 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RLFlow: Optimising Neural Network Subgraph Transformation with World Models
May 03, 2022
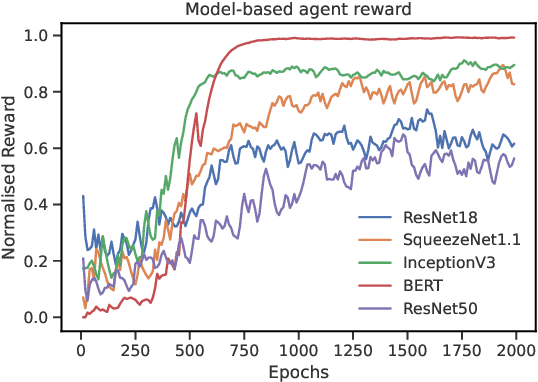
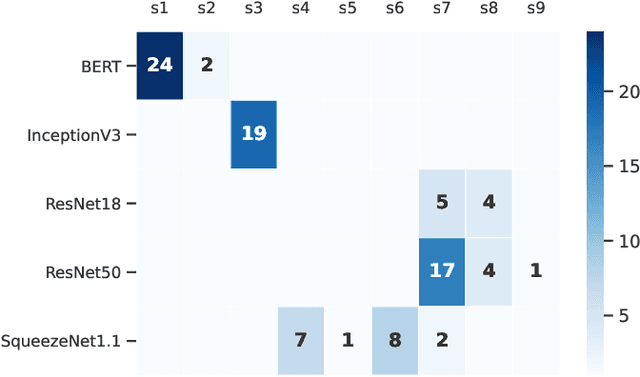
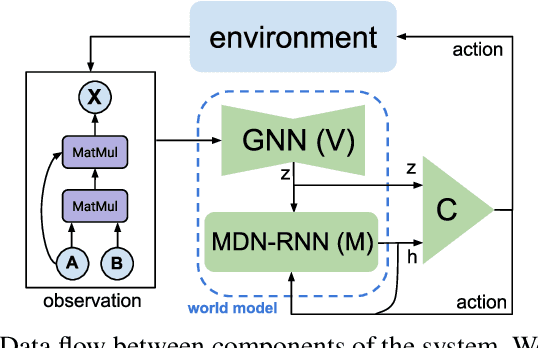
We explored the use of reinforcement learning (RL) agents that can learn to perform neural network subgraph transformations, without the need of expertly designed heuristics to achieve a high level of performance. Reducing compute requirements of deep learning models is a focus of extensive research and many systems, optimisations and just-in-time (JIT) compilers have been proposed to decrease runtime. Recent work has aimed to apply reinforcement learning to computer systems with some success, especially using model-free RL techniques. Model-based reinforcement learning methods have seen an increased focus in research as they can be used to learn the transition dynamics of the environment; this can be leveraged to train an agent using the hallucinogenic environment, thereby increasing sample efficiency compared to model-free approaches. Furthermore, when using a world model as a simulated environment, batch rollouts can occur safely in parallel and, especially in systems environments, it overcomes the latency impact of updating system environments that can take orders of magnitude longer to perform an action compared to simple emulators for video games. We propose a design for a model-based agent which learns to optimise the architecture of neural networks by performing a sequence of subgraph transformations to reduce model runtime. We show our approach can match the performance of state of the art on common convolutional networks and outperform those by up to 5% on transformer-style architectures.
SpeechSplit 2.0: Unsupervised speech disentanglement for voice conversion Without tuning autoencoder Bottlenecks
Mar 26, 2022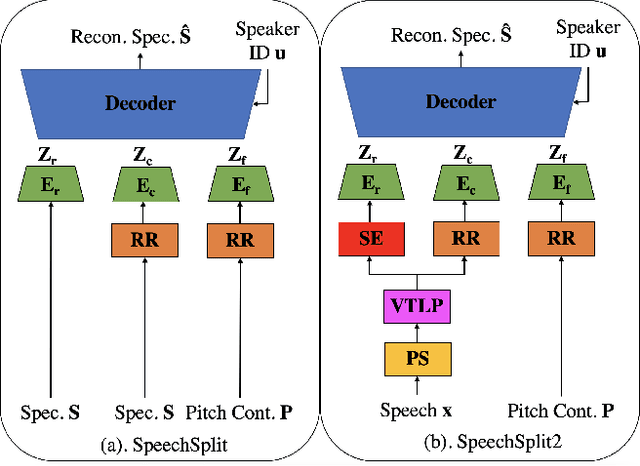
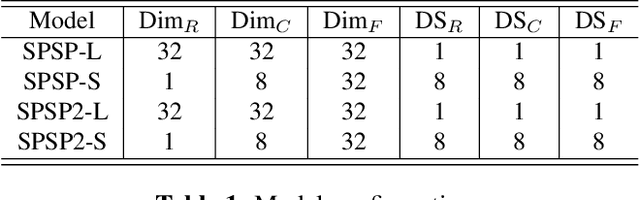
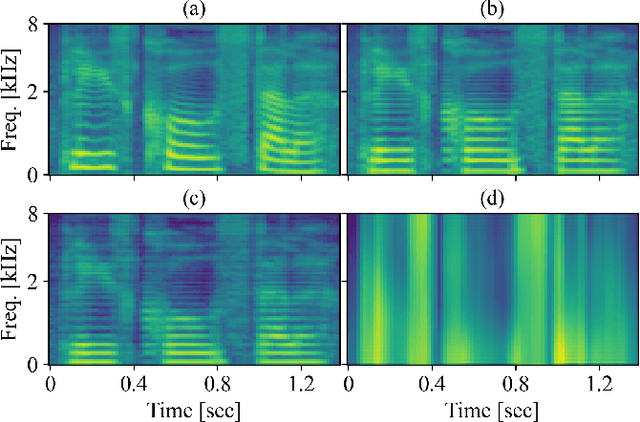
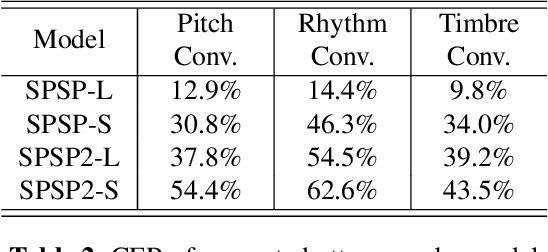
SpeechSplit can perform aspect-specific voice conversion by disentangling speech into content, rhythm, pitch, and timbre using multiple autoencoders in an unsupervised manner. However, SpeechSplit requires careful tuning of the autoencoder bottlenecks, which can be time-consuming and less robust. This paper proposes SpeechSplit 2.0, which constrains the information flow of the speech component to be disentangled on the autoencoder input using efficient signal processing methods instead of bottleneck tuning. Evaluation results show that SpeechSplit 2.0 achieves comparable performance to SpeechSplit in speech disentanglement and superior robustness to the bottleneck size variations. Our code is available at https://github.com/biggytruck/SpeechSplit2.
Interaction-Aware Labeled Multi-Bernoulli Filter
Apr 19, 2022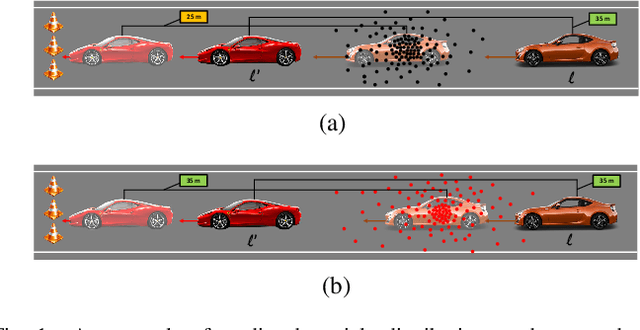
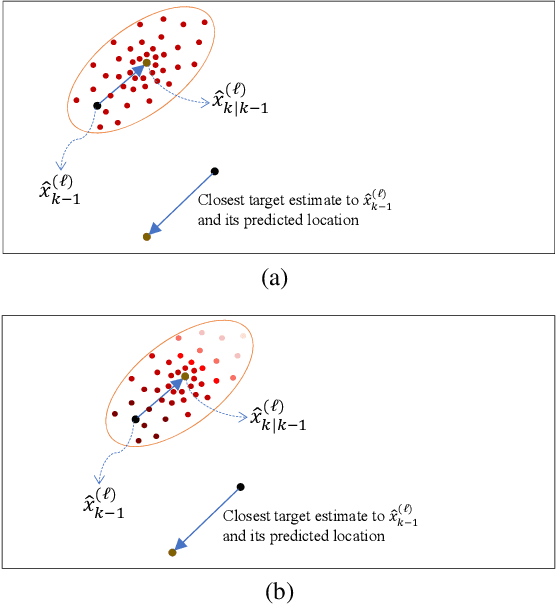
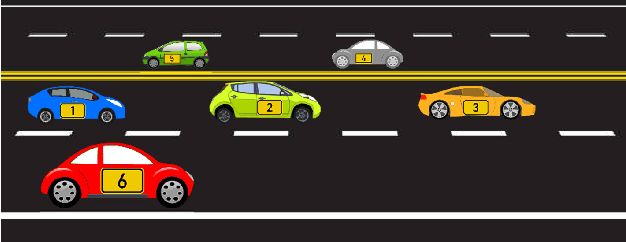
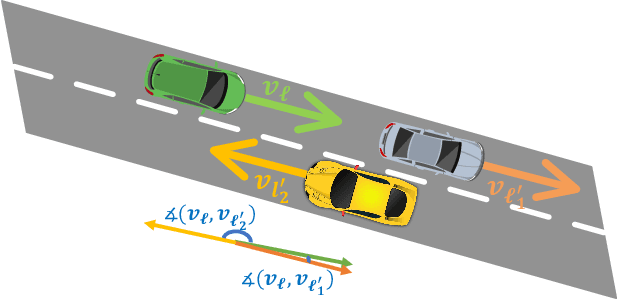
Tracking multiple objects through time is an important part of an intelligent transportation system. Random finite set (RFS)-based filters are one of the emerging techniques for tracking multiple objects. In multi-object tracking (MOT), a common assumption is that each object is moving independent of its surroundings. But in many real-world applications, target objects interact with one another and the environment. Such interactions, when considered for tracking, are usually modeled by an interactive motion model which is application specific. In this paper, we present a novel approach to incorporate target interactions within the prediction step of an RFS-based multi-target filter, i.e. labeled multi-Bernoulli (LMB) filter. The method has been developed for two practical applications of tracking a coordinated swarm and vehicles. The method has been tested for a complex vehicle tracking dataset and compared with the LMB filter through the OSPA and OSPA$^{(2)}$ metrics. The results demonstrate that the proposed interaction-aware method depicts considerable performance enhancement over the LMB filter in terms of the selected metrics.
Partial Relaxed Optimal Transport for Denoised Recommendation
Apr 19, 2022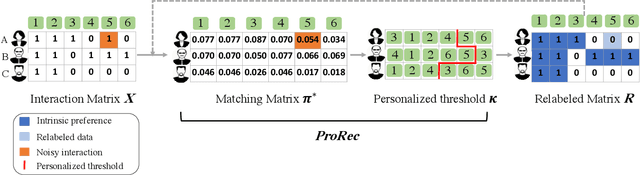
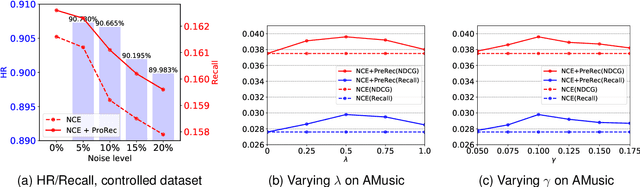
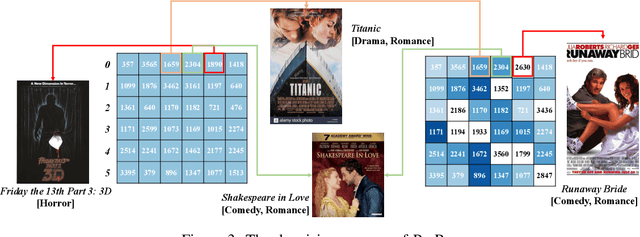
The interaction data used by recommender systems (RSs) inevitably include noises resulting from mistaken or exploratory clicks, especially under implicit feedbacks. Without proper denoising, RS models cannot effectively capture users' intrinsic preferences and the true interactions between users and items. To address such noises, existing methods mostly rely on auxiliary data which are not always available. In this work, we ground on Optimal Transport (OT) to globally match a user embedding space and an item embedding space, allowing both non-deep and deep RS models to discriminate intrinsic and noisy interactions without supervision. Specifically, we firstly leverage the OT framework via Sinkhorn distance to compute the continuous many-to-many user-item matching scores. Then, we relax the regularization in Sinkhorn distance to achieve a closed-form solution with a reduced time complexity. Finally, to consider individual user behaviors for denoising, we develop a partial OT framework to adaptively relabel user-item interactions through a personalized thresholding mechanism. Extensive experiments show that our framework can significantly boost the performances of existing RS models.
Non-intrusive surrogate modeling for parametrized time-dependent PDEs using convolutional autoencoders
Jan 14, 2021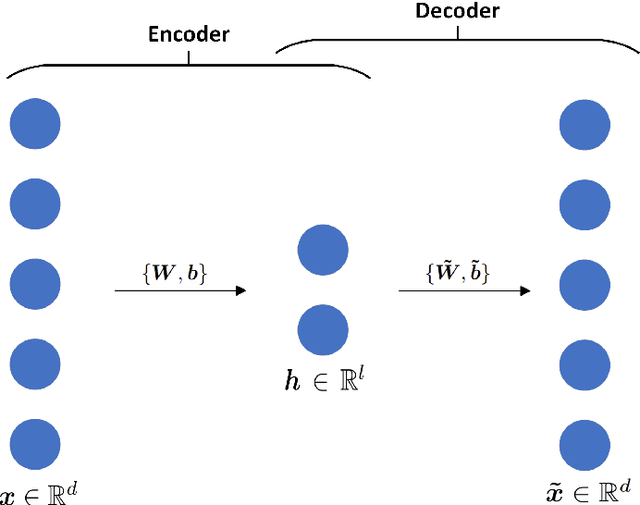
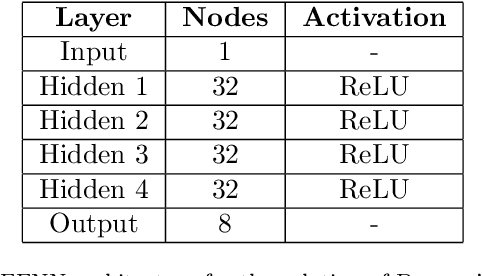
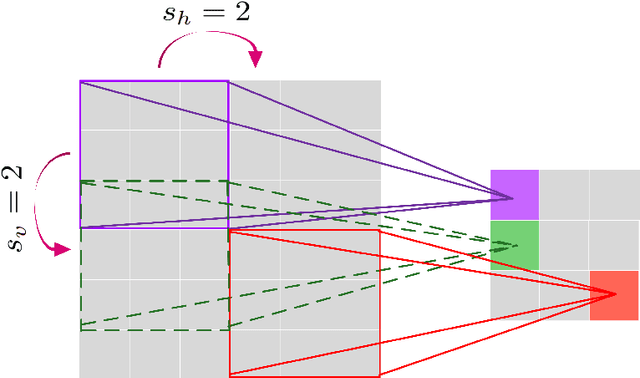
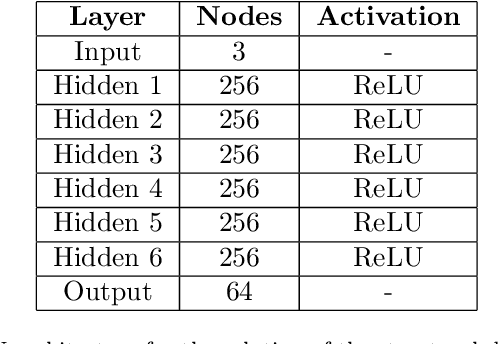
This work presents a non-intrusive surrogate modeling scheme based on machine learning technology for predictive modeling of complex systems, described by parametrized time-dependent PDEs. For these problems, typical finite element approaches involve the spatiotemporal discretization of the PDE and the solution of the corresponding linear system of equations at each time step. Instead, the proposed method utilizes a convolutional autoencoder in conjunction with a feed forward neural network to establish a low-cost and accurate mapping from the problem's parametric space to its solution space. For this purpose, time history response data are collected by solving the high-fidelity model via FEM for a reduced set of parameter values. Then, by applying the convolutional autoencoder to this data set, a low-dimensional representation of the high-dimensional solution matrices is provided by the encoder, while the reconstruction map is obtained by the decoder. Using the latent representation given by the encoder, a feed-forward neural network is efficiently trained to map points from the problem's parametric space to the compressed version of the respective solution matrices. This way, the encoded response of the system at new parameter values is given by the neural network, while the entire response is delivered by the decoder. This approach effectively bypasses the need to serially formulate and solve the system's governing equations at each time increment, thus resulting in a significant cost reduction and rendering the method ideal for problems requiring repeated model evaluations or 'real-time' computations. The elaborated methodology is demonstrated on the stochastic analysis of time-dependent PDEs solved with the Monte Carlo method, however, it can be straightforwardly applied to other similar-type problems, such as sensitivity analysis, design optimization, etc.
A Unified Analysis of Dynamic Interactive Learning
Apr 14, 2022In this paper we investigate the problem of learning evolving concepts over a combinatorial structure. Previous work by Emamjomeh-Zadeh et al. [2020] introduced dynamics into interactive learning as a way to model non-static user preferences in clustering problems or recommender systems. We provide many useful contributions to this problem. First, we give a framework that captures both of the models analyzed by [Emamjomeh-Zadeh et al., 2020], which allows us to study any type of concept evolution and matches the same query complexity bounds and running time guarantees of the previous models. Using this general model we solve the open problem of closing the gap between the upper and lower bounds on query complexity. Finally, we study an efficient algorithm where the learner simply follows the feedback at each round, and we provide mistake bounds for low diameter graphs such as cliques, stars, and general o(log n) diameter graphs by using a Markov Chain model.
Decision-making of Emergent Incident based on P-MADDPG
Mar 19, 2022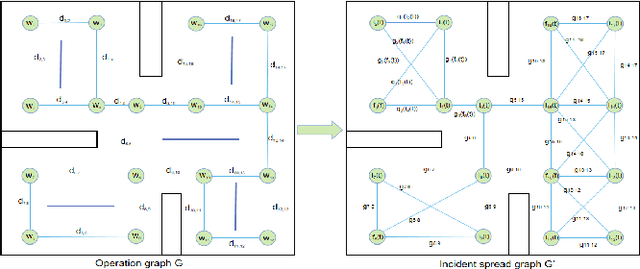
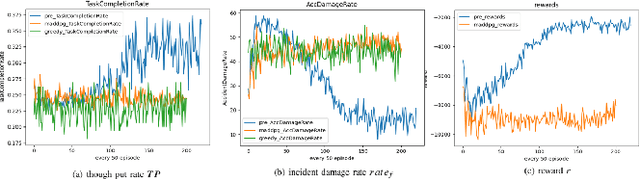
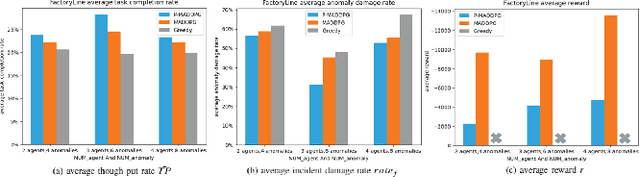

In recent years, human casualties and damage to resources caused by emergent incidents have become a serious problem worldwide. In this paper, we model the emergency decision-making problem and use Multi-agent System (MAS) to solve the problem that the decision speed cannot keep up with the spreading speed. MAS can play an important role in the automated execution of these tasks to reduce mission completion time. In this paper, we propose a P-MADDPG algorithm to solve the emergency decision-making problem of emergent incidents, which predicts the nodes where an incident may occur in the next time by GRU model and makes decisions before the incident occurs, thus solving the problem that the decision speed cannot keep up with the spreading speed. A simulation environment was established for realistic scenarios, and three scenarios were selected to test the performance of P-MADDPG in emergency decision-making problems for emergent incidents: unmanned storage, factory assembly line, and civil airport baggage transportation. Simulation results using the P-MADDPG algorithm are compared with the greedy algorithm and the MADDPG algorithm, and the final experimental results show that the P-MADDPG algorithm converges faster and better than the other algorithms in scenarios of different sizes. This shows that the P-MADDP algorithm is effective for emergency decision-making in emergent incident.
Multimodal Proximity and Visuotactile Sensing With a Selectively Transmissive Soft Membrane
Apr 18, 2022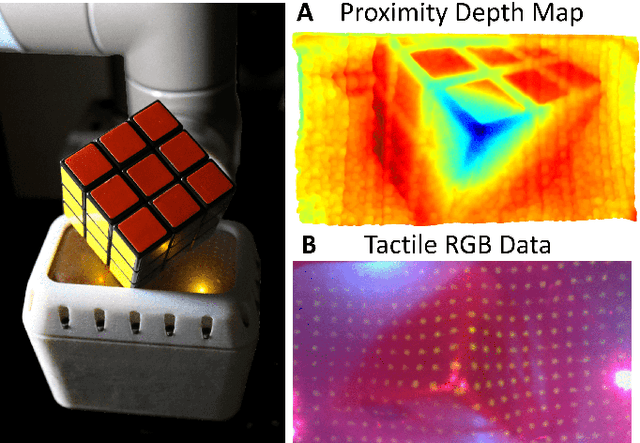
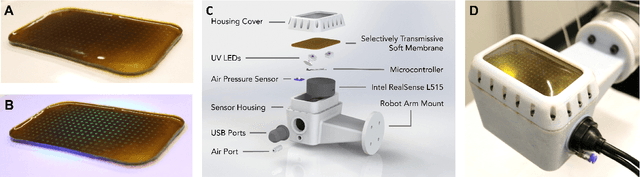
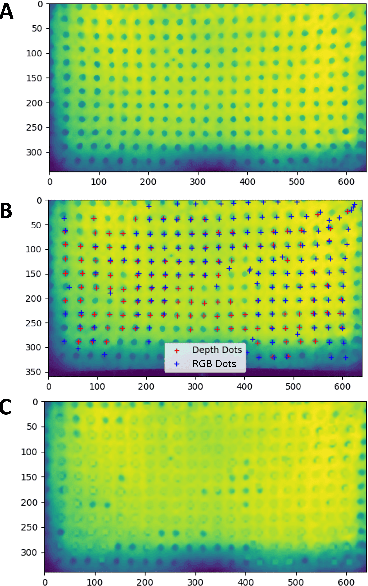
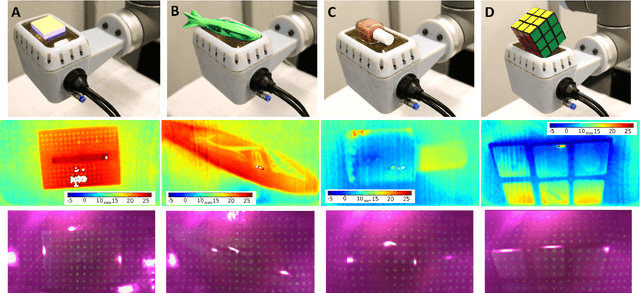
The most common sensing modalities found in a robot perception system are vision and touch, which together can provide global and highly localized data for manipulation. However, these sensing modalities often fail to adequately capture the behavior of target objects during the critical moments as they transition out of static, controlled contact with an end-effector to dynamic and uncontrolled motion. In this work, we present a novel multimodal visuotactile sensor that provides simultaneous visuotactile and proximity depth data. The sensor integrates an RGB camera and air pressure sensor to sense touch with an infrared time-of-flight (ToF) camera to sense proximity by leveraging a selectively transmissive soft membrane to enable the dual sensing modalities. We present the mechanical design, fabrication techniques, algorithm implementations, and evaluation of the sensor's tactile and proximity modalities. The sensor is demonstrated in three open-loop robotic tasks: approaching and contacting an object, catching, and throwing. The fusion of tactile and proximity data could be used to capture key information about a target object's transition behavior for sensor-based control in dynamic manipulation.
Learning Wave Propagation with Attention-Based Convolutional Recurrent Autoencoder Net
Jan 17, 2022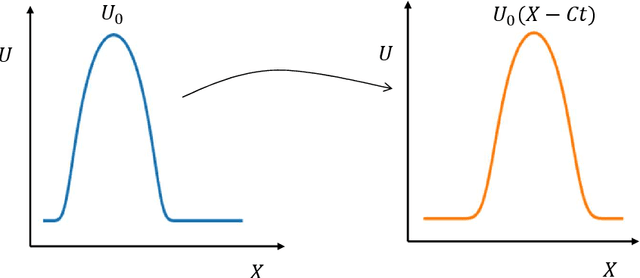

In this paper, we present an end-to-end attention-based convolutional recurrent autoencoder (AB-CRAN) network for data-driven modeling of wave propagation phenomena. The proposed network architecture relies on the attention-based recurrent neural network (RNN) with long short-term memory (LSTM) cells. To construct the low-dimensional learning model, we employ a denoising-based convolutional autoencoder from the full-order snapshots given by time-dependent hyperbolic partial differential equations for wave propagation. To begin, we attempt to address the difficulty in evolving the low-dimensional representation in time with a plain RNN-LSTM for wave propagation phenomenon. We build an attention-based sequence-to-sequence RNN-LSTM architecture to predict the solution over a long time horizon. To demonstrate the effectiveness of the proposed learning model, we consider three benchmark problems namely one-dimensional linear convection, nonlinear viscous Burgers, and two-dimensional Saint-Venant shallow water system. Using the time-series datasets from the benchmark problems, our novel AB-CRAN architecture accurately captures the wave amplitude and preserves the wave characteristics of the solution for long time horizons. The attention-based sequence-to-sequence network increases the time-horizon of prediction by five times compared to the plain RNN-LSTM. Denoising autoencoder further reduces the mean squared error of prediction and improves the generalization capability in the parameter space.
MILES: Visual BERT Pre-training with Injected Language Semantics for Video-text Retrieval
Apr 26, 2022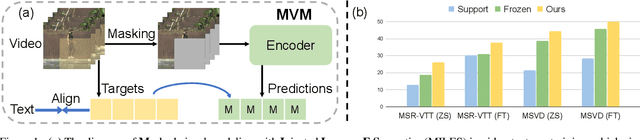
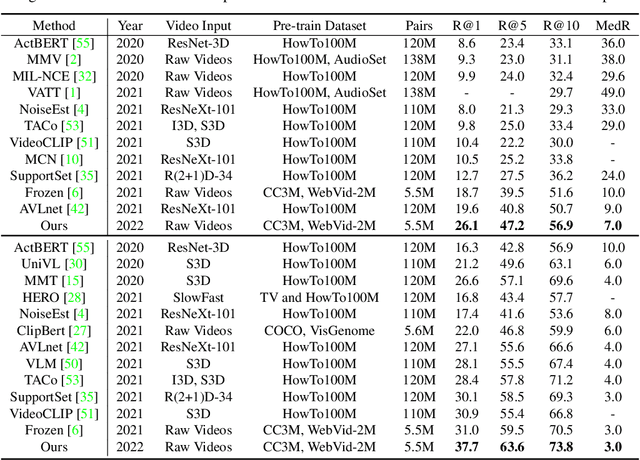
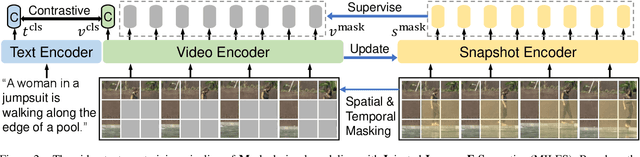
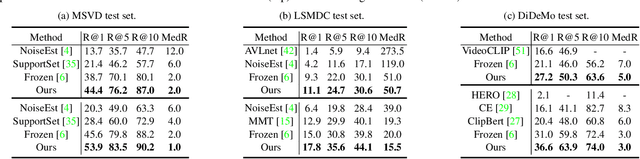
Dominant pre-training work for video-text retrieval mainly adopt the "dual-encoder" architectures to enable efficient retrieval, where two separate encoders are used to contrast global video and text representations, but ignore detailed local semantics. The recent success of image BERT pre-training with masked visual modeling that promotes the learning of local visual context, motivates a possible solution to address the above limitation. In this work, we for the first time investigate masked visual modeling in video-text pre-training with the "dual-encoder" architecture. We perform Masked visual modeling with Injected LanguagE Semantics (MILES) by employing an extra snapshot video encoder as an evolving "tokenizer" to produce reconstruction targets for masked video patch prediction. Given the corrupted video, the video encoder is trained to recover text-aligned features of the masked patches via reasoning with the visible regions along the spatial and temporal dimensions, which enhances the discriminativeness of local visual features and the fine-grained cross-modality alignment. Our method outperforms state-of-the-art methods for text-to-video retrieval on four datasets with both zero-shot and fine-tune evaluation protocols. Our approach also surpasses the baseline models significantly on zero-shot action recognition, which can be cast as video-to-text retrieval.