 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Caching with no Regret: Optimistic Learning via Recommendations
Apr 20, 2022
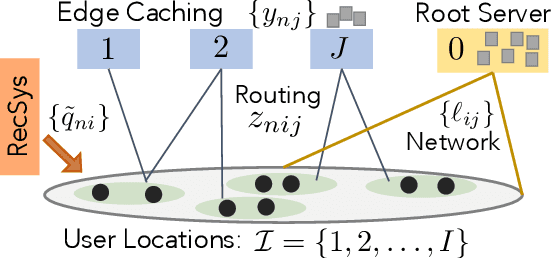
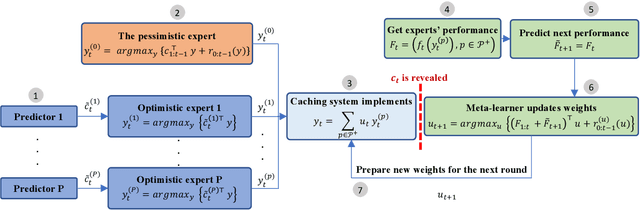
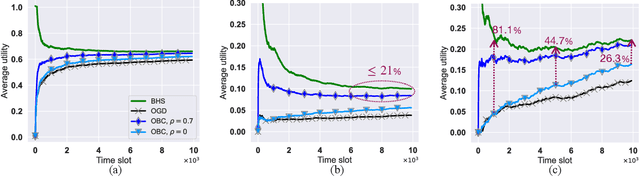
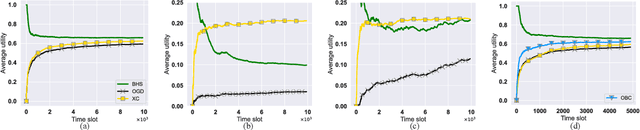
The design of effective online caching policies is an increasingly important problem for content distribution networks, online social networks and edge computing services, among other areas. This paper proposes a new algorithmic toolbox for tackling this problem through the lens of optimistic online learning. We build upon the Follow-the-Regularized-Leader (FTRL) framework, which is developed further here to include predictions for the file requests, and we design online caching algorithms for bipartite networks with fixed-size caches or elastic leased caches subject to time-average budget constraints. The predictions are provided by a content recommendation system that influences the users viewing activity and hence can naturally reduce the caching network's uncertainty about future requests. We also extend the framework to learn and utilize the best request predictor in cases where many are available. We prove that the proposed {optimistic} learning caching policies can achieve sub-zero performance loss (regret) for perfect predictions, and maintain the sub-linear regret bound $O(\sqrt T)$, which is the best achievable bound for policies that do not use predictions, even for arbitrary-bad predictions. The performance of the proposed algorithms is evaluated with detailed trace-driven numerical tests.
M2N: Mesh Movement Networks for PDE Solvers
Apr 24, 2022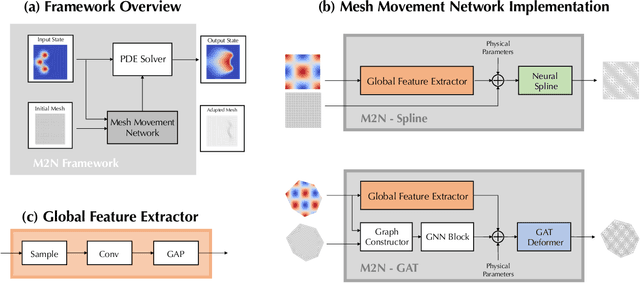
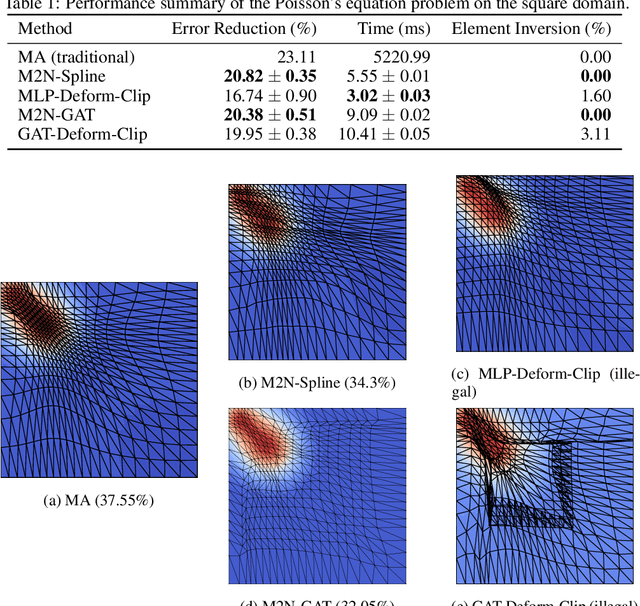
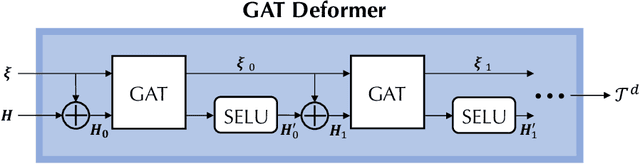
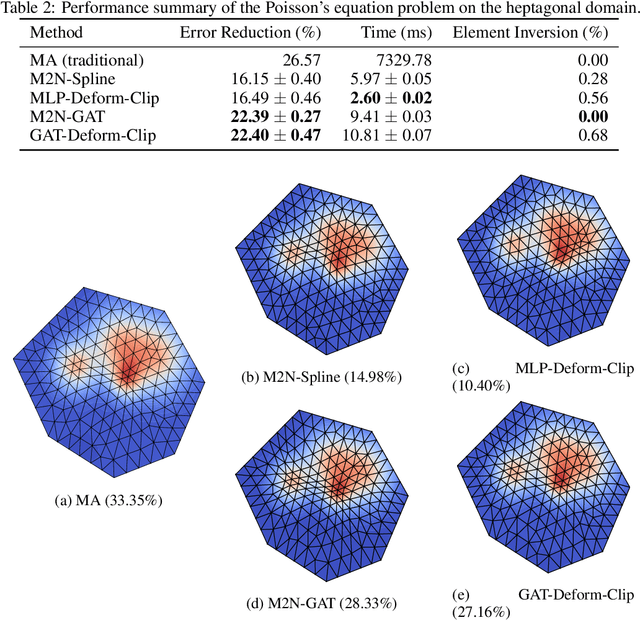
Mainstream numerical Partial Differential Equation (PDE) solvers require discretizing the physical domain using a mesh. Mesh movement methods aim to improve the accuracy of the numerical solution by increasing mesh resolution where the solution is not well-resolved, whilst reducing unnecessary resolution elsewhere. However, mesh movement methods, such as the Monge-Ampere method, require the solution of auxiliary equations, which can be extremely expensive especially when the mesh is adapted frequently. In this paper, we propose to our best knowledge the first learning-based end-to-end mesh movement framework for PDE solvers. Key requirements of learning-based mesh movement methods are alleviating mesh tangling, boundary consistency, and generalization to mesh with different resolutions. To achieve these goals, we introduce the neural spline model and the graph attention network (GAT) into our models respectively. While the Neural-Spline based model provides more flexibility for large deformation, the GAT based model can handle domains with more complicated shapes and is better at performing delicate local deformation. We validate our methods on stationary and time-dependent, linear and non-linear equations, as well as regularly and irregularly shaped domains. Compared to the traditional Monge-Ampere method, our approach can greatly accelerate the mesh adaptation process, whilst achieving comparable numerical error reduction.
Vision-Language Intelligence: Tasks, Representation Learning, and Large Models
Mar 03, 2022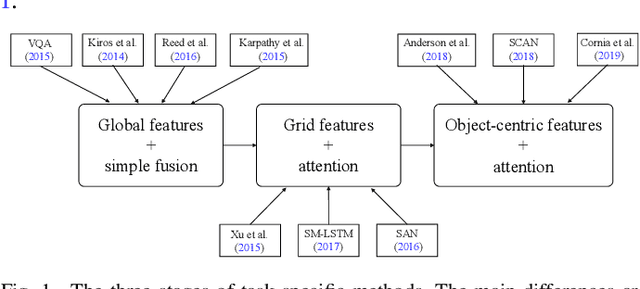
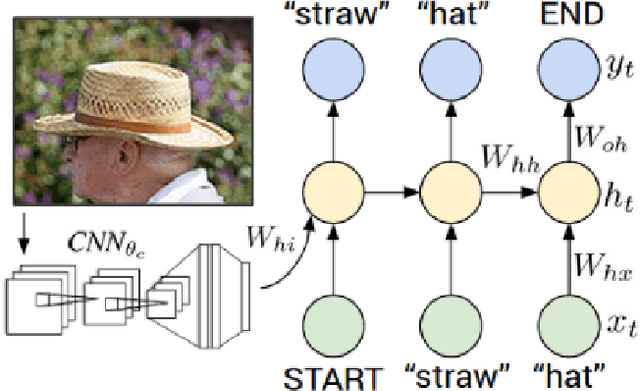
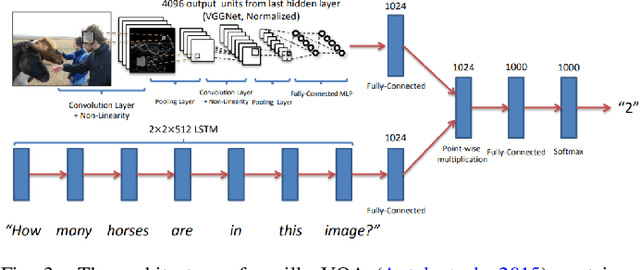
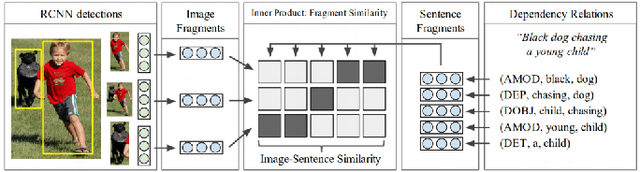
This paper presents a comprehensive survey of vision-language (VL) intelligence from the perspective of time. This survey is inspired by the remarkable progress in both computer vision and natural language processing, and recent trends shifting from single modality processing to multiple modality comprehension. We summarize the development in this field into three time periods, namely task-specific methods, vision-language pre-training (VLP) methods, and larger models empowered by large-scale weakly-labeled data. We first take some common VL tasks as examples to introduce the development of task-specific methods. Then we focus on VLP methods and comprehensively review key components of the model structures and training methods. After that, we show how recent work utilizes large-scale raw image-text data to learn language-aligned visual representations that generalize better on zero or few shot learning tasks. Finally, we discuss some potential future trends towards modality cooperation, unified representation, and knowledge incorporation. We believe that this review will be of help for researchers and practitioners of AI and ML, especially those interested in computer vision and natural language processing.
Automatic spinal curvature measurement on ultrasound spine images using Faster R-CNN
Apr 20, 2022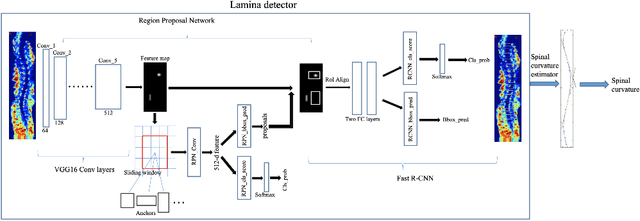
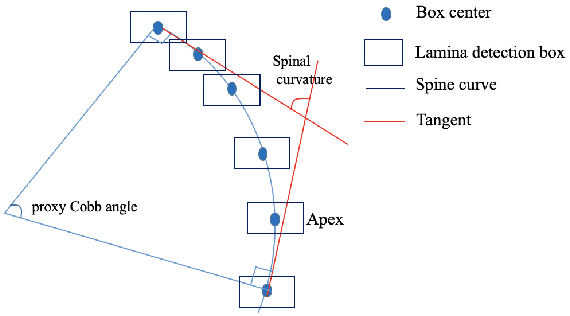
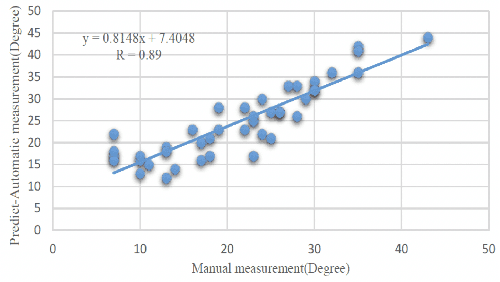
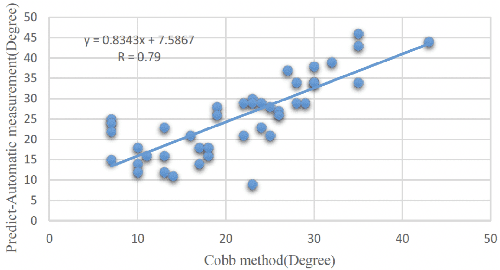
Ultrasound spine imaging technique has been applied to the assessment of spine deformity. However, manual measurements of scoliotic angles on ultrasound images are time-consuming and heavily rely on raters experience. The objectives of this study are to construct a fully automatic framework based on Faster R-CNN for detecting vertebral lamina and to measure the fitting spinal curves from the detected lamina pairs. The framework consisted of two closely linked modules: 1) the lamina detector for identifying and locating each lamina pairs on ultrasound coronal images, and 2) the spinal curvature estimator for calculating the scoliotic angles based on the chain of detected lamina. Two hundred ultrasound images obtained from AIS patients were identified and used for the training and evaluation of the proposed method. The experimental results showed the 0.76 AP on the test set, and the Mean Absolute Difference (MAD) between automatic and manual measurement which was within the clinical acceptance error. Meanwhile the correlation between automatic measurement and Cobb angle from radiographs was 0.79. The results revealed that our proposed technique could provide accurate and reliable automatic curvature measurements on ultrasound spine images for spine deformities.
Bone marrow sparing for cervical cancer radiotherapy on multimodality medical images
Apr 20, 2022
Cervical cancer threatens the health of women seriously. Radiotherapy is one of the main therapy methods but with high risk of acute hematologic toxicity. Delineating the bone marrow (BM) for sparing using computer tomography (CT) images to plan before radiotherapy can effectively avoid this risk. Comparing with magnetic resonance (MR) images, CT lacks the ability to express the activity of BM. Thus, in current clinical practice, medical practitioners manually delineate the BM on CT images by corresponding to MR images. However, the time?consuming delineating BM by hand cannot guarantee the accuracy due to the inconsistency of the CT-MR multimodal images. In this study, we propose a multimodal image oriented automatic registration method for pelvic BM sparing, which consists of three-dimensional bone point cloud reconstruction, a local spherical system iteration closest point registration for marking BM on CT images. Experiments on patient dataset reveal that our proposed method can enhance the multimodal image registration accuracy and efficiency for medical practitioners in sparing BM of cervical cancer radiotherapy. The method proposed in this contribution might also provide references for similar studies in other clinical application.
Domain Specific Fine-tuning of Denoising Sequence-to-Sequence Models for Natural Language Summarization
Apr 06, 2022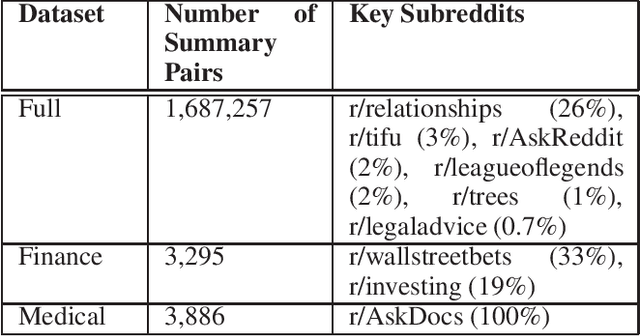


Summarization of long-form text data is a problem especially pertinent in knowledge economy jobs such as medicine and finance, that require continuously remaining informed on a sophisticated and evolving body of knowledge. As such, isolating and summarizing key content automatically using Natural Language Processing (NLP) techniques holds the potential for extensive time savings in these industries. We explore applications of a state-of-the-art NLP model (BART), and explore strategies for tuning it to optimal performance using data augmentation and various fine-tuning strategies. We show that our end-to-end fine-tuning approach can result in a 5-6\% absolute ROUGE-1 improvement over an out-of-the-box pre-trained BART summarizer when tested on domain specific data, and make available our end-to-end pipeline to achieve these results on finance, medical, or other user-specified domains.
Ensembles of Localised Models for Time Series Forecasting
Dec 30, 2020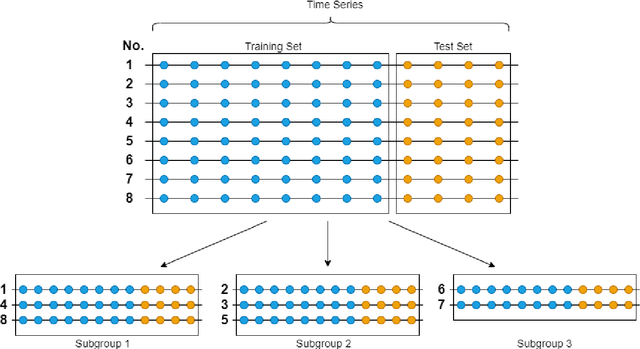

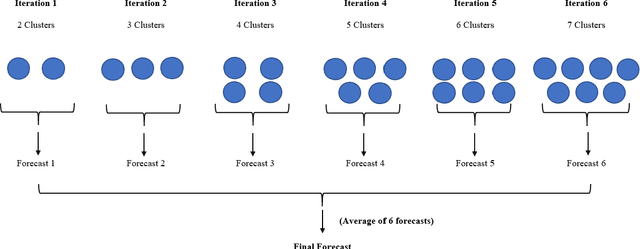
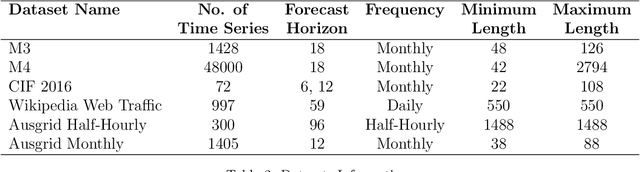
With large quantities of data typically available nowadays, forecasting models that are trained across sets of time series, known as Global Forecasting Models (GFM), are regularly outperforming traditional univariate forecasting models that work on isolated series. As GFMs usually share the same set of parameters across all time series, they often have the problem of not being localised enough to a particular series, especially in situations where datasets are heterogeneous. We study how ensembling techniques can be used with generic GFMs and univariate models to solve this issue. Our work systematises and compares relevant current approaches, namely clustering series and training separate submodels per cluster, the so-called ensemble of specialists approach, and building heterogeneous ensembles of global and local models. We fill some gaps in the approaches and generalise them to different underlying GFM model types. We then propose a new methodology of clustered ensembles where we train multiple GFMs on different clusters of series, obtained by changing the number of clusters and cluster seeds. Using Feed-forward Neural Networks, Recurrent Neural Networks, and Pooled Regression models as the underlying GFMs, in our evaluation on six publicly available datasets, the proposed models are able to achieve significantly higher accuracy than baseline GFM models and univariate forecasting methods.
Towards A COLREGs Compliant Autonomous Surface Vessel in a Constrained Channel
Apr 27, 2022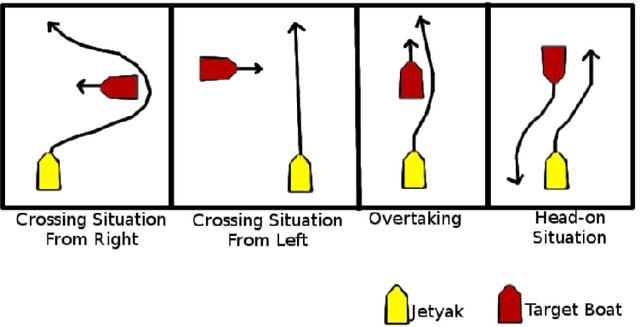
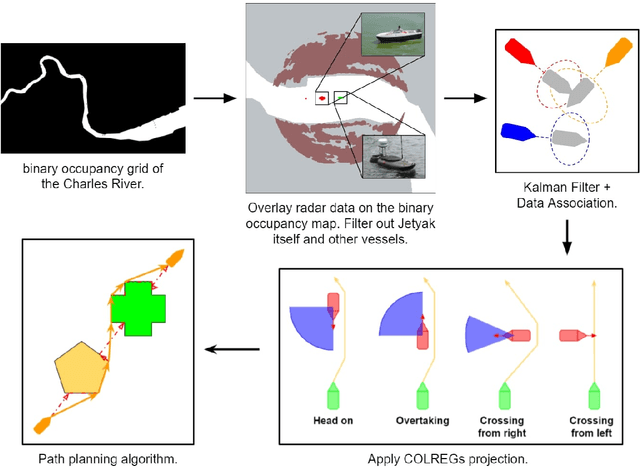

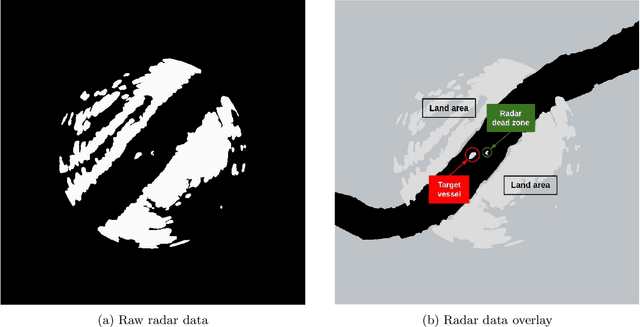
In this paper, we look at the role of autonomous navigation in the maritime domain. Specifically, we examine how an Autonomous Surface Vessel(ASV) can achieve obstacle avoidance based on the Convention on the International Regulations for Preventing Collisions at Sea (1972), or COLREGs, in real-world environments. Our ASV is equipped with a broadband marine radar, an Inertial Navigation System (INS), and uses official Electronic Navigational Charts (ENC). These sensors are used to provide situational awareness and, in series of well-defined steps, we can exclude land objects from the radar data, extract tracks associated with moving vessels within range of the radar, and then use a Kalman Filter to track and predict the motion of other moving vessels in the vicinity. A Constant Velocity model for the Kalman Filter allows us to solve the data association to build a consistent model between successive radar scans. We account for multiple COLREGs situations based on the predicted relative motion. Finally, an efficient path planning algorithm is presented to find a path and publish waypoints to perform real-time COLREGs compliant autonomous navigation within highly constrained environments. We demonstrate the results of our framework with operational results collected over the course of a 3.4 nautical mile mission on the Charles River in Boston in which the ASV encountered and successfully navigated multiple scenarios and encounters with other moving vessels at close quarters.
Ultrafast Ultrasound Imaging for 3D Shear Wave Absolute Vibro-Elastography
Mar 26, 2022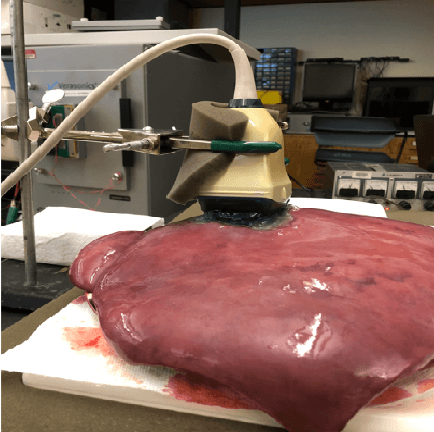

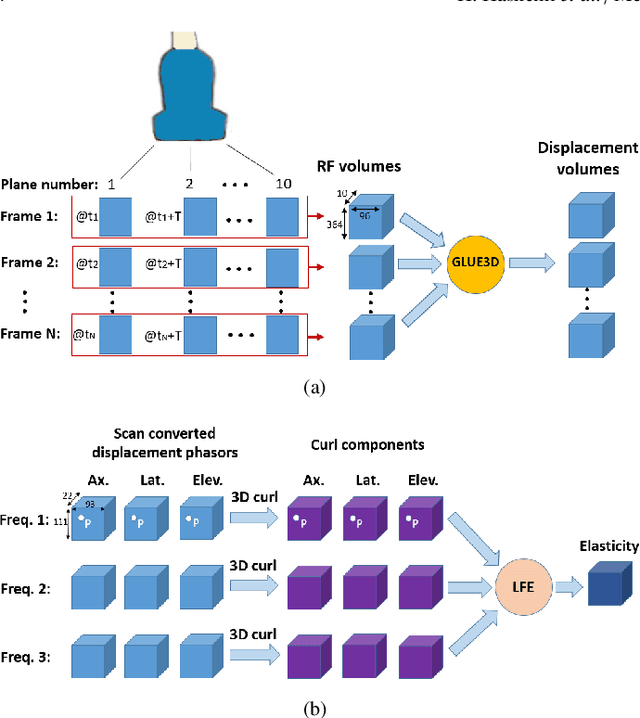
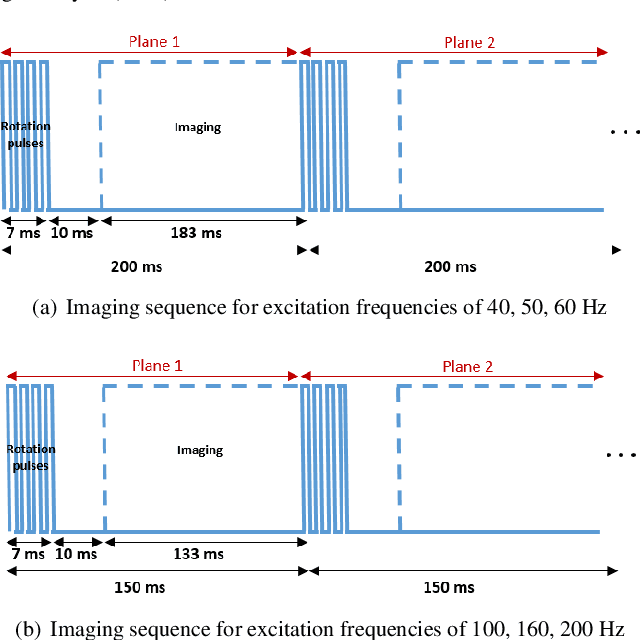
Shear wave absolute vibro-elastography (S-WAVE) is an imaging technique that generates steady-state shear waves inside the tissue using multi-frequency excitation from an external vibration source. In this work, plane wave imaging is introduced to reduce total acquisition time while retaining the benefit of 3D formulation. Plane wave imaging with a frame rate of 3000 frames/s is followed by 3D absolute elasticity estimation. We design two imaging sequences of ultrafast S-WAVE for two sets of excitation frequencies using a Verasonics system and a motorized swept ultrasound transducer to synchronize ultrasound acquisition with the external mechanical excitation. The overall data collection time is improved by 83-88% compared to the original 3D S-WAVE because of the per-channel acquisition offered by the Verasonics system. Tests are performed on liver fibrosis tissue-mimicking phantoms and on ex vivo bovine liver. The curl operator was previously used in magnetic resonance elastography (MRE) to cancel out the effect of the compressional waves. In this work, we apply the curl operator to the full 3D displacement field followed by 3D elasticity reconstruction. The results of phantom experiment show more accurate elasticity estimation as well as 18% less standard deviation (STD) compared to reconstruction using the curl of a 2D displacement field and 45% less STD than without the curl. We also compare our experimental results with a previous method based on acoustic radiation force impulse (ARFI) and achieve closer results to phantom manufacturer provided values with ultrafast S-WAVE. Furthermore, the dependency of the bovine liver elasticity on the frequency of excitation was also shown with our system.
Direct LiDAR-Inertial Odometry
Mar 07, 2022
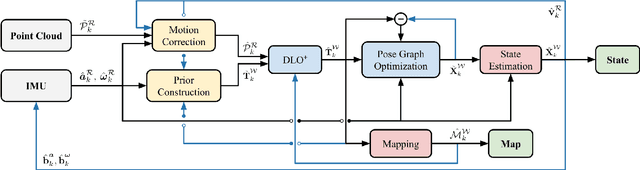
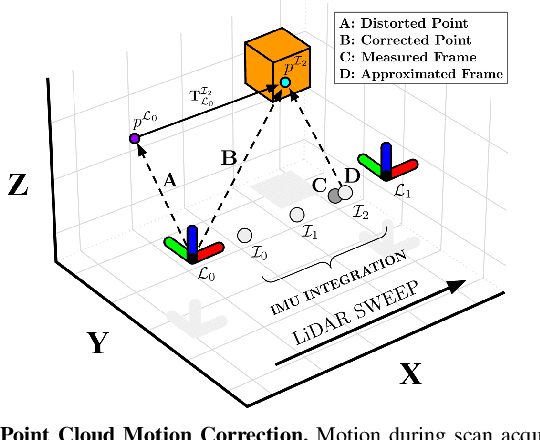
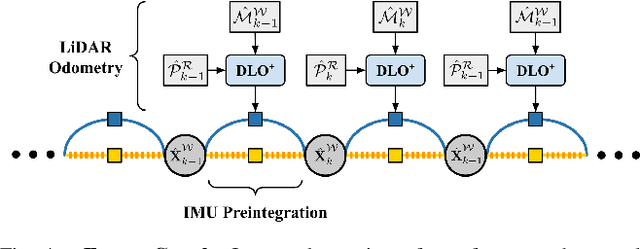
This paper proposes a new LiDAR-inertial odometry framework that generates accurate state estimates and detailed maps in real-time on resource-constrained mobile robots. Our Direct LiDAR-Inertial Odometry (DLIO) algorithm utilizes a hybrid architecture that combines the benefits of loosely-coupled and tightly-coupled IMU integration to enhance reliability and real-time performance while improving accuracy. The proposed architecture has two key elements. The first is a fast keyframe-based LiDAR scan-matcher that builds an internal map by registering dense point clouds to a local submap with a translational and rotational prior generated by a nonlinear motion model. The second is a factor graph and high-rate propagator that fuses the output of the scan-matcher with preintegrated IMU measurements for up-to-date pose, velocity, and bias estimates. These estimates enable us to accurately deskew the next point cloud using a nonlinear kinematic model for precise motion correction, in addition to initializing the next scan-to-map optimization prior. We demonstrate DLIO's superior localization accuracy, map quality, and lower computational overhead by comparing it to the state-of-the-art using multiple benchmark, public, and self-collected datasets on both consumer and hobby-grade hardware.