 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Networks Model for Travel Time Prediction Based on ODTravel Time Matrix
Apr 08, 2020
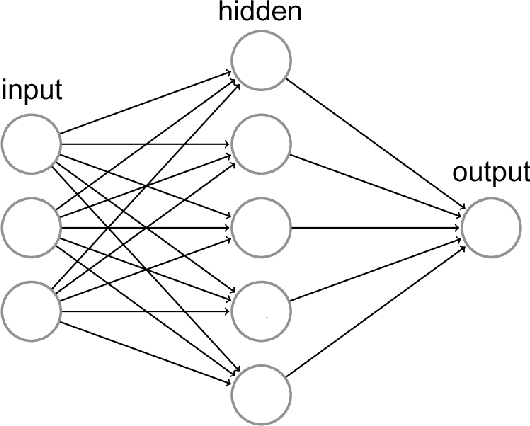
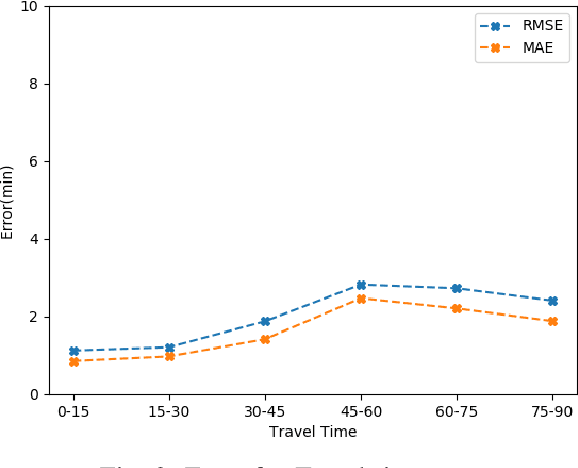
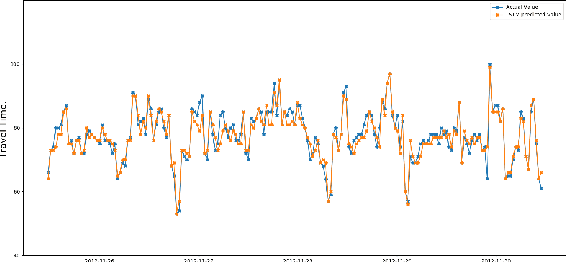
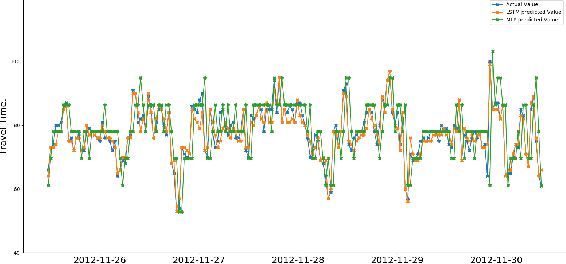
Public transportation system commuters are often interested in getting accurate travel time information to plan their daily activities. However, this information is often difficult to predict accurately due to the irregularities of road traffic, caused by factors such as weather conditions, road accidents, and traffic jams. In this study, two neural network models namely multi-layer(MLP) perceptron and long short-term model(LSTM) are developed for predicting link travel time of a busy route with input generated using Origin-Destination travel time matrix derived from a historical GPS dataset. The experiment result showed that both models can make near-accurate predictions however, LSTM is more susceptible to noise as time step increases.
Wasserstein Adversarial Learning based Temporal Knowledge Graph Embedding
May 04, 2022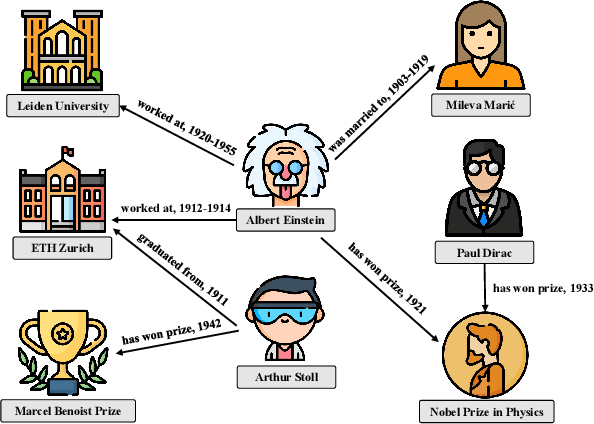
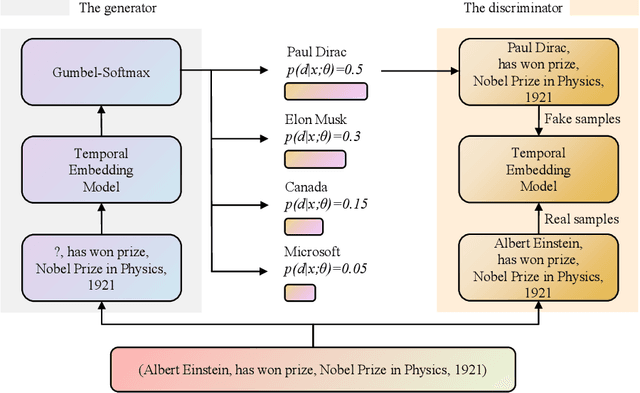
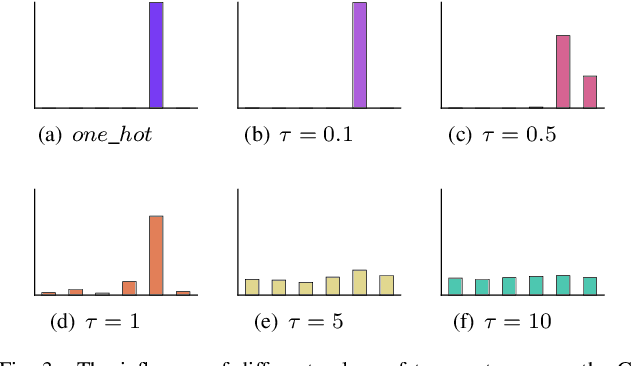

Research on knowledge graph embedding (KGE) has emerged as an active field in which most existing KGE approaches mainly focus on static structural data and ignore the influence of temporal variation involved in time-aware triples. In order to deal with this issue, several temporal knowledge graph embedding (TKGE) approaches have been proposed to integrate temporal and structural information in recent years. However, these methods only employ a uniformly random sampling to construct negative facts. As a consequence, the corrupted samples are often too simplistic for training an effective model. In this paper, we propose a new temporal knowledge graph embedding framework by introducing adversarial learning to further refine the performance of traditional TKGE models. In our framework, a generator is utilized to construct high-quality plausible quadruples and a discriminator learns to obtain the embeddings of entities and relations based on both positive and negative samples. Meanwhile, we also apply a Gumbel-Softmax relaxation and the Wasserstein distance to prevent vanishing gradient problems on discrete data; an inherent flaw in traditional generative adversarial networks. Through comprehensive experimentation on temporal datasets, the results indicate that our proposed framework can attain significant improvements based on benchmark models and also demonstrate the effectiveness and applicability of our framework.
ProtoTEx: Explaining Model Decisions with Prototype Tensors
Apr 11, 2022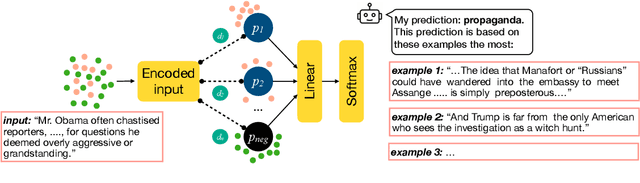
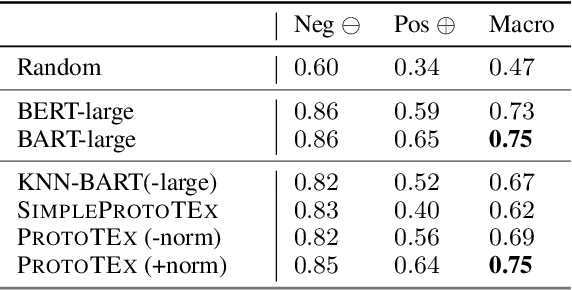
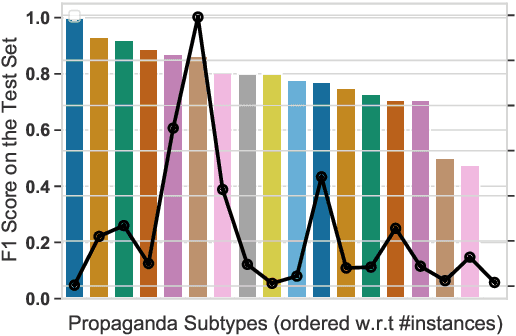

We present ProtoTEx, a novel white-box NLP classification architecture based on prototype networks. ProtoTEx faithfully explains model decisions based on prototype tensors that encode latent clusters of training examples. At inference time, classification decisions are based on the distances between the input text and the prototype tensors, explained via the training examples most similar to the most influential prototypes. We also describe a novel interleaved training algorithm that effectively handles classes characterized by the absence of indicative features. On a propaganda detection task, ProtoTEx accuracy matches BART-large and exceeds BERT-large with the added benefit of providing faithful explanations. A user study also shows that prototype-based explanations help non-experts to better recognize propaganda in online news.
Beam Decoding with Controlled Patience
Apr 11, 2022
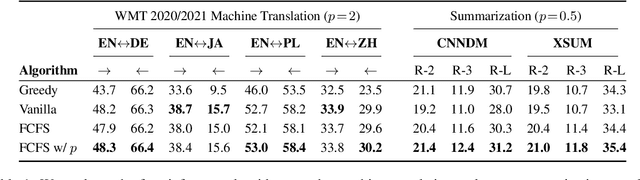


Text generation with beam search has proven successful in a wide range of applications. The commonly-used implementation of beam decoding follows a first come, first served heuristic: it keeps a set of already completed sequences over time steps and stops when the size of this set reaches the beam size. We introduce a patience factor, a simple modification to this decoding algorithm, that generalizes the stopping criterion and provides flexibility to the depth of search. Extensive empirical results demonstrate that the patience factor improves decoding performance of strong pretrained models on news text summarization and machine translation over diverse language pairs, with a negligible inference slowdown. Our approach only modifies one line of code and can be thus readily incorporated in any implementation.
Scale-Equivariant Unrolled Neural Networks for Data-Efficient Accelerated MRI Reconstruction
Apr 21, 2022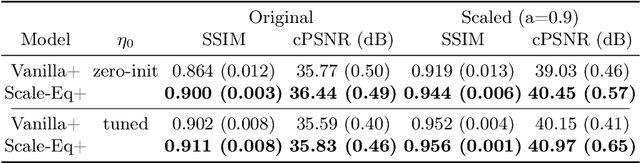
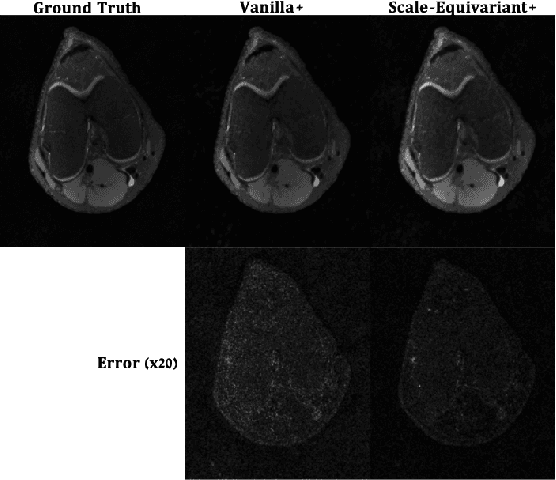
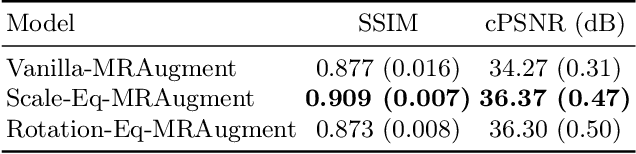
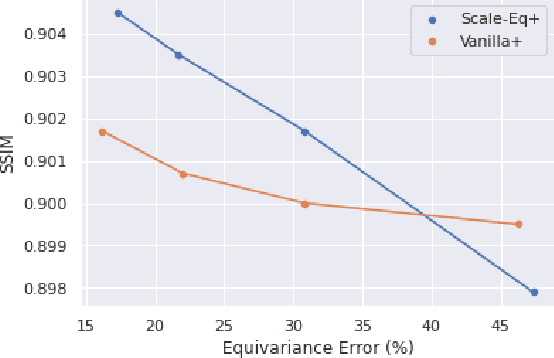
Unrolled neural networks have enabled state-of-the-art reconstruction performance and fast inference times for the accelerated magnetic resonance imaging (MRI) reconstruction task. However, these approaches depend on fully-sampled scans as ground truth data which is either costly or not possible to acquire in many clinical medical imaging applications; hence, reducing dependence on data is desirable. In this work, we propose modeling the proximal operators of unrolled neural networks with scale-equivariant convolutional neural networks in order to improve the data-efficiency and robustness to drifts in scale of the images that might stem from the variability of patient anatomies or change in field-of-view across different MRI scanners. Our approach demonstrates strong improvements over the state-of-the-art unrolled neural networks under the same memory constraints both with and without data augmentations on both in-distribution and out-of-distribution scaled images without significantly increasing the train or inference time.
Calibrating Label Distribution for Class-Imbalanced Barely-Supervised Knee Segmentation
May 07, 2022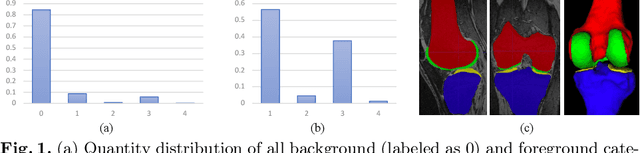
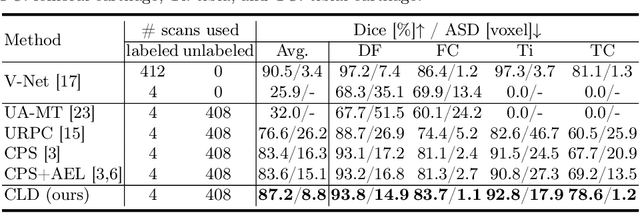
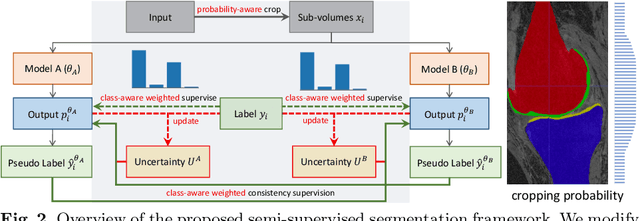

Segmentation of 3D knee MR images is important for the assessment of osteoarthritis. Like other medical data, the volume-wise labeling of knee MR images is expertise-demanded and time-consuming; hence semi-supervised learning (SSL), particularly barely-supervised learning, is highly desirable for training with insufficient labeled data. We observed that the class imbalance problem is severe in the knee MR images as the cartilages only occupy 6% of foreground volumes, and the situation becomes worse without sufficient labeled data. To address the above problem, we present a novel framework for barely-supervised knee segmentation with noisy and imbalanced labels. Our framework leverages label distribution to encourage the network to put more effort into learning cartilage parts. Specifically, we utilize 1.) label quantity distribution for modifying the objective loss function to a class-aware weighted form and 2.) label position distribution for constructing a cropping probability mask to crop more sub-volumes in cartilage areas from both labeled and unlabeled inputs. In addition, we design dual uncertainty-aware sampling supervision to enhance the supervision of low-confident categories for efficient unsupervised learning. Experiments show that our proposed framework brings significant improvements by incorporating the unlabeled data and alleviating the problem of class imbalance. More importantly, our method outperforms the state-of-the-art SSL methods, demonstrating the potential of our framework for the more challenging SSL setting.
Finite-Time Convergence of Continuous-Time Optimization Algorithms via Differential Inclusions
Dec 18, 2019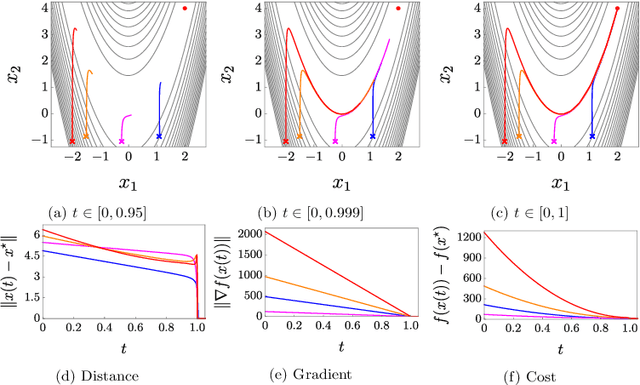
In this paper, we propose two discontinuous dynamical systems in continuous time with guaranteed prescribed finite-time local convergence to strict local minima of a given cost function. Our approach consists of exploiting a Lyapunov-based differential inequality for differential inclusions, which leads to finite-time stability and thus finite-time convergence with a provable bound on the settling time. In particular, for exact solutions to the aforementioned differential inequality, the settling-time bound is also exact, thus achieving prescribed finite-time convergence. We thus construct a class of discontinuous dynamical systems, of second order with respect to the cost function, that serve as continuous-time optimization algorithms with finite-time convergence and prescribed convergence time. Finally, we illustrate our results on the Rosenbrock function.
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
Apr 11, 2021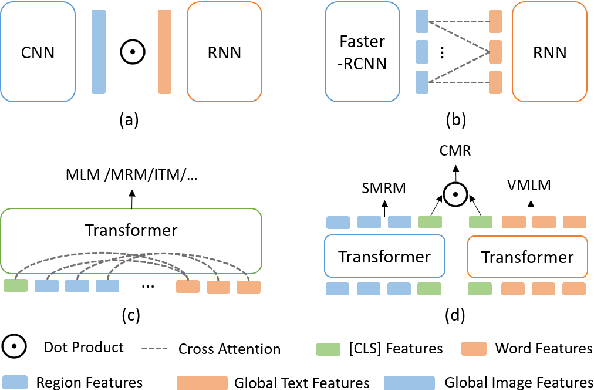
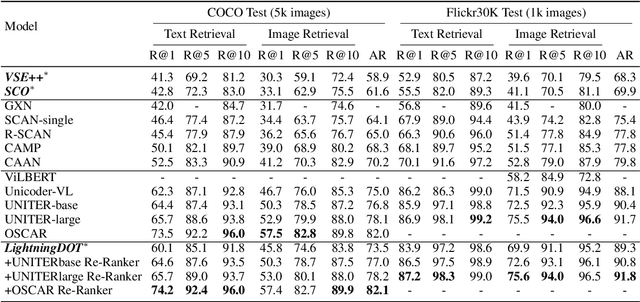
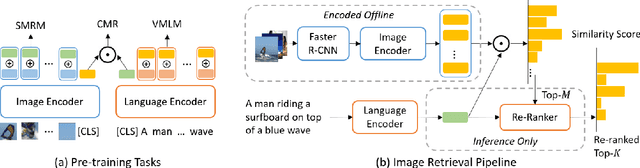

Multimodal pre-training has propelled great advancement in vision-and-language research. These large-scale pre-trained models, although successful, fatefully suffer from slow inference speed due to enormous computation cost mainly from cross-modal attention in Transformer architecture. When applied to real-life applications, such latency and computation demand severely deter the practical use of pre-trained models. In this paper, we study Image-text retrieval (ITR), the most mature scenario of V+L application, which has been widely studied even prior to the emergence of recent pre-trained models. We propose a simple yet highly effective approach, LightningDOT that accelerates the inference time of ITR by thousands of times, without sacrificing accuracy. LightningDOT removes the time-consuming cross-modal attention by pre-training on three novel learning objectives, extracting feature indexes offline, and employing instant dot-product matching with further re-ranking, which significantly speeds up retrieval process. In fact, LightningDOT achieves new state of the art across multiple ITR benchmarks such as Flickr30k, COCO and Multi30K, outperforming existing pre-trained models that consume 1000x magnitude of computational hours. Code and pre-training checkpoints are available at https://github.com/intersun/LightningDOT.
Non-Uniformly Terminating Chase: Size and Complexity
Apr 26, 2022The chase procedure, originally introduced for checking implication of database constraints, and later on used for computing data exchange solutions, has recently become a central algorithmic tool in rule-based ontological reasoning. In this context, a key problem is non-uniform chase termination: does the chase of a database w.r.t. a rule-based ontology terminate? And if this is the case, what is the size of the result of the chase? We focus on guarded tuple-generating dependencies (TGDs), which form a robust rule-based ontology language, and study the above central questions for the semi-oblivious version of the chase. One of our main findings is that non-uniform semi-oblivious chase termination for guarded TGDs is feasible in polynomial time w.r.t. the database, and the size of the result of the chase (whenever is finite) is linear w.r.t. the database. Towards our results concerning non-uniform chase termination, we show that basic techniques such as simplification and linearization, originally introduced in the context of ontological query answering, can be safely applied to the chase termination problem.
Direct LiDAR-Inertial Odometry
Mar 18, 2022
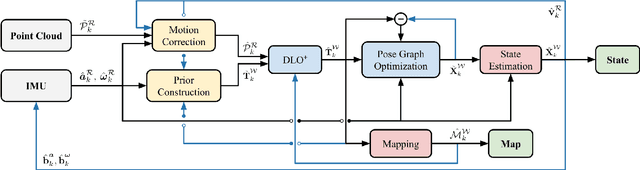
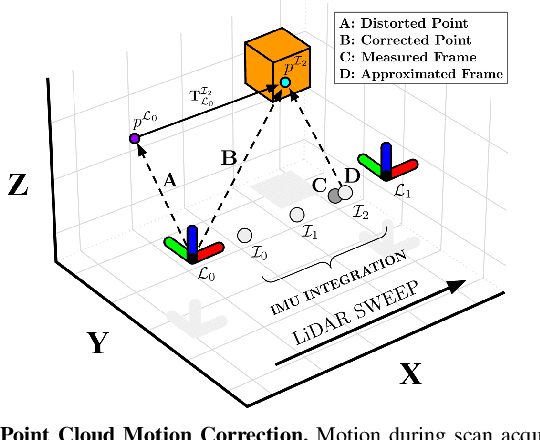
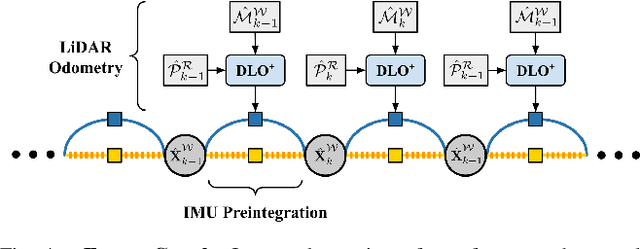
This paper proposes a new LiDAR-inertial odometry framework that generates accurate state estimates and detailed maps in real-time on resource-constrained mobile robots. Our Direct LiDAR-Inertial Odometry (DLIO) algorithm utilizes a hybrid architecture that combines the benefits of loosely-coupled and tightly-coupled IMU integration to enhance reliability and real-time performance while improving accuracy. The proposed architecture has two key elements. The first is a fast keyframe-based LiDAR scan-matcher that builds an internal map by registering dense point clouds to a local submap with a translational and rotational prior generated by a nonlinear motion model. The second is a factor graph and high-rate propagator that fuses the output of the scan-matcher with preintegrated IMU measurements for up-to-date pose, velocity, and bias estimates. These estimates enable us to accurately deskew the next point cloud using a nonlinear kinematic model for precise motion correction, in addition to initializing the next scan-to-map optimization prior. We demonstrate DLIO's superior localization accuracy, map quality, and lower computational overhead by comparing it to the state-of-the-art using multiple benchmark, public, and self-collected datasets on both consumer and hobby-grade hardware.