 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SemanticCAP: Chromatin Accessibility Prediction Enhanced by Features Learning from a Language Model
Apr 06, 2022

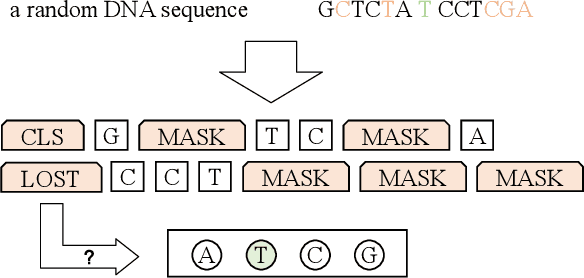
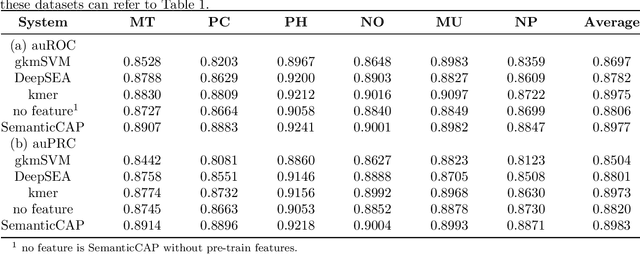
A large number of inorganic and organic compounds are able to bind DNA and form complexes, among which drug-related molecules are important. Chromatin accessibility changes not only directly affects drug-DNA interactions, but also promote or inhibit the expression of critical genes associated with drug resistance by affecting the DNA binding capacity of TFs and transcriptional regulators. However, Biological experimental techniques for measuring it are expensive and time consuming. In recent years, several kinds of computational methods have been proposed to identify accessible regions of the genome. Existing computational models mostly ignore the contextual information of bases in gene sequences. To address these issues, we proposed a new solution named SemanticCAP. It introduces a gene language model which models the context of gene sequences, thus being able to provide an effective representation of a certain site in gene sequences. Basically, we merge the features provided by the gene language model into our chromatin accessibility model. During the process, we designed some methods to make feature fusion smoother. Compared with other systems under public benchmarks, our model proved to have better performance.
Evolutionary Diversity Optimisation for The Traveling Thief Problem
Apr 06, 2022

There has been a growing interest in the evolutionary computation community to compute a diverse set of high-quality solutions for a given optimisation problem. This can provide the practitioners with invaluable information about the solution space and robustness against imperfect modelling and minor problems' changes. It also enables the decision-makers to involve their interests and choose between various solutions. In this study, we investigate for the first time a prominent multi-component optimisation problem, namely the Traveling Thief Problem (TTP), in the context of evolutionary diversity optimisation. We introduce a bi-level evolutionary algorithm to maximise the structural diversity of the set of solutions. Moreover, we examine the inter-dependency among the components of the problem in terms of structural diversity and empirically determine the best method to obtain diversity. We also conduct a comprehensive experimental investigation to examine the introduced algorithm and compare the results to another recently introduced framework based on the use of Quality Diversity (QD). Our experimental results show a significant improvement of the QD approach in terms of structural diversity for most TTP benchmark instances.
Big-means: Less is More for K-means Clustering
Apr 14, 2022
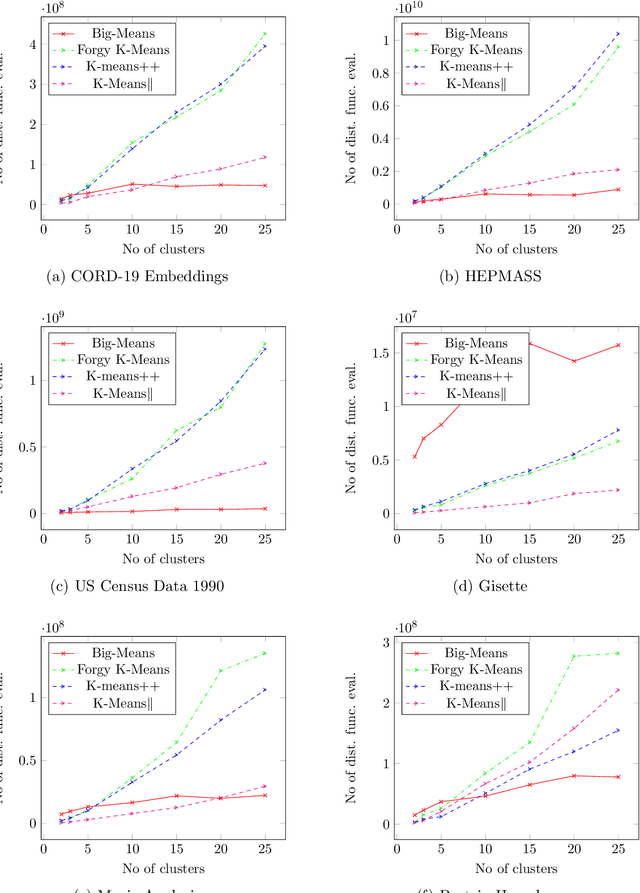

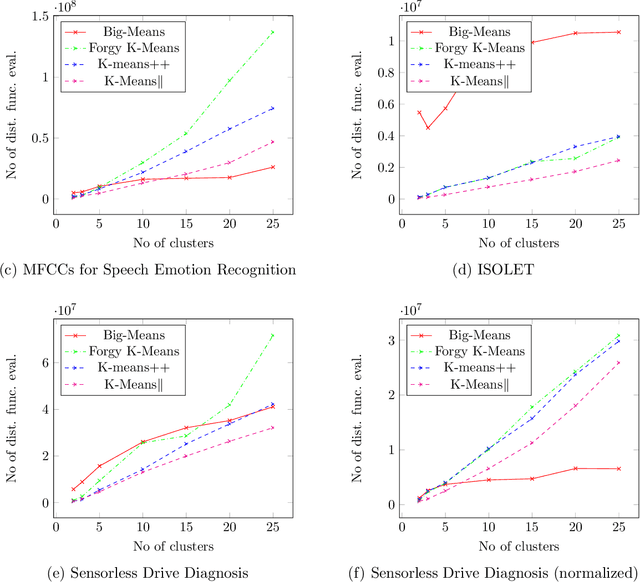
K-means clustering plays a vital role in data mining. However, its performance drastically drops when applied to huge amounts of data. We propose a new heuristic that is built on the basis of regular K-means for faster and more accurate big data clustering using the "less is more" and MSSC decomposition approaches. The main advantage of the proposed algorithm is that it naturally turns the K-means local search into global one through the process of decomposition of the MSSC problem. On one hand, decomposition of the MSSC problem into smaller subproblems reduces the computational complexity and allows for their parallel processing. On the other hand, the MSSC decomposition provides a new method for the natural data-driven shaking of the incumbent solution while introducing a new neighborhood structure for the solution of the MSSC problem. This leads to a new heuristic that improves K-means in big data conditions. The scalability of the algorithm to big data can be easily adjusted by choosing the appropriate number of subproblems and their size. The proposed algorithm is both scalable and accurate. In our experiments it outperforms all recent state-of-the-art algorithms for the MSSC in terms of time as well as the solution quality.
Performer: A Novel PPG to ECG Reconstruction Transformer For a Digital Biomarker of Cardiovascular Disease Detection
Apr 27, 2022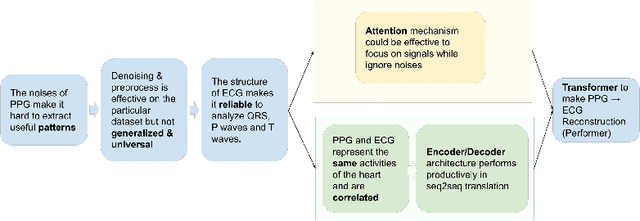
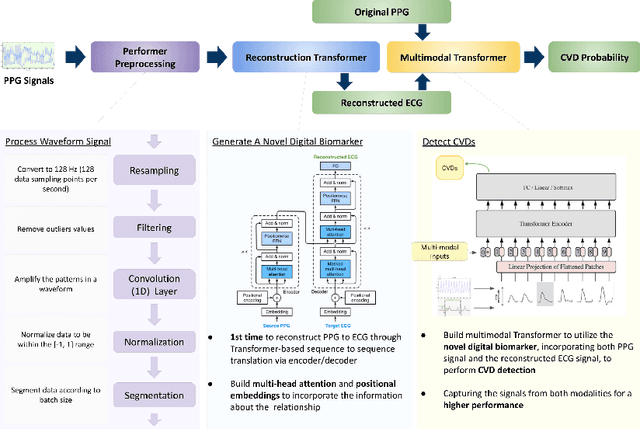
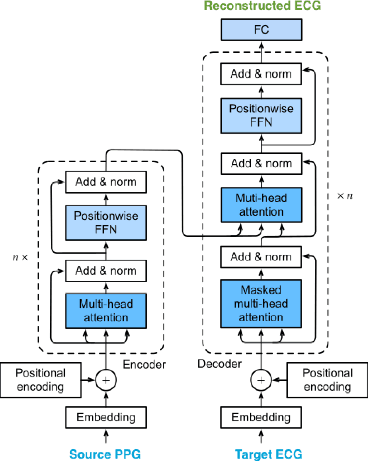
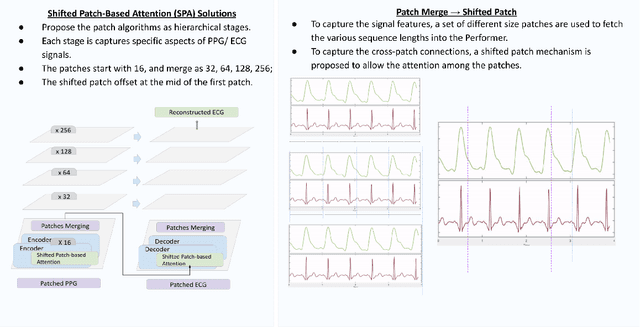
Cardiovascular diseases (CVDs) have become the top one cause of death; three-quarters of these deaths occur in lower-income communities. Electrocardiography (ECG), an electrical measurement capturing the cardiac activities, is a gold-standard to diagnose CVDs. However, ECG is infeasible for continuous cardiac monitoring due to its requirement for user participation. Meanwhile, photoplethysmography (PPG) is easy to collect, but the limited accuracy constrains its clinical usage. In this research, a novel Transformer-based architecture, Performer, is invented to reconstruct ECG from PPG and to create a novel digital biomarker, PPG along with its reconstructed ECG, as multiple modalities for CVD detection. This architecture, for the first time, performs Transformer sequence to sequence translation on biomedical waveforms, while also utilizing the advantages of the easily accessible PPG and the well-studied base of ECG. Shifted Patch-based Attention (SPA) is created to maximize the signal features by fetching the various sequence lengths as hierarchical stages into the training while also capturing cross-patch connections through the shifted patch mechanism. This architecture generates a state-of-the-art performance of 0.29 RMSE for reconstructing ECG from PPG, achieving an average of 95.9% diagnosis for CVDs on the MIMIC III dataset and 75.9% for diabetes on the PPG-BP dataset. Performer, along with its novel digital biomarker, offers a low-cost and non-invasive solution for continuous cardiac monitoring, only requiring the easily extractable PPG data to reconstruct the not-as-accessible ECG data. As a prove of concept, an earring wearable, named PEARL (prototype), is designed to scale up the point-of-care (POC) healthcare system.
Large-scale Stochastic Optimization of NDCG Surrogates for Deep Learning with Provable Convergence
Apr 06, 2022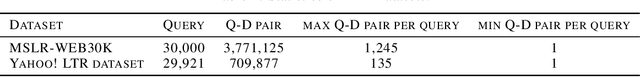

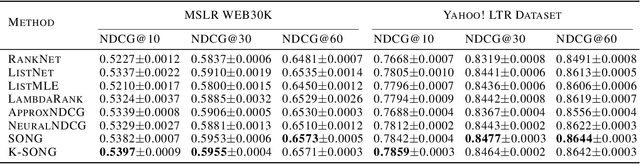

NDCG, namely Normalized Discounted Cumulative Gain, is a widely used ranking metric in information retrieval and machine learning. However, efficient and provable stochastic methods for maximizing NDCG are still lacking, especially for deep models. In this paper, we propose a principled approach to optimize NDCG and its top-$K$ variant. First, we formulate a novel compositional optimization problem for optimizing the NDCG surrogate, and a novel bilevel compositional optimization problem for optimizing the top-$K$ NDCG surrogate. Then, we develop efficient stochastic algorithms with provable convergence guarantees for the non-convex objectives. Different from existing NDCG optimization methods, the per-iteration complexity of our algorithms scales with the mini-batch size instead of the number of total items. To improve the effectiveness for deep learning, we further propose practical strategies by using initial warm-up and stop gradient operator. Experimental results on multiple datasets demonstrate that our methods outperform prior ranking approaches in terms of NDCG. To the best of our knowledge, this is the first time that stochastic algorithms are proposed to optimize NDCG with a provable convergence guarantee.
Approximate Optimal Filter for Linear Gaussian Time-invariant Systems
Mar 09, 2021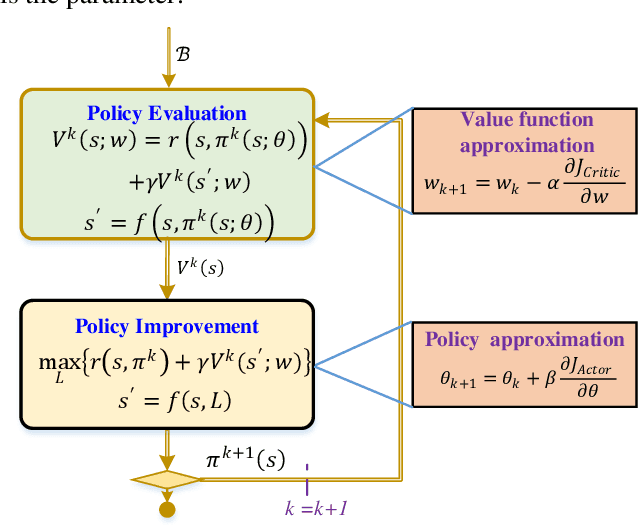
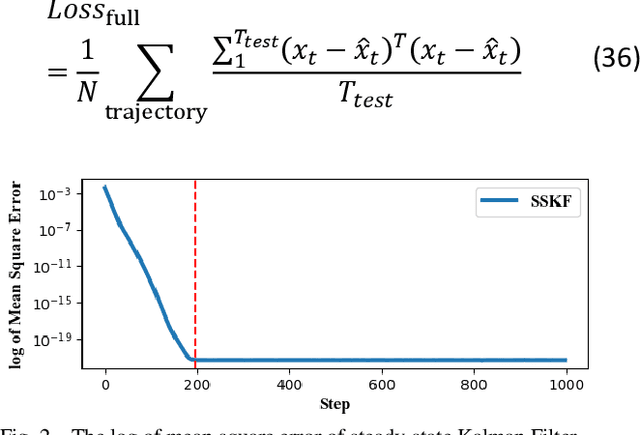

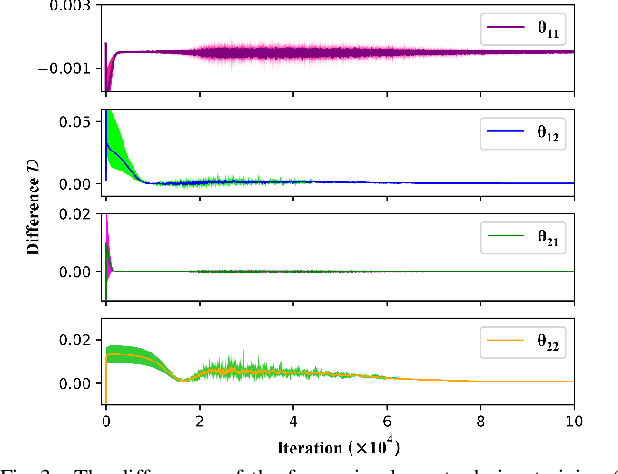
State estimation is critical to control systems, especially when the states cannot be directly measured. This paper presents an approximate optimal filter, which enables to use policy iteration technique to obtain the steady-state gain in linear Gaussian time-invariant systems. This design transforms the optimal filtering problem with minimum mean square error into an optimal control problem, called Approximate Optimal Filtering (AOF) problem. The equivalence holds given certain conditions about initial state distributions and policy formats, in which the system state is the estimation error, control input is the filter gain, and control objective function is the accumulated estimation error. We present a policy iteration algorithm to solve the AOF problem in steady-state. A classic vehicle state estimation problem finally evaluates the approximate filter. The results show that the policy converges to the steady-state Kalman gain, and its accuracy is within 2 %.
On the throughput of the common target area for robotic swarm strategies -- extended version
Jan 25, 2022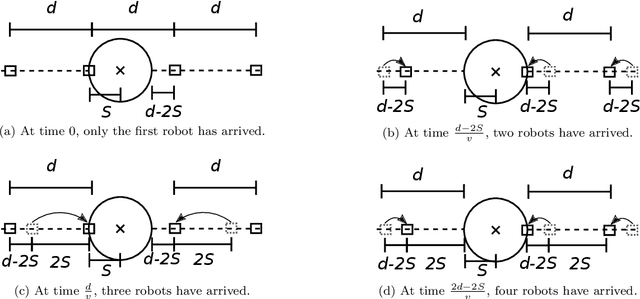
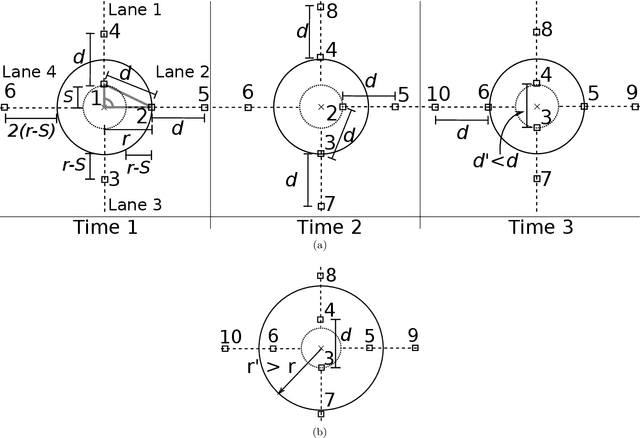
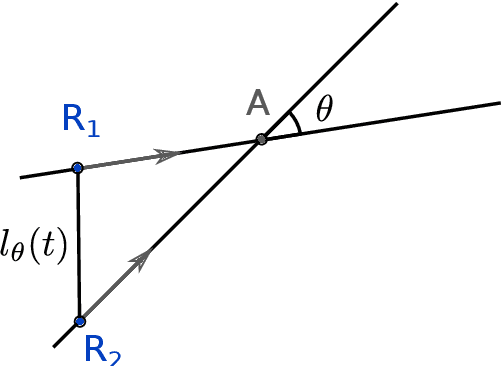
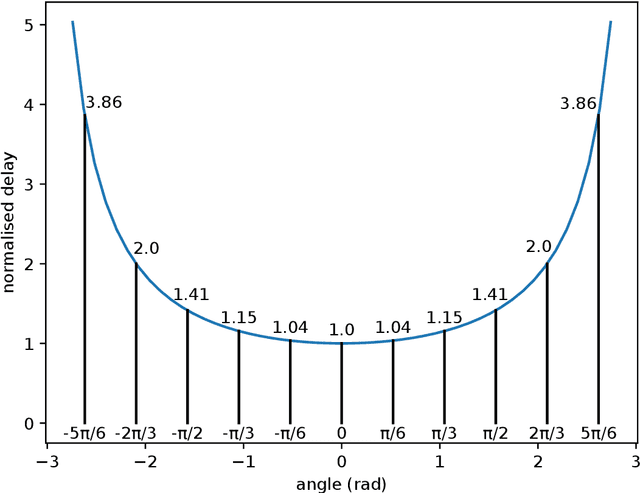
A robotic swarm may encounter traffic congestion when many robots simultaneously attempt to reach the same area. For solving that efficiently, robots must execute decentralised traffic control algorithms. In this work, we propose a measure for evaluating the access efficiency of a common target area as the number of robots in the swarm rises: the common target area throughput. We demonstrate that the throughput of a target region with a limited area as the time tends to infinity -- the asymptotic throughput -- is finite, opposed to the relation arrival time at target per number of robots that tends to infinity. Using this measure, we can analytically compare the effectiveness of different algorithms. In particular, we propose and formally evaluate three different theoretical strategies for getting to a circular target area: (i) forming parallel queues towards the target area, (ii) forming a hexagonal packing through a corridor going to the target, and (iii) making multiple curved trajectories towards the boundary of the target area. We calculate the throughput for a fixed time and the asymptotic throughput for these strategies. Additionally, we corroborate these results by simulations, showing that when an algorithm has higher throughput, its arrival time per number of robots is lower. Thus, we conclude that using throughput is well suited for comparing congestion algorithms for a common target area in robotic swarms even if we do not have their closed asymptotic equation.
Microstructure Surface Reconstruction from SEM Images: An Alternative to Digital Image Correlation (DIC)
Mar 25, 2022
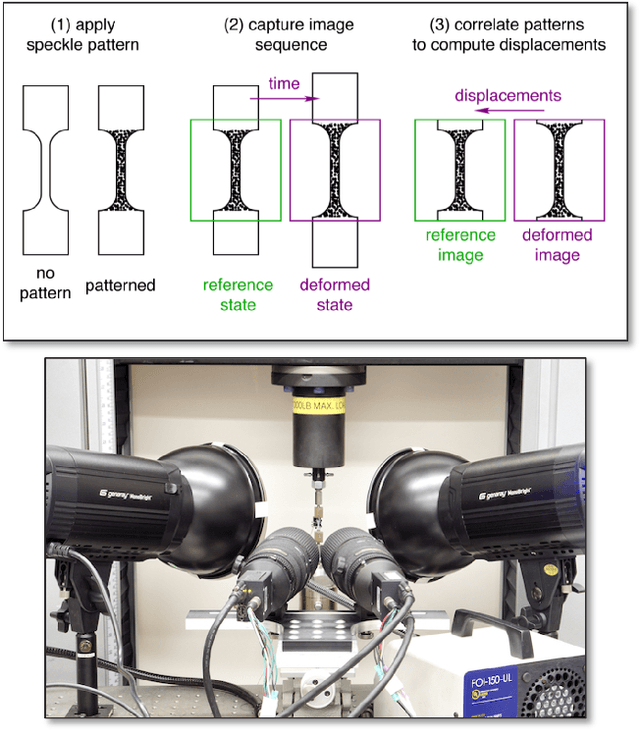


We reconstruct a 3D model of the surface of a material undergoing fatigue testing and experiencing cracking. Specifically we reconstruct the surface depth (out of plane intrusions and extrusions) and lateral (in-plane) motion from multiple views of the sample at the end of the experiment, combined with a reverse optical flow propagation backwards in time that utilizes interim single view images. These measurements can be mapped to a material strain tensor which helps to understand material life and predict failure. This approach offers an alternative to the commonly used Digital Image Correlation (DIC) technique which relies on tracking a speckle pattern applied to the material surface. DIC only produces in-plane (2D) measurements whereas our approach is 3D and non-invasive (requires no pattern being applied to the material).
Improving Distortion Robustness of Self-supervised Speech Processing Tasks with Domain Adaptation
Mar 30, 2022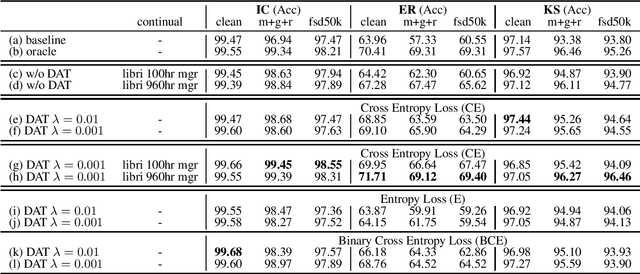
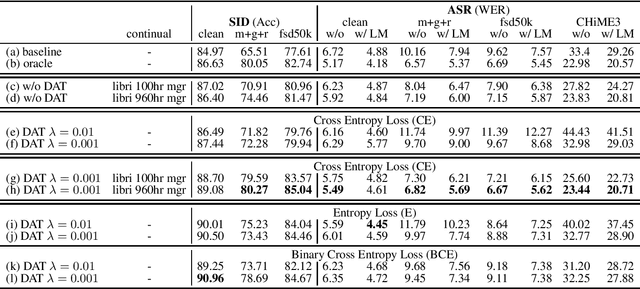
Speech distortions are a long-standing problem that degrades the performance of supervisely trained speech processing models. It is high time that we enhance the robustness of speech processing models to obtain good performance when encountering speech distortions while not hurting the original performance on clean speech. In this work, we propose to improve the robustness of speech processing models by domain adversarial training (DAT). We conducted experiments based on the SUPERB framework on five different speech processing tasks. In case we do not always have knowledge of the distortion types for speech data, we analyzed the binary-domain and multi-domain settings, where the former treats all distorted speech as one domain, and the latter views different distortions as different domains. In contrast to supervised training methods, we obtained promising results in target domains where speech data is distorted with different distortions including new unseen distortions introduced during testing.
CPC: Complementary Progress Constraints for Time-Optimal Quadrotor Trajectories
Aug 03, 2020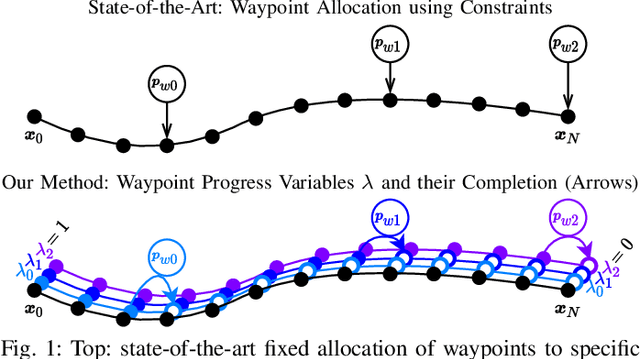
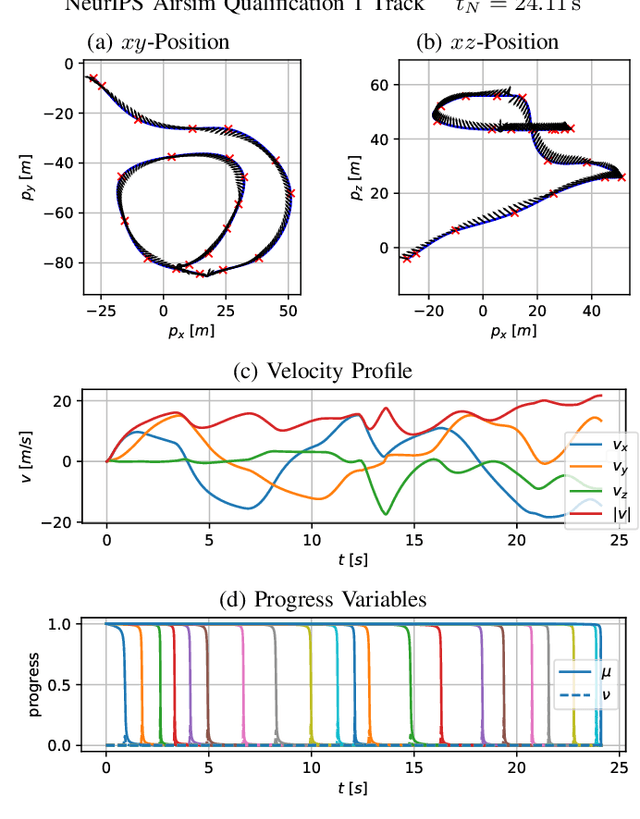
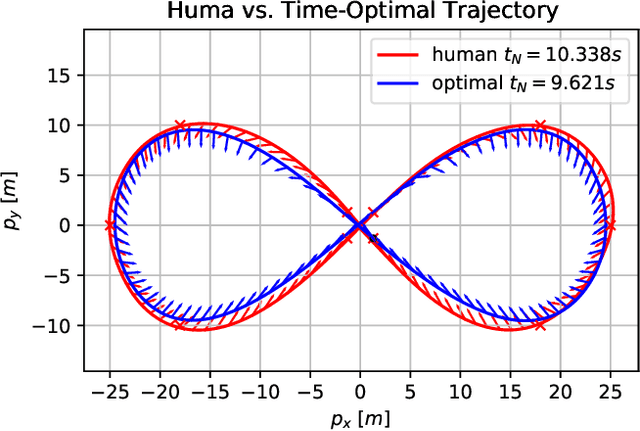
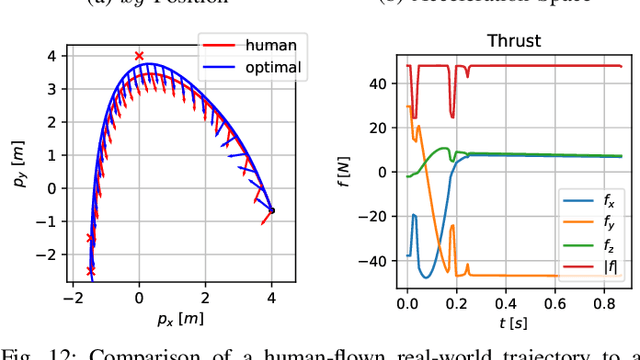
In many mobile robotics scenarios, such as drone racing, the goal is to generate a trajectory that passes through multiple waypoints in minimal time. This problem is referred to as time-optimal planning. State-of-the-art approaches either use polynomial trajectory formulations, which are suboptimal due to their smoothness, or numerical optimization, which requires waypoints to be allocated as costs or constraints to specific discrete-time nodes. For time-optimal planning, this time-allocation is a priori unknown and renders traditional approaches incapable of producing truly time-optimal trajectories. We introduce a novel formulation of progress bound to waypoints by a complementarity constraint. While the progress variables indicate the completion of a waypoint, change of this progress is only allowed in local proximity to the waypoint via complementarity constraints. This enables the simultaneous optimization of the trajectory and the time-allocation of the waypoints. To the best of our knowledge, this is the first approach allowing for truly time-optimal trajectory planning for quadrotors and other systems. We perform and discuss evaluations on optimality and convexity, compare to other related approaches, and qualitatively to an expert-human baseline.