 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Models for information propagation on graphs
Jan 19, 2022
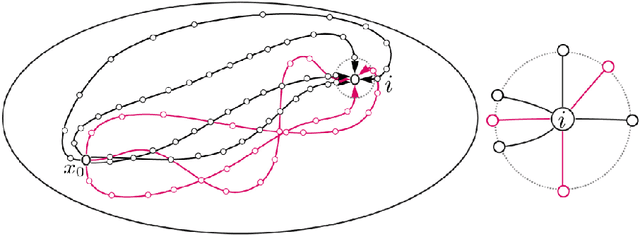

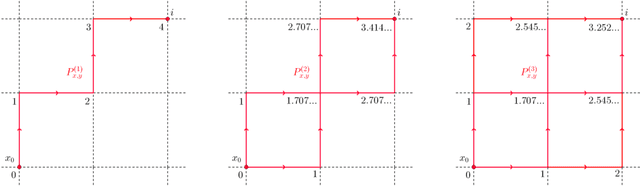
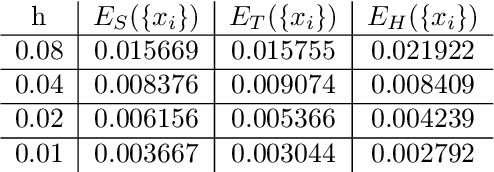
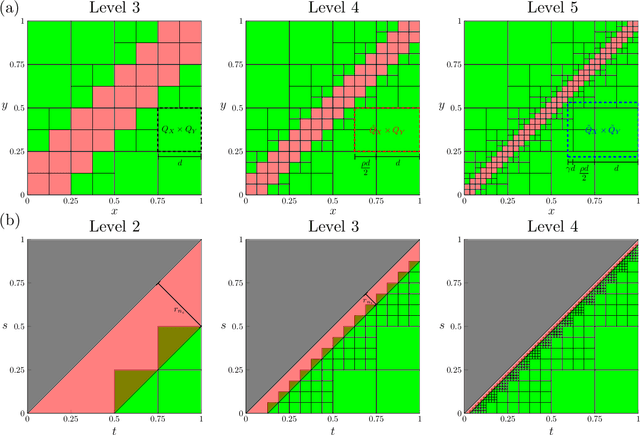
In this work we propose and unify classes of different models for information propagation over graphs. In a first class, propagation is modeled as a wave which emanates from a set of known nodes at an initial time, to all other unknown nodes at later times with an ordering determined by the time at which the information wave front reaches nodes. A second class of models is based on the notion of a travel time along paths between nodes. The time of information propagation from an initial known set of nodes to a node is defined as the minimum of a generalized travel time over subsets of all admissible paths. A final class is given by imposing a local equation of an eikonal form at each unknown node, with boundary conditions at the known nodes. The solution value of the local equation at a node is coupled the neighbouring nodes with smaller solution values. We provide precise formulations of the model classes in this graph setting, and prove equivalences between them. Motivated by the connection between first arrival time model and the eikonal equation in the continuum setting, we demonstrate that for graphs in the particular form of grids in Euclidean space mean field limits under grid refinement of certain graph models lead to Hamilton-Jacobi PDEs. For a specific parameter setting, we demonstrate that the solution on the grid approximates the Euclidean distance.
Where to Go for the Holidays: Towards Mixed-Type Dialogs for Clarification of User Goals
Apr 15, 2022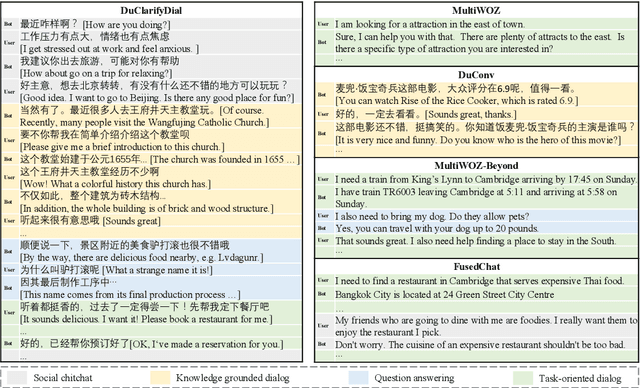

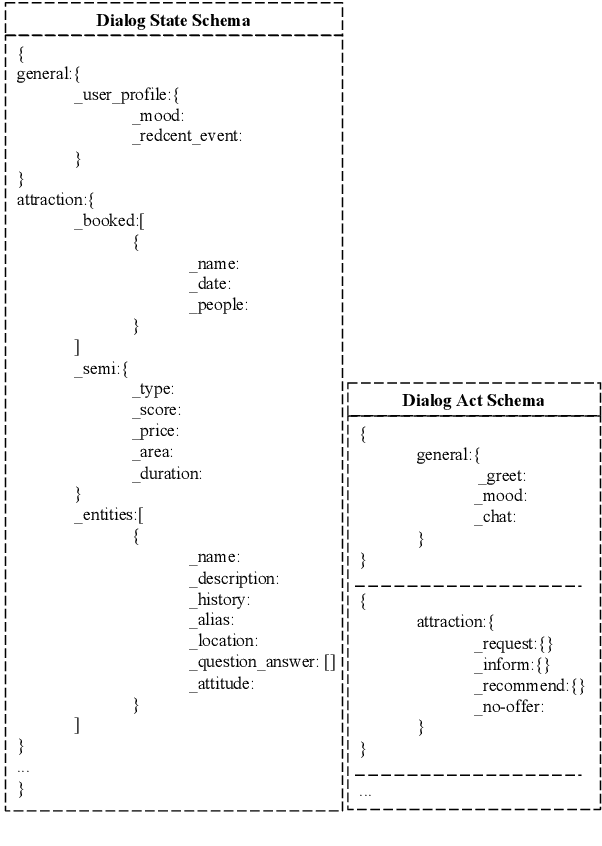
Most dialog systems posit that users have figured out clear and specific goals before starting an interaction. For example, users have determined the departure, the destination, and the travel time for booking a flight. However, in many scenarios, limited by experience and knowledge, users may know what they need, but still struggle to figure out clear and specific goals by determining all the necessary slots. In this paper, we identify this challenge and make a step forward by collecting a new human-to-human mixed-type dialog corpus. It contains 5k dialog sessions and 168k utterances for 4 dialog types and 5 domains. Within each session, an agent first provides user-goal-related knowledge to help figure out clear and specific goals, and then help achieve them. Furthermore, we propose a mixed-type dialog model with a novel Prompt-based continual learning mechanism. Specifically, the mechanism enables the model to continually strengthen its ability on any specific type by utilizing existing dialog corpora effectively.
Learning Green's functions associated with parabolic partial differential equations
Apr 27, 2022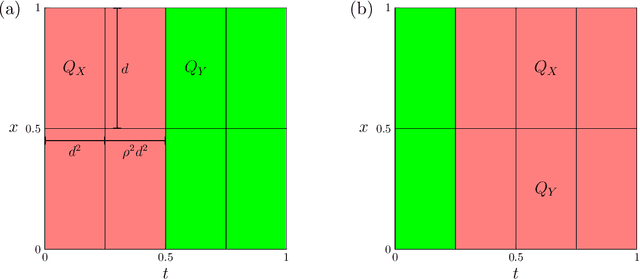
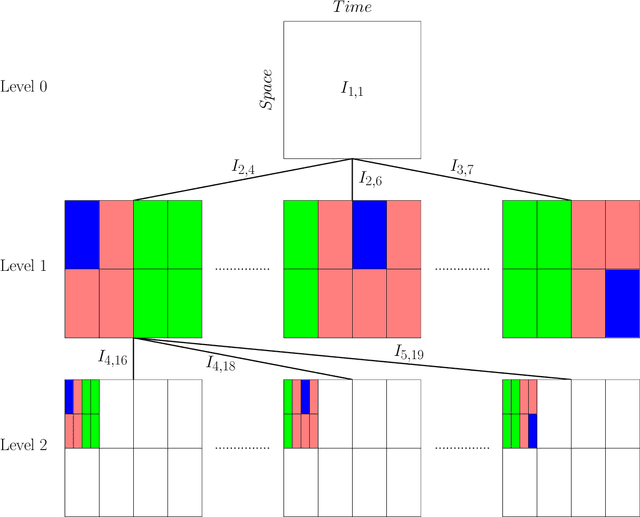
Given input-output pairs from a parabolic partial differential equation (PDE) in any spatial dimension $n\geq 1$, we derive the first theoretically rigorous scheme for learning the associated Green's function $G$. Until now, rigorously learning Green's functions associated with parabolic operators has been a major challenge in the field of scientific machine learning because $G$ may not be square-integrable when $n>1$, and time-dependent PDEs have transient dynamics. By combining the hierarchical low-rank structure of $G$ together with the randomized singular value decomposition, we construct an approximant to $G$ that achieves a relative error of $\smash{\mathcal{O}(\Gamma_\epsilon^{-1/2}\epsilon)}$ in the $L^1$-norm with high probability by using at most $\smash{\mathcal{O}(\epsilon^{-\frac{n+2}{2}}\log(1/\epsilon))}$ input-output training pairs, where $\Gamma_\epsilon$ is a measure of the quality of the training dataset for learning $G$, and $\epsilon>0$ is sufficiently small. Along the way, we extend the low-rank theory of Bebendorf and Hackbusch from elliptic PDEs in dimension $1\leq n\leq 3$ to parabolic PDEs in any dimensions, which shows that Green's functions associated with parabolic PDEs admit a low-rank structure on well-separated domains.
Analysis of Sparse Subspace Clustering: Experiments and Random Projection
Apr 01, 2022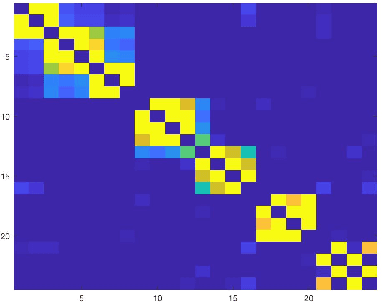
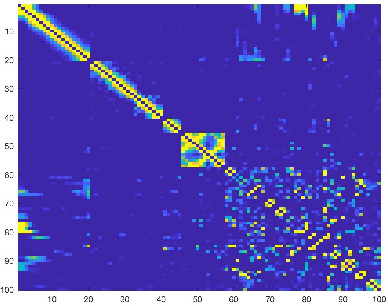
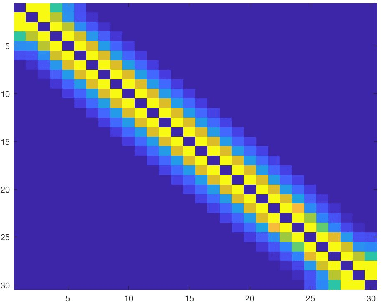

Clustering can be defined as the process of assembling objects into a number of groups whose elements are similar to each other in some manner. As a technique that is used in many domains, such as face clustering, plant categorization, image segmentation, document classification, clustering is considered one of the most important unsupervised learning problems. Scientists have surveyed this problem for years and developed different techniques that can solve it, such as k-means clustering. We analyze one of these techniques: a powerful clustering algorithm called Sparse Subspace Clustering. We demonstrate several experiments using this method and then introduce a new approach that can reduce the computational time required to perform sparse subspace clustering.
10,000 km Straight-line Transmission using a Real-time Software-defined GPU-Based Receiver
Apr 08, 2021Real-time operation of a software-defined, GPU-based optical receiver is demonstrated over a 100-span straight-line optical link. Performance of minimum-phase Kramers-Kronig 4-, 8-, 16-, 32-, and 64-QAM signals are evaluated at various distances.
Geometric Algebra based Embeddings for Staticand Temporal Knowledge Graph Completion
Feb 18, 2022
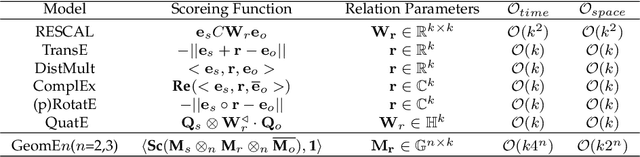
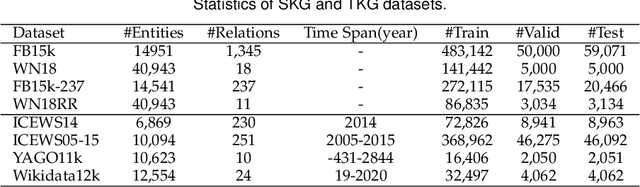
Recent years, Knowledge Graph Embeddings (KGEs) have shown promising performance on link prediction tasks by mapping the entities and relations from a Knowledge Graph (KG) into a geometric space and thus have gained increasing attentions. In addition, many recent Knowledge Graphs involve evolving data, e.g., the fact (\textit{Obama}, \textit{PresidentOf}, \textit{USA}) is valid only from 2009 to 2017. This introduces important challenges for knowledge representation learning since such temporal KGs change over time. In this work, we strive to move beyond the complex or hypercomplex space for KGE and propose a novel geometric algebra based embedding approach, GeomE, which uses multivector representations and the geometric product to model entities and relations. GeomE subsumes several state-of-the-art KGE models and is able to model diverse relations patterns. On top of this, we extend GeomE to TGeomE for temporal KGE, which performs 4th-order tensor factorization of a temporal KG and devises a new linear temporal regularization for time representation learning. Moreover, we study the effect of time granularity on the performance of TGeomE models. Experimental results show that our proposed models achieve the state-of-the-art performances on link prediction over four commonly-used static KG datasets and four well-established temporal KG datasets across various metrics.
Achieving Long-Term Fairness in Sequential Decision Making
Apr 04, 2022
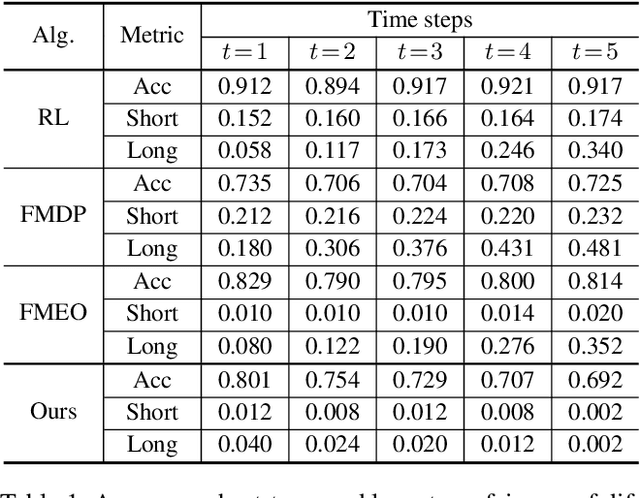
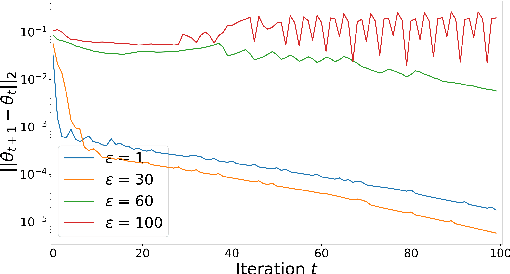
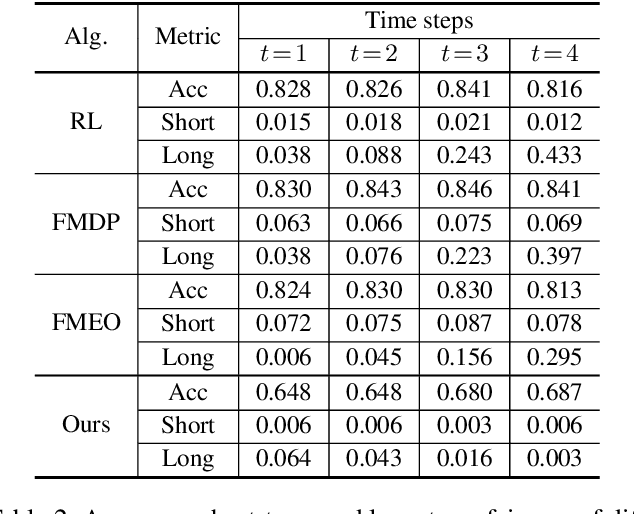
In this paper, we propose a framework for achieving long-term fair sequential decision making. By conducting both the hard and soft interventions, we propose to take path-specific effects on the time-lagged causal graph as a quantitative tool for measuring long-term fairness. The problem of fair sequential decision making is then formulated as a constrained optimization problem with the utility as the objective and the long-term and short-term fairness as constraints. We show that such an optimization problem can be converted to a performative risk optimization. Finally, repeated risk minimization (RRM) is used for model training, and the convergence of RRM is theoretically analyzed. The empirical evaluation shows the effectiveness of the proposed algorithm on synthetic and semi-synthetic temporal datasets.
Decision-making of Emergent Incident based on P-MADDPG
Mar 19, 2022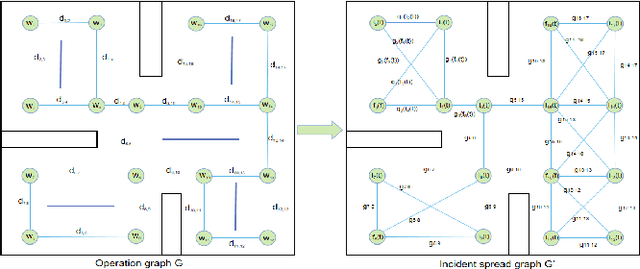
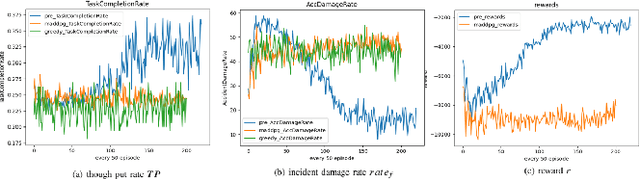
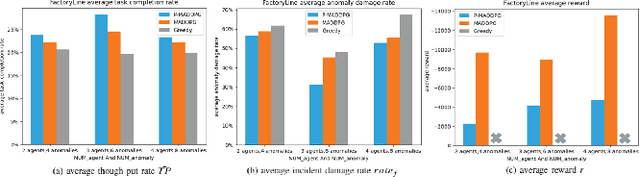

In recent years, human casualties and damage to resources caused by emergent incidents have become a serious problem worldwide. In this paper, we model the emergency decision-making problem and use Multi-agent System (MAS) to solve the problem that the decision speed cannot keep up with the spreading speed. MAS can play an important role in the automated execution of these tasks to reduce mission completion time. In this paper, we propose a P-MADDPG algorithm to solve the emergency decision-making problem of emergent incidents, which predicts the nodes where an incident may occur in the next time by GRU model and makes decisions before the incident occurs, thus solving the problem that the decision speed cannot keep up with the spreading speed. A simulation environment was established for realistic scenarios, and three scenarios were selected to test the performance of P-MADDPG in emergency decision-making problems for emergent incidents: unmanned storage, factory assembly line, and civil airport baggage transportation. Simulation results using the P-MADDPG algorithm are compared with the greedy algorithm and the MADDPG algorithm, and the final experimental results show that the P-MADDPG algorithm converges faster and better than the other algorithms in scenarios of different sizes. This shows that the P-MADDP algorithm is effective for emergency decision-making in emergent incident.
Private Frequency Estimation via Projective Geometry
Mar 01, 2022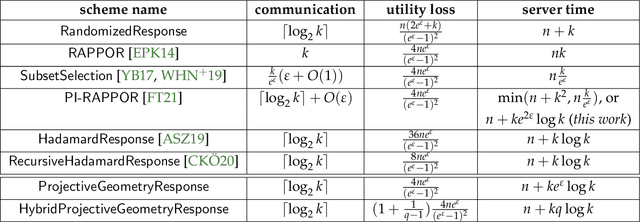
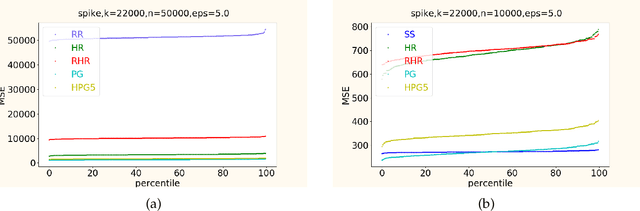
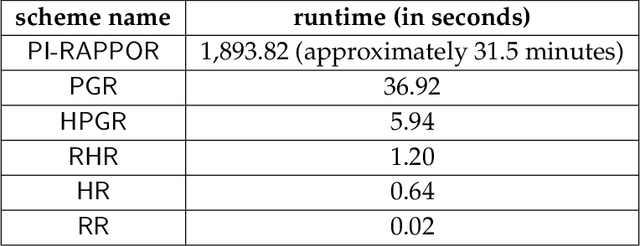
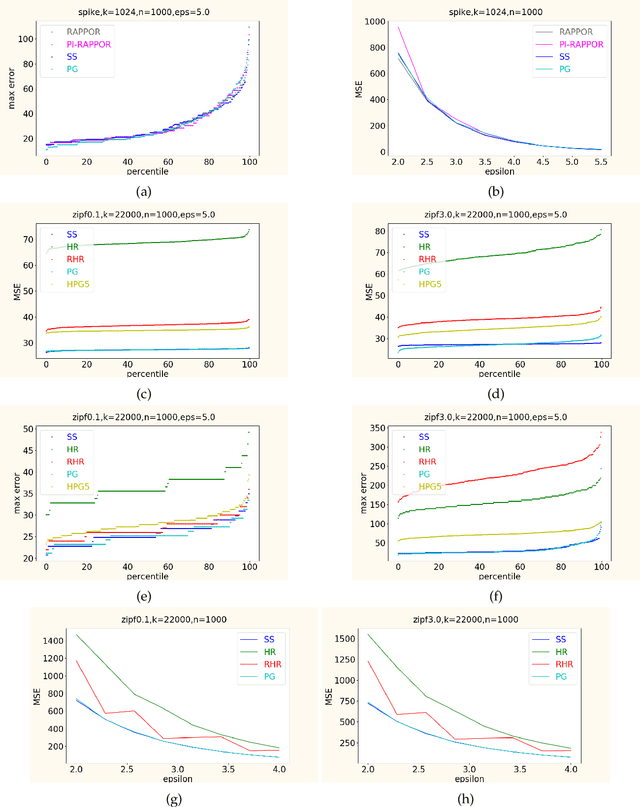
In this work, we propose a new algorithm ProjectiveGeometryResponse (PGR) for locally differentially private (LDP) frequency estimation. For a universe size of $k$ and with $n$ users, our $\varepsilon$-LDP algorithm has communication cost $\lceil\log_2k\rceil$ bits in the private coin setting and $\varepsilon\log_2 e + O(1)$ in the public coin setting, and has computation cost $O(n + k\exp(\varepsilon) \log k)$ for the server to approximately reconstruct the frequency histogram, while achieving the state-of-the-art privacy-utility tradeoff. In many parameter settings used in practice this is a significant improvement over the $ O(n+k^2)$ computation cost that is achieved by the recent PI-RAPPOR algorithm (Feldman and Talwar; 2021). Our empirical evaluation shows a speedup of over 50x over PI-RAPPOR while using approximately 75x less memory for practically relevant parameter settings. In addition, the running time of our algorithm is within an order of magnitude of HadamardResponse (Acharya, Sun, and Zhang; 2019) and RecursiveHadamardResponse (Chen, Kairouz, and Ozgur; 2020) which have significantly worse reconstruction error. The error of our algorithm essentially matches that of the communication- and time-inefficient but utility-optimal SubsetSelection (SS) algorithm (Ye and Barg; 2017). Our new algorithm is based on using Projective Planes over a finite field to define a small collection of sets that are close to being pairwise independent and a dynamic programming algorithm for approximate histogram reconstruction on the server side. We also give an extension of PGR, which we call HybridProjectiveGeometryResponse, that allows trading off computation time with utility smoothly.
Extracting Impact Model Narratives from Social Services' Text
Apr 04, 2022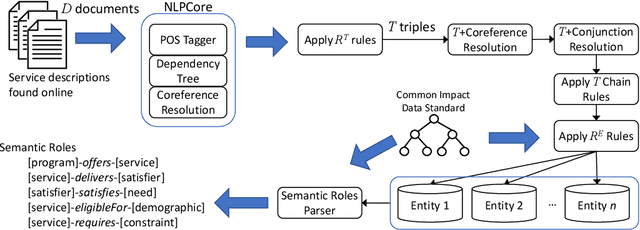


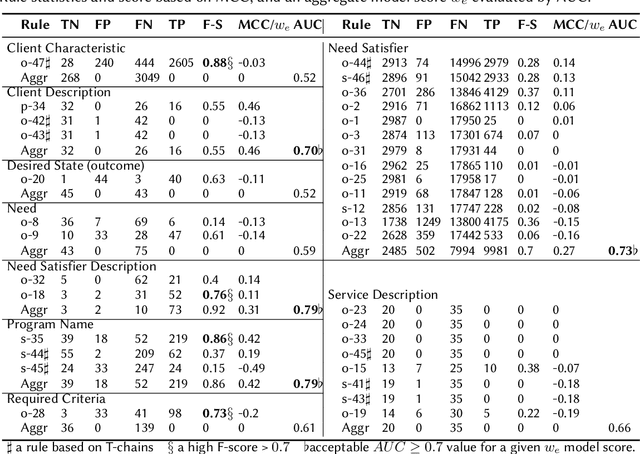
Named entity recognition (NER) is an important task in narration extraction. Narration, as a system of stories, provides insights into how events and characters in the stories develop over time. This paper proposes an architecture for NER on a corpus about social purpose organizations. This is the first NER task specifically targeted at social service entities. We show how this approach can be used for the sequencing of services and impacted clients with information extracted from unstructured text. The methodology outlines steps for extracting ontological representation of entities such as needs and satisfiers and generating hypotheses to answer queries about impact models defined by social purpose organizations. We evaluate the model on a corpus of social service descriptions with empirically calculated score.