 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Online Approach to Solve the Dynamic Vehicle Routing Problem with Stochastic Trip Requests for Paratransit Services
Mar 31, 2022
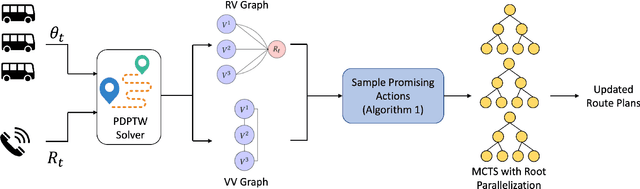
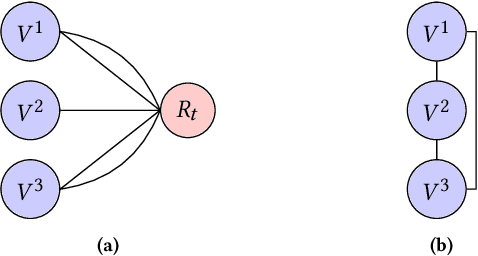
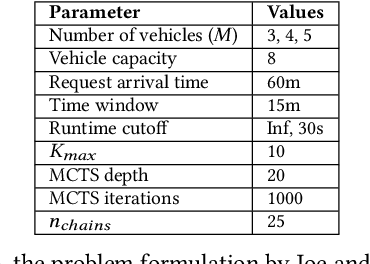
Many transit agencies operating paratransit and microtransit services have to respond to trip requests that arrive in real-time, which entails solving hard combinatorial and sequential decision-making problems under uncertainty. To avoid decisions that lead to significant inefficiency in the long term, vehicles should be allocated to requests by optimizing a non-myopic utility function or by batching requests together and optimizing a myopic utility function. While the former approach is typically offline, the latter can be performed online. We point out two major issues with such approaches when applied to paratransit services in practice. First, it is difficult to batch paratransit requests together as they are temporally sparse. Second, the environment in which transit agencies operate changes dynamically (e.g., traffic conditions), causing estimates that are learned offline to become stale. To address these challenges, we propose a fully online approach to solve the dynamic vehicle routing problem (DVRP) with time windows and stochastic trip requests that is robust to changing environmental dynamics by construction. We focus on scenarios where requests are relatively sparse - our problem is motivated by applications to paratransit services. We formulate DVRP as a Markov decision process and use Monte Carlo tree search to evaluate actions for any given state. Accounting for stochastic requests while optimizing a non-myopic utility function is computationally challenging; indeed, the action space for such a problem is intractably large in practice. To tackle the large action space, we leverage the structure of the problem to design heuristics that can sample promising actions for the tree search. Our experiments using real-world data from our partner agency show that the proposed approach outperforms existing state-of-the-art approaches both in terms of performance and robustness.
Open vs Closed-ended questions in attitudinal surveys -- comparing, combining, and interpreting using natural language processing
May 03, 2022
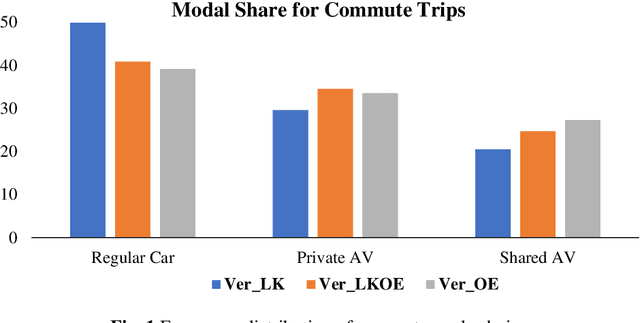
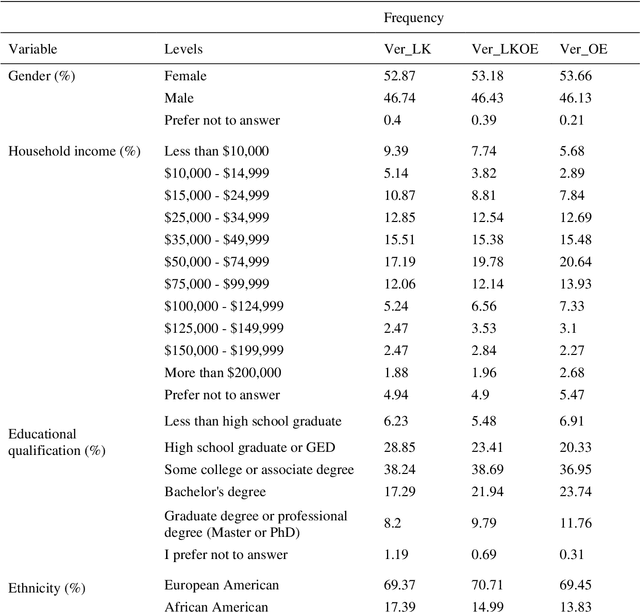
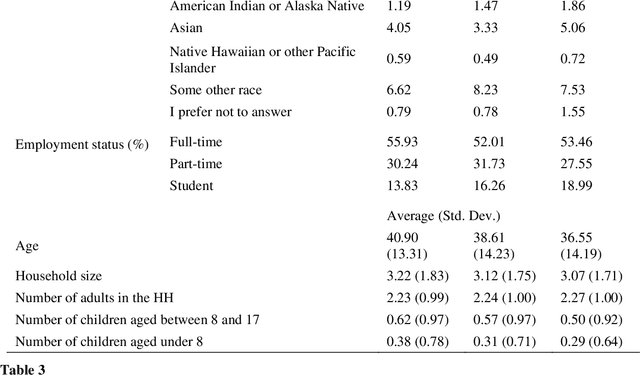
To improve the traveling experience, researchers have been analyzing the role of attitudes in travel behavior modeling. Although most researchers use closed-ended surveys, the appropriate method to measure attitudes is debatable. Topic Modeling could significantly reduce the time to extract information from open-ended responses and eliminate subjective bias, thereby alleviating analyst concerns. Our research uses Topic Modeling to extract information from open-ended questions and compare its performance with closed-ended responses. Furthermore, some respondents might prefer answering questions using their preferred questionnaire type. So, we propose a modeling framework that allows respondents to use their preferred questionnaire type to answer the survey and enable analysts to use the modeling frameworks of their choice to predict behavior. We demonstrate this using a dataset collected from the USA that measures the intention to use Autonomous Vehicles for commute trips. Respondents were presented with alternative questionnaire versions (open- and closed- ended). Since our objective was also to compare the performance of alternative questionnaire versions, the survey was designed to eliminate influences resulting from statements, behavioral framework, and the choice experiment. Results indicate the suitability of using Topic Modeling to extract information from open-ended responses; however, the models estimated using the closed-ended questions perform better compared to them. Besides, the proposed model performs better compared to the models used currently. Furthermore, our proposed framework will allow respondents to choose the questionnaire type to answer, which could be particularly beneficial to them when using voice-based surveys.
A novel evolutionary-based neuro-fuzzy task scheduling approach to jointly optimize the main design challenges of heterogeneous MPSoCs
Mar 14, 2022

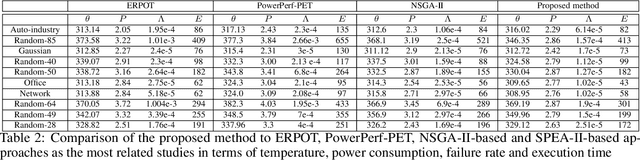
In this paper, an online task scheduling and mapping method based on a fuzzy neural network (FNN) learned by an evolutionary multi-objective algorithm (NSGA-II) to jointly optimize the main design challenges of heterogeneous MPSoCs is proposed. In this approach, first, the FNN parameters are trained using an NSGA-II-based optimization engine by considering the main design challenges of MPSoCs including temperature, power consumption, failure rate, and execution time on a training dataset consisting of different application graphs of various sizes. Next, the trained FNN is employed as an online task scheduler to jointly optimize the main design challenges in heterogeneous MPSoCs. Due to the uncertainty in sensor measurements and the difference between computational models and reality, applying the fuzzy neural network is advantageous in online scheduling procedures. The performance of the method is compared with some previous heuristic, meta-heuristic, and rule-based approaches in several experiments. Based on these experiments our proposed method outperforms the related studies in optimizing all design criteria. Its improvement over related heuristic and meta-heuristic approaches are estimated 10.58% in temperature, 9.22% in power consumption, 39.14% in failure rate, and 12.06% in execution time, averagely. Moreover, considering the interpretable nature of the FNN, the frequently fired extracted fuzzy rules of the proposed approach are demonstrated.
AutoMLBench: A Comprehensive Experimental Evaluation of Automated Machine Learning Frameworks
Apr 18, 2022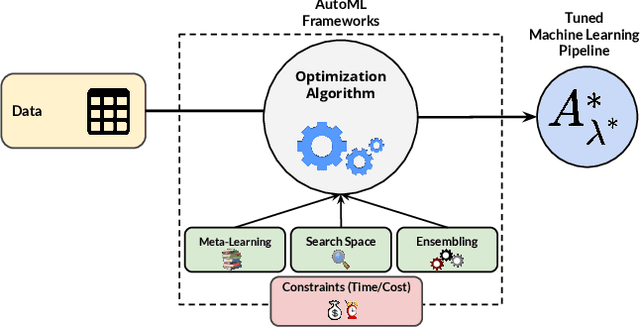
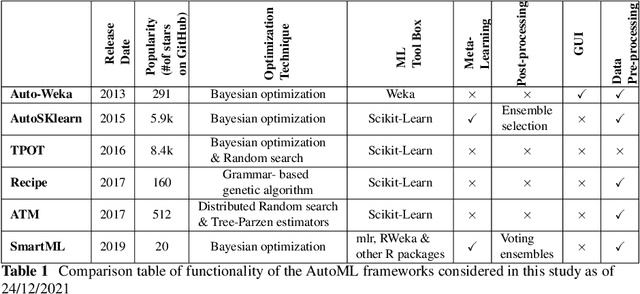
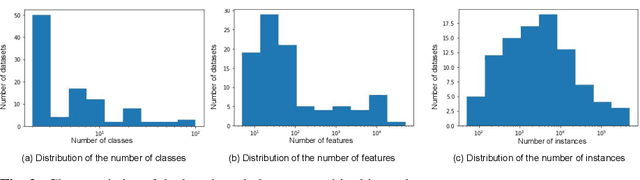
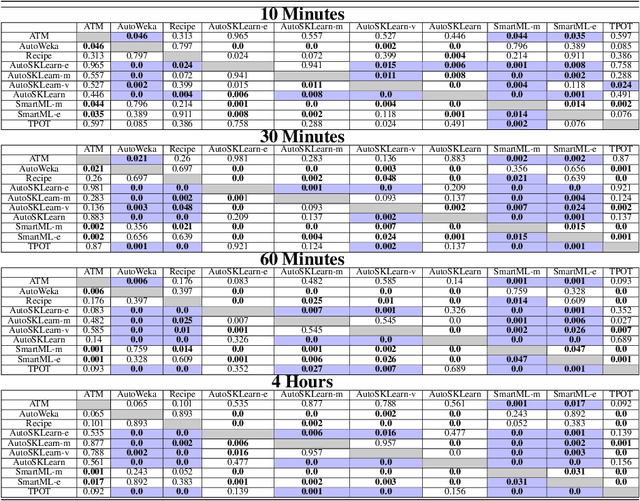
Nowadays, machine learning is playing a crucial role in harnessing the power of the massive amounts of data that we are currently producing every day in our digital world. With the booming demand for machine learning applications, it has been recognized that the number of knowledgeable data scientists can not scale with the growing data volumes and application needs in our digital world. In response to this demand, several automated machine learning (AutoML) techniques and frameworks have been developed to fill the gap of human expertise by automating the process of building machine learning pipelines. In this study, we present a comprehensive evaluation and comparison of the performance characteristics of six popular AutoML frameworks, namely, Auto-Weka, AutoSKlearn, TPOT, Recipe, ATM, and SmartML across 100 data sets from established AutoML benchmark suites. Our experimental evaluation considers different aspects for its comparison including the performance impact of several design decisions including time budget, size of search space, meta-learning, and ensemble construction. The results of our study reveal various interesting insights that can significantly guide and impact the design of AutoML frameworks.
On Negative Sampling for Audio-Visual Contrastive Learning from Movies
Apr 29, 2022
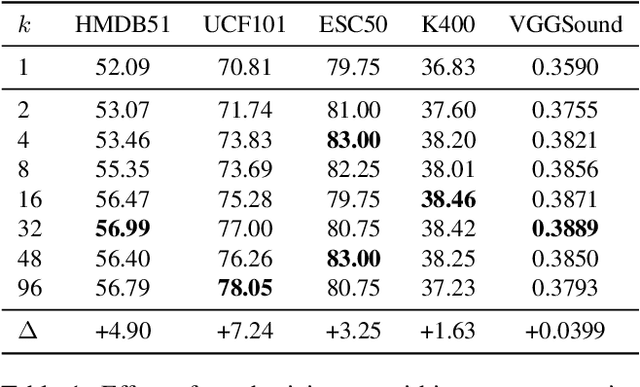
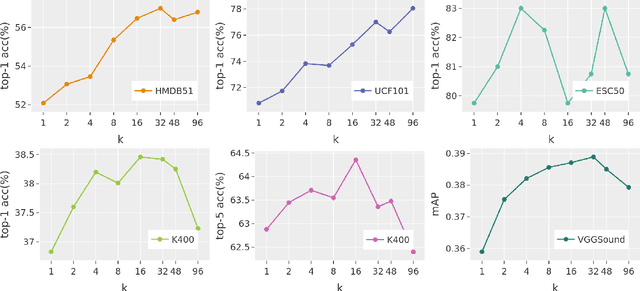
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal a plethora of information about what happens in a scene, make the audio-visual space an intuitive choice for representation learning. In this paper, we explore the efficacy of audio-visual self-supervised learning from uncurated long-form content i.e movies. Studying its differences with conventional short-form content, we identify a non-i.i.d distribution of data, driven by the nature of movies. Specifically, we find long-form content to naturally contain a diverse set of semantic concepts (semantic diversity), where a large portion of them, such as main characters and environments often reappear frequently throughout the movie (reoccurring semantic concepts). In addition, movies often contain content-exclusive artistic artifacts, such as color palettes or thematic music, which are strong signals for uniquely distinguishing a movie (non-semantic consistency). Capitalizing on these observations, we comprehensively study the effect of emphasizing within-movie negative sampling in a contrastive learning setup. Our view is different from those of prior works who consider within-video positive sampling, inspired by the notion of semantic persistency over time, and operate in a short-video regime. Our empirical findings suggest that, with certain modifications, training on uncurated long-form videos yields representations which transfer competitively with the state-of-the-art to a variety of action recognition and audio classification tasks.
Neural Time Warping For Multiple Sequence Alignment
Jun 29, 2020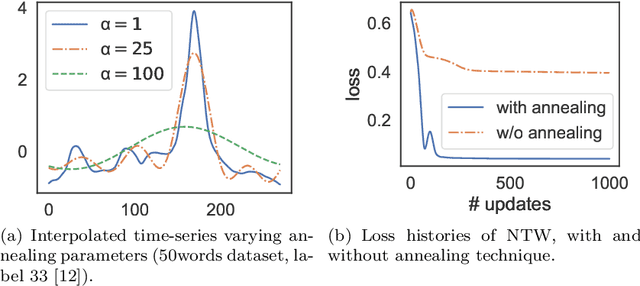
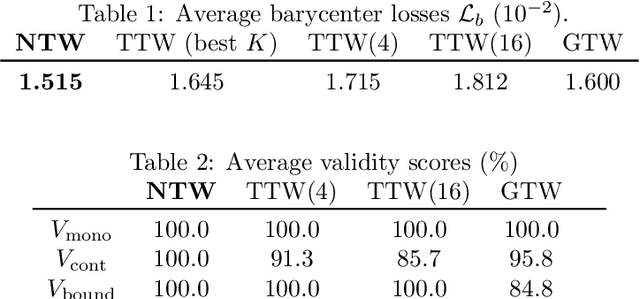
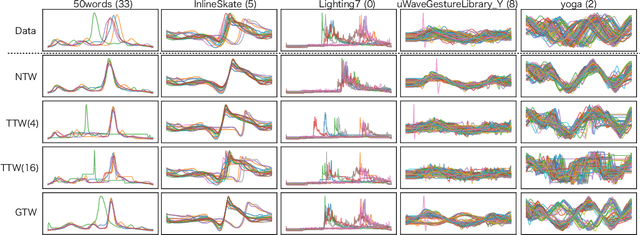
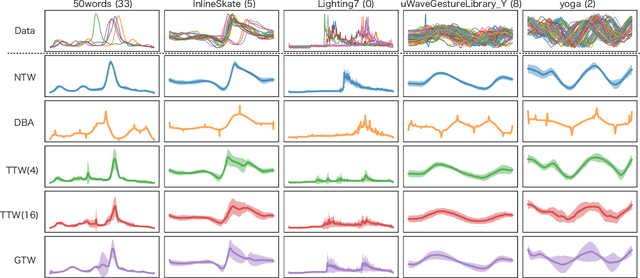
Multiple sequences alignment (MSA) is a traditional and challenging task for time-series analyses. The MSA problem is formulated as a discrete optimization problem and is typically solved by dynamic programming. However, the computational complexity increases exponentially with respect to the number of input sequences. In this paper, we propose neural time warping (NTW) that relaxes the original MSA to a continuous optimization and obtains the alignments using a neural network. The solution obtained by NTW is guaranteed to be a feasible solution for the original discrete optimization problem under mild conditions. Our experimental results show that NTW successfully aligns a hundred time-series and significantly outperforms existing methods for solving the MSA problem. In addition, we show a method for obtaining average time-series data as one of applications of NTW. Compared to the existing barycenters, the mean time series data retains the features of the input time-series data.
Tabular Transformers for Modeling Multivariate Time Series
Nov 03, 2020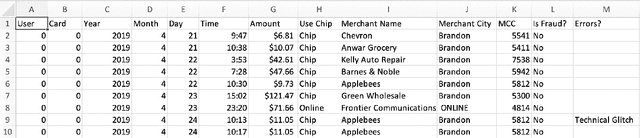

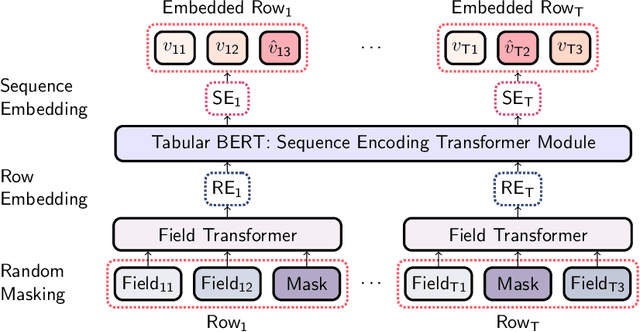
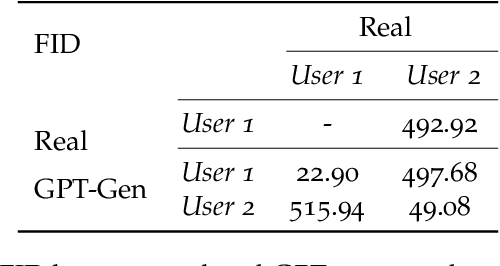
Tabular datasets are ubiquitous in data science applications. Given their importance, it seems natural to apply state-of-the-art deep learning algorithms in order to fully unlock their potential. Here we propose neural network models that represent tabular time series that can optionally leverage their hierarchical structure. This results in two architectures for tabular time series: one for learning representations that is analogous to BERT and can be pre-trained end-to-end and used in downstream tasks, and one that is akin to GPT and can be used for generation of realistic synthetic tabular sequences. We demonstrate our models on two datasets: a synthetic credit card transaction dataset, where the learned representations are used for fraud detection and synthetic data generation, and on a real pollution dataset, where the learned encodings are used to predict atmospheric pollutant concentrations. Code and data are available at https://github.com/IBM/TabFormer.
Progressive Distillation for Fast Sampling of Diffusion Models
Feb 01, 2022

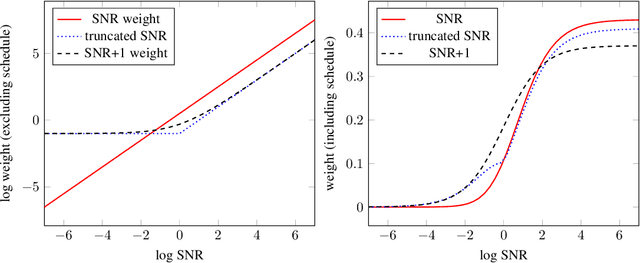
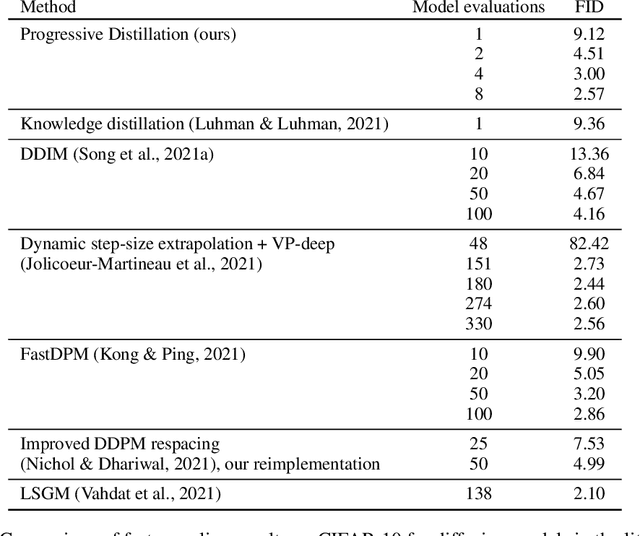
Diffusion models have recently shown great promise for generative modeling, outperforming GANs on perceptual quality and autoregressive models at density estimation. A remaining downside is their slow sampling time: generating high quality samples takes many hundreds or thousands of model evaluations. Here we make two contributions to help eliminate this downside: First, we present new parameterizations of diffusion models that provide increased stability when using few sampling steps. Second, we present a method to distill a trained deterministic diffusion sampler, using many steps, into a new diffusion model that takes half as many sampling steps. We then keep progressively applying this distillation procedure to our model, halving the number of required sampling steps each time. On standard image generation benchmarks like CIFAR-10, ImageNet, and LSUN, we start out with state-of-the-art samplers taking as many as 8192 steps, and are able to distill down to models taking as few as 4 steps without losing much perceptual quality; achieving, for example, a FID of 3.0 on CIFAR-10 in 4 steps. Finally, we show that the full progressive distillation procedure does not take more time than it takes to train the original model, thus representing an efficient solution for generative modeling using diffusion at both train and test time.
A Soft-Bodied Aerial Robot for Collision Resilience and Contact-Reactive Perching
May 02, 2022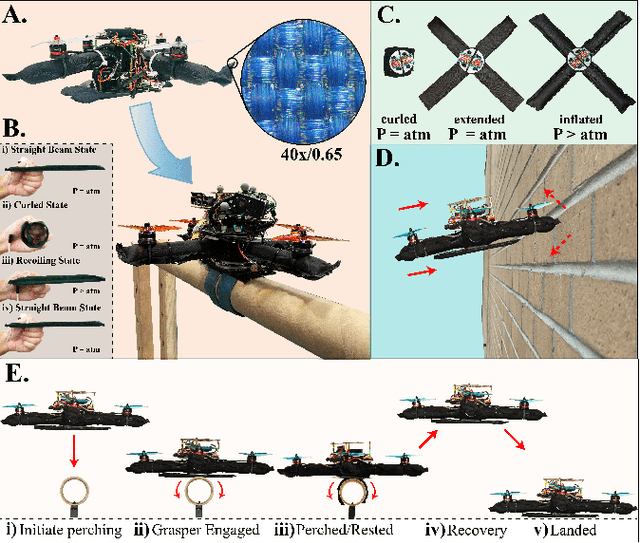
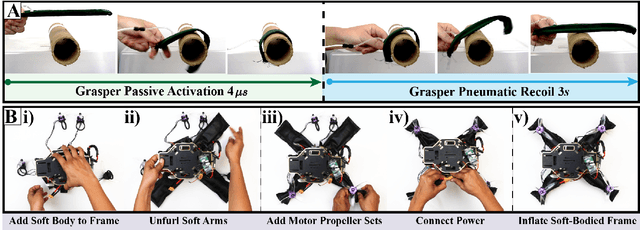
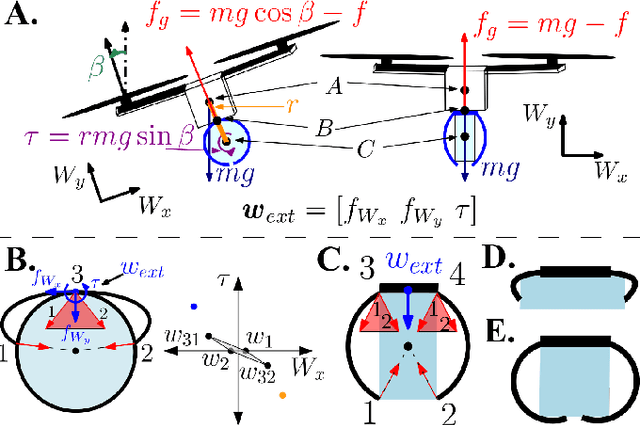

Compared to their biological counterparts, aerial robots demonstrate limited capabilities when tasked to interact in unstructured environments. Very often, the limitation lies in their inability to tolerate collisions and to successfully land, or perch, on objects of unknown shape. Over the past years, efforts to address this have introduced designs that incorporate mechanical impact protection and grasping/perching structures at the cost of reduced agility and flight time due to added weight and bulkiness. In this work, we develop a fabric-based, soft-bodied aerial robot (SoBAR) composed of both contact-reactive perching and embodied impact protection structures while remaining lightweight and streamlined. The robot is capable to 1) pneumatically vary its body stiffness for collision resilience and 2) utilize a hybrid fabric-based, bistable (HFB) grasper to perform passive grasping. When compared to conventional rigid drone frames the SoBAR successfully demonstrates its ability to dissipate impact from head-on collisions and maintain flight stability without any structural damage. Furthermore, in dynamic perching scenarios the HFB grasper is capable to convert impact energy upon contact into firm grasp through rapid body shape conforming in less than 4ms. We exhaustively study and offer insights for this novel perching scheme through grasping characterization, grasp wrench analysis, and experimental grasping validations in objects with various shapes. Finally, we demonstrate the complete control pipeline for SoBAR to approach an object, dynamically perch on it, recover from it, and land.
Multi-Scale Memory-Based Video Deblurring
Apr 06, 2022

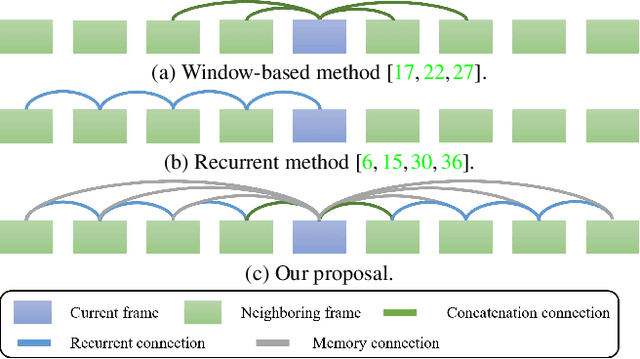

Video deblurring has achieved remarkable progress thanks to the success of deep neural networks. Most methods solve for the deblurring end-to-end with limited information propagation from the video sequence. However, different frame regions exhibit different characteristics and should be provided with corresponding relevant information. To achieve fine-grained deblurring, we designed a memory branch to memorize the blurry-sharp feature pairs in the memory bank, thus providing useful information for the blurry query input. To enrich the memory of our memory bank, we further designed a bidirectional recurrency and multi-scale strategy based on the memory bank. Experimental results demonstrate that our model outperforms other state-of-the-art methods while keeping the model complexity and inference time low. The code is available at https://github.com/jibo27/MemDeblur.