 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accelerated MRI With Deep Linear Convolutional Transform Learning
Apr 17, 2022
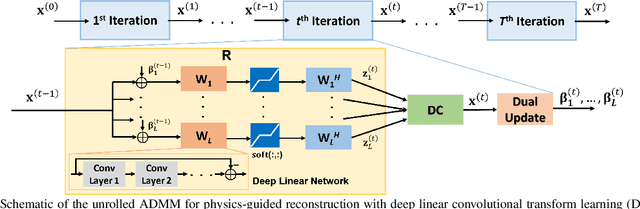
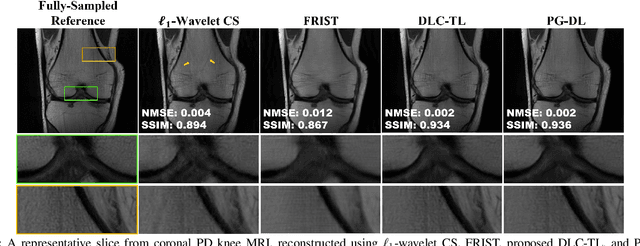
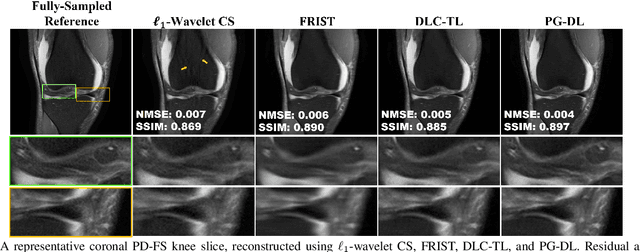
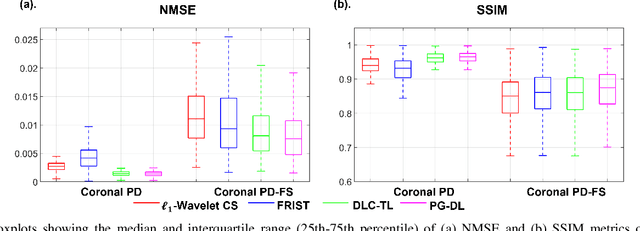
Recent studies show that deep learning (DL) based MRI reconstruction outperforms conventional methods, such as parallel imaging and compressed sensing (CS), in multiple applications. Unlike CS that is typically implemented with pre-determined linear representations for regularization, DL inherently uses a non-linear representation learned from a large database. Another line of work uses transform learning (TL) to bridge the gap between these two approaches by learning linear representations from data. In this work, we combine ideas from CS, TL and DL reconstructions to learn deep linear convolutional transforms as part of an algorithm unrolling approach. Using end-to-end training, our results show that the proposed technique can reconstruct MR images to a level comparable to DL methods, while supporting uniform undersampling patterns unlike conventional CS methods. Our proposed method relies on convex sparse image reconstruction with linear representation at inference time, which may be beneficial for characterizing robustness, stability and generalizability.
Temporal Modulation Network for Controllable Space-Time Video Super-Resolution
Apr 30, 2021
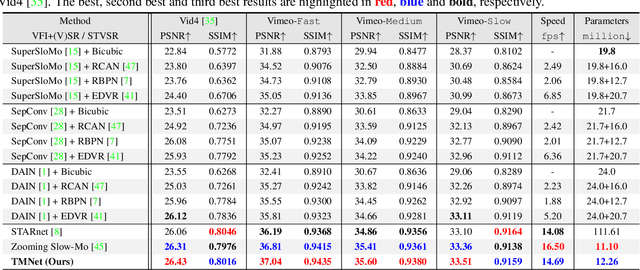
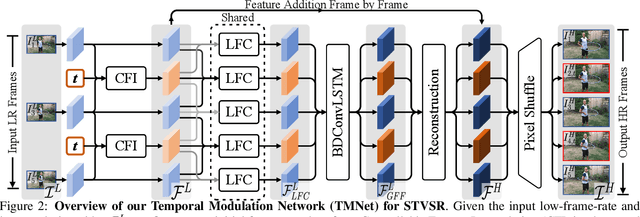
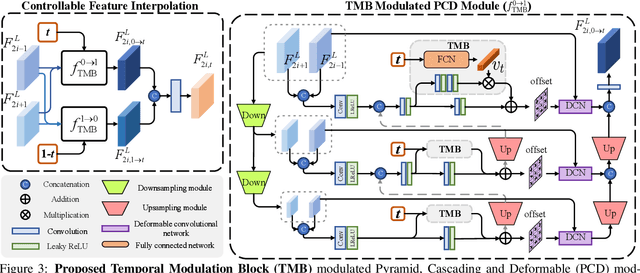
Space-time video super-resolution (STVSR) aims to increase the spatial and temporal resolutions of low-resolution and low-frame-rate videos. Recently, deformable convolution based methods have achieved promising STVSR performance, but they could only infer the intermediate frame pre-defined in the training stage. Besides, these methods undervalued the short-term motion cues among adjacent frames. In this paper, we propose a Temporal Modulation Network (TMNet) to interpolate arbitrary intermediate frame(s) with accurate high-resolution reconstruction. Specifically, we propose a Temporal Modulation Block (TMB) to modulate deformable convolution kernels for controllable feature interpolation. To well exploit the temporal information, we propose a Locally-temporal Feature Comparison (LFC) module, along with the Bi-directional Deformable ConvLSTM, to extract short-term and long-term motion cues in videos. Experiments on three benchmark datasets demonstrate that our TMNet outperforms previous STVSR methods. The code is available at https://github.com/CS-GangXu/TMNet.
A Comparative Evaluation of Machine Learning Algorithms for the Prediction of R/C Buildings' Seismic Damage
Mar 25, 2022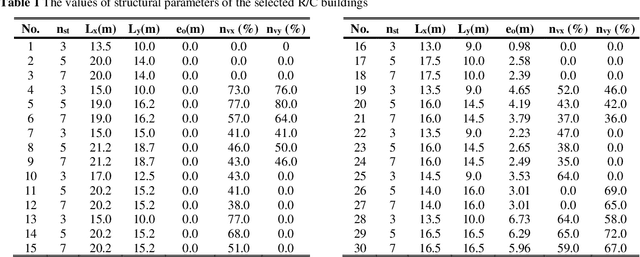
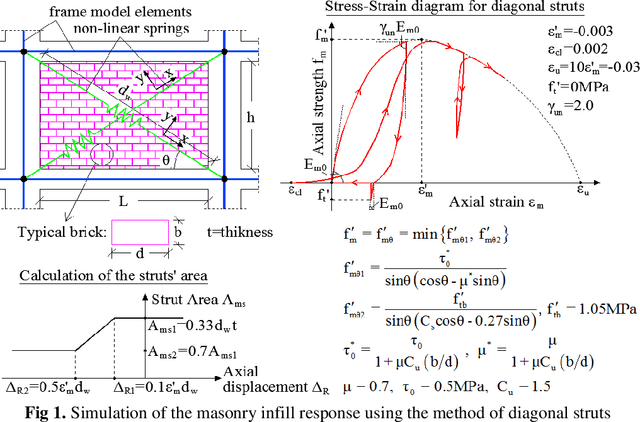
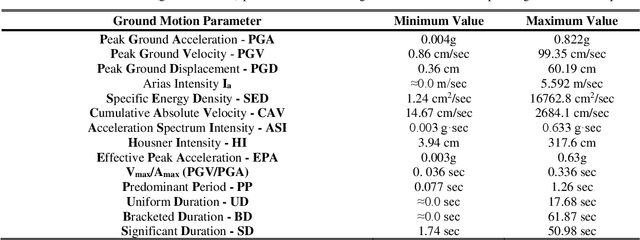
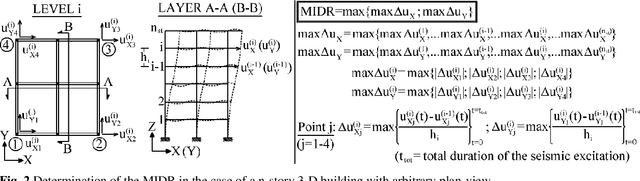
Seismic assessment of buildings and determination of their structural damage is at the forefront of modern scientific research. Since now, several researchers have proposed a number of procedures, in an attempt to estimate the damage response of the buildings subjected to strong ground motions, without conducting time-consuming analyses. These procedures, e.g. construction of fragility curves, usually utilize methods based on the application of statistical theory. In the last decades, the increase of the computers' power has led to the development of modern soft computing methods based on the adoption of Machine Learning algorithms. The present paper attempts an extensive comparative evaluation of the capability of various Machine Learning methods to adequately predict the seismic response of R/C buildings. The training dataset is created by means of Nonlinear Time History Analyses of 90 3D R/C buildings with three different masonry infills' distributions, which are subjected to 65 earthquakes. The seismic damage is expressed in terms of the Maximum Interstory Drift Ratio. A large-scale comparison study is utilized by the most efficient Machine Learning algorithms. The experimentation shows that the LightGBM approach produces training stability, high overall performance and a remarkable coefficient of determination to estimate the ability to predict the buildings' damage response. Due to the extremely urgent issue, civil protection mechanisms need to incorporate in their technological systems scientific methodologies and appropriate technical or modeling tools such as the proposed one, which can offer valuable assistance in making optimal decisions.
Size Generalization for Resource Allocation with Graph Neural Networks
Apr 29, 2022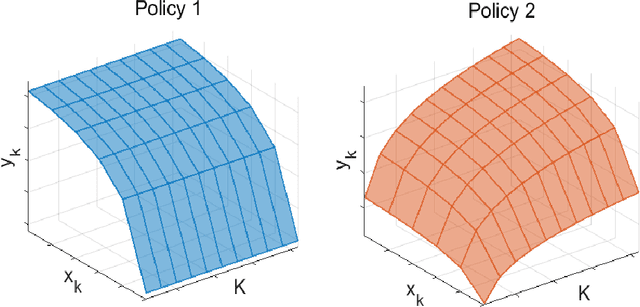
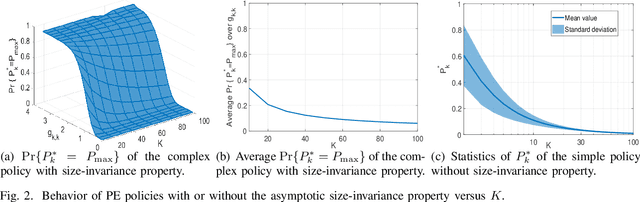
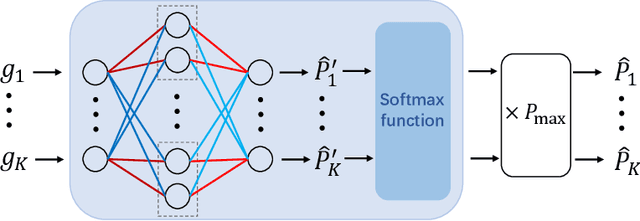
Size generalization is important for learning wireless policies, which are often with dynamic sizes, say caused by time-varying number of users. Recent works of learning to optimize resource allocation empirically demonstrate that graph neural networks (GNNs) can generalize to different problem scales. However, GNNs are not guaranteed to generalize across input sizes. In this paper, we strive to analyze the size generalization mechanism of GNNs when learning permutation equivariant (PE) policies. We find that the aggregation function and activation functions of a GNN play a key role on its size generalization ability. We take the GNN with mean aggregator, called mean-GNN, as an example to demonstrate a size generalization condition, and interpret why several GNNs in the literature of wireless communications can generalize well to problem scales. To illustrate how to design GNNs with size generalizability according to our finding, we consider power and bandwidth allocation, and suggest to select or pre-train activation function in the output layer of mean-GNN for learning the PE policies. Simulation results show that the proposed GNN can generalize well to the number of users, which validate our analysis for the size generalization condition of GNNs when learning the PE policies.
"My nose is running.""Are you also coughing?": Building A Medical Diagnosis Agent with Interpretable Inquiry Logics
Apr 29, 2022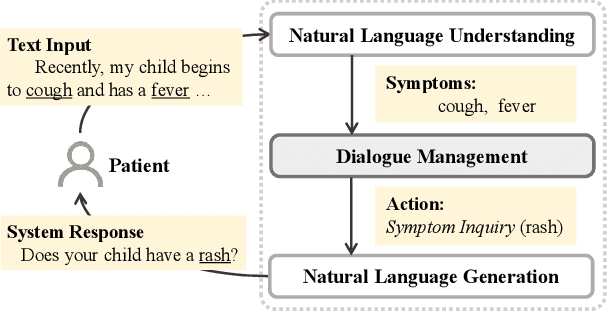
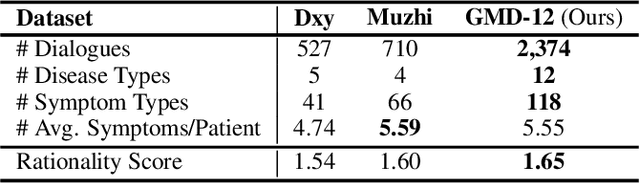
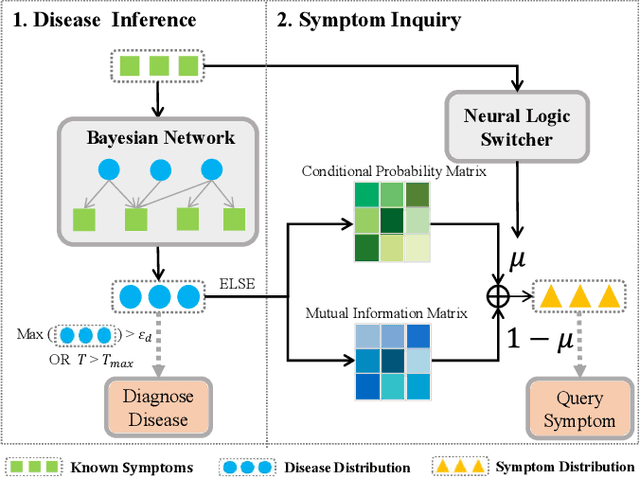
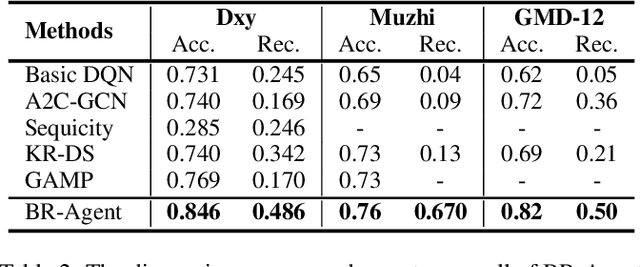
With the rise of telemedicine, the task of developing Dialogue Systems for Medical Diagnosis (DSMD) has received much attention in recent years. Different from early researches that needed to rely on extra human resources and expertise to help construct the system, recent researches focused on how to build DSMD in a purely data-driven manner. However, the previous data-driven DSMD methods largely overlooked the system interpretability, which is critical for a medical application, and they also suffered from the data sparsity issue at the same time. In this paper, we explore how to bring interpretability to data-driven DSMD. Specifically, we propose a more interpretable decision process to implement the dialogue manager of DSMD by reasonably mimicking real doctors' inquiry logics, and we devise a model with highly transparent components to conduct the inference. Moreover, we collect a new DSMD dataset, which has a much larger scale, more diverse patterns and is of higher quality than the existing ones. The experiments show that our method obtains 7.7%, 10.0%, 3.0% absolute improvement in diagnosis accuracy respectively on three datasets, demonstrating the effectiveness of its rational decision process and model design. Our codes and the GMD-12 dataset are available at https://github.com/lwgkzl/BR-Agent.
Computational behavior recognition in child and adolescent psychiatry: A statistical and machine learning analysis plan
May 11, 2022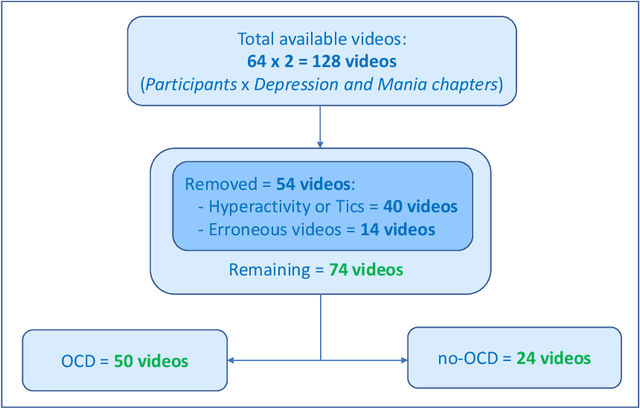
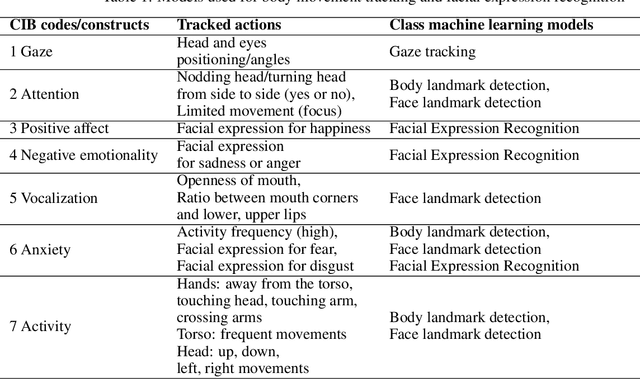
Motivation: Behavioral observations are an important resource in the study and evaluation of psychological phenomena, but it is costly, time-consuming, and susceptible to bias. Thus, we aim to automate coding of human behavior for use in psychotherapy and research with the help of artificial intelligence (AI) tools. Here, we present an analysis plan. Methods: Videos of a gold-standard semi-structured diagnostic interview of 25 youth with obsessive-compulsive disorder (OCD) and 12 youth without a psychiatric diagnosis (no-OCD) will be analyzed. Youth were between 8 and 17 years old. Features from the videos will be extracted and used to compute ratings of behavior, which will be compared to ratings of behavior produced by mental health professionals trained to use a specific behavioral coding manual. We will test the effect of OCD diagnosis on the computationally-derived behavior ratings using multivariate analysis of variance (MANOVA). Using the generated features, a binary classification model will be built and used to classify OCD/no-OCD classes. Discussion: Here, we present a pre-defined plan for how data will be pre-processed, analyzed and presented in the publication of results and their interpretation. A challenge for the proposed study is that the AI approach will attempt to derive behavioral ratings based solely on vision, whereas humans use visual, paralinguistic and linguistic cues to rate behavior. Another challenge will be using machine learning models for body and facial movement detection trained primarily on adults and not on children. If the AI tools show promising results, this pre-registered analysis plan may help reduce interpretation bias. Trial registration: ClinicalTrials.gov - H-18010607
Innovations in trigger and data acquisition systems for next-generation physics facilities
Mar 17, 2022Data-intensive physics facilities are increasingly reliant on heterogeneous and large-scale data processing and computational systems in order to collect, distribute, process, filter, and analyze the ever increasing huge volumes of data being collected. Moreover, these tasks are often performed in hard real-time or quasi real-time processing pipelines that place extreme constraints on various parameters and design choices for those systems. Consequently, a large number and variety of challenges are faced to design, construct, and operate such facilities. This is especially true at the energy and intensity frontiers of particle physics where bandwidths of raw data can exceed 100 TB/s of heterogeneous, high-dimensional data sourced from 300M+ individual sensors. Data filtering and compression algorithms deployed at these facilities often operate at the level of 1 part in $10^5$, and once executed, these algorithms drive the data curation process, further highlighting the critical roles that these systems have in the physics impact of those endeavors. This White Paper aims to highlight the challenges that these facilities face in the design of the trigger and data acquisition instrumentation and systems, as well as in their installation, commissioning, integration and operation, and in building the domain knowledge and technical expertise required to do so.
Autoregressive based Drift Detection Method
Mar 09, 2022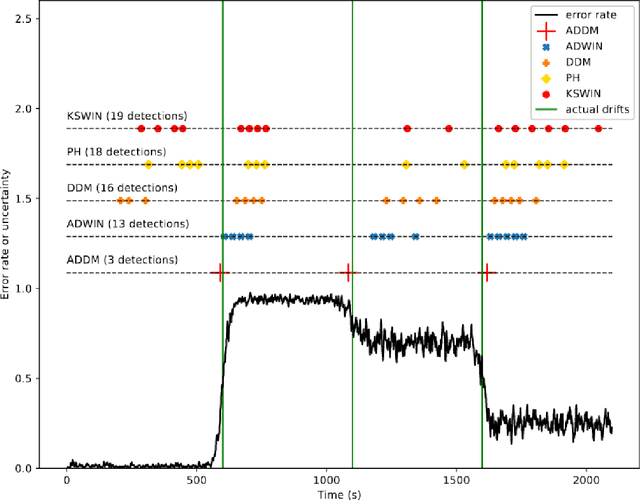
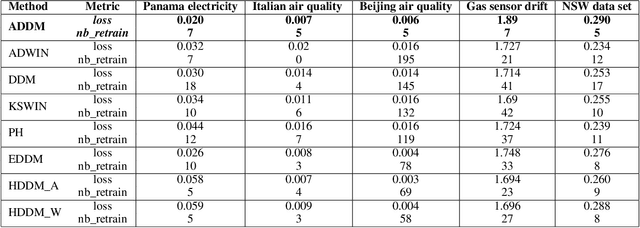
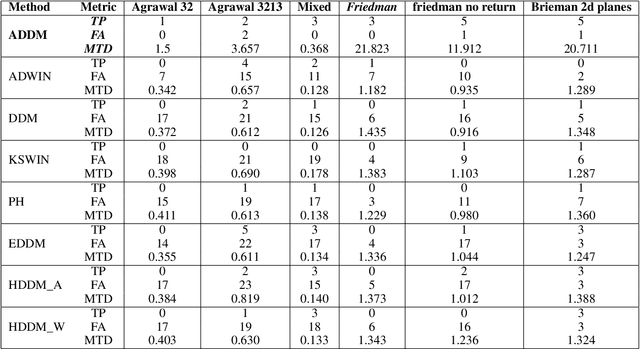
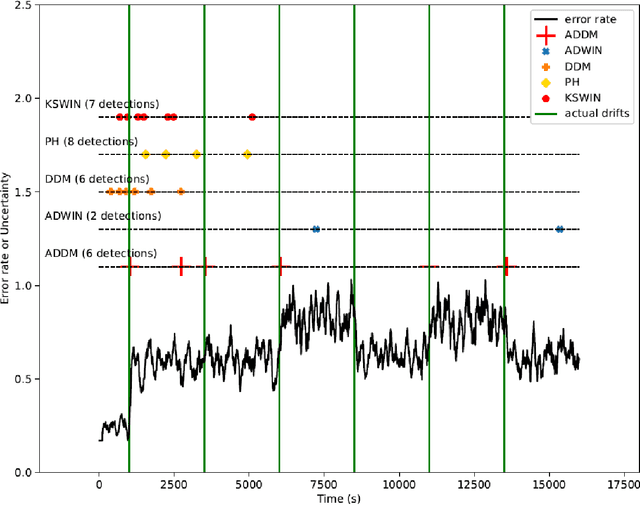
In the classic machine learning framework, models are trained on historical data and used to predict future values. It is assumed that the data distribution does not change over time (stationarity). However, in real-world scenarios, the data generation process changes over time and the model has to adapt to the new incoming data. This phenomenon is known as concept drift and leads to a decrease in the predictive model's performance. In this study, we propose a new concept drift detection method based on autoregressive models called ADDM. This method can be integrated into any machine learning algorithm from deep neural networks to simple linear regression model. Our results show that this new concept drift detection method outperforms the state-of-the-art drift detection methods, both on synthetic data sets and real-world data sets. Our approach is theoretically guaranteed as well as empirical and effective for the detection of various concept drifts. In addition to the drift detector, we proposed a new method of concept drift adaptation based on the severity of the drift.
Localizing the Vehicle's Antenna: an Open Problem in 6G Network Sensing
Apr 03, 2022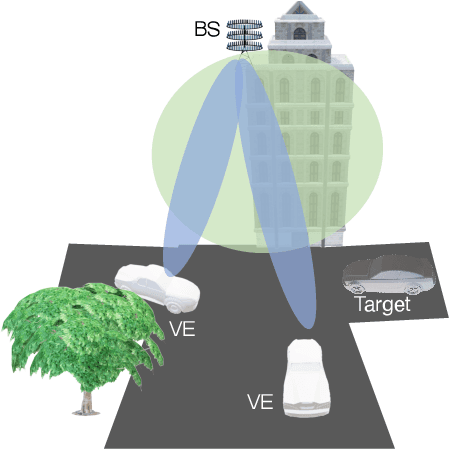
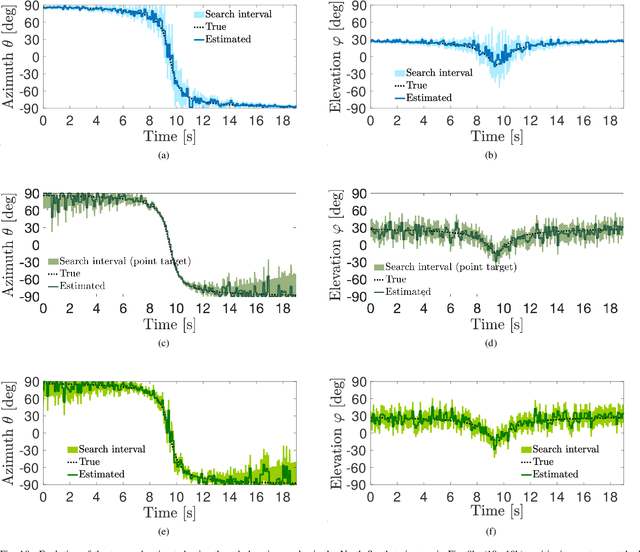
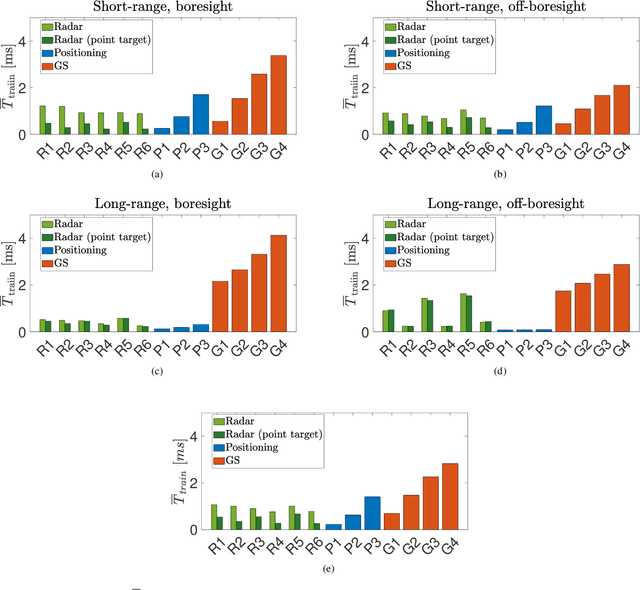
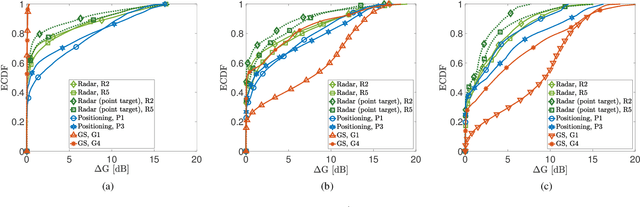
Millimeter Waves (mmW) and sub-THz frequencies are the candidate bands for the upcoming Sixth Generation (6G) of communication systems. The use of collimated beams at mmW/sub-THz to compensate for the increased path and penetration loss arises the need for a seamless Beam Management (BM), especially for high mobility scenarios such as the Vehicle-to-Infrastructure (V2I) one. Recent research advances in Integrated Sensing and Communication (ISAC) indicate that equipping the network infrastructure, e.g., the Base Station (BS), with either a stand-alone radar or sensing capabilities using optimized waveforms, represents the killer technology to facilitate the BM. However, radio sensing should accurately localize the Vehicular Equipment (VE)'s antenna, which is not guaranteed in general. Differently, employing side information from VE's onboard positioning sensors might overcome this limitation at the price of an increased control signaling between VE and BS. This paper provides a pragmatic comparison between radar-assisted and position-assisted BM for mmW V2I systems in a typical urban scenario in terms of BM training time and beamforming gain loss due to a wrong BM decision. Simulation results, supported by experimental evidence, show that the point target approximation of a traveling VE does not hold in practical V2I scenarios with radar-equipped BS. Therefore, the true antenna position has a residual uncertainty that is independent of radar's resolution and implies 50\,\% more BM training time on average. Moreover, there is not a winning technology for BM between BS-mounted radar and VE's onboard positioning systems. They provide complementary performance, depending on position, although outperforming blind BM techniques compared to conventional blind methods. Thus, we propose to optimally combine radar and positioning information in a multi-technology integrated BM solution.
Single UHD Image Dehazing via Interpretable Pyramid Network
Feb 17, 2022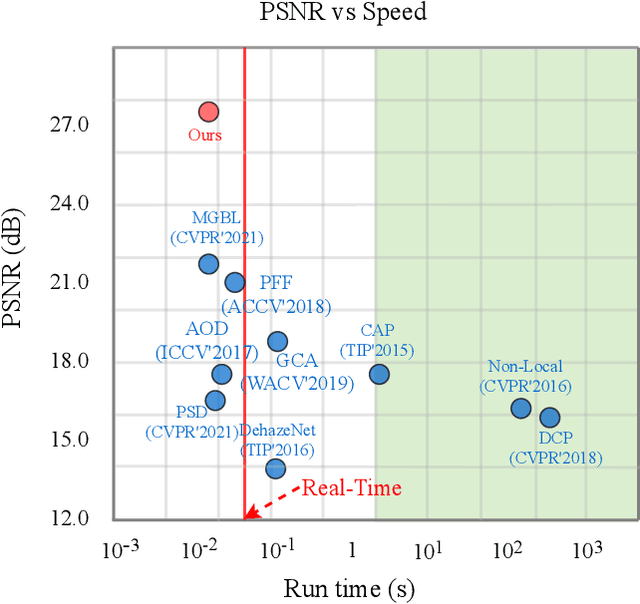

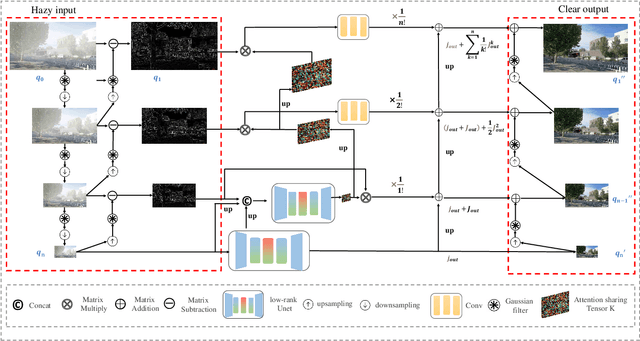

Currently, most single image dehazing models cannot run an ultra-high-resolution (UHD) image with a single GPU shader in real-time. To address the problem, we introduce the principle of infinite approximation of Taylor's theorem with the Laplace pyramid pattern to build a model which is capable of handling 4K hazy images in real-time. The N branch networks of the pyramid network correspond to the N constraint terms in Taylor's theorem. Low-order polynomials reconstruct the low-frequency information of the image (e.g. color, illumination). High-order polynomials regress the high-frequency information of the image (e.g. texture). In addition, we propose a Tucker reconstruction-based regularization term that acts on each branch network of the pyramid model. It further constrains the generation of anomalous signals in the feature space. Extensive experimental results demonstrate that our approach can not only run 4K images with haze in real-time on a single GPU (80FPS) but also has unparalleled interpretability. The developed method achieves state-of-the-art (SOTA) performance on two benchmarks (O/I-HAZE) and our updated 4KID dataset while providing the reliable groundwork for subsequent optimization schemes.