 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian Bilinear Neural Network for Predicting the Mid-price Dynamics in Limit-Order Book Markets
Mar 07, 2022
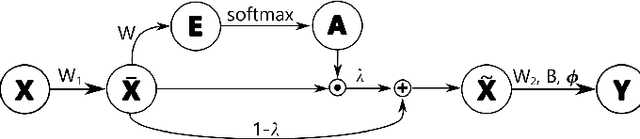
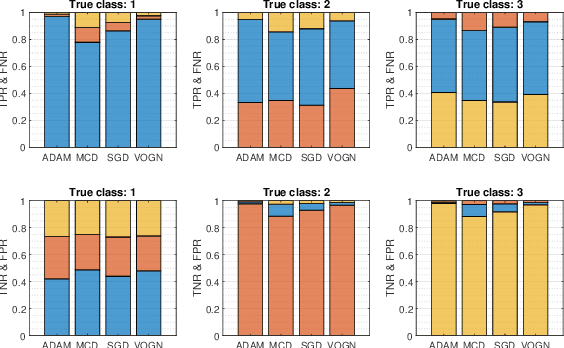
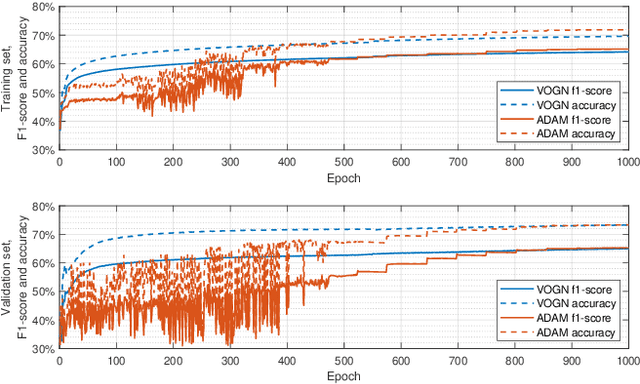
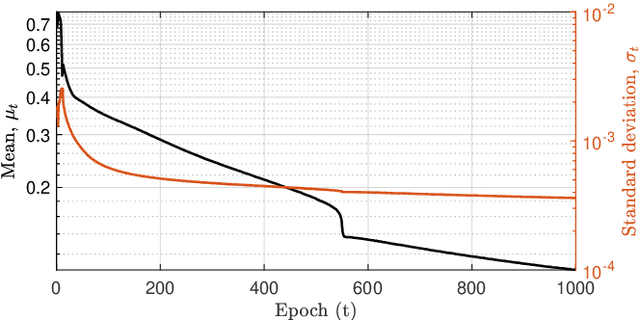
The prediction of financial markets is a challenging yet important task. In modern electronically-driven markets traditional time-series econometric methods often appear incapable of capturing the true complexity of the multi-level interactions driving the price dynamics. While recent research has established the effectiveness of traditional machine learning (ML) models in financial applications, their intrinsic inability in dealing with uncertainties, which is a great concern in econometrics research and real business applications, constitutes a major drawback. Bayesian methods naturally appear as a suitable remedy conveying the predictive ability of ML methods with the probabilistically-oriented practice of econometric research. By adopting a state-of-the-art second-order optimization algorithm, we train a Bayesian bilinear neural network with temporal attention, suitable for the challenging time-series task of predicting mid-price movements in ultra-high-frequency limit-order book markets. By addressing the use of predictive distributions to analyze errors and uncertainties associated with the estimated parameters and model forecasts, we thoroughly compare our Bayesian model with traditional ML alternatives. Our results underline the feasibility of the Bayesian deep learning approach and its predictive and decisional advantages in complex econometric tasks, prompting future research in this direction.
The Sparse Readout RIGEL Application Specific Integrated Circuit for Pixel Silicon Drift Detectors in Soft X-Ray Imaging Space Applications
Apr 27, 2022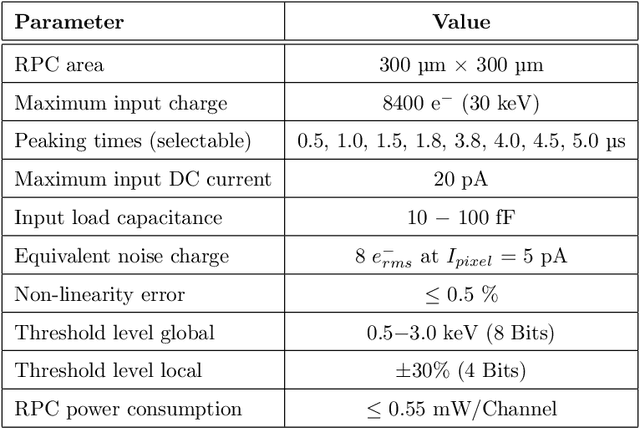
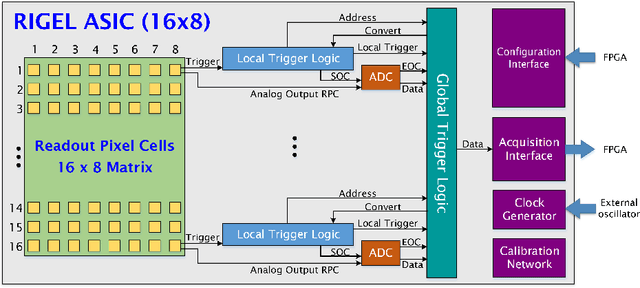
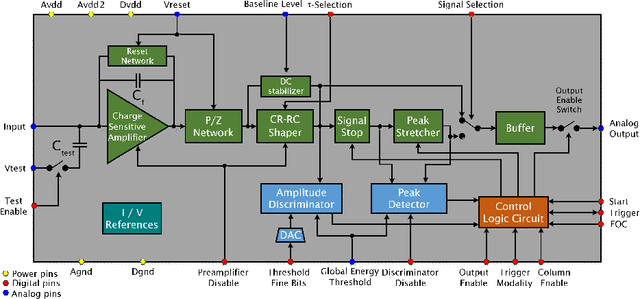
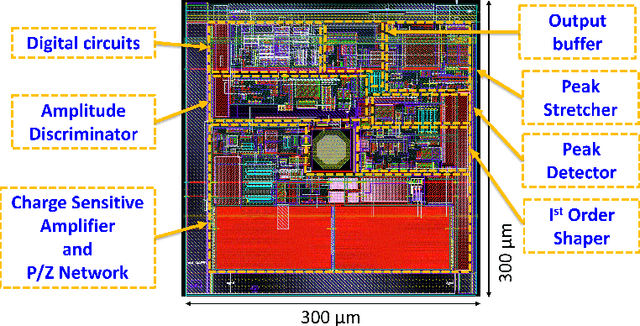
An Application Specific Integrated Circuit (ASIC), called RIGEL, designed for the sparse readout of a Silicon Pixel Drift Detector (PixDD) for space applications is presented.The low leakage current (less than 1 pA at +20 {\deg}C) and anode capacitance (less than 40 fF) of each pixel (300 um x 300 um) of the detector, combined with a low-noise electronics readout, allow to reach a high spectroscopic resolution performance even at room temperature. The RIGEL ASIC front-end architecture is composed by a 2-D matrix of 128 readout pixel cells (RPCs), arranged to host, in a 300 um-sided square area, a central octagonal pad (for the PixDD anode bump-bonding), and the full-analog processing chain, providing a full-shaped and stretched signal. In the chip periphery, the back-end electronics features 16 integrated 10-bits Wilkinson ADCs, the configuration register and a trigger management circuit. The characterization of a single RPC has been carried out whose features are: eight selectable peaking times from 0.5 us to 5 us, an input charge range equivalent to 30 keV, and a power consumption of less than 550 uW per channel. The RPC has been tested also with a 4x4 prototype PixDD and 167 eV Full Width at Half Maximum (FWHM) at the 5.9 keV line of 55Fe at 0{\deg}C and 1.8 us of peaking time has been measured.
ZippyPoint: Fast Interest Point Detection, Description, and Matching through Mixed Precision Discretization
Mar 07, 2022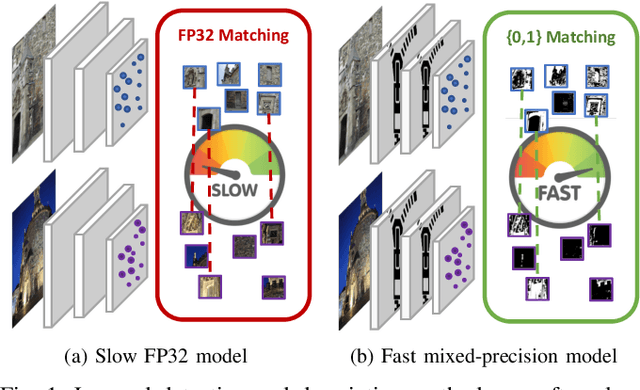
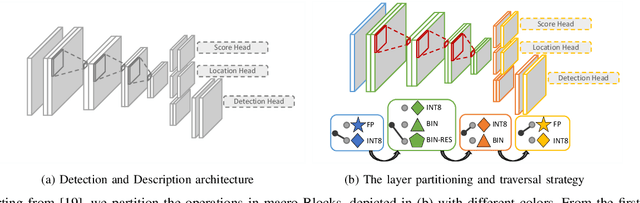
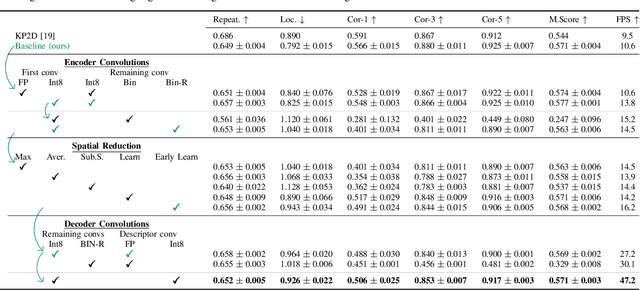

The design of more complex and powerful neural network models has significantly advanced the state-of-the-art in local feature detection and description. These advances can be attributed to deeper networks, improved training methodologies through self-supervision, or the introduction of new building blocks, such as graph neural networks for feature matching. However, in the pursuit of increased performance, efficient architectures that generate lightweight descriptors have received surprisingly little attention. In this paper, we investigate the adaptations neural networks for detection and description require in order to enable their use in embedded platforms. To that end, we investigate and adapt network quantization techniques for use in real-time applications. In addition, we revisit common practices in descriptor quantization and propose the use of a binary descriptor normalization layer, enabling the generation of distinctive length-invariant binary descriptors. ZippyPoint, our efficient network, runs at 47.2 fps on the Apple M1 CPU. This is up to 5x faster than other learned detection and description models, making it the only real-time learned network. ZippyPoint consistently outperforms all other binary detection and descriptor methods in visual localization and homography estimation tasks. Code and trained models will be released upon publication.
Ensembles of Localised Models for Time Series Forecasting
Dec 30, 2020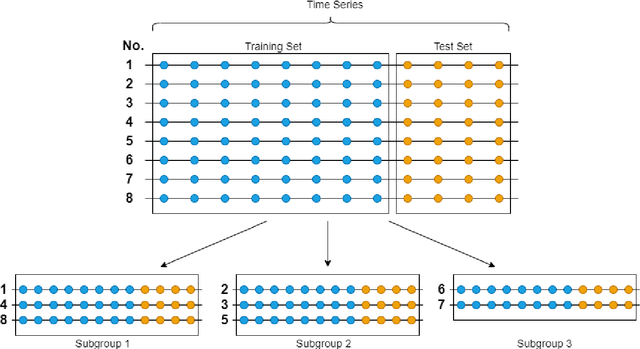

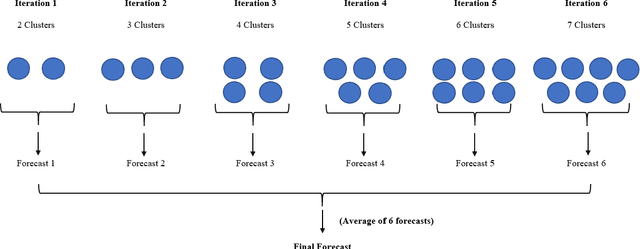
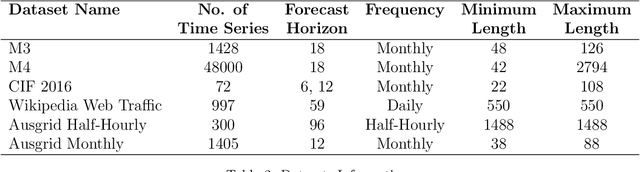
With large quantities of data typically available nowadays, forecasting models that are trained across sets of time series, known as Global Forecasting Models (GFM), are regularly outperforming traditional univariate forecasting models that work on isolated series. As GFMs usually share the same set of parameters across all time series, they often have the problem of not being localised enough to a particular series, especially in situations where datasets are heterogeneous. We study how ensembling techniques can be used with generic GFMs and univariate models to solve this issue. Our work systematises and compares relevant current approaches, namely clustering series and training separate submodels per cluster, the so-called ensemble of specialists approach, and building heterogeneous ensembles of global and local models. We fill some gaps in the approaches and generalise them to different underlying GFM model types. We then propose a new methodology of clustered ensembles where we train multiple GFMs on different clusters of series, obtained by changing the number of clusters and cluster seeds. Using Feed-forward Neural Networks, Recurrent Neural Networks, and Pooled Regression models as the underlying GFMs, in our evaluation on six publicly available datasets, the proposed models are able to achieve significantly higher accuracy than baseline GFM models and univariate forecasting methods.
Leveraging Tactile Sensors for Low Latency Embedded Smart Hands for Prosthetic and Robotic Applications
Mar 28, 2022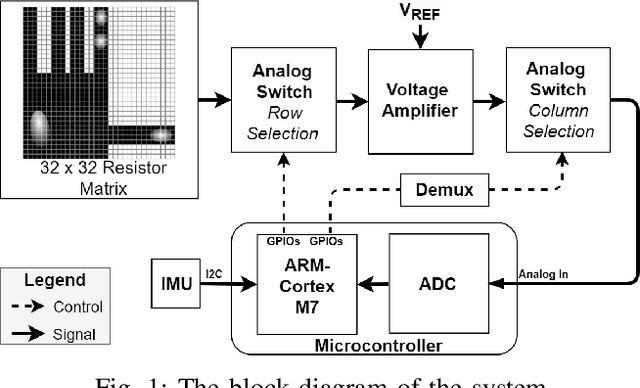
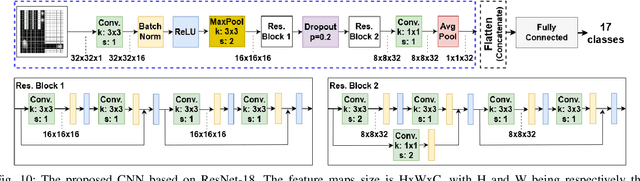

Tactile sensing is a crucial perception mode for robots and human amputees in need of controlling a prosthetic device. Today robotic and prosthetic systems are still missing the important feature of accurate tactile sensing. This lack is mainly due to the fact that the existing tactile technologies have limited spatial and temporal resolution and are either expensive or not scalable. In this paper, we present the design and the implementation of a hardware-software embedded system called SmartHand. It is specifically designed to enable the acquisition and the real-time processing of high-resolution tactile information from a hand-shaped multi-sensor array for prosthetic and robotic applications. During data collection, our system can deliver a high throughput of 100 frames per second, which is 13.7x higher than previous related work. We collected a new tactile dataset while interacting with daily-life objects during five different sessions. We propose a compact yet accurate convolutional neural network that requires one order of magnitude less memory and 15.6x fewer computations compared to related work without degrading classification accuracy. The top-1 and top-3 cross-validation accuracies are respectively 98.86% and 99.83%. We further analyze the inter-session variability and obtain the best top-3 leave-one-out-validation accuracy of 77.84%. We deploy the trained model on a high-performance ARM Cortex-M7 microcontroller achieving an inference time of only 100 ms minimizing the response latency. The overall measured power consumption is 505 mW. Finally, we fabricate a new control sensor and perform additional experiments to provide analyses on sensor degradation and slip detection. This work is a step forward in giving robotic and prosthetic devices a sense of touch and demonstrates the practicality of a smart embedded system empowered by tiny machine learning.
Machine learning based event classification for the energy-differential measurement of the $^\text{nat}$C(n,p) and $^\text{nat}$C(n,d) reactions
Apr 11, 2022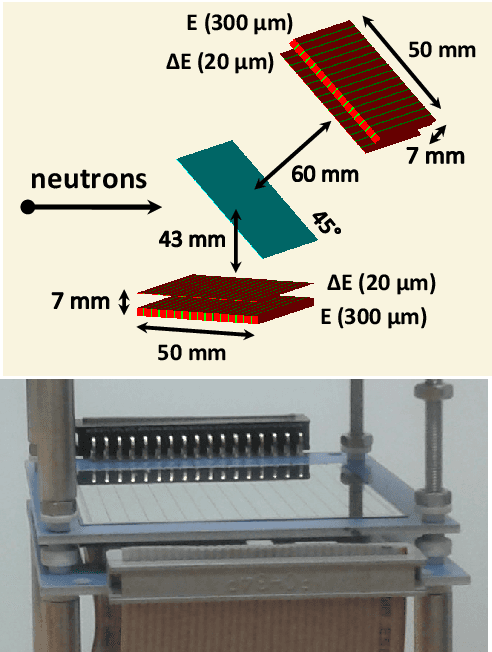

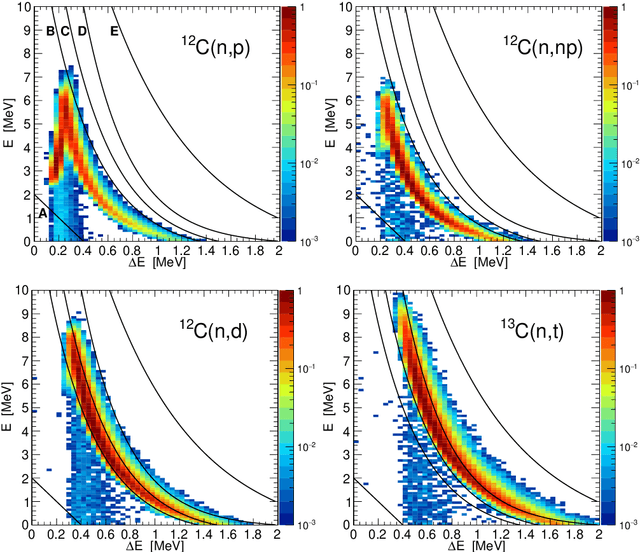

The paper explores the feasibility of using machine learning techniques, in particular neural networks, for classification of the experimental data from the joint $^\text{nat}$C(n,p) and $^\text{nat}$C(n,d) reaction cross section measurement from the neutron time of flight facility n_TOF at CERN. Each relevant $\Delta E$-$E$ pair of strips from two segmented silicon telescopes is treated separately and afforded its own dedicated neural network. An important part of the procedure is a careful preparation of training datasets, based on the raw data from Geant4 simulations. Instead of using these raw data for the training of neural networks, we divide a relevant 3-parameter space into discrete voxels, classify each voxel according to a particle/reaction type and submit these voxels to a training procedure. The classification capabilities of the structurally optimized and trained neural networks are found to be superior to those of the manually selected cuts.
Event-aided Direct Sparse Odometry
Apr 15, 2022
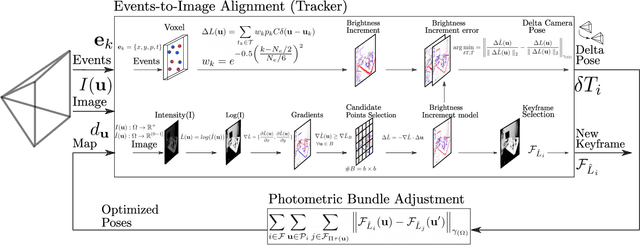
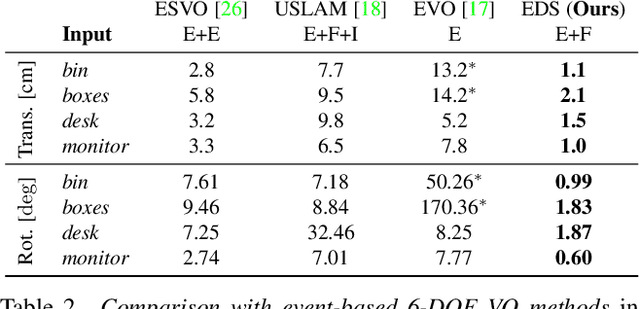

We introduce EDS, a direct monocular visual odometry using events and frames. Our algorithm leverages the event generation model to track the camera motion in the blind time between frames. The method formulates a direct probabilistic approach of observed brightness increments. Per-pixel brightness increments are predicted using a sparse number of selected 3D points and are compared to the events via the brightness increment error to estimate camera motion. The method recovers a semi-dense 3D map using photometric bundle adjustment. EDS is the first method to perform 6-DOF VO using events and frames with a direct approach. By design, it overcomes the problem of changing appearance in indirect methods. We also show that, for a target error performance, EDS can work at lower frame rates than state-of-the-art frame-based VO solutions. This opens the door to low-power motion-tracking applications where frames are sparingly triggered "on demand" and our method tracks the motion in between. We release code and datasets to the public.
* 16 pages, 14 Figures, Page: https://rpg.ifi.uzh.ch/eds
TSAX is Trending
Dec 24, 2021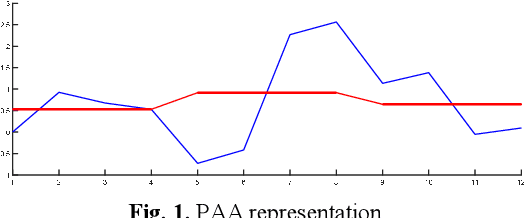
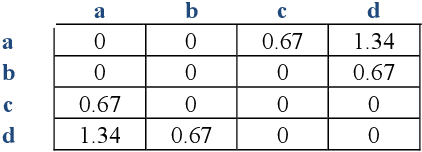
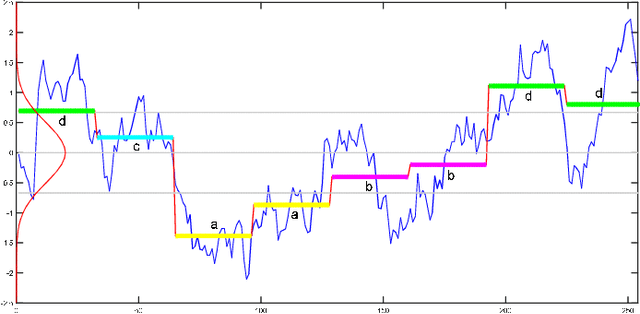
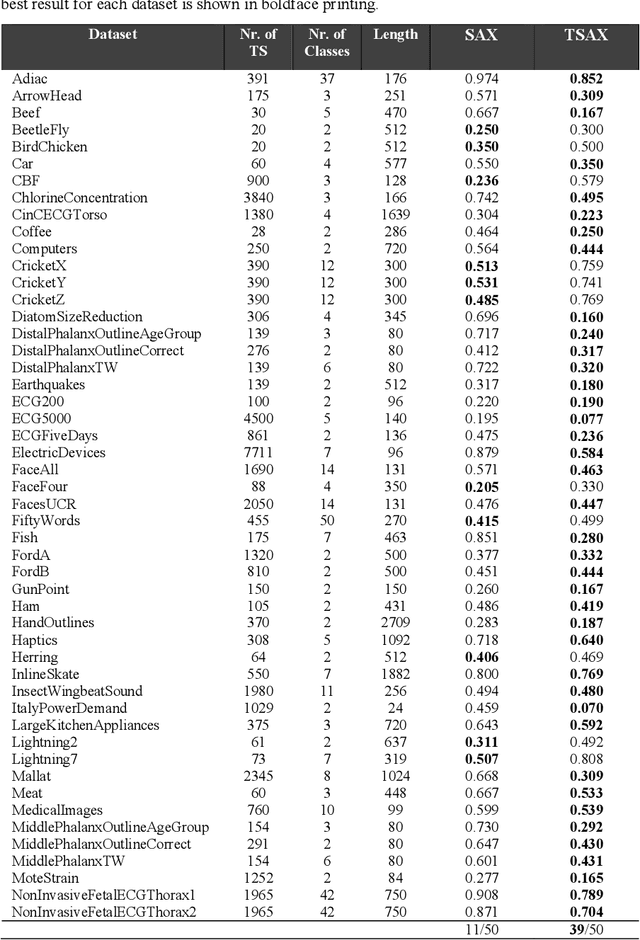
Time series mining is an important branch of data mining, as time series data is ubiquitous and has many applications in several domains. The main task in time series mining is classification. Time series representation methods play an important role in time series classification and other time series mining tasks. One of the most popular representation methods of time series data is the Symbolic Aggregate approXimation (SAX). The secret behind its popularity is its simplicity and efficiency. SAX has however one major drawback, which is its inability to represent trend information. Several methods have been proposed to enable SAX to capture trend information, but this comes at the expense of complex processing, preprocessing, or post-processing procedures. In this paper we present a new modification of SAX that we call Trending SAX (TSAX), which only adds minimal complexity to SAX, but substantially improves its performance in time series classification. This is validated experimentally on 50 datasets. The results show the superior performance of our method, as it gives a smaller classification error on 39 datasets compared with SAX.
* 21st International Conference on Computational Science (ICCS 2021)
Occlusion-Aware Cost Constructor for Light Field Depth Estimation
Mar 03, 2022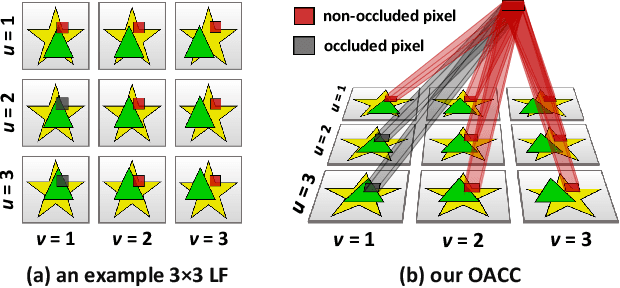

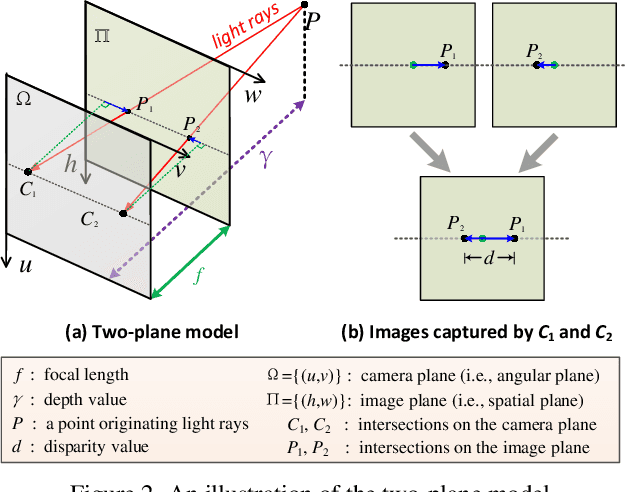
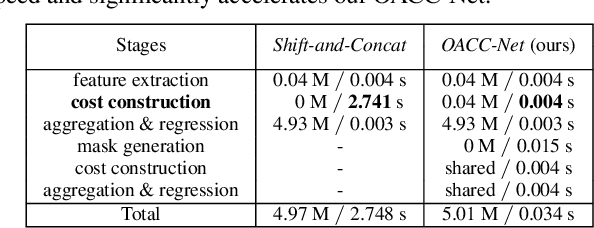
Matching cost construction is a key step in light field (LF) depth estimation, but was rarely studied in the deep learning era. Recent deep learning-based LF depth estimation methods construct matching cost by sequentially shifting each sub-aperture image (SAI) with a series of predefined offsets, which is complex and time-consuming. In this paper, we propose a simple and fast cost constructor to construct matching cost for LF depth estimation. Our cost constructor is composed by a series of convolutions with specifically designed dilation rates. By applying our cost constructor to SAI arrays, pixels under predefined disparities can be integrated and matching cost can be constructed without using any shifting operation. More importantly, the proposed cost constructor is occlusion-aware and can handle occlusions by dynamically modulating pixels from different views. Based on the proposed cost constructor, we develop a deep network for LF depth estimation. Our network ranks first on the commonly used 4D LF benchmark in terms of the mean square error (MSE), and achieves a faster running time than other state-of-the-art methods.
A Formally Robust Time Series Distance Metric
Aug 18, 2020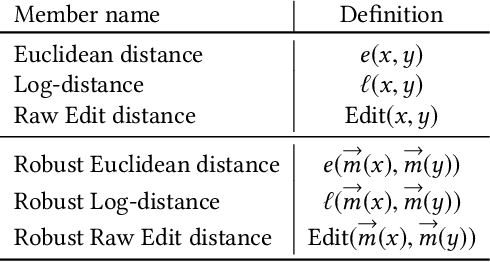
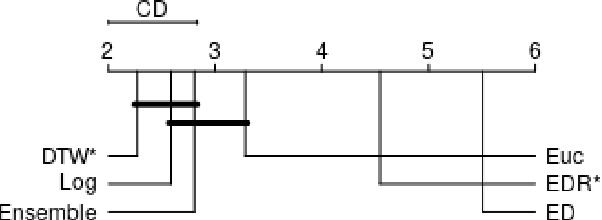
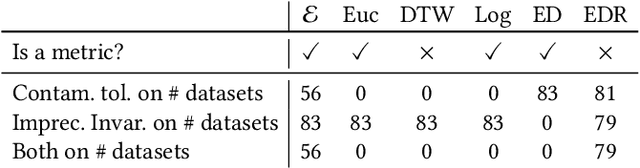
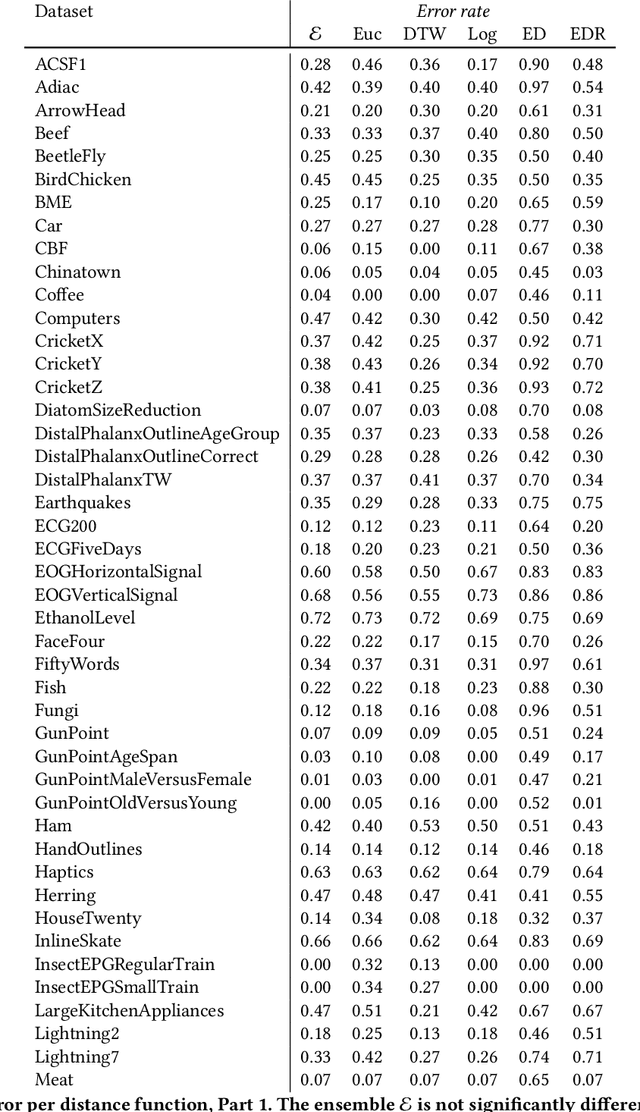
Distance-based classification is among the most competitive classification methods for time series data. The most critical component of distance-based classification is the selected distance function. Past research has proposed various different distance metrics or measures dedicated to particular aspects of real-world time series data, yet there is an important aspect that has not been considered so far: Robustness against arbitrary data contamination. In this work, we propose a novel distance metric that is robust against arbitrarily "bad" contamination and has a worst-case computational complexity of $\mathcal{O}(n\log n)$. We formally argue why our proposed metric is robust, and demonstrate in an empirical evaluation that the metric yields competitive classification accuracy when applied in k-Nearest Neighbor time series classification.