 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Automatic Detection Method Of Cerebral Aneurysms In Time-Of-Flight Magnetic Resonance Angiography Images Based On Attention 3D U-Net
Oct 26, 2021


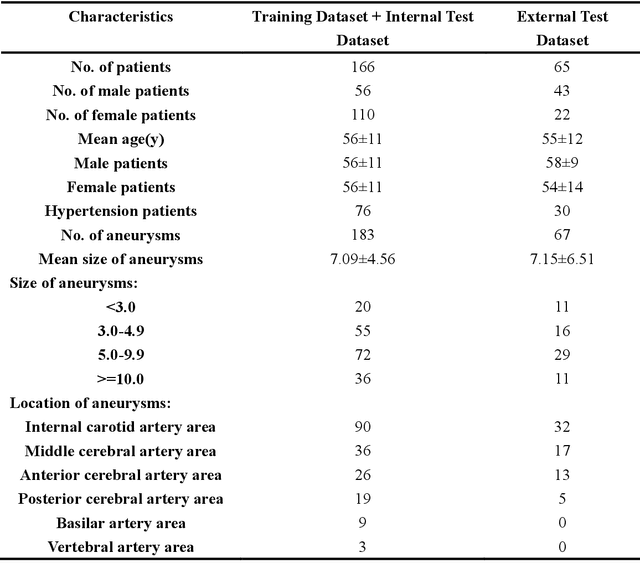
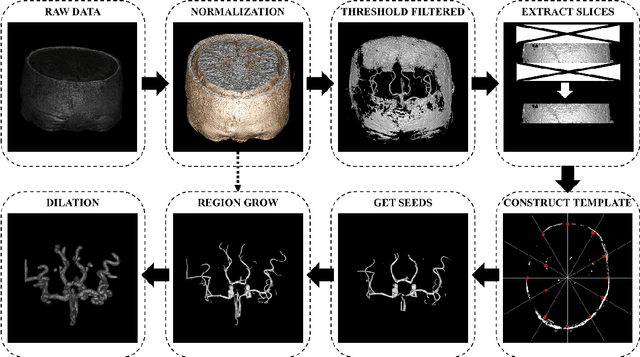
Background:Subarachnoid hemorrhage caused by ruptured cerebral aneurysm often leads to fatal consequences.However,if the aneurysm can be found and treated during asymptomatic periods,the probability of rupture can be greatly reduced.At present,time-of-flight magnetic resonance angiography is one of the most commonly used non-invasive screening techniques for cerebral aneurysm,and the application of deep learning technology in aneurysm detection can effectively improve the screening effect of aneurysm.Existing studies have found that three-dimensional features play an important role in aneurysm detection,but they require a large amount of training data and have problems such as a high false positive rate. Methods:This paper proposed a novel method for aneurysm detection.First,a fully automatic cerebral artery segmentation algorithm without training data was used to extract the volume of interest,and then the 3D U-Net was improved by the 3D SENet module to establish an aneurysm detection model.Eventually a set of fully automated,end-to-end aneurysm detection methods have been formed. Results:A total of 231 magnetic resonance angiography image data were used in this study,among which 132 were training sets,34 were internal test sets and 65 were external test sets.The presented method obtained 97.89% sensitivity in the five-fold cross-validation and obtained 91.0% sensitivity with 2.48 false positives/case in the detection of the external test sets. Conclusions:Compared with the results of our previous studies and other studies,the method in this paper achieves a very competitive sensitivity with less training data and maintains a low false positive rate.As the only method currently using 3D U-Net for aneurysm detection,it proves the feasibility and superior performance of this network in aneurysm detection,and also explores the potential of the channel attention mechanism in this task.
Real-time Travel Time Estimation Using Matrix Factorization
Dec 01, 2019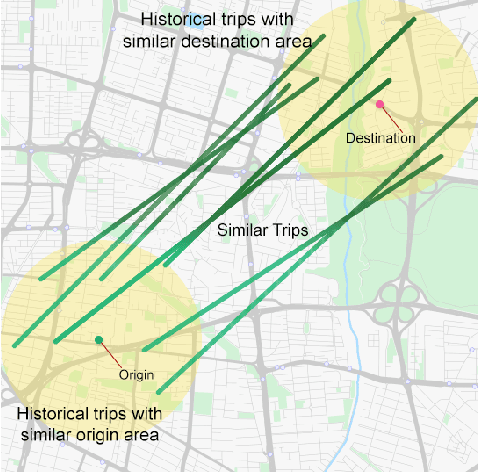

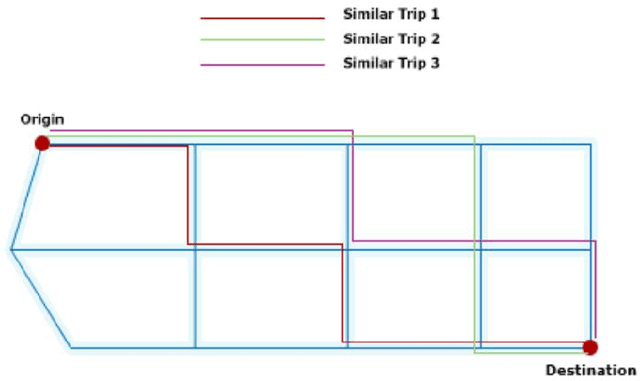
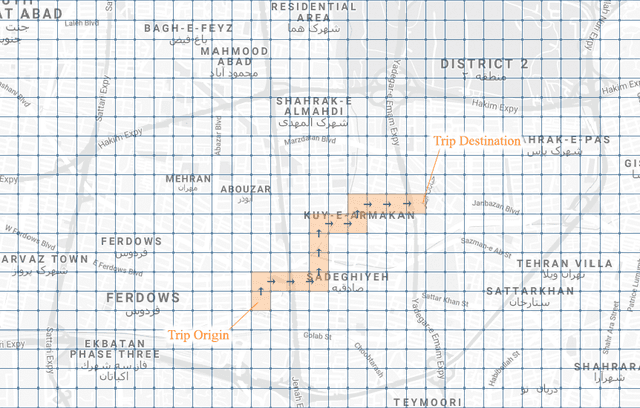
Estimating the travel time of any route is of great importance for trip planners, traffic operators, online taxi dispatching and ride-sharing platforms, and navigation provider systems. With the advance of technology, many traveling cars, including online taxi dispatch systems' vehicles are equipped with Global Positioning System (GPS) devices that can report the location of the vehicle every few seconds. This paper uses GPS data and the Matrix Factorization techniques to estimate the travel times on all road segments and time intervals simultaneously. We aggregate GPS data into a matrix, where each cell of the original matrix contains the average vehicle speed for a segment and a specific time interval. One of the problems with this matrix is its high sparsity. We use Alternating Least Squares (ALS) method along with a regularization term to factorize the matrix. Since this approach can solve the sparsity problem that arises from the absence of cars in many road segments in a specific time interval, matrix factorization is suitable for estimating the travel time. Our comprehensive evaluation results using real data provided by one of the largest online taxi dispatching systems in Iran, shows the strength of our proposed method.
Introducing Block-Toeplitz Covariance Matrices to Remaster Linear Discriminant Analysis for Event-related Potential Brain-computer Interfaces
Feb 04, 2022
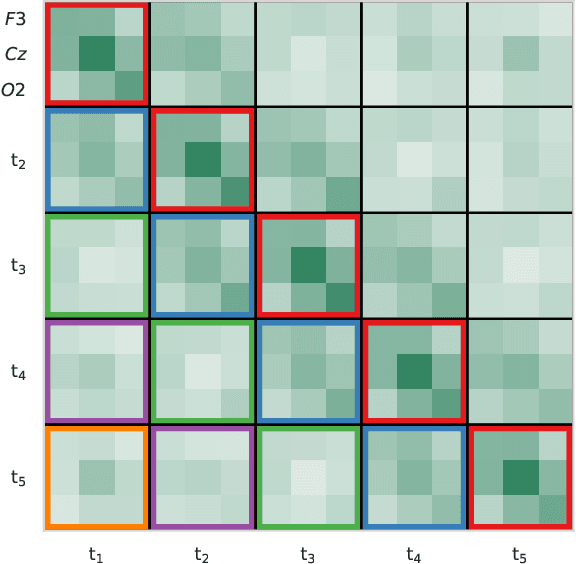
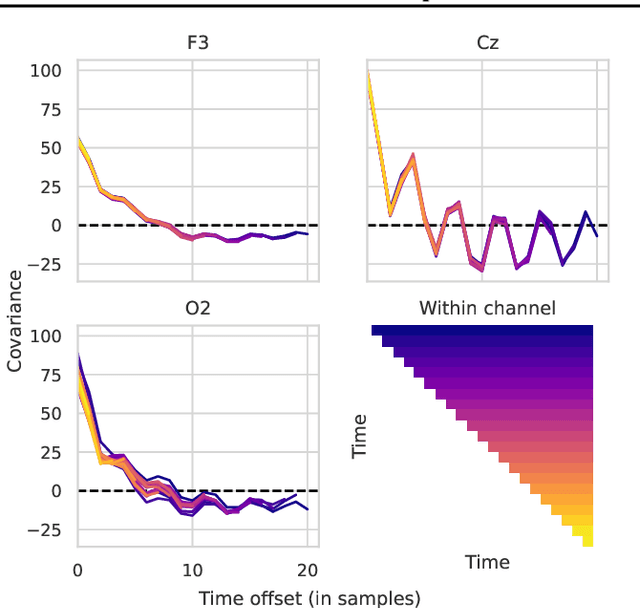
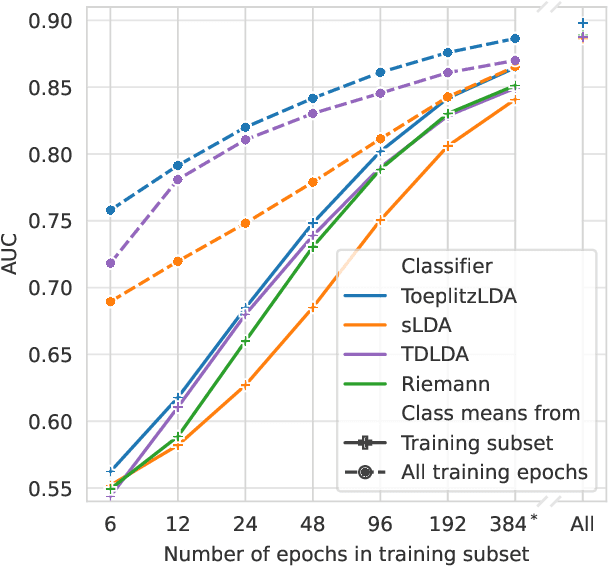
Covariance matrices of noisy multichannel electroencephalogram time series data are hard to estimate due to high dimensionality. In brain-computer interfaces (BCI) based on event-related potentials and a linear discriminant analysis (LDA) for classification, the state of the art to address this problem is by shrinkage regularization. We propose a novel idea to tackle this problem by enforcing a block-Toeplitz structure for the covariance matrix of the LDA, which implements an assumption of signal stationarity in short time windows for each channel. On data of 213 subjects collected under 13 event-related potential BCI protocols, the resulting 'ToeplitzLDA' significantly increases the binary classification performance compared to shrinkage regularized LDA (up to 6 AUC points) and Riemannian classification approaches (up to 2 AUC points). This translates to greatly improved application level performances, as exemplified on data recorded during an unsupervised visual speller application, where spelling errors could be reduced by 81% on average for 25 subjects. Aside from lower memory and time complexity for LDA training, ToeplitzLDA proved to be almost invariant even to a twenty-fold time dimensionality enlargement, which reduces the need of expert knowledge regarding feature extraction.
A De-raining semantic segmentation network for real-time foreground segmentation
Apr 16, 2021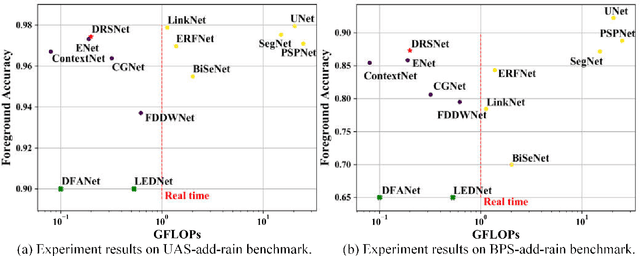

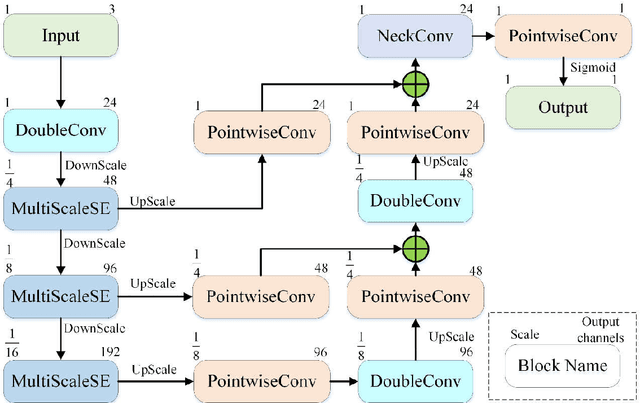
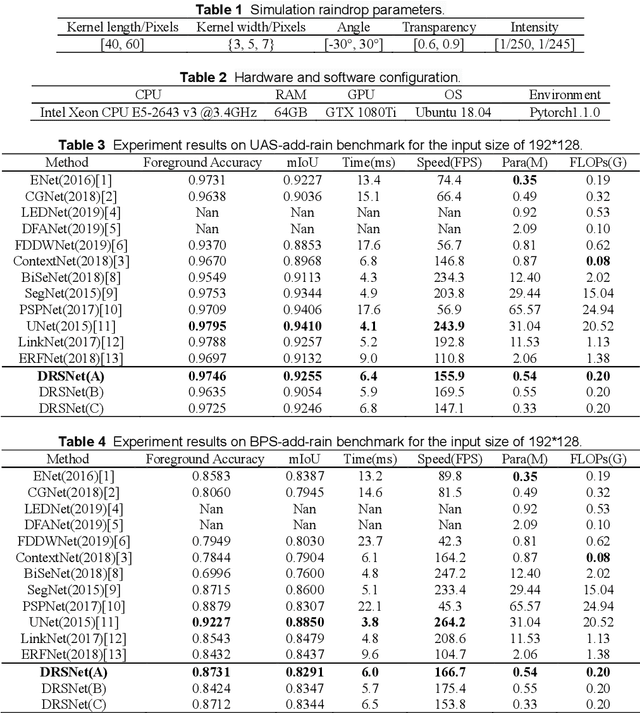
Few researches have been proposed specifically for real-time semantic segmentation in rainy environments. However, the demand in this area is huge and it is challenging for lightweight networks. Therefore, this paper proposes a lightweight network which is specially designed for the foreground segmentation in rainy environments, named De-raining Semantic Segmentation Network (DRSNet). By analyzing the characteristics of raindrops, the MultiScaleSE Block is targetedly designed to encode the input image, it uses multi-scale dilated convolutions to increase the receptive field, and SE attention mechanism to learn the weights of each channels. In order to combine semantic information between different encoder and decoder layers, it is proposed to use Asymmetric Skip, that is, the higher semantic layer of encoder employs bilinear interpolation and the output passes through pointwise convolution, then added element-wise to the lower semantic layer of decoder. According to the control experiments, the performances of MultiScaleSE Block and Asymmetric Skip compared with SEResNet18 and Symmetric Skip respectively are improved to a certain degree on the Foreground Accuracy index. The parameters and the floating point of operations (FLOPs) of DRSNet is only 0.54M and 0.20GFLOPs separately. The state-of-the-art results and real-time performances are achieved on both the UESTC all-day Scenery add rain (UAS-add-rain) and the Baidu People Segmentation add rain (BPS-add-rain) benchmarks with the input sizes of 192*128, 384*256 and 768*512. The speed of DRSNet exceeds all the networks within 1GFLOPs, and Foreground Accuracy index is also the best among the similar magnitude networks on both benchmarks.
Toward More Effective Human Evaluation for Machine Translation
Apr 11, 2022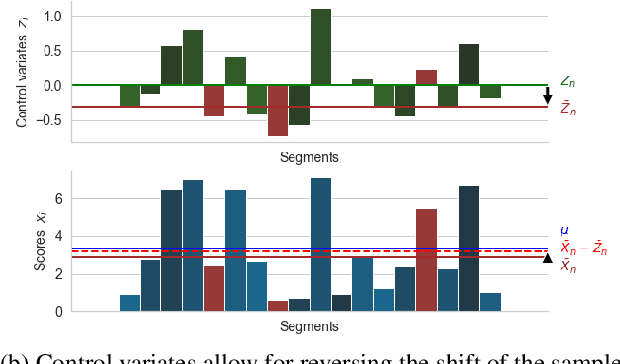
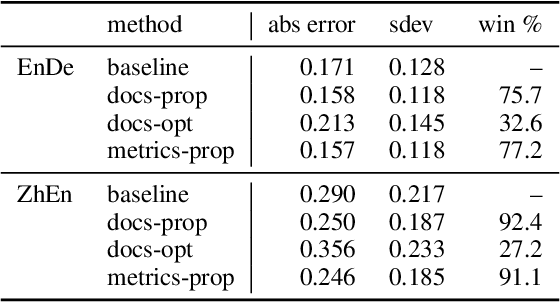
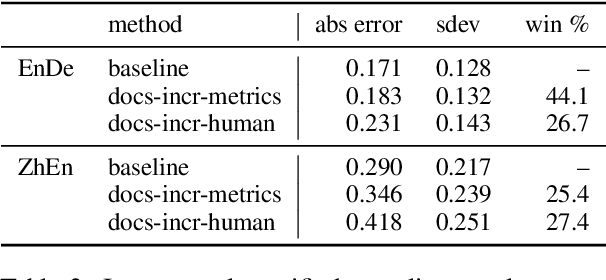
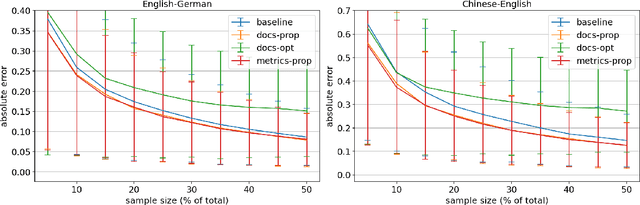
Improvements in text generation technologies such as machine translation have necessitated more costly and time-consuming human evaluation procedures to ensure an accurate signal. We investigate a simple way to reduce cost by reducing the number of text segments that must be annotated in order to accurately predict a score for a complete test set. Using a sampling approach, we demonstrate that information from document membership and automatic metrics can help improve estimates compared to a pure random sampling baseline. We achieve gains of up to 20% in average absolute error by leveraging stratified sampling and control variates. Our techniques can improve estimates made from a fixed annotation budget, are easy to implement, and can be applied to any problem with structure similar to the one we study.
Real-Time Optimization of the Current Steering for Visual Prosthesis
Dec 25, 2020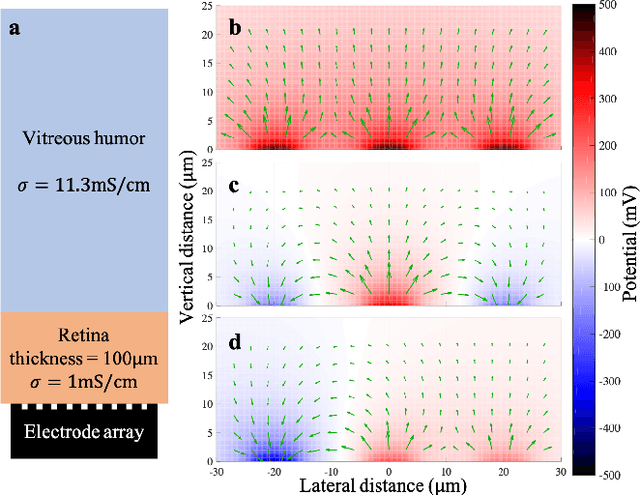
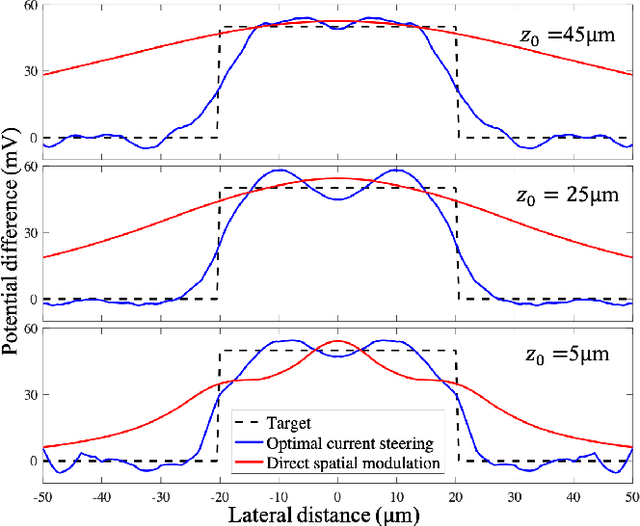
Current steering on a multi-electrode array is commonly used to shape the electric field in the neural tissue in order to improve selectivity and efficacy of stimulation. Previously, simulations of the electric field in tissue required separate computation for each set of the stimulation parameters. Not only is this approach to modeling time-consuming and very difficult with a large number of electrodes, it is incompatible with real-time optimization of the current steering for practical applications. We present a framework for efficient computation of the electric field in the neural tissue based on superposition of the fields from a pre-calculated basis. Such linear algebraic framework enables optimization of the current steering for any targeted electric field in real time. For applications to retinal prosthetics, we demonstrate how the stimulation depth can be optimized for each patient based on the retinal thickness and separation from the array, while maximizing the lateral confinement of the electric field essential for spatial resolution.
Slow-varying Dynamics Assisted Temporal Capsule Network for Machinery Remaining Useful Life Estimation
Mar 30, 2022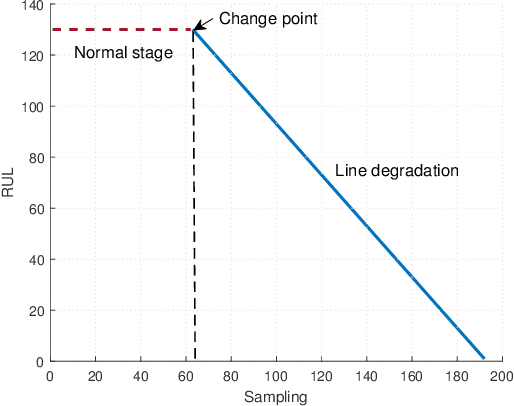
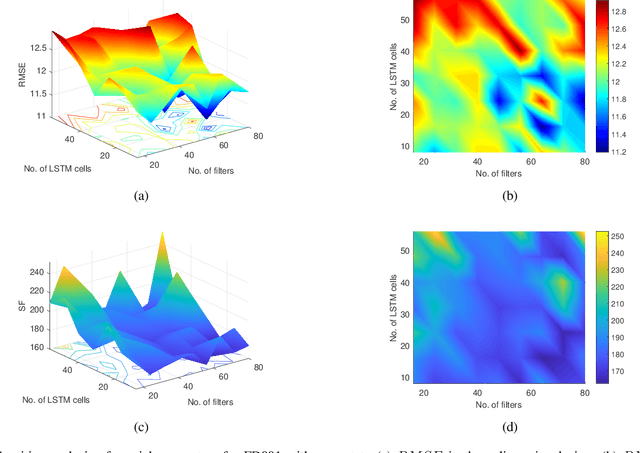
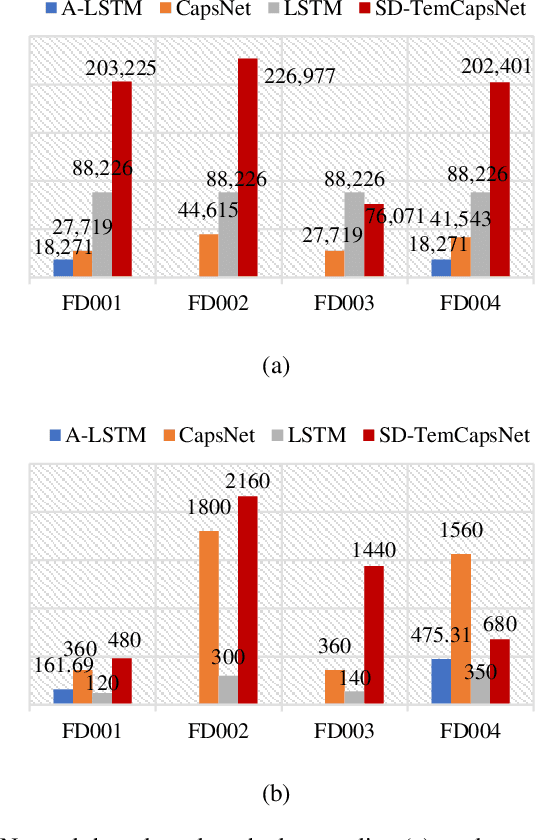
Capsule network (CapsNet) acts as a promising alternative to the typical convolutional neural network, which is the dominant network to develop the remaining useful life (RUL) estimation models for mechanical equipment. Although CapsNet comes with an impressive ability to represent the entities' hierarchical relationships through a high-dimensional vector embedding, it fails to capture the long-term temporal correlation of run-to-failure time series measured from degraded mechanical equipment. On the other hand, the slow-varying dynamics, which reveals the low-frequency information hidden in mechanical dynamical behaviour, is overlooked in the existing RUL estimation models, limiting the utmost ability of advanced networks. To address the aforementioned concerns, we propose a Slow-varying Dynamics assisted Temporal CapsNet (SD-TemCapsNet) to simultaneously learn the slow-varying dynamics and temporal dynamics from measurements for accurate RUL estimation. First, in light of the sensitivity of fault evolution, slow-varying features are decomposed from normal raw data to convey the low-frequency components corresponding to the system dynamics. Next, the long short-term memory (LSTM) mechanism is introduced into CapsNet to capture the temporal correlation of time series. To this end, experiments conducted on an aircraft engine and a milling machine verify that the proposed SD-TemCapsNet outperforms the mainstream methods. In comparison with CapsNet, the estimation accuracy of the aircraft engine with four different scenarios has been improved by 10.17%, 24.97%, 3.25%, and 13.03% concerning the index root mean squared error, respectively. Similarly, the estimation accuracy of the milling machine has been improved by 23.57% compared to LSTM and 19.54% compared to CapsNet.
Adversarial Training for High-Stakes Reliability
May 04, 2022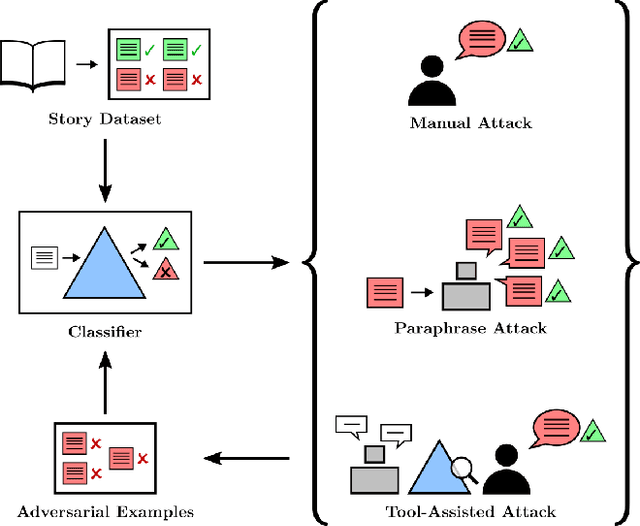


In the future, powerful AI systems may be deployed in high-stakes settings, where a single failure could be catastrophic. One technique for improving AI safety in high-stakes settings is adversarial training, which uses an adversary to generate examples to train on in order to achieve better worst-case performance. In this work, we used a language generation task as a testbed for achieving high reliability through adversarial training. We created a series of adversarial training techniques -- including a tool that assists human adversaries -- to find and eliminate failures in a classifier that filters text completions suggested by a generator. In our simple "avoid injuries" task, we determined that we can set very conservative classifier thresholds without significantly impacting the quality of the filtered outputs. With our chosen thresholds, filtering with our baseline classifier decreases the rate of unsafe completions from about 2.4% to 0.003% on in-distribution data, which is near the limit of our ability to measure. We found that adversarial training significantly increased robustness to the adversarial attacks that we trained on, without affecting in-distribution performance. We hope to see further work in the high-stakes reliability setting, including more powerful tools for enhancing human adversaries and better ways to measure high levels of reliability, until we can confidently rule out the possibility of catastrophic deployment-time failures of powerful models.
Generating Continuous Motion and Force Plans in Real-Time for Legged Mobile Manipulation
Apr 23, 2021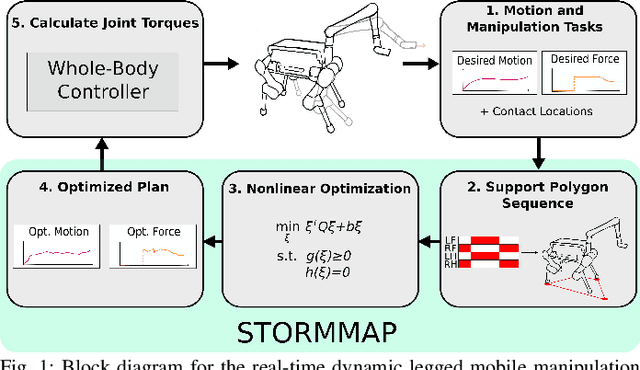

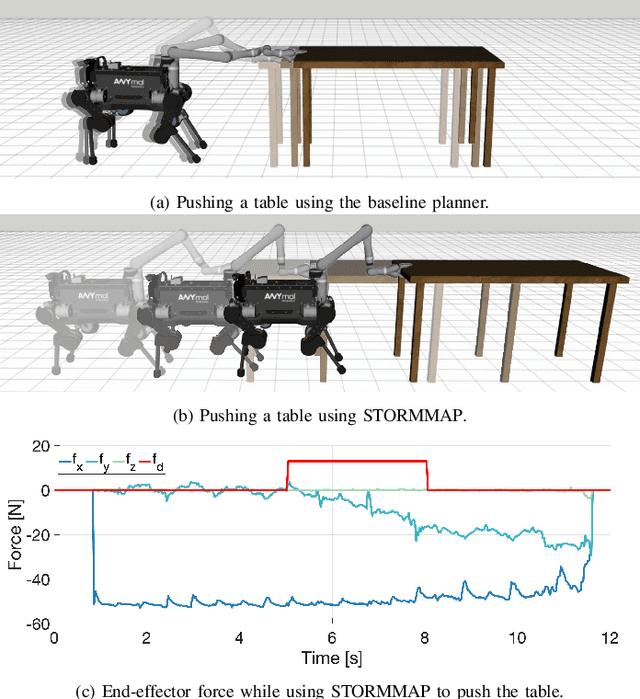
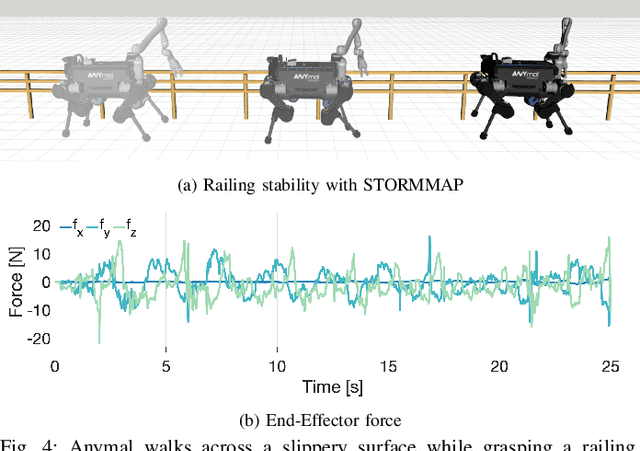
Manipulators can be added to legged robots, allowing them to interact with and change their environment. Legged mobile manipulation planners must consider how contact forces generated by these manipulators affect the system. Current planning strategies either treat these forces as immutable during planning or are unable to optimize over these contact forces while operating in real-time. This paper presents the Stability and Task Oriented Receding-Horizon Motion and Manipulation Autonomous Planner (STORMMAP) that is able to generate continuous plans for the robot's motion and manipulation force trajectories that ensure dynamic feasibility and stability of the platform, and incentivizes accomplishing manipulation and motion tasks specified by a user. STORMMAP uses a nonlinear optimization problem to compute these plans and is able to run in real-time by assuming contact locations are given a-priori, either by a user or an external algorithm. A variety of simulated experiments on a quadruped with a manipulator mounted to its torso demonstrate the versatility of STORMMAP. In contrast to existing state of the art methods, the approach described in this paper generates continuous plans in under ten milliseconds, an order of magnitude faster than previous strategies.
Exact Indexing of Time Series under Dynamic Time Warping
Feb 11, 2020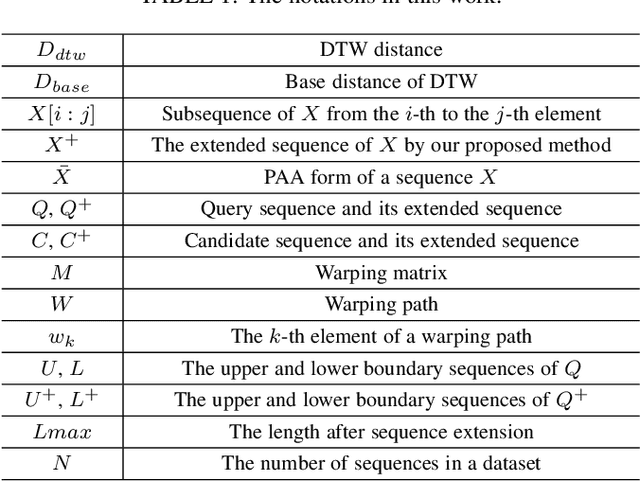
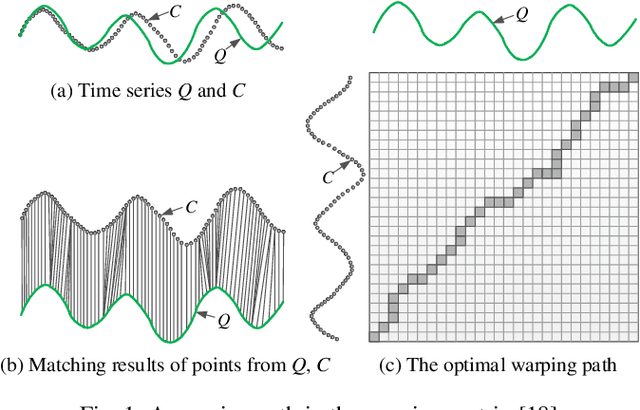
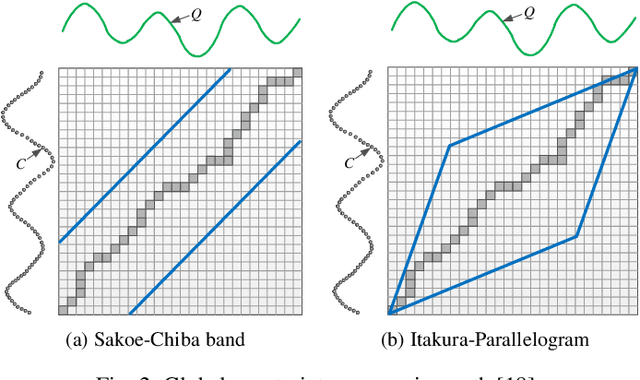
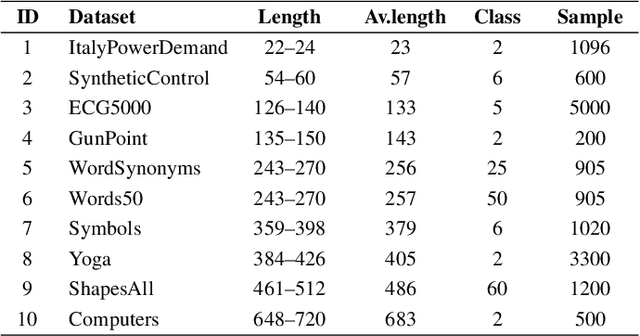
Dynamic time warping (DTW) is a robust similarity measure of time series. However, it does not satisfy triangular inequality and has high computational complexity, severely limiting its applications in similarity search on large-scale datasets. Usually, we resort to lower bounding distances to speed up similarity search under DTW. Unfortunately, there is still a lack of an effective lower bounding distance that can measure unequal-length time series and has desirable tightness. In the paper, we propose a novel lower bounding distance LB_Keogh+, which is a seamless combination of sequence extension and LB_Keogh. It can be used for unequal-length sequences and has low computational complexity. Besides, LB_Keogh+ can extend sequences to an arbitrary suitable length, without significantly reducing tightness. Next, based on LB_Keogh+, an exact index of time series under DTW is devised. Then, we introduce several theorems and complete the relevant proofs to guarantee no false dismissals in our similarity search. Finally, extensive experiments are conducted on real-world datasets. Experimental results indicate that our proposed method can perform similarity search of unequal-length sequences with high tightness and good pruning power.