 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Spatially Varying Pixel Exposures for Motion Deblurring
Apr 14, 2022

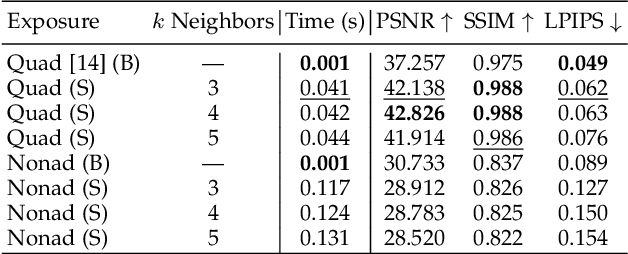
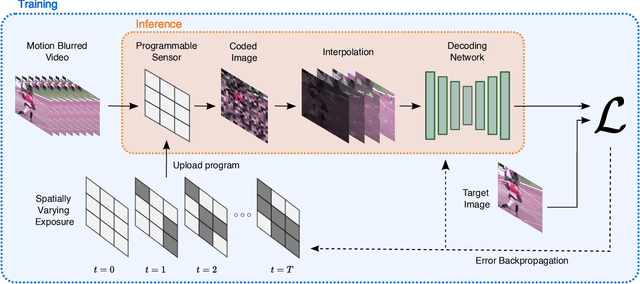
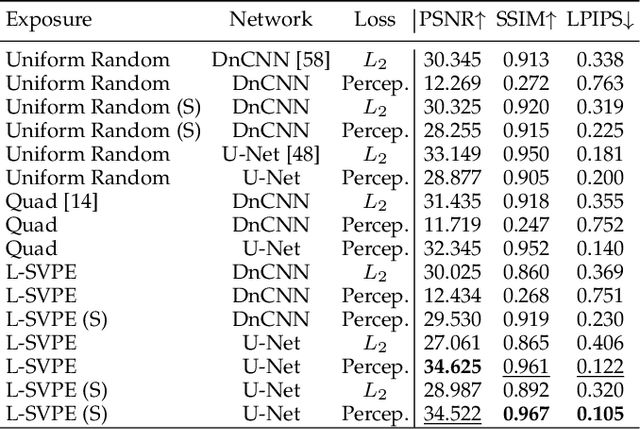
Computationally removing the motion blur introduced by camera shake or object motion in a captured image remains a challenging task in computational photography. Deblurring methods are often limited by the fixed global exposure time of the image capture process. The post-processing algorithm either must deblur a longer exposure that contains relatively little noise or denoise a short exposure that intentionally removes the opportunity for blur at the cost of increased noise. We present a novel approach of leveraging spatially varying pixel exposures for motion deblurring using next-generation focal-plane sensor--processors along with an end-to-end design of these exposures and a machine learning--based motion-deblurring framework. We demonstrate in simulation and a physical prototype that learned spatially varying pixel exposures (L-SVPE) can successfully deblur scenes while recovering high frequency detail. Our work illustrates the promising role that focal-plane sensor--processors can play in the future of computational imaging.
A Quadratic Programming Approach to Manipulation in Real-Time Using Modular Robots
Apr 06, 2021
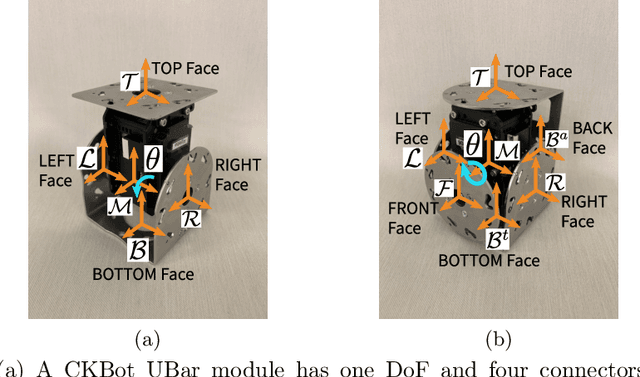
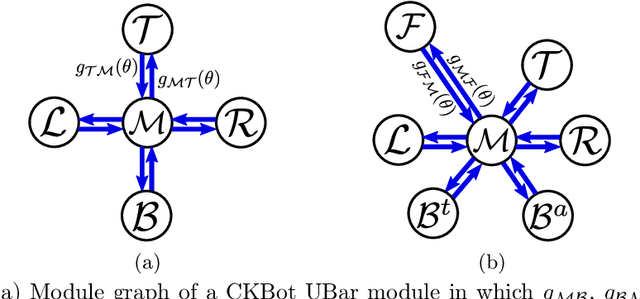

Motion planning in high-dimensional space is a challenging task. In order to perform dexterous manipulation in an unstructured environment, a robot with many degrees of freedom is usually necessary, which also complicates its motion planning problem. Real-time control brings about more difficulties in which robots have to maintain the stability while moving towards the target. Redundant systems are common in modular robots that consist of multiple modules and are able to transformed into different configurations with respect to different needs. Different from robots with fixed geometry or configurations, the kinematics model of a modular robotic system can alter as the robot reconfigures itself, and developing a generic control and motion planning approach for such systems is difficult, especially when multiple motion goals are coupled. A new manipulation planning framework is developed in this paper. The problem is formulated as a sequential linearly constrained quadratic program (QP) that can be solved efficiently. Some constraints can be incorporated into this QP, including a novel way to approximate environment obstacles. This solution can be used directly for real-time applications or as an off-line planning tool, and it is validated and demonstrated on the CKBot and SMORES-EP modular robot platforms.
Private Frequency Estimation via Projective Geometry
Mar 01, 2022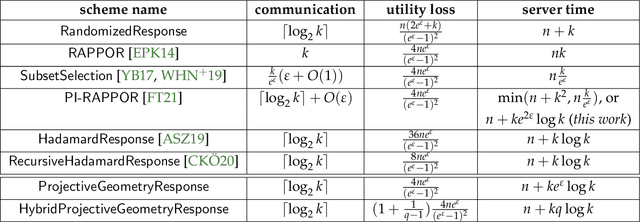
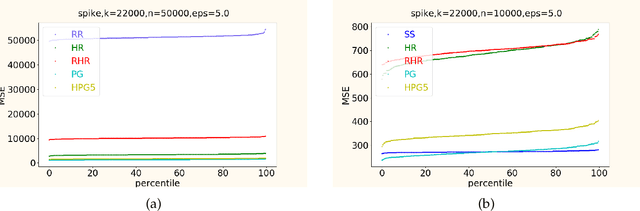
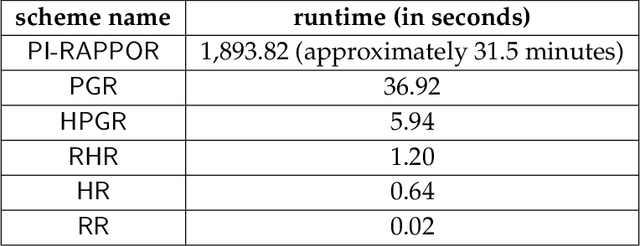
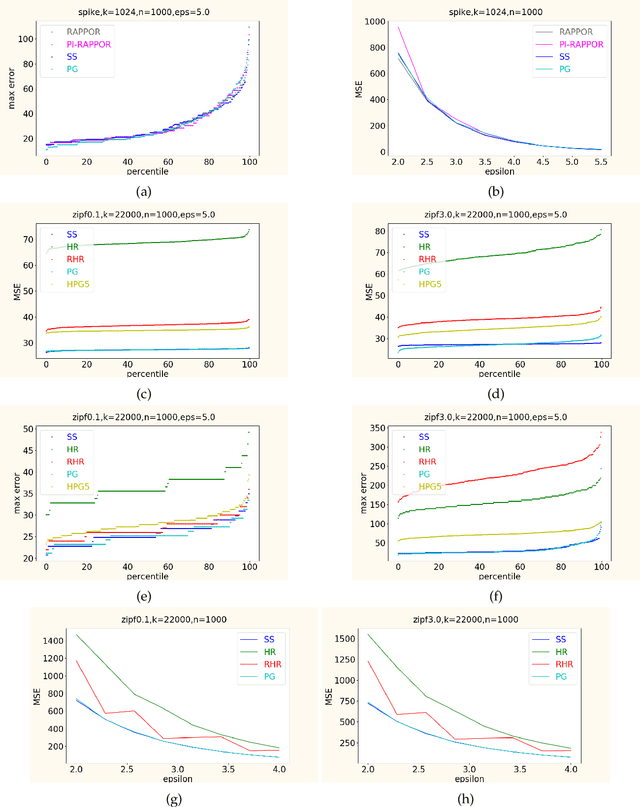
In this work, we propose a new algorithm ProjectiveGeometryResponse (PGR) for locally differentially private (LDP) frequency estimation. For a universe size of $k$ and with $n$ users, our $\varepsilon$-LDP algorithm has communication cost $\lceil\log_2k\rceil$ bits in the private coin setting and $\varepsilon\log_2 e + O(1)$ in the public coin setting, and has computation cost $O(n + k\exp(\varepsilon) \log k)$ for the server to approximately reconstruct the frequency histogram, while achieving the state-of-the-art privacy-utility tradeoff. In many parameter settings used in practice this is a significant improvement over the $ O(n+k^2)$ computation cost that is achieved by the recent PI-RAPPOR algorithm (Feldman and Talwar; 2021). Our empirical evaluation shows a speedup of over 50x over PI-RAPPOR while using approximately 75x less memory for practically relevant parameter settings. In addition, the running time of our algorithm is within an order of magnitude of HadamardResponse (Acharya, Sun, and Zhang; 2019) and RecursiveHadamardResponse (Chen, Kairouz, and Ozgur; 2020) which have significantly worse reconstruction error. The error of our algorithm essentially matches that of the communication- and time-inefficient but utility-optimal SubsetSelection (SS) algorithm (Ye and Barg; 2017). Our new algorithm is based on using Projective Planes over a finite field to define a small collection of sets that are close to being pairwise independent and a dynamic programming algorithm for approximate histogram reconstruction on the server side. We also give an extension of PGR, which we call HybridProjectiveGeometryResponse, that allows trading off computation time with utility smoothly.
$π$BO: Augmenting Acquisition Functions with User Beliefs for Bayesian Optimization
Apr 23, 2022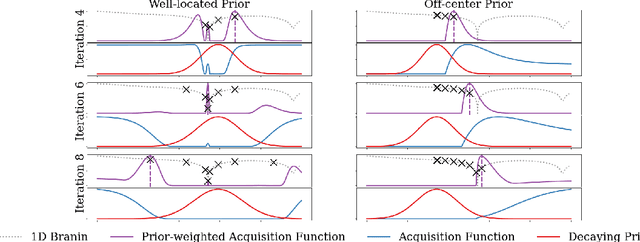
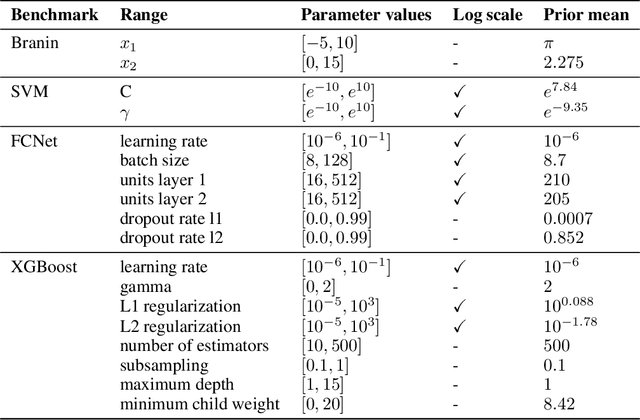
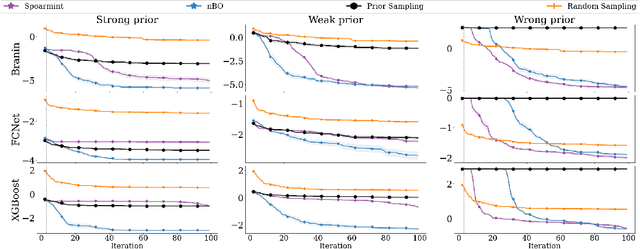

Bayesian optimization (BO) has become an established framework and popular tool for hyperparameter optimization (HPO) of machine learning (ML) algorithms. While known for its sample-efficiency, vanilla BO can not utilize readily available prior beliefs the practitioner has on the potential location of the optimum. Thus, BO disregards a valuable source of information, reducing its appeal to ML practitioners. To address this issue, we propose $\pi$BO, an acquisition function generalization which incorporates prior beliefs about the location of the optimum in the form of a probability distribution, provided by the user. In contrast to previous approaches, $\pi$BO is conceptually simple and can easily be integrated with existing libraries and many acquisition functions. We provide regret bounds when $\pi$BO is applied to the common Expected Improvement acquisition function and prove convergence at regular rates independently of the prior. Further, our experiments show that $\pi$BO outperforms competing approaches across a wide suite of benchmarks and prior characteristics. We also demonstrate that $\pi$BO improves on the state-of-the-art performance for a popular deep learning task, with a 12.5 $\times$ time-to-accuracy speedup over prominent BO approaches.
Jacobian Ensembles Improve Robustness Trade-offs to Adversarial Attacks
Apr 19, 2022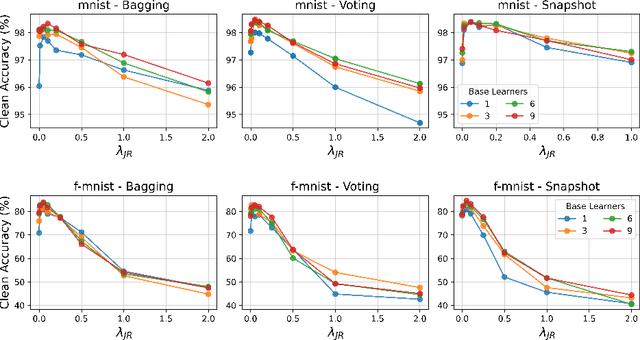
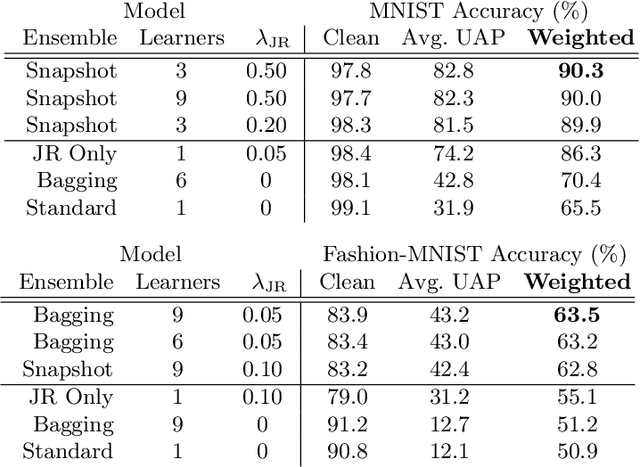
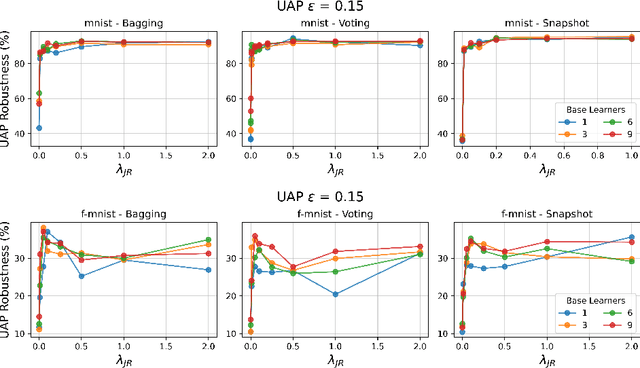
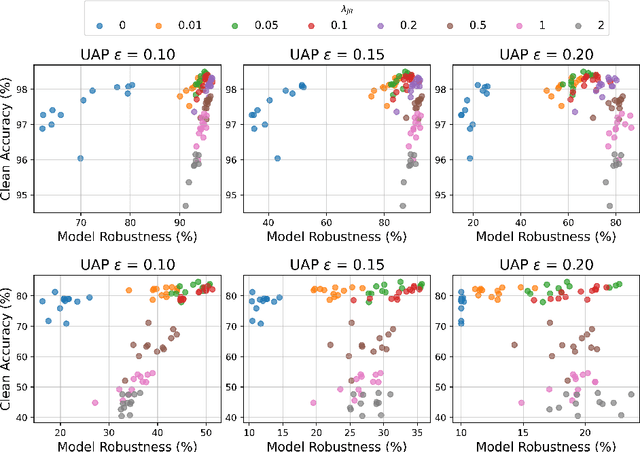
Deep neural networks have become an integral part of our software infrastructure and are being deployed in many widely-used and safety-critical applications. However, their integration into many systems also brings with it the vulnerability to test time attacks in the form of Universal Adversarial Perturbations (UAPs). UAPs are a class of perturbations that when applied to any input causes model misclassification. Although there is an ongoing effort to defend models against these adversarial attacks, it is often difficult to reconcile the trade-offs in model accuracy and robustness to adversarial attacks. Jacobian regularization has been shown to improve the robustness of models against UAPs, whilst model ensembles have been widely adopted to improve both predictive performance and model robustness. In this work, we propose a novel approach, Jacobian Ensembles-a combination of Jacobian regularization and model ensembles to significantly increase the robustness against UAPs whilst maintaining or improving model accuracy. Our results show that Jacobian Ensembles achieves previously unseen levels of accuracy and robustness, greatly improving over previous methods that tend to skew towards only either accuracy or robustness.
Improving Self-Supervised Learning-based MOS Prediction Networks
Apr 23, 2022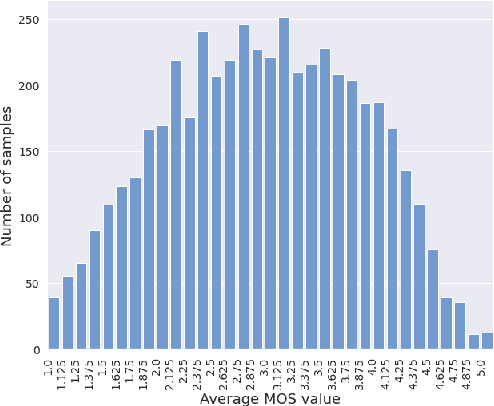
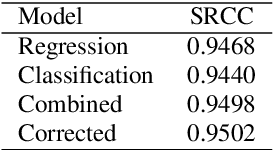
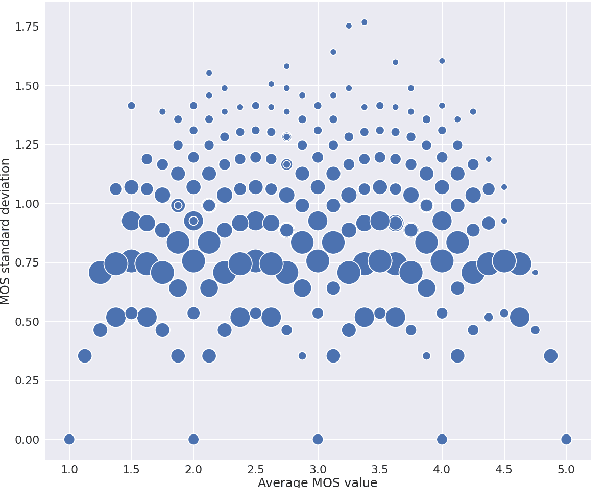
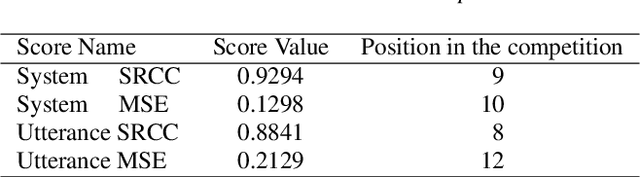
MOS (Mean Opinion Score) is a subjective method used for the evaluation of a system's quality. Telecommunications (for voice and video), and speech synthesis systems (for generated speech) are a few of the many applications of the method. While MOS tests are widely accepted, they are time-consuming and costly since human input is required. In addition, since the systems and subjects of the tests differ, the results are not really comparable. On the other hand, a large number of previous tests allow us to train machine learning models that are capable of predicting MOS value. By automatically predicting MOS values, both the aforementioned issues can be resolved. The present work introduces data-, training- and post-training specific improvements to a previous self-supervised learning-based MOS prediction model. We used a wav2vec 2.0 model pre-trained on LibriSpeech, extended with LSTM and non-linear dense layers. We introduced transfer learning, target data preprocessing a two- and three-phase training method with different batch formulations, dropout accumulation (for larger batch sizes) and quantization of the predictions. The methods are evaluated using the shared synthetic speech dataset of the first Voice MOS challenge.
On-the-fly 3D metrology of volumetric additive manufacturing
Feb 07, 2022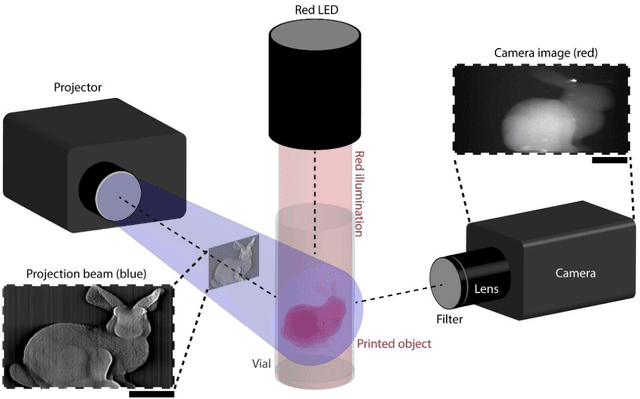
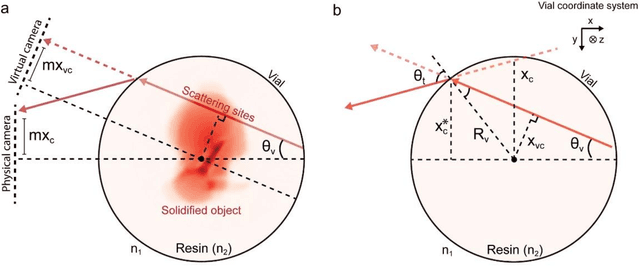
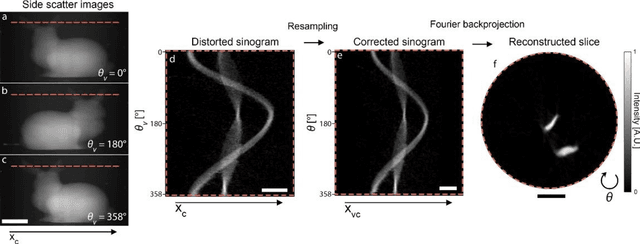
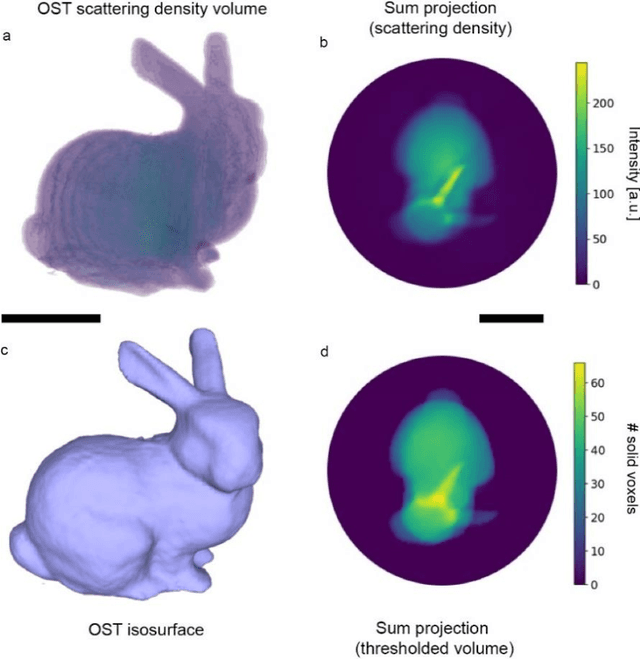
Additive manufacturing techniques are revolutionizing product development by enabling fast turnaround from design to fabrication. However, the throughput of the rapid prototyping pipeline remains constrained by print optimization, requiring multiple iterations of fabrication and ex-situ metrology. Despite the need for a suitable technology, robust in-situ shape measurement of an entire print is not currently available with any additive manufacturing modality. Here, we address this shortcoming by demonstrating fully simultaneous 3D metrology and printing. We exploit the dramatic increase in light scattering by a photoresin during gelation for real-time 3D imaging of prints during tomographic volumetric additive manufacturing. Tomographic imaging of the light scattering density in the build volume yields quantitative, artifact-free 3D + time models of cured objects that are accurate to below 1% of the size of the print. By integrating shape measurement into the printing process, our work paves the way for next-generation rapid prototyping with real-time defect detection and correction.
On Optimal Early Stopping: Over-informative versus Under-informative Parametrization
Feb 20, 2022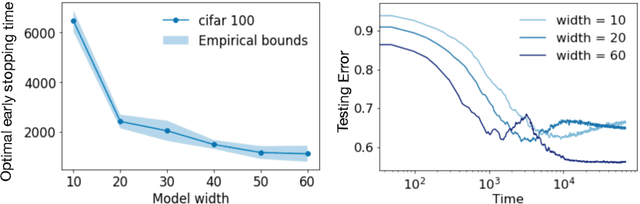
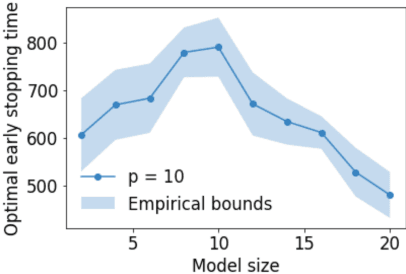
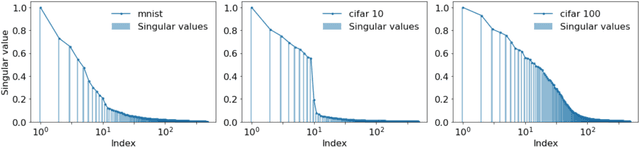
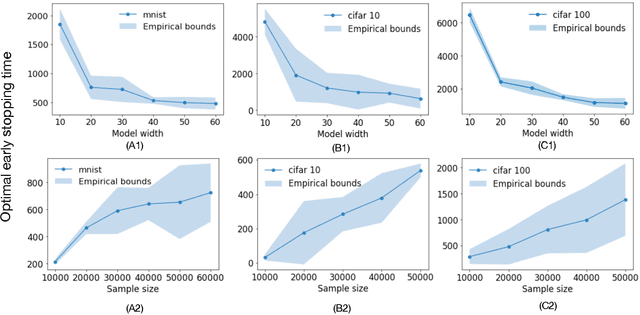
Early stopping is a simple and widely used method to prevent over-training neural networks. We develop theoretical results to reveal the relationship between the optimal early stopping time and model dimension as well as sample size of the dataset for certain linear models. Our results demonstrate two very different behaviors when the model dimension exceeds the number of features versus the opposite scenario. While most previous works on linear models focus on the latter setting, we observe that the dimension of the model often exceeds the number of features arising from data in common deep learning tasks and propose a model to study this setting. We demonstrate experimentally that our theoretical results on optimal early stopping time corresponds to the training process of deep neural networks.
10,000 km Straight-line Transmission using a Real-time Software-defined GPU-Based Receiver
Apr 08, 2021Real-time operation of a software-defined, GPU-based optical receiver is demonstrated over a 100-span straight-line optical link. Performance of minimum-phase Kramers-Kronig 4-, 8-, 16-, 32-, and 64-QAM signals are evaluated at various distances.
A New Lagrangian Problem Crossover: A Systematic Review and Meta-Analysis of Crossover Standards
Apr 27, 2022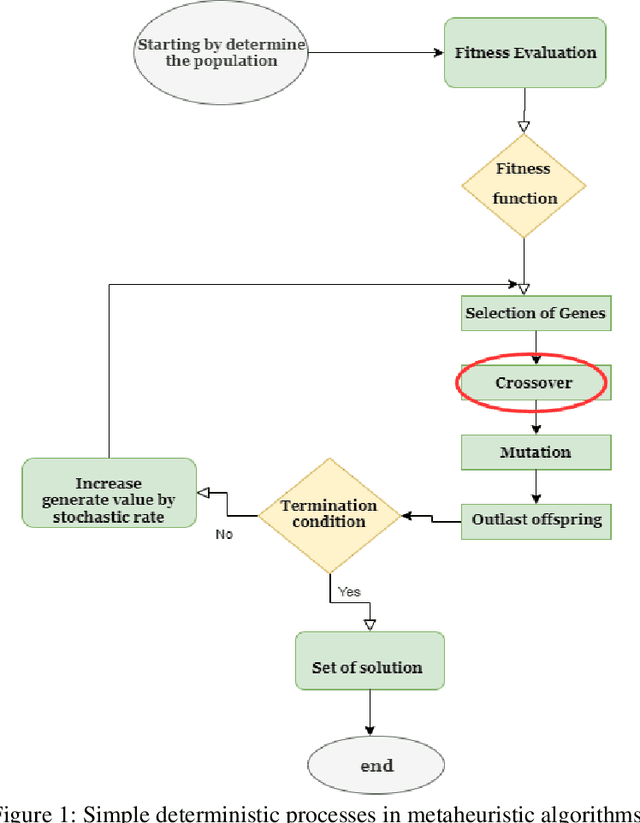
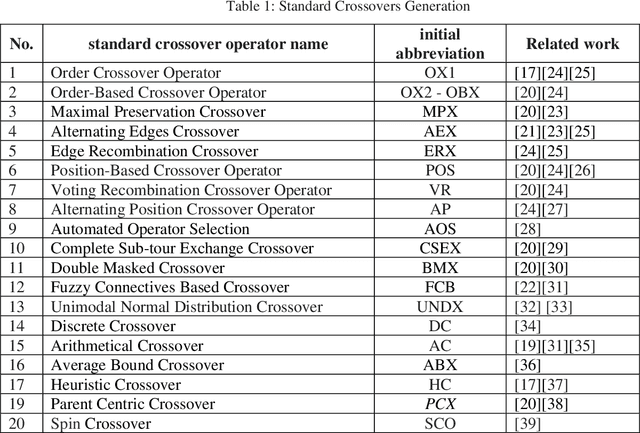
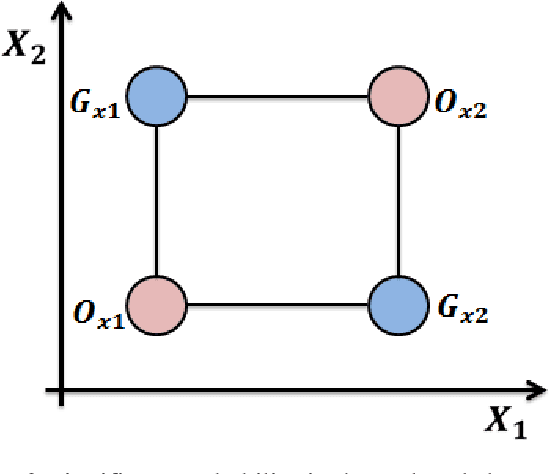

The performance of most evolutionary metaheuristic algorithms depends on various operators. The crossover operator is one of them and is mainly classified into two standards; application-dependent crossover operators and application-independent crossover operators. These standards always help to choose the best-fitted point in the evolutionary algorithm process. The high efficiency of crossover operators enables minimizing the error that occurred in engineering application optimization within a short time and cost. There are two crucial objectives behind this paper; at first, it is an overview of crossover standards classification that has been used by researchers for solving engineering operations and problem representation. The second objective of this paper; The significance of novel standard crossover is proposed depending on Lagrangian Dual Function (LDF) to progress the formulation of the Lagrangian Problem Crossover (LPX) as a new systematic standard operator. The results of the proposed crossover standards for 100 generations of parent chromosomes are compared to the BX and SBX standards, which are the communal real-coded crossover standards. The accuracy and performance of the proposed standard have evaluated by three unimodal test functions. Besides, the proposed standard results are statistically demonstrated and proved that it has an excessive ability to generate and enhance the novel optimization algorithm compared to BX and SBX.