 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Extracting Impact Model Narratives from Social Services' Text
Apr 04, 2022
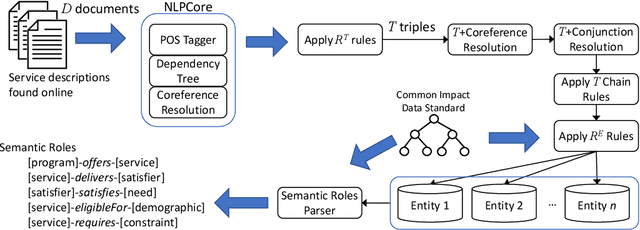


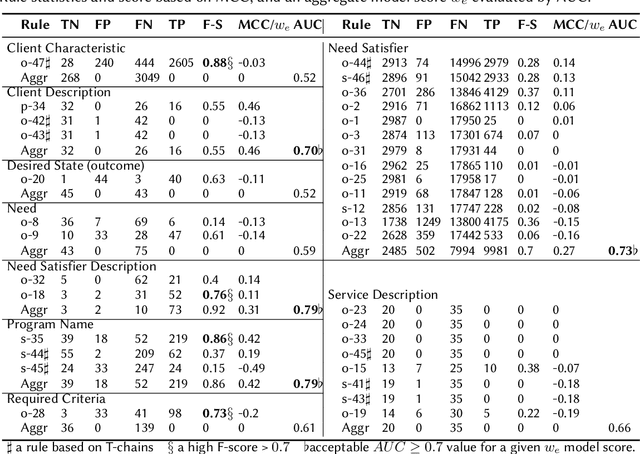
Named entity recognition (NER) is an important task in narration extraction. Narration, as a system of stories, provides insights into how events and characters in the stories develop over time. This paper proposes an architecture for NER on a corpus about social purpose organizations. This is the first NER task specifically targeted at social service entities. We show how this approach can be used for the sequencing of services and impacted clients with information extracted from unstructured text. The methodology outlines steps for extracting ontological representation of entities such as needs and satisfiers and generating hypotheses to answer queries about impact models defined by social purpose organizations. We evaluate the model on a corpus of social service descriptions with empirically calculated score.
Linear time DBSCAN for sorted 1D data and laser range scan segmentation
Mar 30, 2021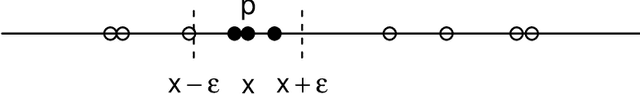


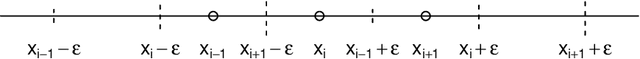
This paper introduces new algorithm for line extraction from laser range data including methodology for efficient computation. The task is cast to series of one dimensional problems in various spaces. A fast and simple specialization of DBSCAN algorithm is proposed to solve one dimensional subproblems. Experiments suggest that the method is suitable for real-time applications, handles noise well and may be useful in practice.
Learning Spatially Varying Pixel Exposures for Motion Deblurring
Apr 14, 2022
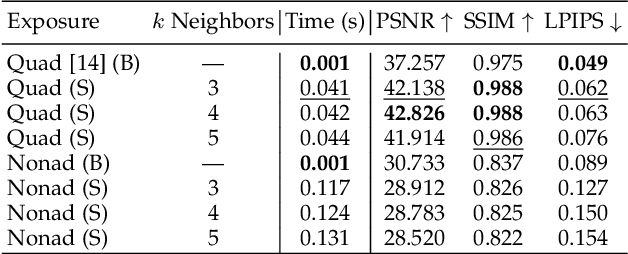
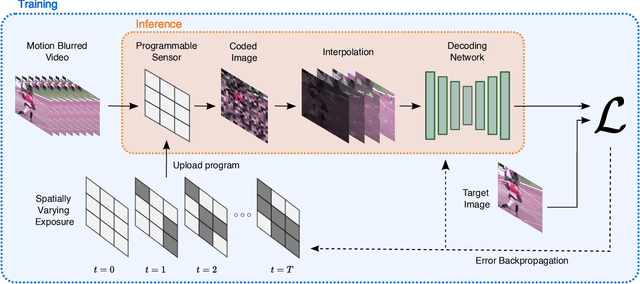
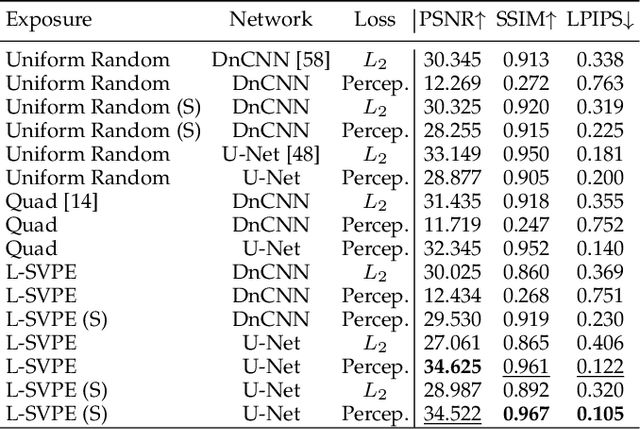
Computationally removing the motion blur introduced by camera shake or object motion in a captured image remains a challenging task in computational photography. Deblurring methods are often limited by the fixed global exposure time of the image capture process. The post-processing algorithm either must deblur a longer exposure that contains relatively little noise or denoise a short exposure that intentionally removes the opportunity for blur at the cost of increased noise. We present a novel approach of leveraging spatially varying pixel exposures for motion deblurring using next-generation focal-plane sensor--processors along with an end-to-end design of these exposures and a machine learning--based motion-deblurring framework. We demonstrate in simulation and a physical prototype that learned spatially varying pixel exposures (L-SVPE) can successfully deblur scenes while recovering high frequency detail. Our work illustrates the promising role that focal-plane sensor--processors can play in the future of computational imaging.
On-the-fly 3D metrology of volumetric additive manufacturing
Feb 07, 2022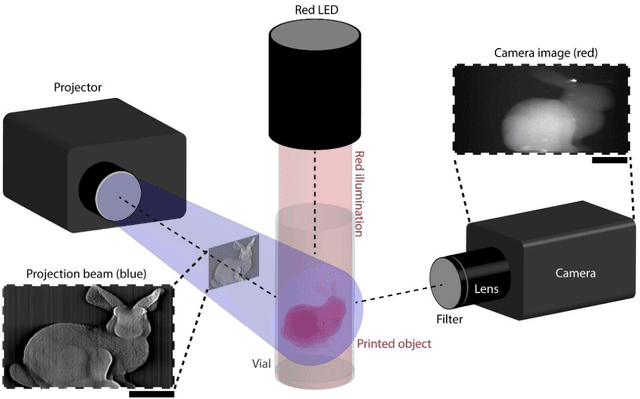
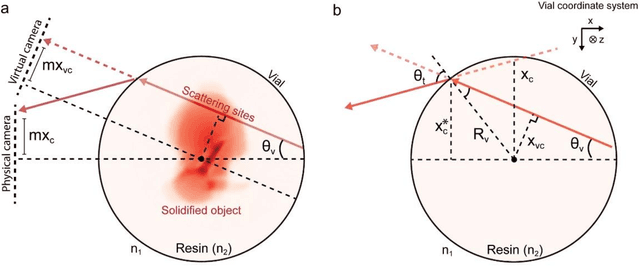
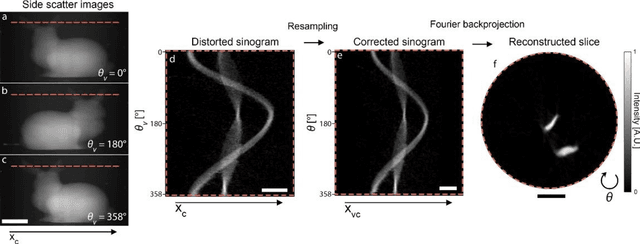
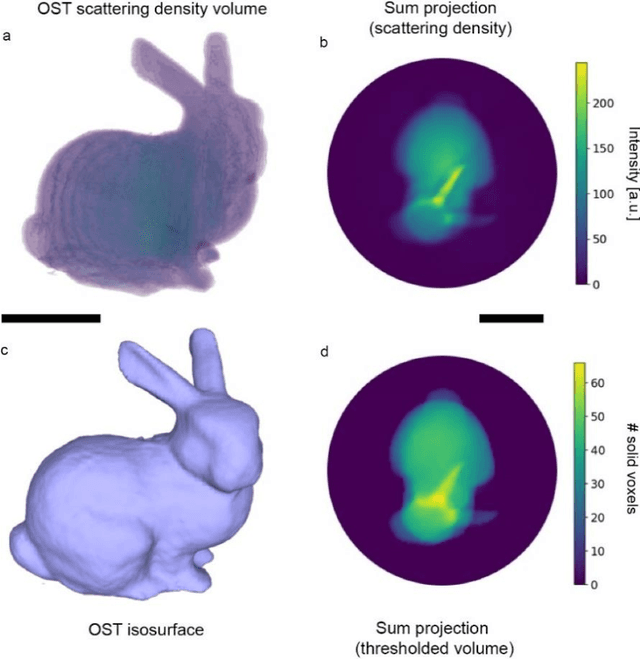
Additive manufacturing techniques are revolutionizing product development by enabling fast turnaround from design to fabrication. However, the throughput of the rapid prototyping pipeline remains constrained by print optimization, requiring multiple iterations of fabrication and ex-situ metrology. Despite the need for a suitable technology, robust in-situ shape measurement of an entire print is not currently available with any additive manufacturing modality. Here, we address this shortcoming by demonstrating fully simultaneous 3D metrology and printing. We exploit the dramatic increase in light scattering by a photoresin during gelation for real-time 3D imaging of prints during tomographic volumetric additive manufacturing. Tomographic imaging of the light scattering density in the build volume yields quantitative, artifact-free 3D + time models of cured objects that are accurate to below 1% of the size of the print. By integrating shape measurement into the printing process, our work paves the way for next-generation rapid prototyping with real-time defect detection and correction.
$π$BO: Augmenting Acquisition Functions with User Beliefs for Bayesian Optimization
Apr 23, 2022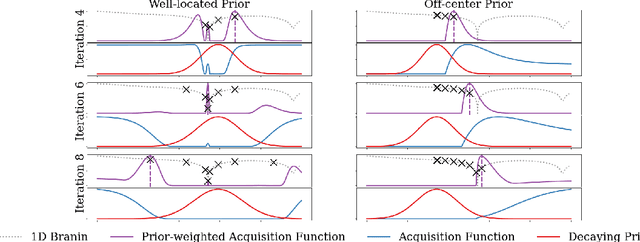
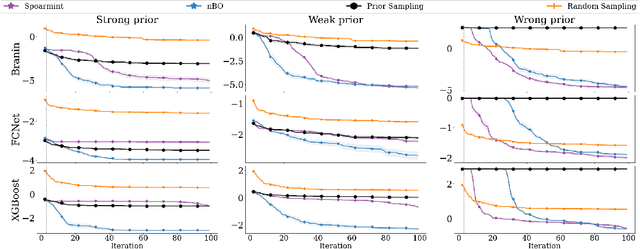

Bayesian optimization (BO) has become an established framework and popular tool for hyperparameter optimization (HPO) of machine learning (ML) algorithms. While known for its sample-efficiency, vanilla BO can not utilize readily available prior beliefs the practitioner has on the potential location of the optimum. Thus, BO disregards a valuable source of information, reducing its appeal to ML practitioners. To address this issue, we propose $\pi$BO, an acquisition function generalization which incorporates prior beliefs about the location of the optimum in the form of a probability distribution, provided by the user. In contrast to previous approaches, $\pi$BO is conceptually simple and can easily be integrated with existing libraries and many acquisition functions. We provide regret bounds when $\pi$BO is applied to the common Expected Improvement acquisition function and prove convergence at regular rates independently of the prior. Further, our experiments show that $\pi$BO outperforms competing approaches across a wide suite of benchmarks and prior characteristics. We also demonstrate that $\pi$BO improves on the state-of-the-art performance for a popular deep learning task, with a 12.5 $\times$ time-to-accuracy speedup over prominent BO approaches.
ARES: Accurate, Autonomous, Near Real-time 3D Reconstruction using Drones
Apr 20, 2021
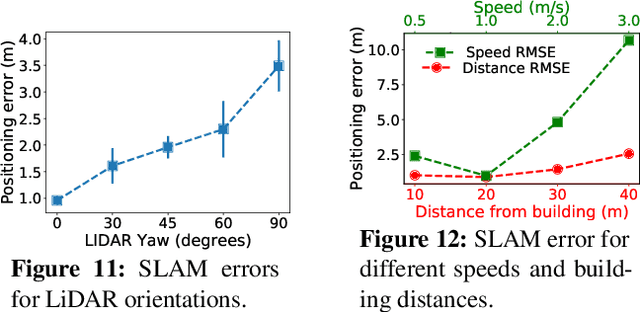
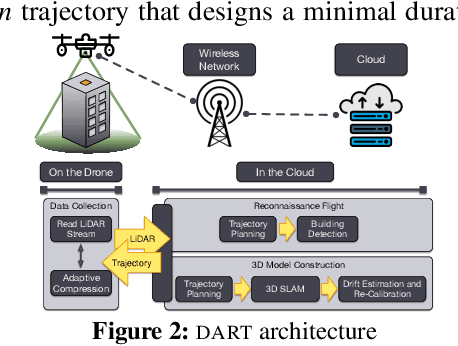
Drones will revolutionize 3D modeling. A 3D model represents an accurate reconstruction of an object or structure. This paper explores the design and implementation of ARES, which provides near real-time, accurate reconstruction of 3D models using a drone-mounted LiDAR; such a capability can be useful to document construction or check aircraft integrity between flights. Accurate reconstruction requires high drone positioning accuracy, and, because GPS can be in accurate, ARES uses SLAM. However, in doing so it must deal with several competing constraints: drone battery and compute resources, SLAM error accumulation, and LiDAR resolution. ARES uses careful trajectory design to find a sweet spot in this constraint space, a fast reconnaissance flight to narrow the search area for structures, and offloads expensive computations to the cloud by streaming compressed LiDAR data over LTE. ARES reconstructs large structures to within 10s of cms and incurs less than 100 ms compute latency.
On Optimal Early Stopping: Over-informative versus Under-informative Parametrization
Feb 20, 2022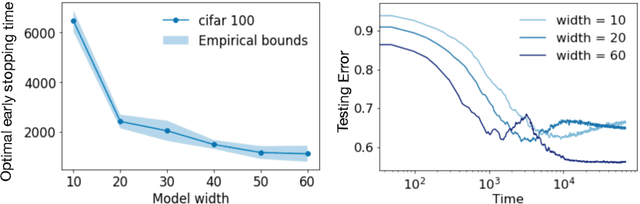
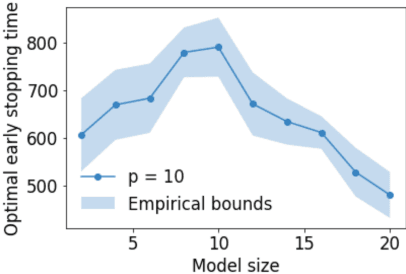
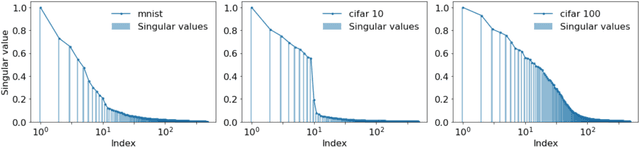
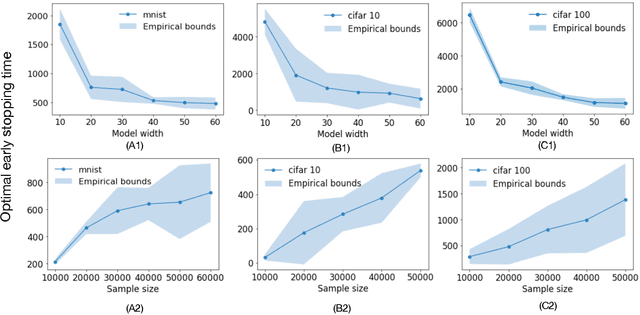
Early stopping is a simple and widely used method to prevent over-training neural networks. We develop theoretical results to reveal the relationship between the optimal early stopping time and model dimension as well as sample size of the dataset for certain linear models. Our results demonstrate two very different behaviors when the model dimension exceeds the number of features versus the opposite scenario. While most previous works on linear models focus on the latter setting, we observe that the dimension of the model often exceeds the number of features arising from data in common deep learning tasks and propose a model to study this setting. We demonstrate experimentally that our theoretical results on optimal early stopping time corresponds to the training process of deep neural networks.
Jacobian Ensembles Improve Robustness Trade-offs to Adversarial Attacks
Apr 19, 2022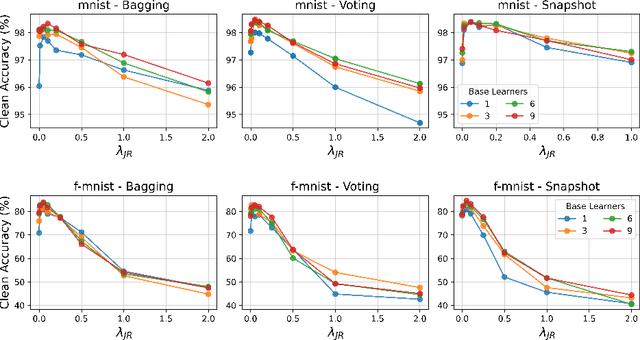
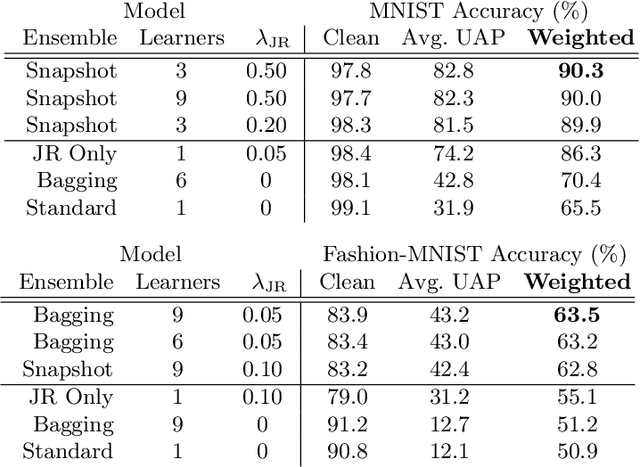
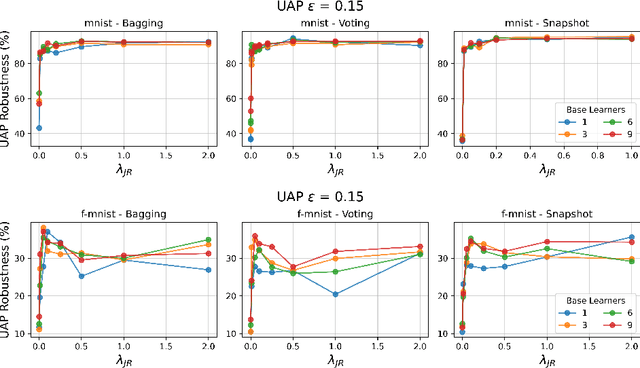
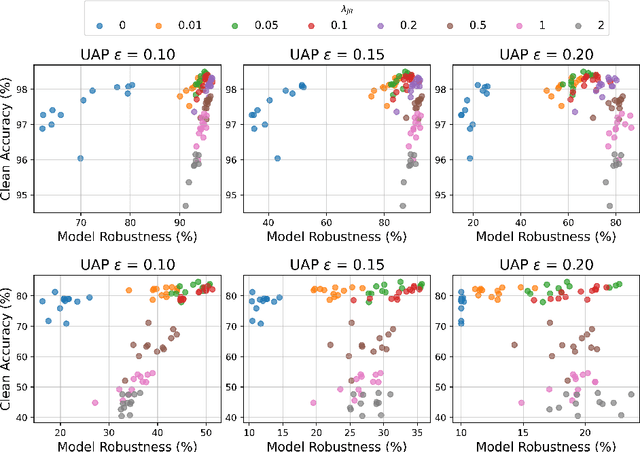
Deep neural networks have become an integral part of our software infrastructure and are being deployed in many widely-used and safety-critical applications. However, their integration into many systems also brings with it the vulnerability to test time attacks in the form of Universal Adversarial Perturbations (UAPs). UAPs are a class of perturbations that when applied to any input causes model misclassification. Although there is an ongoing effort to defend models against these adversarial attacks, it is often difficult to reconcile the trade-offs in model accuracy and robustness to adversarial attacks. Jacobian regularization has been shown to improve the robustness of models against UAPs, whilst model ensembles have been widely adopted to improve both predictive performance and model robustness. In this work, we propose a novel approach, Jacobian Ensembles-a combination of Jacobian regularization and model ensembles to significantly increase the robustness against UAPs whilst maintaining or improving model accuracy. Our results show that Jacobian Ensembles achieves previously unseen levels of accuracy and robustness, greatly improving over previous methods that tend to skew towards only either accuracy or robustness.
Improving Self-Supervised Learning-based MOS Prediction Networks
Apr 23, 2022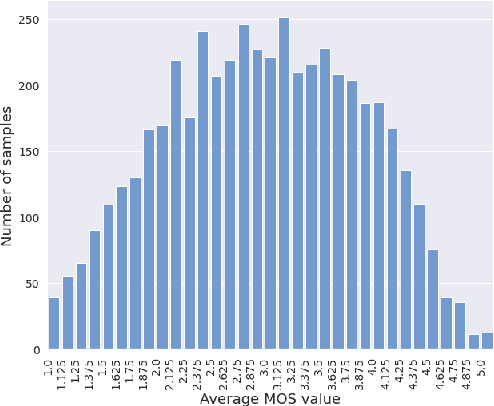
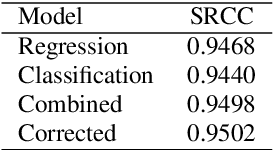
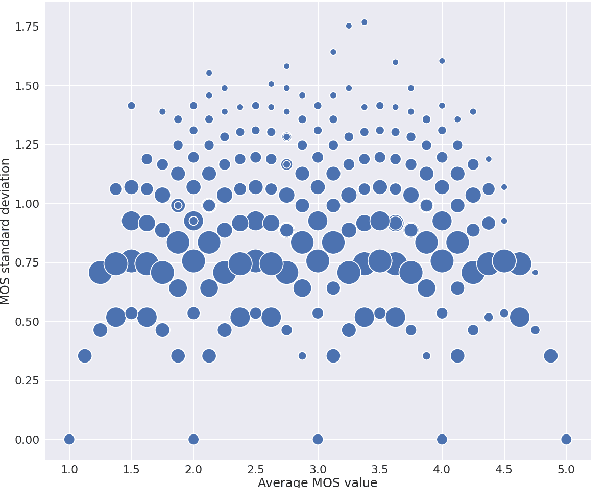
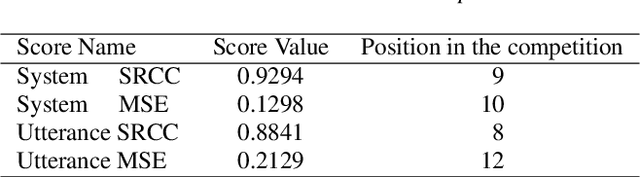
MOS (Mean Opinion Score) is a subjective method used for the evaluation of a system's quality. Telecommunications (for voice and video), and speech synthesis systems (for generated speech) are a few of the many applications of the method. While MOS tests are widely accepted, they are time-consuming and costly since human input is required. In addition, since the systems and subjects of the tests differ, the results are not really comparable. On the other hand, a large number of previous tests allow us to train machine learning models that are capable of predicting MOS value. By automatically predicting MOS values, both the aforementioned issues can be resolved. The present work introduces data-, training- and post-training specific improvements to a previous self-supervised learning-based MOS prediction model. We used a wav2vec 2.0 model pre-trained on LibriSpeech, extended with LSTM and non-linear dense layers. We introduced transfer learning, target data preprocessing a two- and three-phase training method with different batch formulations, dropout accumulation (for larger batch sizes) and quantization of the predictions. The methods are evaluated using the shared synthetic speech dataset of the first Voice MOS challenge.
Real-time Outdoor Localization Using Radio Maps: A Deep Learning Approach
Jun 23, 2021
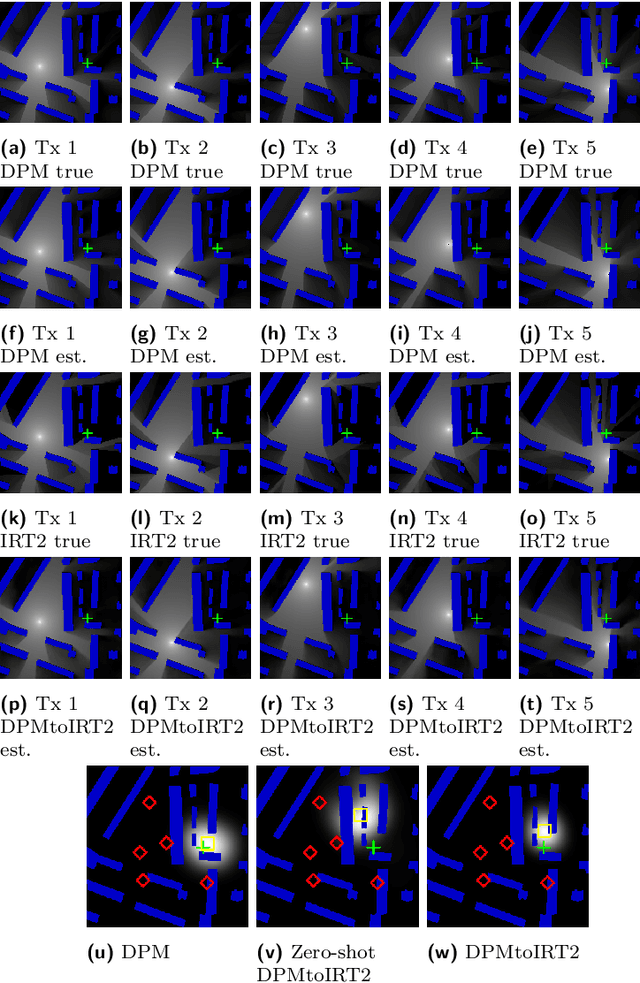
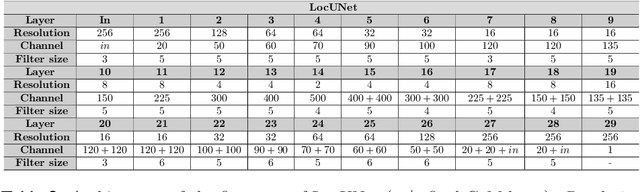
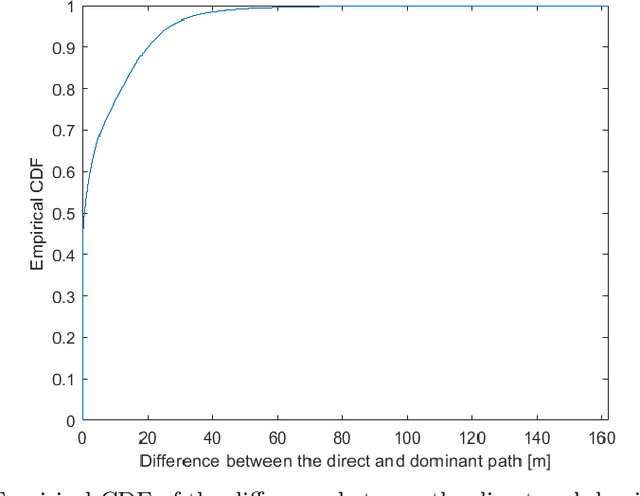
This paper deals with the problem of localization in a cellular network in a dense urban scenario. Global Navigation Satellite Systems typically perform poorly in urban environments, where the likelihood of line-of-sight conditions between the devices and the satellites is low, and thus alternative localization methods are required for good accuracy. We present a deep learning method for localization, based merely on pathloss, which does not require any increase in computation complexity at the user devices with respect to the device standard operations, unlike methods that rely on time of arrival or angle of arrival information. In a wireless network, user devices scan the base station beacon slots and identify the few strongest base station signals for handover and user-base station association purposes. In the proposed method, the user to be localized simply reports such received signal strengths to a central processing unit, which may be located in the cloud. For each base station we have good approximation of the pathloss at every location in a dense grid in the map. This approximation is provided by RadioUNet, a deep learning-based simulator of pathloss functions in urban environment, that we have previously proposed and published. Using the estimated pathloss radio maps of all base stations and the corresponding reported signal strengths, the proposed deep learning algorithm can extract a very accurate localization of the user. The proposed method, called LocUNet, enjoys high robustness to inaccuracies in the estimated radio maps. We demonstrate this by numerical experiments, which obtain state-of-the-art results.