 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Progressive Distillation for Fast Sampling of Diffusion Models
Feb 01, 2022


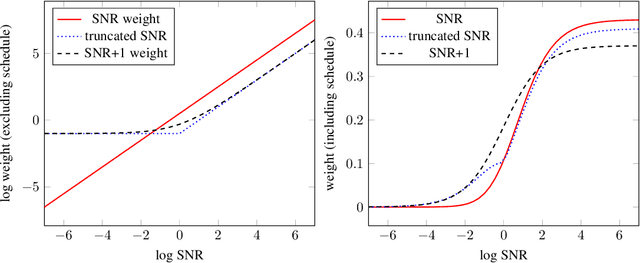
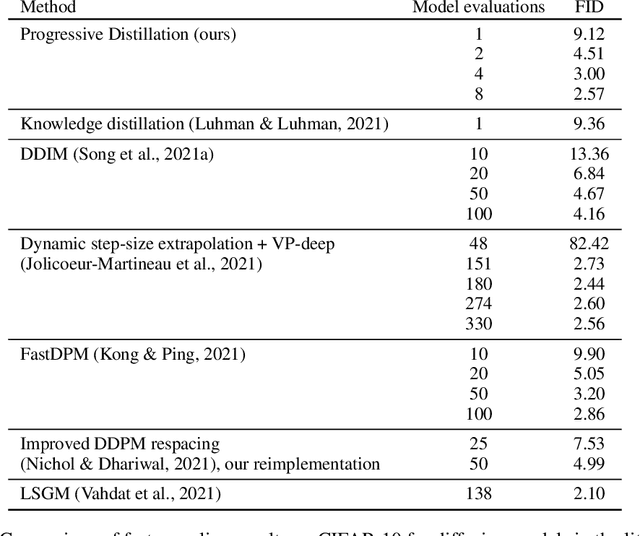
Diffusion models have recently shown great promise for generative modeling, outperforming GANs on perceptual quality and autoregressive models at density estimation. A remaining downside is their slow sampling time: generating high quality samples takes many hundreds or thousands of model evaluations. Here we make two contributions to help eliminate this downside: First, we present new parameterizations of diffusion models that provide increased stability when using few sampling steps. Second, we present a method to distill a trained deterministic diffusion sampler, using many steps, into a new diffusion model that takes half as many sampling steps. We then keep progressively applying this distillation procedure to our model, halving the number of required sampling steps each time. On standard image generation benchmarks like CIFAR-10, ImageNet, and LSUN, we start out with state-of-the-art samplers taking as many as 8192 steps, and are able to distill down to models taking as few as 4 steps without losing much perceptual quality; achieving, for example, a FID of 3.0 on CIFAR-10 in 4 steps. Finally, we show that the full progressive distillation procedure does not take more time than it takes to train the original model, thus representing an efficient solution for generative modeling using diffusion at both train and test time.
Global HRTF Interpolation via Learned Affine Transformation of Hyper-conditioned Features
Apr 06, 2022

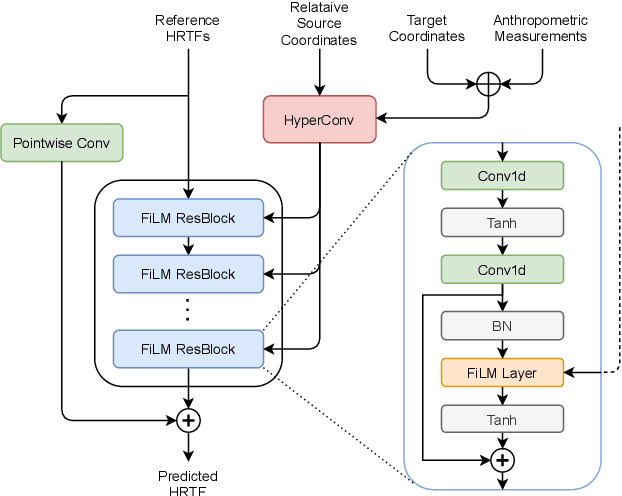

Estimating Head-Related Transfer Functions (HRTFs) of arbitrary source points is essential in immersive binaural audio rendering. Computing each individual's HRTFs is challenging, as traditional approaches require expensive time and computational resources, while modern data-driven approaches are data-hungry. Especially for the data-driven approaches, existing HRTF datasets differ in spatial sampling distributions of source positions, posing a major problem when generalizing the method across multiple datasets. To alleviate this, we propose a deep learning method based on a novel conditioning architecture. The proposed method can predict an HRTF of any position by interpolating the HRTFs of known distributions. Experimental results show that the proposed architecture improves the model's generalizability across datasets with various coordinate systems. Additional demonstrations using coarsened HRTFs demonstrate that the model robustly reconstructs the target HRTFs from the coarsened data.
Collaborative Learning for Cyberattack Detection in Blockchain Networks
Mar 21, 2022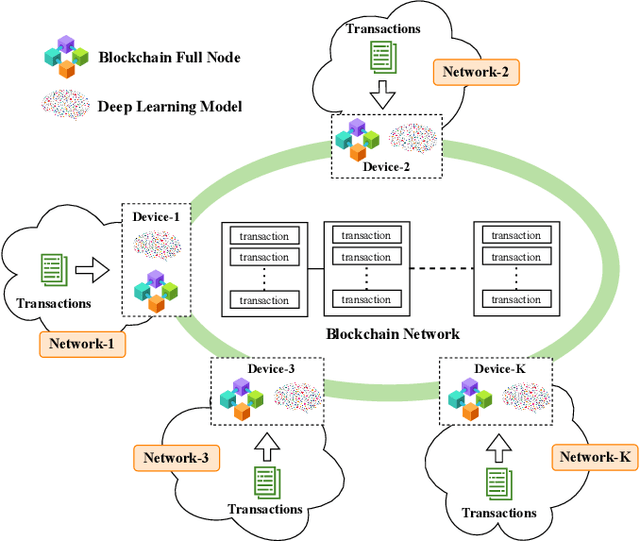
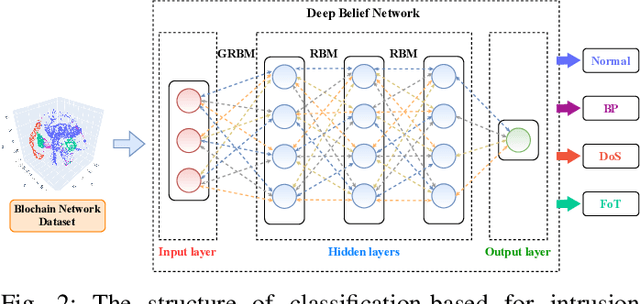
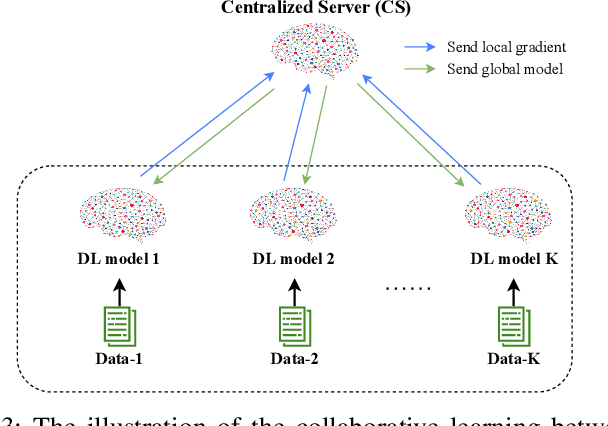
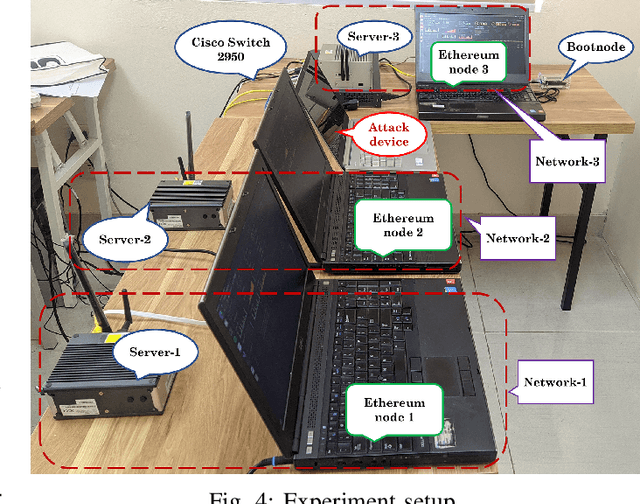
This article aims to study intrusion attacks and then develop a novel cyberattack detection framework for blockchain networks. Specifically, we first design and implement a blockchain network in our laboratory. This blockchain network will serve two purposes, i.e., generate the real traffic data (including both normal data and attack data) for our learning models and implement real-time experiments to evaluate the performance of our proposed intrusion detection framework. To the best of our knowledge, this is the first dataset that is synthesized in a laboratory for cyberattacks in a blockchain network. We then propose a novel collaborative learning model that allows efficient deployment in the blockchain network to detect attacks. The main idea of the proposed learning model is to enable blockchain nodes to actively collect data, share the knowledge learned from its data, and then exchange the knowledge with other blockchain nodes in the network. In this way, we can not only leverage the knowledge from all the nodes in the network but also do not need to gather all raw data for training at a centralized node like conventional centralized learning solutions. Such a framework can also avoid the risk of exposing local data's privacy as well as the excessive network overhead/congestion. Both intensive simulations and real-time experiments clearly show that our proposed collaborative learning-based intrusion detection framework can achieve an accuracy of up to 97.7% in detecting attacks.
Dimensionality Reduction in Deep Learning via Kronecker Multi-layer Architectures
Apr 08, 2022

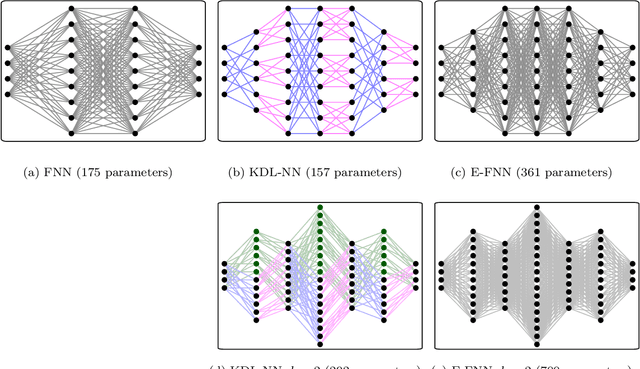
Deep learning using neural networks is an effective technique for generating models of complex data. However, training such models can be expensive when networks have large model capacity resulting from a large number of layers and nodes. For training in such a computationally prohibitive regime, dimensionality reduction techniques ease the computational burden, and allow implementations of more robust networks. We propose a novel type of such dimensionality reduction via a new deep learning architecture based on fast matrix multiplication of a Kronecker product decomposition; in particular our network construction can be viewed as a Kronecker product-induced sparsification of an "extended" fully connected network. Analysis and practical examples show that this architecture allows a neural network to be trained and implemented with a significant reduction in computational time and resources, while achieving a similar error level compared to a traditional feedforward neural network.
Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain
Mar 31, 2022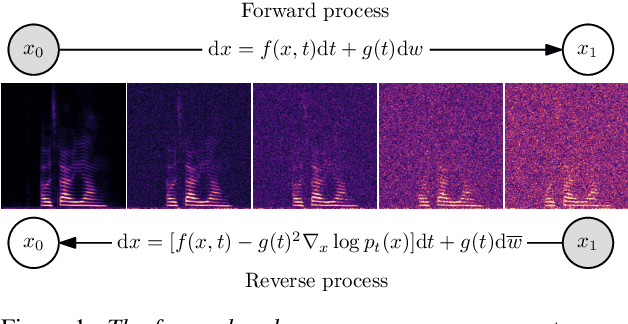
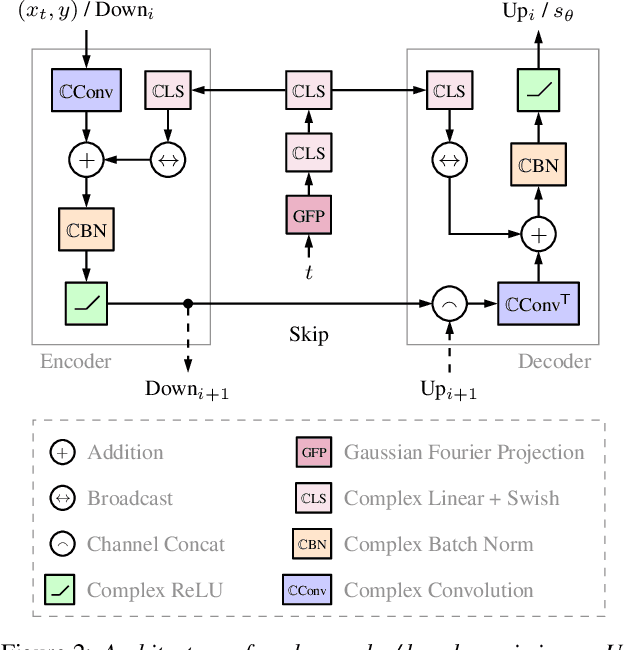
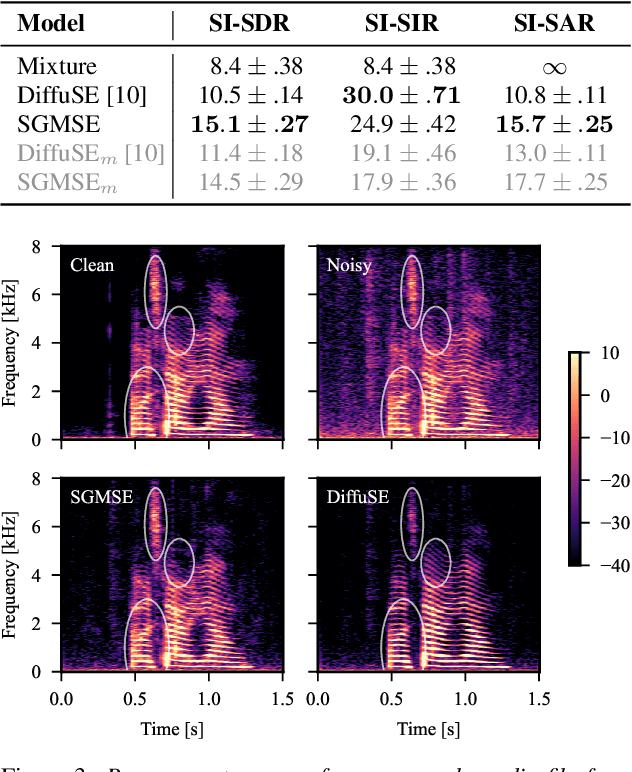
Score-based generative models (SGMs) have recently shown impressive results for difficult generative tasks such as the unconditional and conditional generation of natural images and audio signals. In this work, we extend these models to the complex short-time Fourier transform (STFT) domain, proposing a novel training task for speech enhancement using a complex-valued deep neural network. We derive this training task within the formalism of stochastic differential equations, thereby enabling the use of predictor-corrector samplers. We provide alternative formulations inspired by previous publications on using SGMs for speech enhancement, avoiding the need for any prior assumptions on the noise distribution and making the training task purely generative which, as we show, results in improved enhancement performance.
To Fold or Not to Fold: a Necessary and Sufficient Condition on Batch-Normalization Layers Folding
Mar 28, 2022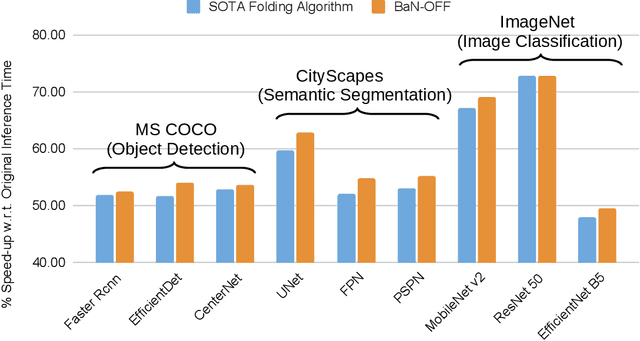
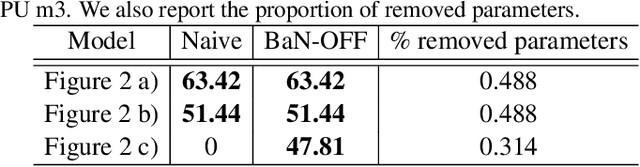
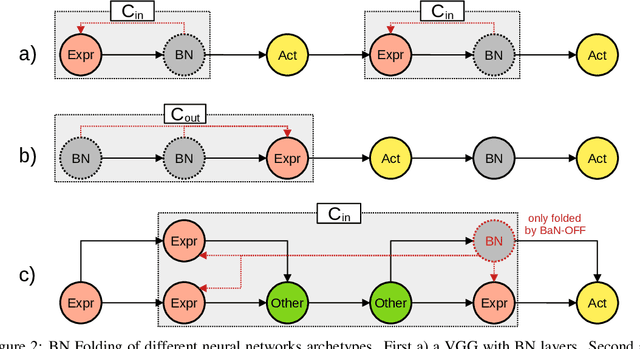
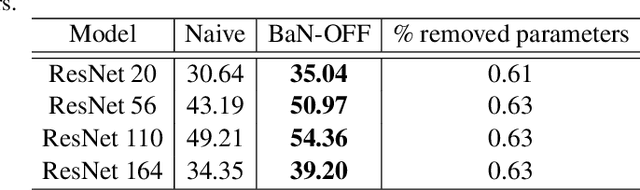
Batch-Normalization (BN) layers have become fundamental components in the evermore complex deep neural network architectures. Such models require acceleration processes for deployment on edge devices. However, BN layers add computation bottlenecks due to the sequential operation processing: thus, a key, yet often overlooked component of the acceleration process is BN layers folding. In this paper, we demonstrate that the current BN folding approaches are suboptimal in terms of how many layers can be removed. We therefore provide a necessary and sufficient condition for BN folding and a corresponding optimal algorithm. The proposed approach systematically outperforms existing baselines and allows to dramatically reduce the inference time of deep neural networks.
Neural Architecture Search for Speech Emotion Recognition
Mar 31, 2022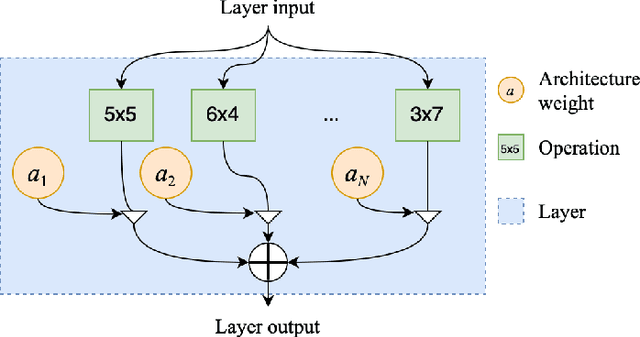
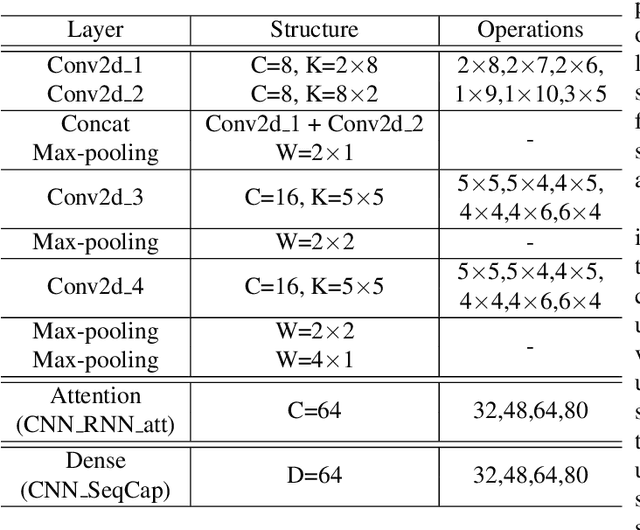
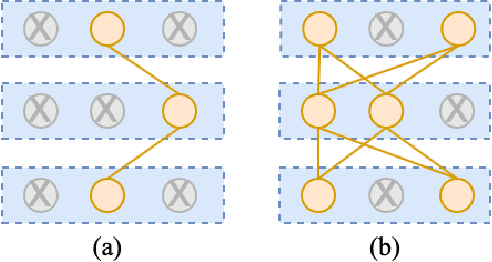
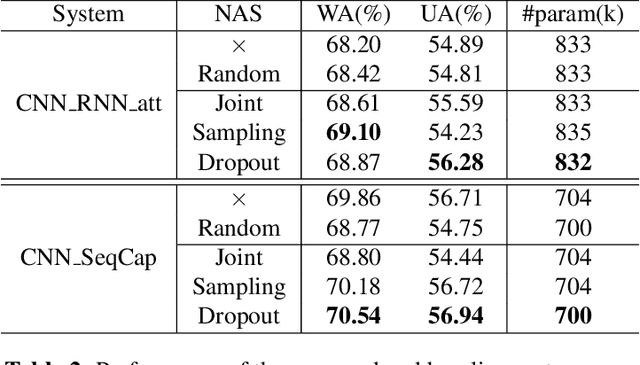
Deep neural networks have brought significant advancements to speech emotion recognition (SER). However, the architecture design in SER is mainly based on expert knowledge and empirical (trial-and-error) evaluations, which is time-consuming and resource intensive. In this paper, we propose to apply neural architecture search (NAS) techniques to automatically configure the SER models. To accelerate the candidate architecture optimization, we propose a uniform path dropout strategy to encourage all candidate architecture operations to be equally optimized. Experimental results of two different neural structures on IEMOCAP show that NAS can improve SER performance (54.89\% to 56.28\%) while maintaining model parameter sizes. The proposed dropout strategy also shows superiority over the previous approaches.
Fast Sampling of Diffusion Models with Exponential Integrator
Apr 29, 2022

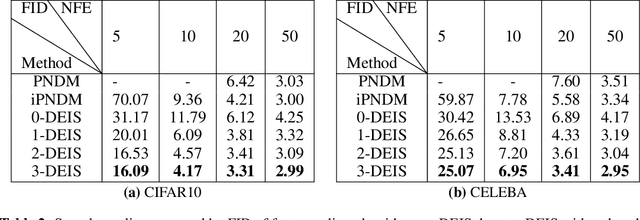
The past few years have witnessed the great success of Diffusion models~(DMs) in generating high-fidelity samples in generative modeling tasks. A major limitation of the DM is its notoriously slow sampling procedure which normally requires hundreds to thousands of time discretization steps of the learned diffusion process to reach the desired accuracy. Our goal is to develop a fast sampling method for DMs with much less number of steps while retaining high sample quality. To this end, we systematically analyze the sampling procedure in DMs and identify key factors that affect the sample quality, among which the method of discretization is most crucial. By carefully examining the learned diffusion process, we propose Diffusion Exponential Integrator Sampler~(DEIS). It is based on the Exponential Integrator designed for discretizing ordinary differential equations (ODEs) and leverages a semilinear structure of the learned diffusion process to reduce the discretization error. The proposed method can be applied to any DMs and can generate high-fidelity samples in as few as 10 steps. In our experiments, it takes about 3 minutes on one A6000 GPU to generate $50k$ images from CIFAR10. Moreover, by directly using pre-trained DMs, we achieve the state-of-art sampling performance when the number of score function evaluation~(NFE) is limited, e.g., 3.37 FID and 9.74 Inception score with only 15 NFEs on CIFAR10.
DropTrack -- automatic droplet tracking using deep learning for microfluidic applications
May 05, 2022


Deep neural networks are rapidly emerging as data analysis tools, often outperforming the conventional techniques used in complex microfluidic systems. One fundamental analysis frequently desired in microfluidic experiments is counting and tracking the droplets. Specifically, droplet tracking in dense emulsions is challenging as droplets move in tightly packed configurations. Sometimes the individual droplets in these dense clusters are hard to resolve, even for a human observer. Here, two deep learning-based cutting-edge algorithms for object detection (YOLO) and object tracking (DeepSORT) are combined into a single image analysis tool, DropTrack, to track droplets in microfluidic experiments. DropTrack analyzes input videos, extracts droplets' trajectories, and infers other observables of interest, such as droplet numbers. Training an object detector network for droplet recognition with manually annotated images is a labor-intensive task and a persistent bottleneck. This work partly resolves this problem by training object detector networks (YOLOv5) with hybrid datasets containing real and synthetic images. We present an analysis of a double emulsion experiment as a case study to measure DropTrack's performance. For our test case, the YOLO networks trained with 60% synthetic images show similar performance in droplet counting as with the one trained using 100% real images, meanwhile saving the image annotation work by 60%. DropTrack's performance is measured in terms of mean average precision (mAP), mean square error in counting the droplets, and inference speed. The fastest configuration of DropTrack runs inference at about 30 frames per second, well within the standards for real-time image analysis.
Biographical: A Semi-Supervised Relation Extraction Dataset
May 02, 2022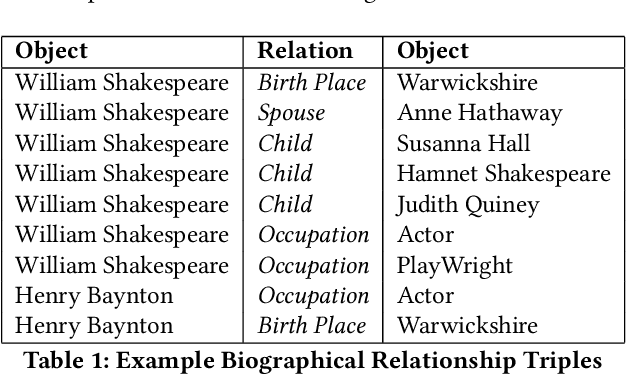
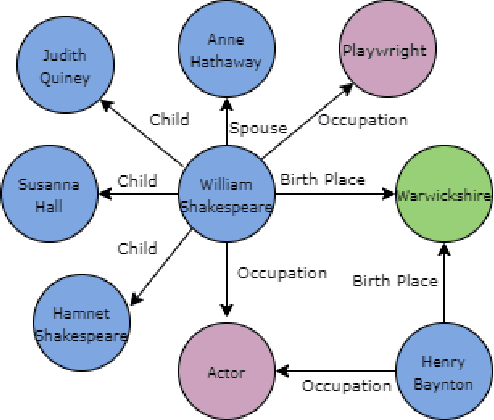
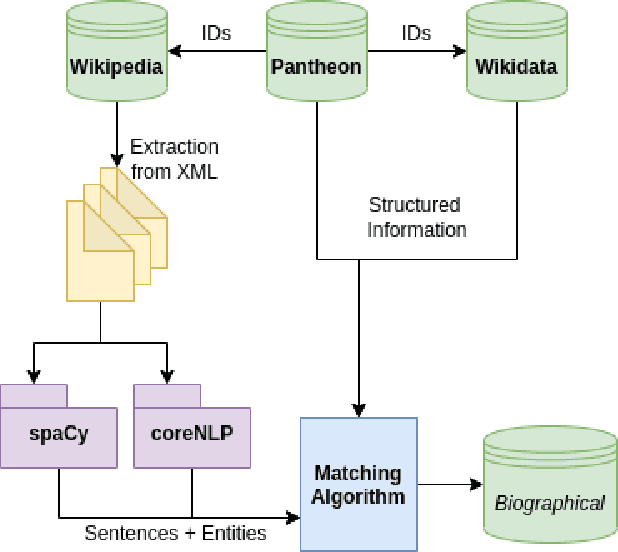
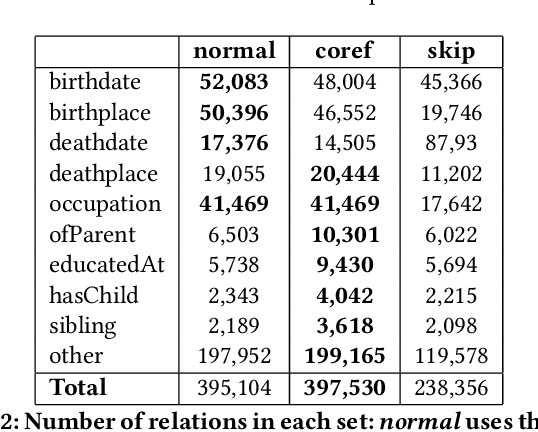
Extracting biographical information from online documents is a popular research topic among the information extraction (IE) community. Various natural language processing (NLP) techniques such as text classification, text summarisation and relation extraction are commonly used to achieve this. Among these techniques, RE is the most common since it can be directly used to build biographical knowledge graphs. RE is usually framed as a supervised machine learning (ML) problem, where ML models are trained on annotated datasets. However, there are few annotated datasets for RE since the annotation process can be costly and time-consuming. To address this, we developed Biographical, the first semi-supervised dataset for RE. The dataset, which is aimed towards digital humanities (DH) and historical research, is automatically compiled by aligning sentences from Wikipedia articles with matching structured data from sources including Pantheon and Wikidata. By exploiting the structure of Wikipedia articles and robust named entity recognition (NER), we match information with relatively high precision in order to compile annotated relation pairs for ten different relations that are important in the DH domain. Furthermore, we demonstrate the effectiveness of the dataset by training a state-of-the-art neural model to classify relation pairs, and evaluate it on a manually annotated gold standard set. Biographical is primarily aimed at training neural models for RE within the domain of digital humanities and history, but as we discuss at the end of this paper, it can be useful for other purposes as well.