 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Event-based Navigation for Autonomous Drone Racing with Sparse Gated Recurrent Network
Apr 05, 2022
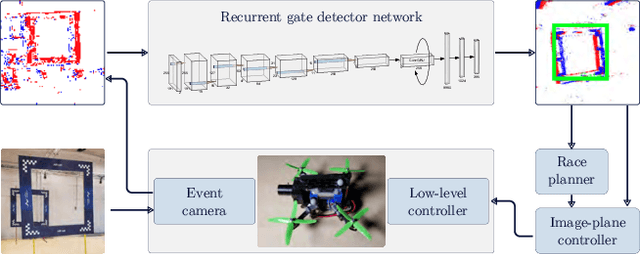

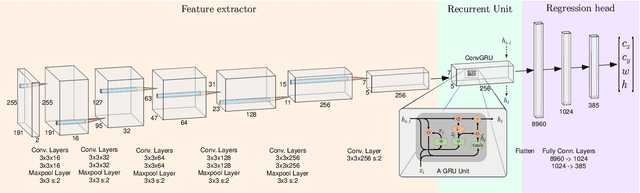
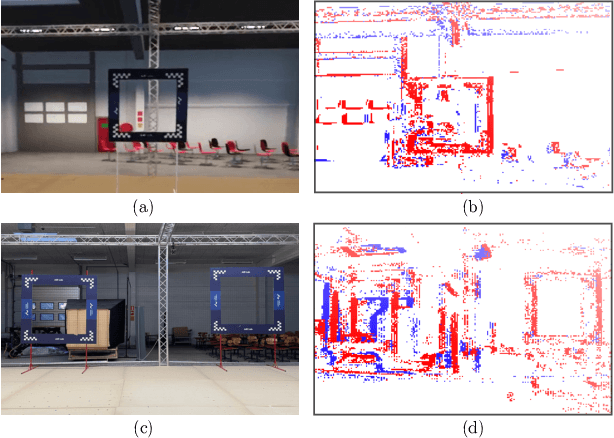
Event-based vision has already revolutionized the perception task for robots by promising faster response, lower energy consumption, and lower bandwidth without introducing motion blur. In this work, a novel deep learning method based on gated recurrent units utilizing sparse convolutions for detecting gates in a race track is proposed using event-based vision for the autonomous drone racing problem. We demonstrate the efficiency and efficacy of the perception pipeline on a real robot platform that can safely navigate a typical autonomous drone racing track in real-time. Throughout the experiments, we show that the event-based vision with the proposed gated recurrent unit and pretrained models on simulated event data significantly improve the gate detection precision. Furthermore, an event-based drone racing dataset consisting of both simulated and real data sequences is publicly released.
Global-Supervised Contrastive Loss and View-Aware-Based Post-Processing for Vehicle Re-Identification
Apr 17, 2022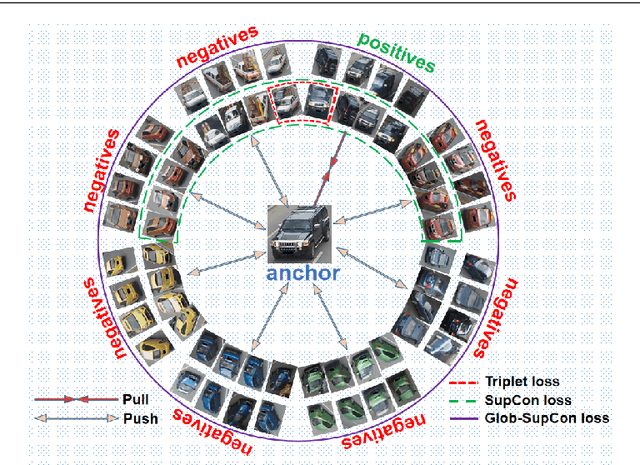
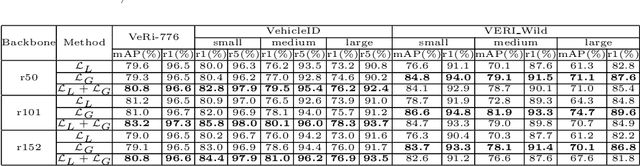


In this paper, we propose a Global-Supervised Contrastive loss and a view-aware-based post-processing (VABPP) method for the field of vehicle re-identification. The traditional supervised contrastive loss calculates the distances of features within the batch, so it has the local attribute. While the proposed Global-Supervised Contrastive loss has new properties and has good global attributes, the positive and negative features of each anchor in the training process come from the entire training set. The proposed VABPP method is the first time that the view-aware-based method is used as a post-processing method in the field of vehicle re-identification. The advantages of VABPP are that, first, it is only used during testing and does not affect the training process. Second, as a post-processing method, it can be easily integrated into other trained re-id models. We directly apply the view-pair distance scaling coefficient matrix calculated by the model trained in this paper to another trained re-id model, and the VABPP method greatly improves its performance, which verifies the feasibility of the VABPP method.
A machine learning-based framework for high resolution mapping of PM2.5 in Tehran, Iran, using MAIAC AOD data
Apr 05, 2022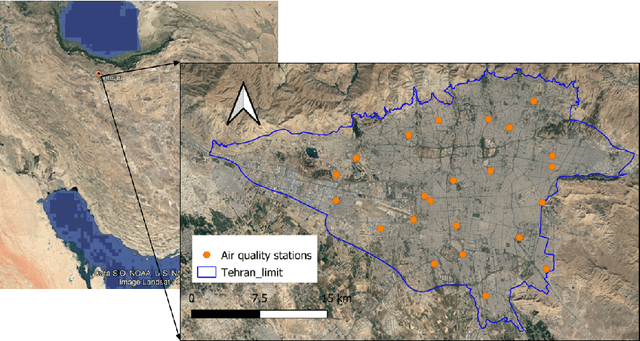
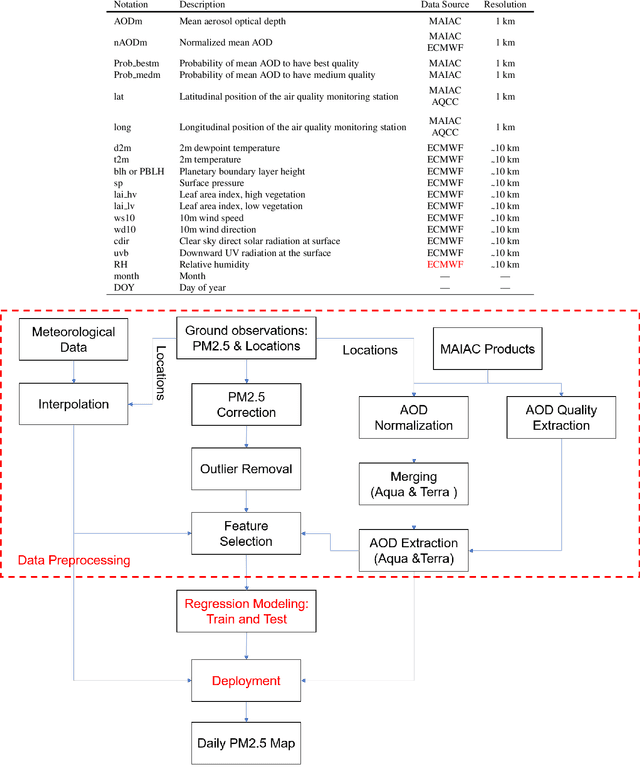

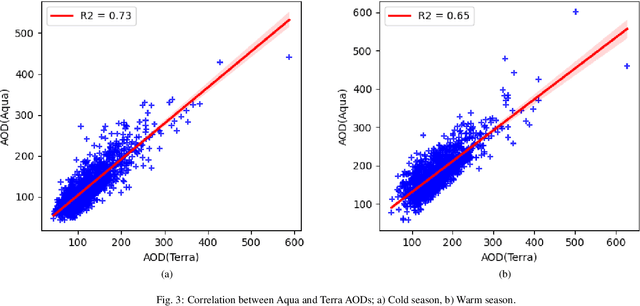
This paper investigates the possibility of high resolution mapping of PM2.5 concentration over Tehran city using high resolution satellite AOD (MAIAC) retrievals. For this purpose, a framework including three main stages, data preprocessing; regression modeling; and model deployment was proposed. The output of the framework was a machine learning model trained to predict PM2.5 from MAIAC AOD retrievals and meteorological data. The results of model testing revealed the efficiency and capability of the developed framework for high resolution mapping of PM2.5, which was not realized in former investigations performed over the city. Thus, this study, for the first time, realized daily, 1 km resolution mapping of PM2.5 in Tehran with R2 around 0.74 and RMSE better than 9.0 mg/m3. Keywords: MAIAC; MODIS; AOD; Machine learning; Deep learning; PM2.5; Regression
List-Mode PET Image Reconstruction Using Deep Image Prior
Apr 28, 2022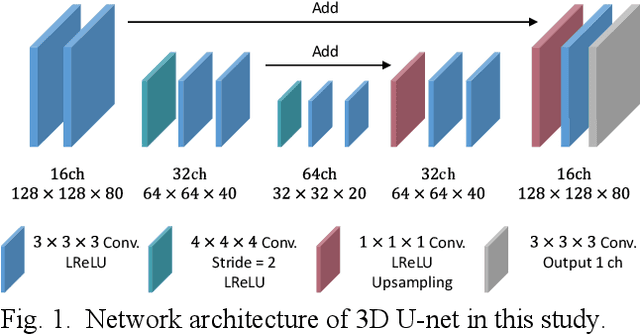
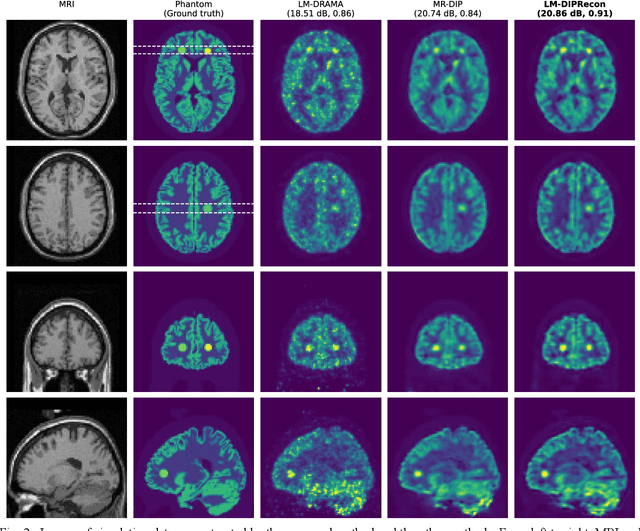
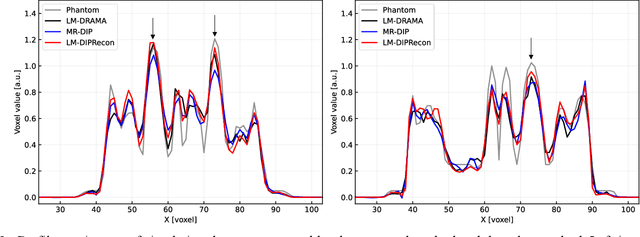
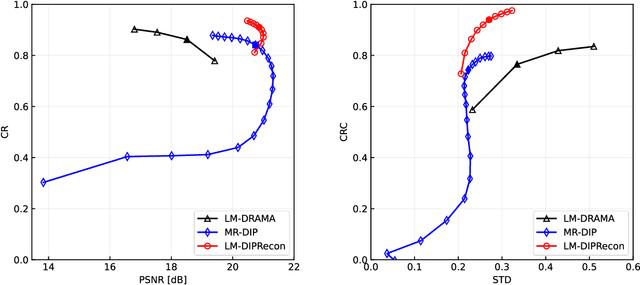
List-mode positron emission tomography (PET) image reconstruction is an important tool for PET scanners with many lines-of-response (LORs) and additional information such as time-of-flight and depth-of-interaction. Deep learning is one possible solution to enhance the quality of PET image reconstruction. However, the application of deep learning techniques to list-mode PET image reconstruction have not been progressed because list data is a sequence of bit codes and unsuitable for processing by convolutional neural networks (CNN). In this study, we propose a novel list-mode PET image reconstruction method using an unsupervised CNN called deep image prior (DIP) and a framework of alternating direction method of multipliers. The proposed list-mode DIP reconstruction (LM-DIPRecon) method alternatively iterates regularized list-mode dynamic row action maximum likelihood algorithm (LM-DRAMA) and magnetic resonance imaging conditioned DIP (MR-DIP). We evaluated LM-DIPRecon using both simulation and clinical data, and it achieved sharper images and better tradeoff curves between contrast and noise than the LM-DRAMA and MR-DIP. These results indicated that the LM-DIPRecon is useful for quantitative PET imaging with limited events. In addition, as list data has finer temporal information than dynamic sinograms, list-mode deep image prior reconstruction is expected to be useful for 4D PET imaging and motion correction.
MAP-SNN: Mapping Spike Activities with Multiplicity, Adaptability, and Plasticity into Bio-Plausible Spiking Neural Networks
Apr 21, 2022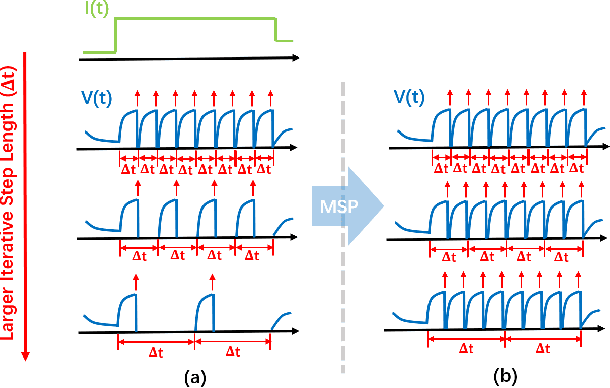
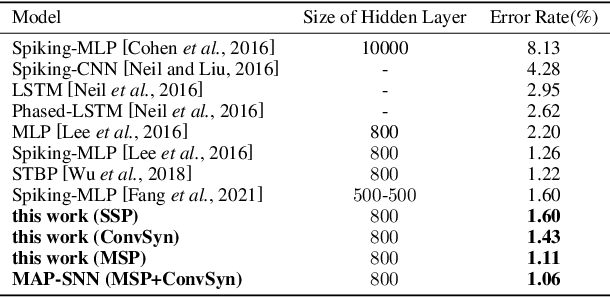
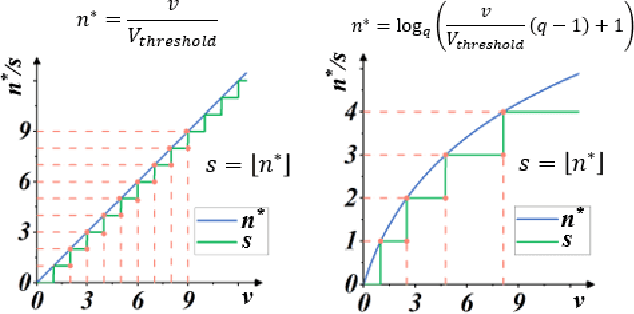
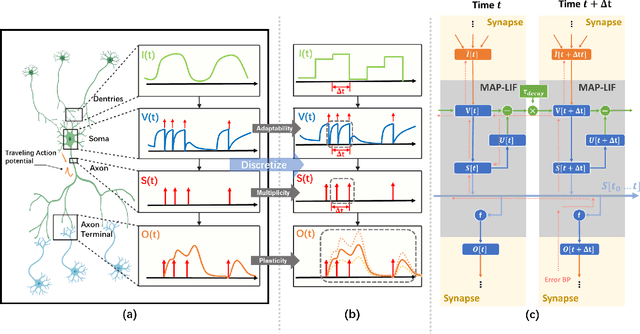
Spiking Neural Network (SNN) is considered more biologically realistic and power-efficient as it imitates the fundamental mechanism of the human brain. Recently, backpropagation (BP) based SNN learning algorithms that utilize deep learning frameworks have achieved good performance. However, bio-interpretability is partially neglected in those BP-based algorithms. Toward bio-plausible BP-based SNNs, we consider three properties in modeling spike activities: Multiplicity, Adaptability, and Plasticity (MAP). In terms of multiplicity, we propose a Multiple-Spike Pattern (MSP) with multiple spike transmission to strengthen model robustness in discrete time-iteration. To realize adaptability, we adopt Spike Frequency Adaption (SFA) under MSP to decrease spike activities for improved efficiency. For plasticity, we propose a trainable convolutional synapse that models spike response current to enhance the diversity of spiking neurons for temporal feature extraction. The proposed SNN model achieves competitive performances on neuromorphic datasets: N-MNIST and SHD. Furthermore, experimental results demonstrate that the proposed three aspects are significant to iterative robustness, spike efficiency, and temporal feature extraction capability of spike activities. In summary, this work proposes a feasible scheme for bio-inspired spike activities with MAP, offering a new neuromorphic perspective to embed biological characteristics into spiking neural networks.
Real-time Outdoor Localization Using Radio Maps: A Deep Learning Approach
Jun 23, 2021
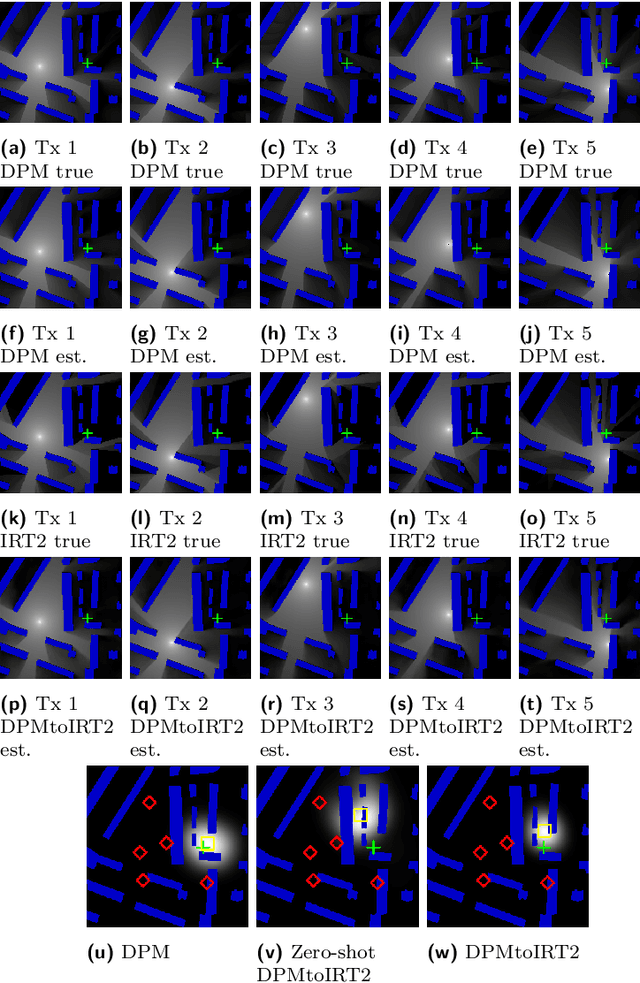
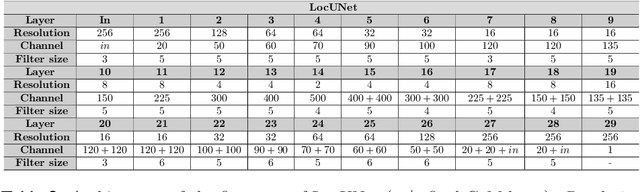
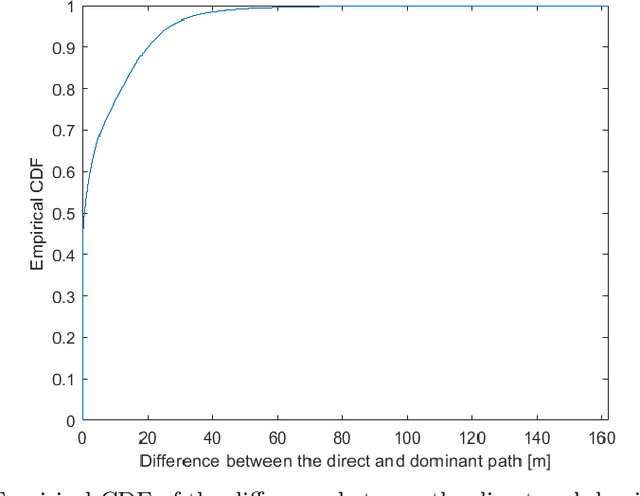
This paper deals with the problem of localization in a cellular network in a dense urban scenario. Global Navigation Satellite Systems typically perform poorly in urban environments, where the likelihood of line-of-sight conditions between the devices and the satellites is low, and thus alternative localization methods are required for good accuracy. We present a deep learning method for localization, based merely on pathloss, which does not require any increase in computation complexity at the user devices with respect to the device standard operations, unlike methods that rely on time of arrival or angle of arrival information. In a wireless network, user devices scan the base station beacon slots and identify the few strongest base station signals for handover and user-base station association purposes. In the proposed method, the user to be localized simply reports such received signal strengths to a central processing unit, which may be located in the cloud. For each base station we have good approximation of the pathloss at every location in a dense grid in the map. This approximation is provided by RadioUNet, a deep learning-based simulator of pathloss functions in urban environment, that we have previously proposed and published. Using the estimated pathloss radio maps of all base stations and the corresponding reported signal strengths, the proposed deep learning algorithm can extract a very accurate localization of the user. The proposed method, called LocUNet, enjoys high robustness to inaccuracies in the estimated radio maps. We demonstrate this by numerical experiments, which obtain state-of-the-art results.
Flowformer: Linearizing Transformers with Conservation Flows
Feb 13, 2022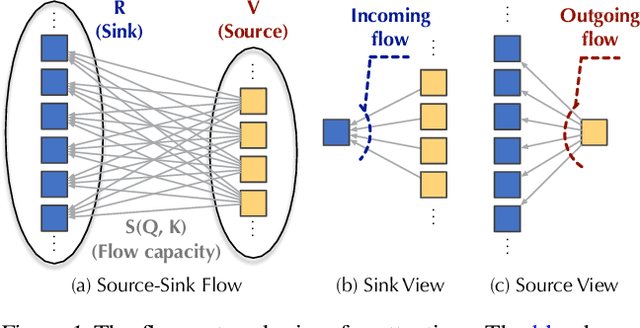
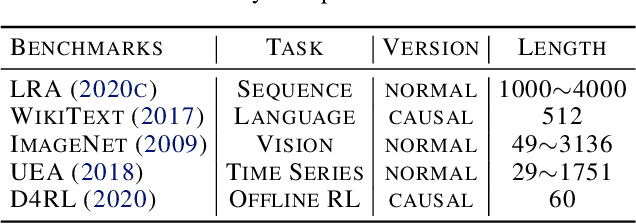
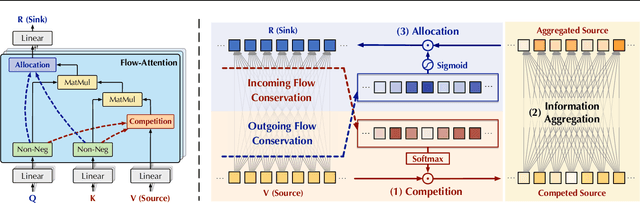
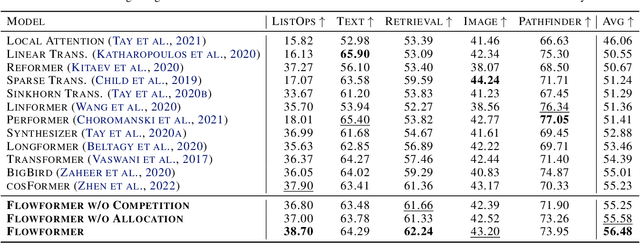
Transformers based on the attention mechanism have achieved impressive success in various areas. However, the attention mechanism has a quadratic complexity, significantly impeding Transformers from dealing with numerous tokens and scaling up to bigger models. Previous methods mainly utilize the similarity decomposition and the associativity of matrix multiplication to devise linear-time attention mechanisms. They avoid degeneration of attention to a trivial distribution by reintroducing inductive biases such as the locality, thereby at the expense of model generality and expressiveness. In this paper, we linearize Transformers free from specific inductive biases based on the flow network theory. We cast attention as the information flow aggregated from the sources (values) to the sinks (results) through the learned flow capacities (attentions). Within this framework, we apply the property of flow conservation with attention and propose the Flow-Attention mechanism of linear complexity. By respectively conserving the incoming flow of sinks for source competition and the outgoing flow of sources for sink allocation, Flow-Attention inherently generates informative attentions without using specific inductive biases. Empowered by the Flow-Attention, Flowformer yields strong performance in linear time for wide areas, including long sequence, time series, vision, natural language, and reinforcement learning.
Pixel2Mesh++: 3D Mesh Generation and Refinement from Multi-View Images
Apr 21, 2022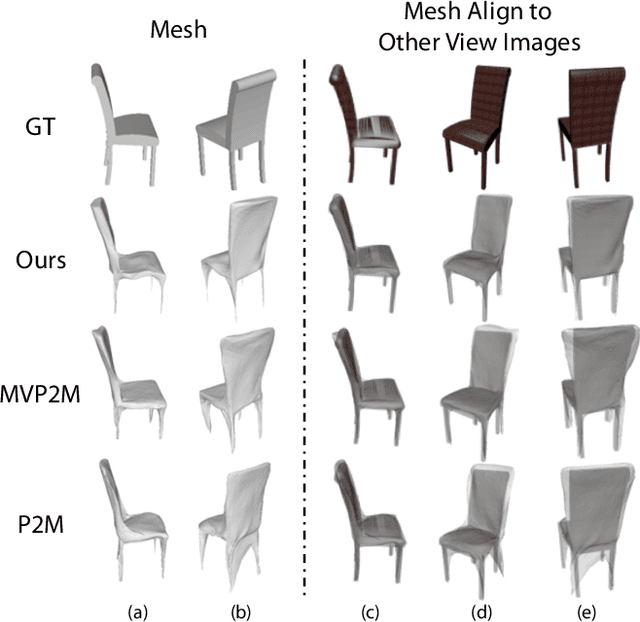
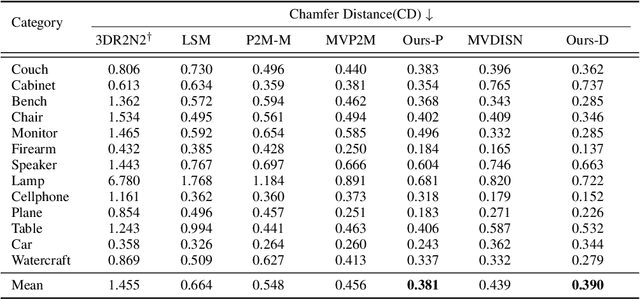
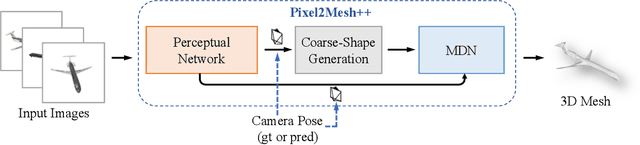
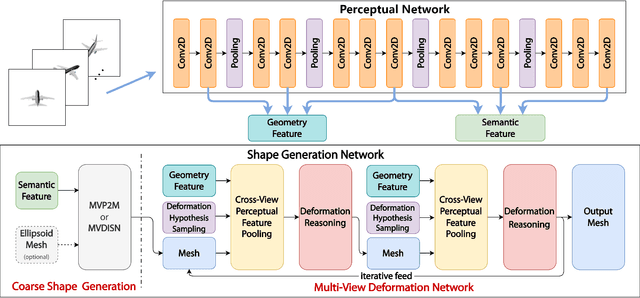
We study the problem of shape generation in 3D mesh representation from a small number of color images with or without camera poses. While many previous works learn to hallucinate the shape directly from priors, we adopt to further improve the shape quality by leveraging cross-view information with a graph convolution network. Instead of building a direct mapping function from images to 3D shape, our model learns to predict series of deformations to improve a coarse shape iteratively. Inspired by traditional multiple view geometry methods, our network samples nearby area around the initial mesh's vertex locations and reasons an optimal deformation using perceptual feature statistics built from multiple input images. Extensive experiments show that our model produces accurate 3D shapes that are not only visually plausible from the input perspectives, but also well aligned to arbitrary viewpoints. With the help of physically driven architecture, our model also exhibits generalization capability across different semantic categories, and the number of input images. Model analysis experiments show that our model is robust to the quality of the initial mesh and the error of camera pose, and can be combined with a differentiable renderer for test-time optimization.
10,000 km Straight-line Transmission using a Real-time Software-defined GPU-Based Receiver
Apr 08, 2021Real-time operation of a software-defined, GPU-based optical receiver is demonstrated over a 100-span straight-line optical link. Performance of minimum-phase Kramers-Kronig 4-, 8-, 16-, 32-, and 64-QAM signals are evaluated at various distances.
Single-pixel imaging based on weight sort of the Hadamard basis
Mar 09, 2022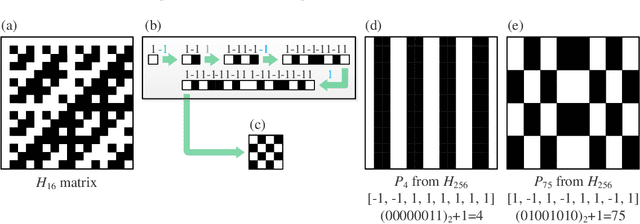
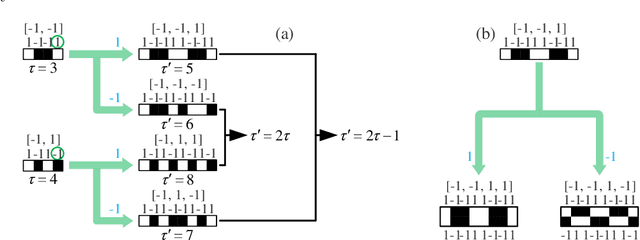

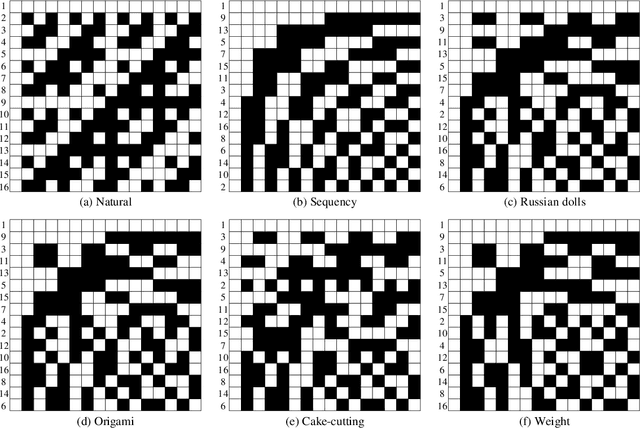
Single-pixel imaging (SPI) is very popular in subsampling applications, but the random measurement matrices it typically uses will lead to measurement blindness as well as difficulties in calculation and storage, and will also limit the further reduction in sampling rate. The deterministic Hadamard basis has become an alternative choice due to its orthogonality and structural characteristics. There is evidence that sorting the Hadamard basis is beneficial to further reduce the sampling rate, thus many orderings have emerged, but their relations remain unclear and lack a unified theory. Given this, here we specially propose a concept named selection history, which can record the Hadamard spatial folding process, and build a model based on it to reveal the formation mechanisms of different orderings and to deduce the mutual conversion relationship among them. Then, a weight ordering of the Hadamard basis is proposed. Both numerical simulation and experimental results have demonstrated that with this weight sort technique, the sampling rate, reconstruction time and matrix memory consumption are greatly reduced in comparison to traditional sorting methods. Therefore, we believe that this method may pave the way for real-time single-pixel imaging.