 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Decision-making of Emergent Incident based on P-MADDPG
Mar 19, 2022
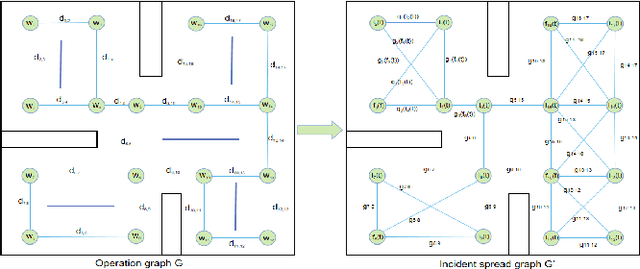
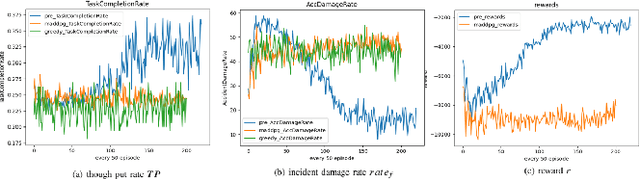
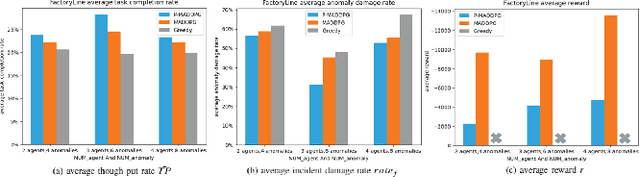

In recent years, human casualties and damage to resources caused by emergent incidents have become a serious problem worldwide. In this paper, we model the emergency decision-making problem and use Multi-agent System (MAS) to solve the problem that the decision speed cannot keep up with the spreading speed. MAS can play an important role in the automated execution of these tasks to reduce mission completion time. In this paper, we propose a P-MADDPG algorithm to solve the emergency decision-making problem of emergent incidents, which predicts the nodes where an incident may occur in the next time by GRU model and makes decisions before the incident occurs, thus solving the problem that the decision speed cannot keep up with the spreading speed. A simulation environment was established for realistic scenarios, and three scenarios were selected to test the performance of P-MADDPG in emergency decision-making problems for emergent incidents: unmanned storage, factory assembly line, and civil airport baggage transportation. Simulation results using the P-MADDPG algorithm are compared with the greedy algorithm and the MADDPG algorithm, and the final experimental results show that the P-MADDPG algorithm converges faster and better than the other algorithms in scenarios of different sizes. This shows that the P-MADDP algorithm is effective for emergency decision-making in emergent incident.
Partial Relaxed Optimal Transport for Denoised Recommendation
Apr 19, 2022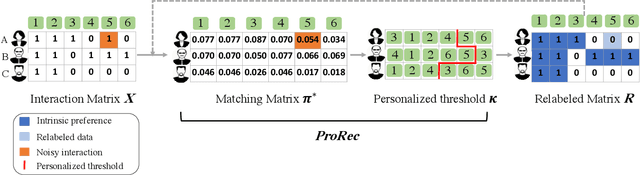
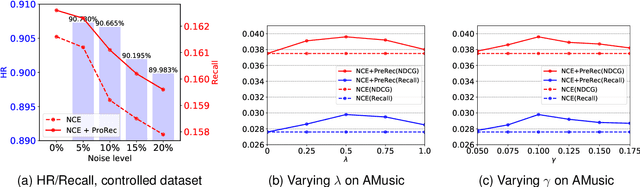
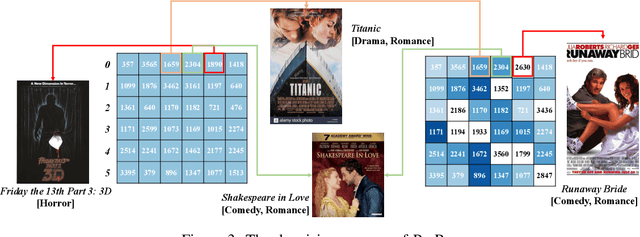
The interaction data used by recommender systems (RSs) inevitably include noises resulting from mistaken or exploratory clicks, especially under implicit feedbacks. Without proper denoising, RS models cannot effectively capture users' intrinsic preferences and the true interactions between users and items. To address such noises, existing methods mostly rely on auxiliary data which are not always available. In this work, we ground on Optimal Transport (OT) to globally match a user embedding space and an item embedding space, allowing both non-deep and deep RS models to discriminate intrinsic and noisy interactions without supervision. Specifically, we firstly leverage the OT framework via Sinkhorn distance to compute the continuous many-to-many user-item matching scores. Then, we relax the regularization in Sinkhorn distance to achieve a closed-form solution with a reduced time complexity. Finally, to consider individual user behaviors for denoising, we develop a partial OT framework to adaptively relabel user-item interactions through a personalized thresholding mechanism. Extensive experiments show that our framework can significantly boost the performances of existing RS models.
RLFlow: Optimising Neural Network Subgraph Transformation with World Models
May 03, 2022
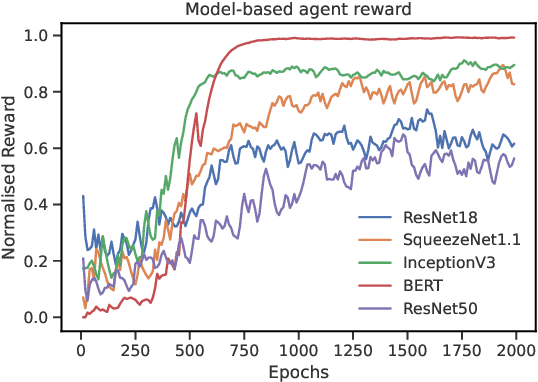
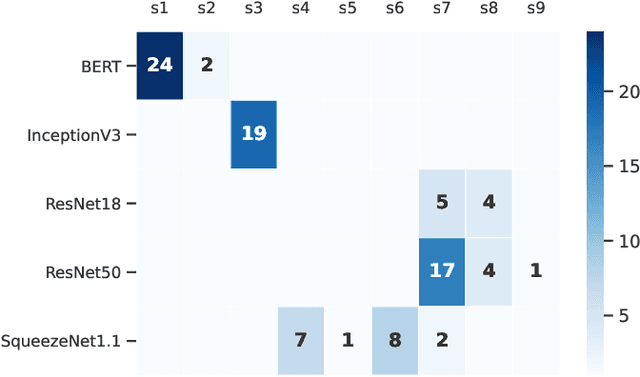
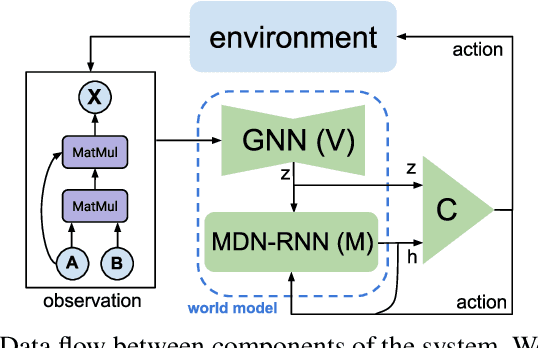
We explored the use of reinforcement learning (RL) agents that can learn to perform neural network subgraph transformations, without the need of expertly designed heuristics to achieve a high level of performance. Reducing compute requirements of deep learning models is a focus of extensive research and many systems, optimisations and just-in-time (JIT) compilers have been proposed to decrease runtime. Recent work has aimed to apply reinforcement learning to computer systems with some success, especially using model-free RL techniques. Model-based reinforcement learning methods have seen an increased focus in research as they can be used to learn the transition dynamics of the environment; this can be leveraged to train an agent using the hallucinogenic environment, thereby increasing sample efficiency compared to model-free approaches. Furthermore, when using a world model as a simulated environment, batch rollouts can occur safely in parallel and, especially in systems environments, it overcomes the latency impact of updating system environments that can take orders of magnitude longer to perform an action compared to simple emulators for video games. We propose a design for a model-based agent which learns to optimise the architecture of neural networks by performing a sequence of subgraph transformations to reduce model runtime. We show our approach can match the performance of state of the art on common convolutional networks and outperform those by up to 5% on transformer-style architectures.
Bidirectional Pricing and Demand Response for Nanogrids with HVAC Systems
Mar 01, 2022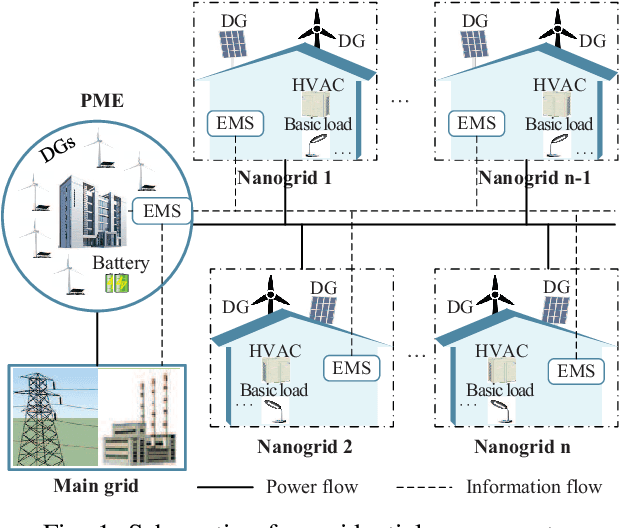

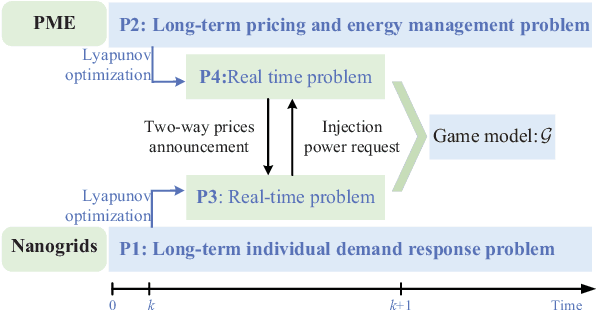
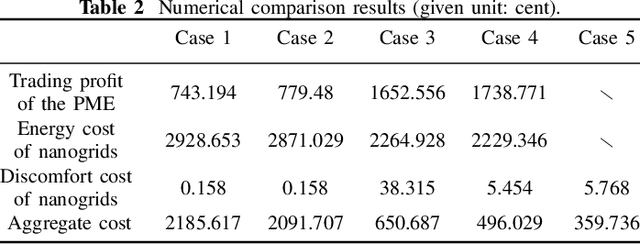
Owing to the fluctuant renewable generation and power demand, the energy surplus or deficit in each nanogrid is embodied differently across time. To stimulate local renewable energy consumption and minimize the long-term energy cost, some issues still remain to be explored: when and how the energy demand and bidirectional trading prices are scheduled considering personal comfort preferences and environmental factors. For this purpose, the demand response and two-way pricing problems concurrently for nanogrids and a public monitoring entity (PME) are studied with exploiting the large potential thermal elastic ability of heating, ventilation and air-conditioning (HVAC) units. Different from nanogrids, in terms of minimizing time-average costs, PME aims to set reasonable prices and optimize profits by trading with nanogrids and the main grid bi-directionally. In particular, such bilevel energy management problem is formulated as a stochastic form in a long-term horizon. Since there are uncertain system parameters, time-coupled queue constraints and the interplay of bilevel decision-making, it is challenging to solve the formulated problems. To this end, we derive a form of relaxation based on Lyapunov optimization technique to make the energy management problem tractable without forecasting the related system parameters. The transaction between nanogrids and PME is captured by a one-leader and multi-follower Stackelberg game framework. Then, theoretical analysis of the existence and uniqueness of Stackelberg equilibrium (SE) is developed based on the proposed game property. Following that, we devise an optimization algorithm to reach the SE with less information exchange. Numerical experiments validate the effectiveness of the proposed approach.
Deep Q-network using reservoir computing with multi-layered readout
Mar 03, 2022
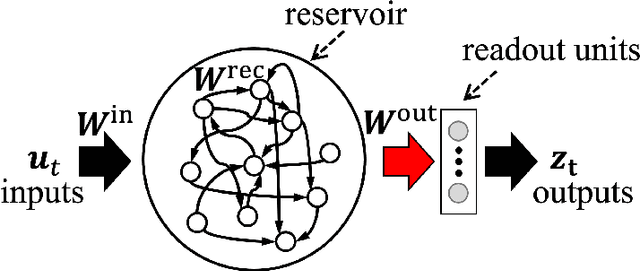
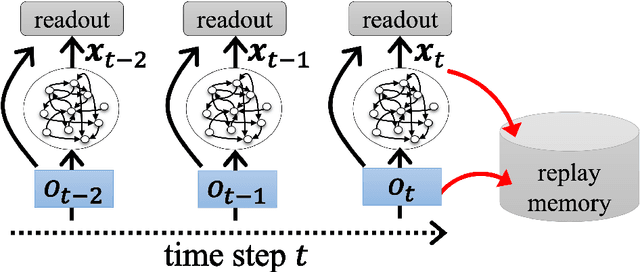
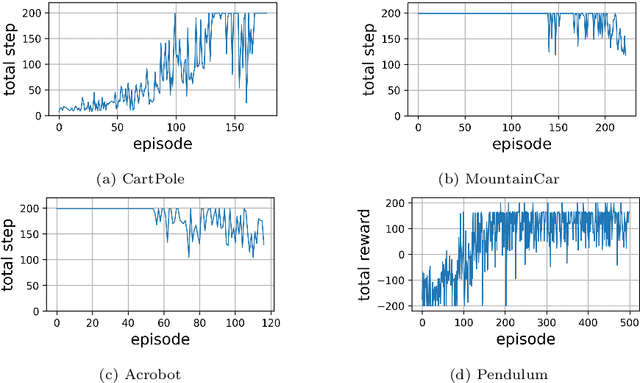
Recurrent neural network (RNN) based reinforcement learning (RL) is used for learning context-dependent tasks and has also attracted attention as a method with remarkable learning performance in recent research. However, RNN-based RL has some issues that the learning procedures tend to be more computationally expensive, and training with backpropagation through time (BPTT) is unstable because of vanishing/exploding gradients problem. An approach with replay memory introducing reservoir computing has been proposed, which trains an agent without BPTT and avoids these issues. The basic idea of this approach is that observations from the environment are input to the reservoir network, and both the observation and the reservoir output are stored in the memory. This paper shows that the performance of this method improves by using a multi-layered neural network for the readout layer, which regularly consists of a single linear layer. The experimental results show that using multi-layered readout improves the learning performance of four classical control tasks that require time-series processing.
A Unified Analysis of Dynamic Interactive Learning
Apr 14, 2022In this paper we investigate the problem of learning evolving concepts over a combinatorial structure. Previous work by Emamjomeh-Zadeh et al. [2020] introduced dynamics into interactive learning as a way to model non-static user preferences in clustering problems or recommender systems. We provide many useful contributions to this problem. First, we give a framework that captures both of the models analyzed by [Emamjomeh-Zadeh et al., 2020], which allows us to study any type of concept evolution and matches the same query complexity bounds and running time guarantees of the previous models. Using this general model we solve the open problem of closing the gap between the upper and lower bounds on query complexity. Finally, we study an efficient algorithm where the learner simply follows the feedback at each round, and we provide mistake bounds for low diameter graphs such as cliques, stars, and general o(log n) diameter graphs by using a Markov Chain model.
Simulating Network Paths with Recurrent Buffering Units
Feb 23, 2022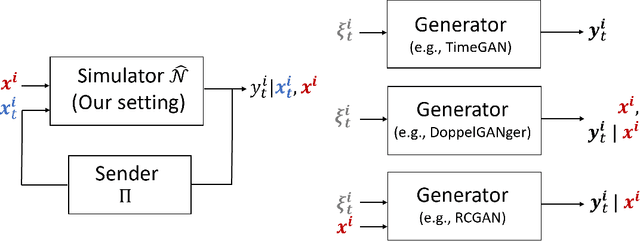
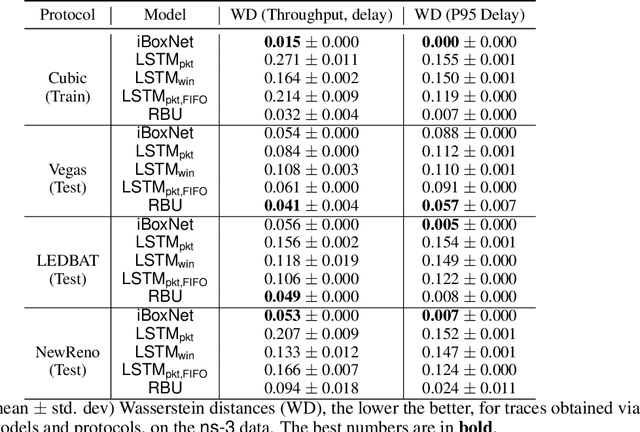
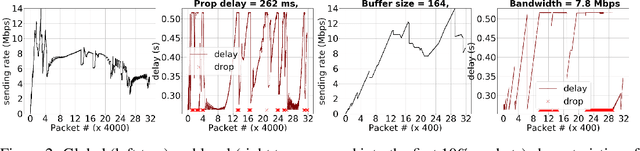
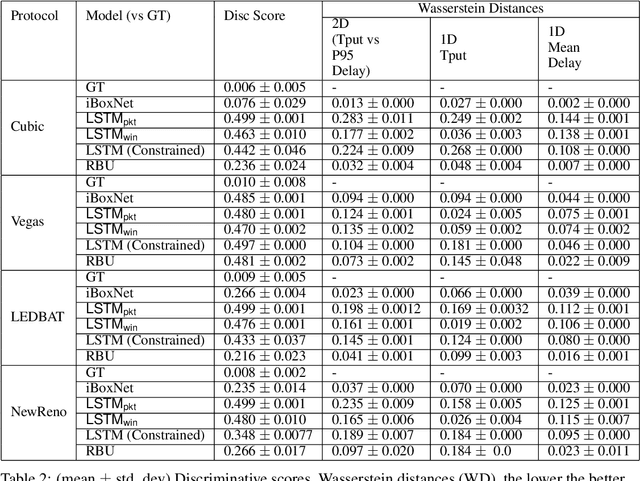
Simulating physical network paths (e.g., Internet) is a cornerstone research problem in the emerging sub-field of AI-for-networking. We seek a model that generates end-to-end packet delay values in response to the time-varying load offered by a sender, which is typically a function of the previously output delays. We formulate an ML problem at the intersection of dynamical systems, sequential decision making, and time-series generative modeling. We propose a novel grey-box approach to network simulation that embeds the semantics of physical network path in a new RNN-style architecture called Recurrent Buffering Unit, providing the interpretability of standard network simulator tools, the power of neural models, the efficiency of SGD-based techniques for learning, and yielding promising results on synthetic and real-world network traces.
Multimodal Proximity and Visuotactile Sensing With a Selectively Transmissive Soft Membrane
Apr 18, 2022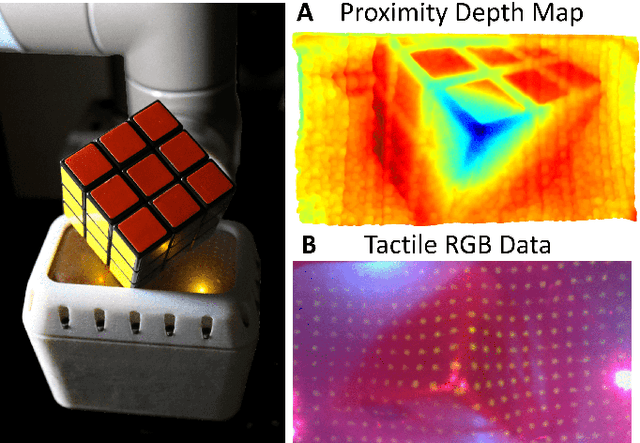
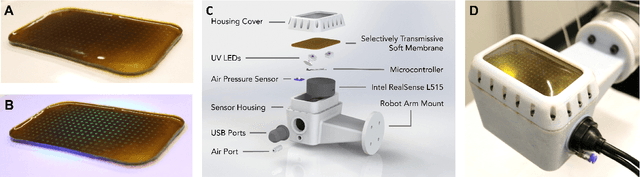
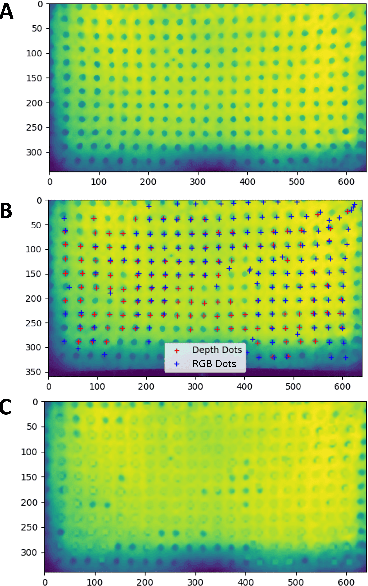
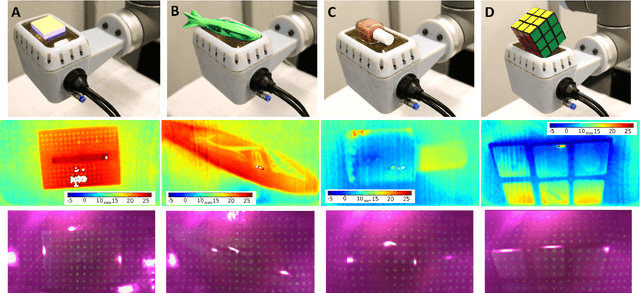
The most common sensing modalities found in a robot perception system are vision and touch, which together can provide global and highly localized data for manipulation. However, these sensing modalities often fail to adequately capture the behavior of target objects during the critical moments as they transition out of static, controlled contact with an end-effector to dynamic and uncontrolled motion. In this work, we present a novel multimodal visuotactile sensor that provides simultaneous visuotactile and proximity depth data. The sensor integrates an RGB camera and air pressure sensor to sense touch with an infrared time-of-flight (ToF) camera to sense proximity by leveraging a selectively transmissive soft membrane to enable the dual sensing modalities. We present the mechanical design, fabrication techniques, algorithm implementations, and evaluation of the sensor's tactile and proximity modalities. The sensor is demonstrated in three open-loop robotic tasks: approaching and contacting an object, catching, and throwing. The fusion of tactile and proximity data could be used to capture key information about a target object's transition behavior for sensor-based control in dynamic manipulation.
Private Frequency Estimation via Projective Geometry
Mar 01, 2022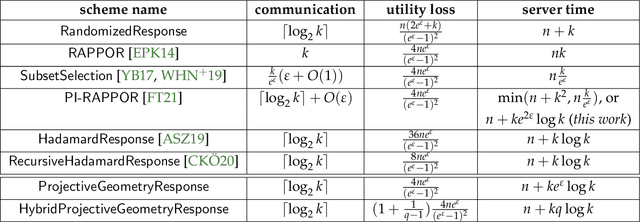
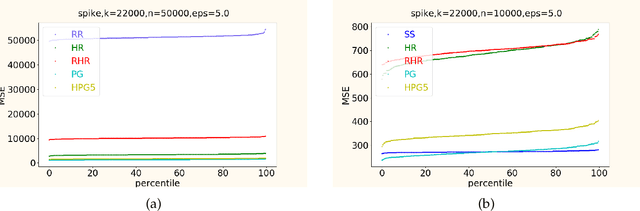
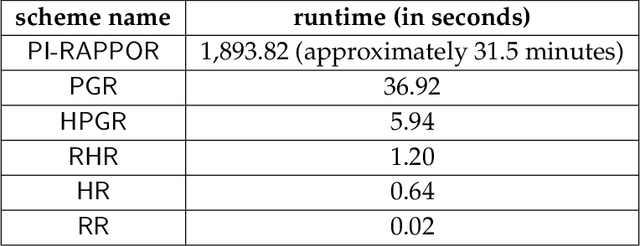
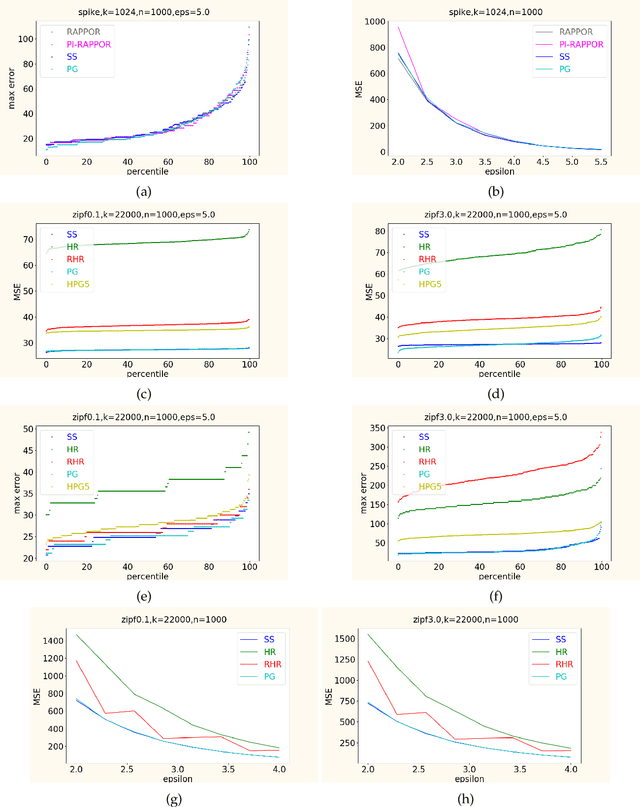
In this work, we propose a new algorithm ProjectiveGeometryResponse (PGR) for locally differentially private (LDP) frequency estimation. For a universe size of $k$ and with $n$ users, our $\varepsilon$-LDP algorithm has communication cost $\lceil\log_2k\rceil$ bits in the private coin setting and $\varepsilon\log_2 e + O(1)$ in the public coin setting, and has computation cost $O(n + k\exp(\varepsilon) \log k)$ for the server to approximately reconstruct the frequency histogram, while achieving the state-of-the-art privacy-utility tradeoff. In many parameter settings used in practice this is a significant improvement over the $ O(n+k^2)$ computation cost that is achieved by the recent PI-RAPPOR algorithm (Feldman and Talwar; 2021). Our empirical evaluation shows a speedup of over 50x over PI-RAPPOR while using approximately 75x less memory for practically relevant parameter settings. In addition, the running time of our algorithm is within an order of magnitude of HadamardResponse (Acharya, Sun, and Zhang; 2019) and RecursiveHadamardResponse (Chen, Kairouz, and Ozgur; 2020) which have significantly worse reconstruction error. The error of our algorithm essentially matches that of the communication- and time-inefficient but utility-optimal SubsetSelection (SS) algorithm (Ye and Barg; 2017). Our new algorithm is based on using Projective Planes over a finite field to define a small collection of sets that are close to being pairwise independent and a dynamic programming algorithm for approximate histogram reconstruction on the server side. We also give an extension of PGR, which we call HybridProjectiveGeometryResponse, that allows trading off computation time with utility smoothly.
Modality-Buffet for Real-Time Object Detection
Nov 17, 2020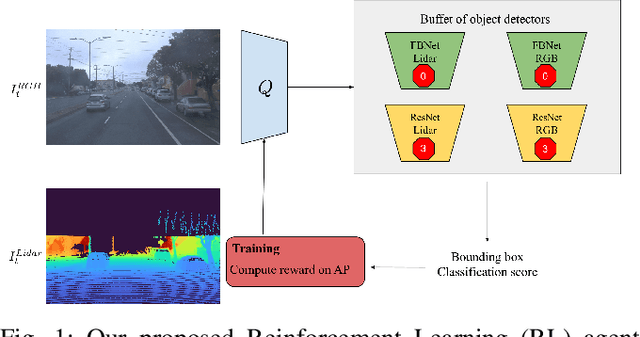
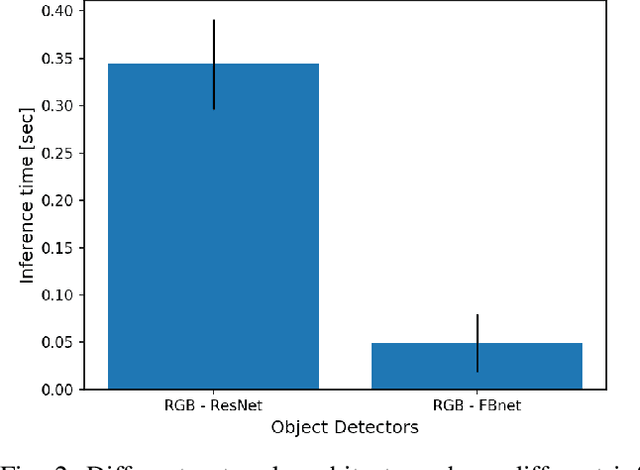
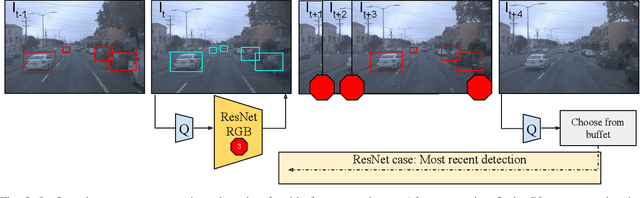
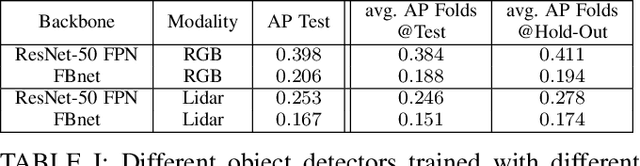
Real-time object detection in videos using lightweight hardware is a crucial component of many robotic tasks. Detectors using different modalities and with varying computational complexities offer different trade-offs. One option is to have a very lightweight model that can predict from all modalities at once for each frame. However, in some situations (e.g., in static scenes) it might be better to have a more complex but more accurate model and to extrapolate from previous predictions for the frames coming in at processing time. We formulate this task as a sequential decision making problem and use reinforcement learning (RL) to generate a policy that decides from the RGB input which detector out of a portfolio of different object detectors to take for the next prediction. The objective of the RL agent is to maximize the accuracy of the predictions per image. We evaluate the approach on the Waymo Open Dataset and show that it exceeds the performance of each single detector.