 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine Learning Advances for Time Series Forecasting
Jan 18, 2021
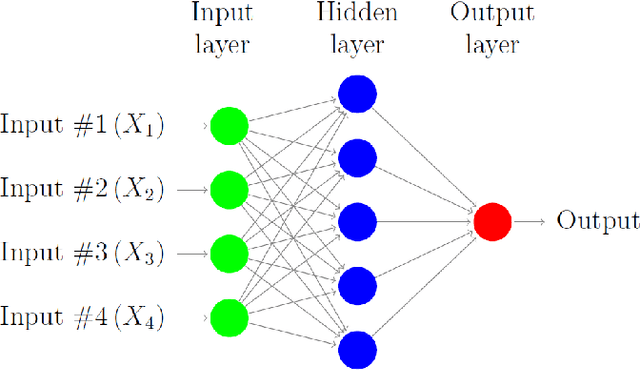
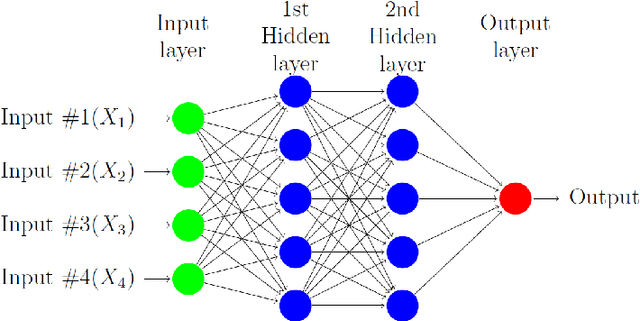
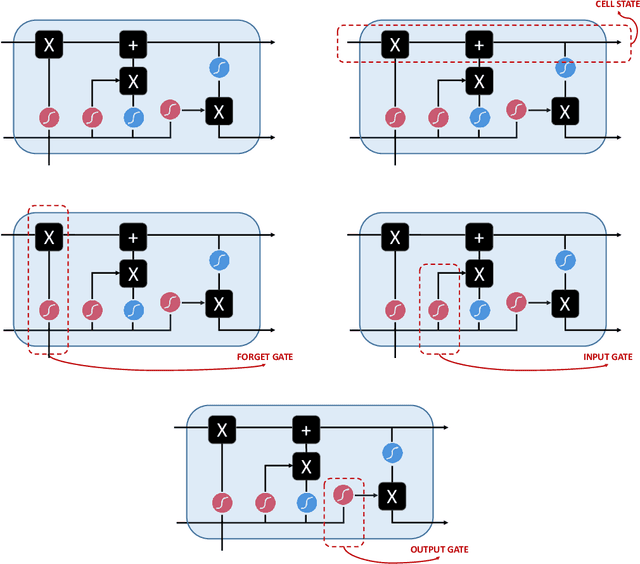
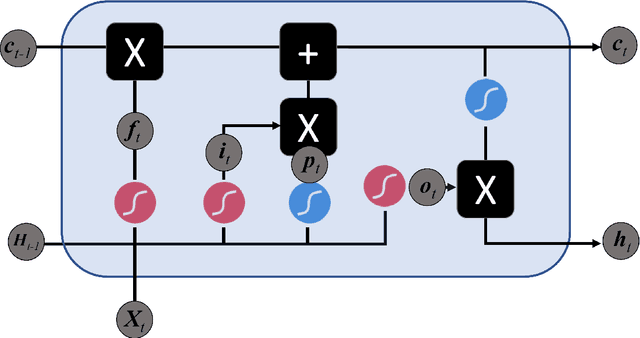
In this paper we survey the most recent advances in supervised machine learning and high-dimensional models for time series forecasting. We consider both linear and nonlinear alternatives. Among the linear methods we pay special attention to penalized regressions and ensemble of models. The nonlinear methods considered in the paper include shallow and deep neural networks, in their feed-forward and recurrent versions, and tree-based methods, such as random forests and boosted trees. We also consider ensemble and hybrid models by combining ingredients from different alternatives. Tests for superior predictive ability are briefly reviewed. Finally, we discuss application of machine learning in economics and finance and provide an illustration with high-frequency financial data.
Fast Sampling of Diffusion Models with Exponential Integrator
Apr 29, 2022

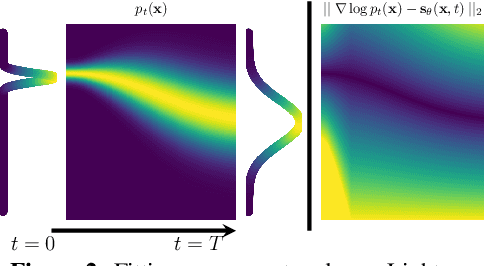
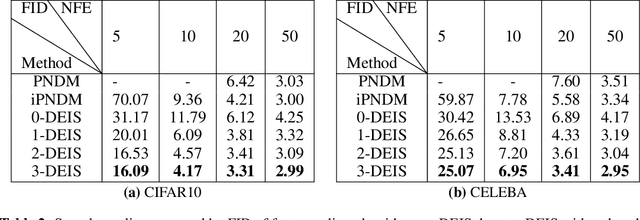
The past few years have witnessed the great success of Diffusion models~(DMs) in generating high-fidelity samples in generative modeling tasks. A major limitation of the DM is its notoriously slow sampling procedure which normally requires hundreds to thousands of time discretization steps of the learned diffusion process to reach the desired accuracy. Our goal is to develop a fast sampling method for DMs with much less number of steps while retaining high sample quality. To this end, we systematically analyze the sampling procedure in DMs and identify key factors that affect the sample quality, among which the method of discretization is most crucial. By carefully examining the learned diffusion process, we propose Diffusion Exponential Integrator Sampler~(DEIS). It is based on the Exponential Integrator designed for discretizing ordinary differential equations (ODEs) and leverages a semilinear structure of the learned diffusion process to reduce the discretization error. The proposed method can be applied to any DMs and can generate high-fidelity samples in as few as 10 steps. In our experiments, it takes about 3 minutes on one A6000 GPU to generate $50k$ images from CIFAR10. Moreover, by directly using pre-trained DMs, we achieve the state-of-art sampling performance when the number of score function evaluation~(NFE) is limited, e.g., 3.37 FID and 9.74 Inception score with only 15 NFEs on CIFAR10.
Biographical: A Semi-Supervised Relation Extraction Dataset
May 02, 2022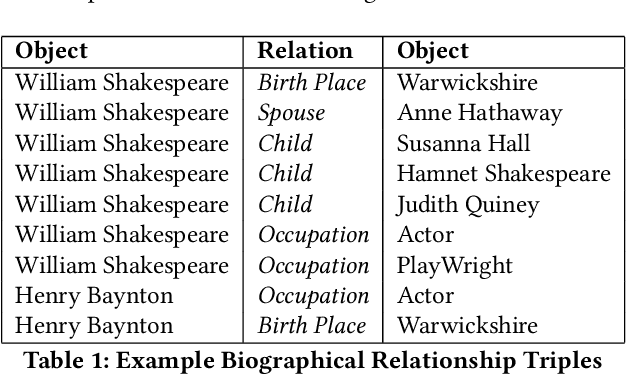
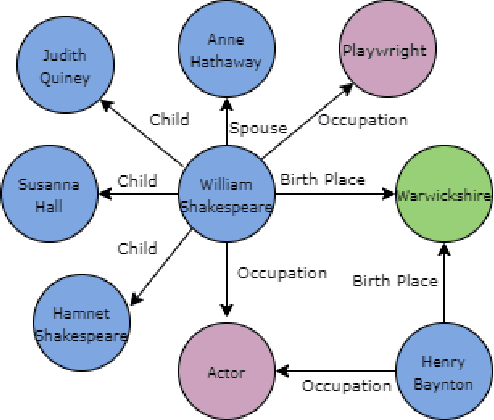
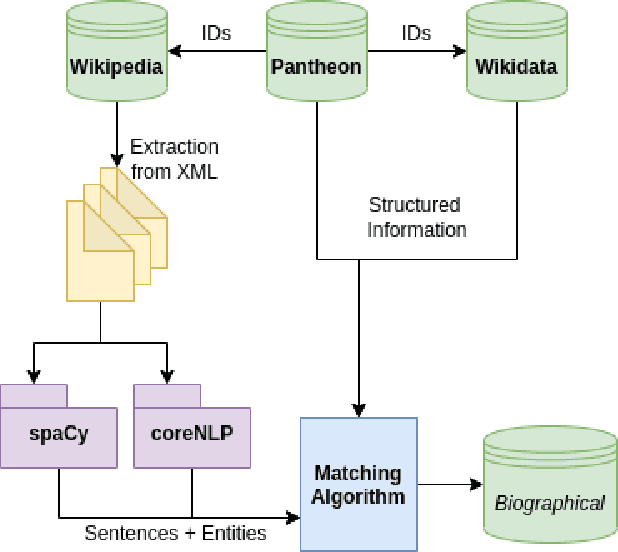
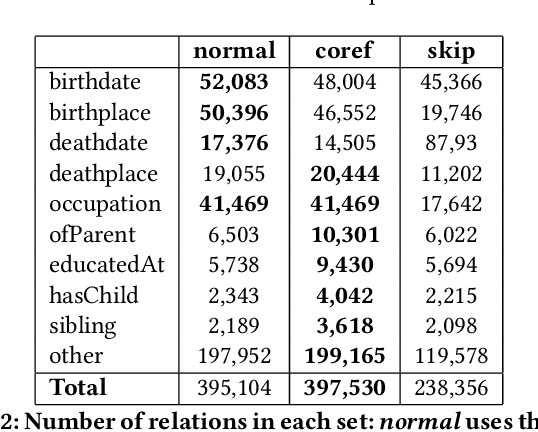
Extracting biographical information from online documents is a popular research topic among the information extraction (IE) community. Various natural language processing (NLP) techniques such as text classification, text summarisation and relation extraction are commonly used to achieve this. Among these techniques, RE is the most common since it can be directly used to build biographical knowledge graphs. RE is usually framed as a supervised machine learning (ML) problem, where ML models are trained on annotated datasets. However, there are few annotated datasets for RE since the annotation process can be costly and time-consuming. To address this, we developed Biographical, the first semi-supervised dataset for RE. The dataset, which is aimed towards digital humanities (DH) and historical research, is automatically compiled by aligning sentences from Wikipedia articles with matching structured data from sources including Pantheon and Wikidata. By exploiting the structure of Wikipedia articles and robust named entity recognition (NER), we match information with relatively high precision in order to compile annotated relation pairs for ten different relations that are important in the DH domain. Furthermore, we demonstrate the effectiveness of the dataset by training a state-of-the-art neural model to classify relation pairs, and evaluate it on a manually annotated gold standard set. Biographical is primarily aimed at training neural models for RE within the domain of digital humanities and history, but as we discuss at the end of this paper, it can be useful for other purposes as well.
Dimensionality Reduction in Deep Learning via Kronecker Multi-layer Architectures
Apr 08, 2022

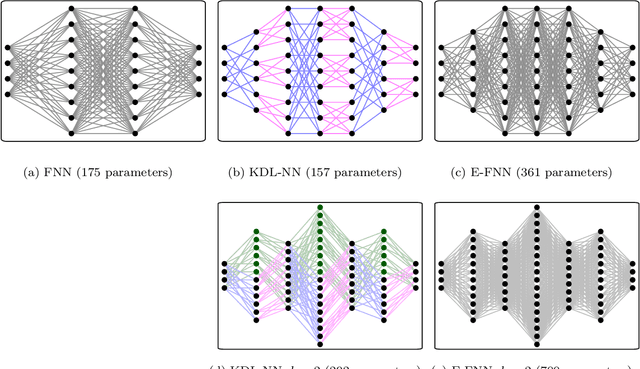
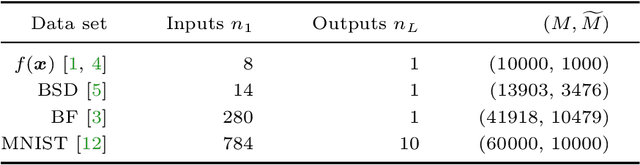
Deep learning using neural networks is an effective technique for generating models of complex data. However, training such models can be expensive when networks have large model capacity resulting from a large number of layers and nodes. For training in such a computationally prohibitive regime, dimensionality reduction techniques ease the computational burden, and allow implementations of more robust networks. We propose a novel type of such dimensionality reduction via a new deep learning architecture based on fast matrix multiplication of a Kronecker product decomposition; in particular our network construction can be viewed as a Kronecker product-induced sparsification of an "extended" fully connected network. Analysis and practical examples show that this architecture allows a neural network to be trained and implemented with a significant reduction in computational time and resources, while achieving a similar error level compared to a traditional feedforward neural network.
Online Approval Committee Elections
Feb 14, 2022Assume $k$ candidates need to be selected. The candidates appear over time. Each time one appears, it must be immediately selected or rejected -- a decision that is made by a group of individuals through voting. Assume the voters use approval ballots, i.e., for each candidate they only specify whether they consider it acceptable or not. This setting can be seen as a voting variant of choosing $k$ secretaries. Our contribution is twofold. (1) We assess to what extent the committees that are computed online can proportionally represent the voters. (2) If a prior probability over candidate approvals is available, we show how to compute committees with maximal expected score.
Por Qué Não Utiliser Alla Språk? Mixed Training with Gradient Optimization in Few-Shot Cross-Lingual Transfer
Apr 29, 2022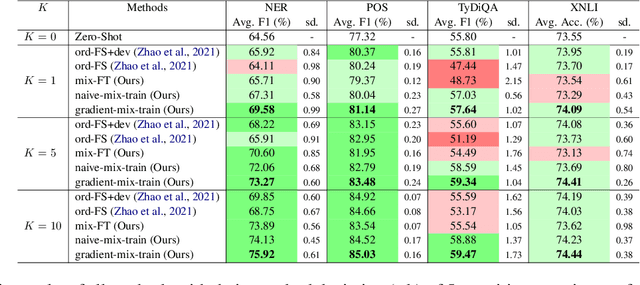
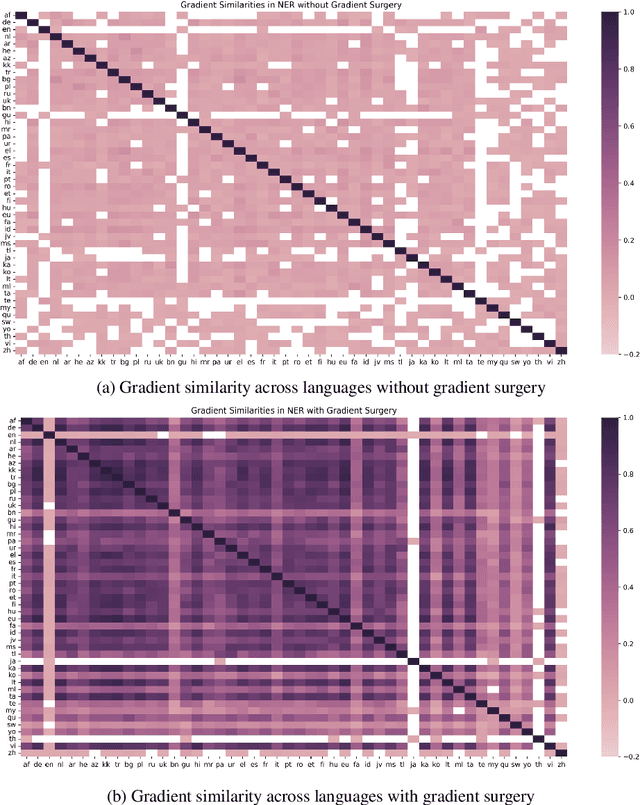
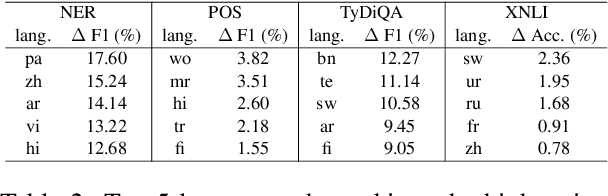
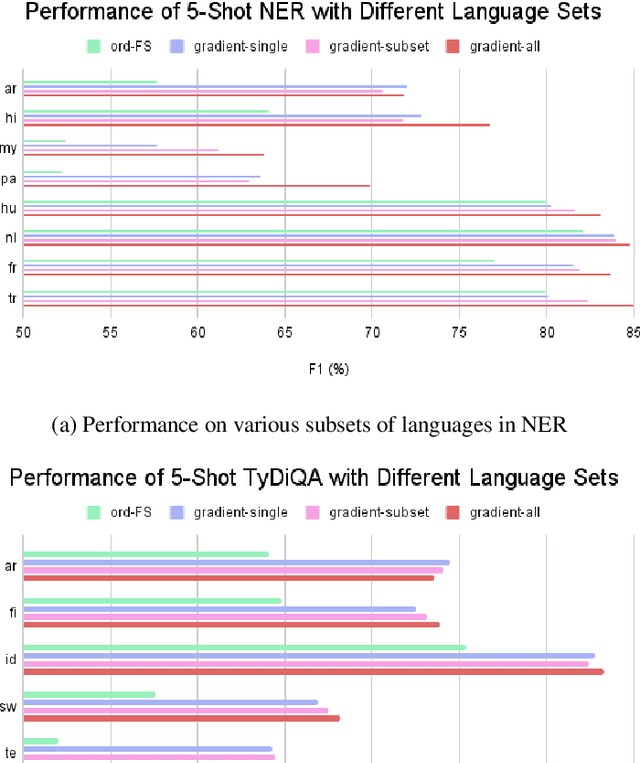
The current state-of-the-art for few-shot cross-lingual transfer learning first trains on abundant labeled data in the source language and then fine-tunes with a few examples on the target language, termed target-adapting. Though this has been demonstrated to work on a variety of tasks, in this paper we show some deficiencies of this approach and propose a one-step mixed training method that trains on both source and target data with \textit{stochastic gradient surgery}, a novel gradient-level optimization. Unlike the previous studies that focus on one language at a time when target-adapting, we use one model to handle all target languages simultaneously to avoid excessively language-specific models. Moreover, we discuss the unreality of utilizing large target development sets for model selection in previous literature. We further show that our method is both development-free for target languages, and is also able to escape from overfitting issues. We conduct a large-scale experiment on 4 diverse NLP tasks across up to 48 languages. Our proposed method achieves state-of-the-art performance on all tasks and outperforms target-adapting by a large margin, especially for languages that are linguistically distant from the source language, e.g., 7.36% F1 absolute gain on average for the NER task, up to 17.60% on Punjabi.
Collaborative Learning for Cyberattack Detection in Blockchain Networks
Mar 21, 2022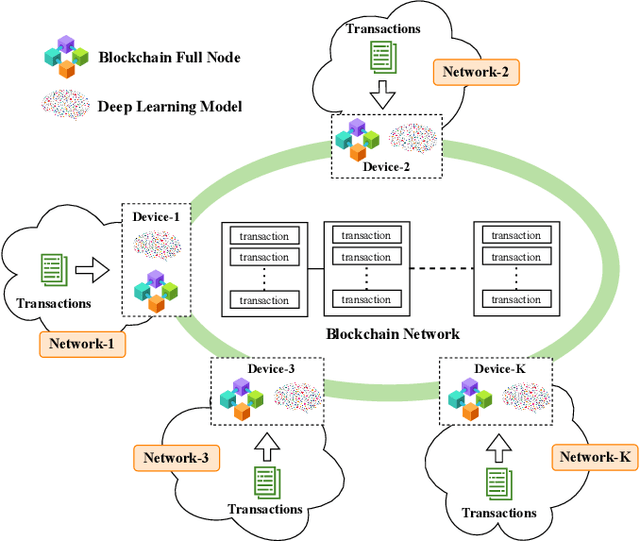
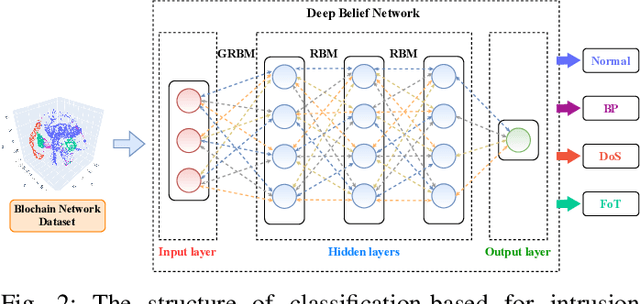
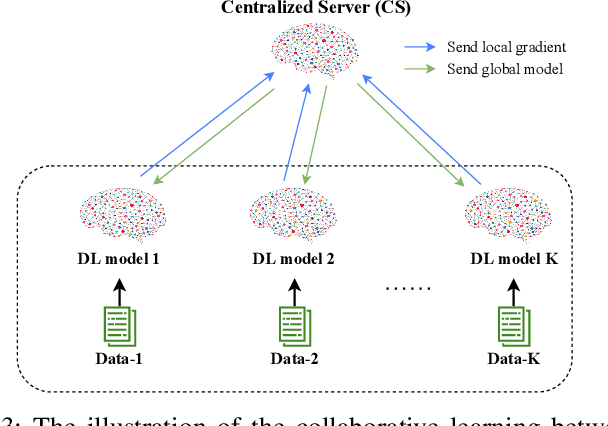
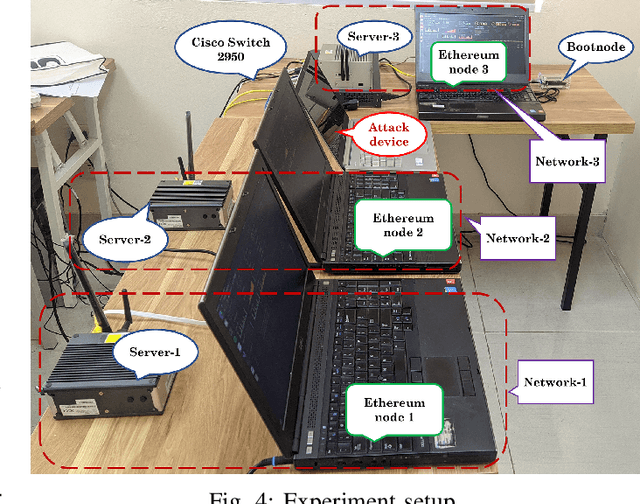
This article aims to study intrusion attacks and then develop a novel cyberattack detection framework for blockchain networks. Specifically, we first design and implement a blockchain network in our laboratory. This blockchain network will serve two purposes, i.e., generate the real traffic data (including both normal data and attack data) for our learning models and implement real-time experiments to evaluate the performance of our proposed intrusion detection framework. To the best of our knowledge, this is the first dataset that is synthesized in a laboratory for cyberattacks in a blockchain network. We then propose a novel collaborative learning model that allows efficient deployment in the blockchain network to detect attacks. The main idea of the proposed learning model is to enable blockchain nodes to actively collect data, share the knowledge learned from its data, and then exchange the knowledge with other blockchain nodes in the network. In this way, we can not only leverage the knowledge from all the nodes in the network but also do not need to gather all raw data for training at a centralized node like conventional centralized learning solutions. Such a framework can also avoid the risk of exposing local data's privacy as well as the excessive network overhead/congestion. Both intensive simulations and real-time experiments clearly show that our proposed collaborative learning-based intrusion detection framework can achieve an accuracy of up to 97.7% in detecting attacks.
CellDefectNet: A Machine-designed Attention Condenser Network for Electroluminescence-based Photovoltaic Cell Defect Inspection
Apr 25, 2022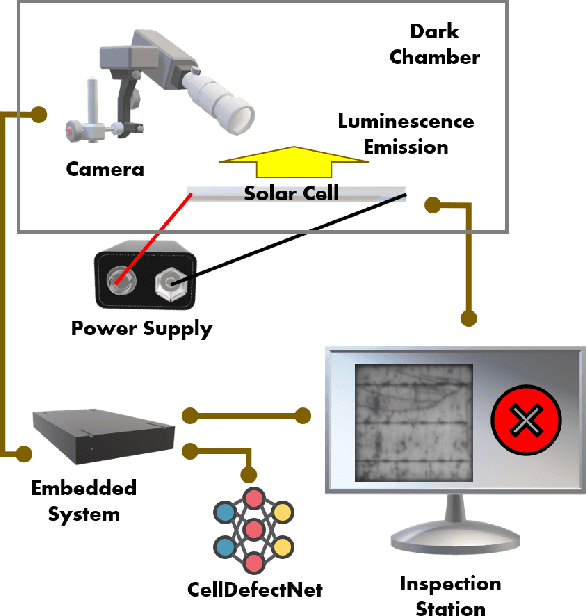
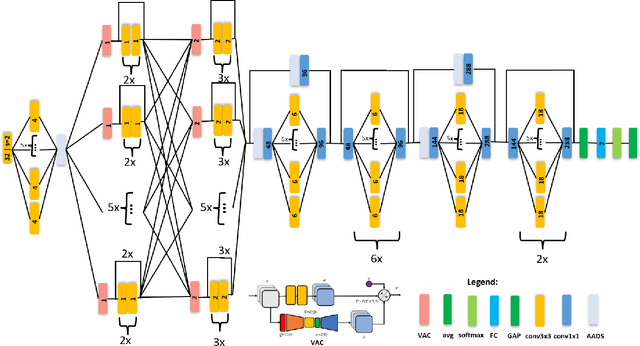
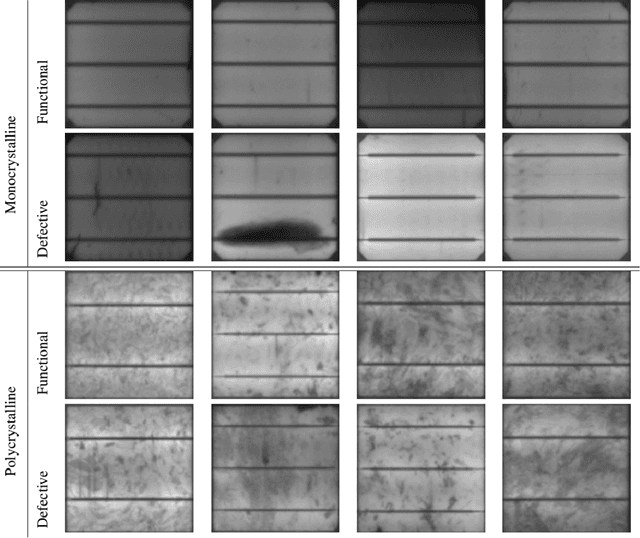
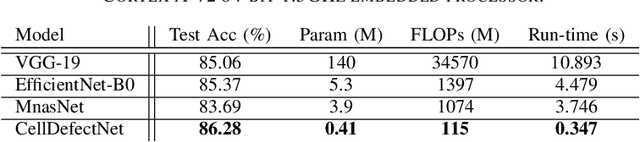
Photovoltaic cells are electronic devices that convert light energy to electricity, forming the backbone of solar energy harvesting systems. An essential step in the manufacturing process for photovoltaic cells is visual quality inspection using electroluminescence imaging to identify defects such as cracks, finger interruptions, and broken cells. A big challenge faced by industry in photovoltaic cell visual inspection is the fact that it is currently done manually by human inspectors, which is extremely time consuming, laborious, and prone to human error. While deep learning approaches holds great potential to automating this inspection, the hardware resource-constrained manufacturing scenario makes it challenging for deploying complex deep neural network architectures. In this work, we introduce CellDefectNet, a highly efficient attention condenser network designed via machine-driven design exploration specifically for electroluminesence-based photovoltaic cell defect detection on the edge. We demonstrate the efficacy of CellDefectNet on a benchmark dataset comprising of a diversity of photovoltaic cells captured using electroluminescence imagery, achieving an accuracy of ~86.3% while possessing just 410K parameters (~13$\times$ lower than EfficientNet-B0, respectively) and ~115M FLOPs (~12$\times$ lower than EfficientNet-B0) and ~13$\times$ faster on an ARM Cortex A-72 embedded processor when compared to EfficientNet-B0.
A feasibility study proposal of the predictive model to enable the prediction of population susceptibility to COVID-19 by analysis of vaccine utilization for advising deployment of a booster dose
Apr 25, 2022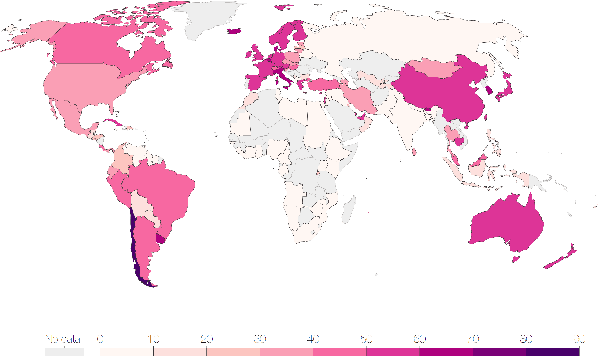
With the present highly infectious dominant SARS-CoV-2 strain of B1.1.529 or Omicron spreading around the globe, there is concern that the COVID-19 pandemic will not end soon and that it will be a race against time until a more contagious and virulent variant emerges. One of the most promising approaches for preventing virus propagation is to maintain continuous high vaccination efficacy among the population, thereby strengthening the population protective effect and preventing the majority of infection in the vaccinated population, as is known to occur with the Omicron variant frequently. Countries must structure vaccination programs in accordance with their populations' susceptibility to infection, optimizing vaccination efforts by delivering vaccines progressively enough to protect the majority of the population. We present a feasibility study proposal for maintaining optimal continuous vaccination by assessing the susceptible population, the decline of vaccine efficacy in the population, and advising booster dosage deployment to maintain the population's protective efficacy through the use of a predictive model. Numerous studies have been conducted in the direction of analyzing vaccine utilization; however, very little study has been conducted to substantiate the optimal deployment of booster dosage vaccination with the help of a predictive model based on machine learning algorithms.
Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain
Mar 31, 2022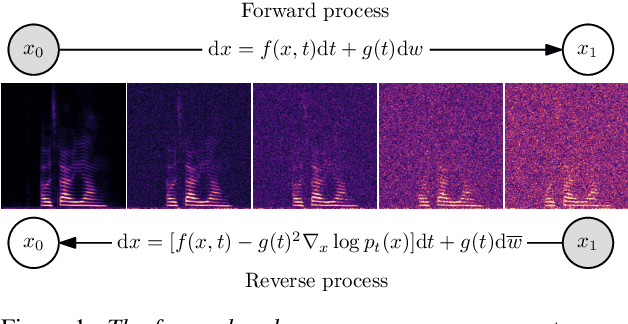
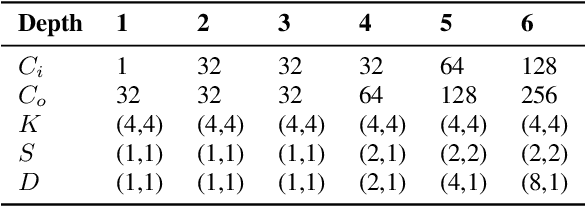
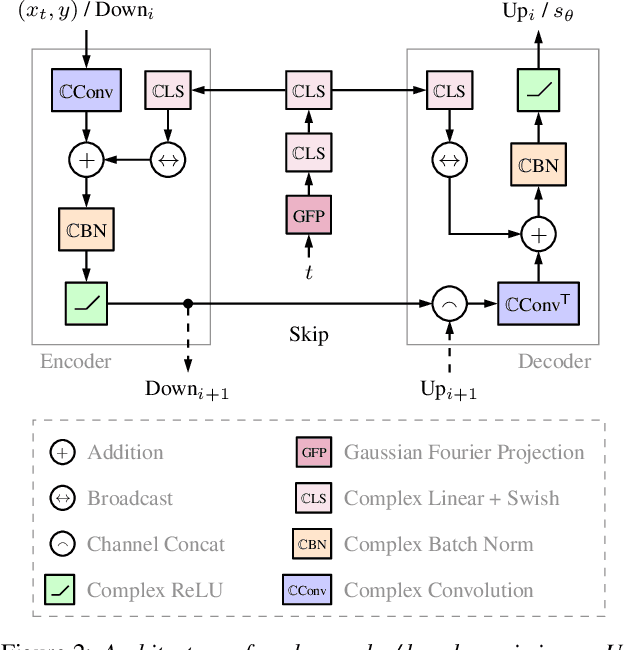
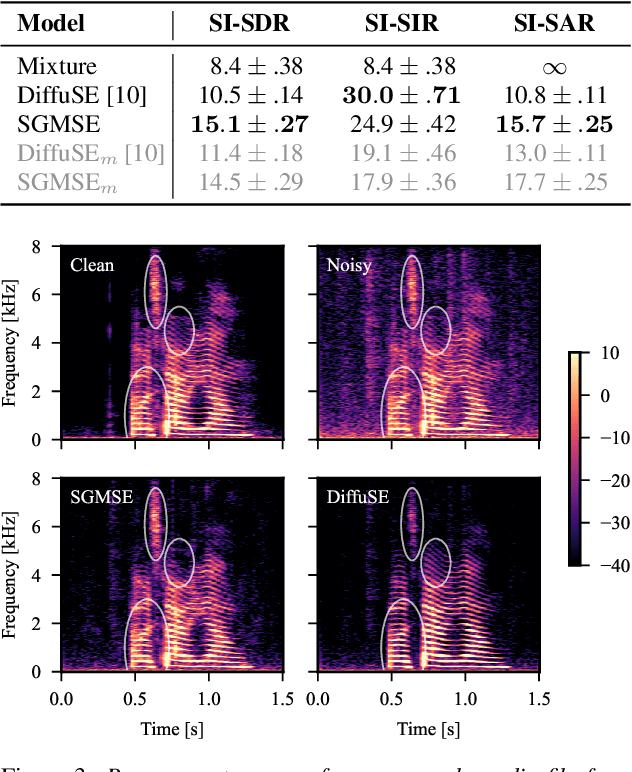
Score-based generative models (SGMs) have recently shown impressive results for difficult generative tasks such as the unconditional and conditional generation of natural images and audio signals. In this work, we extend these models to the complex short-time Fourier transform (STFT) domain, proposing a novel training task for speech enhancement using a complex-valued deep neural network. We derive this training task within the formalism of stochastic differential equations, thereby enabling the use of predictor-corrector samplers. We provide alternative formulations inspired by previous publications on using SGMs for speech enhancement, avoiding the need for any prior assumptions on the noise distribution and making the training task purely generative which, as we show, results in improved enhancement performance.