 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Exact Poly-Time Membership-Queries Algorithm for Extraction a three-Layer ReLU Network
May 20, 2021
As machine learning increasingly becomes more prevalent in our everyday life, many organizations offer neural-networks based services as a black-box. The reasons for hiding a learning model may vary: e.g., preventing copying of its behavior or keeping back an adversarial from reverse-engineering its mechanism and revealing sensitive information about its training data. However, even as a black-box, some information can still be discovered by specific queries. In this work, we show a polynomial-time algorithm that uses a polynomial number of queries to mimic precisely the behavior of a three-layer neural network that uses ReLU activation.
Integrated Radar Sensing and Communication-assisted Orthogonal Time Frequency Space Transmission for Vehicular Networks
May 07, 2021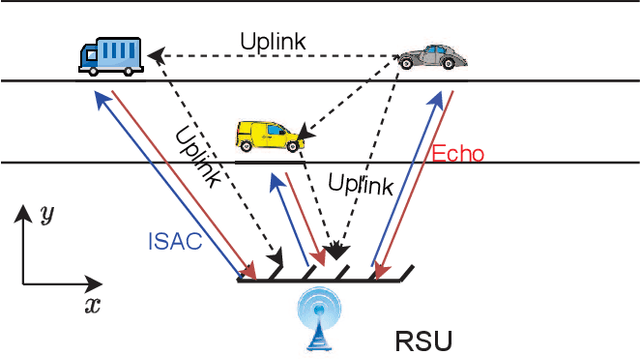
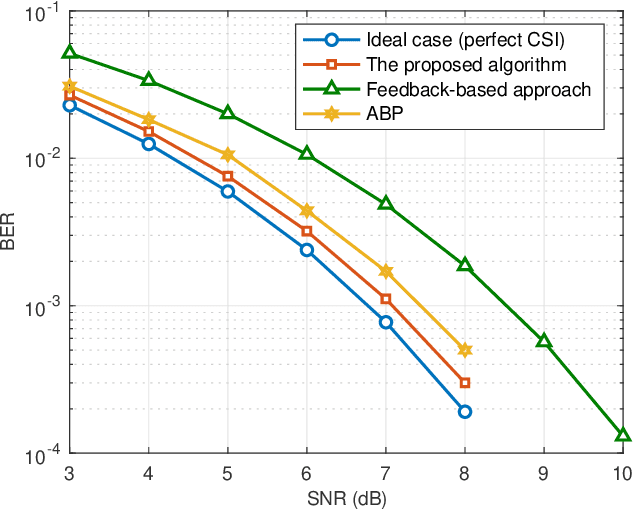
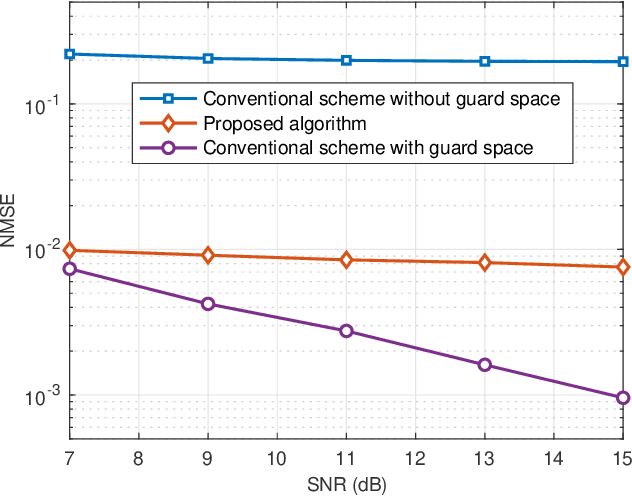
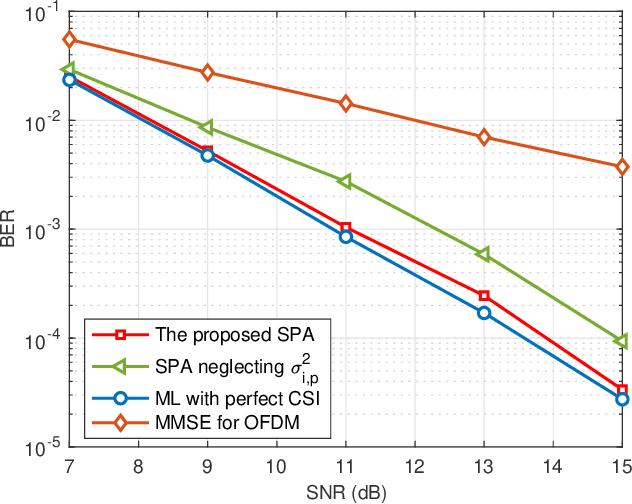
Orthogonal time frequency space (OTFS) modulation is a promising candidate for supporting reliable information transmission in high-mobility vehicular networks. In this paper, we consider the employment of the integrated (radar) sensing and communication (ISAC) technique for assisting OTFS transmission in both uplink and downlink vehicular communication systems. Benefiting from the OTFS-ISAC signals, the roadside unit (RSU) is capable of simultaneously transmitting downlink information to the vehicles and estimating the sensing parameters of vehicles, e.g., locations and speeds, based on the reflected echoes. Then, relying on the estimated kinematic parameters of vehicles, the RSU can construct the topology of the vehicular network that enables the prediction of the vehicle states in the following time instant. Consequently, the RSU can effectively formulate the transmit downlink beamformers according to the predicted parameters to counteract the channel adversity such that the vehicles can directly detect the information without the need of performing channel estimation. As for the uplink transmission, the RSU can infer the delays and Dopplers associated with different channel paths based on the aforementioned dynamic topology of the vehicular network. Thus, inserting guard space as in conventional methods are not needed for uplink channel estimation which removes the required training overhead. Finally, an efficient uplink detector is proposed by taking into account the channel estimation uncertainty. Through numerical simulations, we demonstrate the benefits of the proposed ISAC-assisted OTFS transmission scheme.
Embedded quantitative MRI T1rho mapping using non-linear primal-dual proximal splitting
Feb 14, 2022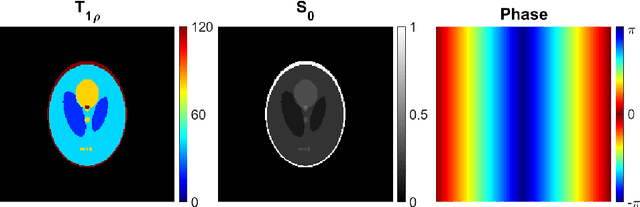
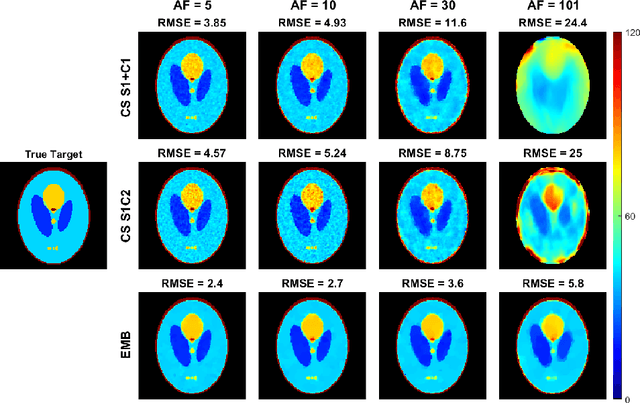
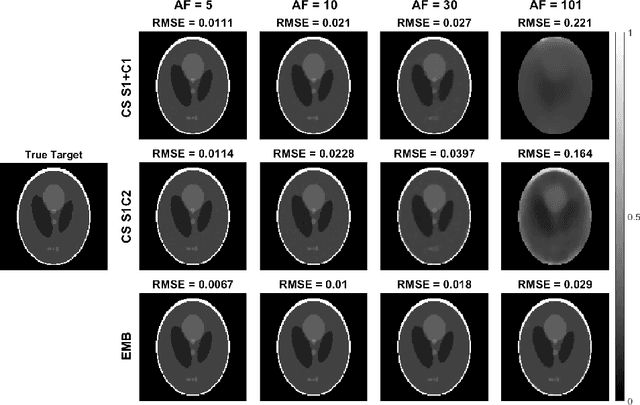
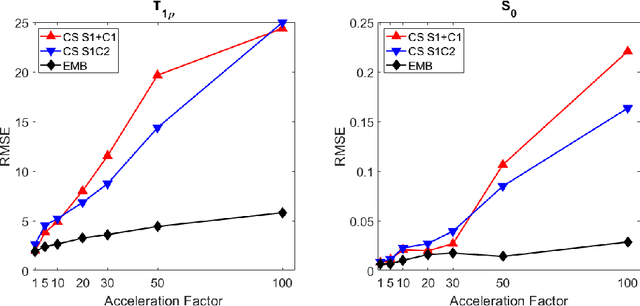
Quantitative MRI (qMRI) methods allow reducing the subjectivity of clinical MRI by providing numerical values on which diagnostic assessment or predictions of tissue properties can be based. However, qMRI measurements typically take more time than anatomical imaging due to requiring multiple measurements with varying contrasts for, e.g., relaxation time mapping. To reduce the scanning time, undersampled data may be combined with compressed sensing reconstruction techniques. Typical CS reconstructions first reconstruct a complex-valued set of images corresponding to the varying contrasts, followed by a non-linear signal model fit to obtain the parameter maps. We propose a direct, embedded reconstruction method for T1rho mapping. The proposed method capitalizes on a known signal model to directly reconstruct the desired parameter map using a non-linear optimization model. The proposed reconstruction method also allows directly regularizing the parameter map of interest, and greatly reduces the number of unknowns in the reconstruction. We test the proposed model using a simulated radially sampled data from a 2D phantom and 2D cartesian ex vivo measurements of a mouse kidney specimen. We compare the embedded reconstruction model to two CS reconstruction models, and in the cartesian test case also iFFT. The proposed, embedded model outperformed the reference methods on both test cases, especially with higher acceleration factors.
Improving Pre-trained Language Models with Syntactic Dependency Prediction Task for Chinese Semantic Error Recognition
Apr 15, 2022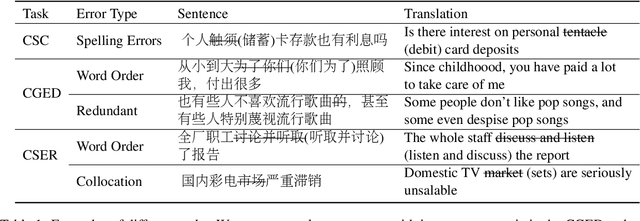
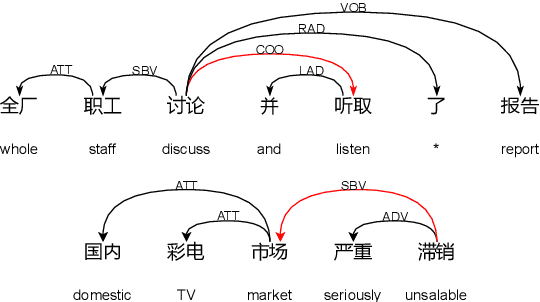

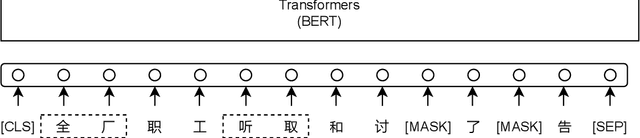
Existing Chinese text error detection mainly focuses on spelling and simple grammatical errors. These errors have been studied extensively and are relatively simple for humans. On the contrary, Chinese semantic errors are understudied and more complex that humans cannot easily recognize. The task of this paper is Chinese Semantic Error Recognition (CSER), a binary classification task to determine whether a sentence contains semantic errors. The current research has no effective method to solve this task. In this paper, we inherit the model structure of BERT and design several syntax-related pre-training tasks so that the model can learn syntactic knowledge. Our pre-training tasks consider both the directionality of the dependency structure and the diversity of the dependency relationship. Due to the lack of a published dataset for CSER, we build a high-quality dataset for CSER for the first time named Corpus of Chinese Linguistic Semantic Acceptability (CoCLSA). The experimental results on the CoCLSA show that our methods outperform universal pre-trained models and syntax-infused models.
Shape Prior Non-Uniform Sampling Guided Real-time Stereo 3D Object Detection
Jun 22, 2021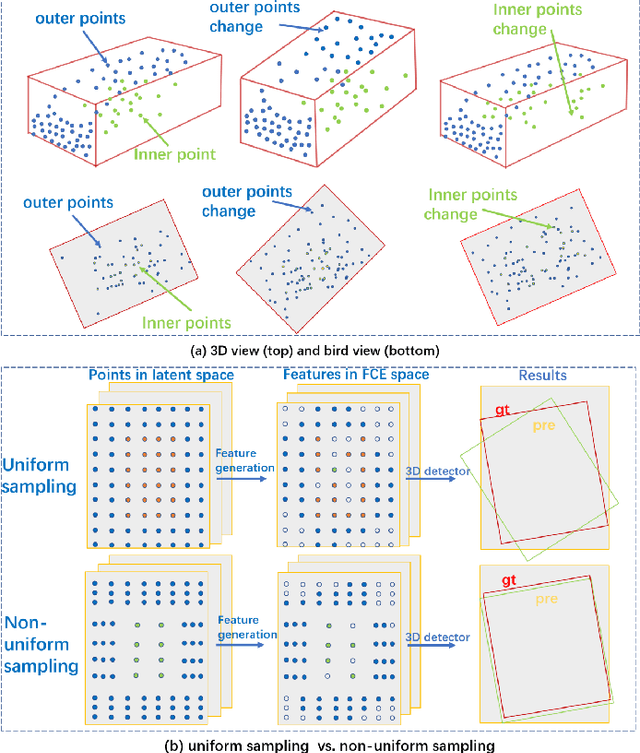
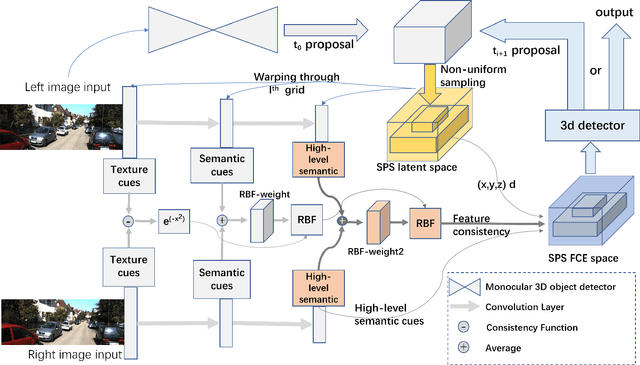
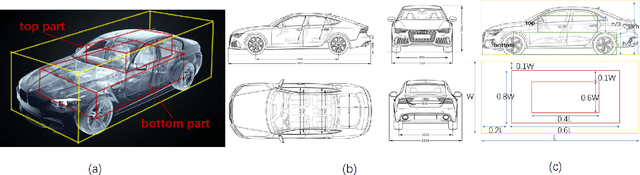
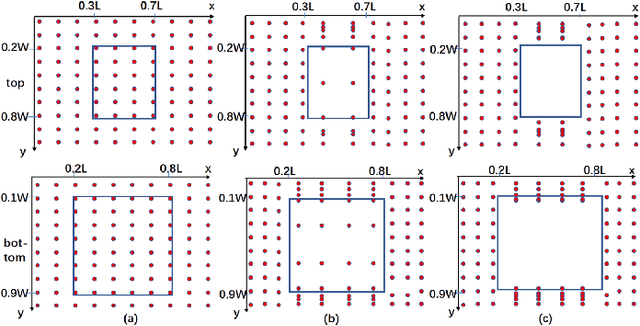
Pseudo-LiDAR based 3D object detectors have gained popularity due to their high accuracy. However, these methods need dense depth supervision and suffer from inferior speed. To solve these two issues, a recently introduced RTS3D builds an efficient 4D Feature-Consistency Embedding (FCE) space for the intermediate representation of object without depth supervision. FCE space splits the entire object region into 3D uniform grid latent space for feature sampling point generation, which ignores the importance of different object regions. However, we argue that, compared with the inner region, the outer region plays a more important role for accurate 3D detection. To encode more information from the outer region, we propose a shape prior non-uniform sampling strategy that performs dense sampling in outer region and sparse sampling in inner region. As a result, more points are sampled from the outer region and more useful features are extracted for 3D detection. Further, to enhance the feature discrimination of each sampling point, we propose a high-level semantic enhanced FCE module to exploit more contextual information and suppress noise better. Experiments on the KITTI dataset are performed to show the effectiveness of the proposed method. Compared with the baseline RTS3D, our proposed method has 2.57% improvement on AP3d almost without extra network parameters. Moreover, our proposed method outperforms the state-of-the-art methods without extra supervision at a real-time speed.
Achieving Efficient Distributed Machine Learning Using a Novel Non-Linear Class of Aggregation Functions
Jan 29, 2022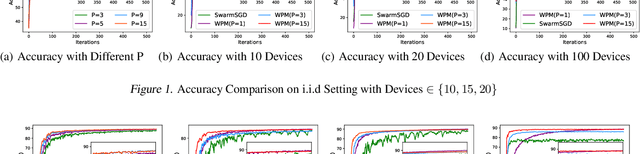
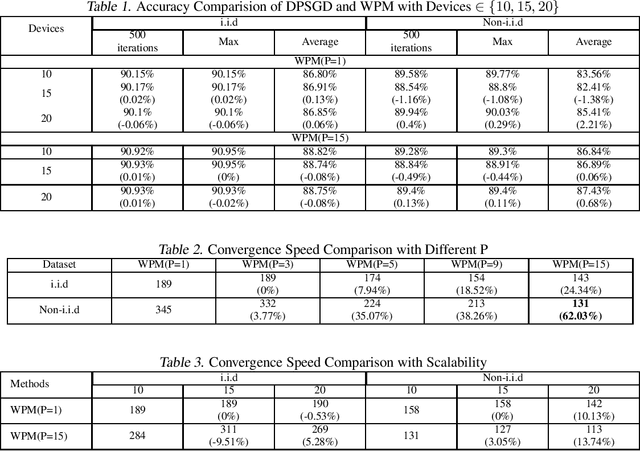


Distributed machine learning (DML) over time-varying networks can be an enabler for emerging decentralized ML applications such as autonomous driving and drone fleeting. However, the commonly used weighted arithmetic mean model aggregation function in existing DML systems can result in high model loss, low model accuracy, and slow convergence speed over time-varying networks. To address this issue, in this paper, we propose a novel non-linear class of model aggregation functions to achieve efficient DML over time-varying networks. Instead of taking a linear aggregation of neighboring models as most existing studies do, our mechanism uses a nonlinear aggregation, a weighted power-p mean (WPM) where p is a positive odd integer, as the aggregation function of local models from neighbors. The subsequent optimizing steps are taken using mirror descent defined by a Bregman divergence that maintains convergence to optimality. In this paper, we analyze properties of the WPM and rigorously prove convergence properties of our aggregation mechanism. Additionally, through extensive experiments, we show that when p > 1, our design significantly improves the convergence speed of the model and the scalability of DML under time-varying networks compared with arithmetic mean aggregation functions, with little additional 26computation overhead.
Recovering models of open quantum systems from data via polynomial optimization: Towards globally convergent quantum system identification
Mar 31, 2022
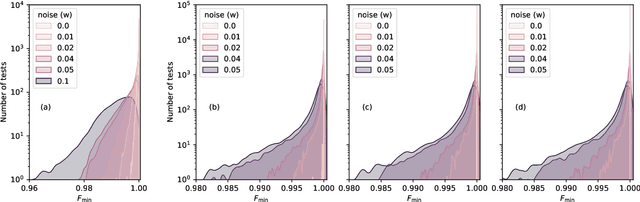
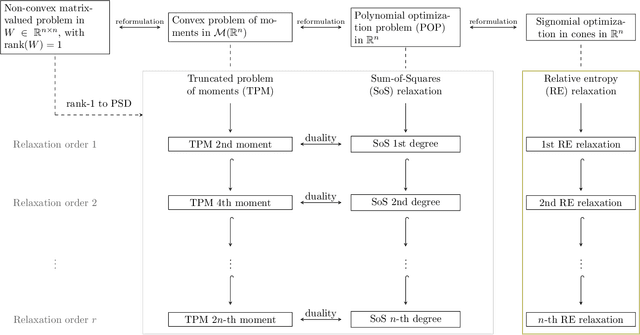
Current quantum devices suffer imperfections as a result of fabrication, as well as noise and dissipation as a result of coupling to their immediate environments. Because of this, it is often difficult to obtain accurate models of their dynamics from first principles. An alternative is to extract such models from time-series measurements of their behavior. Here, we formulate this system-identification problem as a polynomial optimization problem. Recent advances in optimization have provided globally convergent solvers for this class of problems, which using our formulation prove estimates of the Kraus map or the Lindblad equation. We include an overview of the state-of-the-art algorithms, bounds, and convergence rates, and illustrate the use of this approach to modeling open quantum systems.
Physics to the Rescue: Deep Non-line-of-sight Reconstruction for High-speed Imaging
May 03, 2022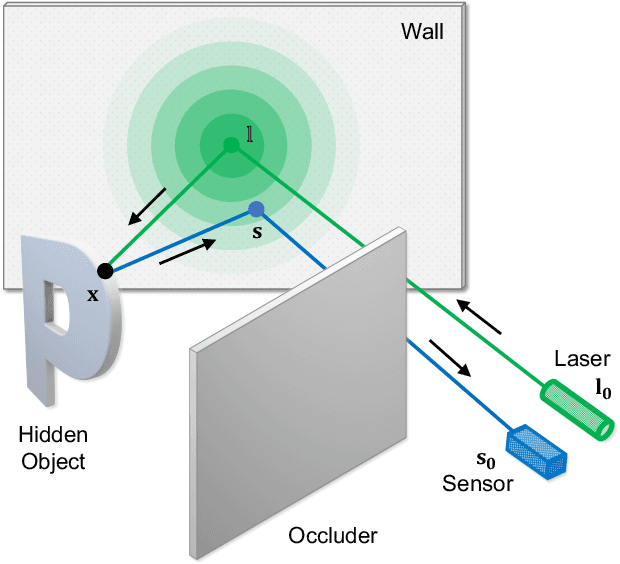
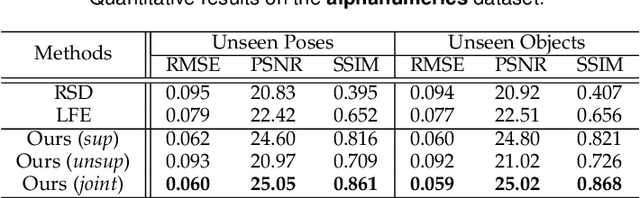
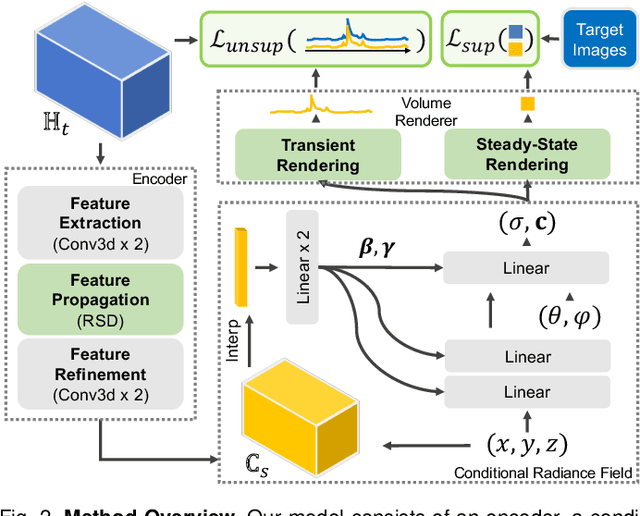
Computational approach to imaging around the corner, or non-line-of-sight (NLOS) imaging, is becoming a reality thanks to major advances in imaging hardware and reconstruction algorithms. A recent development towards practical NLOS imaging, Nam et al. demonstrated a high-speed non-confocal imaging system that operates at 5Hz, 100x faster than the prior art. This enormous gain in acquisition rate, however, necessitates numerous approximations in light transport, breaking many existing NLOS reconstruction methods that assume an idealized image formation model. To bridge the gap, we present a novel deep model that incorporates the complementary physics priors of wave propagation and volume rendering into a neural network for high-quality and robust NLOS reconstruction. This orchestrated design regularizes the solution space by relaxing the image formation model, resulting in a deep model that generalizes well on real captures despite being exclusively trained on synthetic data. Further, we devise a unified learning framework that enables our model to be flexibly trained using diverse supervision signals, including target intensity images or even raw NLOS transient measurements. Once trained, our model renders both intensity and depth images at inference time in a single forward pass, capable of processing more than 5 captures per second on a high-end GPU. Through extensive qualitative and quantitative experiments, we show that our method outperforms prior physics and learning based approaches on both synthetic and real measurements. We anticipate that our method along with the fast capturing system will accelerate future development of NLOS imaging for real world applications that require high-speed imaging.
Over-The-Air Federated Learning under Byzantine Attacks
May 05, 2022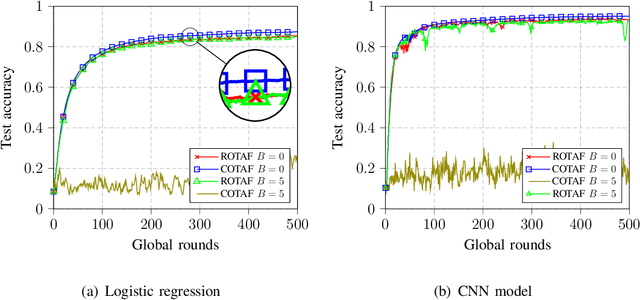
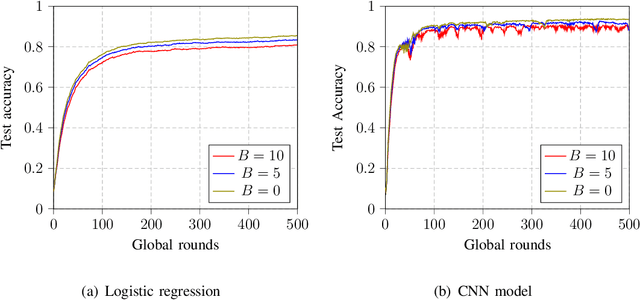
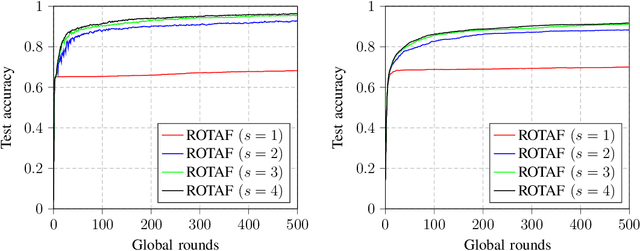
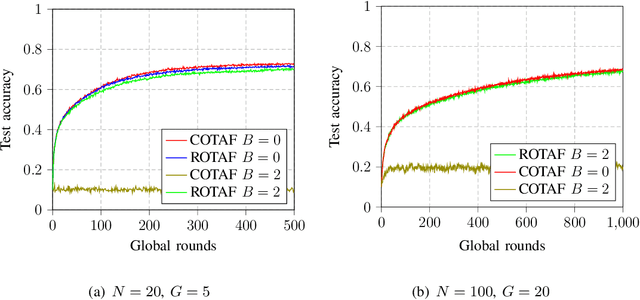
Federated learning (FL) is a promising solution to enable many AI applications, where sensitive datasets from distributed clients are needed for collaboratively training a global model. FL allows the clients to participate in the training phase, governed by a central server, without sharing their local data. One of the main challenges of FL is the communication overhead, where the model updates of the participating clients are sent to the central server at each global training round. Over-the-air computation (AirComp) has been recently proposed to alleviate the communication bottleneck where the model updates are sent simultaneously over the multiple-access channel. However, simple averaging of the model updates via AirComp makes the learning process vulnerable to random or intended modifications of the local model updates of some Byzantine clients. In this paper, we propose a transmission and aggregation framework to reduce the effect of such attacks while preserving the benefits of AirComp for FL. For the proposed robust approach, the central server divides the participating clients randomly into groups and allocates a transmission time slot for each group. The updates of the different groups are then aggregated using a robust aggregation technique. We extend our approach to handle the case of non-i.i.d. local data, where a resampling step is added before robust aggregation. We analyze the convergence of the proposed approach for both cases of i.i.d. and non-i.i.d. data and demonstrate that the proposed algorithm converges at a linear rate to a neighborhood of the optimal solution. Experiments on real datasets are provided to confirm the robustness of the proposed approach.
Double Diffusion Maps and their Latent Harmonics for Scientific Computations in Latent Space
Apr 26, 2022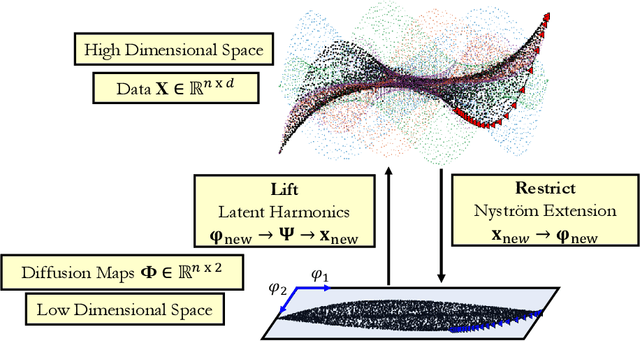
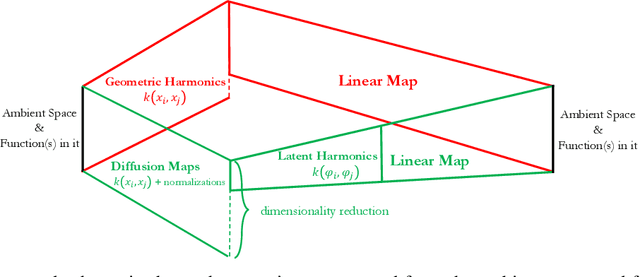
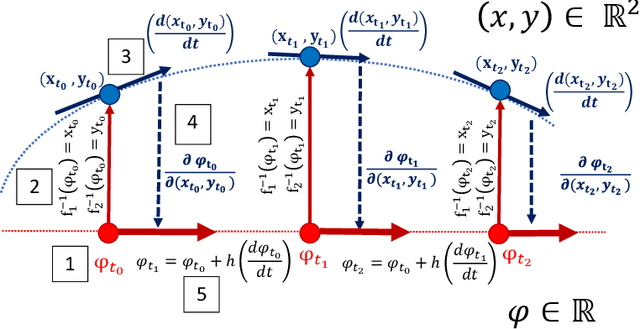
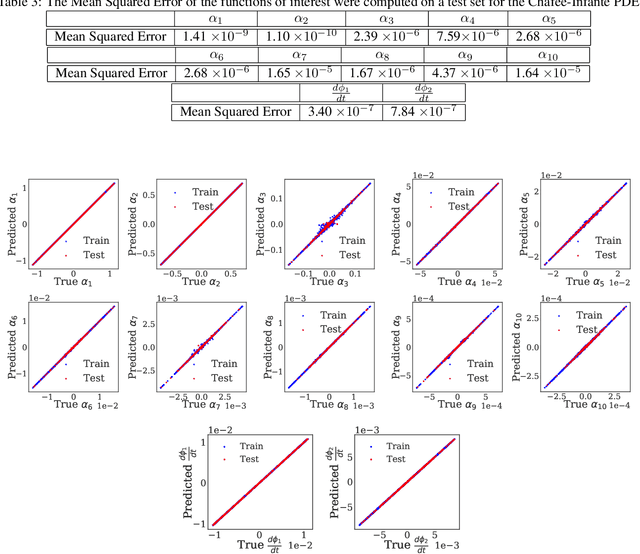
We introduce a data-driven approach to building reduced dynamical models through manifold learning; the reduced latent space is discovered using Diffusion Maps (a manifold learning technique) on time series data. A second round of Diffusion Maps on those latent coordinates allows the approximation of the reduced dynamical models. This second round enables mapping the latent space coordinates back to the full ambient space (what is called lifting); it also enables the approximation of full state functions of interest in terms of the reduced coordinates. In our work, we develop and test three different reduced numerical simulation methodologies, either through pre-tabulation in the latent space and integration on the fly or by going back and forth between the ambient space and the latent space. The data-driven latent space simulation results, based on the three different approaches, are validated through (a) the latent space observation of the full simulation through the Nystr\"om Extension formula, or through (b) lifting the reduced trajectory back to the full ambient space, via Latent Harmonics. Latent space modeling often involves additional regularization to favor certain properties of the space over others, and the mapping back to the ambient space is then constructed mostly independently from these properties; here, we use the same data-driven approach to construct the latent space and then map back to the ambient space.