 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Usage-based learning of grammatical categories
Apr 14, 2022
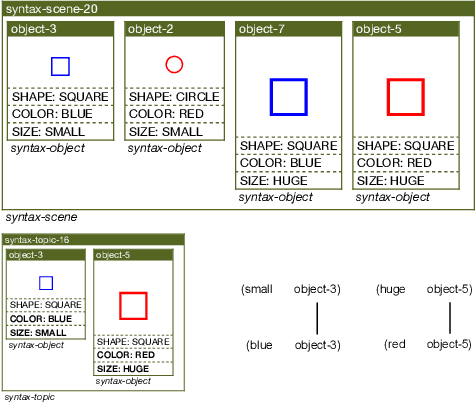
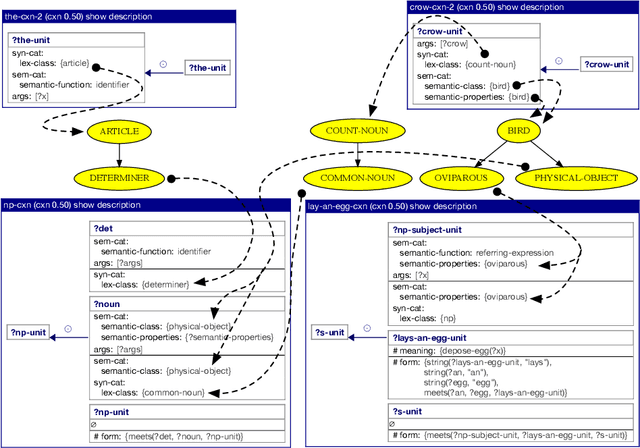
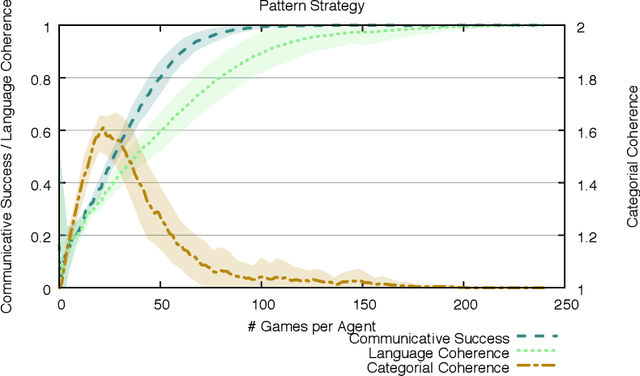
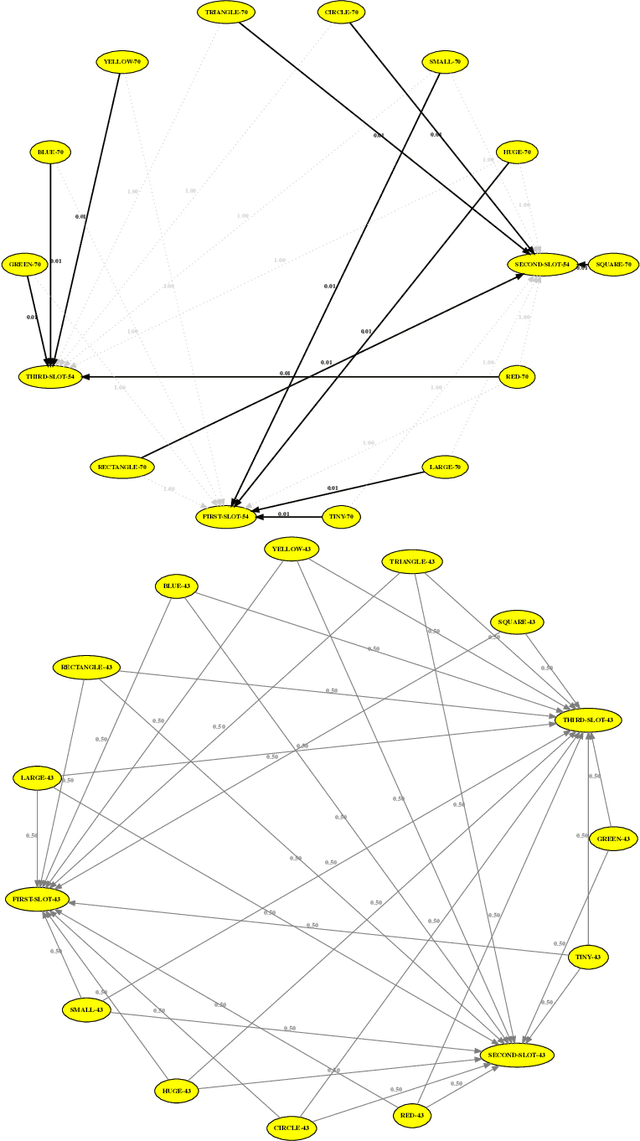
Human languages use a wide range of grammatical categories to constrain which words or phrases can fill certain slots in grammatical patterns and to express additional meanings, such as tense or aspect, through morpho-syntactic means. These grammatical categories, which are most often language-specific and changing over time, are difficult to define and learn. This paper raises the question how these categories can be acquired and where they have come from. We explore a usage-based approach. This means that categories and grammatical constructions are selected and aligned by their success in language interactions. We report on a multi-agent experiment in which agents are endowed with mechanisms for understanding and producing utterances as well as mechanisms for expanding their inventories using a meta-level learning process based on pro- and anti-unification. We show that a categorial type network which has scores based on the success in a language interaction leads to the spontaneous formation of grammatical categories in tandem with the formation of grammatical patterns.
* Published after double-blind review as: Steels, L., Van Eecke, P. & Beuls, K. (2018). Usage-based learning of grammatical categories. Belgian/Netherlands Artificial Intelligence Conference (BNAIC) 2018 Preproceedings (pp. 253-264)
Visual-Inertial Odometry with Online Calibration of Velocity-Control Based Kinematic Motion Models
Apr 14, 2022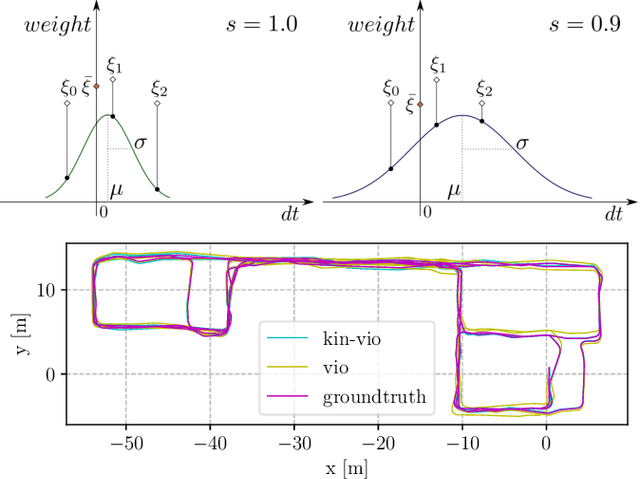
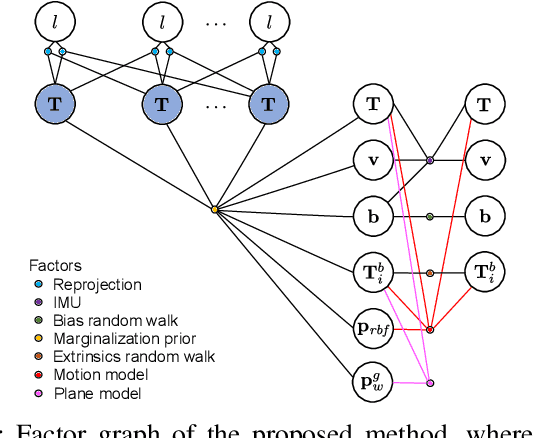

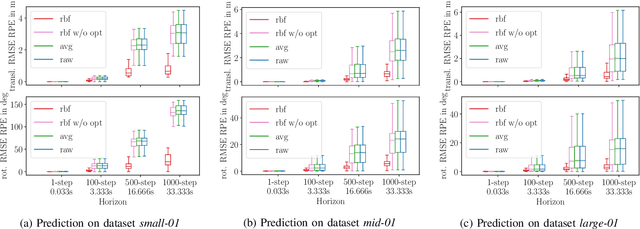
Visual-inertial odometry (VIO) is an important technology for autonomous robots with power and payload constraints. In this paper, we propose a novel approach for VIO with stereo cameras which integrates and calibrates the velocity-control based kinematic motion model of wheeled mobile robots online. Including such a motion model can help to improve the accuracy of VIO. Compared to several previous approaches proposed to integrate wheel odometer measurements for this purpose, our method does not require wheel encoders and can be applied when the robot motion can be modeled with velocity-control based kinematic motion model. We use radial basis function (RBF) kernels to compensate for the time delay and deviations between control commands and actual robot motion. The motion model is calibrated online by the VIO system and can be used as a forward model for motion control and planning. We evaluate our approach with data obtained in variously sized indoor environments, demonstrate improvements over a pure VIO method, and evaluate the prediction accuracy of the online calibrated model.
Internet-augmented language models through few-shot prompting for open-domain question answering
Mar 10, 2022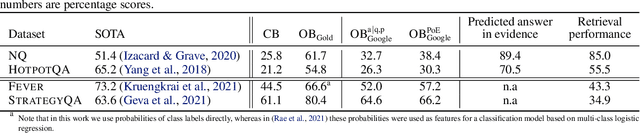
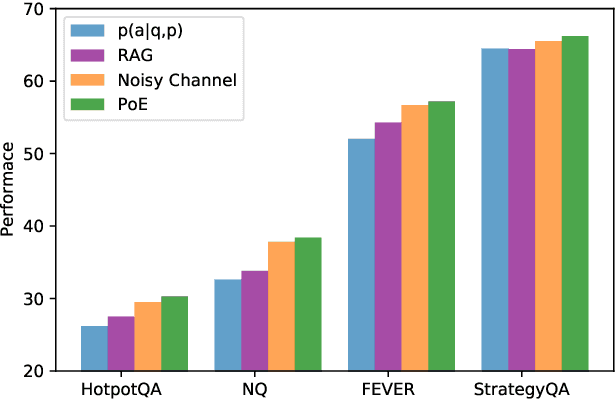
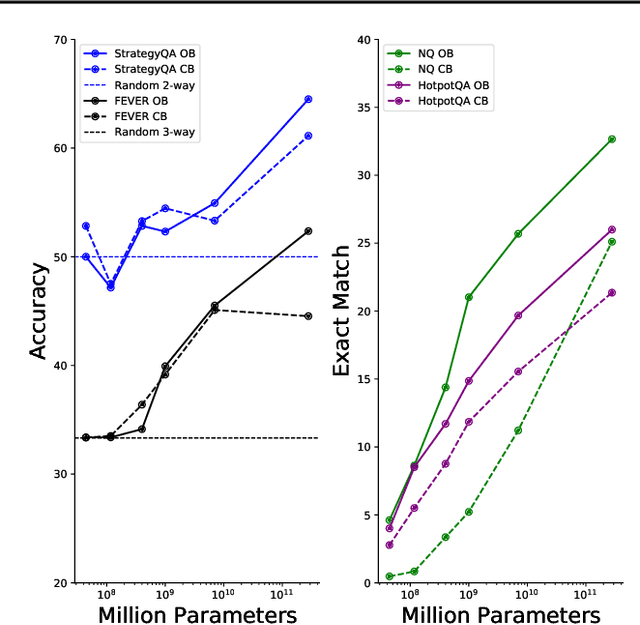
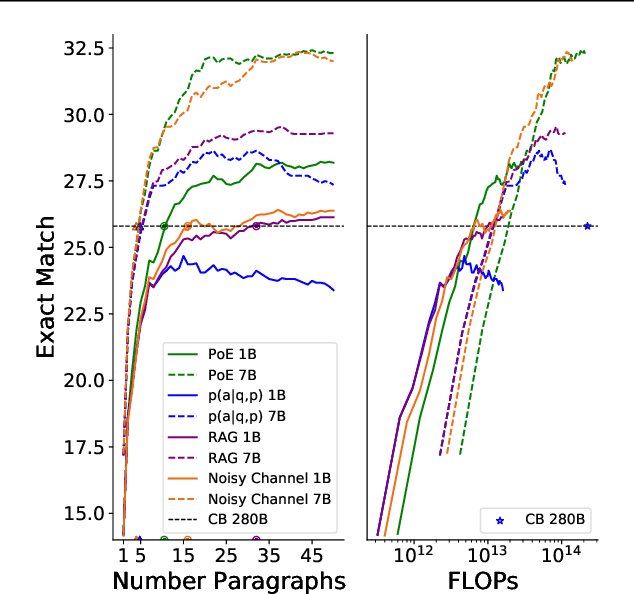
In this work, we aim to capitalize on the unique few-shot capabilities offered by large-scale language models to overcome some of their challenges with respect to grounding to factual and up-to-date information. Motivated by semi-parametric language models, which ground their decisions in external retrieved evidence, we use few-shot prompting to learn to condition language models on information returned from the web using Google Search, a broad and constantly updated knowledge source. Our approach does not involve fine-tuning or learning additional parameters, thus making it applicable to any language model, offering like this a strong baseline. Indeed, we find that language models conditioned on the web surpass performance of closed-book models of similar, or even larger, model sizes in open-domain question answering. Finally, we find that increasing the inference-time compute of models, achieved via using multiple retrieved evidences to generate multiple answers followed by a reranking stage, alleviates generally decreased performance of smaller few-shot language models. All in all, our findings suggest that it might be beneficial to slow down the race towards the biggest model and instead shift the attention towards finding more effective ways to use models, including but not limited to better prompting or increasing inference-time compute.
Shape Prior Non-Uniform Sampling Guided Real-time Stereo 3D Object Detection
Jun 21, 2021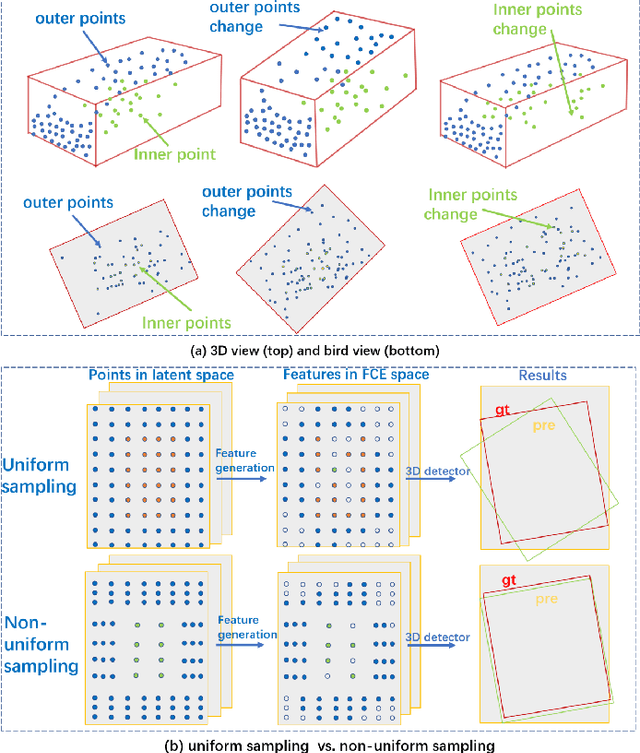
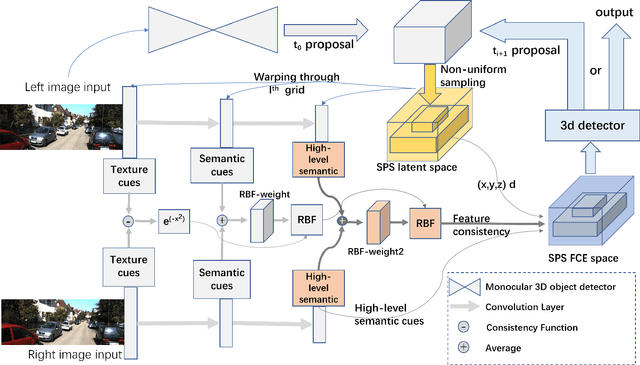
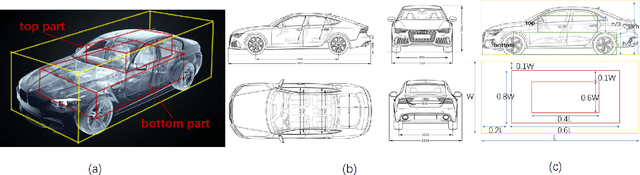
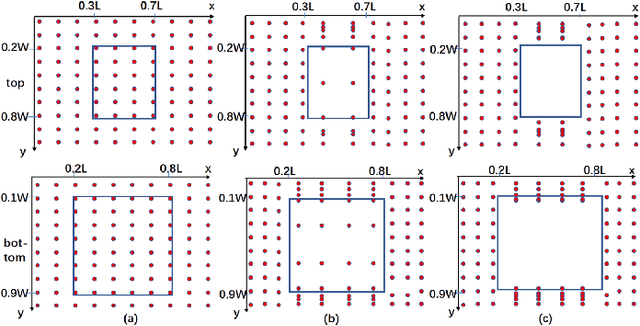
Pseudo-LiDAR based 3D object detectors have gained popularity due to their high accuracy. However, these methods need dense depth supervision and suffer from inferior speed. To solve these two issues, a recently introduced RTS3D builds an efficient 4D Feature-Consistency Embedding (FCE) space for the intermediate representation of object without depth supervision. FCE space splits the entire object region into 3D uniform grid latent space for feature sampling point generation, which ignores the importance of different object regions. However, we argue that, compared with the inner region, the outer region plays a more important role for accurate 3D detection. To encode more information from the outer region, we propose a shape prior non-uniform sampling strategy that performs dense sampling in outer region and sparse sampling in inner region. As a result, more points are sampled from the outer region and more useful features are extracted for 3D detection. Further, to enhance the feature discrimination of each sampling point, we propose a high-level semantic enhanced FCE module to exploit more contextual information and suppress noise better. Experiments on the KITTI dataset are performed to show the effectiveness of the proposed method. Compared with the baseline RTS3D, our proposed method has 2.57% improvement on AP3d almost without extra network parameters. Moreover, our proposed method outperforms the state-of-the-art methods without extra supervision at a real-time speed.
An untrained deep learning method for reconstructing dynamic magnetic resonance images from accelerated model-based data
May 04, 2022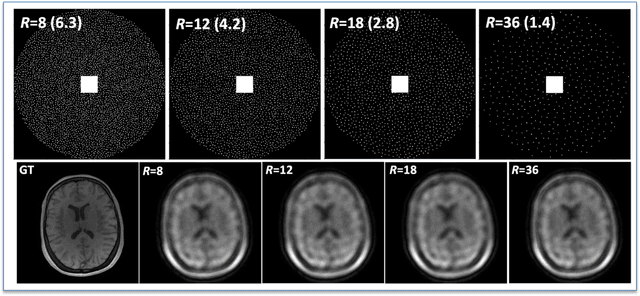
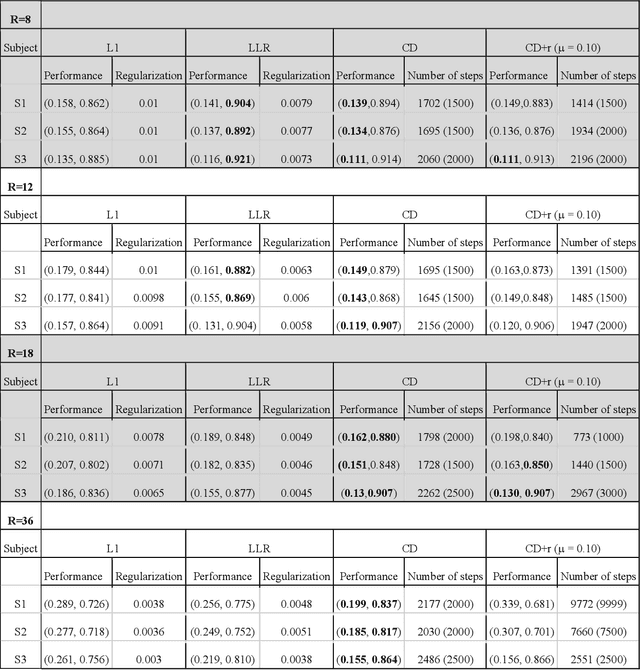
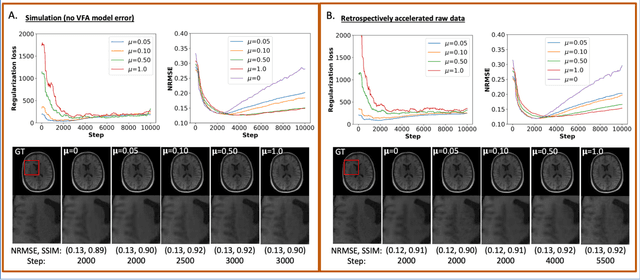
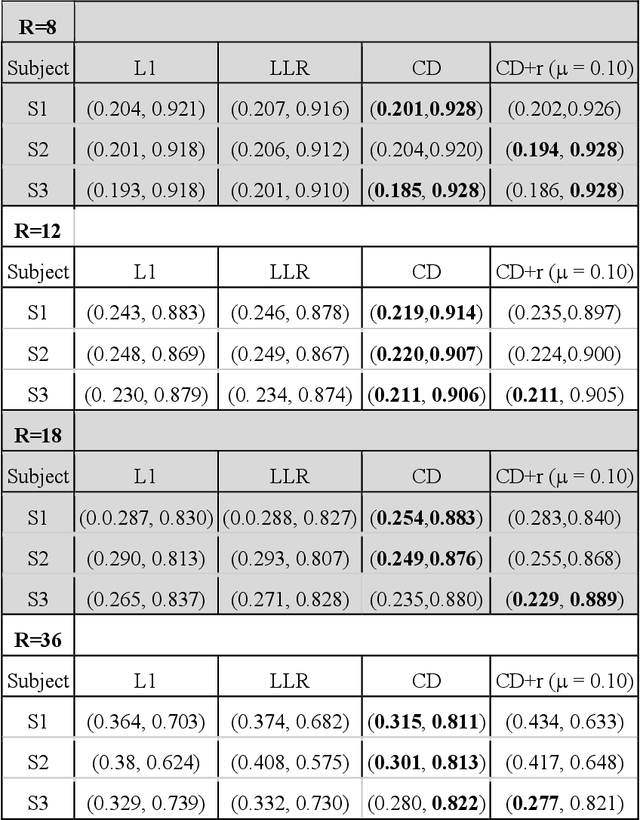
The purpose of this work is to implement physics-based regularization as a stopping condition in tuning an untrained deep neural network for reconstructing MR images from accelerated data. The ConvDecoder neural network was trained with a physics-based regularization term incorporating the spoiled gradient echo equation that describes variable-flip angle (VFA) data. Fully-sampled VFA k-space data were retrospectively accelerated by factors of R={8,12,18,36} and reconstructed with ConvDecoder (CD), ConvDecoder with the proposed regularization (CD+r), locally low-rank (LR) reconstruction, and compressed sensing with L1-wavelet regularization (L1). Final images from CD+r training were evaluated at the \emph{argmin} of the regularization loss; whereas the CD, LR, and L1 reconstructions were chosen optimally based on ground truth data. The performance measures used were the normalized root-mean square error, the concordance correlation coefficient (CCC), and the structural similarity index (SSIM). The CD+r reconstructions, chosen using the stopping condition, yielded SSIMs that were similar to the CD (p=0.47) and LR SSIMs (p=0.95) across R and that were significantly higher than the L1 SSIMs (p=0.04). The CCC values for the CD+r T1 maps across all R and subjects were greater than those corresponding to the L1 (p=0.15) and LR (p=0.13) T1 maps, respectively. For R > 12 (<4.2 minutes scan time), L1 and LR T1 maps exhibit a loss of spatially refined details compared to CD+r. We conclude that the use of an untrained neural network together with a physics-based regularization loss shows promise as a measure for determining the optimal stopping point in training without relying on fully-sampled ground truth data.
Algorithms and Theory for Supervised Gradual Domain Adaptation
Apr 25, 2022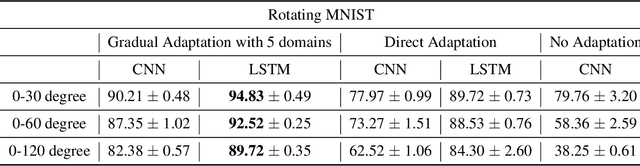
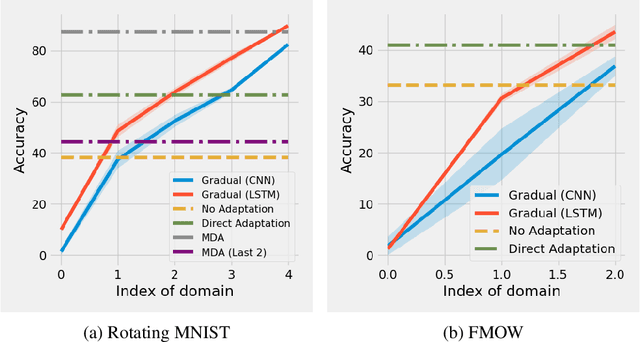
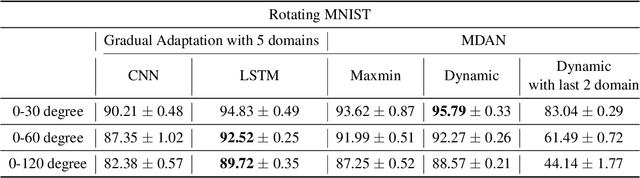
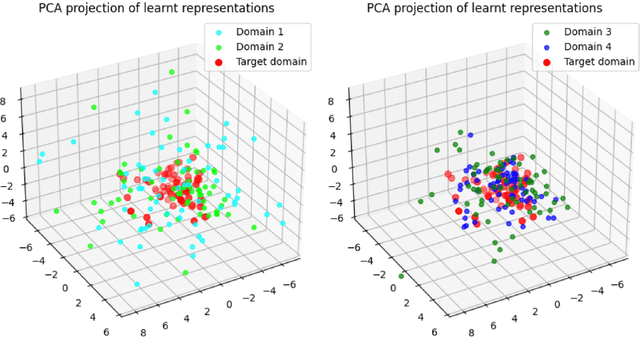
The phenomenon of data distribution evolving over time has been observed in a range of applications, calling the needs of adaptive learning algorithms. We thus study the problem of supervised gradual domain adaptation, where labeled data from shifting distributions are available to the learner along the trajectory, and we aim to learn a classifier on a target data distribution of interest. Under this setting, we provide the first generalization upper bound on the learning error under mild assumptions. Our results are algorithm agnostic, general for a range of loss functions, and only depend linearly on the averaged learning error across the trajectory. This shows significant improvement compared to the previous upper bound for unsupervised gradual domain adaptation, where the learning error on the target domain depends exponentially on the initial error on the source domain. Compared with the offline setting of learning from multiple domains, our results also suggest the potential benefits of the temporal structure among different domains in adapting to the target one. Empirically, our theoretical results imply that learning proper representations across the domains will effectively mitigate the learning errors. Motivated by these theoretical insights, we propose a min-max learning objective to learn the representation and classifier simultaneously. Experimental results on both semi-synthetic and large-scale real datasets corroborate our findings and demonstrate the effectiveness of our objectives.
A Fast Edge-Based Synchronizer for Tasks in Real-Time Artificial Intelligence Applications
Dec 21, 2020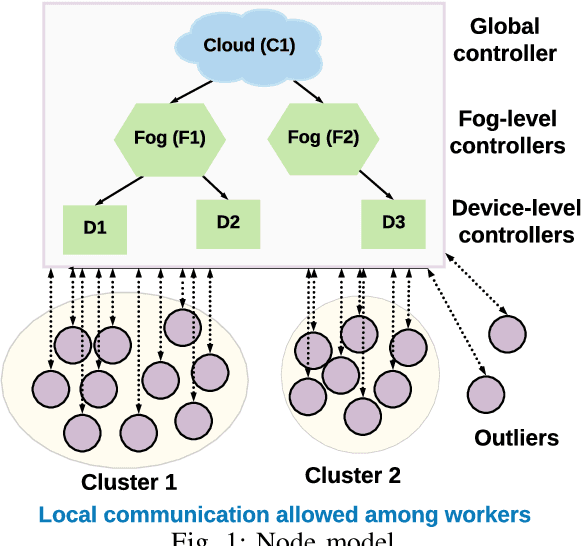
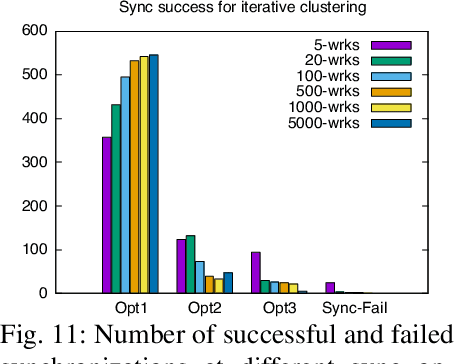
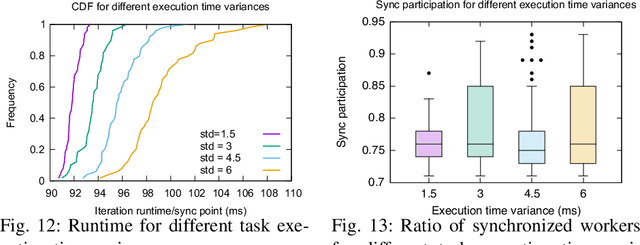
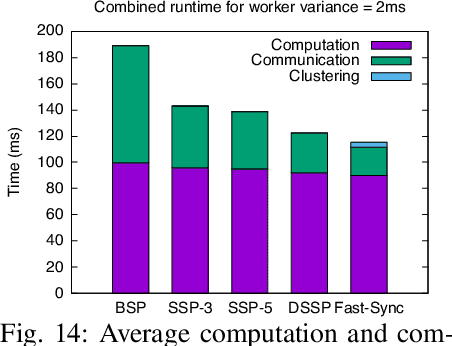
Real-time artificial intelligence (AI) applications mapped onto edge computing need to perform data capture, process data, and device actuation within given bounds while using the available devices. Task synchronization across the devices is an important problem that affects the timely progress of an AI application by determining the quality of the captured data, time to process the data, and the quality of actuation. In this paper, we develop a fast edge-based synchronization scheme that can time align the execution of input-output tasks as well compute tasks. The primary idea of the fast synchronizer is to cluster the devices into groups that are highly synchronized in their task executions and statically determine few synchronization points using a game-theoretic solver. The cluster of devices use a late notification protocol to select the best point among the pre-computed synchronization points to reach a time aligned task execution as quickly as possible. We evaluate the performance of our synchronization scheme using trace-driven simulations and we compare the performance with existing distributed synchronization schemes for real-time AI application tasks. We implement our synchronization scheme and compare its training accuracy and training time with other parameter server synchronization frameworks.
Learning Efficient Exploration through Human Seeded Rapidly-exploring Random Trees
Mar 23, 2022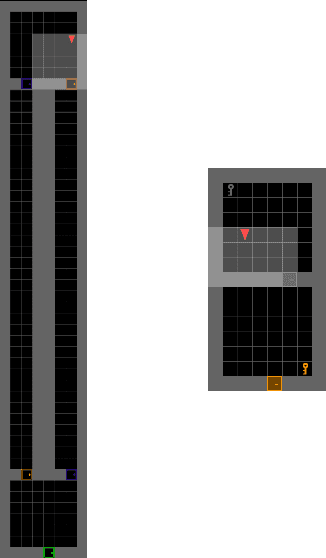
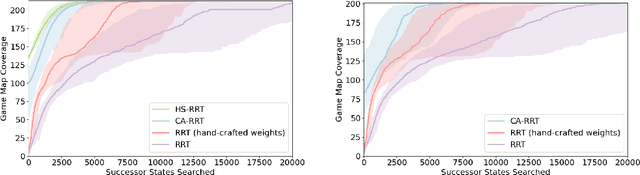
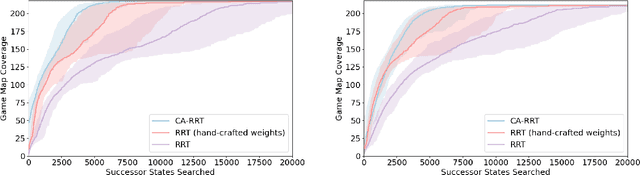
Modern day computer games have extremely large state and action spaces. To detect bugs in these games' models, human testers play the games repeatedly to explore the game and find errors in the games. Such game play is exhaustive and time consuming. Moreover, since robotics simulators depend on similar methods of model specification and debugging, the problem of finding errors in the model is of interest for the robotics community to ensure robot behaviors and interactions are consistent in simulators. Previous methods have used reinforcement learning and search based methods including Rapidly-exploring Random Trees (RRT) to explore a game's state-action space to find bugs. However, such search and exploration based methods are not efficient at exploring the state-action space without a pre-defined heuristic. In this work we attempt to combine a human-tester's expertise in solving games, and the exhaustiveness of RRT to search a game's state space efficiently with high coverage. This paper introduces human-seeded RRT (HS-RRT) and behavior-cloning-assisted RRT (CA-RRT) in testing the number of game states searched and the time taken to explore those game states. We compare our methods to an existing weighted RRT baseline for game exploration testing studied. We find HS-RRT and CA-RRT both explore more game states in fewer tree expansions/iterations when compared to the existing baseline. In each test, CA-RRT reached more states on average in the same number of iterations as RRT. In our tested environments, CA-RRT was able to reach the same number of states as RRT by more than 5000 fewer iterations on average, almost a 50% reduction.
Near-Field Rainbow: Wideband Beam Training for XL-MIMO
May 07, 2022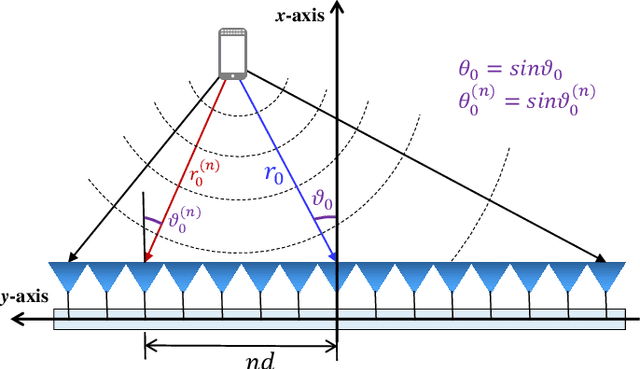
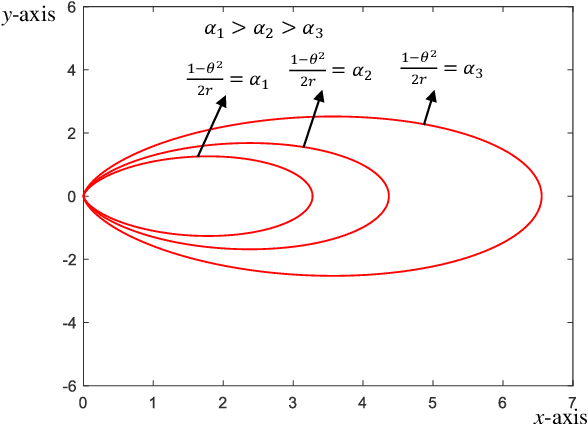
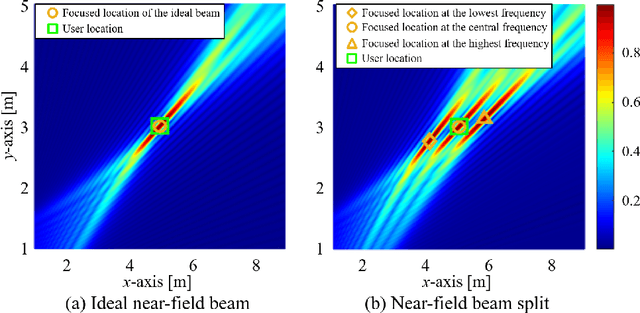
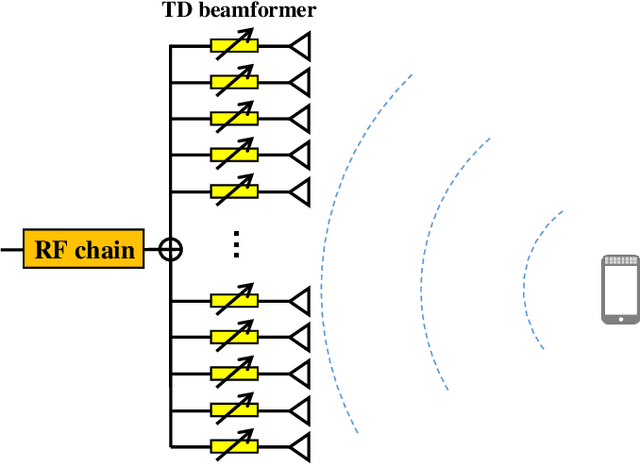
Wideband extremely large-scale multiple-input-multiple-output (XL-MIMO) is a promising technique to achieve Tbps data rates in future 6G systems through beamforming and spatial multiplexing. Due to the extensive bandwidth and the huge number of antennas for wideband XL-MIMO, a significant near-field beam split effect will be induced, where beams at different frequencies are focused on different locations. The near-field beam split effect results in a severe array gain loss, so existing works mainly focus on compensating for this loss by utilizing the time delay (TD) beamformer. By contrast, this paper demonstrates that although the near-field beam split effect degrades the array gain, it also provides a new possibility to realize fast near-field beam training. Specifically, we first reveal the mechanism of the near-field controllable beam split effect. This effect indicates that, by dedicatedly designing the delay parameters, a TD beamformer is able to control the degree of the near-field beam split effect, i.e., beams at different frequencies can flexibly occupy the desired location range. Due to the similarity with the dispersion of natural light caused by a prism, this effect is also termed as the near-field rainbow in this paper. Then, taking advantage of the near-field rainbow effect, a fast wideband beam training scheme is proposed. In our scheme, the close form of the beamforming vector is elaborately derived to enable beams at different frequencies to be focused on different desired locations. By this means, the optimal beamforming vector with the largest array gain can be rapidly searched out by generating multiple beams focused on multiple locations simultaneously through only one radio-frequency (RF) chain. Finally, simulation results demonstrate the proposed scheme is able to realize near-optimal nearfield beam training with a very low training overhead.
SemAttNet: Towards Attention-based Semantic Aware Guided Depth Completion
Apr 28, 2022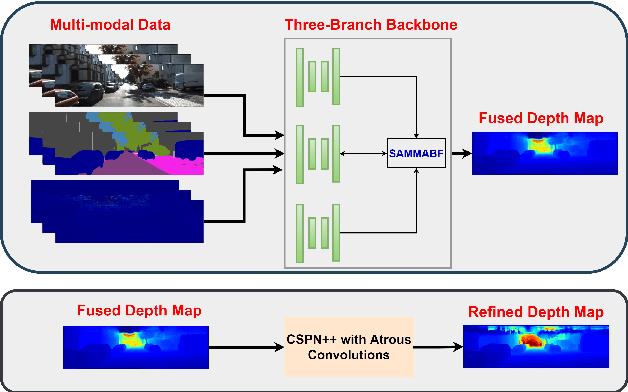
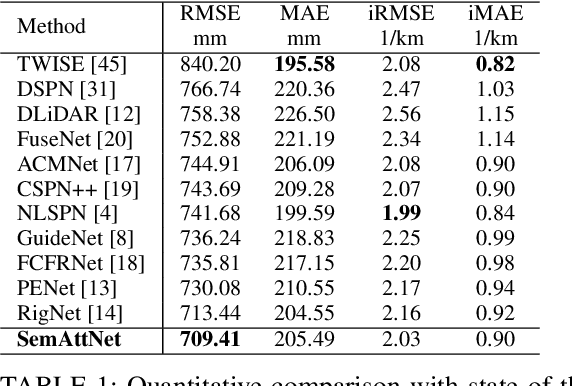
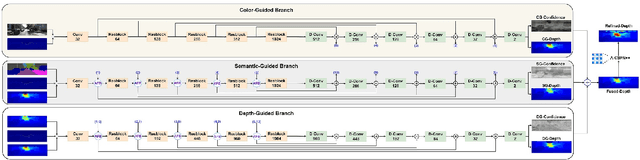

Depth completion involves recovering a dense depth map from a sparse map and an RGB image. Recent approaches focus on utilizing color images as guidance images to recover depth at invalid pixels. However, color images alone are not enough to provide the necessary semantic understanding of the scene. Consequently, the depth completion task suffers from sudden illumination changes in RGB images (e.g., shadows). In this paper, we propose a novel three-branch backbone comprising color-guided, semantic-guided, and depth-guided branches. Specifically, the color-guided branch takes a sparse depth map and RGB image as an input and generates color depth which includes color cues (e.g., object boundaries) of the scene. The predicted dense depth map of color-guided branch along-with semantic image and sparse depth map is passed as input to semantic-guided branch for estimating semantic depth. The depth-guided branch takes sparse, color, and semantic depths to generate the dense depth map. The color depth, semantic depth, and guided depth are adaptively fused to produce the output of our proposed three-branch backbone. In addition, we also propose to apply semantic-aware multi-modal attention-based fusion block (SAMMAFB) to fuse features between all three branches. We further use CSPN++ with Atrous convolutions to refine the dense depth map produced by our three-branch backbone. Extensive experiments show that our model achieves state-of-the-art performance in the KITTI depth completion benchmark at the time of submission.