 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Overlapping Word Removal is All You Need: Revisiting Data Imbalance in Hope Speech Detection
Apr 12, 2022

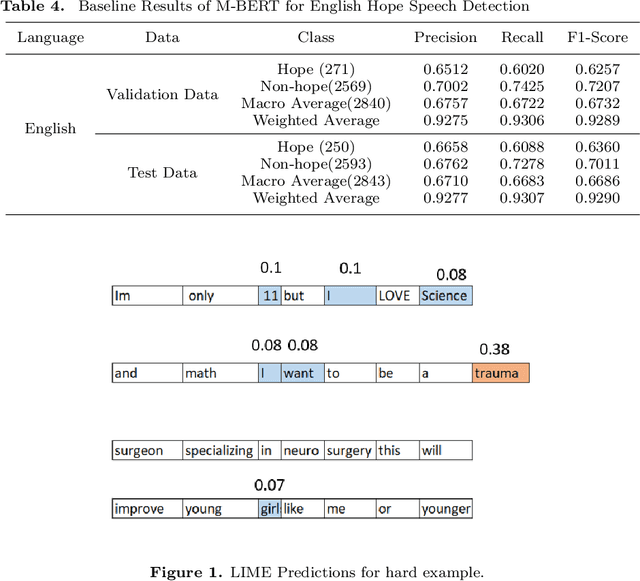

Hope Speech Detection, a task of recognizing positive expressions, has made significant strides recently. However, much of the current works focus on model development without considering the issue of inherent imbalance in the data. Our work revisits this issue in hope-speech detection by introducing focal loss, data augmentation, and pre-processing strategies. Accordingly, we find that introducing focal loss as part of Multilingual-BERT's (M-BERT) training process mitigates the effect of class imbalance and improves overall F1-Macro by 0.11. At the same time, contextual and back-translation-based word augmentation with M-BERT improves results by 0.10 over baseline despite imbalance. Finally, we show that overlapping word removal based on pre-processing, though simple, improves F1-Macro by 0.28. In due process, we present detailed studies depicting various behaviors of each of these strategies and summarize key findings from our empirical results for those interested in getting the most out of M-BERT for hope speech detection under real-world conditions of data imbalance.
CorrectSpeech: A Fully Automated System for Speech Correction and Accent Reduction
Apr 12, 2022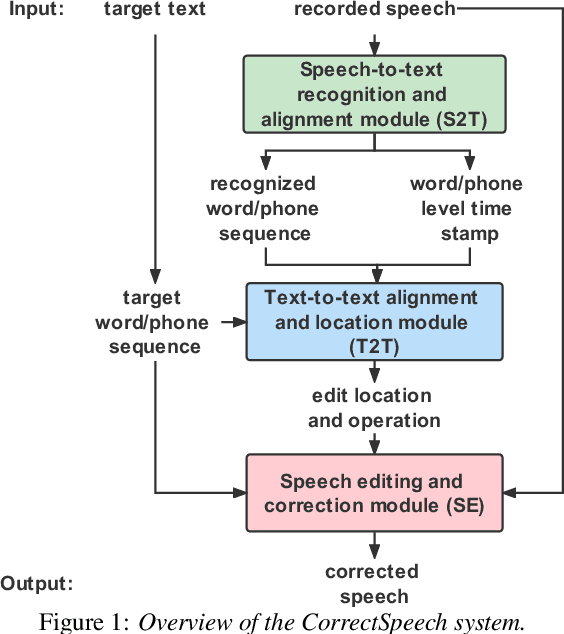
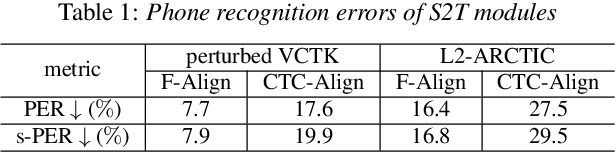
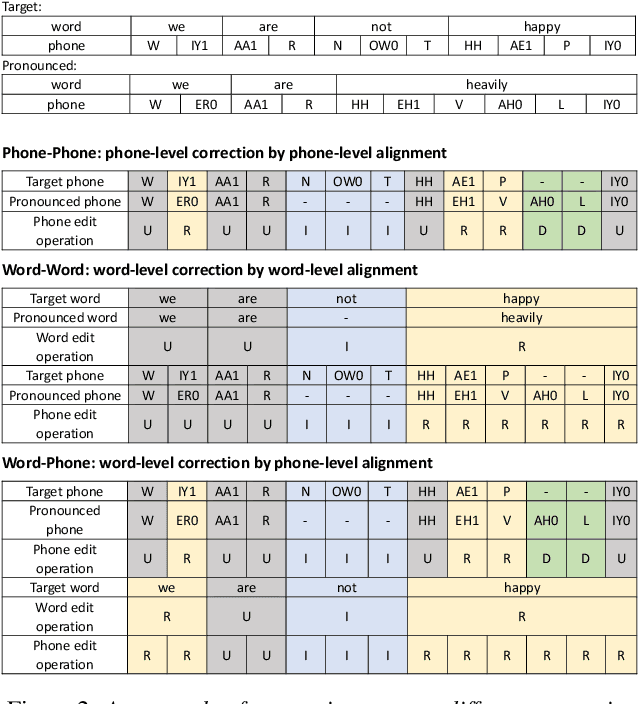
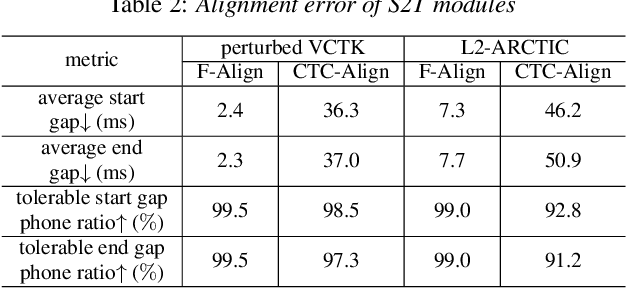
This study extends our previous work on text-based speech editing to developing a fully automated system for speech correction and accent reduction. Consider the application scenario that a recorded speech audio contains certain errors, e.g., inappropriate words, mispronunciations, that need to be corrected. The proposed system, named CorrectSpeech, performs the correction in three steps: recognizing the recorded speech and converting it into time-stamped symbol sequence, aligning recognized symbol sequence with target text to determine locations and types of required edit operations, and generating the corrected speech. Experiments show that the quality and naturalness of corrected speech depend on the performance of speech recognition and alignment modules, as well as the granularity level of editing operations. The proposed system is evaluated on two corpora: a manually perturbed version of VCTK and L2-ARCTIC. The results demonstrate that our system is able to correct mispronunciation and reduce accent in speech recordings. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/CorrectSpeech/ .
Traffic Context Aware Data Augmentation for Rare Object Detection in Autonomous Driving
May 01, 2022
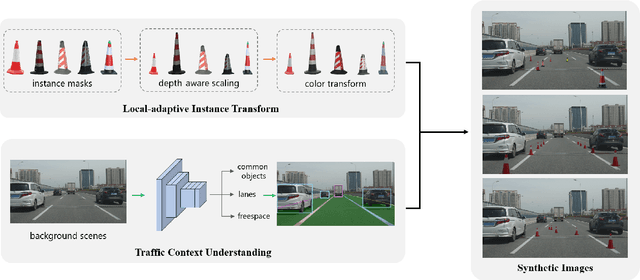


Detection of rare objects (e.g., traffic cones, traffic barrels and traffic warning triangles) is an important perception task to improve the safety of autonomous driving. Training of such models typically requires a large number of annotated data which is expensive and time consuming to obtain. To address the above problem, an emerging approach is to apply data augmentation to automatically generate cost-free training samples. In this work, we propose a systematic study on simple Copy-Paste data augmentation for rare object detection in autonomous driving. Specifically, local adaptive instance-level image transformation is introduced to generate realistic rare object masks from source domain to the target domain. Moreover, traffic scene context is utilized to guide the placement of masks of rare objects. To this end, our data augmentation generates training data with high quality and realistic characteristics by leveraging both local and global consistency. In addition, we build a new dataset named NM10k consisting 10k training images, 4k validation images and the corresponding labels with a diverse range of scenarios in autonomous driving. Experiments on NM10k show that our method achieves promising results on rare object detection. We also present a thorough study to illustrate the effectiveness of our local-adaptive and global constraints based Copy-Paste data augmentation for rare object detection. The data, development kit and more information of NM10k dataset are available online at: \url{https://nullmax-vision.github.io}.
EF-BV: A Unified Theory of Error Feedback and Variance Reduction Mechanisms for Biased and Unbiased Compression in Distributed Optimization
May 09, 2022


In distributed or federated optimization and learning, communication between the different computing units is often the bottleneck, and gradient compression is a widely used technique for reducing the number of bits sent within each communication round of iterative methods. There are two classes of compression operators and separate algorithms making use of them. In the case of unbiased random compressors with bounded variance (e.g., rand-k), the DIANA algorithm of Mishchenko et al. [2019], which implements a variance reduction technique for handling the variance introduced by compression, is the current state of the art. In the case of biased and contractive compressors (e.g., top-k), the EF21 algorithm of Richt\'arik et al. [2021], which implements an error-feedback mechanism for handling the error introduced by compression, is the current state of the art. These two classes of compression schemes and algorithms are distinct, with different analyses and proof techniques. In this paper, we unify them into a single framework and propose a new algorithm, recovering DIANA and EF21 as particular cases. We prove linear convergence under certain conditions. Our general approach works with a new, larger class of compressors, which includes unbiased and biased compressors as particular cases, and has two parameters, the bias and the variance. These gives a finer control and allows us to inherit the best of the two worlds: biased compressors, whose good performance in practice is recognized, can be used. And independent randomness at the compressors allows to mitigate the effects of compression, with the convergence rate improving when the number of parallel workers is large. This is the first time that an algorithm with all these features is proposed. Our approach takes a step towards better understanding of two so-far distinct worlds of communication-efficient distributed learning.
Fractional Vegetation Cover Estimation using Hough Lines and Linear Iterative Clustering
Apr 30, 2022
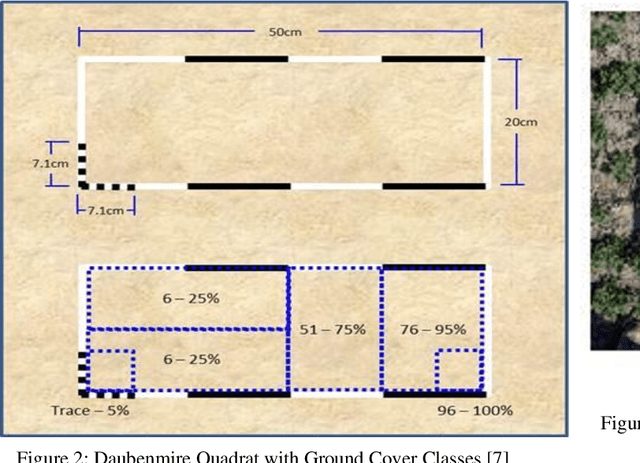

A common requirement of plant breeding programs across the country is companion planting -- growing different species of plants in close proximity so they can mutually benefit each other. However, the determination of companion plants requires meticulous monitoring of plant growth. The technique of ocular monitoring is often laborious and error prone. The availability of image processing techniques can be used to address the challenge of plant growth monitoring and provide robust solutions that assist plant scientists to identify companion plants. This paper presents a new image processing algorithm to determine the amount of vegetation cover present in a given area, called fractional vegetation cover. The proposed technique draws inspiration from the trusted Daubenmire method for vegetation cover estimation and expands upon it. Briefly, the idea is to estimate vegetation cover from images containing multiple rows of plant species growing in close proximity separated by a multi-segment PVC frame of known size. The proposed algorithm applies a Hough Transform and Simple Linear Iterative Clustering (SLIC) to estimate the amount of vegetation cover within each segment of the PVC frame. The analysis when repeated over images captured at regular intervals of time provides crucial insights into plant growth. As a means of comparison, the proposed algorithm is compared with SamplePoint and Canopeo, two trusted applications used for vegetation cover estimation. The comparison shows a 99% similarity with both SamplePoint and Canopeo demonstrating the accuracy and feasibility of the algorithm for fractional vegetation cover estimation.
Locally private nonparametric confidence intervals and sequences
Feb 17, 2022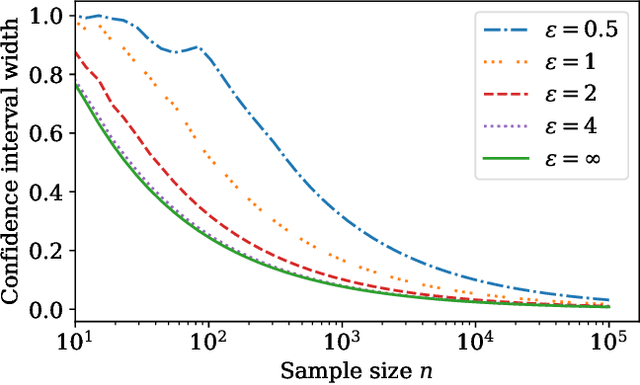
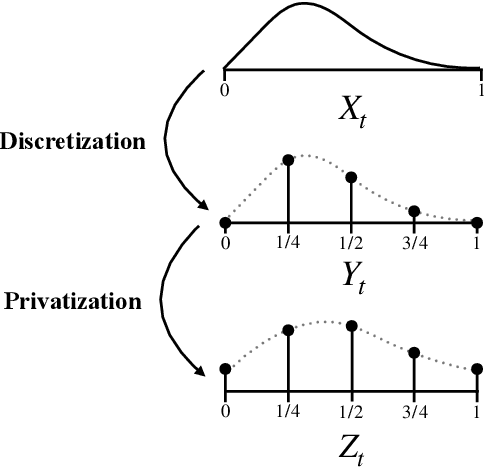
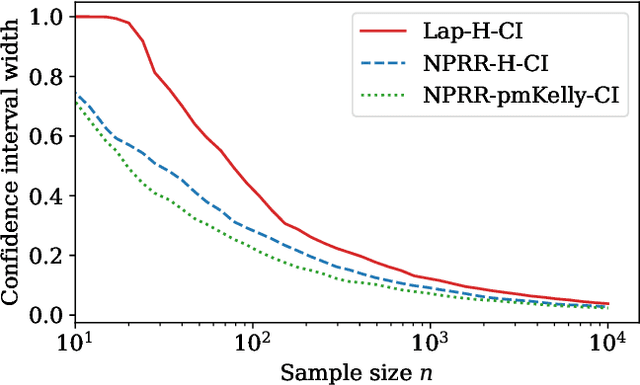
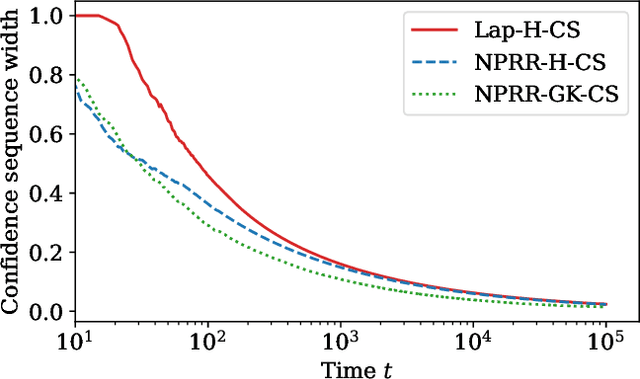
This work derives methods for performing nonparametric, nonasymptotic statistical inference for population parameters under the constraint of local differential privacy (LDP). Given observations $(X_1, \dots, X_n)$ with mean $\mu^\star$ that are privatized into $(Z_1, \dots, Z_n)$, we introduce confidence intervals (CI) and time-uniform confidence sequences (CS) for $\mu^\star \in \mathbb R$ when only given access to the privatized data. We introduce a nonparametric and sequentially interactive generalization of Warner's famous "randomized response" mechanism, satisfying LDP for arbitrary bounded random variables, and then provide CIs and CSs for their means given access to the resulting privatized observations. We extend these CSs to capture time-varying (non-stationary) means, and conclude by illustrating how these methods can be used to conduct private online A/B tests.
COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks
Mar 16, 2022
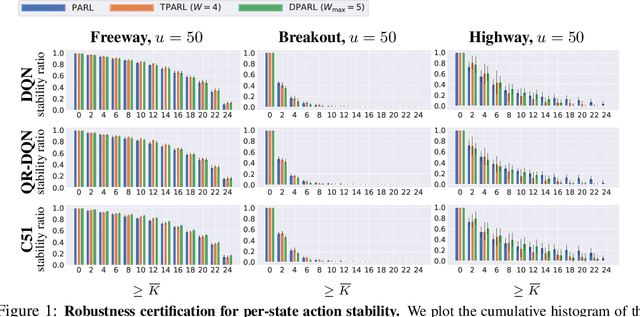
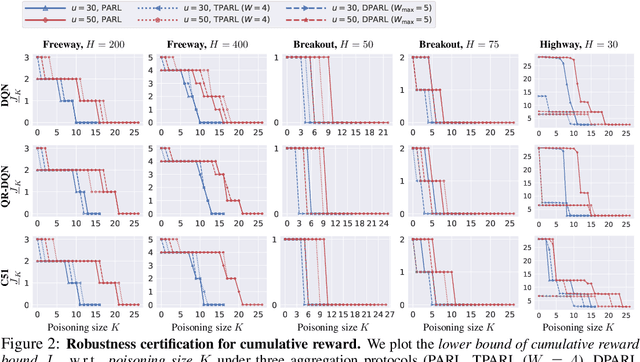
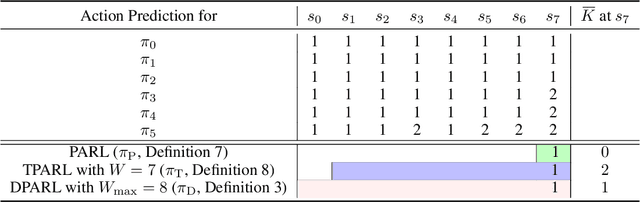
As reinforcement learning (RL) has achieved near human-level performance in a variety of tasks, its robustness has raised great attention. While a vast body of research has explored test-time (evasion) attacks in RL and corresponding defenses, its robustness against training-time (poisoning) attacks remains largely unanswered. In this work, we focus on certifying the robustness of offline RL in the presence of poisoning attacks, where a subset of training trajectories could be arbitrarily manipulated. We propose the first certification framework, COPA, to certify the number of poisoning trajectories that can be tolerated regarding different certification criteria. Given the complex structure of RL, we propose two certification criteria: per-state action stability and cumulative reward bound. To further improve the certification, we propose new partition and aggregation protocols to train robust policies. We further prove that some of the proposed certification methods are theoretically tight and some are NP-Complete problems. We leverage COPA to certify three RL environments trained with different algorithms and conclude: (1) The proposed robust aggregation protocols such as temporal aggregation can significantly improve the certifications; (2) Our certification for both per-state action stability and cumulative reward bound are efficient and tight; (3) The certification for different training algorithms and environments are different, implying their intrinsic robustness properties. All experimental results are available at https://copa-leaderboard.github.io.
Core Box Image Recognition and its Improvement with a New Augmentation Technique
Apr 20, 2022
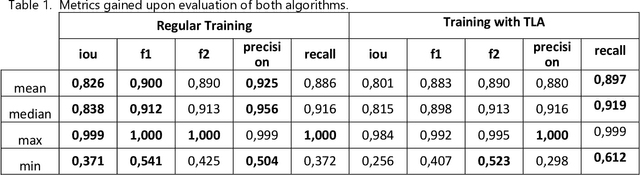

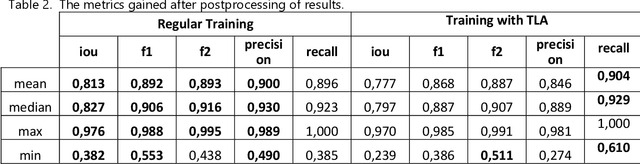
Most methods for automated full-bore rock core image analysis (description, colour, properties distribution, etc.) are based on separate core column analyses. The core is usually imaged in a box because of the significant amount of time taken to get an image for each core column. The work presents an innovative method and algorithm for core columns extraction from core boxes. The conditions for core boxes imaging may differ tremendously. Such differences are disastrous for machine learning algorithms which need a large dataset describing all possible data variations. Still, such images have some standard features - a box and core. Thus, we can emulate different environments with a unique augmentation described in this work. It is called template-like augmentation (TLA). The method is described and tested on various environments, and results are compared on an algorithm trained on both 'traditional' data and a mix of traditional and TLA data. The algorithm trained with TLA data provides better metrics and can detect core on most new images, unlike the algorithm trained on data without TLA. The algorithm for core column extraction implemented in an automated core description system speeds up the core box processing by a factor of 20.
* 20 pages, 16 figures, 1 table, the augmentation pipeline code samples published as Open-Source code for TLA at https://github.com/BEEugene/TemplateArtification/, continue of the research from arXiv:1909.10227
Color2Style: Real-Time Exemplar-Based Image Colorization with Self-Reference Learning and Deep Feature Modulation
Jun 16, 2021

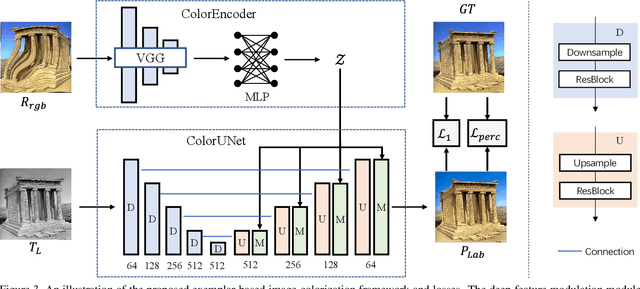
Legacy black-and-white photos are riddled with people's nostalgia and glorious memories of the past. To better relive the elapsed frozen moments, in this paper, we present a deep exemplar-based image colorization approach named Color2Style to resurrect these grayscale image media by filling them with vibrant colors. Generally, for exemplar-based colorization, unsupervised and unpaired training are usually adopted, due to the difficulty of obtaining input and ground truth image pairs. To train an exemplar-based colorization model, current algorithms usually strive to achieve two procedures: i) retrieving a large number of reference images with high similarity in advance, which is inevitably time-consuming and tedious; ii) designing complicated modules to transfer the colors of the reference image to the grayscale image, by calculating and leveraging the deep semantic correspondence between them (e.g., non-local operation). Contrary to the previous methods, we solve and simplify the above two steps in one end-to-end learning procedure. First, we adopt a self-augmented self-reference training scheme, where the reference image is generated by graphical transformations from the original colorful one whereby the training can be formulated in a paired manner. Second, instead of computing complex and inexplicable correspondence maps, our method exploits a simple yet effective deep feature modulation (DFM) module, which injects the color embeddings extracted from the reference image into the deep representations of the input grayscale image. Such design is much more lightweight and intelligible, achieving appealing performance with real-time processing speed. Moreover, our model does not require multifarious loss functions and regularization terms like existing methods, but only two widely used loss functions. Codes and models will be available at https://github.com/zhaohengyuan1/Color2Style.
M2N: Mesh Movement Networks for PDE Solvers
Apr 24, 2022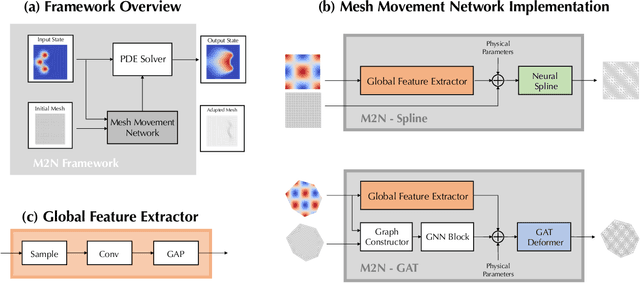
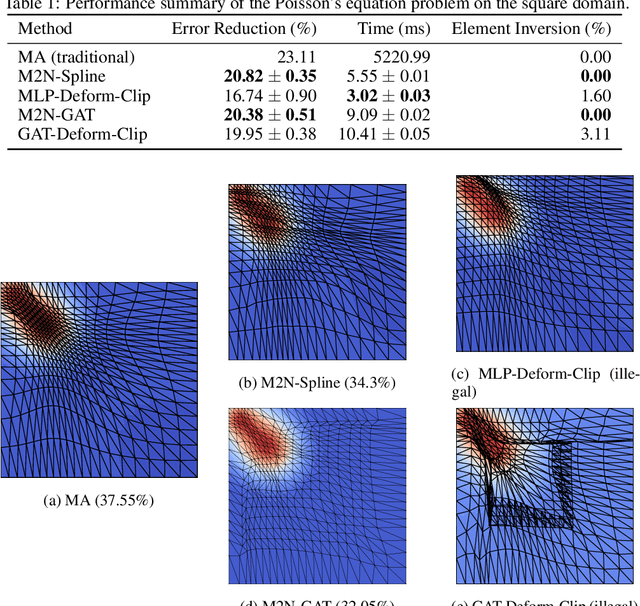
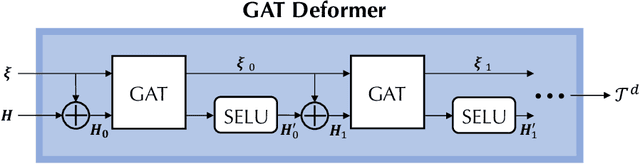
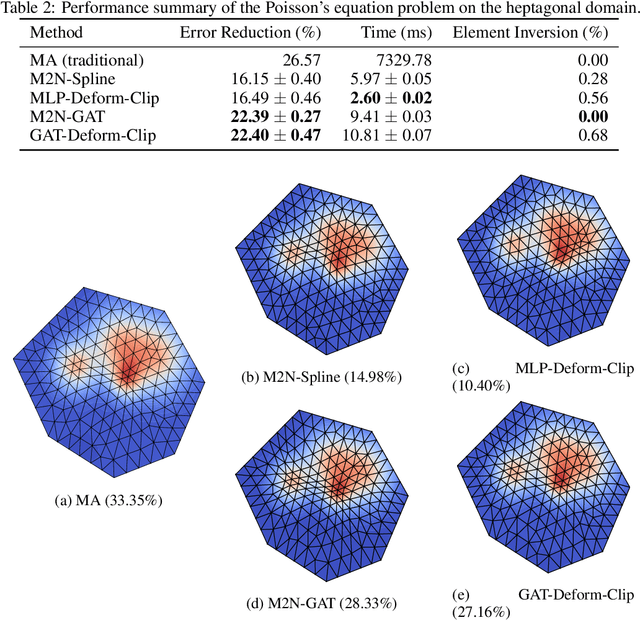
Mainstream numerical Partial Differential Equation (PDE) solvers require discretizing the physical domain using a mesh. Mesh movement methods aim to improve the accuracy of the numerical solution by increasing mesh resolution where the solution is not well-resolved, whilst reducing unnecessary resolution elsewhere. However, mesh movement methods, such as the Monge-Ampere method, require the solution of auxiliary equations, which can be extremely expensive especially when the mesh is adapted frequently. In this paper, we propose to our best knowledge the first learning-based end-to-end mesh movement framework for PDE solvers. Key requirements of learning-based mesh movement methods are alleviating mesh tangling, boundary consistency, and generalization to mesh with different resolutions. To achieve these goals, we introduce the neural spline model and the graph attention network (GAT) into our models respectively. While the Neural-Spline based model provides more flexibility for large deformation, the GAT based model can handle domains with more complicated shapes and is better at performing delicate local deformation. We validate our methods on stationary and time-dependent, linear and non-linear equations, as well as regularly and irregularly shaped domains. Compared to the traditional Monge-Ampere method, our approach can greatly accelerate the mesh adaptation process, whilst achieving comparable numerical error reduction.