 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time non-rigid 3D respiratory motion estimation for MR-guided radiotherapy using MR-MOTUS
Apr 16, 2021
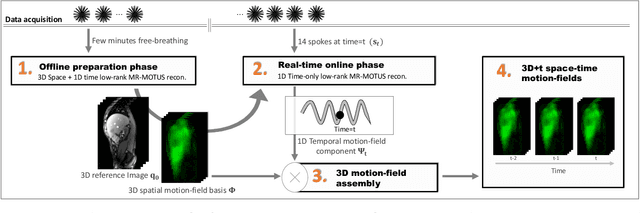
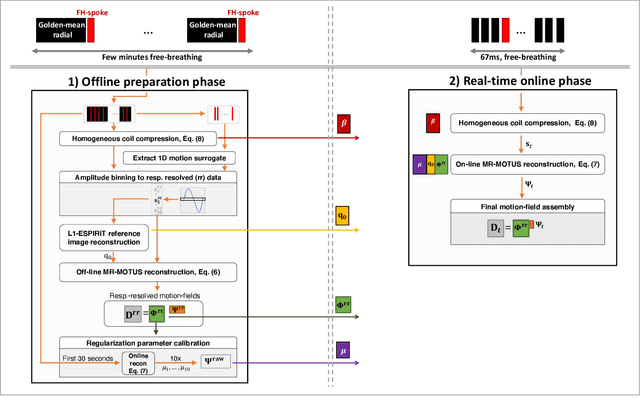
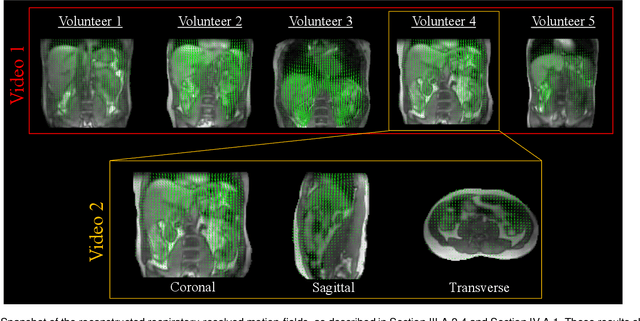
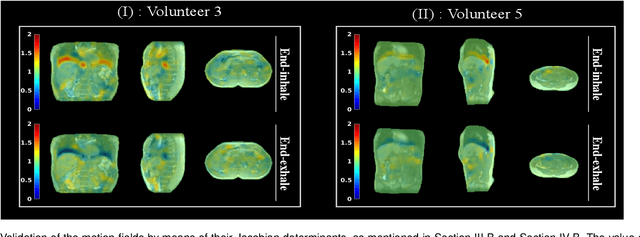
The MR-Linac is a combination of an MR-scanner and radiotherapy linear accelerator (Linac) which holds the promise to increase the precision of radiotherapy treatments with MR-guided radiotherapy by monitoring motion during radiotherapy with MRI, and adjusting the radiotherapy plan accordingly. Optimal MR-guidance for respiratory motion during radiotherapy requires MR-based 3D motion estimation with a latency of 200-500 ms. Currently this is still challenging since typical methods rely on MR-images, and are therefore limited to the 3D MR-imaging latency. In this work, we present a method to perform non-rigid 3D respiratory motion estimation with 170 ms latency, including both acquisition and reconstruction. The proposed method called real-time low-rank MR-MOTUS reconstructs motion-fields directly from k-space data, and leverages an explicit low-rank decomposition of motion-fields to split the large scale 3D+t motion-field reconstruction problem posed in our previous work into two parts: (I) a medium-scale offline preparation phase and (II) a small-scale online inference phase which exploits the results of the offline phase for real-time computations. The method was validated on free-breathing data of five volunteers, acquired with a 1.5T Elekta Unity MR-Linac. Results show that the reconstructed 3D motion-fields are anatomically plausible, highly correlated with a self-navigation motion surrogate (R = 0.975 +/- 0.0110), and can be reconstructed with a total latency of 170 ms that is sufficient for real-time MR-guided abdominal radiotherapy.
List-Mode PET Image Reconstruction Using Deep Image Prior
Apr 28, 2022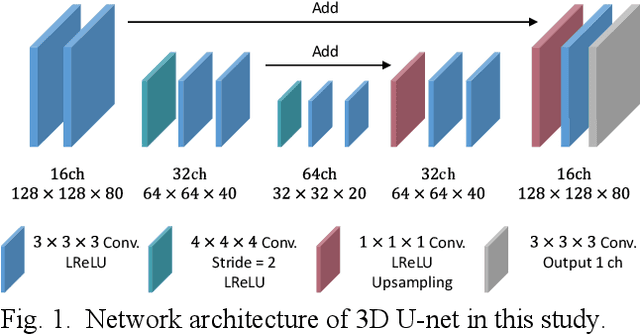
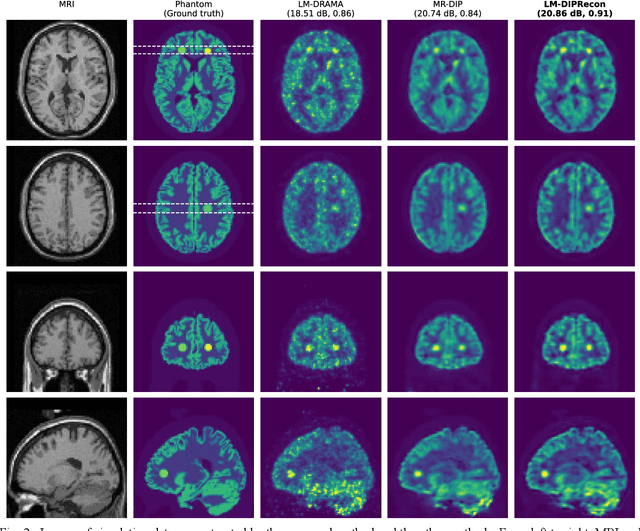
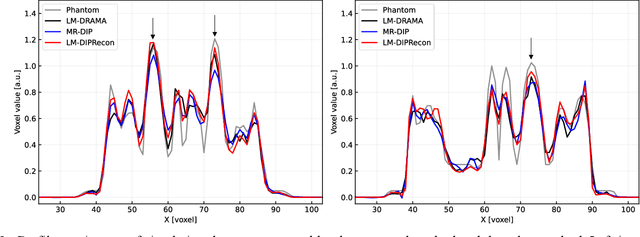
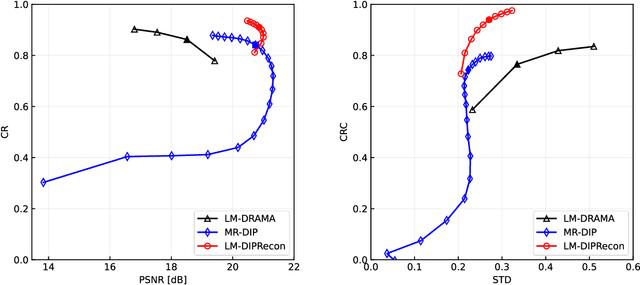
List-mode positron emission tomography (PET) image reconstruction is an important tool for PET scanners with many lines-of-response (LORs) and additional information such as time-of-flight and depth-of-interaction. Deep learning is one possible solution to enhance the quality of PET image reconstruction. However, the application of deep learning techniques to list-mode PET image reconstruction have not been progressed because list data is a sequence of bit codes and unsuitable for processing by convolutional neural networks (CNN). In this study, we propose a novel list-mode PET image reconstruction method using an unsupervised CNN called deep image prior (DIP) and a framework of alternating direction method of multipliers. The proposed list-mode DIP reconstruction (LM-DIPRecon) method alternatively iterates regularized list-mode dynamic row action maximum likelihood algorithm (LM-DRAMA) and magnetic resonance imaging conditioned DIP (MR-DIP). We evaluated LM-DIPRecon using both simulation and clinical data, and it achieved sharper images and better tradeoff curves between contrast and noise than the LM-DRAMA and MR-DIP. These results indicated that the LM-DIPRecon is useful for quantitative PET imaging with limited events. In addition, as list data has finer temporal information than dynamic sinograms, list-mode deep image prior reconstruction is expected to be useful for 4D PET imaging and motion correction.
Pixel2Mesh++: 3D Mesh Generation and Refinement from Multi-View Images
Apr 21, 2022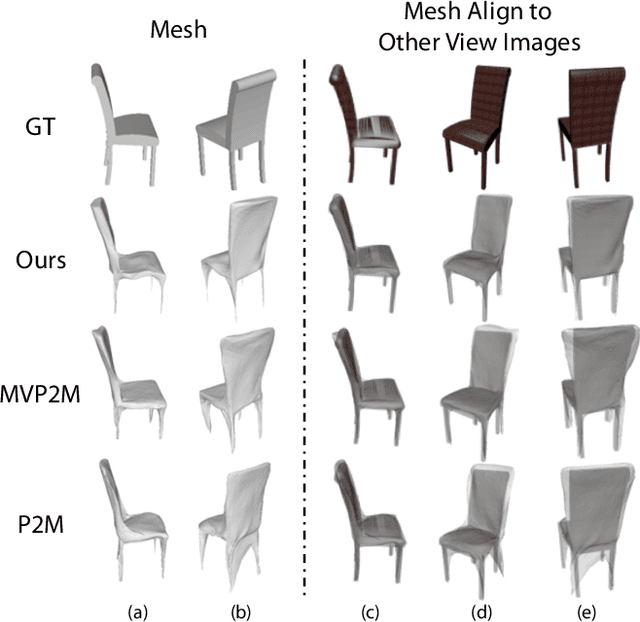
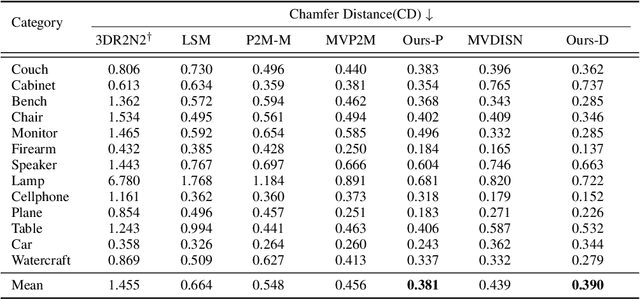
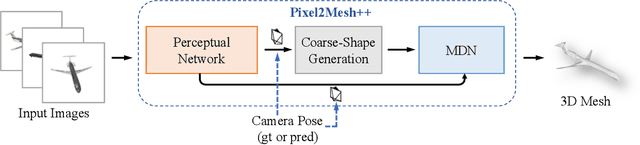
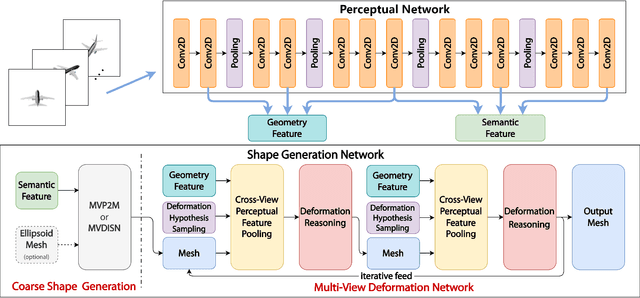
We study the problem of shape generation in 3D mesh representation from a small number of color images with or without camera poses. While many previous works learn to hallucinate the shape directly from priors, we adopt to further improve the shape quality by leveraging cross-view information with a graph convolution network. Instead of building a direct mapping function from images to 3D shape, our model learns to predict series of deformations to improve a coarse shape iteratively. Inspired by traditional multiple view geometry methods, our network samples nearby area around the initial mesh's vertex locations and reasons an optimal deformation using perceptual feature statistics built from multiple input images. Extensive experiments show that our model produces accurate 3D shapes that are not only visually plausible from the input perspectives, but also well aligned to arbitrary viewpoints. With the help of physically driven architecture, our model also exhibits generalization capability across different semantic categories, and the number of input images. Model analysis experiments show that our model is robust to the quality of the initial mesh and the error of camera pose, and can be combined with a differentiable renderer for test-time optimization.
Efficient Multiscale Object-based Superpixel Framework
Apr 07, 2022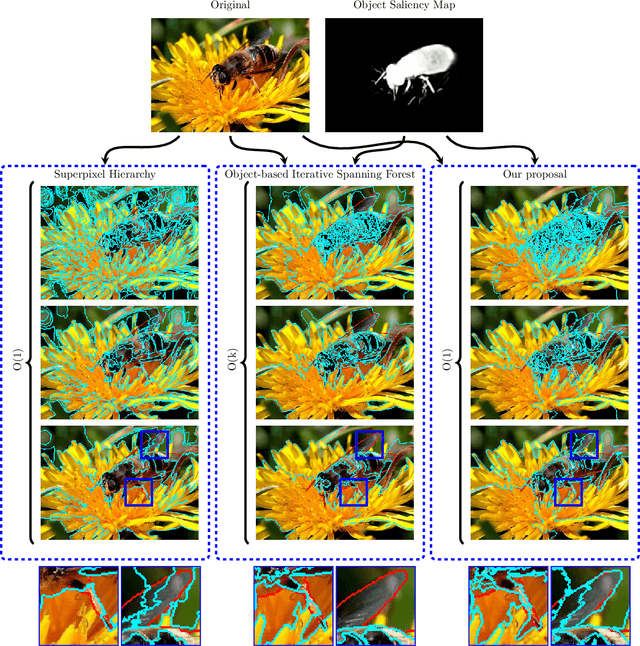
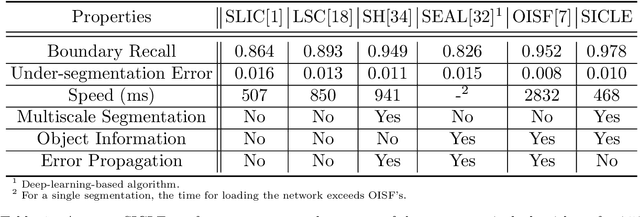
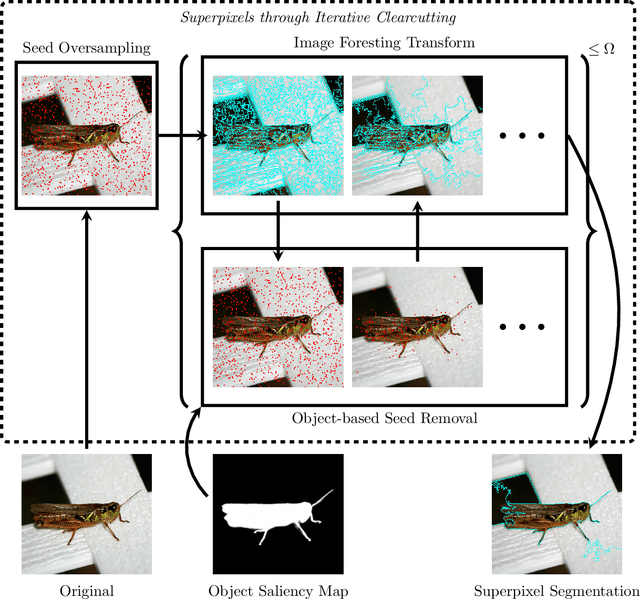

Superpixel segmentation can be used as an intermediary step in many applications, often to improve object delineation and reduce computer workload. However, classical methods do not incorporate information about the desired object. Deep-learning-based approaches consider object information, but their delineation performance depends on data annotation. Additionally, the computational time of object-based methods is usually much higher than desired. In this work, we propose a novel superpixel framework, named Superpixels through Iterative CLEarcutting (SICLE), which exploits object information being able to generate a multiscale segmentation on-the-fly. SICLE starts off from seed oversampling and repeats optimal connectivity-based superpixel delineation and object-based seed removal until a desired number of superpixels is reached. It generalizes recent superpixel methods, surpassing them and other state-of-the-art approaches in efficiency and effectiveness according to multiple delineation metrics.
Continuous-Curvature Target Tree Algorithm for Path Planning in Complex Parking Environments
Jan 19, 2022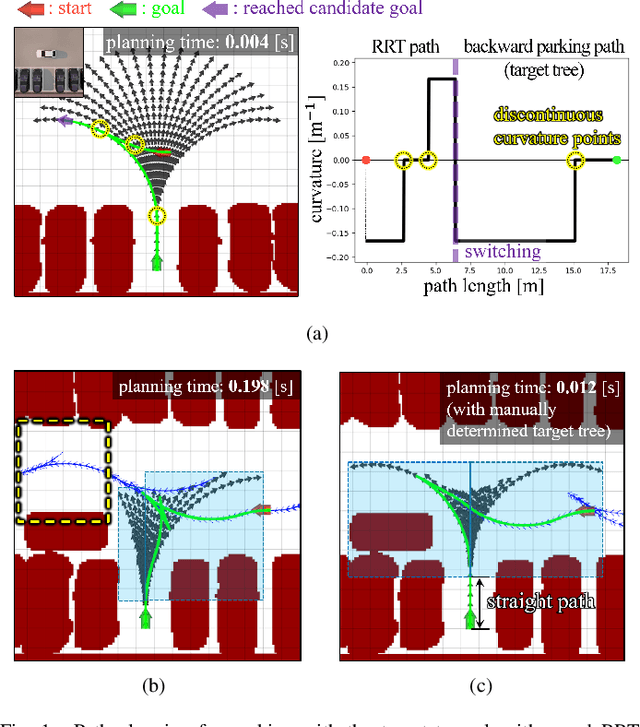
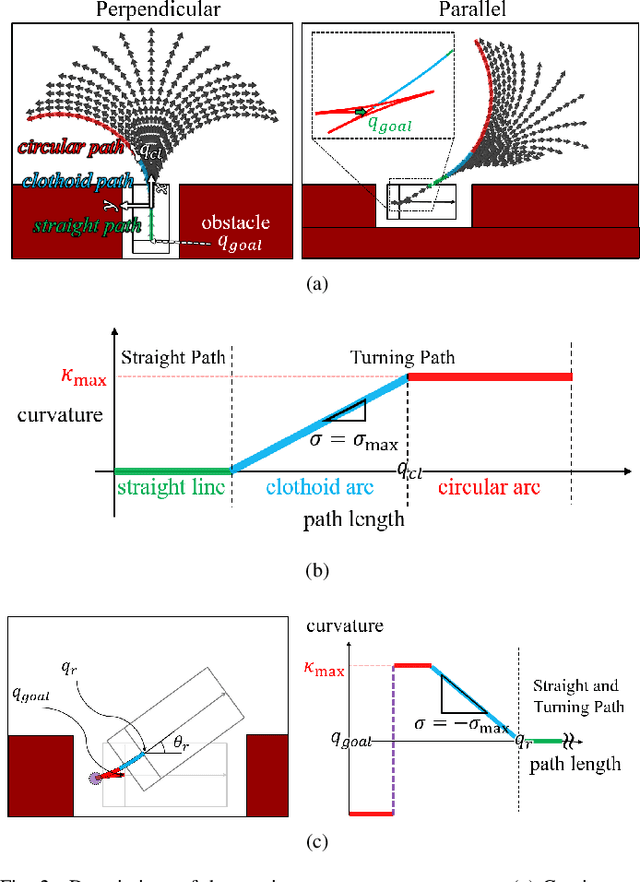
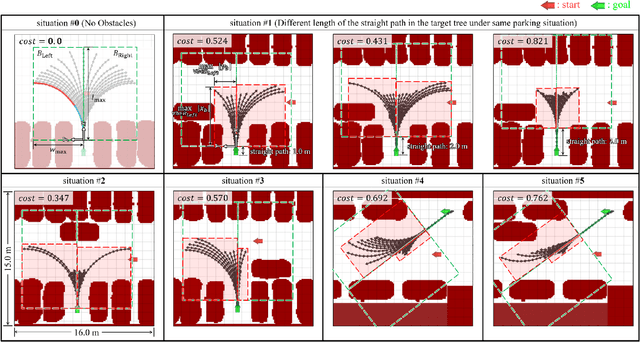
Rapidly-exploring random tree (RRT) has been applied for autonomous parking due to quickly solving high-dimensional motion planning and easily reflecting constraints. However, planning time increases by the low probability of extending toward narrow parking spots without collisions. To reduce the planning time, the target tree algorithm was proposed, substituting a parking goal in RRT with a set (target tree) of backward parking paths. However, it consists of circular and straight paths, and an autonomous vehicle cannot park accurately because of curvature-discontinuity. Moreover, the planning time increases in complex environments; backward paths can be blocked by obstacles. Therefore, this paper introduces the continuous-curvature target tree algorithm for complex parking environments. First, a target tree includes clothoid paths to address such curvature-discontinuity. Second, to reduce the planning time further, a cost function is defined to construct a target tree that considers obstacles. Integrated with optimal-variant RRT and searching for the shortest path among the reached backward paths, the proposed algorithm obtains a near-optimal path as the sampling time increases. Experiment results in real environments show that the vehicle more accurately parks, and continuous-curvature paths are obtained more quickly and with higher success rates than those acquired with other sampling-based algorithms.
TeRo: A Time-aware Knowledge Graph Embedding via Temporal Rotation
Oct 24, 2020

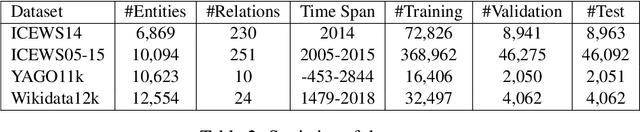
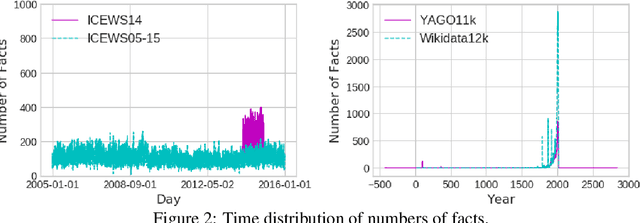
In the last few years, there has been a surge of interest in learning representations of entitiesand relations in knowledge graph (KG). However, the recent availability of temporal knowledgegraphs (TKGs) that contain time information for each fact created the need for reasoning overtime in such TKGs. In this regard, we present a new approach of TKG embedding, TeRo, which defines the temporal evolution of entity embedding as a rotation from the initial time to the currenttime in the complex vector space. Specially, for facts involving time intervals, each relation isrepresented as a pair of dual complex embeddings to handle the beginning and the end of therelation, respectively. We show our proposed model overcomes the limitations of the existing KG embedding models and TKG embedding models and has the ability of learning and inferringvarious relation patterns over time. Experimental results on four different TKGs show that TeRo significantly outperforms existing state-of-the-art models for link prediction. In addition, we analyze the effect of time granularity on link prediction over TKGs, which as far as we know hasnot been investigated in previous literature.
Time Series Data Augmentation for Neural Networks by Time Warping with a Discriminative Teacher
Apr 19, 2020

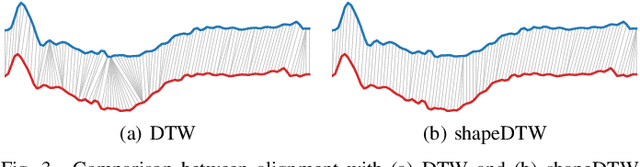
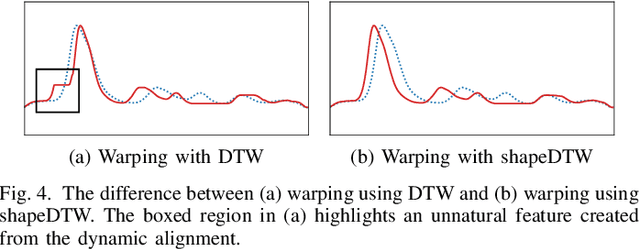
Neural networks have become a powerful tool in pattern recognition and part of their success is due to generalization from using large datasets. However, unlike other domains, time series classification datasets are often small. In order to address this problem, we propose a novel time series data augmentation called guided warping. While many data augmentation methods are based on random transformations, guided warping exploits the element alignment properties of Dynamic Time Warping (DTW) and shapeDTW, a high-level DTW method based on shape descriptors, to deterministically warp sample patterns. In this way, the time series are mixed by warping the features of a sample pattern to match the time steps of a reference pattern. Furthermore, we introduce a discriminative teacher in order to serve as a directed reference for the guided warping. We evaluate the method on all 85 datasets in the 2015 UCR Time Series Archive with a deep convolutional neural network (CNN) and a recurrent neural network (RNN). The code with an easy to use implementation can be found at https://github.com/uchidalab/time_series_augmentation .
Small Batch Sizes Improve Training of Low-Resource Neural MT
Mar 20, 2022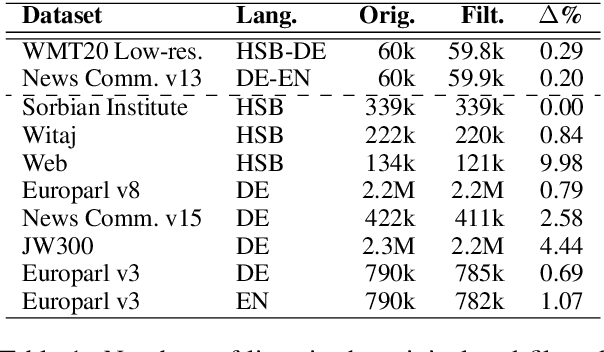
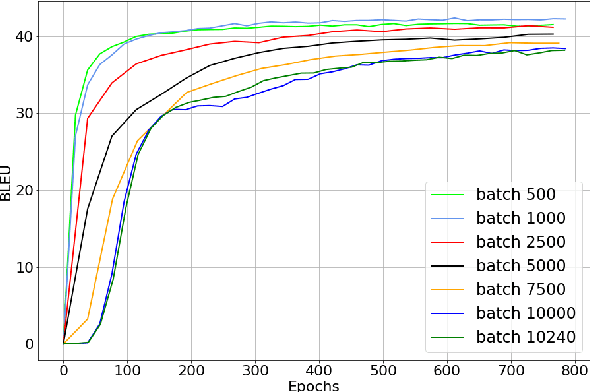
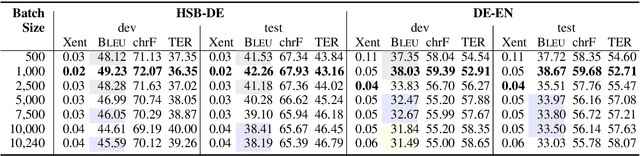

We study the role of an essential hyper-parameter that governs the training of Transformers for neural machine translation in a low-resource setting: the batch size. Using theoretical insights and experimental evidence, we argue against the widespread belief that batch size should be set as large as allowed by the memory of the GPUs. We show that in a low-resource setting, a smaller batch size leads to higher scores in a shorter training time, and argue that this is due to better regularization of the gradients during training.
Change-point Detection and Segmentation of Discrete Data using Bayesian Context Trees
Mar 08, 2022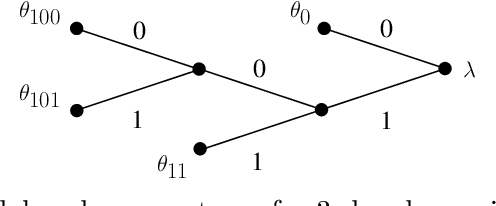
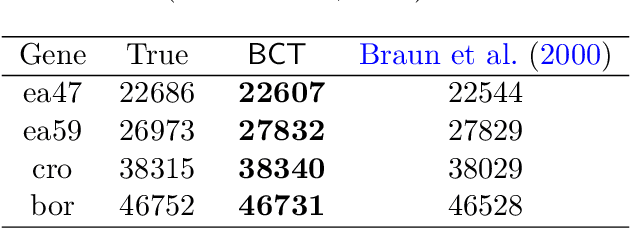
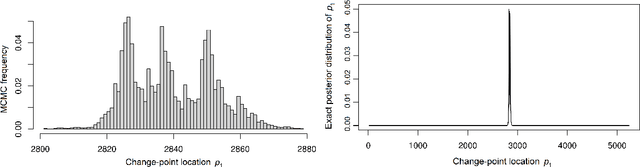
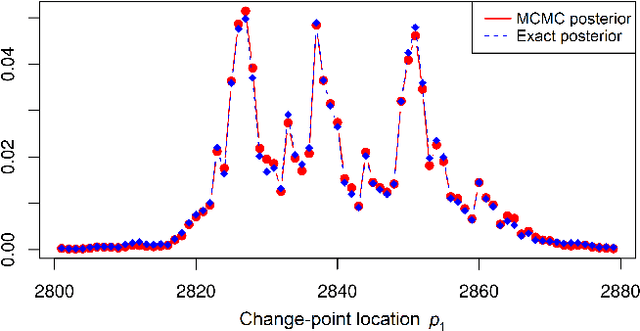
A new Bayesian modelling framework is introduced for piece-wise homogeneous variable-memory Markov chains, along with a collection of effective algorithmic tools for change-point detection and segmentation of discrete time series. Building on the recently introduced Bayesian Context Trees (BCT) framework, the distributions of different segments in a discrete time series are described as variable-memory Markov chains. Inference for the presence and location of change-points is then performed via Markov chain Monte Carlo sampling. The key observation that facilitates effective sampling is that, using one of the BCT algorithms, the prior predictive likelihood of the data can be computed exactly, integrating out all the models and parameters in each segment. This makes it possible to sample directly from the posterior distribution of the number and location of the change-points, leading to accurate estimates and providing a natural quantitative measure of uncertainty in the results. Estimates of the actual model in each segment can also be obtained, at essentially no additional computational cost. Results on both simulated and real-world data indicate that the proposed methodology performs better than or as well as state-of-the-art techniques.
Detecting GAN-generated Images by Orthogonal Training of Multiple CNNs
Mar 04, 2022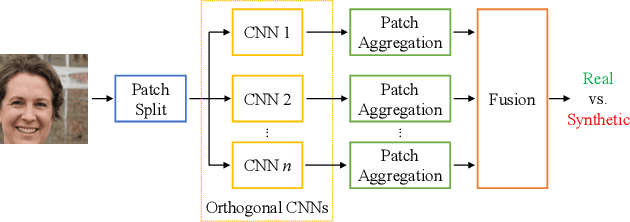
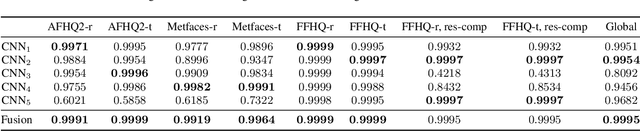
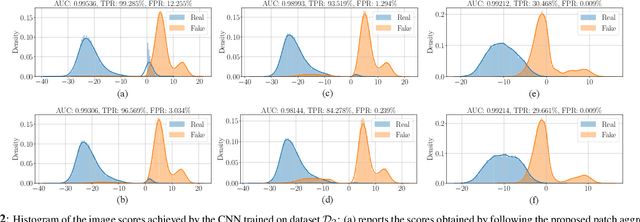
In the last few years, we have witnessed the rise of a series of deep learning methods to generate synthetic images that look extremely realistic. These techniques prove useful in the movie industry and for artistic purposes. However, they also prove dangerous if used to spread fake news or to generate fake online accounts. For this reason, detecting if an image is an actual photograph or has been synthetically generated is becoming an urgent necessity. This paper proposes a detector of synthetic images based on an ensemble of Convolutional Neural Networks (CNNs). We consider the problem of detecting images generated with techniques not available at training time. This is a common scenario, given that new image generators are published more and more frequently. To solve this issue, we leverage two main ideas: (i) CNNs should provide orthogonal results to better contribute to the ensemble; (ii) original images are better defined than synthetic ones, thus they should be better trusted at testing time. Experiments show that pursuing these two ideas improves the detector accuracy on NVIDIA's newly generated StyleGAN3 images, never used in training.