 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Core Box Image Recognition and its Improvement with a New Augmentation Technique
Apr 20, 2022

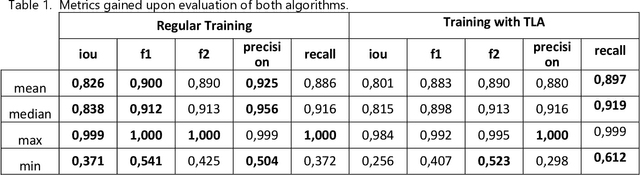

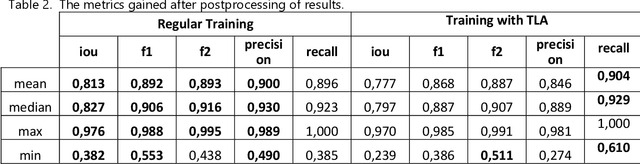
Most methods for automated full-bore rock core image analysis (description, colour, properties distribution, etc.) are based on separate core column analyses. The core is usually imaged in a box because of the significant amount of time taken to get an image for each core column. The work presents an innovative method and algorithm for core columns extraction from core boxes. The conditions for core boxes imaging may differ tremendously. Such differences are disastrous for machine learning algorithms which need a large dataset describing all possible data variations. Still, such images have some standard features - a box and core. Thus, we can emulate different environments with a unique augmentation described in this work. It is called template-like augmentation (TLA). The method is described and tested on various environments, and results are compared on an algorithm trained on both 'traditional' data and a mix of traditional and TLA data. The algorithm trained with TLA data provides better metrics and can detect core on most new images, unlike the algorithm trained on data without TLA. The algorithm for core column extraction implemented in an automated core description system speeds up the core box processing by a factor of 20.
* 20 pages, 16 figures, 1 table, the augmentation pipeline code samples published as Open-Source code for TLA at https://github.com/BEEugene/TemplateArtification/, continue of the research from arXiv:1909.10227
Phase-Based Signal Representations for Scattering
Feb 15, 2022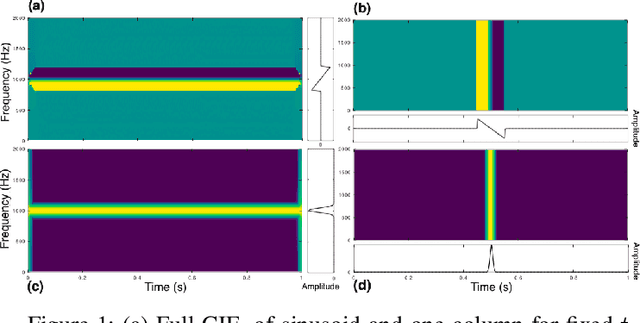
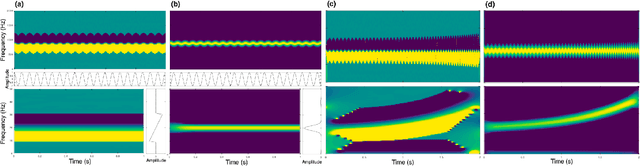
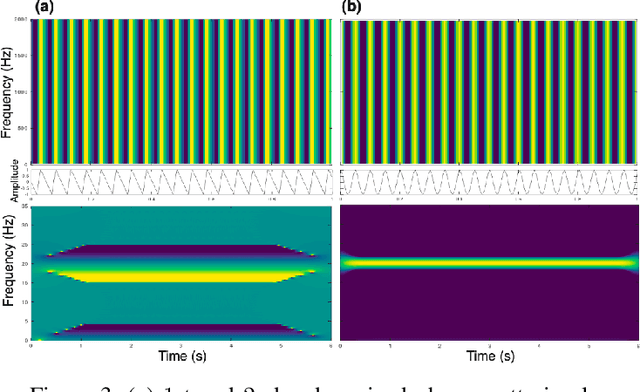
The scattering transform is a non-linear signal representation method based on cascaded wavelet transform magnitudes. In this paper we introduce phase scattering, a novel approach where we use phase derivatives in a scattering procedure. We first revisit phase-related concepts for representing time-frequency information of audio signals, in particular, the partial derivatives of the phase in the time-frequency domain. By putting analytical and numerical results in a new light, we set the basis to extend the phase-based representations to higher orders by means of a scattering transform, which leads to well localized signal representations of large-scale structures. All the ideas are introduced in a general way and then applied using the STFT.
M2N: Mesh Movement Networks for PDE Solvers
Apr 24, 2022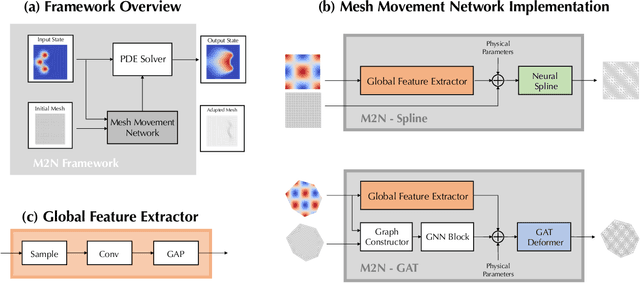
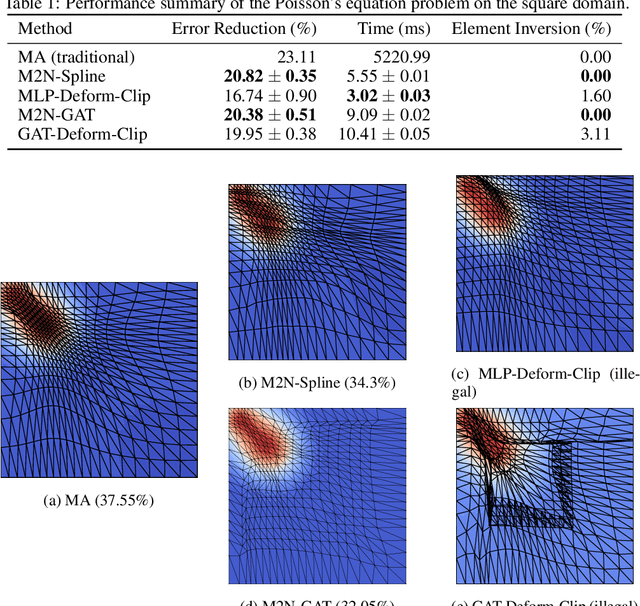
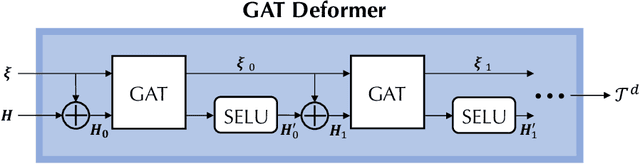
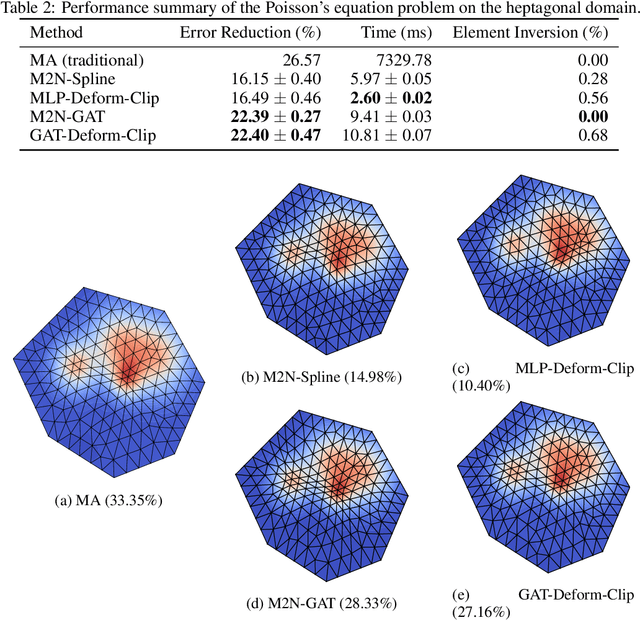
Mainstream numerical Partial Differential Equation (PDE) solvers require discretizing the physical domain using a mesh. Mesh movement methods aim to improve the accuracy of the numerical solution by increasing mesh resolution where the solution is not well-resolved, whilst reducing unnecessary resolution elsewhere. However, mesh movement methods, such as the Monge-Ampere method, require the solution of auxiliary equations, which can be extremely expensive especially when the mesh is adapted frequently. In this paper, we propose to our best knowledge the first learning-based end-to-end mesh movement framework for PDE solvers. Key requirements of learning-based mesh movement methods are alleviating mesh tangling, boundary consistency, and generalization to mesh with different resolutions. To achieve these goals, we introduce the neural spline model and the graph attention network (GAT) into our models respectively. While the Neural-Spline based model provides more flexibility for large deformation, the GAT based model can handle domains with more complicated shapes and is better at performing delicate local deformation. We validate our methods on stationary and time-dependent, linear and non-linear equations, as well as regularly and irregularly shaped domains. Compared to the traditional Monge-Ampere method, our approach can greatly accelerate the mesh adaptation process, whilst achieving comparable numerical error reduction.
Change-point Detection and Segmentation of Discrete Data using Bayesian Context Trees
Mar 08, 2022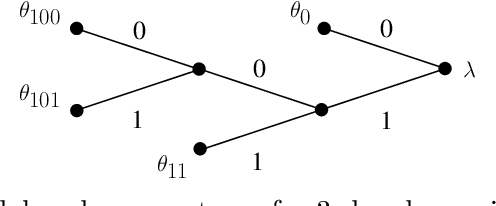
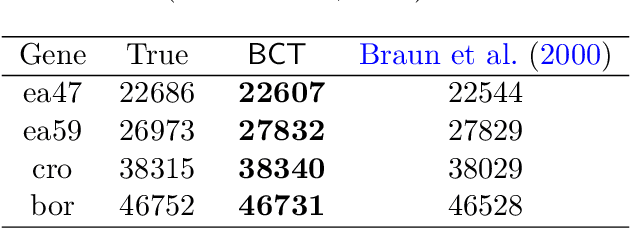
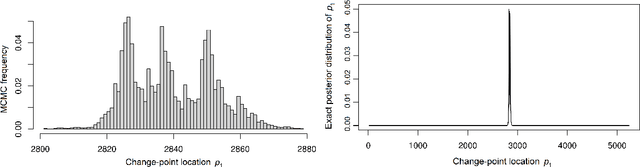
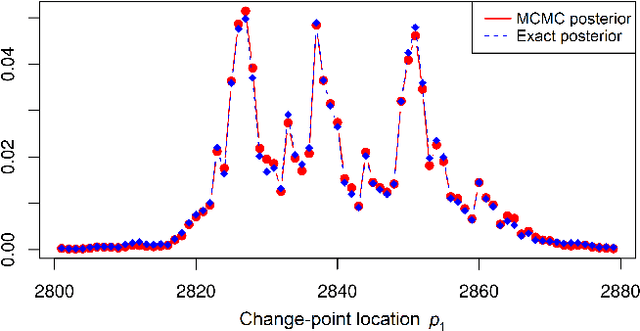
A new Bayesian modelling framework is introduced for piece-wise homogeneous variable-memory Markov chains, along with a collection of effective algorithmic tools for change-point detection and segmentation of discrete time series. Building on the recently introduced Bayesian Context Trees (BCT) framework, the distributions of different segments in a discrete time series are described as variable-memory Markov chains. Inference for the presence and location of change-points is then performed via Markov chain Monte Carlo sampling. The key observation that facilitates effective sampling is that, using one of the BCT algorithms, the prior predictive likelihood of the data can be computed exactly, integrating out all the models and parameters in each segment. This makes it possible to sample directly from the posterior distribution of the number and location of the change-points, leading to accurate estimates and providing a natural quantitative measure of uncertainty in the results. Estimates of the actual model in each segment can also be obtained, at essentially no additional computational cost. Results on both simulated and real-world data indicate that the proposed methodology performs better than or as well as state-of-the-art techniques.
Online Caching with no Regret: Optimistic Learning via Recommendations
Apr 20, 2022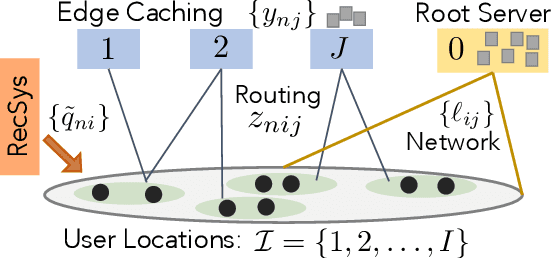
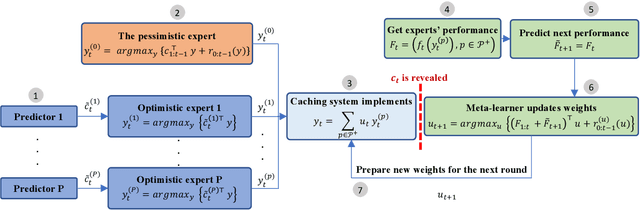
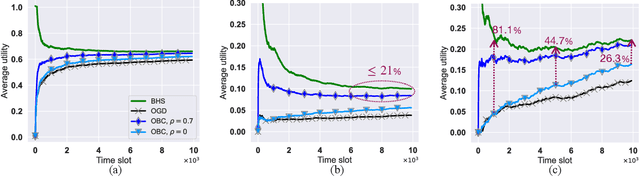
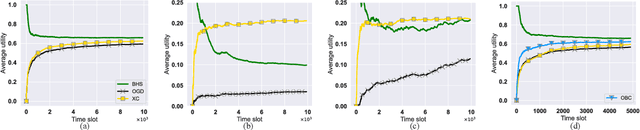
The design of effective online caching policies is an increasingly important problem for content distribution networks, online social networks and edge computing services, among other areas. This paper proposes a new algorithmic toolbox for tackling this problem through the lens of optimistic online learning. We build upon the Follow-the-Regularized-Leader (FTRL) framework, which is developed further here to include predictions for the file requests, and we design online caching algorithms for bipartite networks with fixed-size caches or elastic leased caches subject to time-average budget constraints. The predictions are provided by a content recommendation system that influences the users viewing activity and hence can naturally reduce the caching network's uncertainty about future requests. We also extend the framework to learn and utilize the best request predictor in cases where many are available. We prove that the proposed {optimistic} learning caching policies can achieve sub-zero performance loss (regret) for perfect predictions, and maintain the sub-linear regret bound $O(\sqrt T)$, which is the best achievable bound for policies that do not use predictions, even for arbitrary-bad predictions. The performance of the proposed algorithms is evaluated with detailed trace-driven numerical tests.
R3LIVE: A Robust, Real-time, RGB-colored, LiDAR-Inertial-Visual tightly-coupled state Estimation and mapping package
Sep 10, 2021
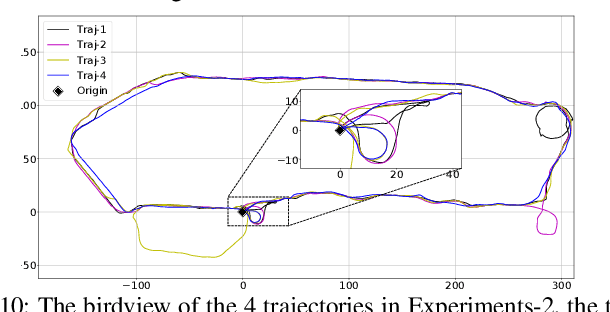
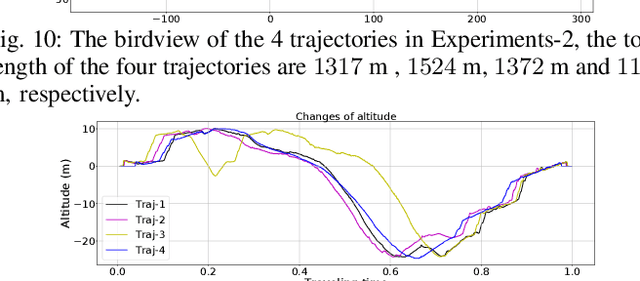
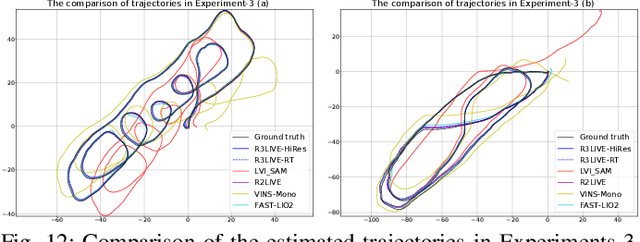
In this letter, we propose a novel LiDAR-Inertial-Visual sensor fusion framework termed R3LIVE, which takes advantage of measurement of LiDAR, inertial, and visual sensors to achieve robust and accurate state estimation. R3LIVE is contained of two subsystems, the LiDAR-inertial odometry (LIO) and visual-inertial odometry (VIO). The LIO subsystem (FAST-LIO) takes advantage of the measurement from LiDAR and inertial sensors and builds the geometry structure of (i.e. the position of 3D points) global maps. The VIO subsystem utilizes the data of visual-inertial sensors and renders the map's texture (i.e. the color of 3D points). More specifically, the VIO subsystem fuses the visual data directly and effectively by minimizing the frame-to-map photometric error. The developed system R3LIVE is developed based on our previous work R2LIVE, with careful architecture design and implementation. Experiment results show that the resultant system achieves more robustness and higher accuracy in state estimation than current counterparts (see our attached video). R3LIVE is a versatile and well-engineered system toward various possible applications, which can not only serve as a SLAM system for real-time robotic applications, but can also reconstruct the dense, precise, RGB-colored 3D maps for applications like surveying and mapping. Moreover, to make R3LIVE more extensible, we develop a series of offline utilities for reconstructing and texturing meshes, which further minimizes the gap between R3LIVE and various of 3D applications such as simulators, video games and etc (see our demos video). To share our findings and make contributions to the community, we open source R3LIVE on our Github, including all of our codes, software utilities, and the mechanical design of our device.
Towards A COLREGs Compliant Autonomous Surface Vessel in a Constrained Channel
Apr 27, 2022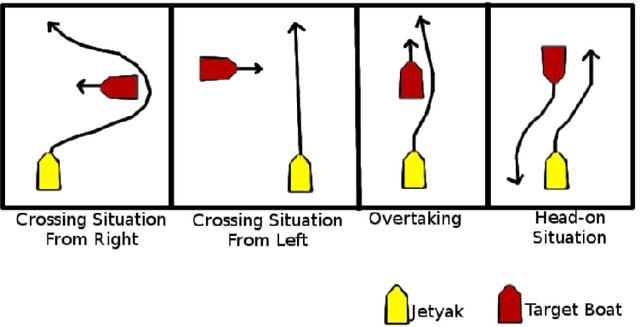
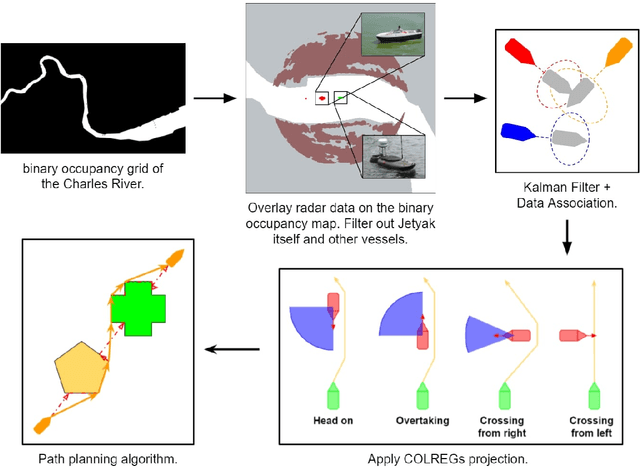

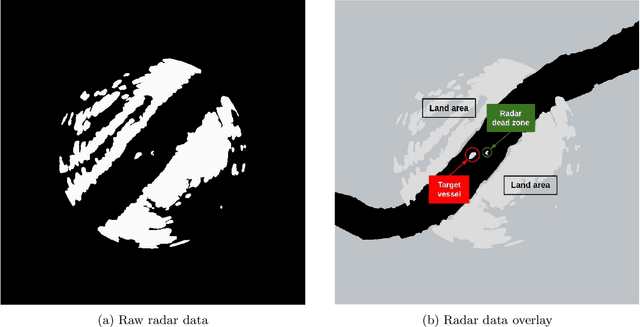
In this paper, we look at the role of autonomous navigation in the maritime domain. Specifically, we examine how an Autonomous Surface Vessel(ASV) can achieve obstacle avoidance based on the Convention on the International Regulations for Preventing Collisions at Sea (1972), or COLREGs, in real-world environments. Our ASV is equipped with a broadband marine radar, an Inertial Navigation System (INS), and uses official Electronic Navigational Charts (ENC). These sensors are used to provide situational awareness and, in series of well-defined steps, we can exclude land objects from the radar data, extract tracks associated with moving vessels within range of the radar, and then use a Kalman Filter to track and predict the motion of other moving vessels in the vicinity. A Constant Velocity model for the Kalman Filter allows us to solve the data association to build a consistent model between successive radar scans. We account for multiple COLREGs situations based on the predicted relative motion. Finally, an efficient path planning algorithm is presented to find a path and publish waypoints to perform real-time COLREGs compliant autonomous navigation within highly constrained environments. We demonstrate the results of our framework with operational results collected over the course of a 3.4 nautical mile mission on the Charles River in Boston in which the ASV encountered and successfully navigated multiple scenarios and encounters with other moving vessels at close quarters.
Automatic spinal curvature measurement on ultrasound spine images using Faster R-CNN
Apr 20, 2022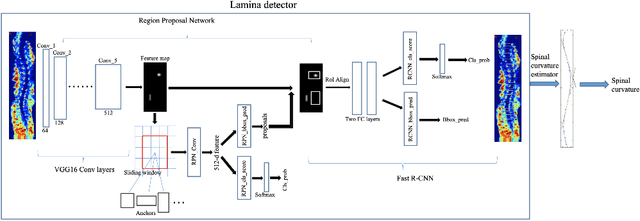
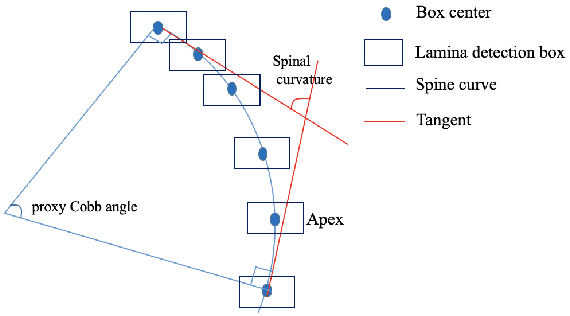
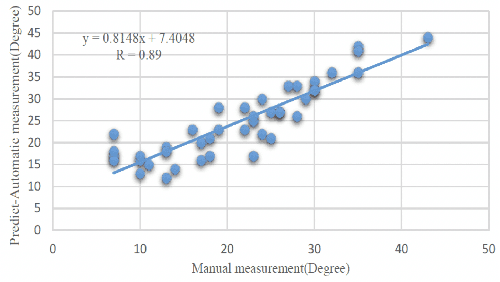
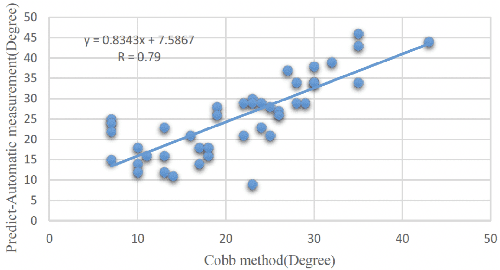
Ultrasound spine imaging technique has been applied to the assessment of spine deformity. However, manual measurements of scoliotic angles on ultrasound images are time-consuming and heavily rely on raters experience. The objectives of this study are to construct a fully automatic framework based on Faster R-CNN for detecting vertebral lamina and to measure the fitting spinal curves from the detected lamina pairs. The framework consisted of two closely linked modules: 1) the lamina detector for identifying and locating each lamina pairs on ultrasound coronal images, and 2) the spinal curvature estimator for calculating the scoliotic angles based on the chain of detected lamina. Two hundred ultrasound images obtained from AIS patients were identified and used for the training and evaluation of the proposed method. The experimental results showed the 0.76 AP on the test set, and the Mean Absolute Difference (MAD) between automatic and manual measurement which was within the clinical acceptance error. Meanwhile the correlation between automatic measurement and Cobb angle from radiographs was 0.79. The results revealed that our proposed technique could provide accurate and reliable automatic curvature measurements on ultrasound spine images for spine deformities.
Locate This, Not That: Class-Conditioned Sound Event DOA Estimation
Mar 08, 2022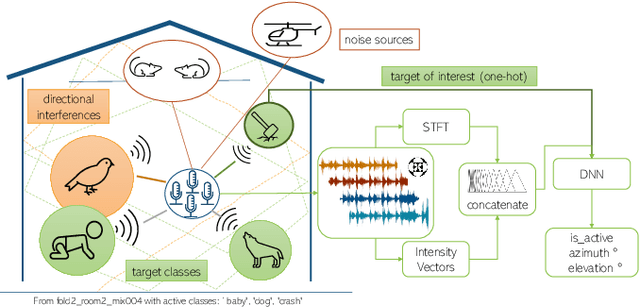
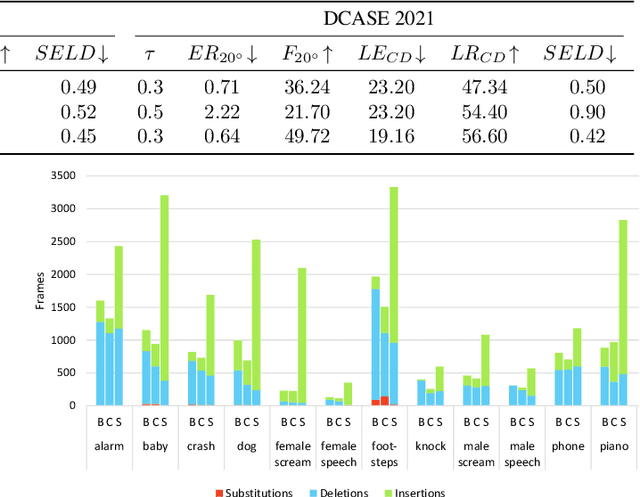
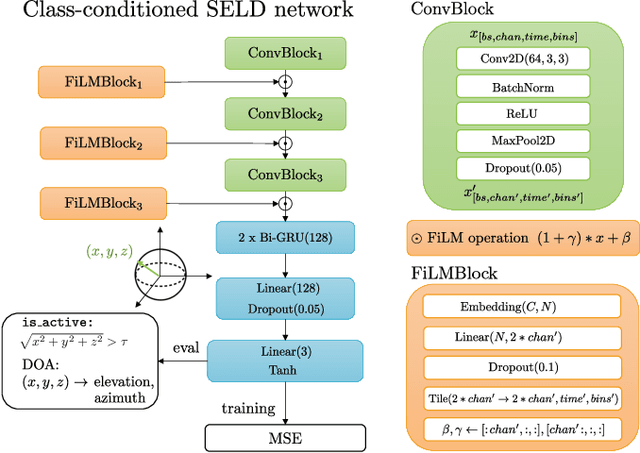
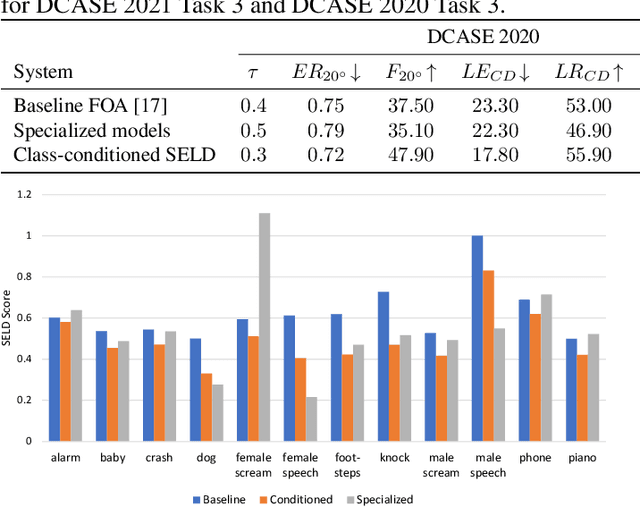
Existing systems for sound event localization and detection (SELD) typically operate by estimating a source location for all classes at every time instant. In this paper, we propose an alternative class-conditioned SELD model for situations where we may not be interested in localizing all classes all of the time. This class-conditioned SELD model takes as input the spatial and spectral features from the sound file, and also a one-hot vector indicating the class we are currently interested in localizing. We inject the conditioning information at several points in our model using feature-wise linear modulation (FiLM) layers. Through experiments on the DCASE 2020 Task 3 dataset, we show that the proposed class-conditioned SELD model performs better in terms of common SELD metrics than the baseline model that locates all classes simultaneously, and also outperforms specialist models that are trained to locate only a single class of interest. We also evaluate performance on the DCASE 2021 Task 3 dataset, which includes directional interference (sound events from classes we are not interested in localizing) and notice especially strong improvement from the class-conditioned model.
Detecting GAN-generated Images by Orthogonal Training of Multiple CNNs
Mar 04, 2022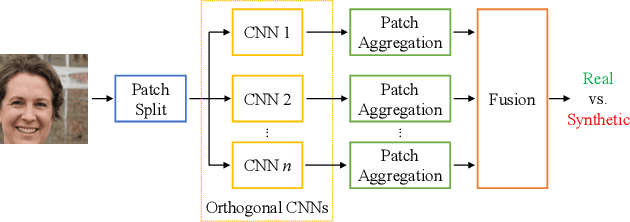
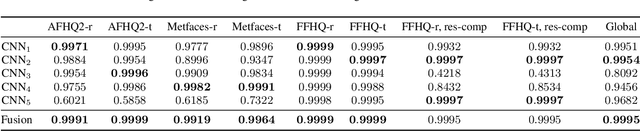
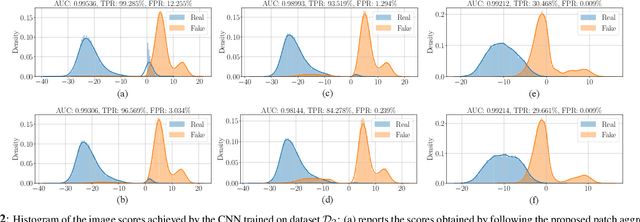
In the last few years, we have witnessed the rise of a series of deep learning methods to generate synthetic images that look extremely realistic. These techniques prove useful in the movie industry and for artistic purposes. However, they also prove dangerous if used to spread fake news or to generate fake online accounts. For this reason, detecting if an image is an actual photograph or has been synthetically generated is becoming an urgent necessity. This paper proposes a detector of synthetic images based on an ensemble of Convolutional Neural Networks (CNNs). We consider the problem of detecting images generated with techniques not available at training time. This is a common scenario, given that new image generators are published more and more frequently. To solve this issue, we leverage two main ideas: (i) CNNs should provide orthogonal results to better contribute to the ensemble; (ii) original images are better defined than synthetic ones, thus they should be better trusted at testing time. Experiments show that pursuing these two ideas improves the detector accuracy on NVIDIA's newly generated StyleGAN3 images, never used in training.