 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interaction-Aware Labeled Multi-Bernoulli Filter
Apr 19, 2022
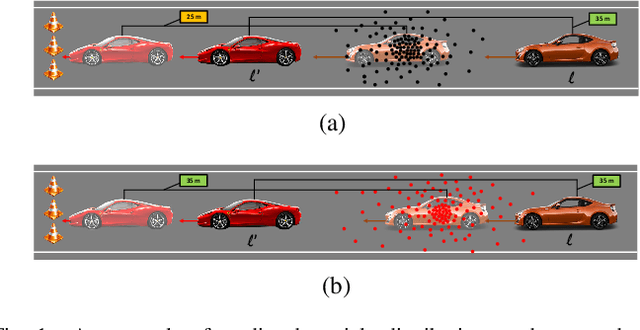
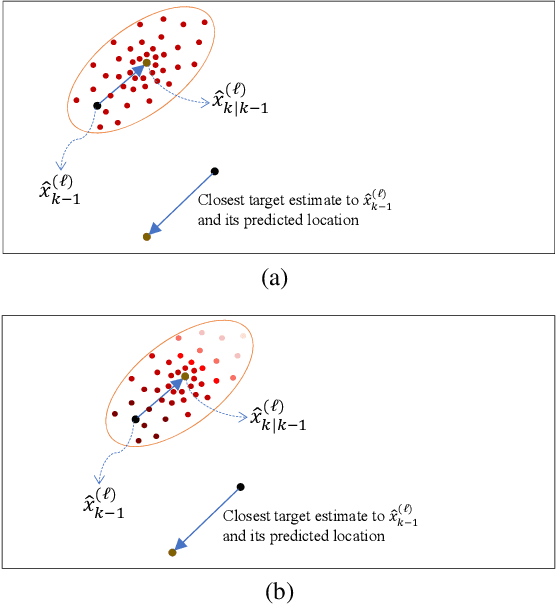
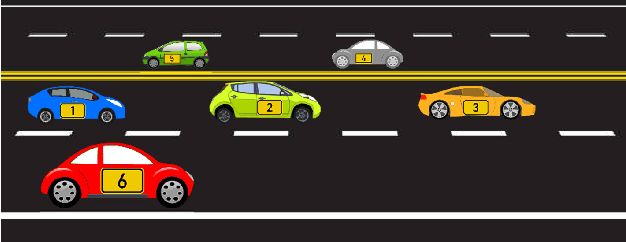
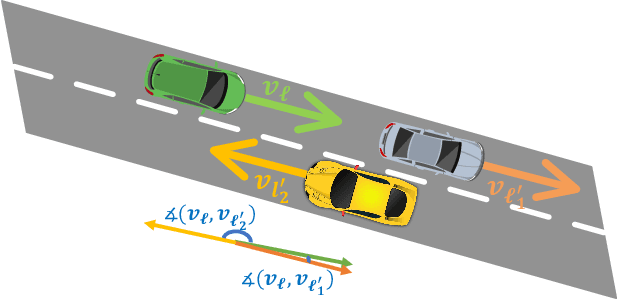
Tracking multiple objects through time is an important part of an intelligent transportation system. Random finite set (RFS)-based filters are one of the emerging techniques for tracking multiple objects. In multi-object tracking (MOT), a common assumption is that each object is moving independent of its surroundings. But in many real-world applications, target objects interact with one another and the environment. Such interactions, when considered for tracking, are usually modeled by an interactive motion model which is application specific. In this paper, we present a novel approach to incorporate target interactions within the prediction step of an RFS-based multi-target filter, i.e. labeled multi-Bernoulli (LMB) filter. The method has been developed for two practical applications of tracking a coordinated swarm and vehicles. The method has been tested for a complex vehicle tracking dataset and compared with the LMB filter through the OSPA and OSPA$^{(2)}$ metrics. The results demonstrate that the proposed interaction-aware method depicts considerable performance enhancement over the LMB filter in terms of the selected metrics.
Partial Relaxed Optimal Transport for Denoised Recommendation
Apr 19, 2022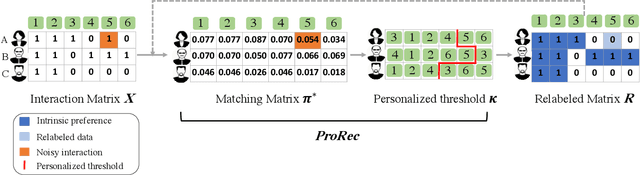
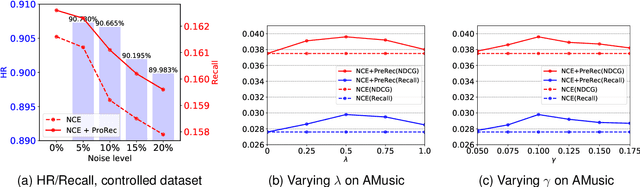
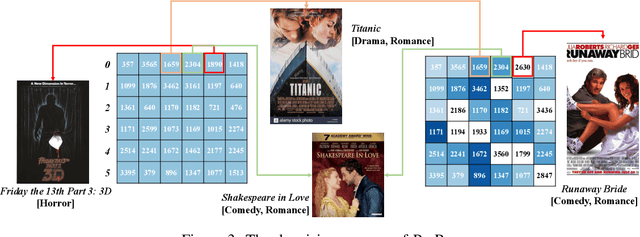
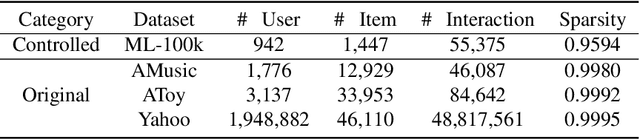
The interaction data used by recommender systems (RSs) inevitably include noises resulting from mistaken or exploratory clicks, especially under implicit feedbacks. Without proper denoising, RS models cannot effectively capture users' intrinsic preferences and the true interactions between users and items. To address such noises, existing methods mostly rely on auxiliary data which are not always available. In this work, we ground on Optimal Transport (OT) to globally match a user embedding space and an item embedding space, allowing both non-deep and deep RS models to discriminate intrinsic and noisy interactions without supervision. Specifically, we firstly leverage the OT framework via Sinkhorn distance to compute the continuous many-to-many user-item matching scores. Then, we relax the regularization in Sinkhorn distance to achieve a closed-form solution with a reduced time complexity. Finally, to consider individual user behaviors for denoising, we develop a partial OT framework to adaptively relabel user-item interactions through a personalized thresholding mechanism. Extensive experiments show that our framework can significantly boost the performances of existing RS models.
A Unified Analysis of Dynamic Interactive Learning
Apr 14, 2022In this paper we investigate the problem of learning evolving concepts over a combinatorial structure. Previous work by Emamjomeh-Zadeh et al. [2020] introduced dynamics into interactive learning as a way to model non-static user preferences in clustering problems or recommender systems. We provide many useful contributions to this problem. First, we give a framework that captures both of the models analyzed by [Emamjomeh-Zadeh et al., 2020], which allows us to study any type of concept evolution and matches the same query complexity bounds and running time guarantees of the previous models. Using this general model we solve the open problem of closing the gap between the upper and lower bounds on query complexity. Finally, we study an efficient algorithm where the learner simply follows the feedback at each round, and we provide mistake bounds for low diameter graphs such as cliques, stars, and general o(log n) diameter graphs by using a Markov Chain model.
10,000 km Straight-line Transmission using a Real-time Software-defined GPU-Based Receiver
Apr 08, 2021Real-time operation of a software-defined, GPU-based optical receiver is demonstrated over a 100-span straight-line optical link. Performance of minimum-phase Kramers-Kronig 4-, 8-, 16-, 32-, and 64-QAM signals are evaluated at various distances.
SPARCS: A Sparse Recovery Approach for Integrated Communication and Human Sensing in mmWave Systems
May 06, 2022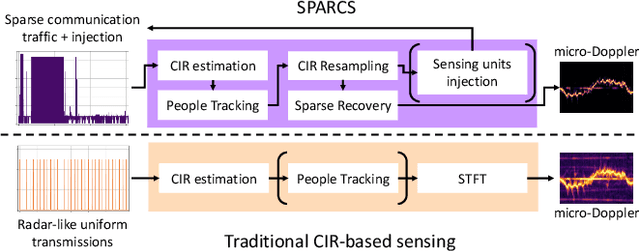


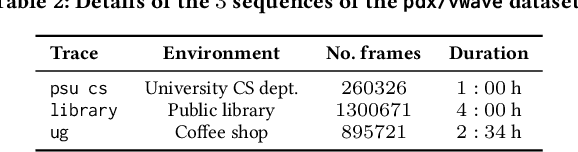
A well established method to detect and classify human movements using Millimeter-Wave ( mmWave) devices is the time-frequency analysis of the small-scale Doppler effect (termed micro-Doppler) of the different body parts, which requires a regularly spaced and dense sampling of the Channel Impulse Response ( CIR). This is currently done in the literature either using special-purpose radar sensors, or interrupting communications to transmit dedicated sensing waveforms, entailing high overhead and channel utilization. In this work we present SPARCS, an integrated human sensing and communication solution for mmWave systems. SPARCS is the first method that reconstructs high quality signatures of human movement from irregular and sparse CIR samples, such as the ones obtained during communication traffic patterns. To accomplish this, we formulate the micro-Doppler extraction as a sparse recovery problem, which is critical to enable a smooth integration between communication and sensing. Moreover, if needed, our system can seamlessly inject short CIR estimation fields into the channel whenever communication traffic is absent or insufficient for the micro-Doppler extraction. SPARCS effectively leverages the intrinsic sparsity of the mmWave channel, thus drastically reducing the sensing overhead with respect to available approaches. We implemented SPARCS on an IEEE 802.11ay Software Defined Radio (SDR) platform working in the 60 GHz band, collecting standard-compliant CIR traces matching the traffic patterns of real WiFi access points. Our results show that the micro-Doppler signatures obtained by SPARCS enable a typical downstream application such as human activity recognition with more than 7 times lower overhead with respect to existing methods, while achieving better recognition performance.
Training Speaker Embedding Extractors Using Multi-Speaker Audio with Unknown Speaker Boundaries
Mar 29, 2022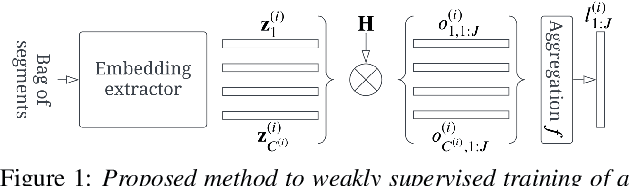
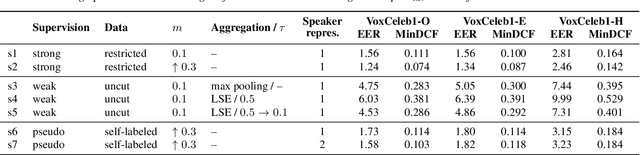
In this paper, we demonstrate a method for training speaker embedding extractors using weak annotation. More specifically, we are using the full VoxCeleb recordings and the name of the celebrities appearing on each video without knowledge of the time intervals the celebrities appear in the video. We show that by combining a baseline speaker diarization algorithm that requires no training or parameter tuning, a modified loss with aggregation over segments, and a two-stage training approach, we are able to train a competitive ResNet-based embedding extractor. Finally, we experiment with two different aggregation functions and analyze their behaviour in terms of their gradients.
QDrop: Randomly Dropping Quantization for Extremely Low-bit Post-Training Quantization
Mar 11, 2022
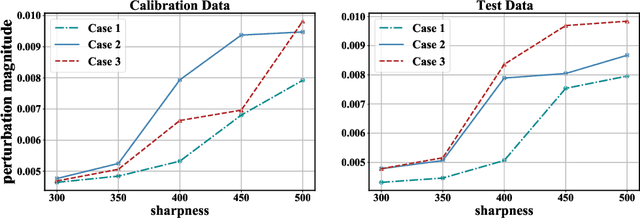

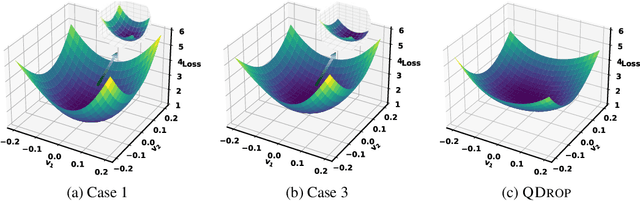
Recently, post-training quantization (PTQ) has driven much attention to produce efficient neural networks without long-time retraining. Despite its low cost, current PTQ works tend to fail under the extremely low-bit setting. In this study, we pioneeringly confirm that properly incorporating activation quantization into the PTQ reconstruction benefits the final accuracy. To deeply understand the inherent reason, a theoretical framework is established, indicating that the flatness of the optimized low-bit model on calibration and test data is crucial. Based on the conclusion, a simple yet effective approach dubbed as QDROP is proposed, which randomly drops the quantization of activations during PTQ. Extensive experiments on various tasks including computer vision (image classification, object detection) and natural language processing (text classification and question answering) prove its superiority. With QDROP, the limit of PTQ is pushed to the 2-bit activation for the first time and the accuracy boost can be up to 51.49%. Without bells and whistles, QDROP establishes a new state of the art for PTQ. Our code is available at https://github.com/wimh966/QDrop and has been integrated into MQBench (https://github.com/ModelTC/MQBench)
Fluid registration between lung CT and stationary chest tomosynthesis images
Mar 06, 2022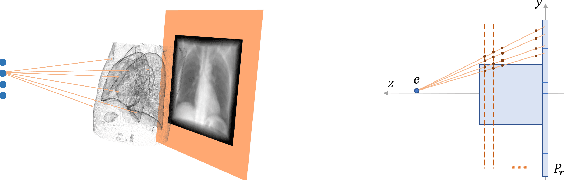

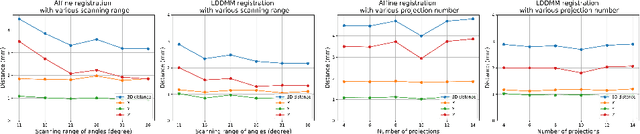
Registration is widely used in image-guided therapy and image-guided surgery to estimate spatial correspondences between organs of interest between planning and treatment images. However, while high-quality computed tomography (CT) images are often available at planning time, limited angle acquisitions are frequently used during treatment because of radiation concerns or imaging time constraints. This requires algorithms to register CT images based on limited angle acquisitions. We, therefore, formulate a 3D/2D registration approach which infers a 3D deformation based on measured projections and digitally reconstructed radiographs of the CT. Most 3D/2D registration approaches use simple transformation models or require complex mathematical derivations to formulate the underlying optimization problem. Instead, our approach entirely relies on differentiable operations which can be combined with modern computational toolboxes supporting automatic differentiation. This then allows for rapid prototyping, integration with deep neural networks, and to support a variety of transformation models including fluid flow models. We demonstrate our approach for the registration between CT and stationary chest tomosynthesis (sDCT) images and show how it naturally leads to an iterative image reconstruction approach.
Multimodal Proximity and Visuotactile Sensing With a Selectively Transmissive Soft Membrane
Apr 18, 2022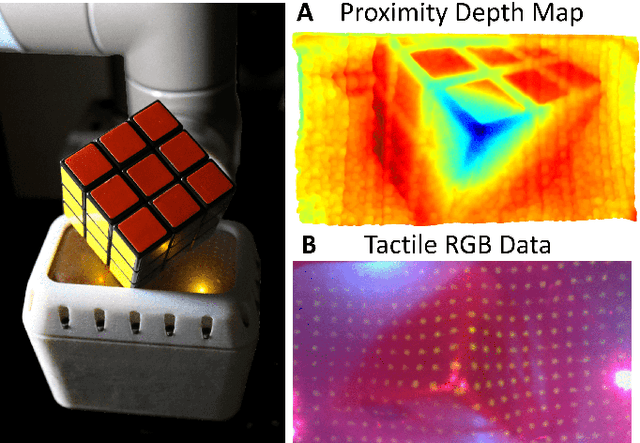
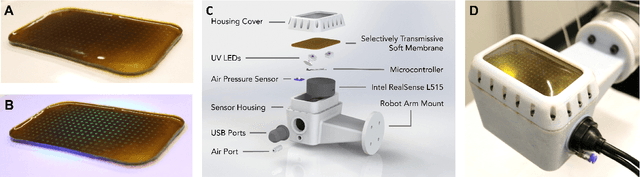
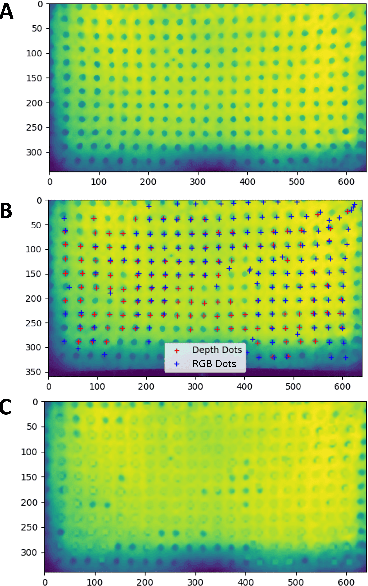
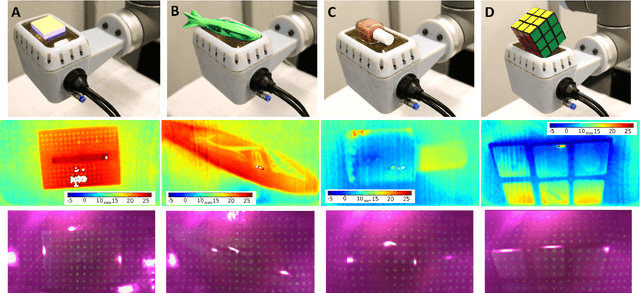
The most common sensing modalities found in a robot perception system are vision and touch, which together can provide global and highly localized data for manipulation. However, these sensing modalities often fail to adequately capture the behavior of target objects during the critical moments as they transition out of static, controlled contact with an end-effector to dynamic and uncontrolled motion. In this work, we present a novel multimodal visuotactile sensor that provides simultaneous visuotactile and proximity depth data. The sensor integrates an RGB camera and air pressure sensor to sense touch with an infrared time-of-flight (ToF) camera to sense proximity by leveraging a selectively transmissive soft membrane to enable the dual sensing modalities. We present the mechanical design, fabrication techniques, algorithm implementations, and evaluation of the sensor's tactile and proximity modalities. The sensor is demonstrated in three open-loop robotic tasks: approaching and contacting an object, catching, and throwing. The fusion of tactile and proximity data could be used to capture key information about a target object's transition behavior for sensor-based control in dynamic manipulation.
Position-aware Location Regression Network for Temporal Video Grounding
Apr 12, 2022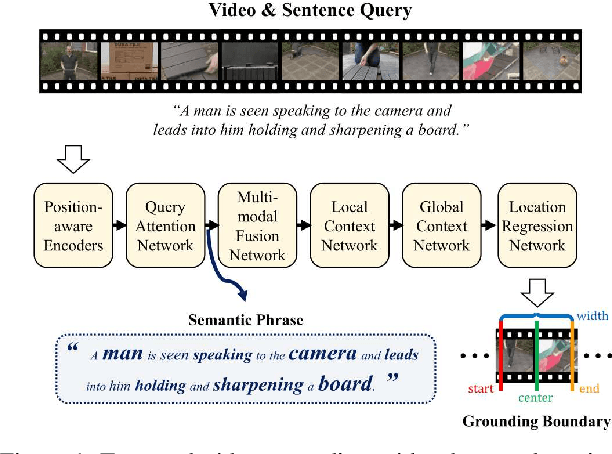
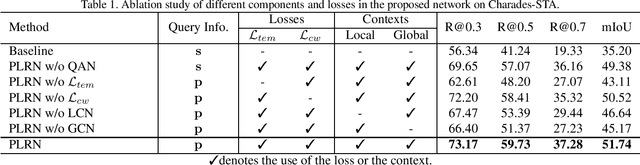
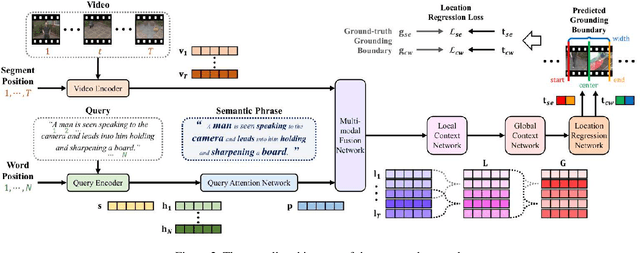

The key to successful grounding for video surveillance is to understand a semantic phrase corresponding to important actors and objects. Conventional methods ignore comprehensive contexts for the phrase or require heavy computation for multiple phrases. To understand comprehensive contexts with only one semantic phrase, we propose Position-aware Location Regression Network (PLRN) which exploits position-aware features of a query and a video. Specifically, PLRN first encodes both the video and query using positional information of words and video segments. Then, a semantic phrase feature is extracted from an encoded query with attention. The semantic phrase feature and encoded video are merged and made into a context-aware feature by reflecting local and global contexts. Finally, PLRN predicts start, end, center, and width values of a grounding boundary. Our experiments show that PLRN achieves competitive performance over existing methods with less computation time and memory.