 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Single-pixel imaging based on weight sort of the Hadamard basis
Mar 09, 2022
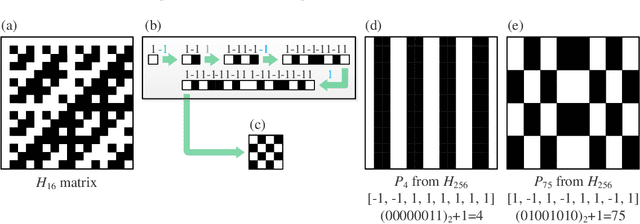
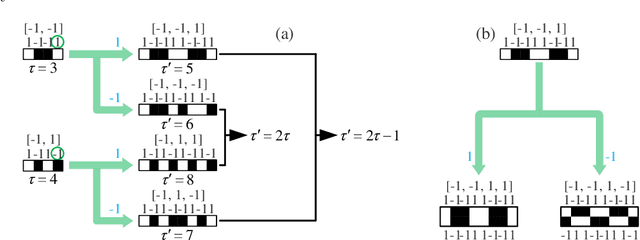

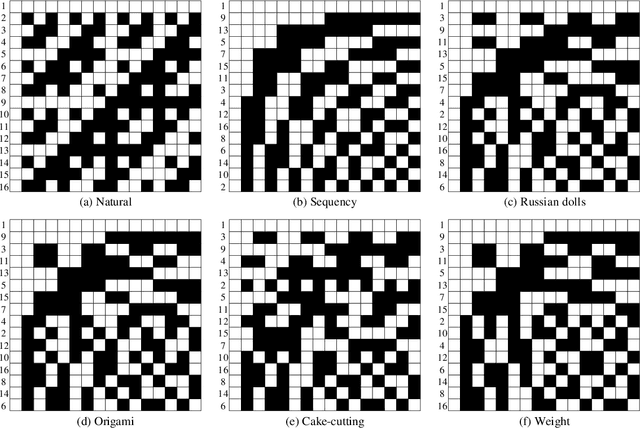
Single-pixel imaging (SPI) is very popular in subsampling applications, but the random measurement matrices it typically uses will lead to measurement blindness as well as difficulties in calculation and storage, and will also limit the further reduction in sampling rate. The deterministic Hadamard basis has become an alternative choice due to its orthogonality and structural characteristics. There is evidence that sorting the Hadamard basis is beneficial to further reduce the sampling rate, thus many orderings have emerged, but their relations remain unclear and lack a unified theory. Given this, here we specially propose a concept named selection history, which can record the Hadamard spatial folding process, and build a model based on it to reveal the formation mechanisms of different orderings and to deduce the mutual conversion relationship among them. Then, a weight ordering of the Hadamard basis is proposed. Both numerical simulation and experimental results have demonstrated that with this weight sort technique, the sampling rate, reconstruction time and matrix memory consumption are greatly reduced in comparison to traditional sorting methods. Therefore, we believe that this method may pave the way for real-time single-pixel imaging.
Event-based Navigation for Autonomous Drone Racing with Sparse Gated Recurrent Network
Apr 05, 2022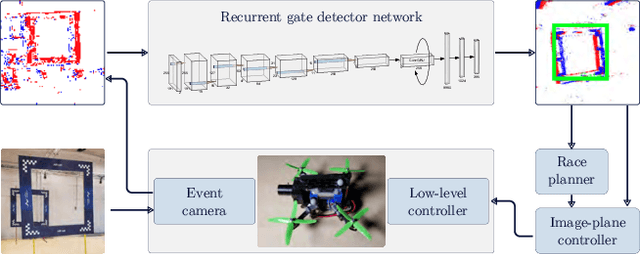

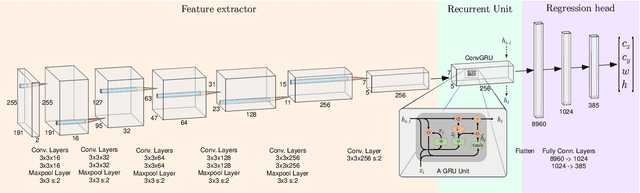
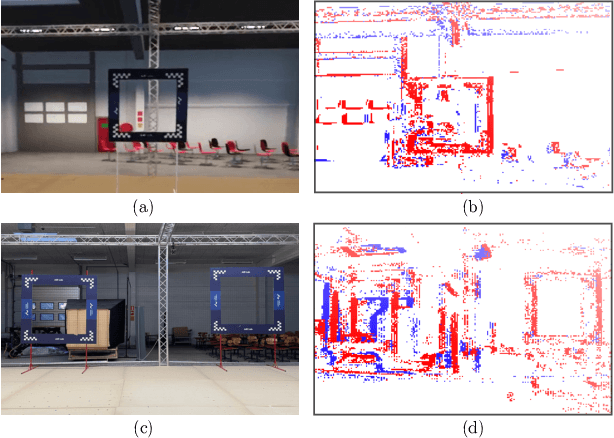
Event-based vision has already revolutionized the perception task for robots by promising faster response, lower energy consumption, and lower bandwidth without introducing motion blur. In this work, a novel deep learning method based on gated recurrent units utilizing sparse convolutions for detecting gates in a race track is proposed using event-based vision for the autonomous drone racing problem. We demonstrate the efficiency and efficacy of the perception pipeline on a real robot platform that can safely navigate a typical autonomous drone racing track in real-time. Throughout the experiments, we show that the event-based vision with the proposed gated recurrent unit and pretrained models on simulated event data significantly improve the gate detection precision. Furthermore, an event-based drone racing dataset consisting of both simulated and real data sequences is publicly released.
STONet: A Neural-Operator-Driven Spatio-temporal Network
Apr 21, 2022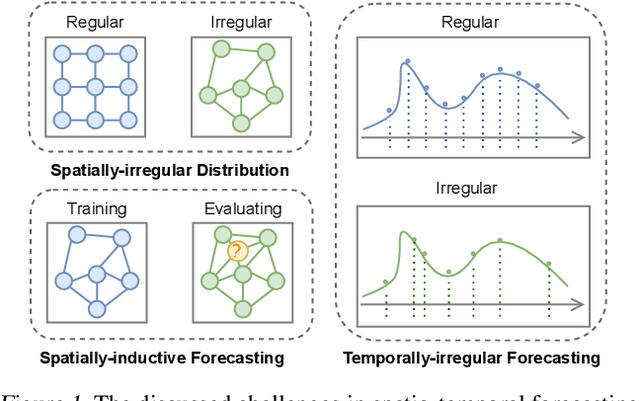
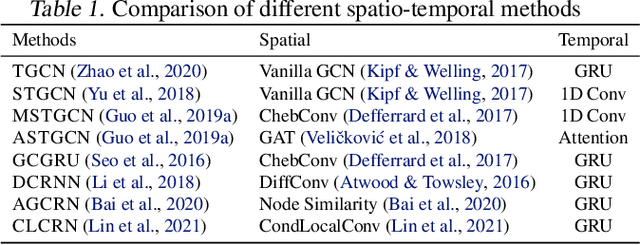
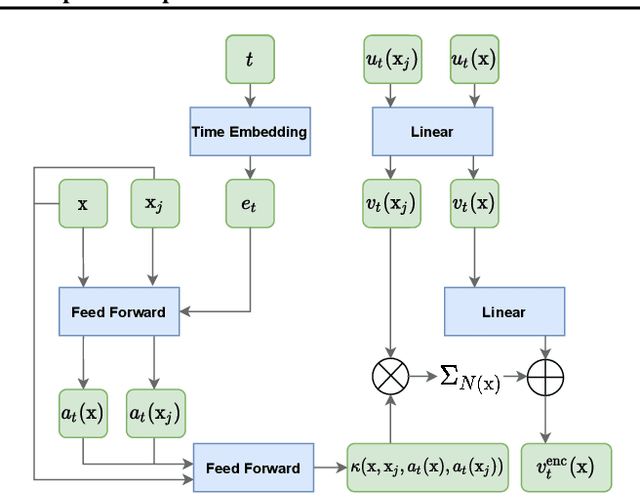

Graph-based spatio-temporal neural networks are effective to model the spatial dependency among discrete points sampled irregularly from unstructured grids, thanks to the great expressiveness of graph neural networks. However, these models are usually spatially-transductive -- only fitting the signals for discrete spatial nodes fed in models but unable to generalize to `unseen' spatial points with zero-shot. In comparison, for forecasting tasks on continuous space such as temperature prediction on the earth's surface, the \textit{spatially-inductive} property allows the model to generalize to any point in the spatial domain, demonstrating models' ability to learn the underlying mechanisms or physics laws of the systems, rather than simply fit the signals. Besides, in temporal domains, \textit{irregularly-sampled} time series, e.g. data with missing values, urge models to be temporally-continuous. Motivated by the two issues, we propose a spatio-temporal framework based on neural operators for PDEs, which learn the underlying mechanisms governing the dynamics of spatially-continuous physical quantities. Experiments show our model's improved performance on forecasting spatially-continuous physic quantities, and its superior generalization to unseen spatial points and ability to handle temporally-irregular data.
Supporting Complex Information-Seeking Tasks with Implicit Constraints
May 02, 2022
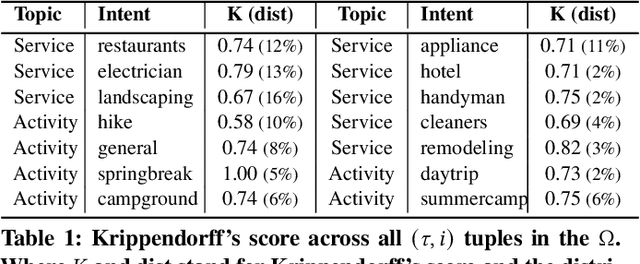
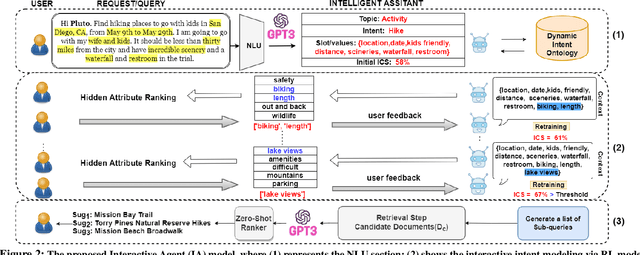
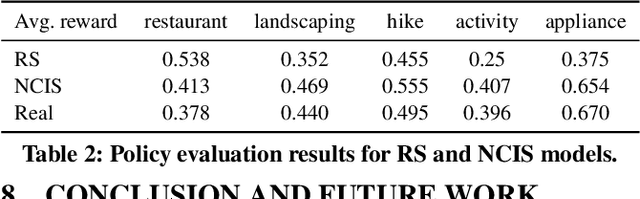
Current interactive systems with natural language interface lack an ability to understand a complex information-seeking request which expresses several implicit constraints at once, and there is no prior information about user preferences, e.g., "find hiking trails around San Francisco which are accessible with toddlers and have beautiful scenery in summer", where output is a list of possible suggestions for users to start their exploration. In such scenarios, the user requests can be issued at once in the form of a complex and long query, unlike conversational and exploratory search models that require short utterances or queries where they often require to be fed into the system step by step. This advancement provides the final user more flexibility and precision in expressing their intent through the search process. Such systems are inherently helpful for day-today user tasks requiring planning that are usually time-consuming, sometimes tricky, and cognitively taxing. We have designed and deployed a platform to collect the data from approaching such complex interactive systems. In this paper, we propose an Interactive Agent (IA) that allows intricately refined user requests by making it complete, which should lead to better retrieval. To demonstrate the performance of the proposed modeling paradigm, we have adopted various pre-retrieval metrics that capture the extent to which guided interactions with our system yield better retrieval results. Through extensive experimentation, we demonstrated that our method significantly outperforms several robust baselines
Time-Series Imputation with Wasserstein Interpolation for Optimal Look-Ahead-Bias and Variance Tradeoff
Feb 25, 2021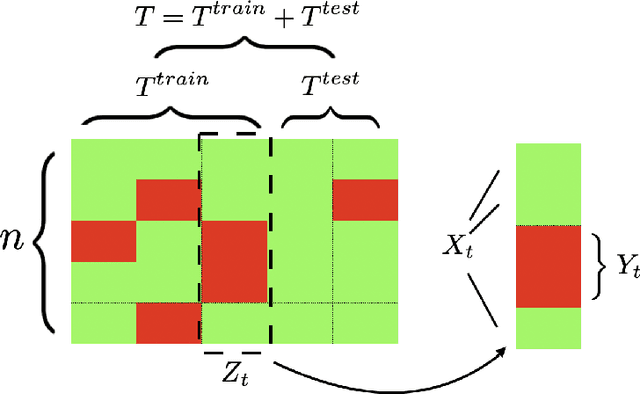
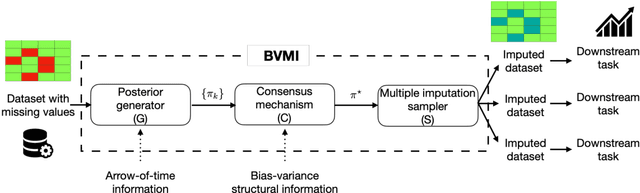
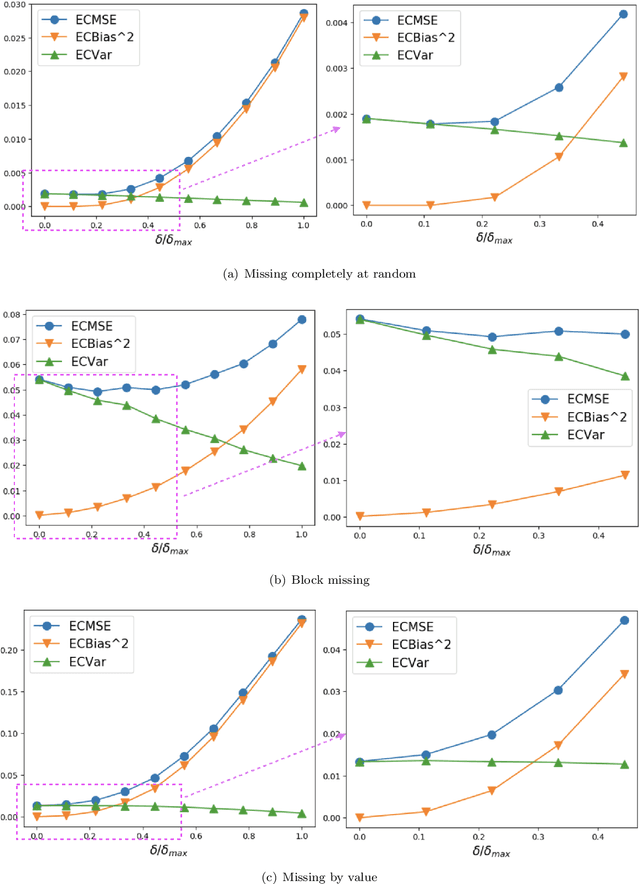
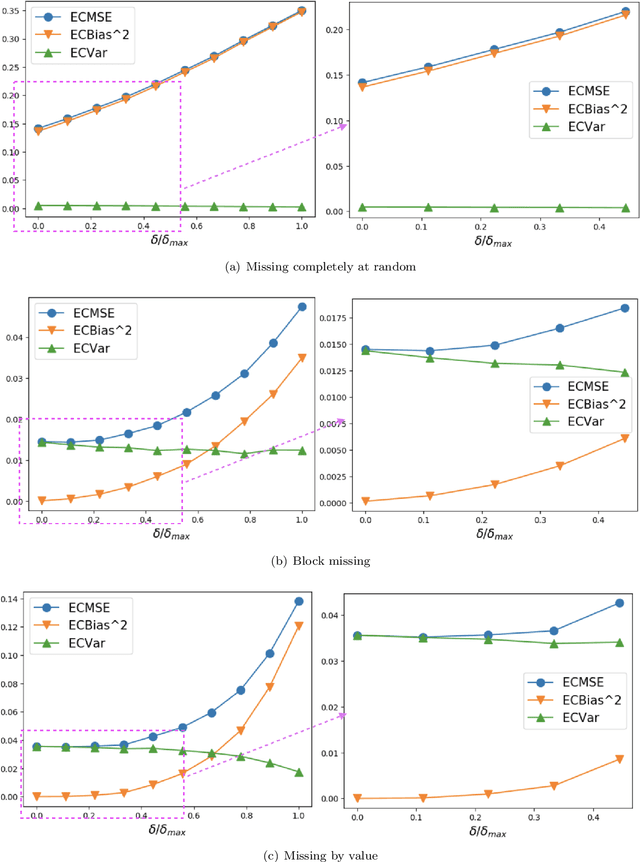
Missing time-series data is a prevalent practical problem. Imputation methods in time-series data often are applied to the full panel data with the purpose of training a model for a downstream out-of-sample task. For example, in finance, imputation of missing returns may be applied prior to training a portfolio optimization model. Unfortunately, this practice may result in a look-ahead-bias in the future performance on the downstream task. There is an inherent trade-off between the look-ahead-bias of using the full data set for imputation and the larger variance in the imputation from using only the training data. By connecting layers of information revealed in time, we propose a Bayesian posterior consensus distribution which optimally controls the variance and look-ahead-bias trade-off in the imputation. We demonstrate the benefit of our methodology both in synthetic and real financial data.
A machine learning-based framework for high resolution mapping of PM2.5 in Tehran, Iran, using MAIAC AOD data
Apr 05, 2022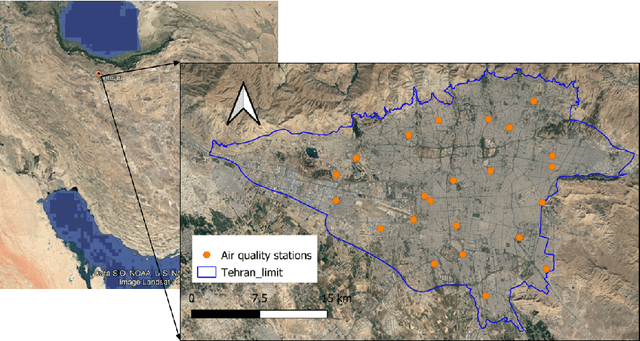
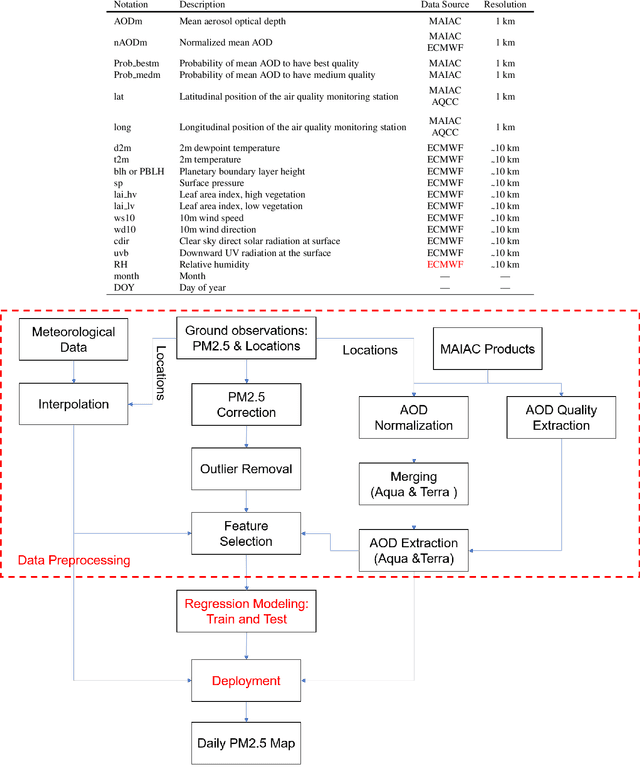

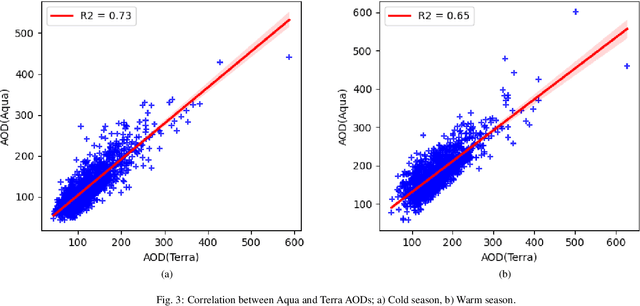
This paper investigates the possibility of high resolution mapping of PM2.5 concentration over Tehran city using high resolution satellite AOD (MAIAC) retrievals. For this purpose, a framework including three main stages, data preprocessing; regression modeling; and model deployment was proposed. The output of the framework was a machine learning model trained to predict PM2.5 from MAIAC AOD retrievals and meteorological data. The results of model testing revealed the efficiency and capability of the developed framework for high resolution mapping of PM2.5, which was not realized in former investigations performed over the city. Thus, this study, for the first time, realized daily, 1 km resolution mapping of PM2.5 in Tehran with R2 around 0.74 and RMSE better than 9.0 mg/m3. Keywords: MAIAC; MODIS; AOD; Machine learning; Deep learning; PM2.5; Regression
Integrated In-vehicle Monitoring System Using 3D Human Pose Estimation and Seat Belt Segmentation
Apr 17, 2022

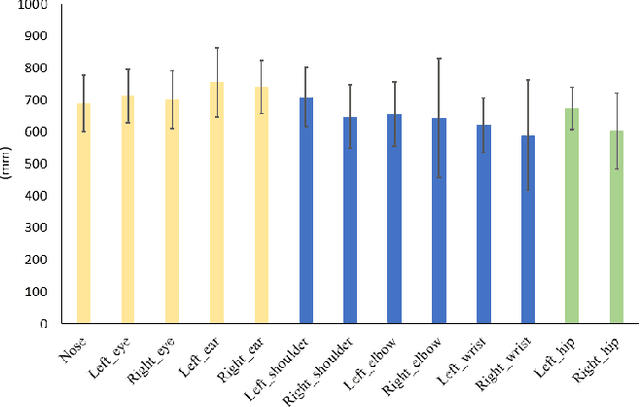
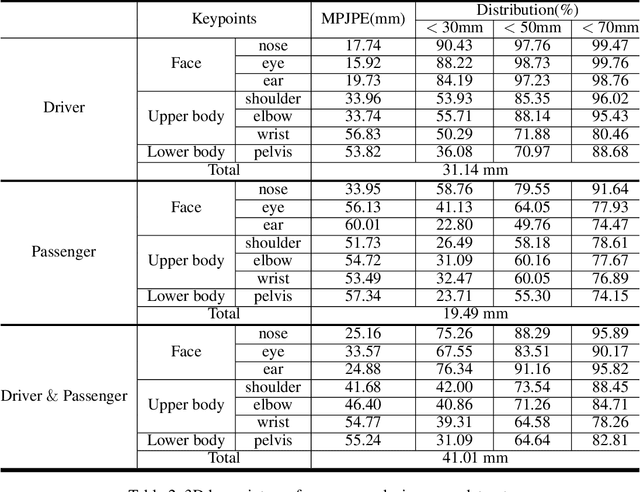
Recently, along with interest in autonomous vehicles, the importance of monitoring systems for both drivers and passengers inside vehicles has been increasing. This paper proposes a novel in-vehicle monitoring system the combines 3D pose estimation, seat-belt segmentation, and seat-belt status classification networks. Our system outputs various information necessary for monitoring by accurately considering the data characteristics of the in-vehicle environment. Specifically, the proposed 3D pose estimation directly estimates the absolute coordinates of keypoints for a driver and passengers, and the proposed seat-belt segmentation is implemented by applying a structure based on the feature pyramid. In addition, we propose a classification task to distinguish between normal and abnormal states of wearing a seat belt using results that combine 3D pose estimation with seat-belt segmentation. These tasks can be learned simultaneously and operate in real-time. Our method was evaluated on a private dataset we newly created and annotated. The experimental results show that our method has significantly high performance that can be applied directly to real in-vehicle monitoring systems.
Learning to Generalize across Domains on Single Test Samples
Feb 16, 2022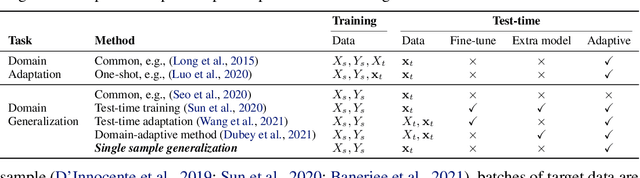
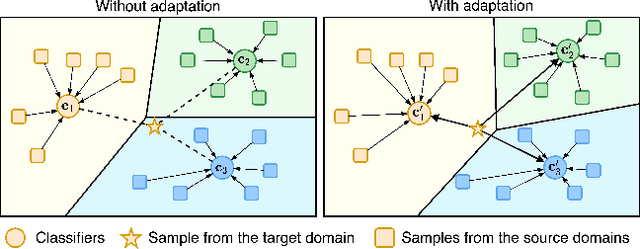
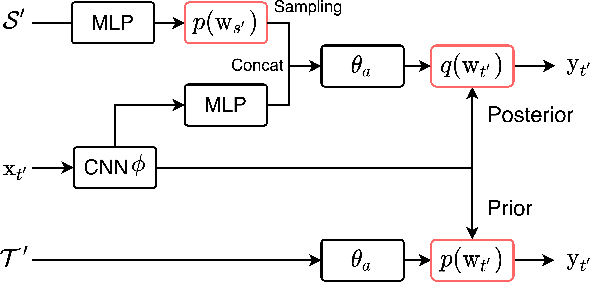
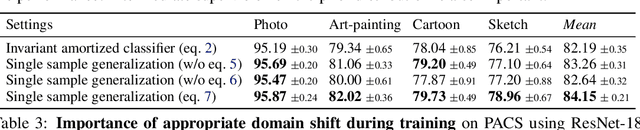
We strive to learn a model from a set of source domains that generalizes well to unseen target domains. The main challenge in such a domain generalization scenario is the unavailability of any target domain data during training, resulting in the learned model not being explicitly adapted to the unseen target domains. We propose learning to generalize across domains on single test samples. We leverage a meta-learning paradigm to learn our model to acquire the ability of adaptation with single samples at training time so as to further adapt itself to each single test sample at test time. We formulate the adaptation to the single test sample as a variational Bayesian inference problem, which incorporates the test sample as a conditional into the generation of model parameters. The adaptation to each test sample requires only one feed-forward computation at test time without any fine-tuning or self-supervised training on additional data from the unseen domains. Extensive ablation studies demonstrate that our model learns the ability to adapt models to each single sample by mimicking domain shifts during training. Further, our model achieves at least comparable -- and often better -- performance than state-of-the-art methods on multiple benchmarks for domain generalization.
Active Self-Semi-Supervised Learning for Few Labeled Samples Fast Training
Mar 09, 2022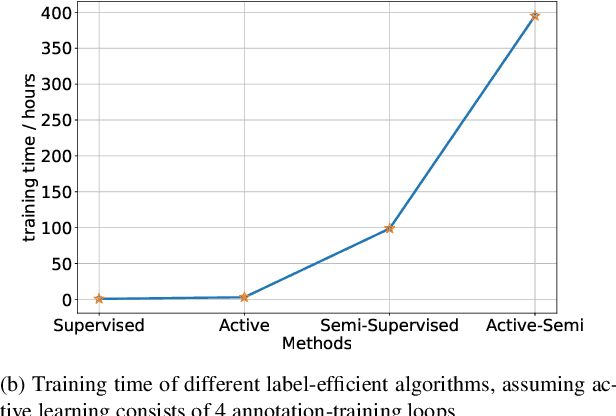
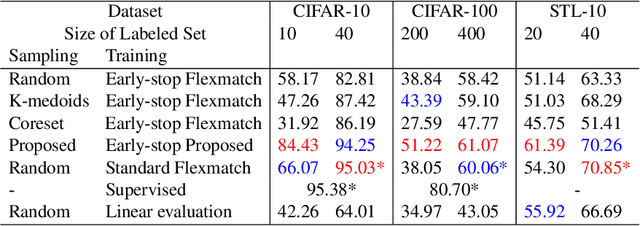
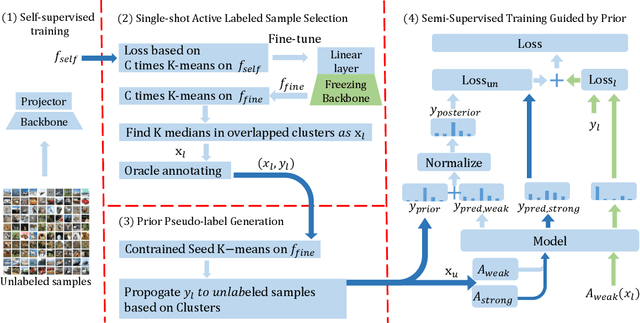

Faster training and fewer annotations are two key issues for applying deep models to various practical domains. Now, semi-supervised learning has achieved great success in training with few annotations. However, low-quality labeled samples produced by random sampling make it difficult to continue to reduce the number of annotations. In this paper we propose an active self-semi-supervised training framework that bootstraps semi-supervised models with good prior pseudo-labels, where the priors are obtained by label propagation over self-supervised features. Because the accuracy of the prior is not only affected by the quality of features, but also by the selection of the labeled samples. We develop active learning and label propagation strategies to obtain better prior pseudo-labels. Consequently, our framework can greatly improve the performance of models with few annotations and greatly reduce the training time. Experiments on three semi-supervised learning benchmarks demonstrate effectiveness. Our method achieves similar accuracy to standard semi-supervised approaches in about 1/3 of the training time, and even outperform them when fewer annotations are available (84.10\% in CIFAR-10 with 10 labels).
Global-Supervised Contrastive Loss and View-Aware-Based Post-Processing for Vehicle Re-Identification
Apr 17, 2022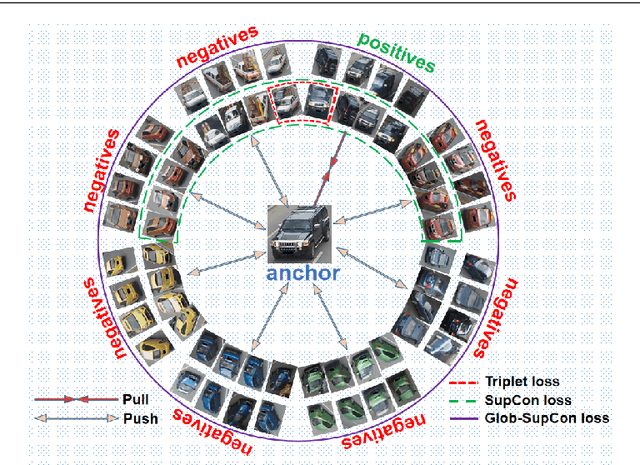
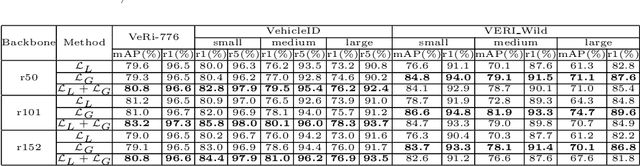


In this paper, we propose a Global-Supervised Contrastive loss and a view-aware-based post-processing (VABPP) method for the field of vehicle re-identification. The traditional supervised contrastive loss calculates the distances of features within the batch, so it has the local attribute. While the proposed Global-Supervised Contrastive loss has new properties and has good global attributes, the positive and negative features of each anchor in the training process come from the entire training set. The proposed VABPP method is the first time that the view-aware-based method is used as a post-processing method in the field of vehicle re-identification. The advantages of VABPP are that, first, it is only used during testing and does not affect the training process. Second, as a post-processing method, it can be easily integrated into other trained re-id models. We directly apply the view-pair distance scaling coefficient matrix calculated by the model trained in this paper to another trained re-id model, and the VABPP method greatly improves its performance, which verifies the feasibility of the VABPP method.