture, and illumination, we study existing works and introduce an explainable structural causal map (SCM) to build our model. The proposed model structure follows the spirit of the causal map, which explicitly considers the prior template in the camera estimation and shape prediction. When optimization, the causality intervention tool, i.e., two expectation-maximization loops, is deeply embedded in our algorithm to (1) disentangle four encoders and (2) help the prior template update. Extensive experiments on two 2D fashion benchmarks, e.g., ATR, and Market-HQ, show that the proposed method could yield high-fidelity 3D reconstruction. Furthermore, we also verify the scalability of the proposed method on a fine-grained bird dataset, i.e., CUB.
Time Series Source Separation with Slow Flows
Jul 20, 2020

In this paper, we show that slow feature analysis (SFA), a common time series decomposition method, naturally fits into the flow-based models (FBM) framework, a type of invertible neural latent variable models. Building upon recent advances on blind source separation, we show that such a fit makes the time series decomposition identifiable.
Application of Federated Learning in Building a Robust COVID-19 Chest X-ray Classification Model
Apr 22, 2022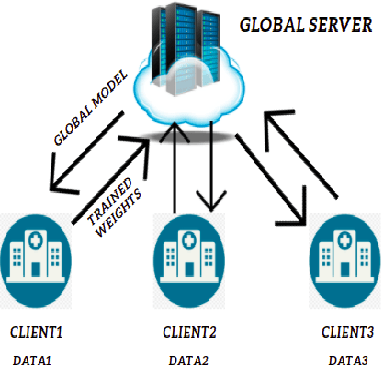
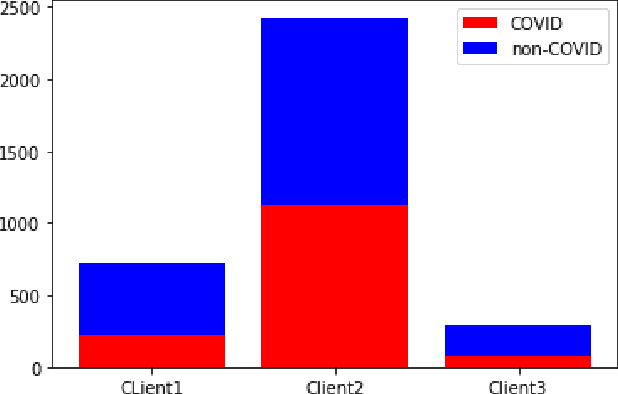
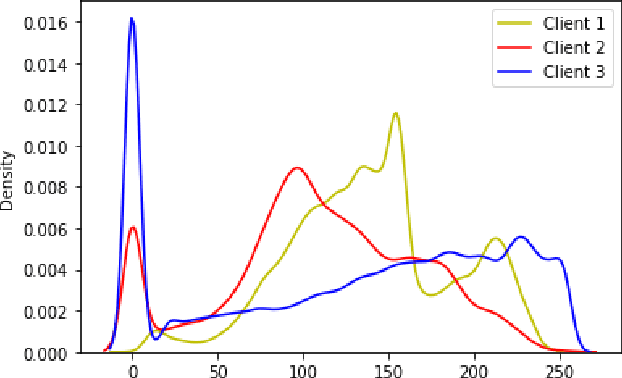
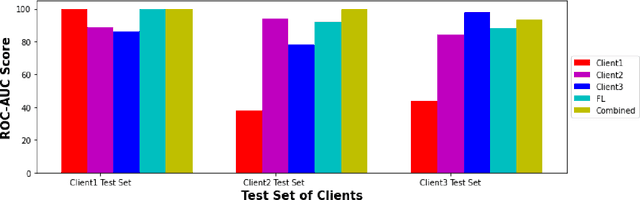
While developing artificial intelligence (AI)-based algorithms to solve problems, the amount of data plays a pivotal role - large amount of data helps the researchers and engineers to develop robust AI algorithms. In the case of building AI-based models for problems related to medical imaging, these data need to be transferred from the medical institutions where they were acquired to the organizations developing the algorithms. This movement of data involves time-consuming formalities like complying with HIPAA, GDPR, etc.There is also a risk of patients' private data getting leaked, compromising their confidentiality. One solution to these problems is using the Federated Learning framework. Federated Learning (FL) helps AI models to generalize better and create a robust AI model by using data from different sources having different distributions and data characteristics without moving all the data to a central server. In our paper, we apply the FL framework for training a deep learning model to solve a binary classification problem of predicting the presence or absence of COVID-19. We took three different sources of data and trained individual models on each source. Then we trained an FL model on the complete data and compared all the model performances. We demonstrated that the FL model performs better than the individual models. Moreover, the FL model performed at par with the model trained on all the data combined at a central server. Thus Federated Learning leads to generalized AI models without the cost of data transfer and regulatory overhead.
Decentralized Connectivity Maintenance with Time Delays using Control Barrier Functions
Mar 23, 2021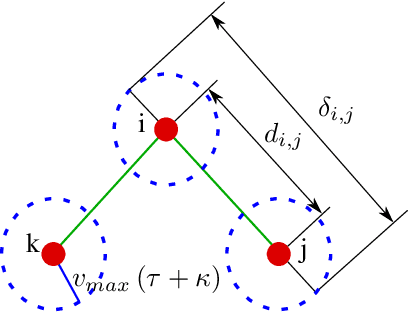

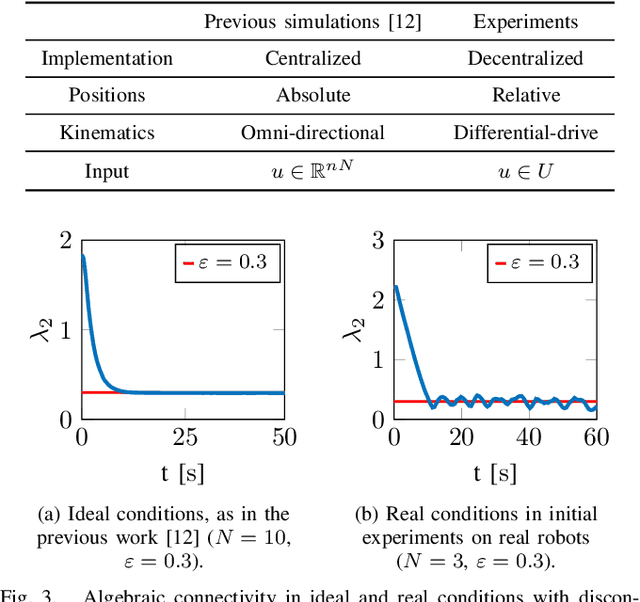
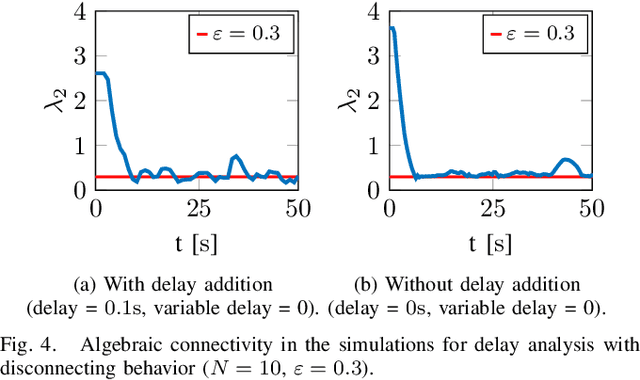
Connectivity maintenance is crucial for the real world deployment of multi-robot systems, as it ultimately allows the robots to communicate, coordinate and perform tasks in a collaborative way. A connectivity maintenance controller must keep the multi-robot system connected independently from the system's mission and in the presence of undesired real world effects such as communication delays, model errors, and computational time delays, among others. In this paper we present the implementation, on a real robotic setup, of a connectivity maintenance control strategy based on Control Barrier Functions. During experimentation, we found that the presence of communication delays has a significant impact on the performance of the controlled system, with respect to the ideal case. We propose a heuristic to counteract the effects of communication delays, and we verify its efficacy both in simulation and with physical robot experiments.
HyperDet3D: Learning a Scene-conditioned 3D Object Detector
Apr 12, 2022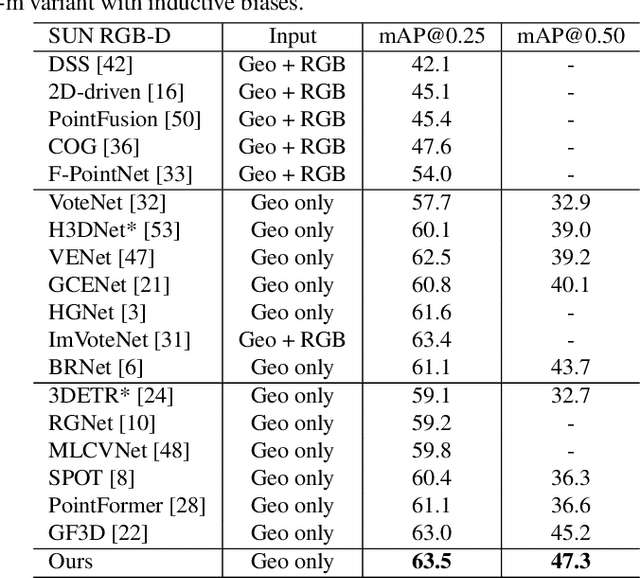
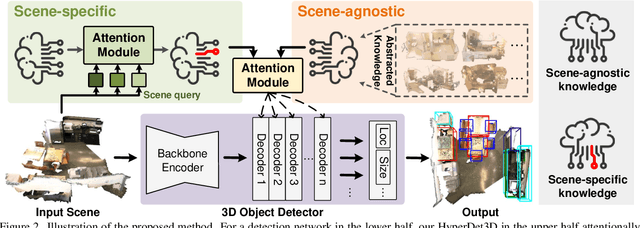

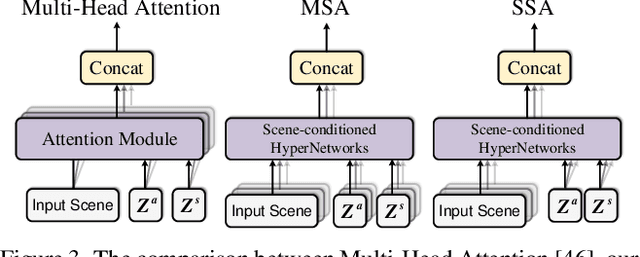
A bathtub in a library, a sink in an office, a bed in a laundry room -- the counter-intuition suggests that scene provides important prior knowledge for 3D object detection, which instructs to eliminate the ambiguous detection of similar objects. In this paper, we propose HyperDet3D to explore scene-conditioned prior knowledge for 3D object detection. Existing methods strive for better representation of local elements and their relations without scene-conditioned knowledge, which may cause ambiguity merely based on the understanding of individual points and object candidates. Instead, HyperDet3D simultaneously learns scene-agnostic embeddings and scene-specific knowledge through scene-conditioned hypernetworks. More specifically, our HyperDet3D not only explores the sharable abstracts from various 3D scenes, but also adapts the detector to the given scene at test time. We propose a discriminative Multi-head Scene-specific Attention (MSA) module to dynamically control the layer parameters of the detector conditioned on the fusion of scene-conditioned knowledge. Our HyperDet3D achieves state-of-the-art results on the 3D object detection benchmark of the ScanNet and SUN RGB-D datasets. Moreover, through cross-dataset evaluation, we show the acquired scene-conditioned prior knowledge still takes effect when facing 3D scenes with domain gap.
Automatic detection of glaucoma via fundus imaging and artificial intelligence: A review
Apr 12, 2022Glaucoma is a leading cause of irreversible vision impairment globally and cases are continuously rising worldwide. Early detection is crucial, allowing timely intervention which can prevent further visual field loss. To detect glaucoma, examination of the optic nerve head via fundus imaging can be performed, at the centre of which is the assessment of the optic cup and disc boundaries. Fundus imaging is non-invasive and low-cost; however, the image examination relies on subjective, time-consuming, and costly expert assessments. A timely question to ask is can artificial intelligence mimic glaucoma assessments made by experts. Namely, can artificial intelligence automatically find the boundaries of the optic cup and disc (providing a so-called segmented fundus image) and then use the segmented image to identify glaucoma with high accuracy. We conducted a comprehensive review on artificial intelligence-enabled glaucoma detection frameworks that produce and use segmented fundus images. We found 28 papers and identified two main approaches: 1) logical rule-based frameworks, based on a set of simplistic decision rules; and 2) machine learning/statistical modelling based frameworks. We summarise the state-of-art of the two approaches and highlight the key hurdles to overcome for artificial intelligence-enabled glaucoma detection frameworks to be translated into clinical practice.
Physics-constrained Unsupervised Learning of Partial Differential Equations using Meshes
Mar 30, 2022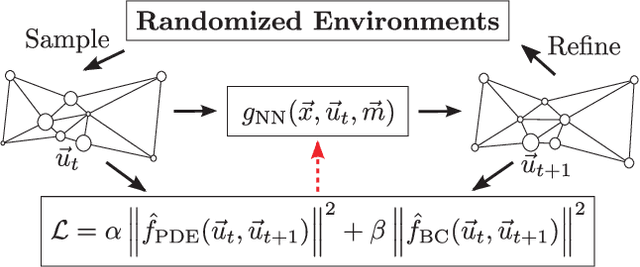

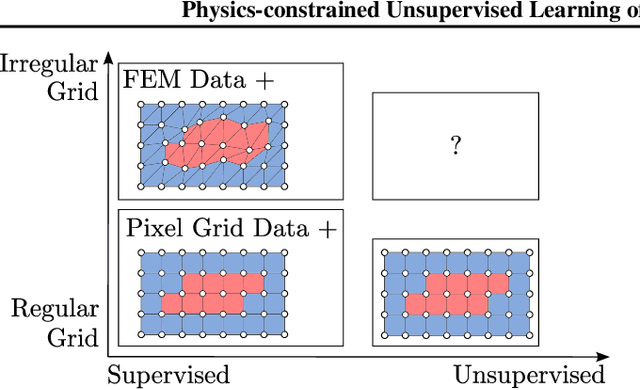
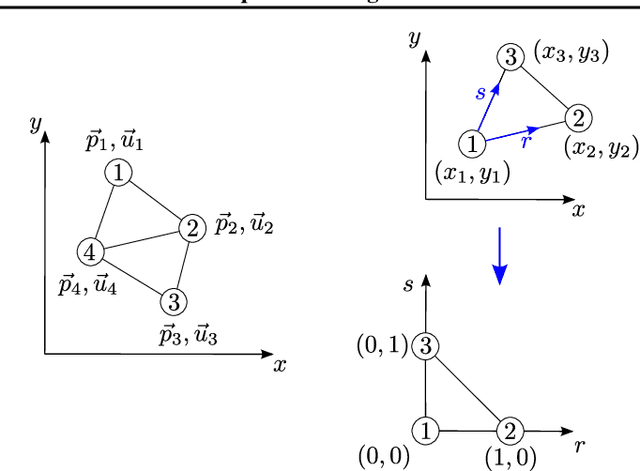
Enhancing neural networks with knowledge of physical equations has become an efficient way of solving various physics problems, from fluid flow to electromagnetism. Graph neural networks show promise in accurately representing irregularly meshed objects and learning their dynamics, but have so far required supervision through large datasets. In this work, we represent meshes naturally as graphs, process these using Graph Networks, and formulate our physics-based loss to provide an unsupervised learning framework for partial differential equations (PDE). We quantitatively compare our results to a classical numerical PDE solver, and show that our computationally efficient approach can be used as an interactive PDE solver that is adjusting boundary conditions in real-time and remains sufficiently close to the baseline solution. Our inherently differentiable framework will enable the application of PDE solvers in interactive settings, such as model-based control of soft-body deformations, or in gradient-based optimization methods that require a fully differentiable pipeline.
On the throughput of the common target area for robotic swarm strategies -- extended version
Jan 23, 2022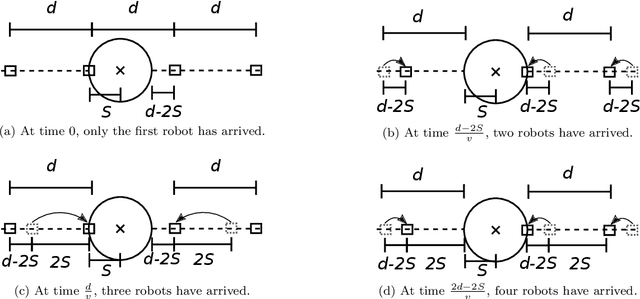
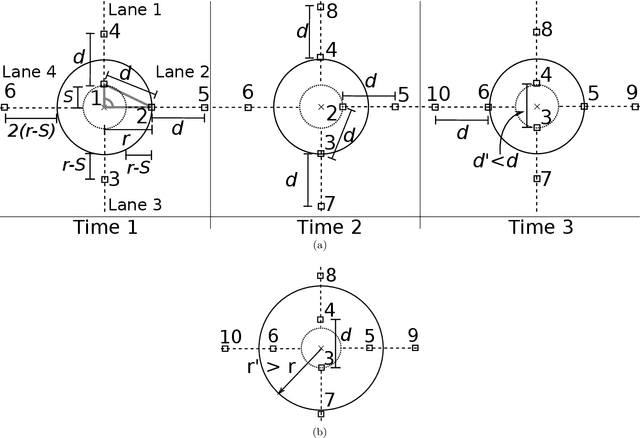
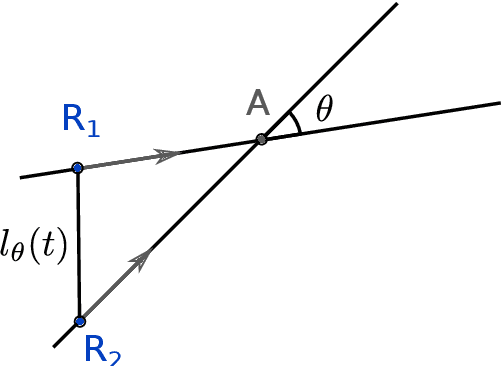
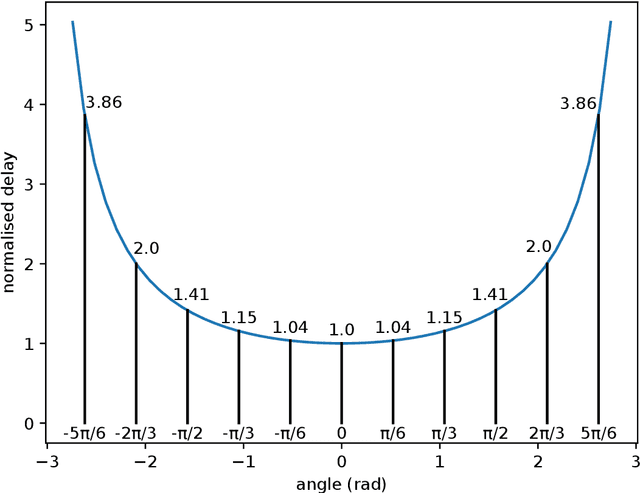
A robotic swarm may encounter traffic congestion when many robots simultaneously attempt to reach the same area. For solving that efficiently, robots must execute decentralised traffic control algorithms. In this work, we propose a measure for evaluating the access efficiency of a common target area as the number of robots in the swarm rises: the common target area throughput. We demonstrate that the throughput of a target region with a limited area as the time tends to infinity -- the asymptotic throughput -- is finite, opposed to the relation arrival time at target per number of robots that tends to infinity. Using this measure, we can analytically compare the effectiveness of different algorithms. In particular, we propose and formally evaluate three different theoretical strategies for getting to a circular target area: (i) forming parallel queues towards the target area, (ii) forming a hexagonal packing through a corridor going to the target, and (iii) making multiple curved trajectories towards the boundary of the target area. We calculate the throughput for a fixed time and the asymptotic throughput for these strategies. Additionally, we corroborate these results by simulations, showing that when an algorithm has higher throughput, its arrival time per number of robots is lower. Thus, we conclude that using throughput is well suited for comparing congestion algorithms for a common target area in robotic swarms even if we do not have their closed asymptotic equation.
InsightNet: non-contact blood pressure measuring network based on face video
Mar 07, 2022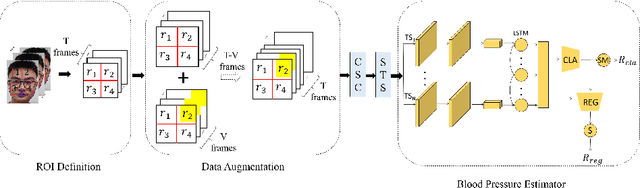
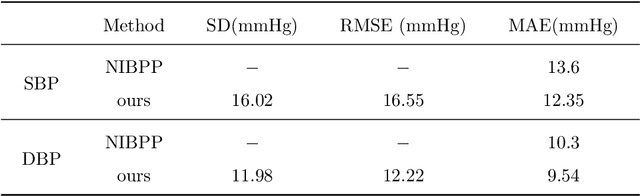

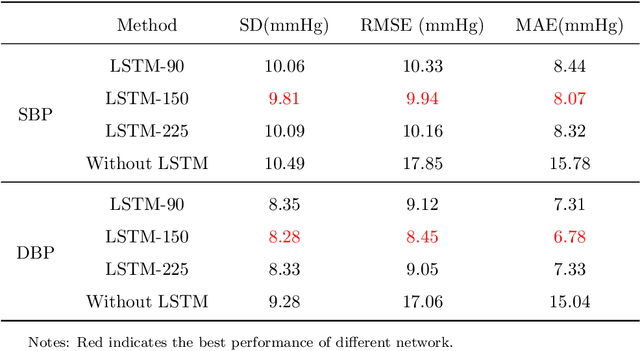
Blood pressure indicates cardiac function and peripheral vascular resistance and is critical for disease diagnosis. Traditionally, blood pressure data are mainly acquired through contact sensors, which require high maintenance and may be inconvenient and unfriendly to some people (e.g., burn patients). In this paper, an efficient non-contact blood pressure measurement network based on face videos is proposed for the first time. An innovative oversampling training strategy is proposed to handle the unbalanced data distribution. The input video sequences are first normalized and converted to our proposed YUVT color space. Then, the Spatio-temporal slicer encodes it into a multi-domain Spatio-temporal mapping. Finally, the neural network computation module, used for high-dimensional feature extraction of the multi-domain spatial feature mapping, after which the extracted high-dimensional features are used to enhance the time-domain feature association using LSTM, is computed by the blood pressure classifier to obtain the blood pressure measurement intervals. Combining the output of feature extraction and the result after classification, the blood pressure calculator, calculates the blood pressure measurement values. The solution uses a blood pressure classifier to calculate blood pressure intervals, which can help the neural network distinguish between the high-dimensional features of different blood pressure intervals and alleviate the overfitting phenomenon. It can also locate the blood pressure intervals, correct the final blood pressure values and improve the network performance. Experimental results on two datasets show that the network outperforms existing state-of-the-art methods.