 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bringing Rolling Shutter Images Alive with Dual Reversed Distortion
Mar 12, 2022
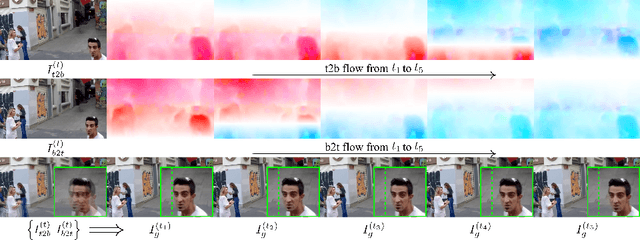

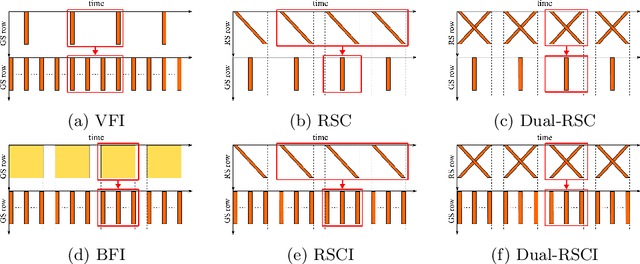
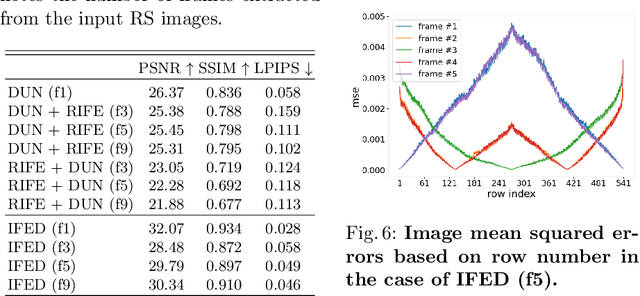
Rolling shutter (RS) distortion can be interpreted as the result of picking a row of pixels from instant global shutter (GS) frames over time during the exposure of the RS camera. This means that the information of each instant GS frame is partially, yet sequentially, embedded into the row-dependent distortion. Inspired by this fact, we address the challenging task of reversing this process, i.e., extracting undistorted GS frames from images suffering from RS distortion. However, since RS distortion is coupled with other factors such as readout settings and the relative velocity of scene elements to the camera, models that only exploit the geometric correlation between temporally adjacent images suffer from poor generality in processing data with different readout settings and dynamic scenes with both camera motion and object motion. In this paper, instead of two consecutive frames, we propose to exploit a pair of images captured by dual RS cameras with reversed RS directions for this highly challenging task. Grounded on the symmetric and complementary nature of dual reversed distortion, we develop a novel end-to-end model, IFED, to generate dual optical flow sequence through iterative learning of the velocity field during the RS time. Extensive experimental results demonstrate that IFED is superior to naive cascade schemes, as well as the state-of-the-art which utilizes adjacent RS images. Most importantly, although it is trained on a synthetic dataset, IFED is shown to be effective at retrieving GS frame sequences from real-world RS distorted images of dynamic scenes.
Flexible LED Index Modulation for MIMO Optical Wireless Communications
Apr 14, 2022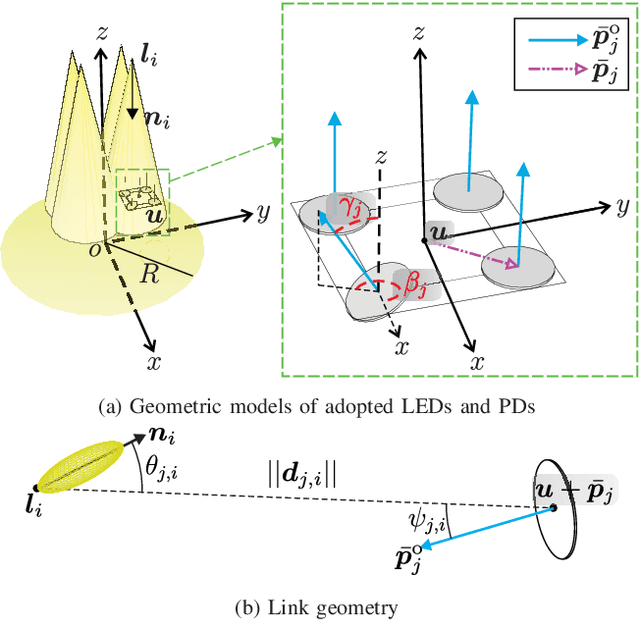
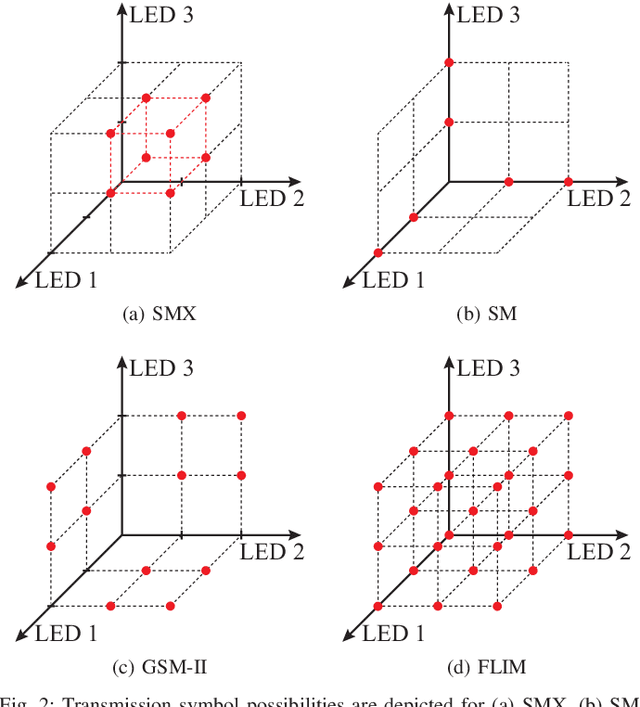
The limited bandwidth of optical wireless communication (OWC) front-end devices motivates the use of multiple-input-multiple-output (MIMO) techniques to enhance data rates. It is known that very high multiplexing gains could be achieved by spatial multiplexing (SMX) in exchange for exhaustive detection complexity. Alternatively, in spatial modulation (SM), a single light emitting diode (LED) is activated per time instance where information is carried by both the signal and the LED index. Since only an LED is active, both transmitter (TX) and receiver (RX) complexity reduces significantly while retaining the information transmission in the spatial domain. However, significant spectral efficiency losses occur in SM compared to SMX. In this paper, we propose a technique which adopts the advantages of both systems. Accordingly, the proposed flexible LED index modulation (FLIM) technique harnesses the inactive state of the LEDs as a transmit symbol. Therefore, the number of active LEDs changes in each transmission, unlike conventional techniques. Moreover, the system complexity is reduced by employing a linear minimum mean squared error (MMSE) equalizer and an angle perturbed receiver at the RX. Numerical results show that FLIM outperforms the reference systems by at least 6 dB in the low and medium/high spectral efficiency regions.
Territory Design for Dynamic Multi-Period Vehicle Routing Problem with Time Windows
Dec 18, 2020
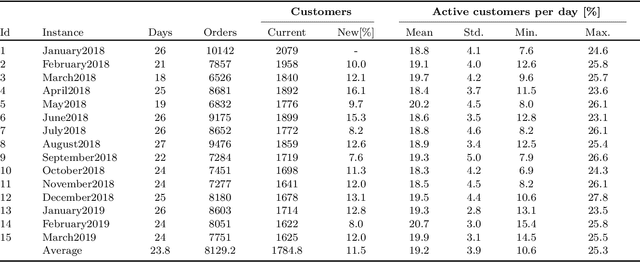
This study introduces the Territory Design for Dynamic Multi-Period Vehicle Routing Problem with Time Windows (TD-DMPVRPTW), motivated by a real-world application at a food company's distribution center. This problem deals with the design of contiguous and compact territories for delivery of orders from a depot to a set of customers, with time windows, over a multi-period planning horizon. Customers and their demands vary dynamically over time. The problem is modeled as a mixed-integer linear program (MILP) and solved by a proposed heuristic. The heuristic solutions are compared with the proposed MILP solutions on a set of small artificial instances and the food company's solutions on a set of real-world instances. Computational results show that the proposed algorithm can yield high-quality solutions within moderate running times.
Large-scale Stochastic Optimization of NDCG Surrogates for Deep Learning with Provable Convergence
Apr 06, 2022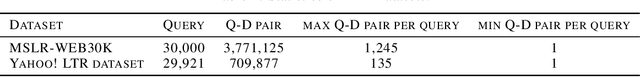

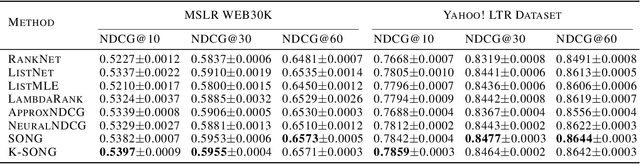

NDCG, namely Normalized Discounted Cumulative Gain, is a widely used ranking metric in information retrieval and machine learning. However, efficient and provable stochastic methods for maximizing NDCG are still lacking, especially for deep models. In this paper, we propose a principled approach to optimize NDCG and its top-$K$ variant. First, we formulate a novel compositional optimization problem for optimizing the NDCG surrogate, and a novel bilevel compositional optimization problem for optimizing the top-$K$ NDCG surrogate. Then, we develop efficient stochastic algorithms with provable convergence guarantees for the non-convex objectives. Different from existing NDCG optimization methods, the per-iteration complexity of our algorithms scales with the mini-batch size instead of the number of total items. To improve the effectiveness for deep learning, we further propose practical strategies by using initial warm-up and stop gradient operator. Experimental results on multiple datasets demonstrate that our methods outperform prior ranking approaches in terms of NDCG. To the best of our knowledge, this is the first time that stochastic algorithms are proposed to optimize NDCG with a provable convergence guarantee.
Fast algorithm for overcomplete order-3 tensor decomposition
Feb 14, 2022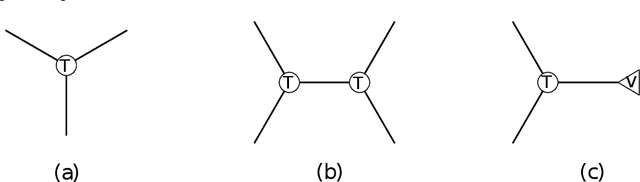
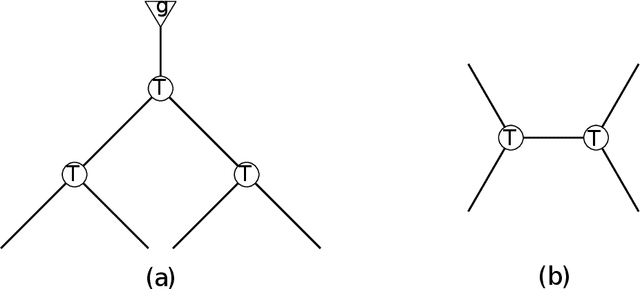
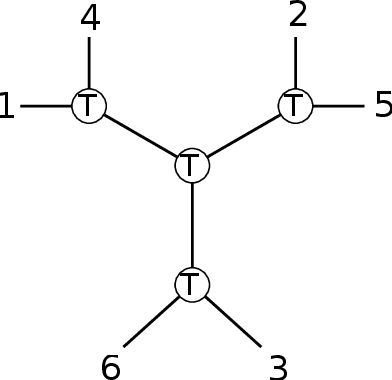
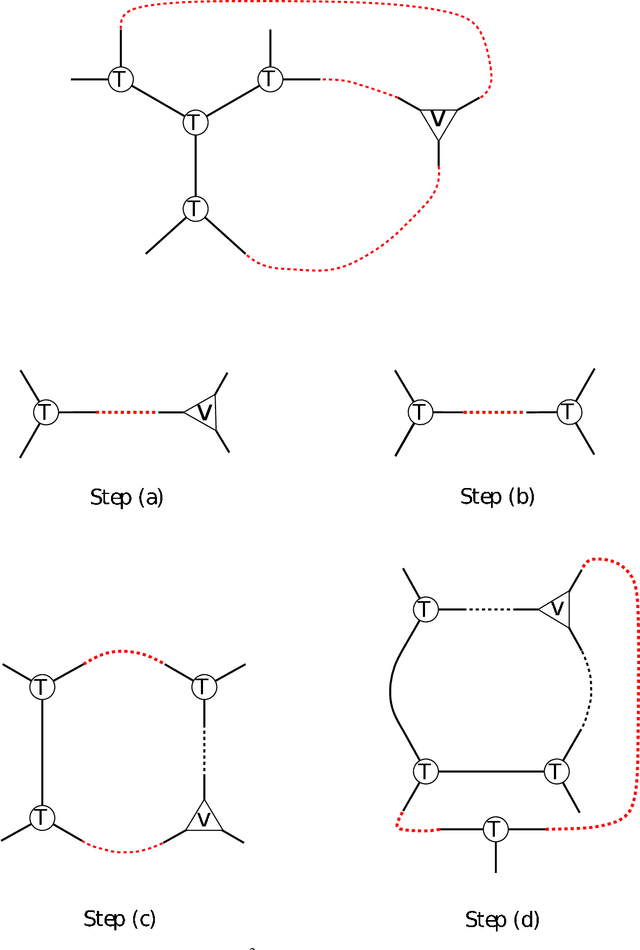
We develop the first fast spectral algorithm to decompose a random third-order tensor over R^d of rank up to O(d^{3/2}/polylog(d)). Our algorithm only involves simple linear algebra operations and can recover all components in time O(d^{6.05}) under the current matrix multiplication time. Prior to this work, comparable guarantees could only be achieved via sum-of-squares [Ma, Shi, Steurer 2016]. In contrast, fast algorithms [Hopkins, Schramm, Shi, Steurer 2016] could only decompose tensors of rank at most O(d^{4/3}/polylog(d)). Our algorithmic result rests on two key ingredients. A clean lifting of the third-order tensor to a sixth-order tensor, which can be expressed in the language of tensor networks. A careful decomposition of the tensor network into a sequence of rectangular matrix multiplications, which allows us to have a fast implementation of the algorithm.
Boosting the Learning for Ranking Patterns
Mar 05, 2022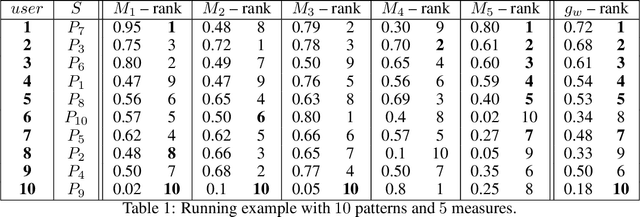
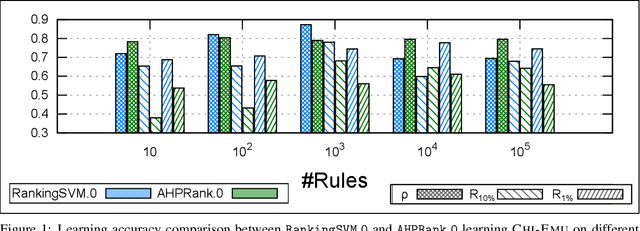

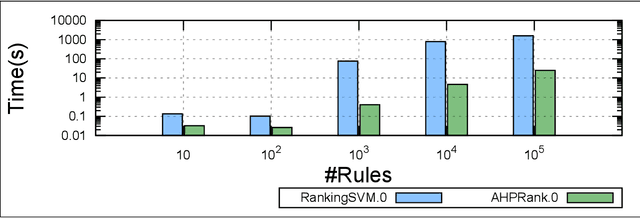
Discovering relevant patterns for a particular user remains a challenging tasks in data mining. Several approaches have been proposed to learn user-specific pattern ranking functions. These approaches generalize well, but at the expense of the running time. On the other hand, several measures are often used to evaluate the interestingness of patterns, with the hope to reveal a ranking that is as close as possible to the user-specific ranking. In this paper, we formulate the problem of learning pattern ranking functions as a multicriteria decision making problem. Our approach aggregates different interestingness measures into a single weighted linear ranking function, using an interactive learning procedure that operates in either passive or active modes. A fast learning step is used for eliciting the weights of all the measures by mean of pairwise comparisons. This approach is based on Analytic Hierarchy Process (AHP), and a set of user-ranked patterns to build a preference matrix, which compares the importance of measures according to the user-specific interestingness. A sensitivity based heuristic is proposed for the active learning mode, in order to insure high quality results with few user ranking queries. Experiments conducted on well-known datasets show that our approach significantly reduces the running time and returns precise pattern ranking, while being robust to user-error compared with state-of-the-art approaches.
Improving Distortion Robustness of Self-supervised Speech Processing Tasks with Domain Adaptation
Mar 30, 2022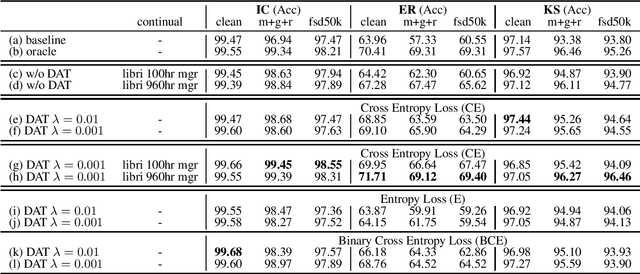
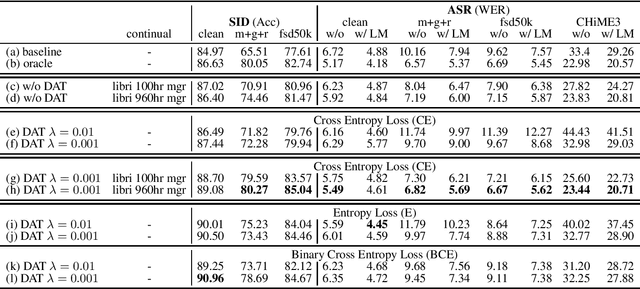
Speech distortions are a long-standing problem that degrades the performance of supervisely trained speech processing models. It is high time that we enhance the robustness of speech processing models to obtain good performance when encountering speech distortions while not hurting the original performance on clean speech. In this work, we propose to improve the robustness of speech processing models by domain adversarial training (DAT). We conducted experiments based on the SUPERB framework on five different speech processing tasks. In case we do not always have knowledge of the distortion types for speech data, we analyzed the binary-domain and multi-domain settings, where the former treats all distorted speech as one domain, and the latter views different distortions as different domains. In contrast to supervised training methods, we obtained promising results in target domains where speech data is distorted with different distortions including new unseen distortions introduced during testing.
Big-means: Less is More for K-means Clustering
Apr 14, 2022
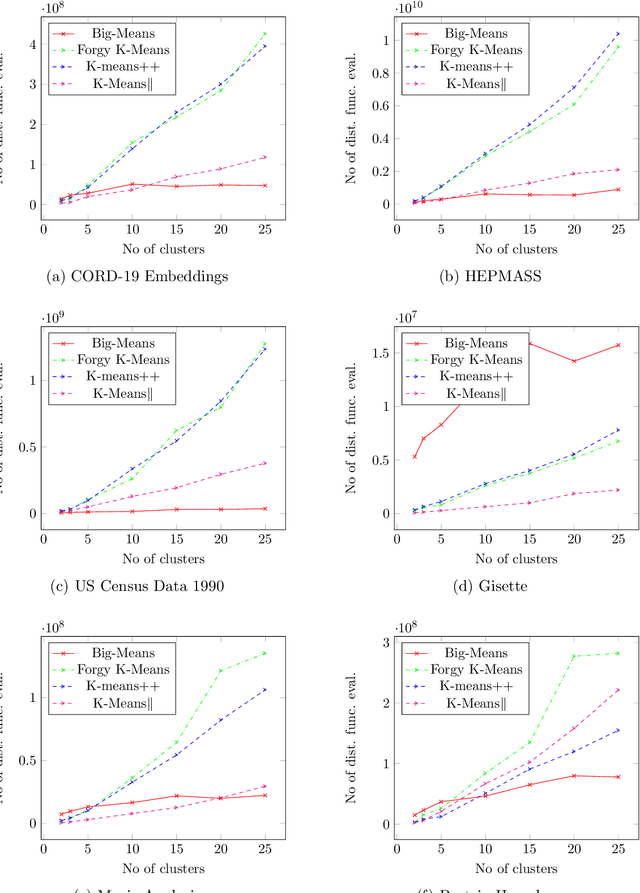

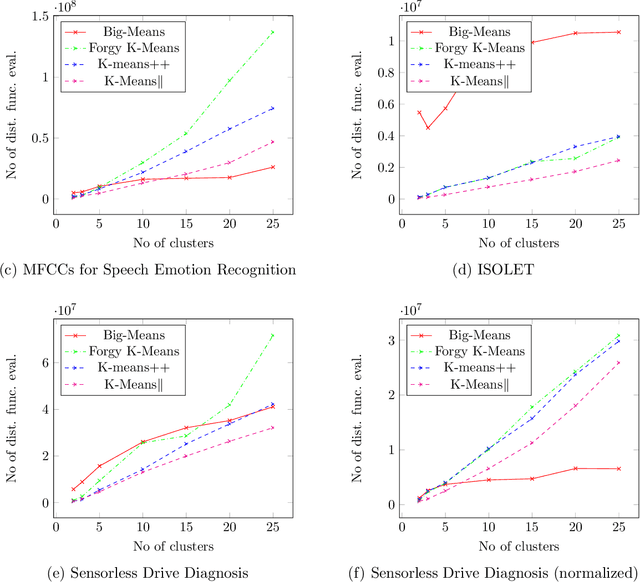
K-means clustering plays a vital role in data mining. However, its performance drastically drops when applied to huge amounts of data. We propose a new heuristic that is built on the basis of regular K-means for faster and more accurate big data clustering using the "less is more" and MSSC decomposition approaches. The main advantage of the proposed algorithm is that it naturally turns the K-means local search into global one through the process of decomposition of the MSSC problem. On one hand, decomposition of the MSSC problem into smaller subproblems reduces the computational complexity and allows for their parallel processing. On the other hand, the MSSC decomposition provides a new method for the natural data-driven shaking of the incumbent solution while introducing a new neighborhood structure for the solution of the MSSC problem. This leads to a new heuristic that improves K-means in big data conditions. The scalability of the algorithm to big data can be easily adjusted by choosing the appropriate number of subproblems and their size. The proposed algorithm is both scalable and accurate. In our experiments it outperforms all recent state-of-the-art algorithms for the MSSC in terms of time as well as the solution quality.
Approximating a deep reinforcement learning docking agent using linear model trees
Mar 01, 2022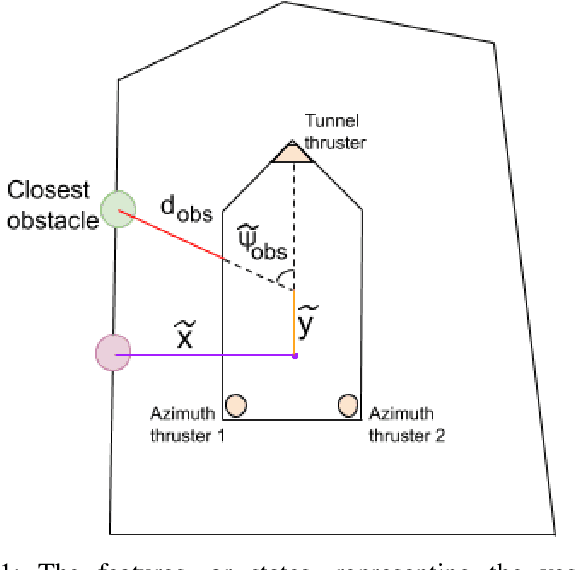
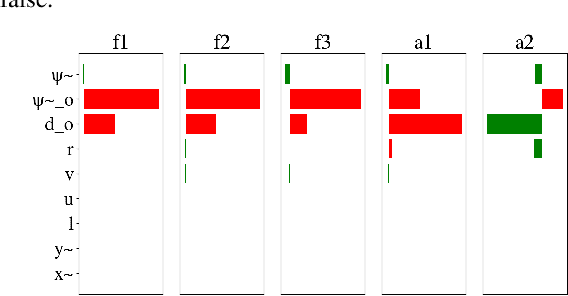
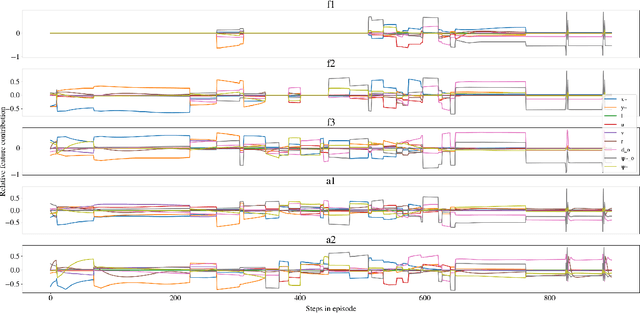
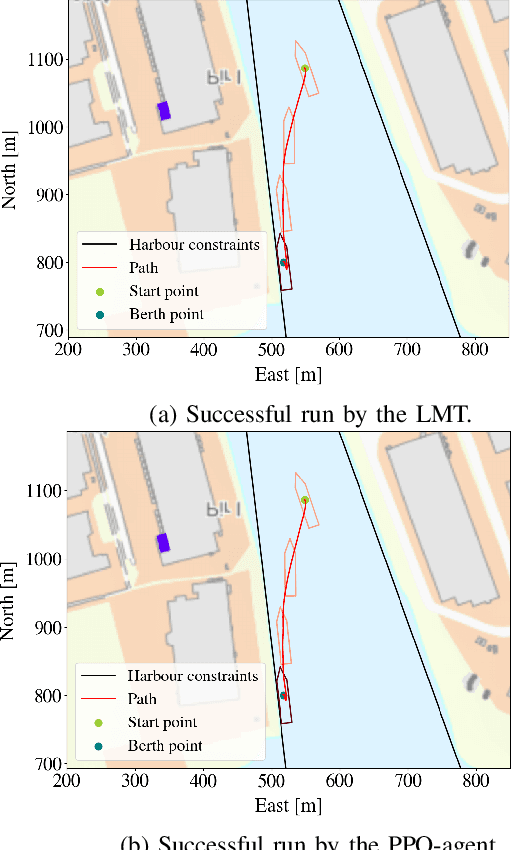
Deep reinforcement learning has led to numerous notable results in robotics. However, deep neural networks (DNNs) are unintuitive, which makes it difficult to understand their predictions and strongly limits their potential for real-world applications due to economic, safety, and assurance reasons. To remedy this problem, a number of explainable AI methods have been presented, such as SHAP and LIME, but these can be either be too costly to be used in real-time robotic applications or provide only local explanations. In this paper, the main contribution is the use of a linear model tree (LMT) to approximate a DNN policy, originally trained via proximal policy optimization(PPO), for an autonomous surface vehicle with five control inputs performing a docking operation. The two main benefits of the proposed approach are: a) LMTs are transparent which makes it possible to associate directly the outputs (control actions, in our case) with specific values of the input features, b) LMTs are computationally efficient and can provide information in real-time. In our simulations, the opaque DNN policy controls the vehicle and the LMT runs in parallel to provide explanations in the form of feature attributions. Our results indicate that LMTs can be a useful component within digital assurance frameworks for autonomous ships.
Non-linear manifold ROM with Convolutional Autoencoders and Reduced Over-Collocation method
Mar 01, 2022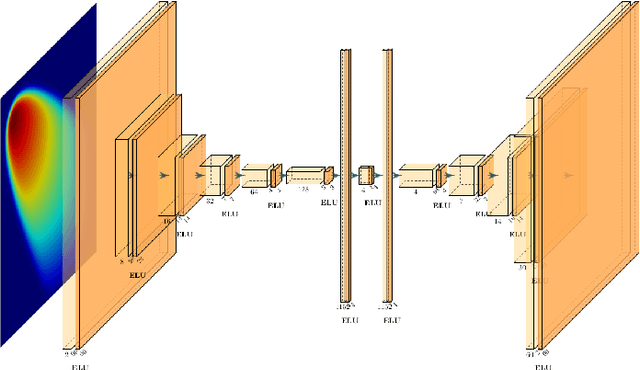


Non-affine parametric dependencies, nonlinearities and advection-dominated regimes of the model of interest can result in a slow Kolmogorov n-width decay, which precludes the realization of efficient reduced-order models based on linear subspace approximations. Among the possible solutions, there are purely data-driven methods that leverage autoencoders and their variants to learn a latent representation of the dynamical system, and then evolve it in time with another architecture. Despite their success in many applications where standard linear techniques fail, more has to be done to increase the interpretability of the results, especially outside the training range and not in regimes characterized by an abundance of data. Not to mention that none of the knowledge on the physics of the model is exploited during the predictive phase. In order to overcome these weaknesses, we implement the non-linear manifold method introduced by Carlberg et al [37] with hyper-reduction achieved through reduced over-collocation and teacher-student training of a reduced decoder. We test the methodology on a 2d non-linear conservation law and a 2d shallow water models, and compare the results obtained with a purely data-driven method for which the dynamics is evolved in time with a long-short term memory network.