 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A New Lagrangian Problem Crossover: A Systematic Review and Meta-Analysis of Crossover Standards
Apr 27, 2022
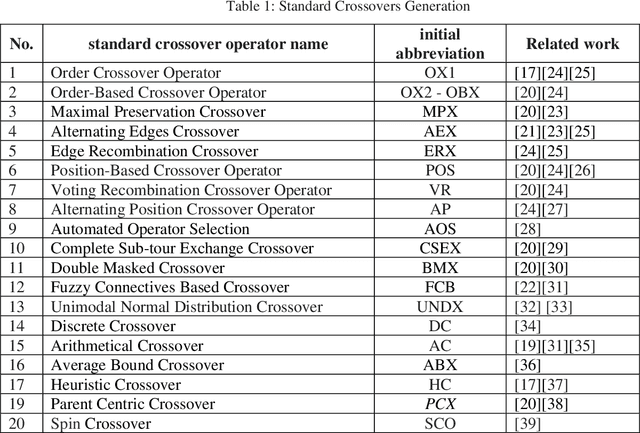
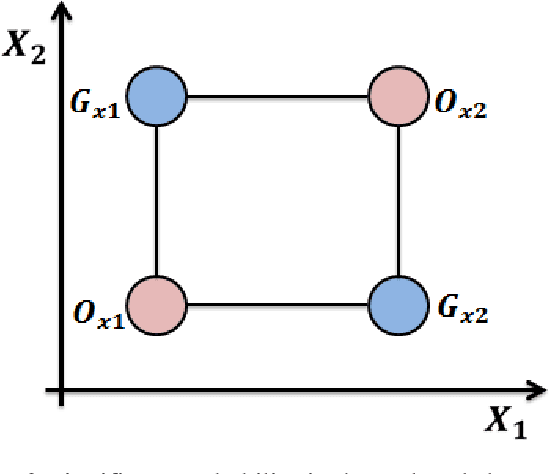

The performance of most evolutionary metaheuristic algorithms depends on various operators. The crossover operator is one of them and is mainly classified into two standards; application-dependent crossover operators and application-independent crossover operators. These standards always help to choose the best-fitted point in the evolutionary algorithm process. The high efficiency of crossover operators enables minimizing the error that occurred in engineering application optimization within a short time and cost. There are two crucial objectives behind this paper; at first, it is an overview of crossover standards classification that has been used by researchers for solving engineering operations and problem representation. The second objective of this paper; The significance of novel standard crossover is proposed depending on Lagrangian Dual Function (LDF) to progress the formulation of the Lagrangian Problem Crossover (LPX) as a new systematic standard operator. The results of the proposed crossover standards for 100 generations of parent chromosomes are compared to the BX and SBX standards, which are the communal real-coded crossover standards. The accuracy and performance of the proposed standard have evaluated by three unimodal test functions. Besides, the proposed standard results are statistically demonstrated and proved that it has an excessive ability to generate and enhance the novel optimization algorithm compared to BX and SBX.
Real-time Outdoor Localization Using Radio Maps: A Deep Learning Approach
Jun 23, 2021
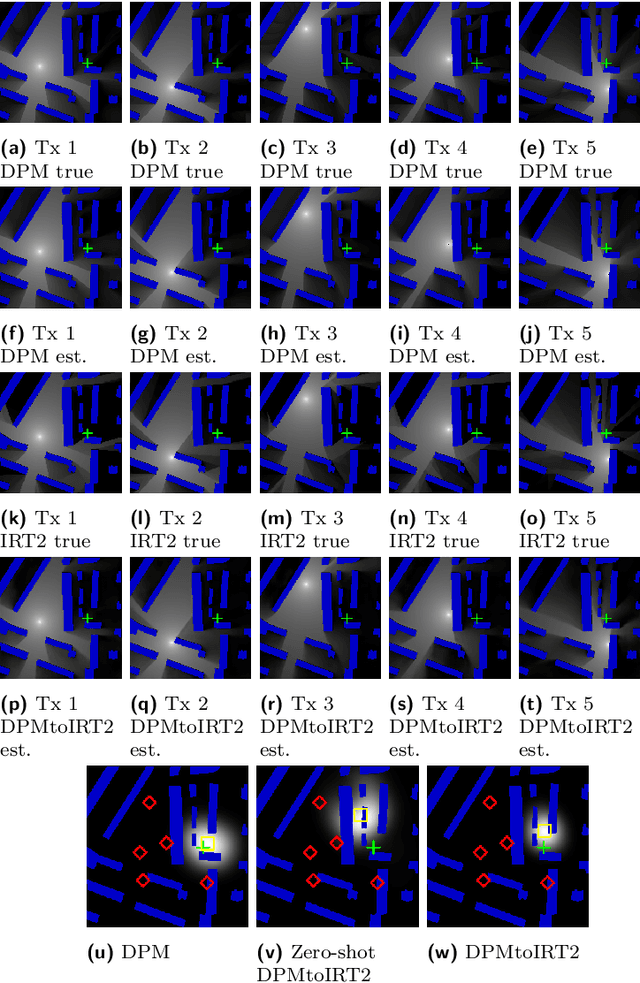
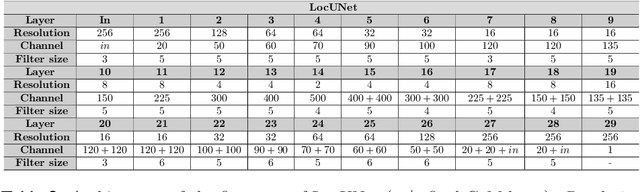
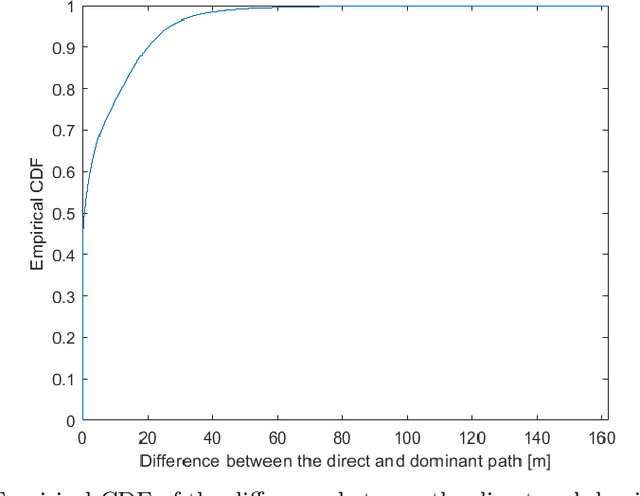
This paper deals with the problem of localization in a cellular network in a dense urban scenario. Global Navigation Satellite Systems typically perform poorly in urban environments, where the likelihood of line-of-sight conditions between the devices and the satellites is low, and thus alternative localization methods are required for good accuracy. We present a deep learning method for localization, based merely on pathloss, which does not require any increase in computation complexity at the user devices with respect to the device standard operations, unlike methods that rely on time of arrival or angle of arrival information. In a wireless network, user devices scan the base station beacon slots and identify the few strongest base station signals for handover and user-base station association purposes. In the proposed method, the user to be localized simply reports such received signal strengths to a central processing unit, which may be located in the cloud. For each base station we have good approximation of the pathloss at every location in a dense grid in the map. This approximation is provided by RadioUNet, a deep learning-based simulator of pathloss functions in urban environment, that we have previously proposed and published. Using the estimated pathloss radio maps of all base stations and the corresponding reported signal strengths, the proposed deep learning algorithm can extract a very accurate localization of the user. The proposed method, called LocUNet, enjoys high robustness to inaccuracies in the estimated radio maps. We demonstrate this by numerical experiments, which obtain state-of-the-art results.
A Unified Analysis of Dynamic Interactive Learning
Apr 14, 2022In this paper we investigate the problem of learning evolving concepts over a combinatorial structure. Previous work by Emamjomeh-Zadeh et al. [2020] introduced dynamics into interactive learning as a way to model non-static user preferences in clustering problems or recommender systems. We provide many useful contributions to this problem. First, we give a framework that captures both of the models analyzed by [Emamjomeh-Zadeh et al., 2020], which allows us to study any type of concept evolution and matches the same query complexity bounds and running time guarantees of the previous models. Using this general model we solve the open problem of closing the gap between the upper and lower bounds on query complexity. Finally, we study an efficient algorithm where the learner simply follows the feedback at each round, and we provide mistake bounds for low diameter graphs such as cliques, stars, and general o(log n) diameter graphs by using a Markov Chain model.
Partial Relaxed Optimal Transport for Denoised Recommendation
Apr 19, 2022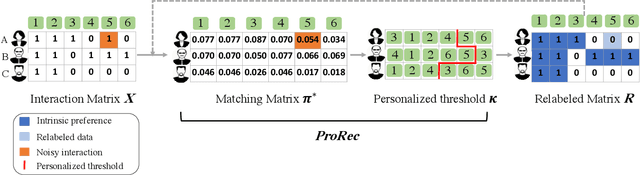
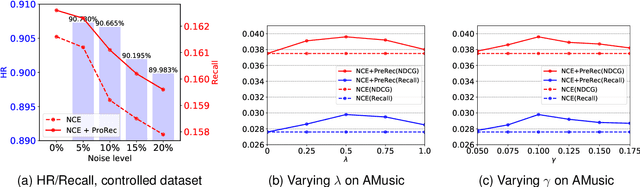
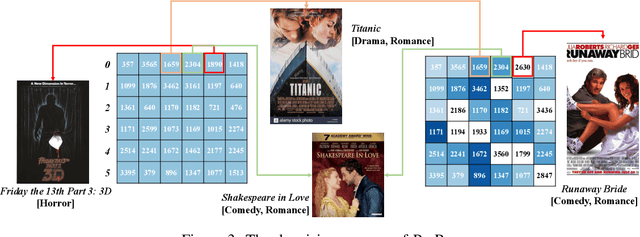
The interaction data used by recommender systems (RSs) inevitably include noises resulting from mistaken or exploratory clicks, especially under implicit feedbacks. Without proper denoising, RS models cannot effectively capture users' intrinsic preferences and the true interactions between users and items. To address such noises, existing methods mostly rely on auxiliary data which are not always available. In this work, we ground on Optimal Transport (OT) to globally match a user embedding space and an item embedding space, allowing both non-deep and deep RS models to discriminate intrinsic and noisy interactions without supervision. Specifically, we firstly leverage the OT framework via Sinkhorn distance to compute the continuous many-to-many user-item matching scores. Then, we relax the regularization in Sinkhorn distance to achieve a closed-form solution with a reduced time complexity. Finally, to consider individual user behaviors for denoising, we develop a partial OT framework to adaptively relabel user-item interactions through a personalized thresholding mechanism. Extensive experiments show that our framework can significantly boost the performances of existing RS models.
QDrop: Randomly Dropping Quantization for Extremely Low-bit Post-Training Quantization
Mar 11, 2022
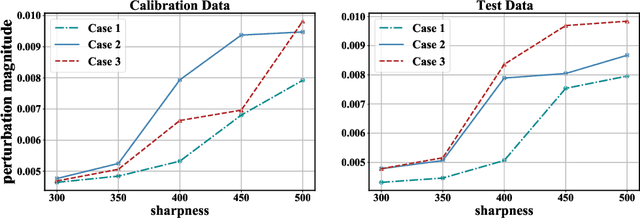

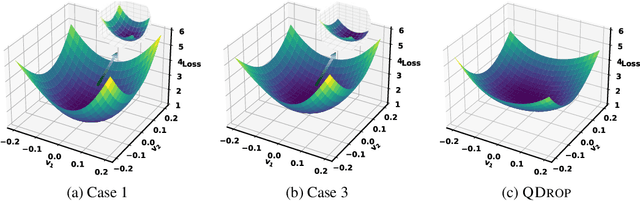
Recently, post-training quantization (PTQ) has driven much attention to produce efficient neural networks without long-time retraining. Despite its low cost, current PTQ works tend to fail under the extremely low-bit setting. In this study, we pioneeringly confirm that properly incorporating activation quantization into the PTQ reconstruction benefits the final accuracy. To deeply understand the inherent reason, a theoretical framework is established, indicating that the flatness of the optimized low-bit model on calibration and test data is crucial. Based on the conclusion, a simple yet effective approach dubbed as QDROP is proposed, which randomly drops the quantization of activations during PTQ. Extensive experiments on various tasks including computer vision (image classification, object detection) and natural language processing (text classification and question answering) prove its superiority. With QDROP, the limit of PTQ is pushed to the 2-bit activation for the first time and the accuracy boost can be up to 51.49%. Without bells and whistles, QDROP establishes a new state of the art for PTQ. Our code is available at https://github.com/wimh966/QDrop and has been integrated into MQBench (https://github.com/ModelTC/MQBench)
Fluid registration between lung CT and stationary chest tomosynthesis images
Mar 06, 2022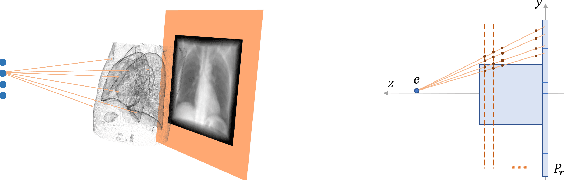

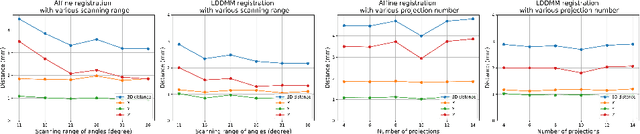
Registration is widely used in image-guided therapy and image-guided surgery to estimate spatial correspondences between organs of interest between planning and treatment images. However, while high-quality computed tomography (CT) images are often available at planning time, limited angle acquisitions are frequently used during treatment because of radiation concerns or imaging time constraints. This requires algorithms to register CT images based on limited angle acquisitions. We, therefore, formulate a 3D/2D registration approach which infers a 3D deformation based on measured projections and digitally reconstructed radiographs of the CT. Most 3D/2D registration approaches use simple transformation models or require complex mathematical derivations to formulate the underlying optimization problem. Instead, our approach entirely relies on differentiable operations which can be combined with modern computational toolboxes supporting automatic differentiation. This then allows for rapid prototyping, integration with deep neural networks, and to support a variety of transformation models including fluid flow models. We demonstrate our approach for the registration between CT and stationary chest tomosynthesis (sDCT) images and show how it naturally leads to an iterative image reconstruction approach.
Training Speaker Embedding Extractors Using Multi-Speaker Audio with Unknown Speaker Boundaries
Mar 29, 2022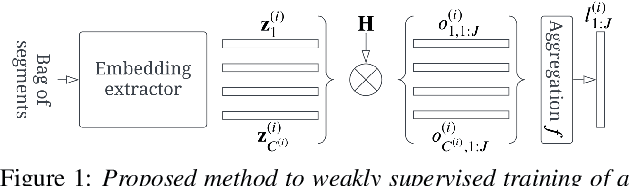
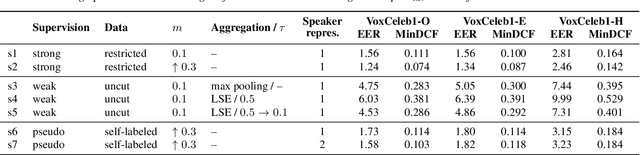
In this paper, we demonstrate a method for training speaker embedding extractors using weak annotation. More specifically, we are using the full VoxCeleb recordings and the name of the celebrities appearing on each video without knowledge of the time intervals the celebrities appear in the video. We show that by combining a baseline speaker diarization algorithm that requires no training or parameter tuning, a modified loss with aggregation over segments, and a two-stage training approach, we are able to train a competitive ResNet-based embedding extractor. Finally, we experiment with two different aggregation functions and analyze their behaviour in terms of their gradients.
SPARCS: A Sparse Recovery Approach for Integrated Communication and Human Sensing in mmWave Systems
May 06, 2022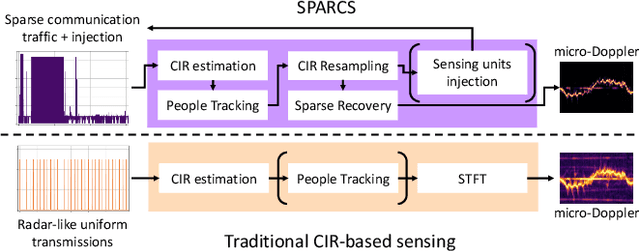


A well established method to detect and classify human movements using Millimeter-Wave ( mmWave) devices is the time-frequency analysis of the small-scale Doppler effect (termed micro-Doppler) of the different body parts, which requires a regularly spaced and dense sampling of the Channel Impulse Response ( CIR). This is currently done in the literature either using special-purpose radar sensors, or interrupting communications to transmit dedicated sensing waveforms, entailing high overhead and channel utilization. In this work we present SPARCS, an integrated human sensing and communication solution for mmWave systems. SPARCS is the first method that reconstructs high quality signatures of human movement from irregular and sparse CIR samples, such as the ones obtained during communication traffic patterns. To accomplish this, we formulate the micro-Doppler extraction as a sparse recovery problem, which is critical to enable a smooth integration between communication and sensing. Moreover, if needed, our system can seamlessly inject short CIR estimation fields into the channel whenever communication traffic is absent or insufficient for the micro-Doppler extraction. SPARCS effectively leverages the intrinsic sparsity of the mmWave channel, thus drastically reducing the sensing overhead with respect to available approaches. We implemented SPARCS on an IEEE 802.11ay Software Defined Radio (SDR) platform working in the 60 GHz band, collecting standard-compliant CIR traces matching the traffic patterns of real WiFi access points. Our results show that the micro-Doppler signatures obtained by SPARCS enable a typical downstream application such as human activity recognition with more than 7 times lower overhead with respect to existing methods, while achieving better recognition performance.
ES-dRNN with Dynamic Attention for Short-Term Load Forecasting
Mar 02, 2022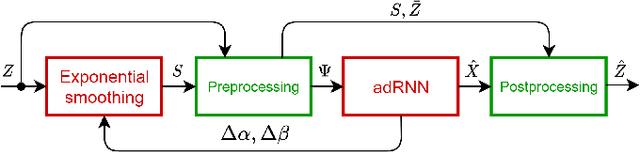
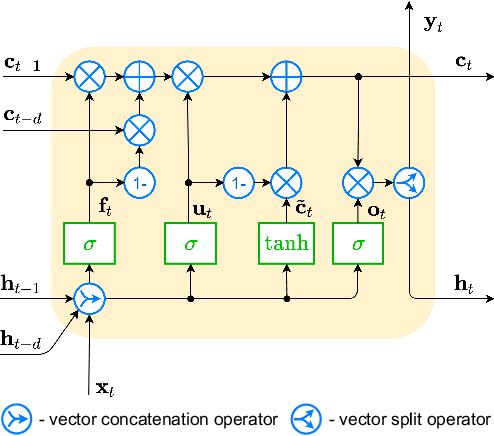
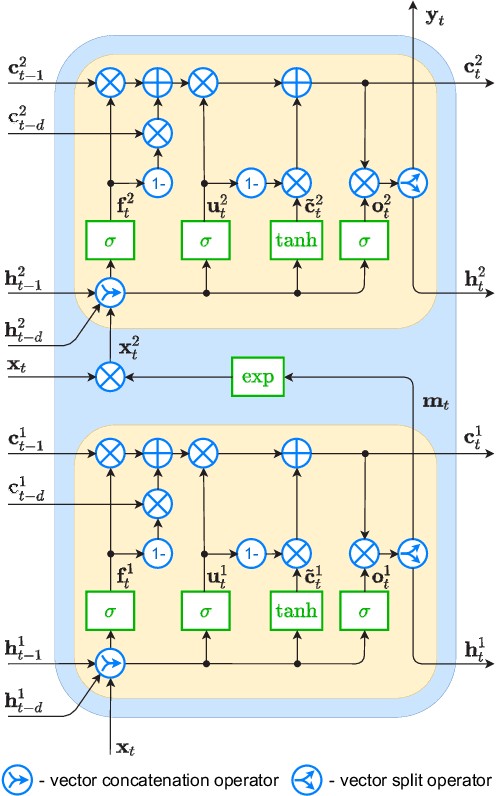
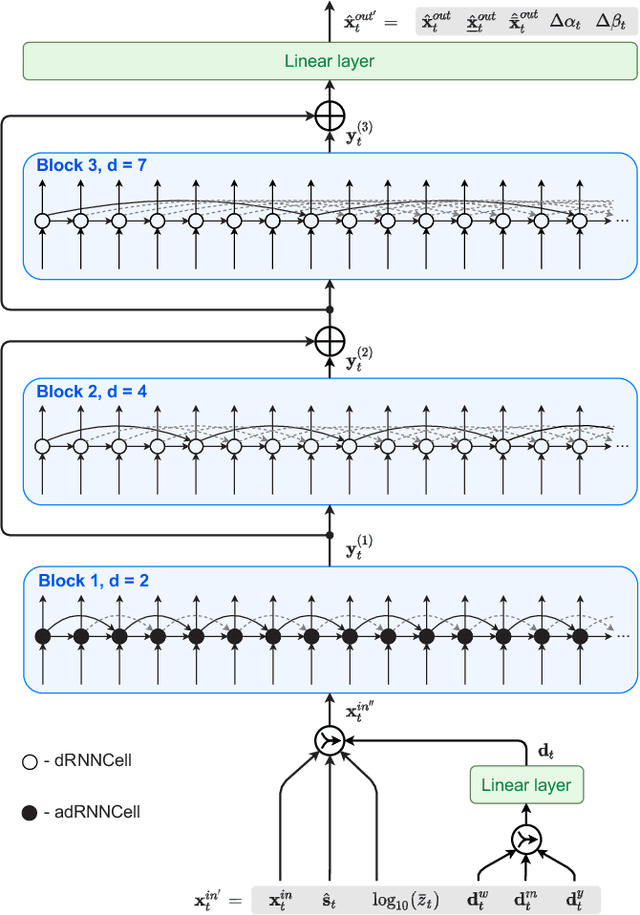
Short-term load forecasting (STLF) is a challenging problem due to the complex nature of the time series expressing multiple seasonality and varying variance. This paper proposes an extension of a hybrid forecasting model combining exponential smoothing and dilated recurrent neural network (ES-dRNN) with a mechanism for dynamic attention. We propose a new gated recurrent cell -- attentive dilated recurrent cell, which implements an attention mechanism for dynamic weighting of input vector components. The most relevant components are assigned greater weights, which are subsequently dynamically fine-tuned. This attention mechanism helps the model to select input information and, along with other mechanisms implemented in ES-dRNN, such as adaptive time series processing, cross-learning, and multiple dilation, leads to a significant improvement in accuracy when compared to well-established statistical and state-of-the-art machine learning forecasting models. This was confirmed in the extensive experimental study concerning STLF for 35 European countries.
Neural Time Warping For Multiple Sequence Alignment
Jun 29, 2020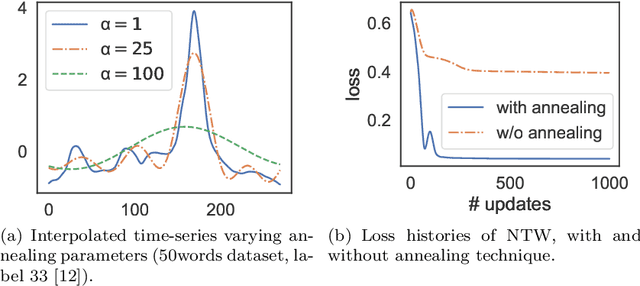
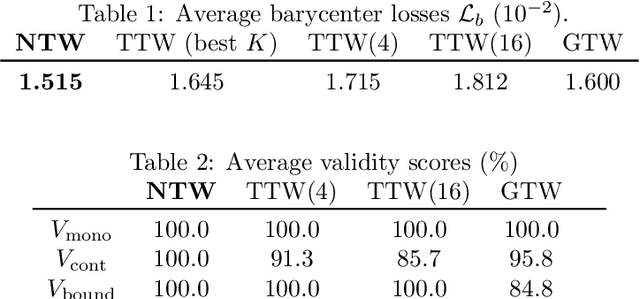
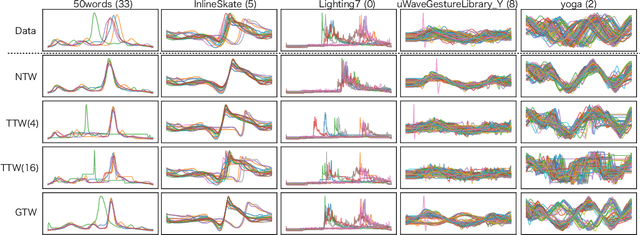
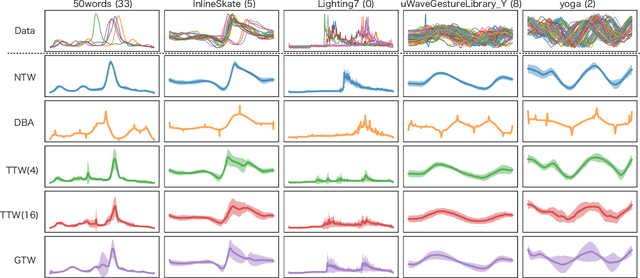
Multiple sequences alignment (MSA) is a traditional and challenging task for time-series analyses. The MSA problem is formulated as a discrete optimization problem and is typically solved by dynamic programming. However, the computational complexity increases exponentially with respect to the number of input sequences. In this paper, we propose neural time warping (NTW) that relaxes the original MSA to a continuous optimization and obtains the alignments using a neural network. The solution obtained by NTW is guaranteed to be a feasible solution for the original discrete optimization problem under mild conditions. Our experimental results show that NTW successfully aligns a hundred time-series and significantly outperforms existing methods for solving the MSA problem. In addition, we show a method for obtaining average time-series data as one of applications of NTW. Compared to the existing barycenters, the mean time series data retains the features of the input time-series data.