 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wind speed forecast using random forest learning method
Mar 23, 2022
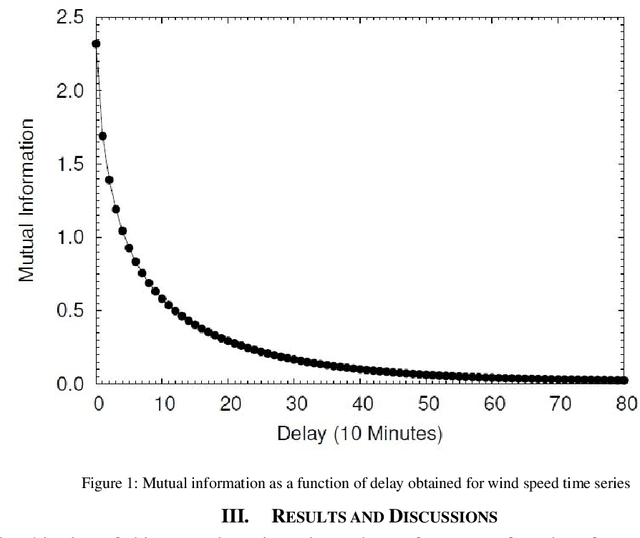
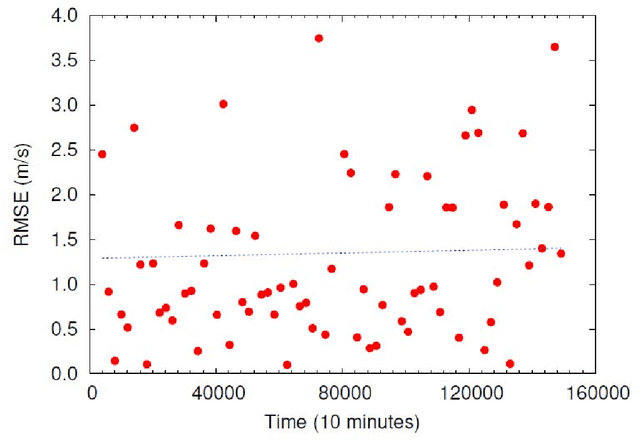
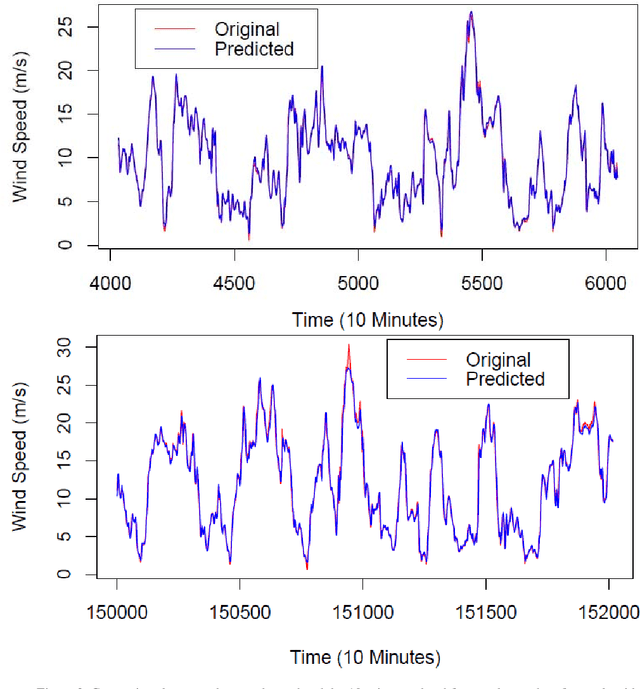
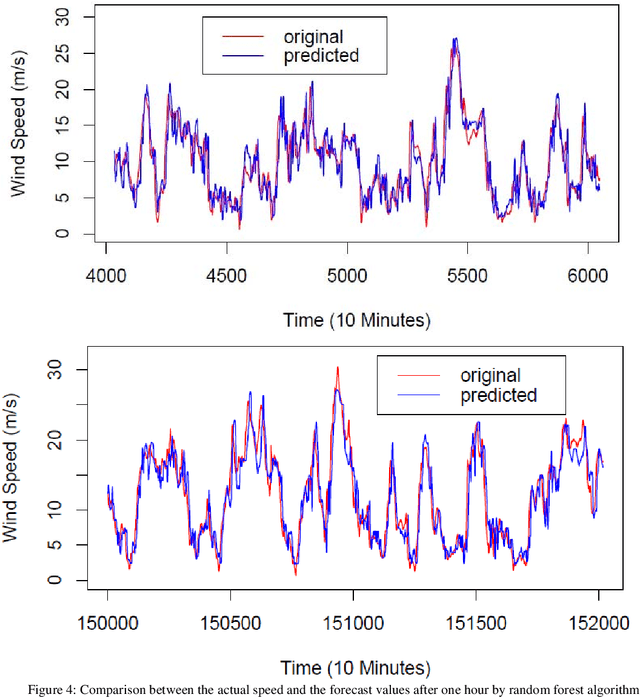
Wind speed forecasting models and their application to wind farm operations are attaining remarkable attention in the literature because of its benefits as a clean energy source. In this paper, we suggested the time series machine learning approach called random forest regression for predicting wind speed variations. The computed values of mutual information and auto-correlation shows that wind speed values depend on the past data up to 12 hours. The random forest model was trained using ensemble from two weeks data with previous 12 hours values as input for every value. The computed root mean square error shows that model trained with two weeks data can be employed to make reliable short-term predictions up to three years ahead.
PGD: A Large-scale Professional Go Dataset for Data-driven Analytics
Apr 30, 2022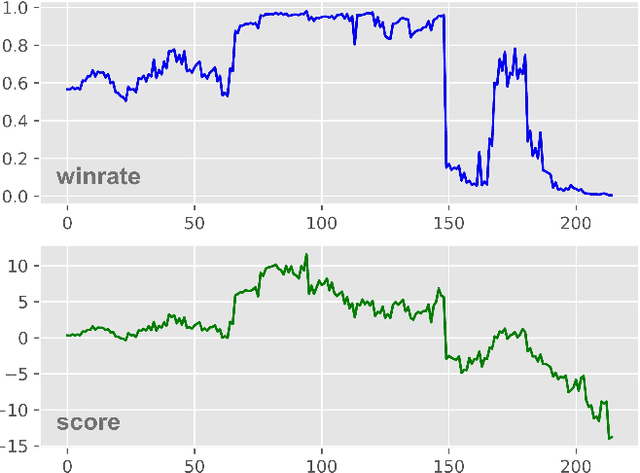
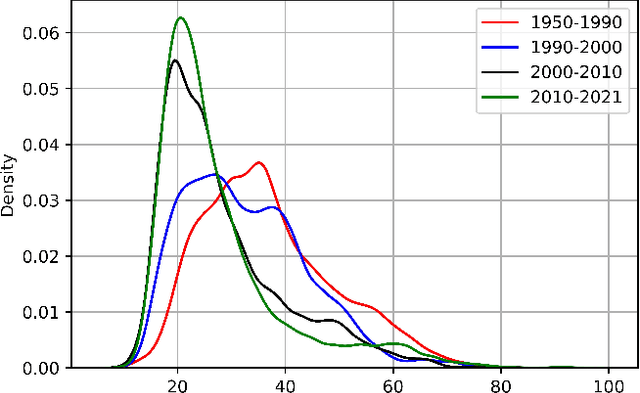
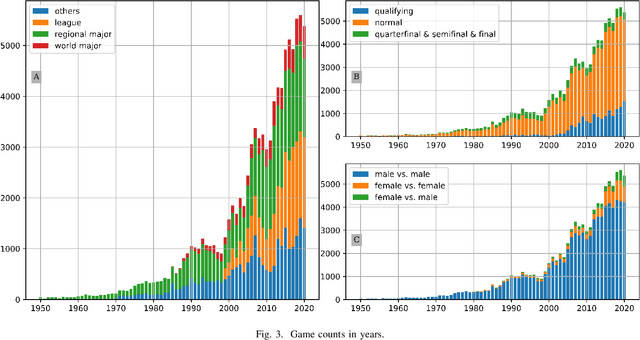
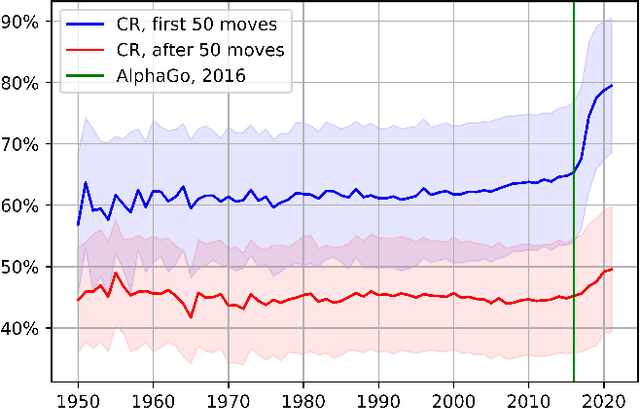
Lee Sedol is on a winning streak--does this legend rise again after the competition with AlphaGo? Ke Jie is invincible in the world championship--can he still win the title this time? Go is one of the most popular board games in East Asia, with a stable professional sports system that has lasted for decades in China, Japan, and Korea. There are mature data-driven analysis technologies for many sports, such as soccer, basketball, and esports. However, developing such technology for Go remains nontrivial and challenging due to the lack of datasets, meta-information, and in-game statistics. This paper creates the Professional Go Dataset (PGD), containing 98,043 games played by 2,148 professional players from 1950 to 2021. After manual cleaning and labeling, we provide detailed meta-information for each player, game, and tournament. Moreover, the dataset includes analysis results for each move in the match evaluated by advanced AlphaZero-based AI. To establish a benchmark for PGD, we further analyze the data and extract meaningful in-game features based on prior knowledge related to Go that can indicate the game status. With the help of complete meta-information and constructed in-game features, our results prediction system achieves an accuracy of 75.30%, much higher than several state-of-the-art approaches (64%-65%). As far as we know, PGD is the first dataset for data-driven analytics in Go and even in board games. Beyond this promising result, we provide more examples of tasks that benefit from our dataset. The ultimate goal of this paper is to bridge this ancient game and the modern data science community. It will advance research on Go-related analytics to enhance the fan experience, help players improve their ability, and facilitate other promising aspects. The dataset will be made publicly available.
The Quest for a Common Model of the Intelligent Decision Maker
Feb 26, 2022The premise of Multi-disciplinary Conference on Reinforcement Learning and Decision Making is that multiple disciplines share an interest in goal-directed decision making over time. The idea of this paper is to sharpen and deepen this premise by proposing a perspective on the decision maker that is substantive and widely held across psychology, artificial intelligence, economics, control theory, and neuroscience, which I call the "common model of the intelligent agent". The common model does not include anything specific to any organism, world, or application domain. The common model does include aspects of the decision maker's interaction with its world (there must be input and output, and a goal) and internal components of the decision maker (for perception, decision-making, internal evaluation, and a world model). I identify these aspects and components, note that they are given different names in different disciplines but refer essentially to the same ideas, and discuss the challenges and benefits of devising a neutral terminology that can be used across disciplines. It is time to recognize and build on the convergence of multiple diverse disciplines on a substantive common model of the intelligent agent.
Learning Dynamics and Structure of Complex Systems Using Graph Neural Networks
Feb 22, 2022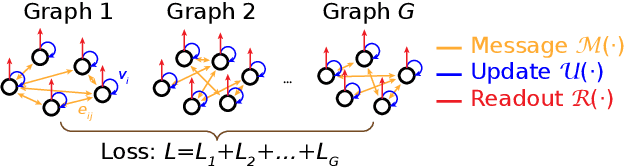
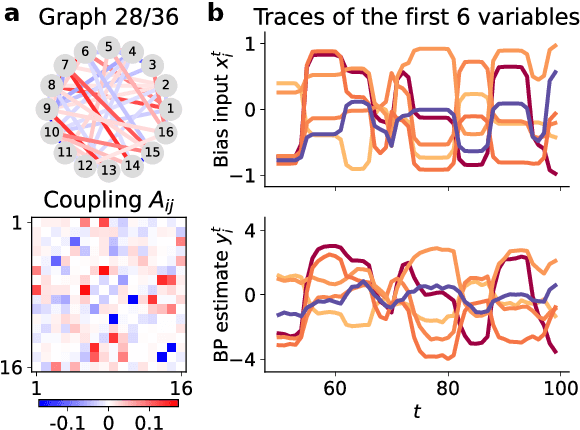
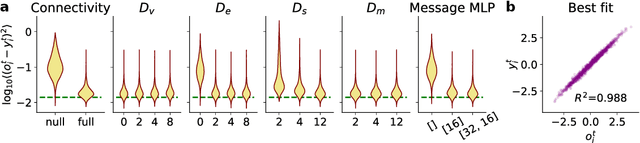
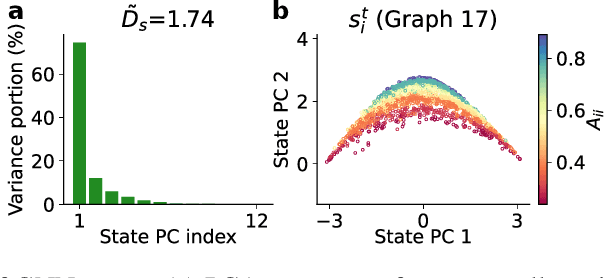
Many complex systems are composed of interacting parts, and the underlying laws are usually simple and universal. While graph neural networks provide a useful relational inductive bias for modeling such systems, generalization to new system instances of the same type is less studied. In this work we trained graph neural networks to fit time series from an example nonlinear dynamical system, the belief propagation algorithm. We found simple interpretations of the learned representation and model components, and they are consistent with core properties of the probabilistic inference algorithm. We successfully identified a `graph translator' between the statistical interactions in belief propagation and parameters of the corresponding trained network, and showed that it enables two types of novel generalization: to recover the underlying structure of a new system instance based solely on time series observations, or to construct a new network from this structure directly. Our results demonstrated a path towards understanding both dynamics and structure of a complex system and how such understanding can be used for generalization.
Real-time Localized Photorealistic Video Style Transfer
Oct 20, 2020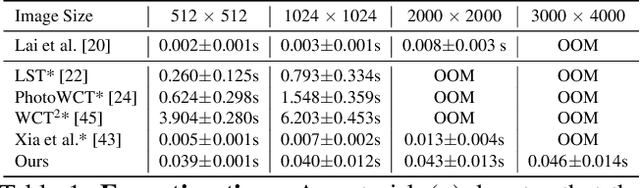
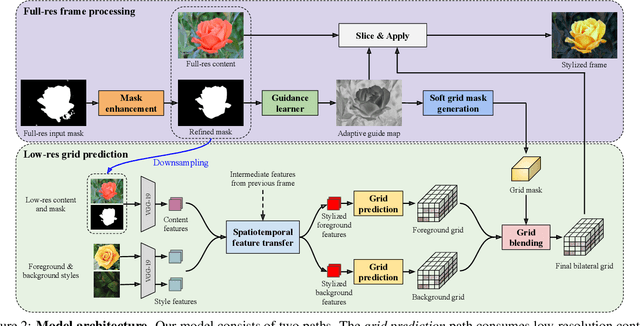
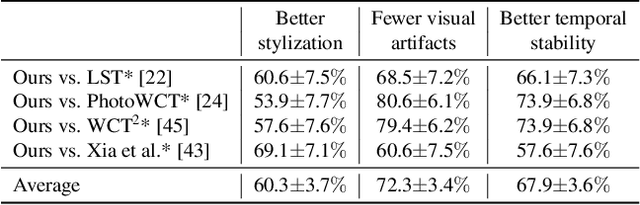

We present a novel algorithm for transferring artistic styles of semantically meaningful local regions of an image onto local regions of a target video while preserving its photorealism. Local regions may be selected either fully automatically from an image, through using video segmentation algorithms, or from casual user guidance such as scribbles. Our method, based on a deep neural network architecture inspired by recent work in photorealistic style transfer, is real-time and works on arbitrary inputs without runtime optimization once trained on a diverse dataset of artistic styles. By augmenting our video dataset with noisy semantic labels and jointly optimizing over style, content, mask, and temporal losses, our method can cope with a variety of imperfections in the input and produce temporally coherent videos without visual artifacts. We demonstrate our method on a variety of style images and target videos, including the ability to transfer different styles onto multiple objects simultaneously, and smoothly transition between styles in time.
Don't Touch What Matters: Task-Aware Lipschitz Data Augmentation for Visual Reinforcement Learning
Feb 22, 2022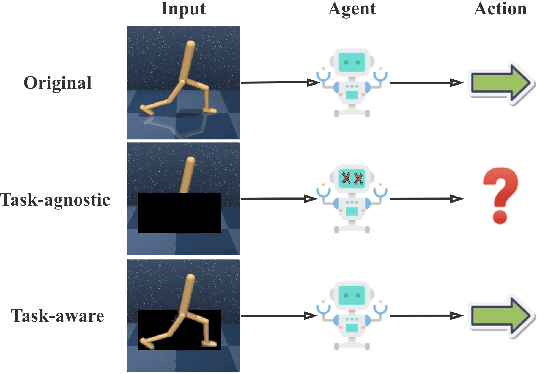
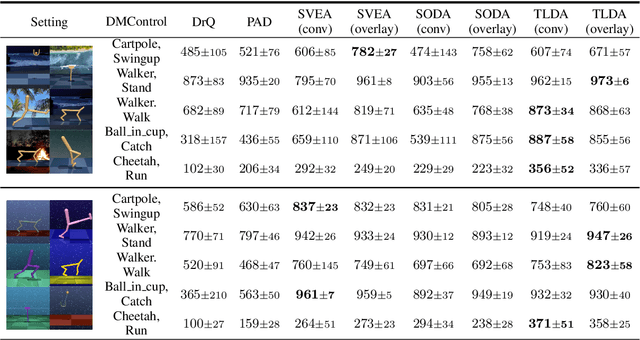
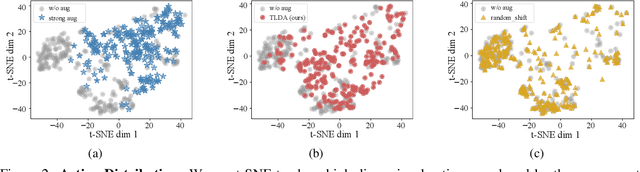
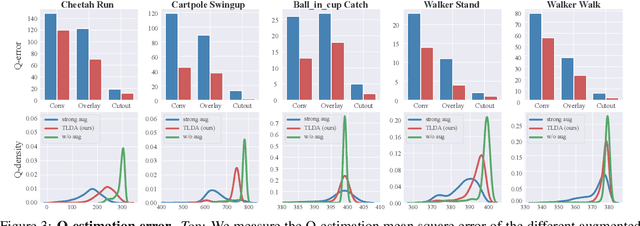
One of the key challenges in visual Reinforcement Learning (RL) is to learn policies that can generalize to unseen environments. Recently, data augmentation techniques aiming at enhancing data diversity have demonstrated proven performance in improving the generalization ability of learned policies. However, due to the sensitivity of RL training, naively applying data augmentation, which transforms each pixel in a task-agnostic manner, may suffer from instability and damage the sample efficiency, thus further exacerbating the generalization performance. At the heart of this phenomenon is the diverged action distribution and high-variance value estimation in the face of augmented images. To alleviate this issue, we propose Task-aware Lipschitz Data Augmentation (TLDA) for visual RL, which explicitly identifies the task-correlated pixels with large Lipschitz constants, and only augments the task-irrelevant pixels. To verify the effectiveness of TLDA, we conduct extensive experiments on DeepMind Control suite, CARLA and DeepMind Manipulation tasks, showing that TLDA improves both sample efficiency in training time and generalization in test time. It outperforms previous state-of-the-art methods across the 3 different visual control benchmarks.
Feature Compression for Rate Constrained Object Detection on the Edge
Apr 15, 2022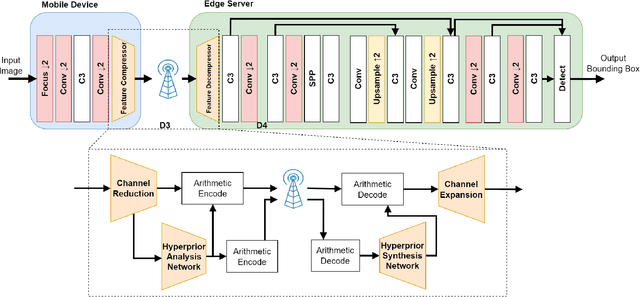

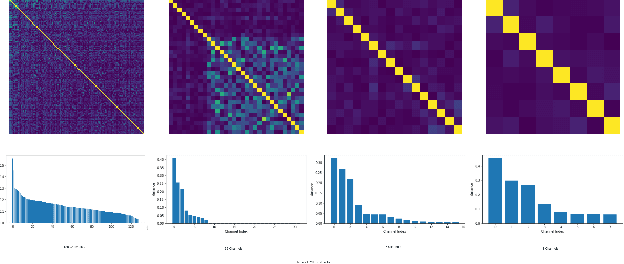
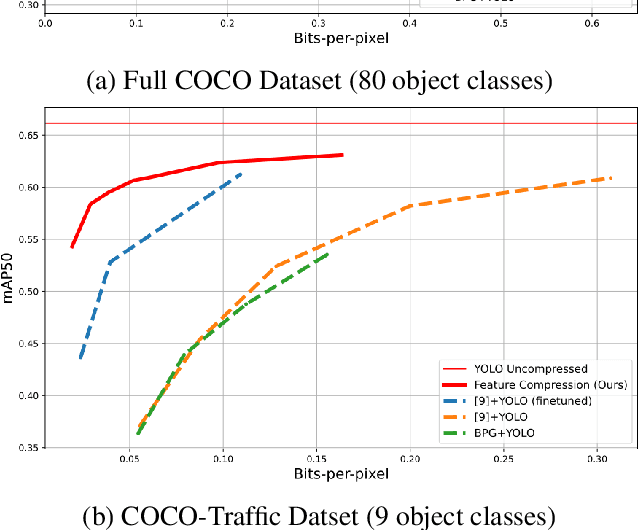
Recent advances in computer vision has led to a growth of interest in deploying visual analytics model on mobile devices. However, most mobile devices have limited computing power, which prohibits them from running large scale visual analytics neural networks. An emerging approach to solve this problem is to offload the computation of these neural networks to computing resources at an edge server. Efficient computation offloading requires optimizing the trade-off between multiple objectives including compressed data rate, analytics performance, and computation speed. In this work, we consider a "split computation" system to offload a part of the computation of the YOLO object detection model. We propose a learnable feature compression approach to compress the intermediate YOLO features with light-weight computation. We train the feature compression and decompression module together with the YOLO model to optimize the object detection accuracy under a rate constraint. Compared to baseline methods that apply either standard image compression or learned image compression at the mobile and perform image decompression and YOLO at the edge, the proposed system achieves higher detection accuracy at the low to medium rate range. Furthermore, the proposed system requires substantially lower computation time on the mobile device with CPU only.
TAnoGAN: Time Series Anomaly Detection with Generative Adversarial Networks
Sep 25, 2020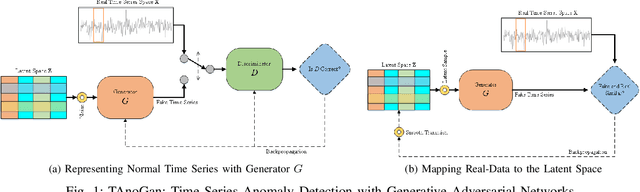
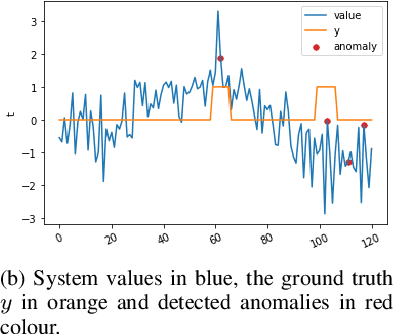
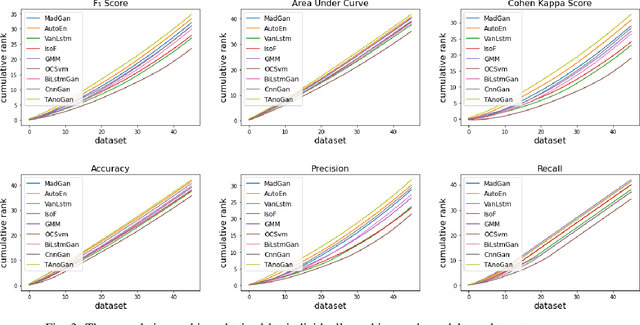
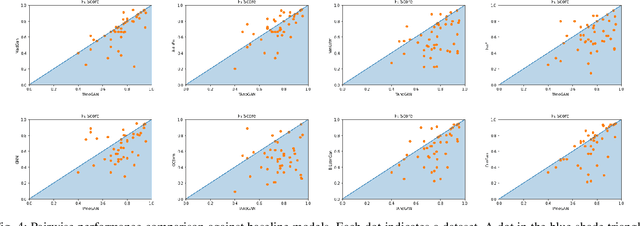
Anomaly detection in time series data is a significant problem faced in many application areas such as manufacturing, medical imaging and cyber-security. Recently, Generative Adversarial Networks (GAN) have gained attention for generation and anomaly detection in image domain. In this paper, we propose a novel GAN-based unsupervised method called TAnoGan for detecting anomalies in time series when a small number of data points are available. We evaluate TAnoGan with 46 real-world time series datasets that cover a variety of domains. Extensive experimental results show that TAnoGan performs better than traditional and neural network models.
Optimal Spend Rate Estimation and Pacing for Ad Campaigns with Budgets
Feb 04, 2022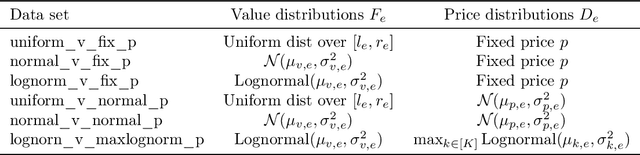
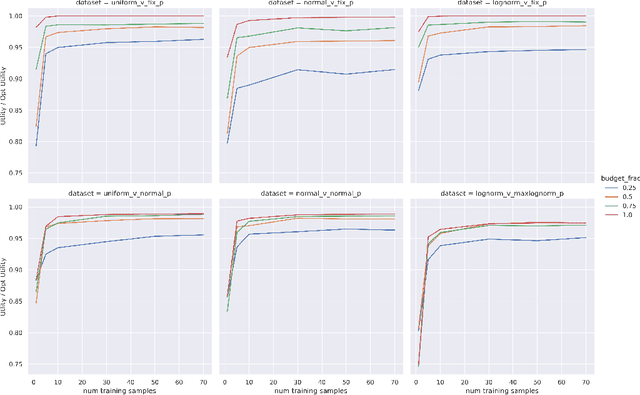
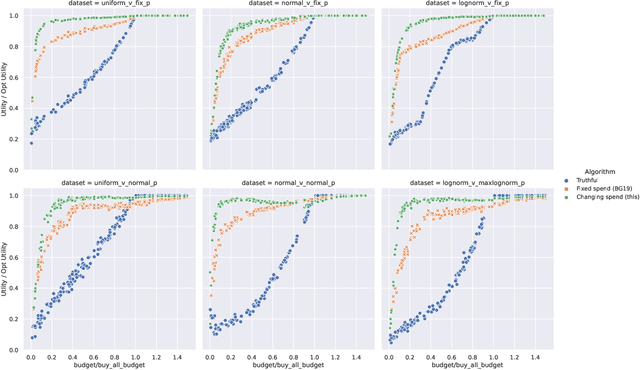
Online ad platforms offer budget management tools for advertisers that aim to maximize the number of conversions given a budget constraint. As the volume of impressions, conversion rates and prices vary over time, these budget management systems learn a spend plan (to find the optimal distribution of budget over time) and run a pacing algorithm which follows the spend plan. This paper considers two models for impressions and competition that varies with time: a) an episodic model which exhibits stationarity in each episode, but each episode can be arbitrarily different from the next, and b) a model where the distributions of prices and values change slowly over time. We present the first learning theoretic guarantees on both the accuracy of spend plans and the resulting end-to-end budget management system. We present four main results: 1) for the episodic setting we give sample complexity bounds for the spend rate prediction problem: given $n$ samples from each episode, with high probability we have $|\widehat{\rho}_e - \rho_e| \leq \tilde{O}(\frac{1}{n^{1/3}})$ where $\rho_e$ is the optimal spend rate for the episode, $\widehat{\rho}_e$ is the estimate from our algorithm, 2) we extend the algorithm of Balseiro and Gur (2017) to operate on varying, approximate spend rates and show that the resulting combined system of optimal spend rate estimation and online pacing algorithm for episodic settings has regret that vanishes in number of historic samples $n$ and the number of rounds $T$, 3) for non-episodic but slowly-changing distributions we show that the same approach approximates the optimal bidding strategy up to a factor dependent on the rate-of-change of the distributions and 4) we provide experiments showing that our algorithm outperforms both static spend plans and non-pacing across a wide variety of settings.
Pavlovian Signalling with General Value Functions in Agent-Agent Temporal Decision Making
Jan 11, 2022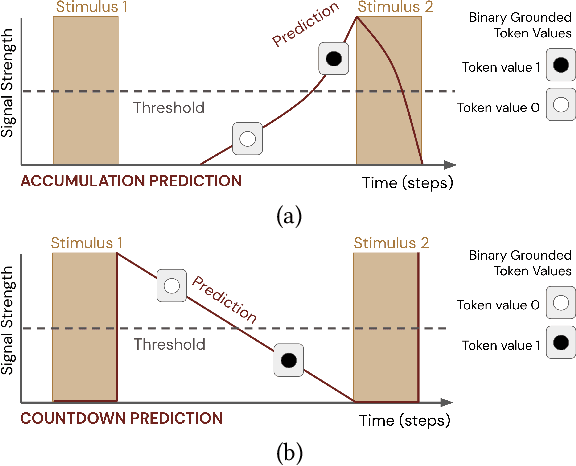
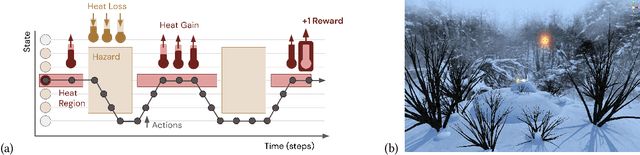
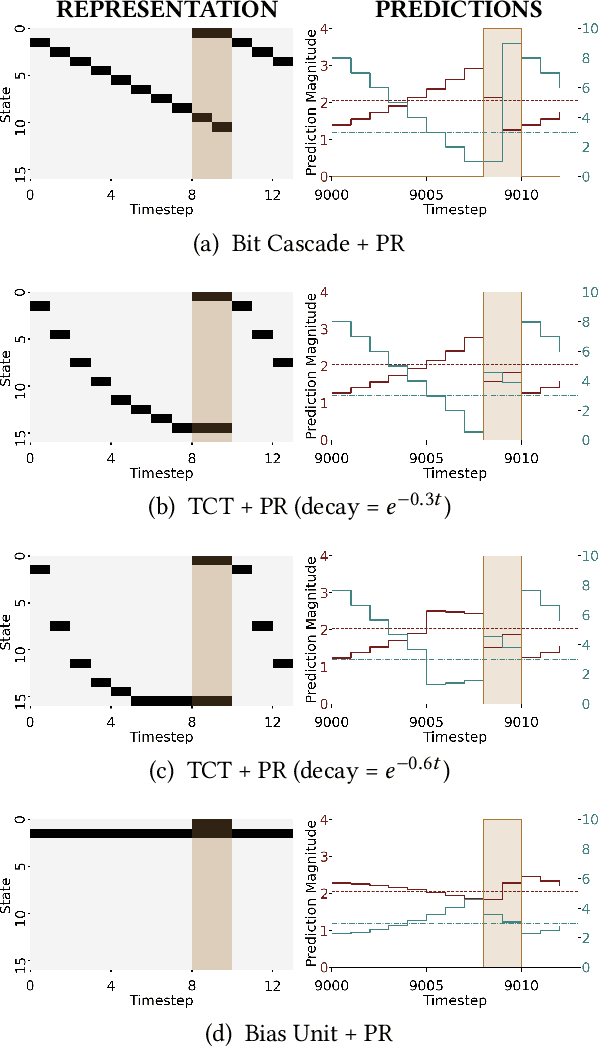
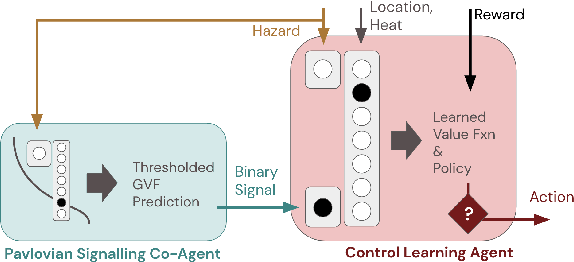
In this paper, we contribute a multi-faceted study into Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent. Signalling is intimately connected to time and timing. In service of generating and receiving signals, humans and other animals are known to represent time, determine time since past events, predict the time until a future stimulus, and both recognize and generate patterns that unfold in time. We investigate how different temporal processes impact coordination and signalling between learning agents by introducing a partially observable decision-making domain we call the Frost Hollow. In this domain, a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that works to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: machine agents interacting in a seven-state linear walk, and human-machine interaction in a virtual-reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning between two agents. We further show how to computationally build this adaptive signalling process out of a fixed signalling process, characterized by fast continual prediction learning and minimal constraints on the nature of the agent receiving signals. Our results therefore suggest an actionable, constructivist path towards communication learning between reinforcement learning agents.