 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-Supervised Learning of Object Parts for Semantic Segmentation
Apr 27, 2022
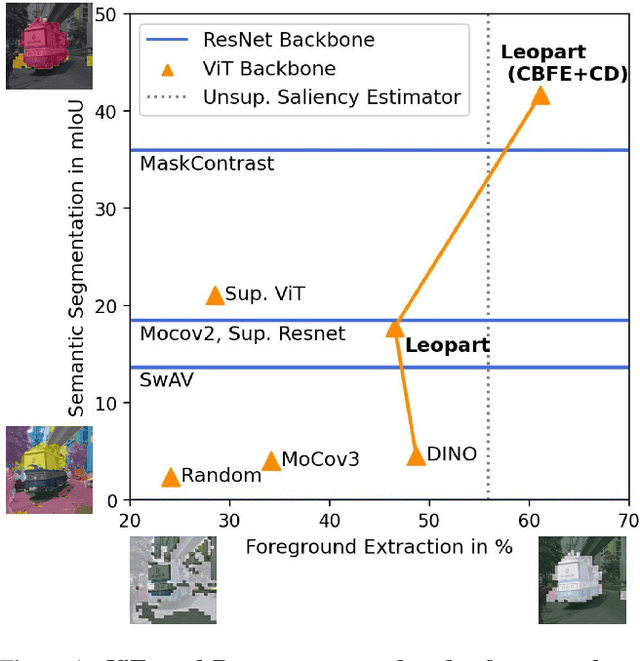
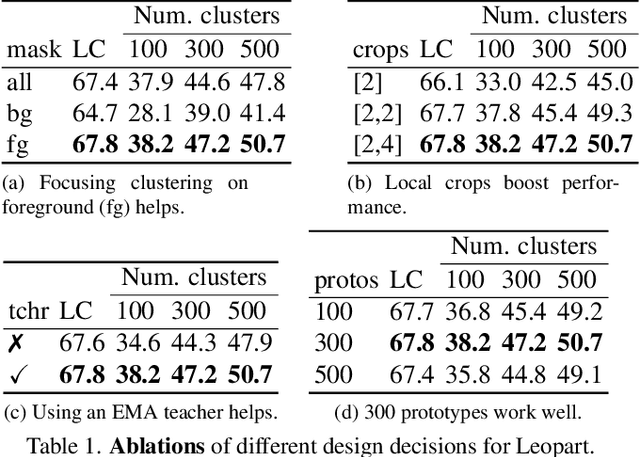
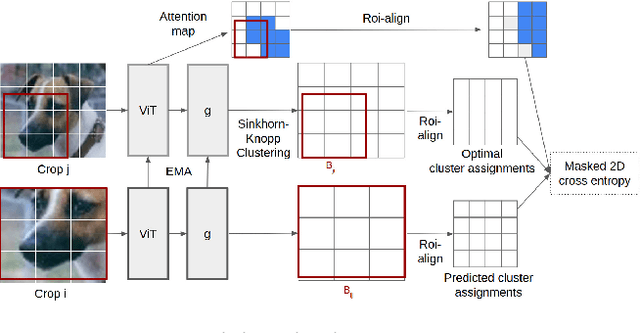
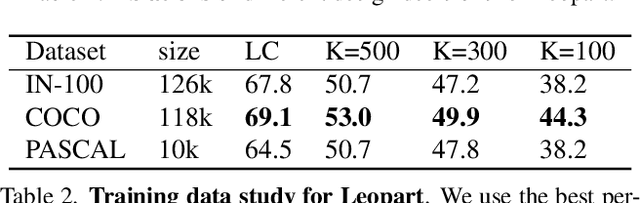
Progress in self-supervised learning has brought strong general image representation learning methods. Yet so far, it has mostly focused on image-level learning. In turn, tasks such as unsupervised image segmentation have not benefited from this trend as they require spatially-diverse representations. However, learning dense representations is challenging, as in the unsupervised context it is not clear how to guide the model to learn representations that correspond to various potential object categories. In this paper, we argue that self-supervised learning of object parts is a solution to this issue. Object parts are generalizable: they are a priori independent of an object definition, but can be grouped to form objects a posteriori. To this end, we leverage the recently proposed Vision Transformer's capability of attending to objects and combine it with a spatially dense clustering task for fine-tuning the spatial tokens. Our method surpasses the state-of-the-art on three semantic segmentation benchmarks by 17%-3%, showing that our representations are versatile under various object definitions. Finally, we extend this to fully unsupervised segmentation - which refrains completely from using label information even at test-time - and demonstrate that a simple method for automatically merging discovered object parts based on community detection yields substantial gains.
Nonsmooth convex optimization to estimate the Covid-19 reproduction number space-time evolution with robustness against low quality data
Sep 20, 2021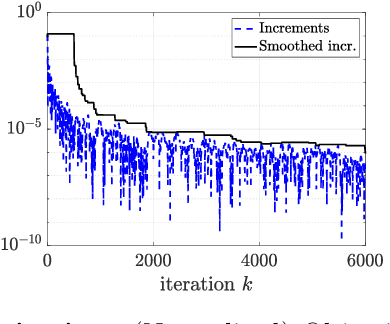
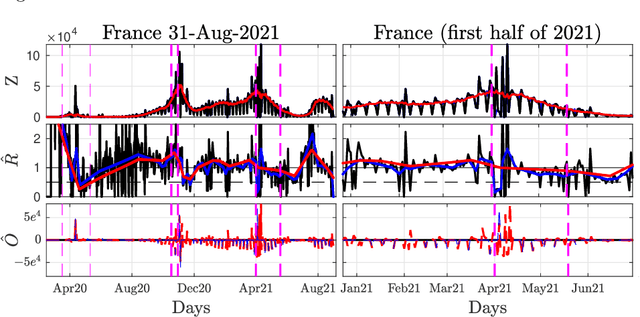
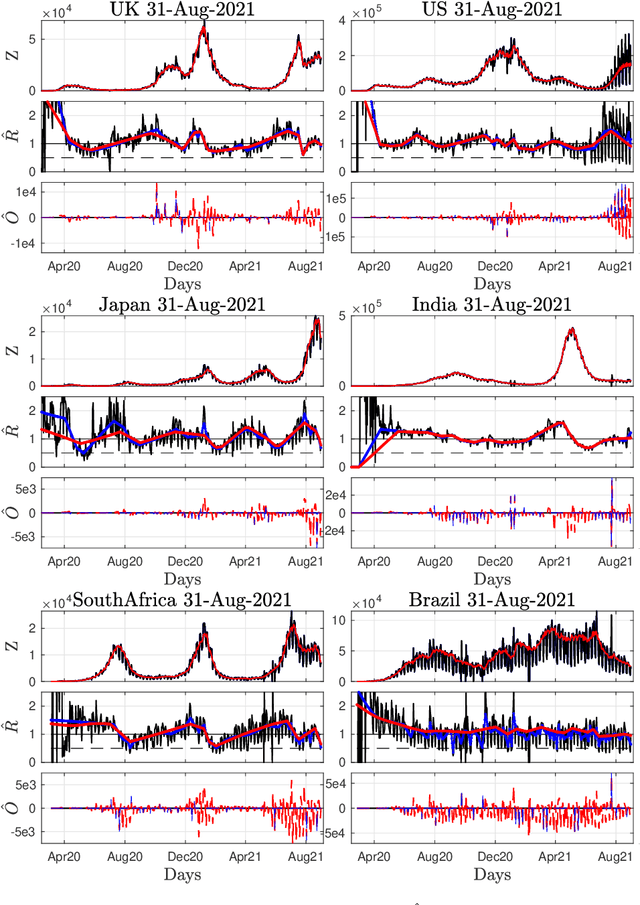
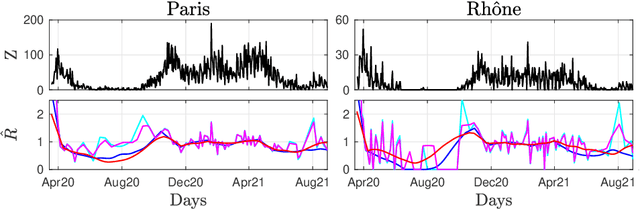
Daily pandemic surveillance, often achieved through the estimation of the reproduction number, constitutes a critical challenge for national health authorities to design countermeasures. In an earlier work, we proposed to formulate the estimation of the reproduction number as an optimization problem, combining data-model fidelity and space-time regularity constraints, solved by nonsmooth convex proximal minimizations. Though promising, that first formulation significantly lacks robustness against the Covid-19 data low quality (irrelevant or missing counts, pseudo-seasonalities,.. .) stemming from the emergency and crisis context, which significantly impairs accurate pandemic evolution assessments. The present work aims to overcome these limitations by carefully crafting a functional permitting to estimate jointly, in a single step, the reproduction number and outliers defined to model low quality data. This functional also enforces epidemiology-driven regularity properties for the reproduction number estimates, while preserving convexity, thus permitting the design of efficient minimization algorithms, based on proximity operators that are derived analytically. The explicit convergence of the proposed algorithm is proven theoretically. Its relevance is quantified on real Covid-19 data, consisting of daily new infection counts for 200+ countries and for the 96 metropolitan France counties, publicly available at Johns Hopkins University and Sant{\'e}-Publique-France. The procedure permits automated daily updates of these estimates, reported via animated and interactive maps. Open-source estimation procedures will be made publicly available.
Real-Time Optimization of the Current Steering for Visual Prosthesis
Dec 25, 2020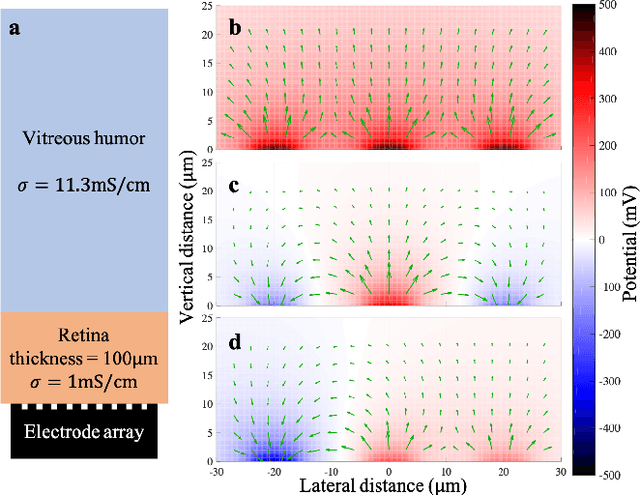
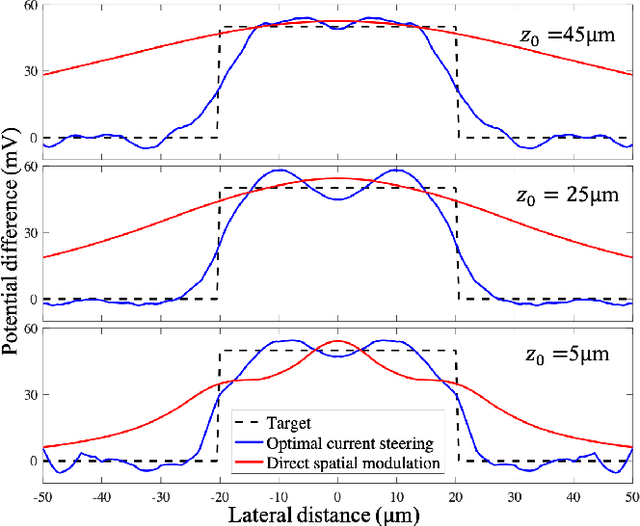
Current steering on a multi-electrode array is commonly used to shape the electric field in the neural tissue in order to improve selectivity and efficacy of stimulation. Previously, simulations of the electric field in tissue required separate computation for each set of the stimulation parameters. Not only is this approach to modeling time-consuming and very difficult with a large number of electrodes, it is incompatible with real-time optimization of the current steering for practical applications. We present a framework for efficient computation of the electric field in the neural tissue based on superposition of the fields from a pre-calculated basis. Such linear algebraic framework enables optimization of the current steering for any targeted electric field in real time. For applications to retinal prosthetics, we demonstrate how the stimulation depth can be optimized for each patient based on the retinal thickness and separation from the array, while maximizing the lateral confinement of the electric field essential for spatial resolution.
Dynamic Deep Convolutional Candlestick Learner
Jan 21, 2022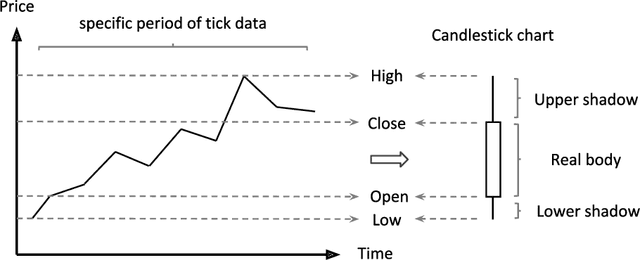
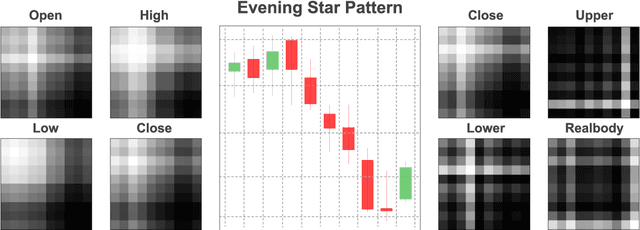
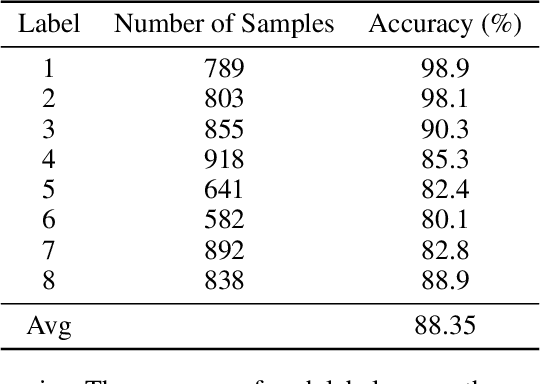
Candlestick pattern is one of the most fundamental and valuable graphical tools in financial trading that supports traders observing the current market conditions to make the proper decision. This task has a long history and, most of the time, human experts. Recently, efforts have been made to automatically classify these patterns with the deep learning models. The GAF-CNN model is a well-suited way to imitate how human traders capture the candlestick pattern by integrating spatial features visually. However, with the great potential of the GAF encoding, this classification task can be extended to a more complicated object detection level. This work presents an innovative integration of modern object detection techniques and GAF time-series encoding on candlestick pattern tasks. We make crucial modifications to the representative yet straightforward YOLO version 1 model based on our time-series encoding method and the property of such data type. Powered by the deep neural networks and the unique architectural design, the proposed model performs pretty well in candlestick classification and location recognition. The results show tremendous potential in applying modern object detection techniques on time-series tasks in a real-time manner.
Nth Order Analytical Time Derivatives of Inverse Dynamics in Recursive and Closed Forms
Mar 10, 2021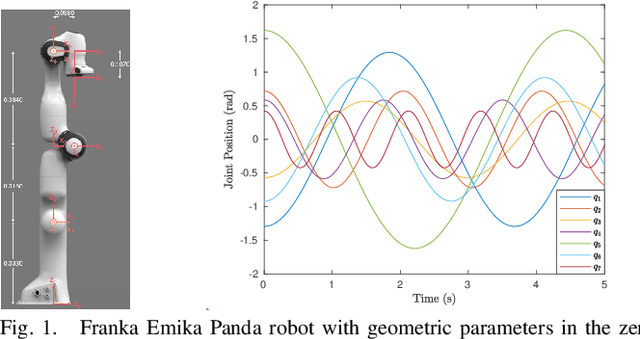
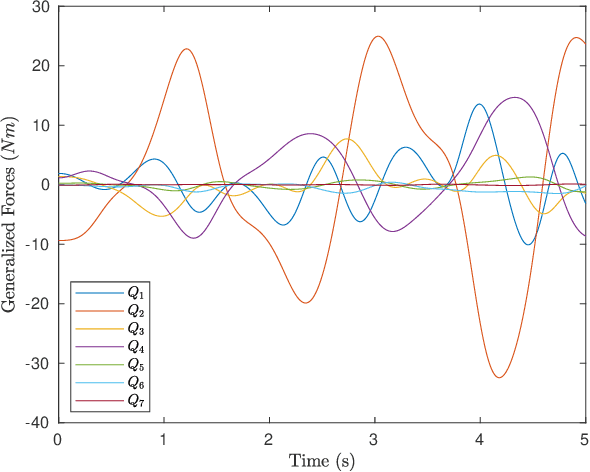
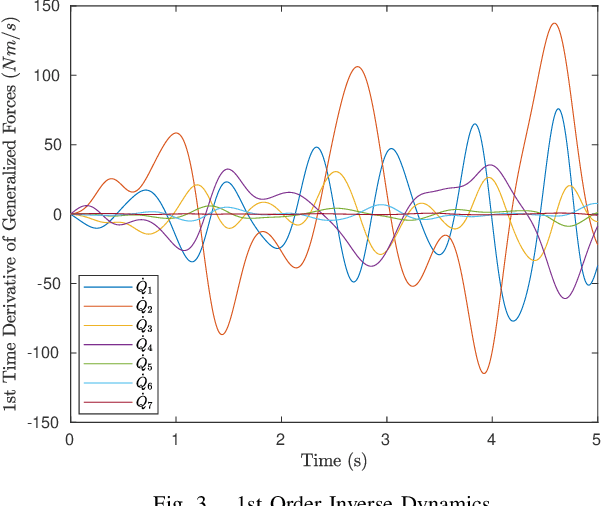
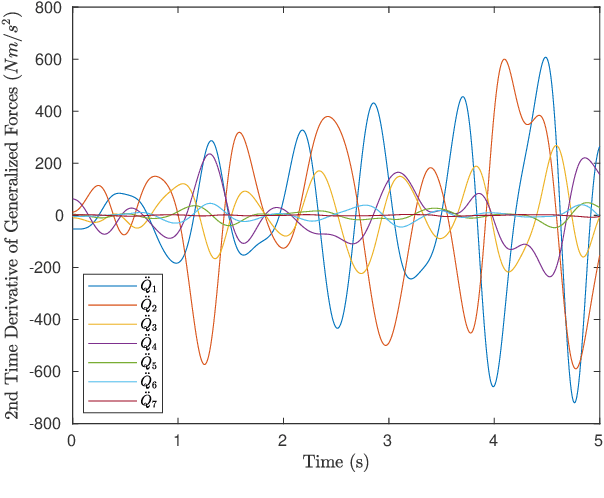
Derivatives of equations of motion describing the rigid body dynamics are becoming increasingly relevant for the robotics community and find many applications in design and control of robotic systems. Controlling robots, and multibody systems comprising elastic components in particular, not only requires smooth trajectories but also the time derivatives of the control forces/torques, hence of the equations of motion (EOM). This paper presents novel nth order time derivatives of the EOM in both closed and recursive forms. While the former provides a direct insight into the structure of these derivatives,the latter leads to their highly efficient implementation for large degree of freedom robotic system.
Revisiting Multi-Scale Feature Fusion for Semantic Segmentation
Mar 23, 2022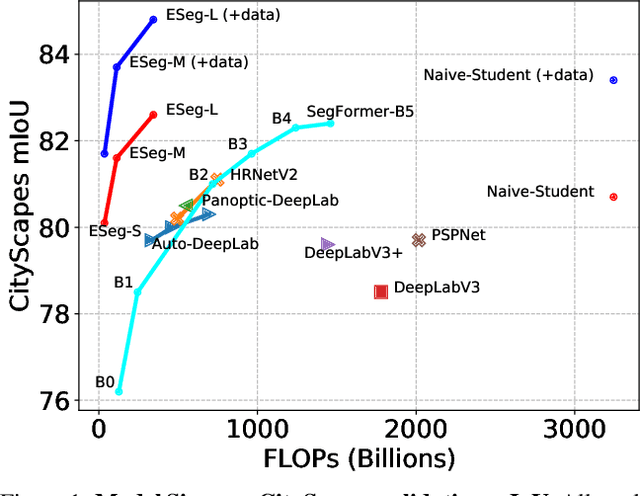

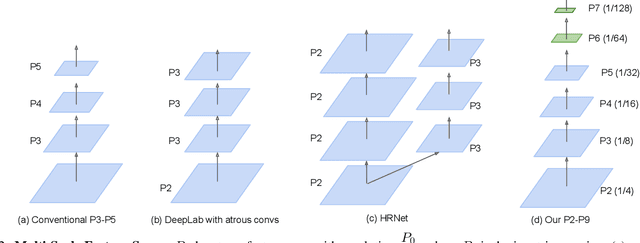
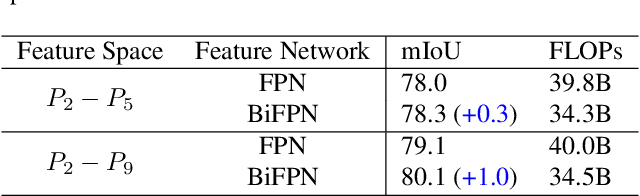
It is commonly believed that high internal resolution combined with expensive operations (e.g. atrous convolutions) are necessary for accurate semantic segmentation, resulting in slow speed and large memory usage. In this paper, we question this belief and demonstrate that neither high internal resolution nor atrous convolutions are necessary. Our intuition is that although segmentation is a dense per-pixel prediction task, the semantics of each pixel often depend on both nearby neighbors and far-away context; therefore, a more powerful multi-scale feature fusion network plays a critical role. Following this intuition, we revisit the conventional multi-scale feature space (typically capped at P5) and extend it to a much richer space, up to P9, where the smallest features are only 1/512 of the input size and thus have very large receptive fields. To process such a rich feature space, we leverage the recent BiFPN to fuse the multi-scale features. Based on these insights, we develop a simplified segmentation model, named ESeg, which has neither high internal resolution nor expensive atrous convolutions. Perhaps surprisingly, our simple method can achieve better accuracy with faster speed than prior art across multiple datasets. In real-time settings, ESeg-Lite-S achieves 76.0% mIoU on CityScapes [12] at 189 FPS, outperforming FasterSeg [9] (73.1% mIoU at 170 FPS). Our ESeg-Lite-L runs at 79 FPS and achieves 80.1% mIoU, largely closing the gap between real-time and high-performance segmentation models.
Online Motion Style Transfer for Interactive Character Control
Mar 30, 2022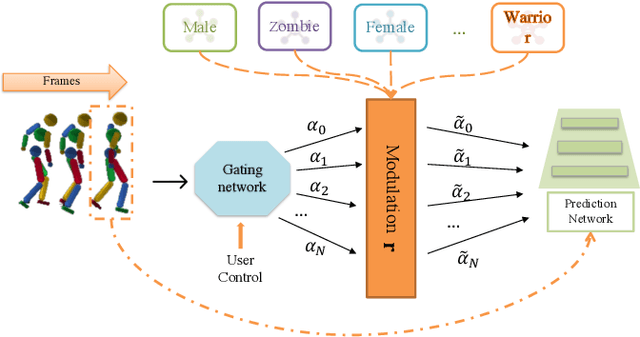
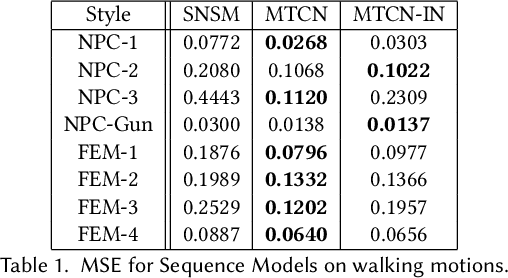
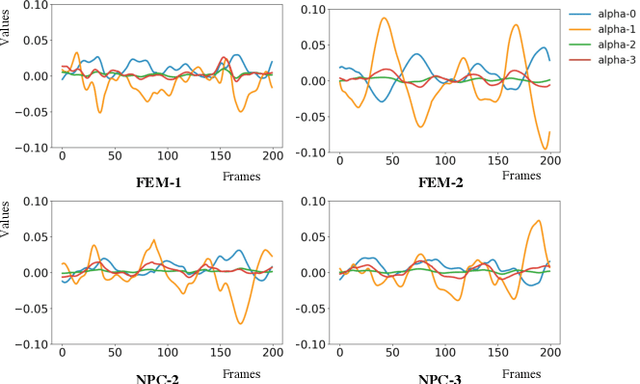
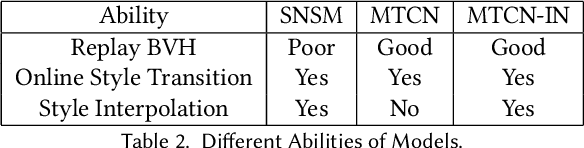
Motion style transfer is highly desired for motion generation systems for gaming. Compared to its offline counterpart, the research on online motion style transfer under interactive control is limited. In this work, we propose an end-to-end neural network that can generate motions with different styles and transfer motion styles in real-time under user control. Our approach eliminates the use of handcrafted phase features, and could be easily trained and directly deployed in game systems. In the experiment part, we evaluate our approach from three aspects that are essential for industrial game design: accuracy, flexibility, and variety, and our model performs a satisfying result.
Online Weak-form Sparse Identification of Partial Differential Equations
Mar 08, 2022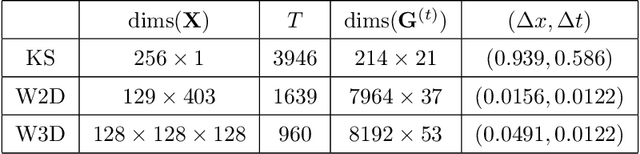
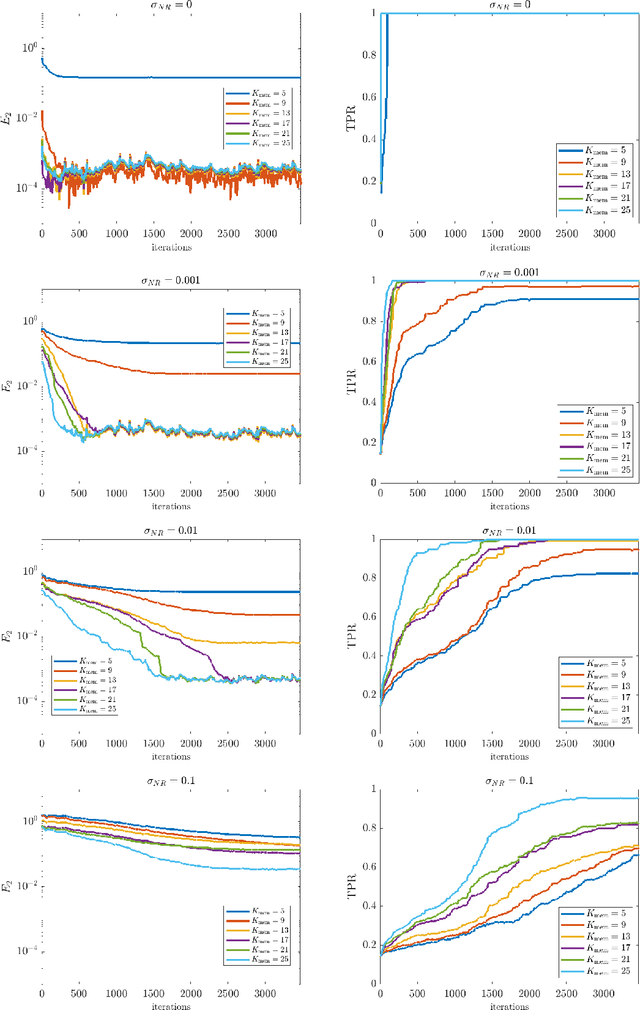
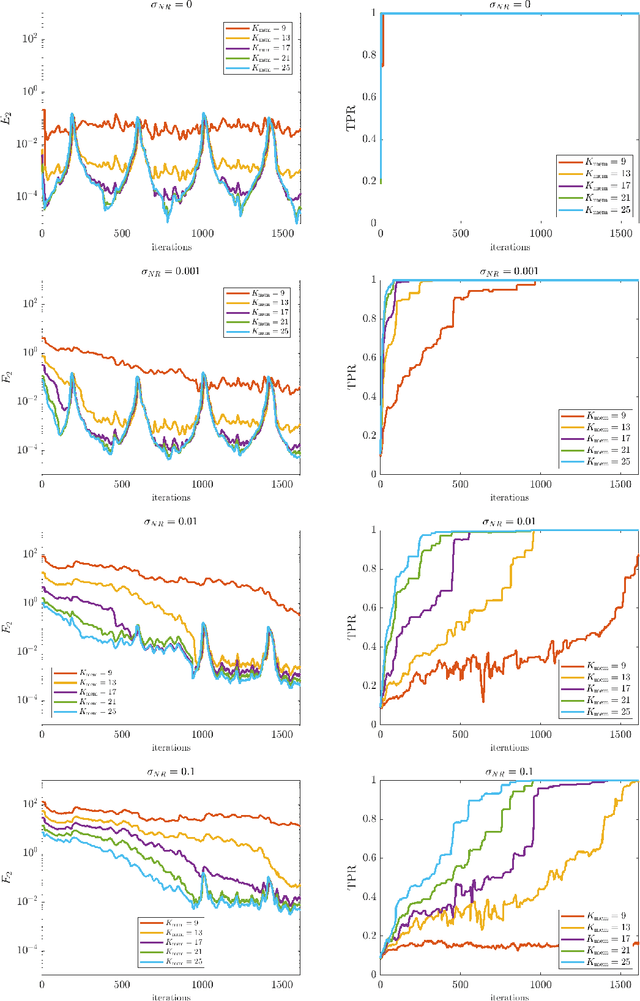
This paper presents an online algorithm for identification of partial differential equations (PDEs) based on the weak-form sparse identification of nonlinear dynamics algorithm (WSINDy). The algorithm is online in a sense that if performs the identification task by processing solution snapshots that arrive sequentially. The core of the method combines a weak-form discretization of candidate PDEs with an online proximal gradient descent approach to the sparse regression problem. In particular, we do not regularize the $\ell_0$-pseudo-norm, instead finding that directly applying its proximal operator (which corresponds to a hard thresholding) leads to efficient online system identification from noisy data. We demonstrate the success of the method on the Kuramoto-Sivashinsky equation, the nonlinear wave equation with time-varying wavespeed, and the linear wave equation, in one, two, and three spatial dimensions, respectively. In particular, our examples show that the method is capable of identifying and tracking systems with coefficients that vary abruptly in time, and offers a streaming alternative to problems in higher dimensions.
Interpretable Latent Variables in Deep State Space Models
Mar 03, 2022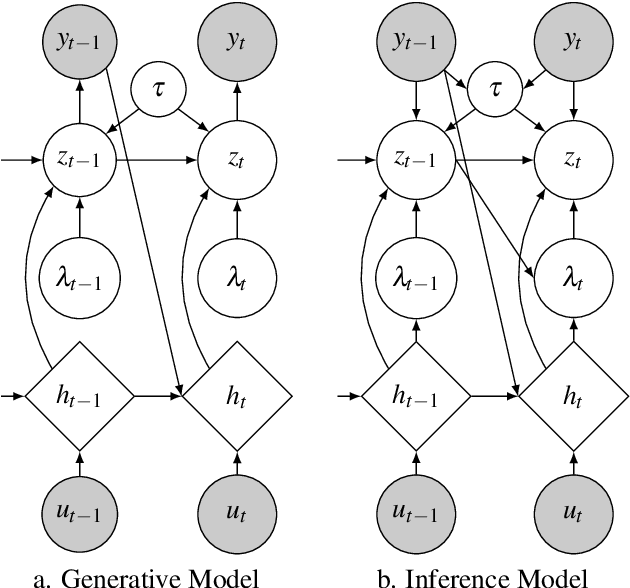
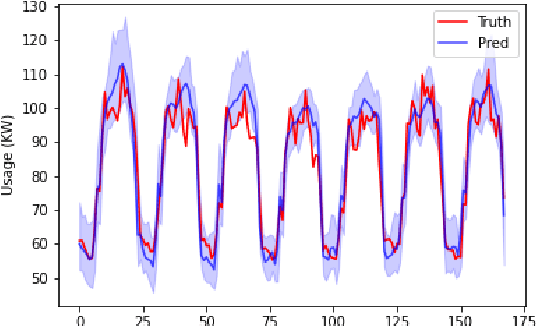
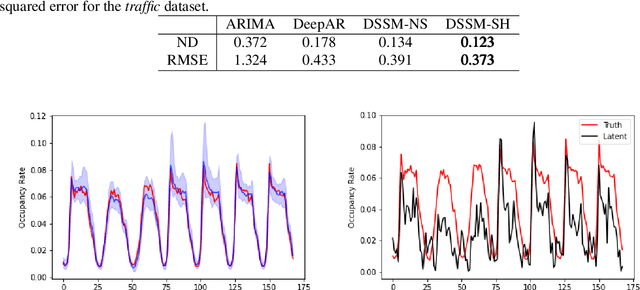
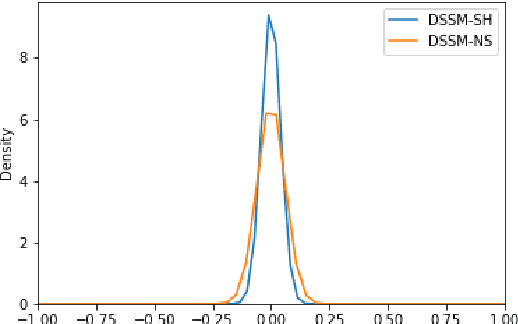
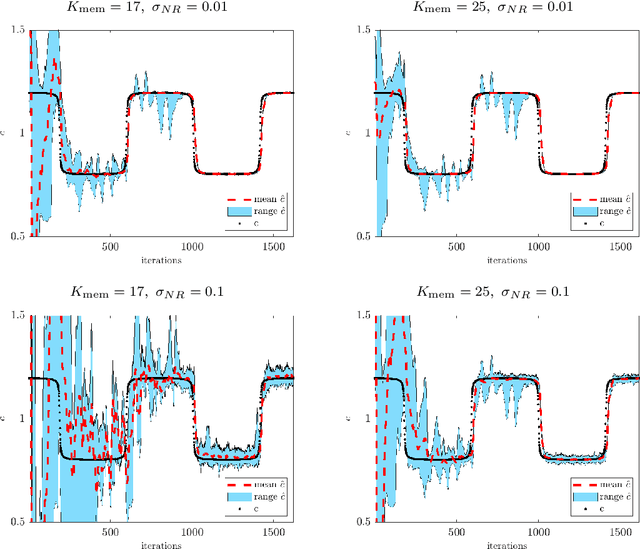
We introduce a new version of deep state-space models (DSSMs) that combines a recurrent neural network with a state-space framework to forecast time series data. The model estimates the observed series as functions of latent variables that evolve non-linearly through time. Due to the complexity and non-linearity inherent in DSSMs, previous works on DSSMs typically produced latent variables that are very difficult to interpret. Our paper focus on producing interpretable latent parameters with two key modifications. First, we simplify the predictive decoder by restricting the response variables to be a linear transformation of the latent variables plus some noise. Second, we utilize shrinkage priors on the latent variables to reduce redundancy and improve robustness. These changes make the latent variables much easier to understand and allow us to interpret the resulting latent variables as random effects in a linear mixed model. We show through two public benchmark datasets the resulting model improves forecasting performances.
Quantum Finite Automata and Quiver Algebras
Mar 15, 2022
We find an application in quantum finite automata for the ideas and results of [JL21] and [JL22]. We reformulate quantum finite automata with multiple-time measurements using the algebraic notion of near-ring. This gives a unified understanding towards quantum computing and deep learning. When the near-ring comes from a quiver, we have a nice moduli space of computing machines with metric that can be optimized by gradient descent.