 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Parallel Network with Channel Attention and Post-Processing for Carotid Arteries Vulnerable Plaque Segmentation in Ultrasound Images
Apr 18, 2022
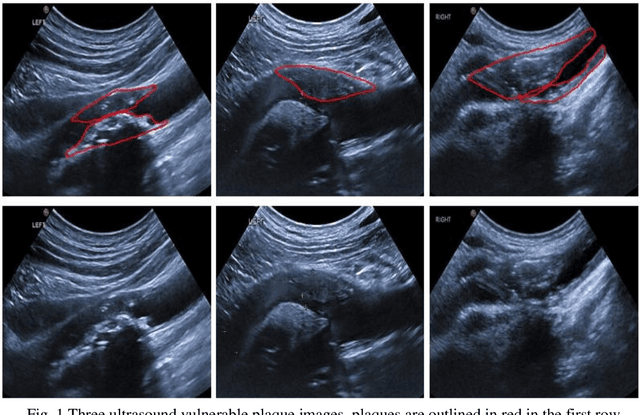

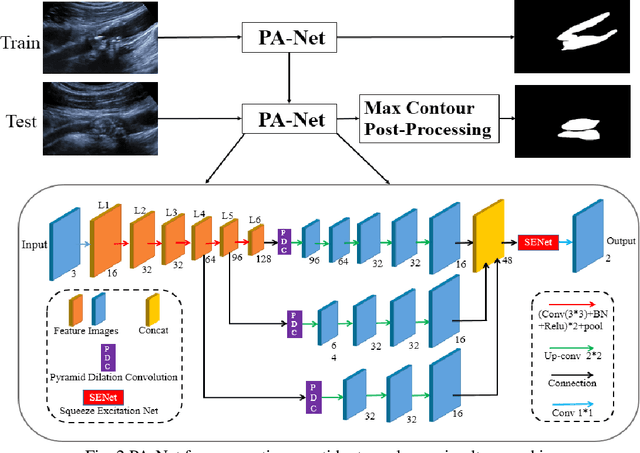
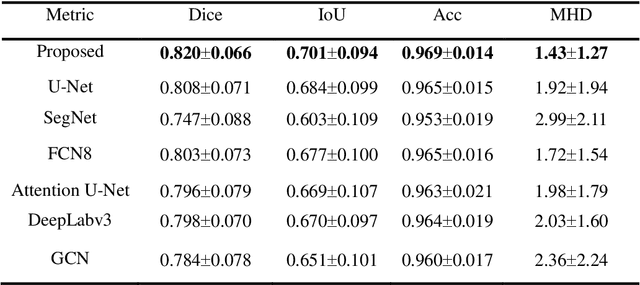
Carotid arteries vulnerable plaques are a crucial factor in the screening of atherosclerosis by ultrasound technique. However, the plaques are contaminated by various noises such as artifact, speckle noise, and manual segmentation may be time-consuming. This paper proposes an automatic convolutional neural network (CNN) method for plaque segmentation in carotid ultrasound images using a small dataset. First, a parallel network with three independent scale decoders is utilized as our base segmentation network, pyramid dilation convolutions are used to enlarge receptive fields in the three segmentation sub-networks. Subsequently, the three decoders are merged to be rectified in channels by SENet. Thirdly, in test stage, the initially segmented plaque is refined by the max contour morphology post-processing to obtain the final plaque. Moreover, three loss function Dice loss, SSIM loss and cross-entropy loss are compared to segment plaques. Test results show that the proposed method with dice loss function yields a Dice value of 0.820, an IoU of 0.701, Acc of 0.969, and modified Hausdorff distance (MHD) of 1.43 for 30 vulnerable cases of plaques, it outperforms some of the conventional CNN-based methods on these metrics. Additionally, we apply an ablation experiment to show the validity of each proposed module. Our study provides some reference for similar researches and may be useful in actual applications for plaque segmentation of ultrasound carotid arteries.
Identifying Exoplanets with Machine Learning Methods: A Preliminary Study
Apr 01, 2022

The discovery of habitable exoplanets has long been a heated topic in astronomy. Traditional methods for exoplanet identification include the wobble method, direct imaging, gravitational microlensing, etc., which not only require a considerable investment of manpower, time, and money, but also are limited by the performance of astronomical telescopes. In this study, we proposed the idea of using machine learning methods to identify exoplanets. We used the Kepler dataset collected by NASA from the Kepler Space Observatory to conduct supervised learning, which predicts the existence of exoplanet candidates as a three-categorical classification task, using decision tree, random forest, na\"ive Bayes, and neural network; we used another NASA dataset consisted of the confirmed exoplanets data to conduct unsupervised learning, which divides the confirmed exoplanets into different clusters, using k-means clustering. As a result, our models achieved accuracies of 99.06%, 92.11%, 88.50%, and 99.79%, respectively, in the supervised learning task and successfully obtained reasonable clusters in the unsupervised learning task.
* 12 pages with 9 figures and 2 tables
Provably Efficient Primal-Dual Reinforcement Learning for CMDPs with Non-stationary Objectives and Constraints
Jan 28, 2022
We consider primal-dual-based reinforcement learning (RL) in episodic constrained Markov decision processes (CMDPs) with non-stationary objectives and constraints, which play a central role in ensuring the safety of RL in time-varying environments. In this problem, the reward/utility functions and the state transition functions are both allowed to vary arbitrarily over time as long as their cumulative variations do not exceed certain known variation budgets. Designing safe RL algorithms in time-varying environments is particularly challenging because of the need to integrate the constraint violation reduction, safe exploration, and adaptation to the non-stationarity. To this end, we propose a Periodically Restarted Optimistic Primal-Dual Proximal Policy Optimization (PROPD-PPO) algorithm that features three mechanisms: periodic-restart-based policy improvement, dual update with dual regularization, and periodic-restart-based optimistic policy evaluation. We establish a dynamic regret bound and a constraint violation bound for the proposed algorithm in both the linear kernel CMDP function approximation setting and the tabular CMDP setting. This paper provides the first provably efficient algorithm for non-stationary CMDPs with safe exploration.
Quickest Change Detection in Anonymous Heterogeneous Sensor Networks
Feb 26, 2022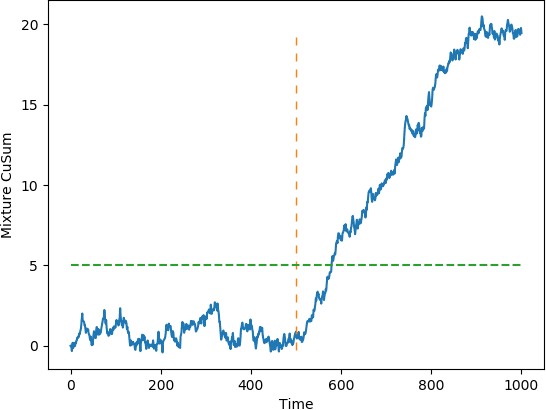
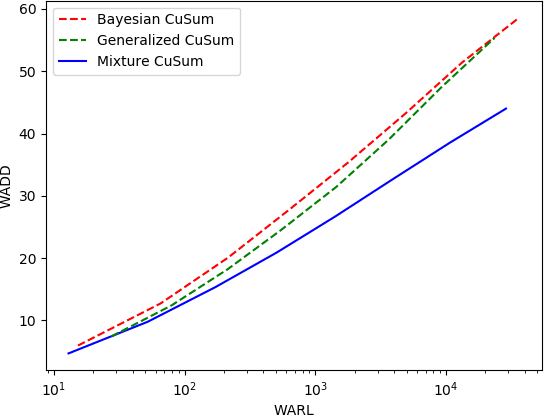
The problem of quickest change detection (QCD) in anonymous heterogeneous sensor networks is studied. There are $n$ heterogeneous sensors and a fusion center. The sensors are clustered into $K$ groups, and different groups follow different data-generating distributions. At some unknown time, an event occurs in the network and changes the data-generating distribution of the sensors. The goal is to detect the change as quickly as possible, subject to false alarm constraints. The anonymous setting is studied, where at each time step, the fusion center receives $n$ unordered samples, and the fusion center does not know which sensor each sample comes from, and thus does not know its exact distribution. A simple optimality proof is first derived for the mixture likelihood ratio test, which was constructed and proved to be optimal for the non-sequential anonymous setting in (Chen and Wang, 2019). For the QCD problem, a mixture CuSum algorithm is further constructed, and is further shown to be optimal under Lorden's criterion. For large networks, a computationally efficient test is proposed and a novel theoretical characterization of its false alarm rate is developed. Numerical results are provided to validate the theoretical results.
Visual Mechanisms Inspired Efficient Transformers for Image and Video Quality Assessment
Apr 06, 2022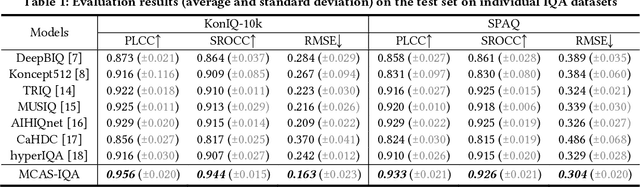

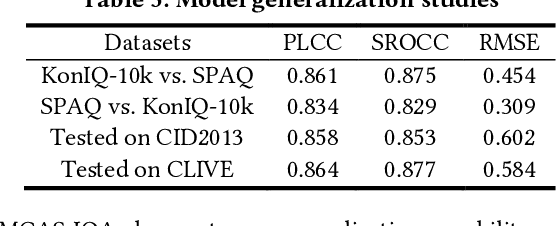
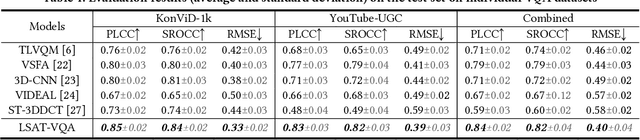
Visual (image, video) quality assessments can be modelled by visual features in different domains, e.g., spatial, frequency, and temporal domains. Perceptual mechanisms in the human visual system (HVS) play a crucial role in generation of quality perception. This paper proposes a general framework for no-reference visual quality assessment using efficient windowed transformer architectures. A lightweight module for multi-stage channel attention is integrated into Swin (shifted window) Transformer. Such module can represent appropriate perceptual mechanisms in image quality assessment (IQA) to build an accurate IQA model. Meanwhile, representative features for image quality perception in the spatial and frequency domains can also be derived from the IQA model, which are then fed into another windowed transformer architecture for video quality assessment (VQA). The VQA model efficiently reuses attention information across local windows to tackle the issue of expensive time and memory complexities of original transformer. Experimental results on both large-scale IQA and VQA databases demonstrate that the proposed quality assessment models outperform other state-of-the-art models by large margins. The complete source code will be published on Github.
Continuous-time State & Dynamics Estimation using a Pseudo-Spectral Parameterization
Mar 26, 2021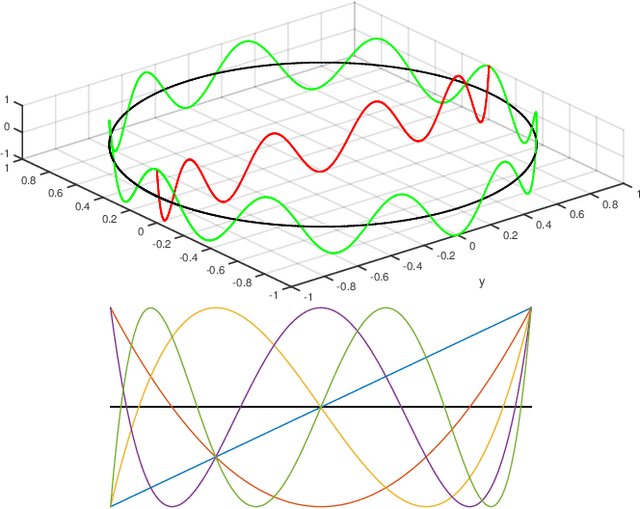
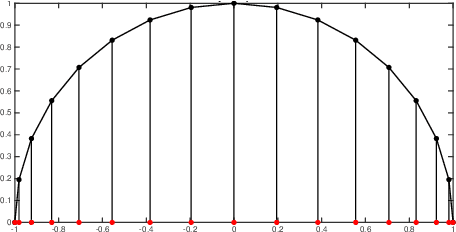
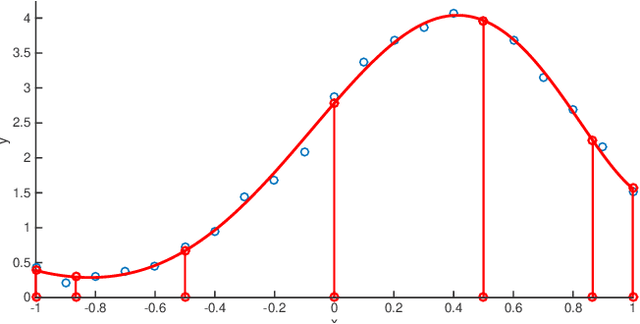
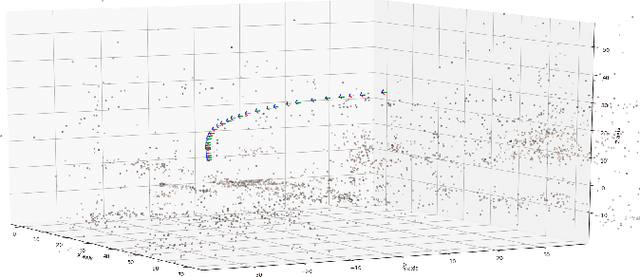
We present a novel continuous time trajectory representation based on a Chebyshev polynomial basis, which when governed by known dynamics models, allows for full trajectory and robot dynamics estimation, particularly useful for high-performance robotics applications such as unmanned aerial vehicles. We show that we can gracefully incorporate model dynamics to our trajectory representation, within a factor-graph based framework, and leverage ideas from pseudo-spectral optimal control to parameterize the state and the control trajectories as interpolating polynomials. This allows us to perform efficient optimization at specifically chosen points derived from the theory, while recovering full trajectory estimates. Through simulated experiments we demonstrate the applicability of our representation for accurate flight dynamics estimation for multirotor aerial vehicles. The representation framework is general and can thus be applied to a multitude of high-performance applications beyond multirotor platforms.
Flexible LED Index Modulation for MIMO Optical Wireless Communications
Apr 14, 2022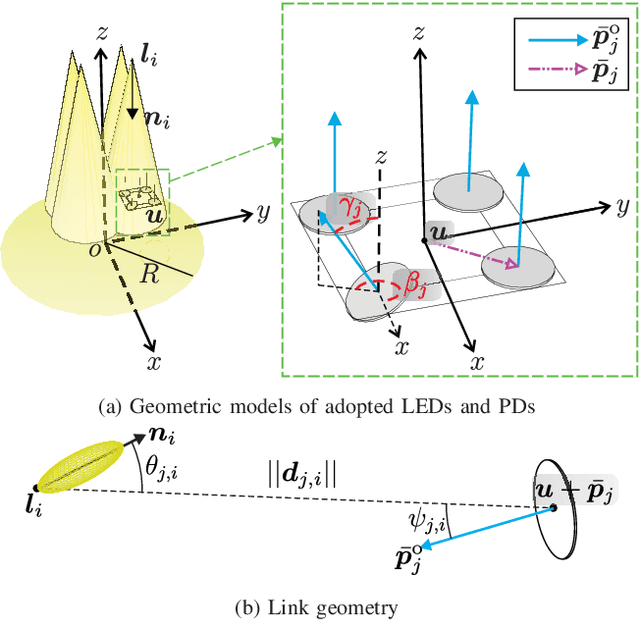
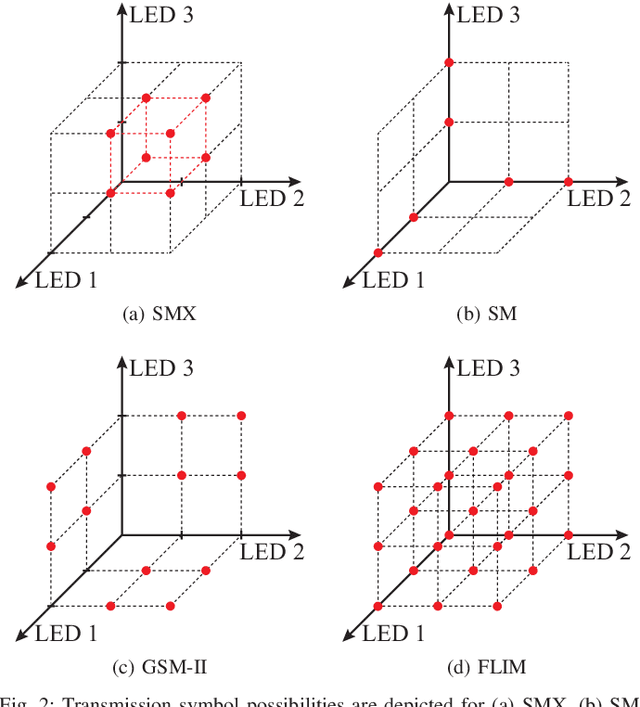
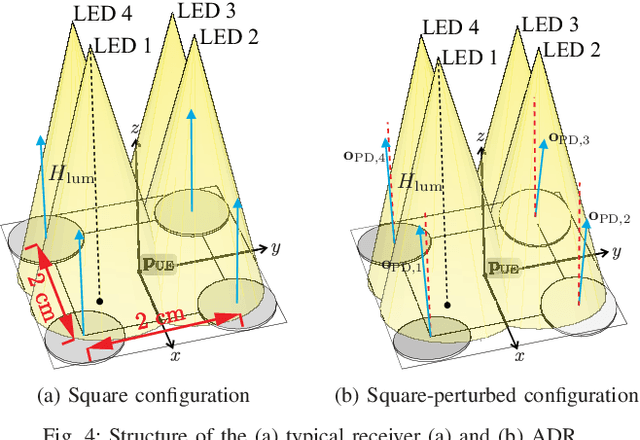
The limited bandwidth of optical wireless communication (OWC) front-end devices motivates the use of multiple-input-multiple-output (MIMO) techniques to enhance data rates. It is known that very high multiplexing gains could be achieved by spatial multiplexing (SMX) in exchange for exhaustive detection complexity. Alternatively, in spatial modulation (SM), a single light emitting diode (LED) is activated per time instance where information is carried by both the signal and the LED index. Since only an LED is active, both transmitter (TX) and receiver (RX) complexity reduces significantly while retaining the information transmission in the spatial domain. However, significant spectral efficiency losses occur in SM compared to SMX. In this paper, we propose a technique which adopts the advantages of both systems. Accordingly, the proposed flexible LED index modulation (FLIM) technique harnesses the inactive state of the LEDs as a transmit symbol. Therefore, the number of active LEDs changes in each transmission, unlike conventional techniques. Moreover, the system complexity is reduced by employing a linear minimum mean squared error (MMSE) equalizer and an angle perturbed receiver at the RX. Numerical results show that FLIM outperforms the reference systems by at least 6 dB in the low and medium/high spectral efficiency regions.
Bunched LPCNet2: Efficient Neural Vocoders Covering Devices from Cloud to Edge
Mar 27, 2022

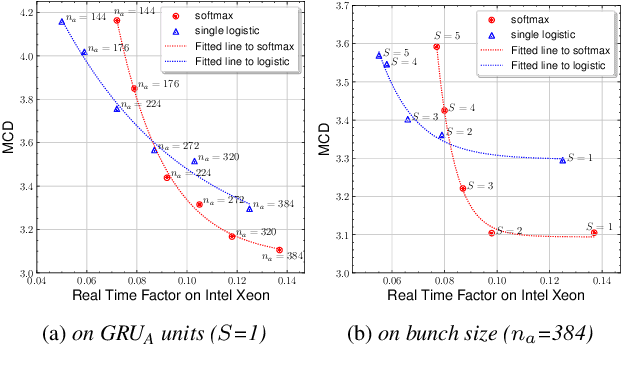
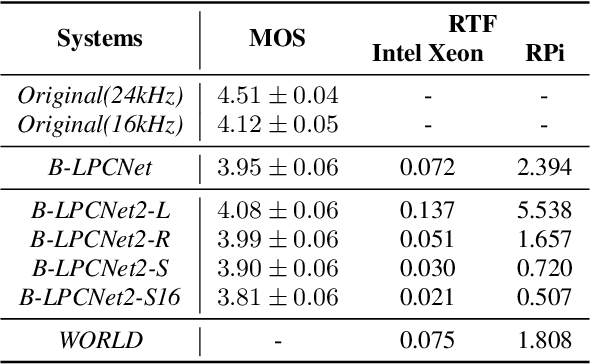
Text-to-Speech (TTS) services that run on edge devices have many advantages compared to cloud TTS, e.g., latency and privacy issues. However, neural vocoders with a low complexity and small model footprint inevitably generate annoying sounds. This study proposes a Bunched LPCNet2, an improved LPCNet architecture that provides highly efficient performance in high-quality for cloud servers and in a low-complexity for low-resource edge devices. Single logistic distribution achieves computational efficiency, and insightful tricks reduce the model footprint while maintaining speech quality. A DualRate architecture, which generates a lower sampling rate from a prosody model, is also proposed to reduce maintenance costs. The experiments demonstrate that Bunched LPCNet2 generates satisfactory speech quality with a model footprint of 1.1MB while operating faster than real-time on a RPi 3B. Our audio samples are available at https://srtts.github.io/bunchedLPCNet2.
Efficient Argument Structure Extraction with Transfer Learning and Active Learning
Apr 01, 2022
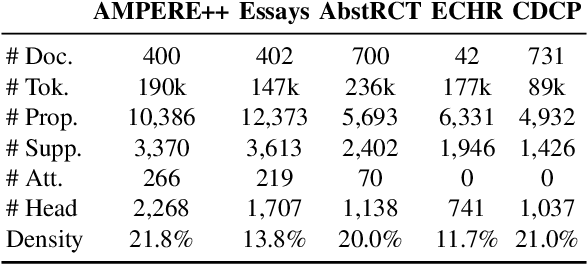
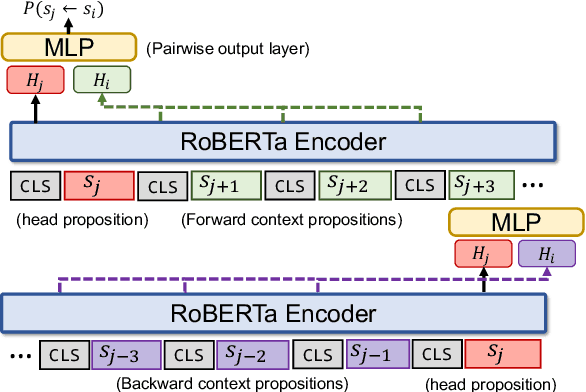
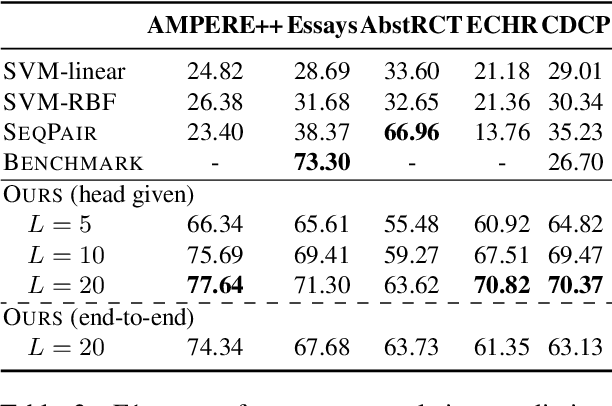
The automation of extracting argument structures faces a pair of challenges on (1) encoding long-term contexts to facilitate comprehensive understanding, and (2) improving data efficiency since constructing high-quality argument structures is time-consuming. In this work, we propose a novel context-aware Transformer-based argument structure prediction model which, on five different domains, significantly outperforms models that rely on features or only encode limited contexts. To tackle the difficulty of data annotation, we examine two complementary methods: (i) transfer learning to leverage existing annotated data to boost model performance in a new target domain, and (ii) active learning to strategically identify a small amount of samples for annotation. We further propose model-independent sample acquisition strategies, which can be generalized to diverse domains. With extensive experiments, we show that our simple-yet-effective acquisition strategies yield competitive results against three strong comparisons. Combined with transfer learning, substantial F1 score boost (5-25) can be further achieved during the early iterations of active learning across domains.
SemanticCAP: Chromatin Accessibility Prediction Enhanced by Features Learning from a Language Model
Apr 06, 2022

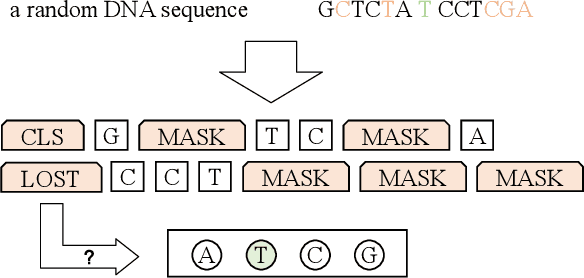
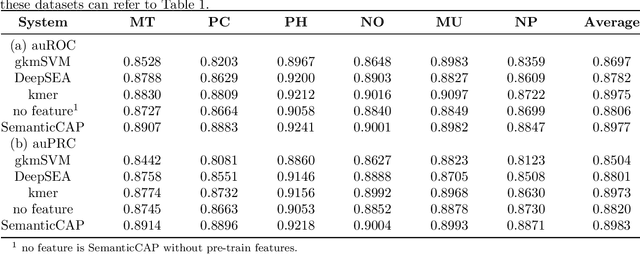
A large number of inorganic and organic compounds are able to bind DNA and form complexes, among which drug-related molecules are important. Chromatin accessibility changes not only directly affects drug-DNA interactions, but also promote or inhibit the expression of critical genes associated with drug resistance by affecting the DNA binding capacity of TFs and transcriptional regulators. However, Biological experimental techniques for measuring it are expensive and time consuming. In recent years, several kinds of computational methods have been proposed to identify accessible regions of the genome. Existing computational models mostly ignore the contextual information of bases in gene sequences. To address these issues, we proposed a new solution named SemanticCAP. It introduces a gene language model which models the context of gene sequences, thus being able to provide an effective representation of a certain site in gene sequences. Basically, we merge the features provided by the gene language model into our chromatin accessibility model. During the process, we designed some methods to make feature fusion smoother. Compared with other systems under public benchmarks, our model proved to have better performance.