 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluation of Multi-Scale Multiple Instance Learning to Improve Thyroid Cancer Classification
Apr 22, 2022
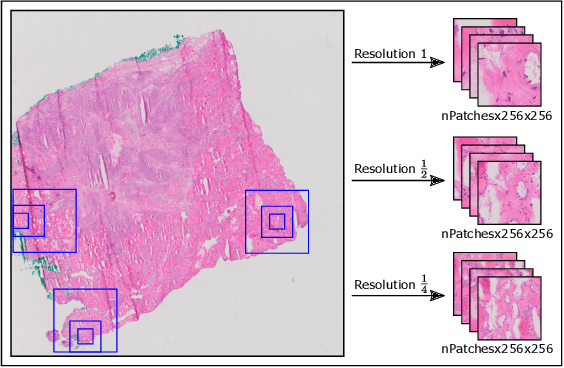
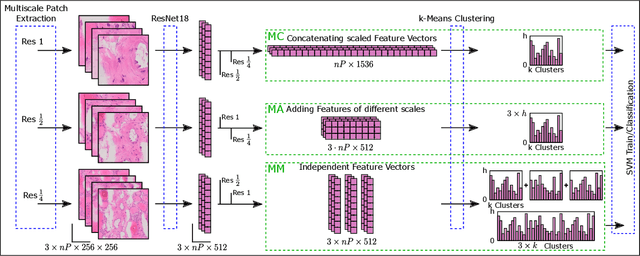
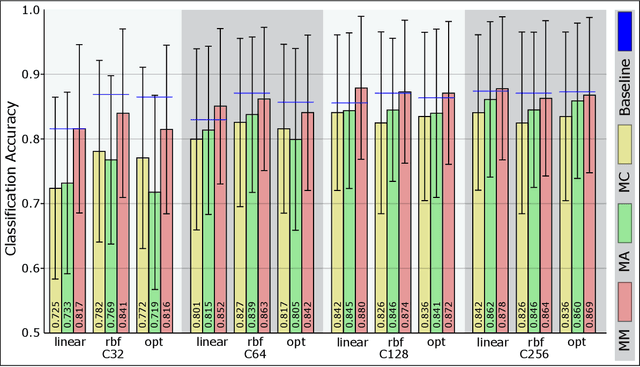
Thyroid cancer is currently the fifth most common malignancy diagnosed in women. Since differentiation of cancer sub-types is important for treatment and current, manual methods are time consuming and subjective, automatic computer-aided differentiation of cancer types is crucial. Manual differentiation of thyroid cancer is based on tissue sections, analysed by pathologists using histological features. Due to the enormous size of gigapixel whole slide images, holistic classification using deep learning methods is not feasible. Patch based multiple instance learning approaches, combined with aggregations such as bag-of-words, is a common approach. This work's contribution is to extend a patch based state-of-the-art method by generating and combining feature vectors of three different patch resolutions and analysing three distinct ways of combining them. The results showed improvements in one of the three multi-scale approaches, while the others led to decreased scores. This provides motivation for analysis and discussion of the individual approaches.
CV4Code: Sourcecode Understanding via Visual Code Representations
May 11, 2022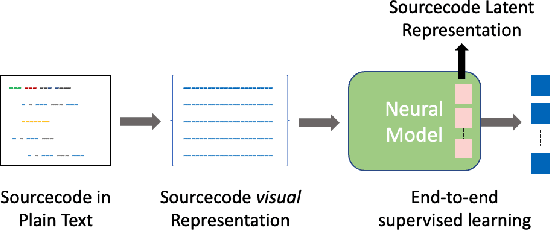
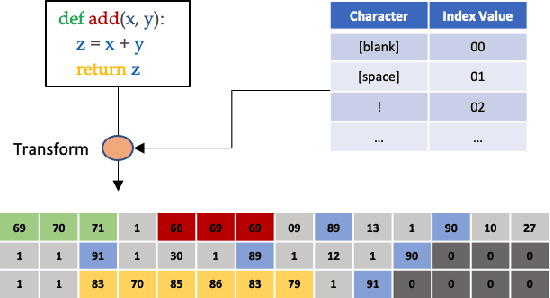

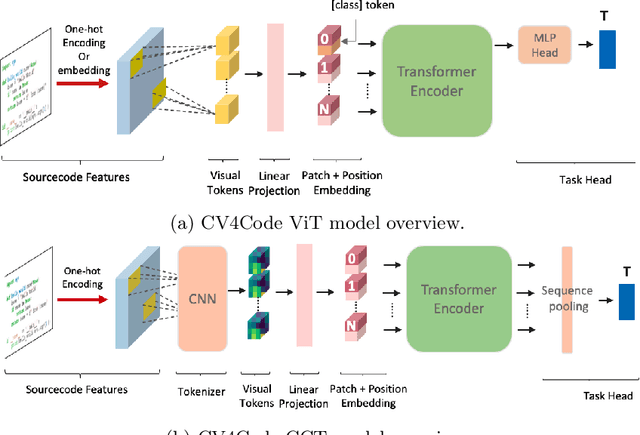
We present CV4Code, a compact and effective computer vision method for sourcecode understanding. Our method leverages the contextual and the structural information available from the code snippet by treating each snippet as a two-dimensional image, which naturally encodes the context and retains the underlying structural information through an explicit spatial representation. To codify snippets as images, we propose an ASCII codepoint-based image representation that facilitates fast generation of sourcecode images and eliminates redundancy in the encoding that would arise from an RGB pixel representation. Furthermore, as sourcecode is treated as images, neither lexical analysis (tokenisation) nor syntax tree parsing is required, which makes the proposed method agnostic to any particular programming language and lightweight from the application pipeline point of view. CV4Code can even featurise syntactically incorrect code which is not possible from methods that depend on the Abstract Syntax Tree (AST). We demonstrate the effectiveness of CV4Code by learning Convolutional and Transformer networks to predict the functional task, i.e. the problem it solves, of the source code directly from its two-dimensional representation, and using an embedding from its latent space to derive a similarity score of two code snippets in a retrieval setup. Experimental results show that our approach achieves state-of-the-art performance in comparison to other methods with the same task and data configurations. For the first time we show the benefits of treating sourcecode understanding as a form of image processing task.
Detect Professional Malicious User with Metric Learning in Recommender Systems
May 19, 2022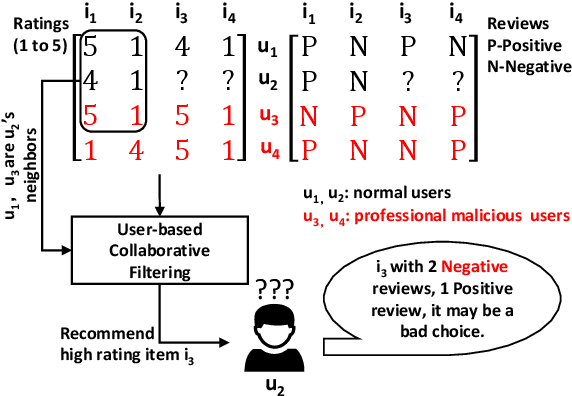

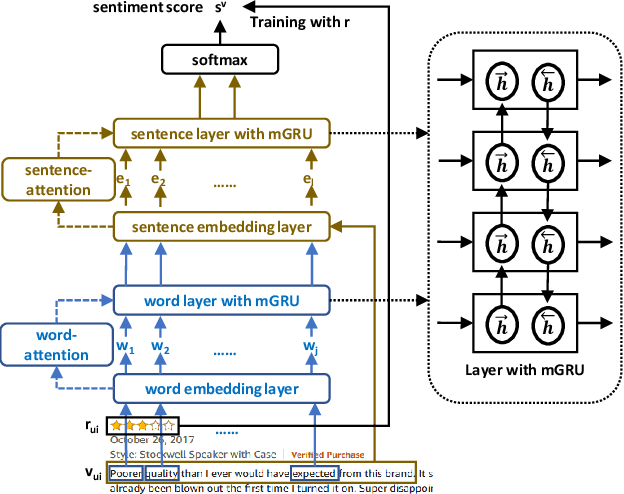
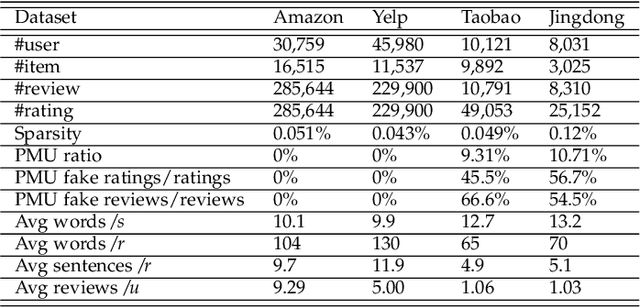
In e-commerce, online retailers are usually suffering from professional malicious users (PMUs), who utilize negative reviews and low ratings to their consumed products on purpose to threaten the retailers for illegal profits. Specifically, there are three challenges for PMU detection: 1) professional malicious users do not conduct any abnormal or illegal interactions (they never concurrently leave too many negative reviews and low ratings at the same time), and they conduct masking strategies to disguise themselves. Therefore, conventional outlier detection methods are confused by their masking strategies. 2) the PMU detection model should take both ratings and reviews into consideration, which makes PMU detection a multi-modal problem. 3) there are no datasets with labels for professional malicious users in public, which makes PMU detection an unsupervised learning problem. To this end, we propose an unsupervised multi-modal learning model: MMD, which employs Metric learning for professional Malicious users Detection with both ratings and reviews. MMD first utilizes a modified RNN to project the informational review into a sentiment score, which jointly considers the ratings and reviews. Then professional malicious user profiling (MUP) is proposed to catch the sentiment gap between sentiment scores and ratings. MUP filters the users and builds a candidate PMU set. We apply a metric learning-based clustering to learn a proper metric matrix for PMU detection. Finally, we can utilize this metric and labeled users to detect PMUs. Specifically, we apply the attention mechanism in metric learning to improve the model's performance. The extensive experiments in four datasets demonstrate that our proposed method can solve this unsupervised detection problem. Moreover, the performance of the state-of-the-art recommender models is enhanced by taking MMD as a preprocessing stage.
Particle-based Fast Jet Simulation at the LHC with Variational Autoencoders
Mar 01, 2022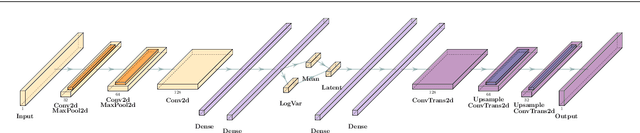
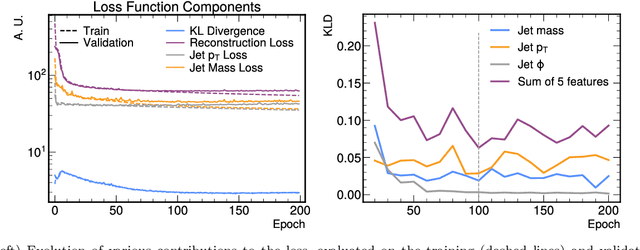
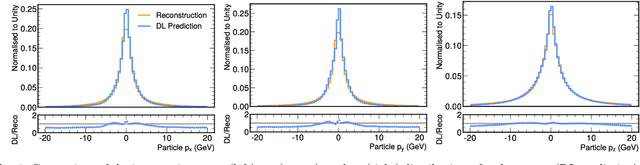
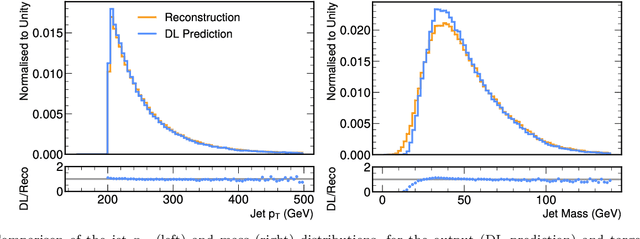
We study how to use Deep Variational Autoencoders for a fast simulation of jets of particles at the LHC. We represent jets as a list of constituents, characterized by their momenta. Starting from a simulation of the jet before detector effects, we train a Deep Variational Autoencoder to return the corresponding list of constituents after detection. Doing so, we bypass both the time-consuming detector simulation and the collision reconstruction steps of a traditional processing chain, speeding up significantly the events generation workflow. Through model optimization and hyperparameter tuning, we achieve state-of-the-art precision on the jet four-momentum, while providing an accurate description of the constituents momenta, and an inference time comparable to that of a rule-based fast simulation.
Distributed Learning and its Application for Time-Series Prediction
Jun 06, 2021
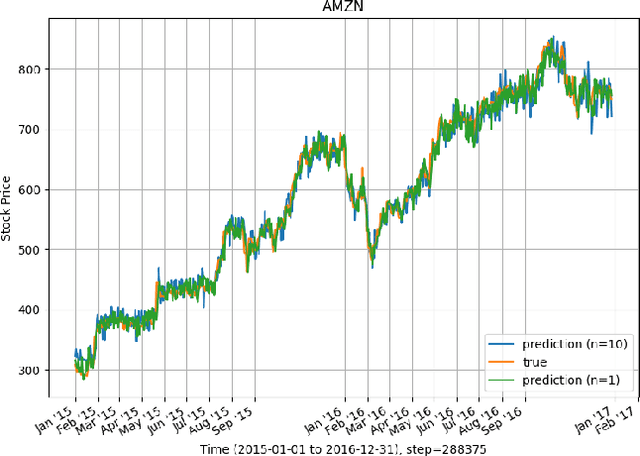


Extreme events are occurrences whose magnitude and potential cause extensive damage on people, infrastructure, and the environment. Motivated by the extreme nature of the current global health landscape, which is plagued by the coronavirus pandemic, we seek to better understand and model extreme events. Modeling extreme events is common in practice and plays an important role in time-series prediction applications. Our goal is to (i) compare and investigate the effect of some common extreme events modeling methods to explore which method can be practical in reality and (ii) accelerate the deep learning training process, which commonly uses deep recurrent neural network (RNN), by implementing the asynchronous local Stochastic Gradient Descent (SGD) framework among multiple compute nodes. In order to verify our distributed extreme events modeling, we evaluate our proposed framework on a stock data set S\&P500, with a standard recurrent neural network. Our intuition is to explore the (best) extreme events modeling method which could work well under the distributed deep learning setting. Moreover, by using asynchronous distributed learning, we aim to significantly reduce the communication cost among the compute nodes and central server, which is the main bottleneck of almost all distributed learning frameworks. We implement our proposed work and evaluate its performance on representative data sets, such as S\&P500 stock in $5$-year period. The experimental results validate the correctness of the design principle and show a significant training duration reduction upto $8$x, compared to the baseline single compute node. Our results also show that our proposed work can achieve the same level of test accuracy, compared to the baseline setting.
Improving Irregularly Sampled Time Series Learning with Dense Descriptors of Time
Mar 20, 2020

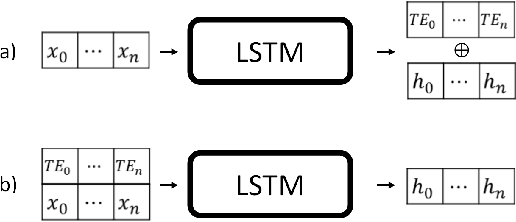
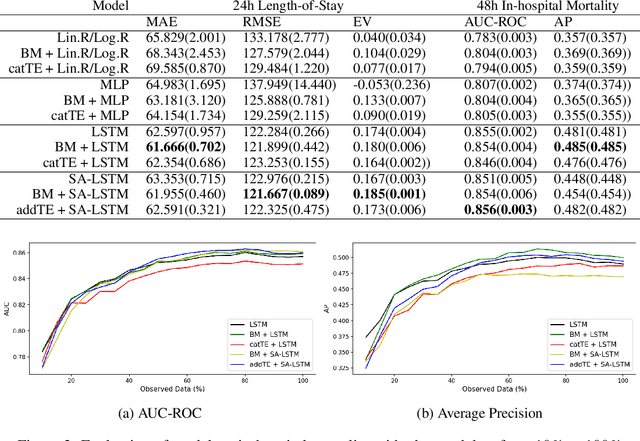
Supervised learning with irregularly sampled time series have been a challenge to Machine Learning methods due to the obstacle of dealing with irregular time intervals. Some papers introduced recently recurrent neural network models that deals with irregularity, but most of them rely on complex mechanisms to achieve a better performance. This work propose a novel method to represent timestamps (hours or dates) as dense vectors using sinusoidal functions, called Time Embeddings. As a data input method it and can be applied to most machine learning models. The method was evaluated with two predictive tasks from MIMIC III, a dataset of irregularly sampled time series of electronic health records. Our tests showed an improvement to LSTM-based and classical machine learning models, specially with very irregular data.
Dancing along Battery: Enabling Transformer with Run-time Reconfigurability on Mobile Devices
Feb 12, 2021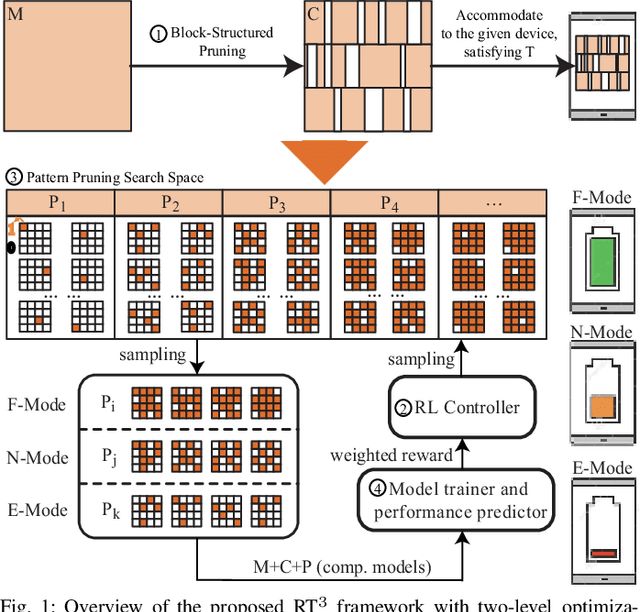
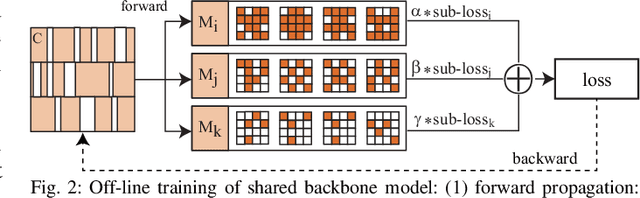
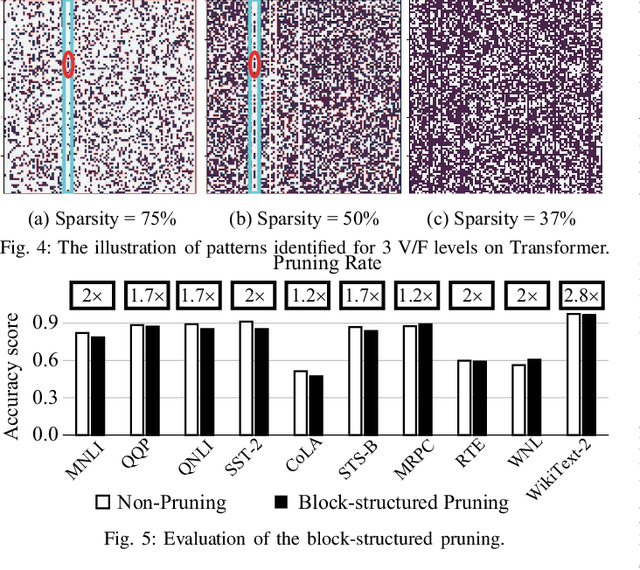

A pruning-based AutoML framework for run-time reconfigurability, namely RT3, is proposed in this work. This enables Transformer-based large Natural Language Processing (NLP) models to be efficiently executed on resource-constrained mobile devices and reconfigured (i.e., switching models for dynamic hardware conditions) at run-time. Such reconfigurability is the key to save energy for battery-powered mobile devices, which widely use dynamic voltage and frequency scaling (DVFS) technique for hardware reconfiguration to prolong battery life. In this work, we creatively explore a hybrid block-structured pruning (BP) and pattern pruning (PP) for Transformer-based models and first attempt to combine hardware and software reconfiguration to maximally save energy for battery-powered mobile devices. Specifically, RT3 integrates two-level optimizations: First, it utilizes an efficient BP as the first-step compression for resource-constrained mobile devices; then, RT3 heuristically generates a shrunken search space based on the first level optimization and searches multiple pattern sets with diverse sparsity for PP via reinforcement learning to support lightweight software reconfiguration, which corresponds to available frequency levels of DVFS (i.e., hardware reconfiguration). At run-time, RT3 can switch the lightweight pattern sets within 45ms to guarantee the required real-time constraint at different frequency levels. Results further show that RT3 can prolong battery life over 4x improvement with less than 1% accuracy loss for Transformer and 1.5% score decrease for DistilBERT.
Possibility Before Utility: Learning And Using Hierarchical Affordances
Mar 23, 2022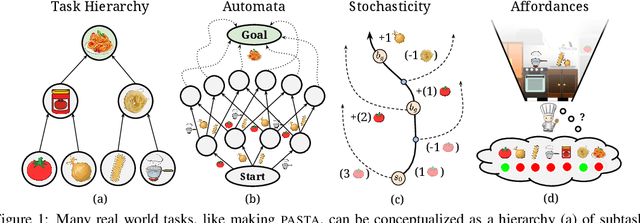
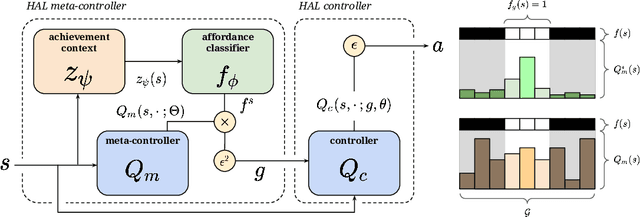
Reinforcement learning algorithms struggle on tasks with complex hierarchical dependency structures. Humans and other intelligent agents do not waste time assessing the utility of every high-level action in existence, but instead only consider ones they deem possible in the first place. By focusing only on what is feasible, or "afforded", at the present moment, an agent can spend more time both evaluating the utility of and acting on what matters. To this end, we present Hierarchical Affordance Learning (HAL), a method that learns a model of hierarchical affordances in order to prune impossible subtasks for more effective learning. Existing works in hierarchical reinforcement learning provide agents with structural representations of subtasks but are not affordance-aware, and by grounding our definition of hierarchical affordances in the present state, our approach is more flexible than the multitude of approaches that ground their subtask dependencies in a symbolic history. While these logic-based methods often require complete knowledge of the subtask hierarchy, our approach is able to utilize incomplete and varying symbolic specifications. Furthermore, we demonstrate that relative to non-affordance-aware methods, HAL agents are better able to efficiently learn complex tasks, navigate environment stochasticity, and acquire diverse skills in the absence of extrinsic supervision -- all of which are hallmarks of human learning.
Research on Parallel SVM Algorithm Based on Cascade SVM
Mar 11, 2022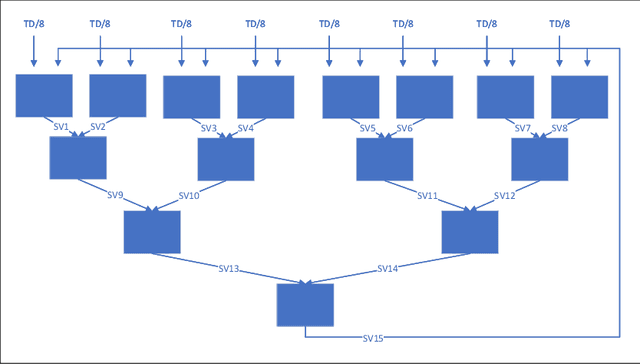

Cascade SVM (CSVM) can group datasets and train subsets in parallel, which greatly reduces the training time and memory consumption. However, the model accuracy obtained by using this method has some errors compared with direct training. In order to reduce the error, we analyze the causes of error in grouping training, and summarize the grouping without error under ideal conditions. A Balanced Cascade SVM (BCSVM) algorithm is proposed, which balances the sample proportion in the subset after grouping to ensure that the sample proportion in the subset is the same as the original dataset. At the same time, it proves that the accuracy of the model obtained by BCSVM algorithm is higher than that of CSVM. Finally, two common datasets are used for experimental verification, and the results show that the accuracy error obtained by using BCSVM algorithm is reduced from 1% of CSVM to 0.1%, which is reduced by an order of magnitude.
POMDPs in Continuous Time and Discrete Spaces
Oct 26, 2020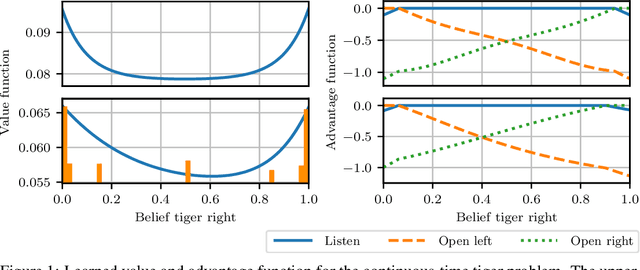
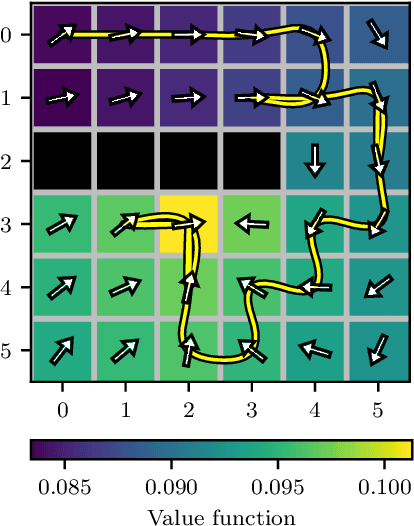
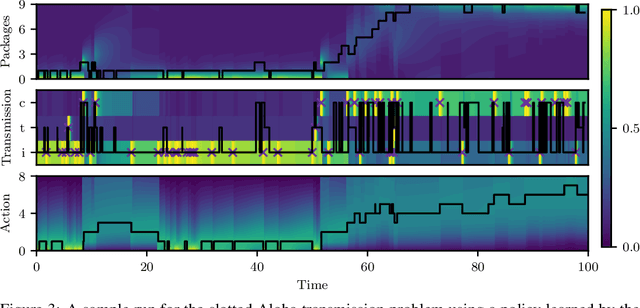
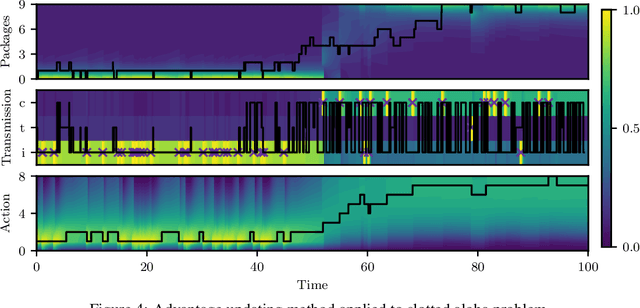
Many processes, such as discrete event systems in engineering or population dynamics in biology, evolve in discrete space and continuous time. We consider the problem of optimal decision making in such discrete state and action space systems under partial observability. This places our work at the intersection of optimal filtering and optimal control. At the current state of research, a mathematical description for simultaneous decision making and filtering in continuous time with finite state and action spaces is still missing. In this paper, we give a mathematical description of a continuous-time partial observable Markov decision process (POMDP). By leveraging optimal filtering theory we derive a Hamilton-Jacobi-Bellman (HJB) type equation that characterizes the optimal solution. Using techniques from deep learning we approximately solve the resulting partial integro-differential equation. We present (i) an approach solving the decision problem offline by learning an approximation of the value function and (ii) an online algorithm which provides a solution in belief space using deep reinforcement learning. We show the applicability on a set of toy examples which pave the way for future methods providing solutions for high dimensional problems.