 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transformer-based Knowledge Distillation for Efficient Semantic Segmentation of Road-driving Scenes
Feb 27, 2022
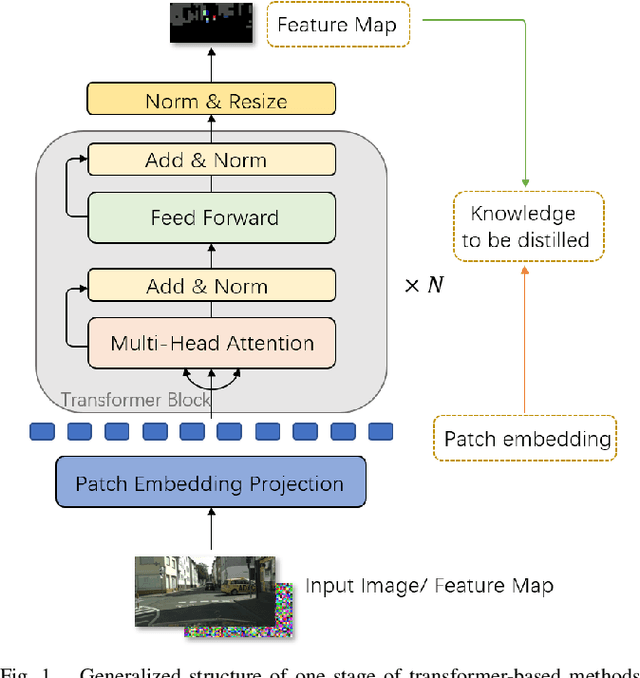
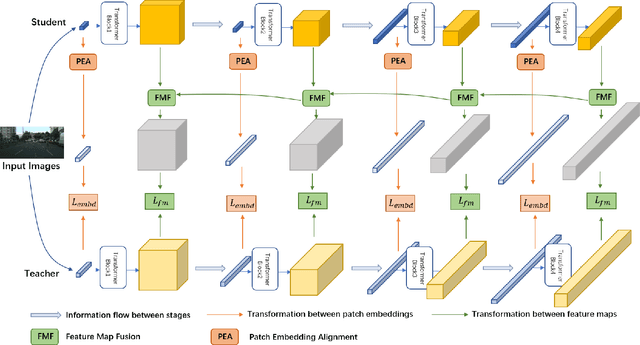
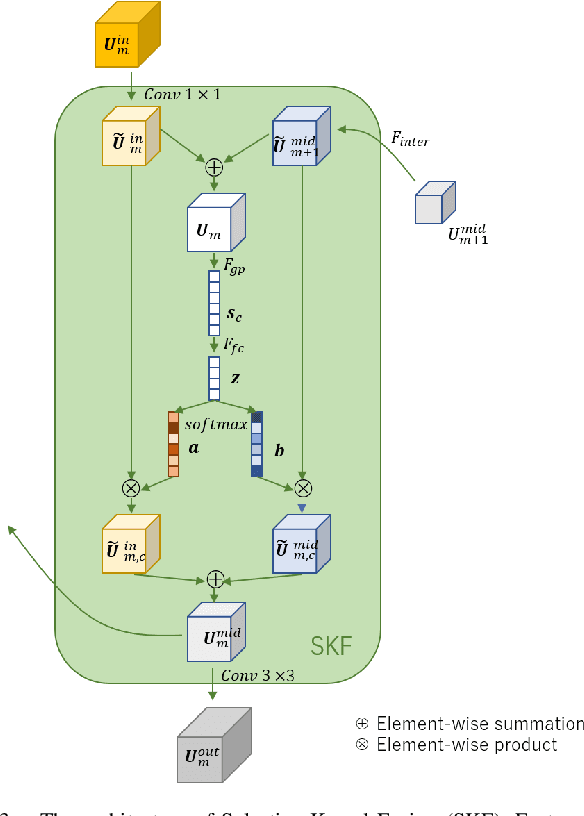
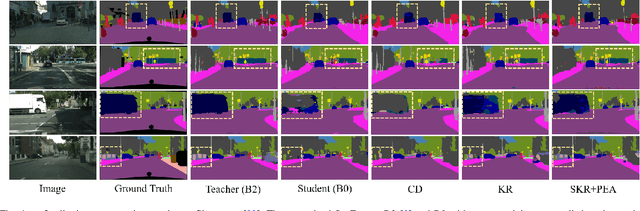
For scene understanding in robotics and automated driving, there is a growing interest in solving semantic segmentation tasks with transformer-based methods. However, effective transformers are always too cumbersome and computationally expensive to solve semantic segmentation in real time, which is desired for robotic systems. Moreover, due to the lack of inductive biases compared to Convolutional Neural Networks (CNNs), pre-training on a large dataset is essential but it takes a long time. Knowledge Distillation (KD) speeds up inference and maintains accuracy while transferring knowledge from a pre-trained cumbersome teacher model to a compact student model. Most traditional KD methods for CNNs focus on response-based knowledge and feature-based knowledge. In contrast, we present a novel KD framework according to the nature of transformers, i.e., training compact transformers by transferring the knowledge from feature maps and patch embeddings of large transformers. To this purpose, two modules are proposed: (1) the Selective Kernel Fusion (SKF) module, which helps to construct an efficient relation-based KD framework, Selective Kernel Review (SKR); (2) the Patch Embedding Alignment (PEA) module, which performs the dimensional transformation of patch embeddings. The combined KD framework is called SKR+PEA. Through comprehensive experiments on Cityscapes and ACDC datasets, it indicates that our proposed approach outperforms recent state-of-the-art KD frameworks and rivals the time-consuming pre-training method. Code will be made publicly available at https://github.com/RuipingL/SKR_PEA.git
SoccerNet-Tracking: Multiple Object Tracking Dataset and Benchmark in Soccer Videos
Apr 20, 2022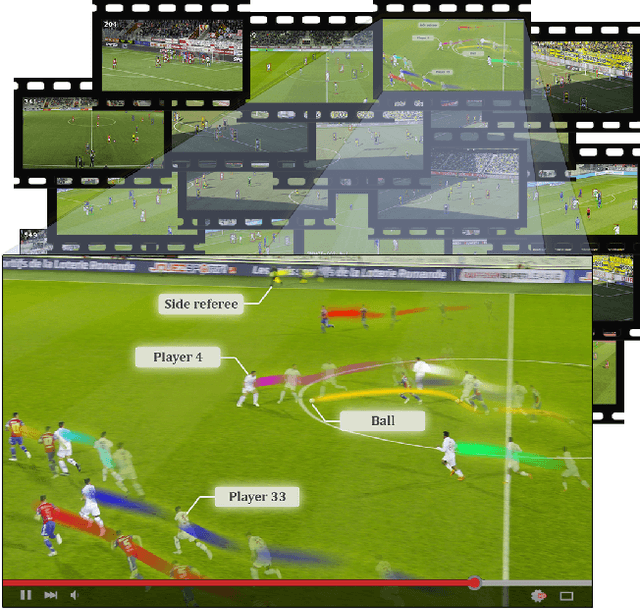
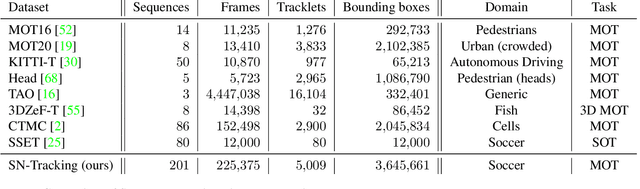
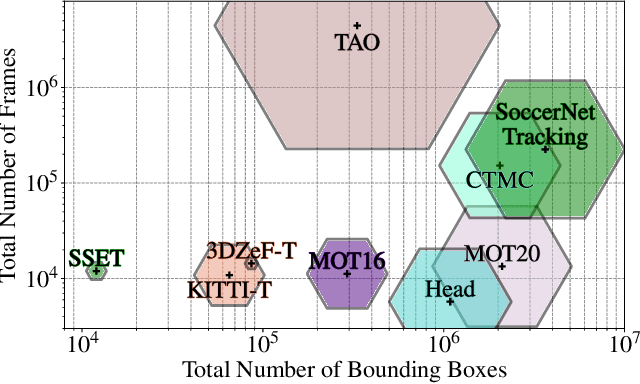
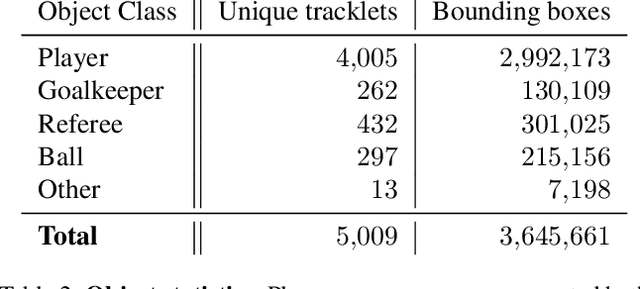
Tracking objects in soccer videos is extremely important to gather both player and team statistics, whether it is to estimate the total distance run, the ball possession or the team formation. Video processing can help automating the extraction of those information, without the need of any invasive sensor, hence applicable to any team on any stadium. Yet, the availability of datasets to train learnable models and benchmarks to evaluate methods on a common testbed is very limited. In this work, we propose a novel dataset for multiple object tracking composed of 200 sequences of 30s each, representative of challenging soccer scenarios, and a complete 45-minutes half-time for long-term tracking. The dataset is fully annotated with bounding boxes and tracklet IDs, enabling the training of MOT baselines in the soccer domain and a full benchmarking of those methods on our segregated challenge sets. Our analysis shows that multiple player, referee and ball tracking in soccer videos is far from being solved, with several improvement required in case of fast motion or in scenarios of severe occlusion.
Underwater Image Enhancement Using Pre-trained Transformer
Apr 08, 2022
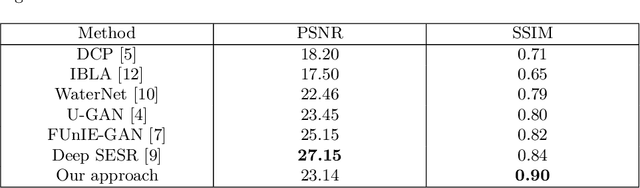
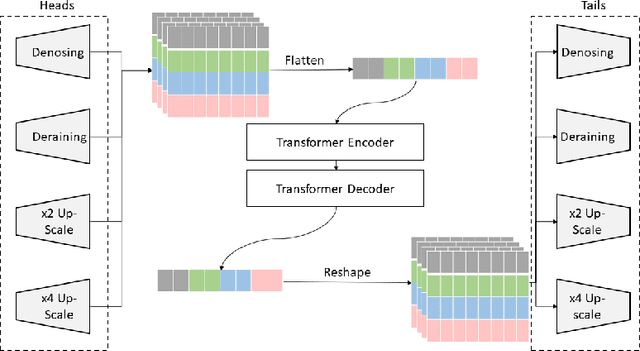
The goal of this work is to apply a denoising image transformer to remove the distortion from underwater images and compare it with other similar approaches. Automatic restoration of underwater images plays an important role since it allows to increase the quality of the images, without the need for more expensive equipment. This is a critical example of the important role of the machine learning algorithms to support marine exploration and monitoring, reducing the need for human intervention like the manual processing of the images, thus saving time, effort, and cost. This paper is the first application of the image transformer-based approach called "Pre-Trained Image Processing Transformer" to underwater images. This approach is tested on the UFO-120 dataset, containing 1500 images with the corresponding clean images.
Nonsmooth convex optimization to estimate the Covid-19 reproduction number space-time evolution with robustness against low quality data
Sep 20, 2021
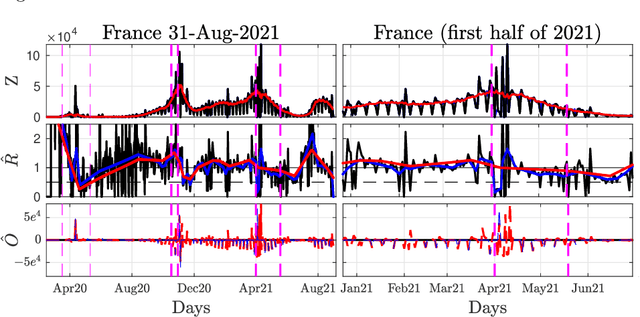
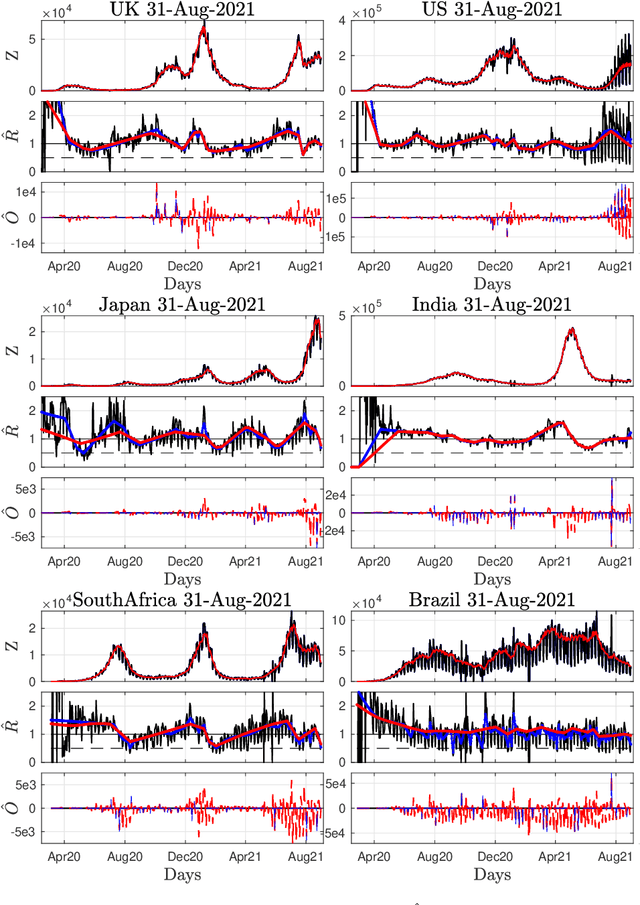
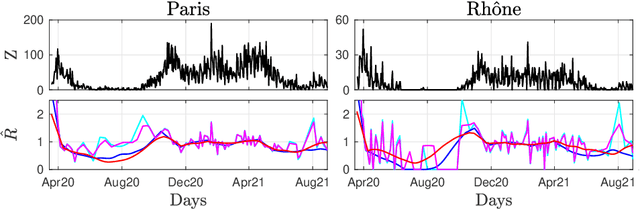
Daily pandemic surveillance, often achieved through the estimation of the reproduction number, constitutes a critical challenge for national health authorities to design countermeasures. In an earlier work, we proposed to formulate the estimation of the reproduction number as an optimization problem, combining data-model fidelity and space-time regularity constraints, solved by nonsmooth convex proximal minimizations. Though promising, that first formulation significantly lacks robustness against the Covid-19 data low quality (irrelevant or missing counts, pseudo-seasonalities,.. .) stemming from the emergency and crisis context, which significantly impairs accurate pandemic evolution assessments. The present work aims to overcome these limitations by carefully crafting a functional permitting to estimate jointly, in a single step, the reproduction number and outliers defined to model low quality data. This functional also enforces epidemiology-driven regularity properties for the reproduction number estimates, while preserving convexity, thus permitting the design of efficient minimization algorithms, based on proximity operators that are derived analytically. The explicit convergence of the proposed algorithm is proven theoretically. Its relevance is quantified on real Covid-19 data, consisting of daily new infection counts for 200+ countries and for the 96 metropolitan France counties, publicly available at Johns Hopkins University and Sant{\'e}-Publique-France. The procedure permits automated daily updates of these estimates, reported via animated and interactive maps. Open-source estimation procedures will be made publicly available.
Wind power predictions from nowcasts to 4-hour forecasts: a learning approach with variable selection
Apr 20, 2022

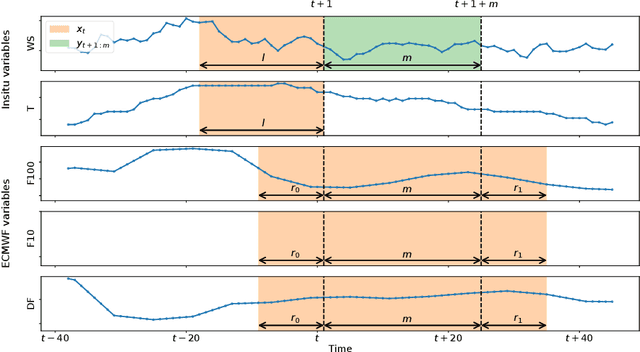
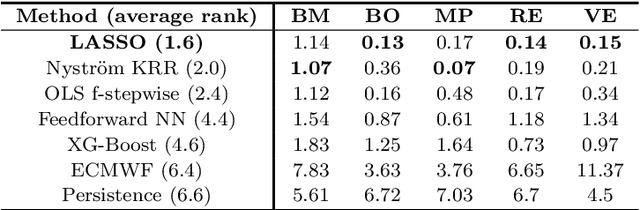
We study the prediction of short term wind speed and wind power (every 10 minutes up to 4 hours ahead). Accurate forecasts for those quantities are crucial to mitigate the negative effects of wind farms' intermittent production on energy systems and markets. For those time scales, outputs of numerical weather prediction models are usually overlooked even though they should provide valuable information on higher scales dynamics. In this work, we combine those outputs with local observations using machine learning. So as to make the results usable for practitioners, we focus on simple and well known methods which can handle a high volume of data. We study first variable selection through two simple techniques, a linear one and a nonlinear one. Then we exploit those results to forecast wind speed and wind power still with an emphasis on linear models versus nonlinear ones. For the wind power prediction, we also compare the indirect approach (wind speed predictions passed through a power curve) and the indirect one (directly predict wind power).
The role of haptic communication in dyadic collaborative object manipulation tasks
Mar 02, 2022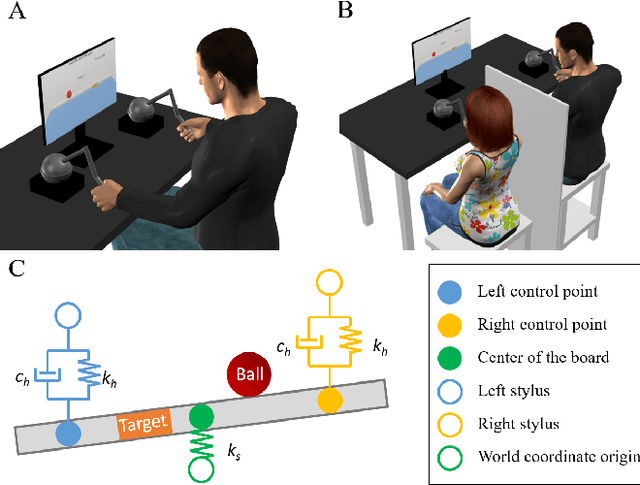
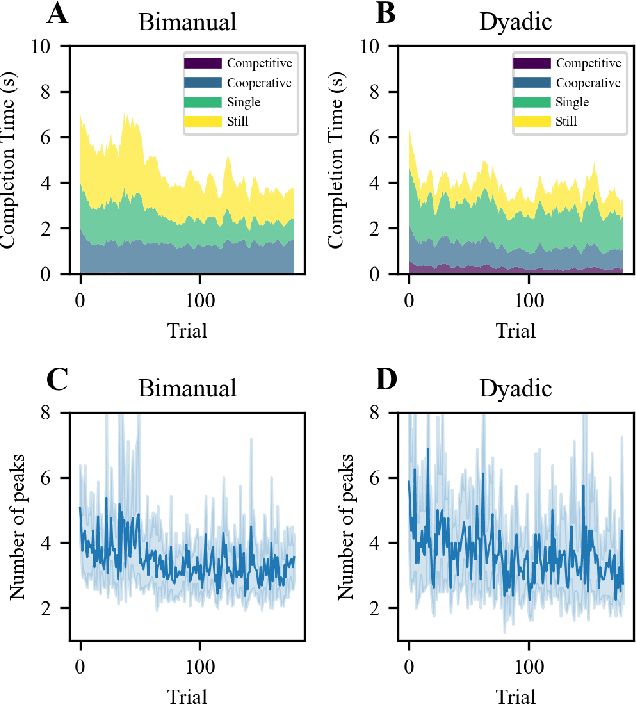
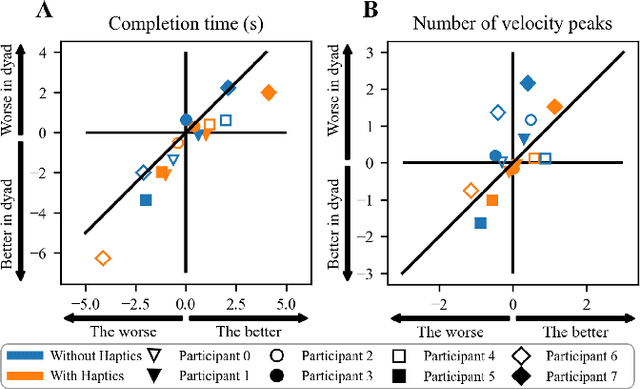
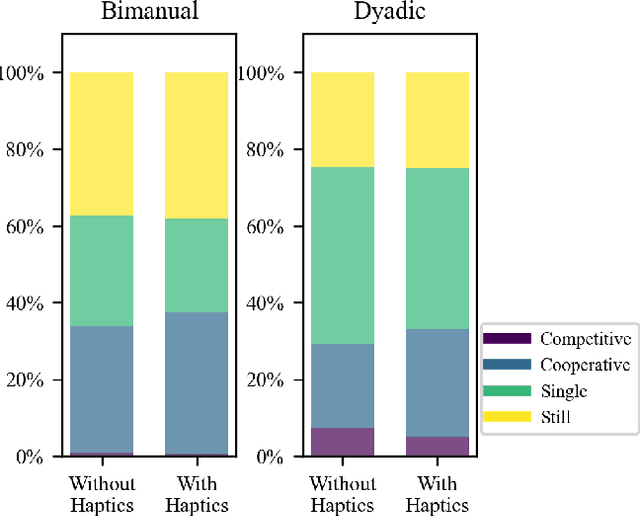
Intuitive and efficient physical human-robot collaboration relies on the mutual observability of the human and the robot, i.e. the two entities being able to interpret each other's intentions and actions. This is remedied by a myriad of methods involving human sensing or intention decoding, as well as human-robot turn-taking and sequential task planning. However, the physical interaction establishes a rich channel of communication through forces, torques and haptics in general, which is often overlooked in industrial implementations of human-robot interaction. In this work, we investigate the role of haptics in human collaborative physical tasks, to identify how to integrate physical communication in human-robot teams. We present a task to balance a ball at a target position on a board either bimanually by one participant, or dyadically by two participants, with and without haptic information. The task requires that the two sides coordinate with each other, in real-time, to balance the ball at the target. We found that with training the completion time and number of velocity peaks of the ball decreased, and that participants gradually became consistent in their braking strategy. Moreover we found that the presence of haptic information improved the performance (decreased completion time) and led to an increase in overall cooperative movements. Overall, our results show that humans can better coordinate with one another when haptic feedback is available. These results also highlight the likely importance of haptic communication in human-robot physical interaction, both as a tool to infer human intentions and to make the robot behaviour interpretable to humans.
OutCast: Outdoor Single-image Relighting with Cast Shadows
Apr 20, 2022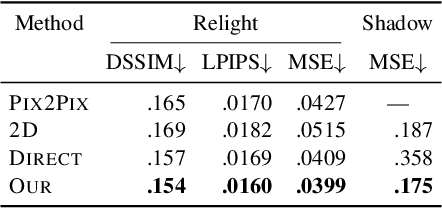
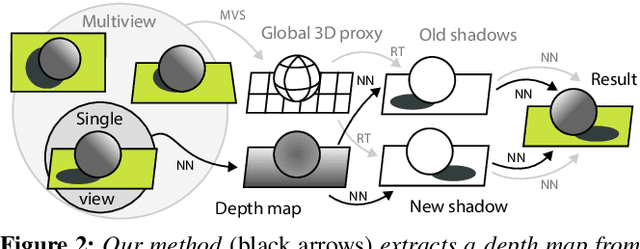
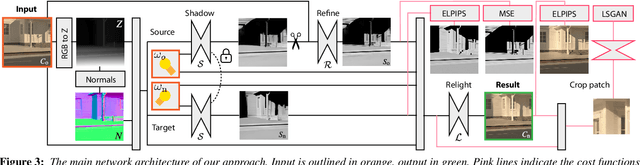
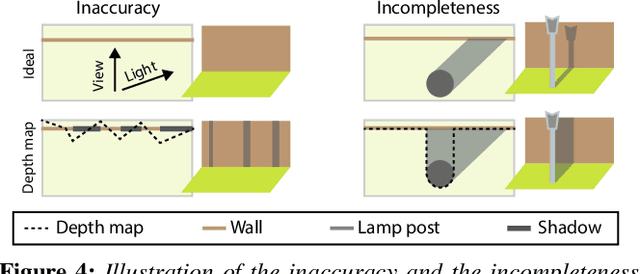
We propose a relighting method for outdoor images. Our method mainly focuses on predicting cast shadows in arbitrary novel lighting directions from a single image while also accounting for shading and global effects such the sun light color and clouds. Previous solutions for this problem rely on reconstructing occluder geometry, e.g. using multi-view stereo, which requires many images of the scene. Instead, in this work we make use of a noisy off-the-shelf single-image depth map estimation as a source of geometry. Whilst this can be a good guide for some lighting effects, the resulting depth map quality is insufficient for directly ray-tracing the shadows. Addressing this, we propose a learned image space ray-marching layer that converts the approximate depth map into a deep 3D representation that is fused into occlusion queries using a learned traversal. Our proposed method achieves, for the first time, state-of-the-art relighting results, with only a single image as input. For supplementary material visit our project page at: https://dgriffiths.uk/outcast.
Leveraging Smooth Attention Prior for Multi-Agent Trajectory Prediction
Mar 08, 2022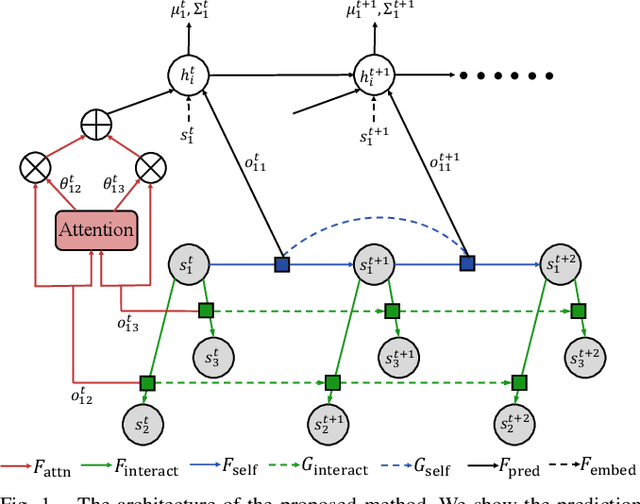
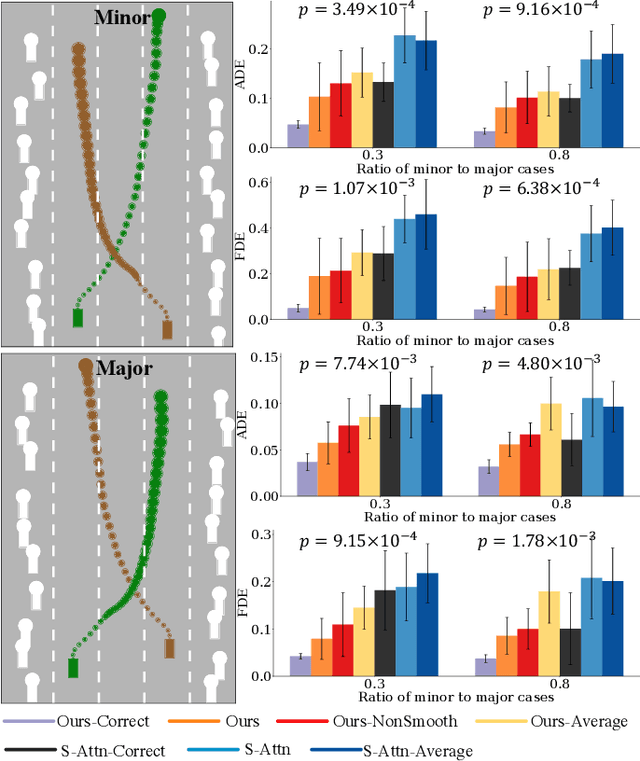
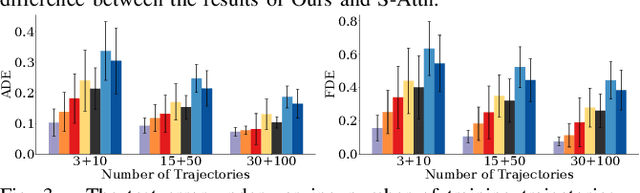
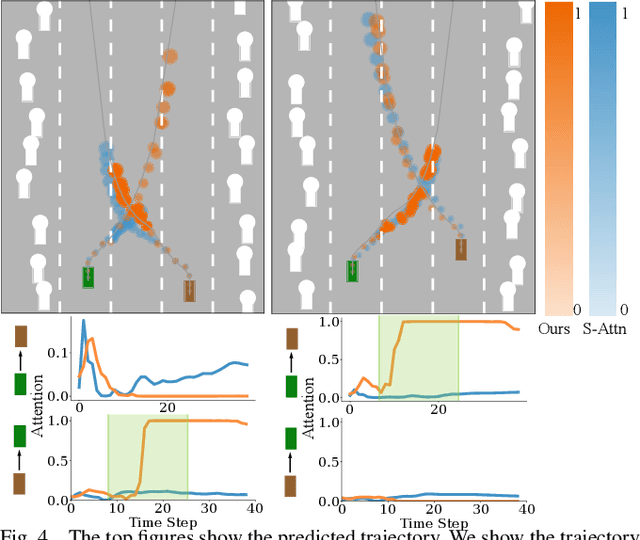
Multi-agent interactions are important to model for forecasting other agents' behaviors and trajectories. At a certain time, to forecast a reasonable future trajectory, each agent needs to pay attention to the interactions with only a small group of most relevant agents instead of unnecessarily paying attention to all the other agents. However, existing attention modeling works ignore that human attention in driving does not change rapidly, and may introduce fluctuating attention across time steps. In this paper, we formulate an attention model for multi-agent interactions based on a total variation temporal smoothness prior and propose a trajectory prediction architecture that leverages the knowledge of these attended interactions. We demonstrate how the total variation attention prior along with the new sequence prediction loss terms leads to smoother attention and more sample-efficient learning of multi-agent trajectory prediction, and show its advantages in terms of prediction accuracy by comparing it with the state-of-the-art approaches on both synthetic and naturalistic driving data. We demonstrate the performance of our algorithm for trajectory prediction on the INTERACTION dataset on our website.
* 8 pages
Non-intrusive surrogate modeling for parametrized time-dependent PDEs using convolutional autoencoders
Jan 14, 2021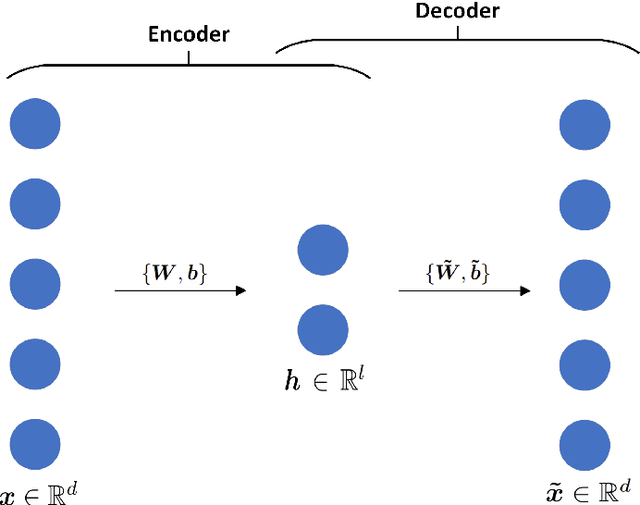
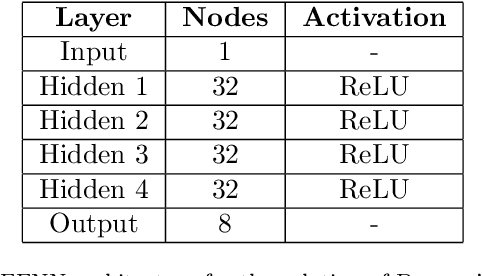
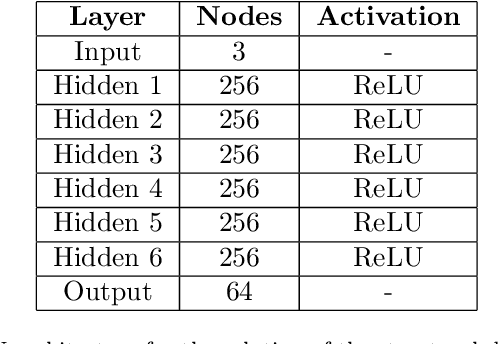
This work presents a non-intrusive surrogate modeling scheme based on machine learning technology for predictive modeling of complex systems, described by parametrized time-dependent PDEs. For these problems, typical finite element approaches involve the spatiotemporal discretization of the PDE and the solution of the corresponding linear system of equations at each time step. Instead, the proposed method utilizes a convolutional autoencoder in conjunction with a feed forward neural network to establish a low-cost and accurate mapping from the problem's parametric space to its solution space. For this purpose, time history response data are collected by solving the high-fidelity model via FEM for a reduced set of parameter values. Then, by applying the convolutional autoencoder to this data set, a low-dimensional representation of the high-dimensional solution matrices is provided by the encoder, while the reconstruction map is obtained by the decoder. Using the latent representation given by the encoder, a feed-forward neural network is efficiently trained to map points from the problem's parametric space to the compressed version of the respective solution matrices. This way, the encoded response of the system at new parameter values is given by the neural network, while the entire response is delivered by the decoder. This approach effectively bypasses the need to serially formulate and solve the system's governing equations at each time increment, thus resulting in a significant cost reduction and rendering the method ideal for problems requiring repeated model evaluations or 'real-time' computations. The elaborated methodology is demonstrated on the stochastic analysis of time-dependent PDEs solved with the Monte Carlo method, however, it can be straightforwardly applied to other similar-type problems, such as sensitivity analysis, design optimization, etc.
Federated Learning in Multi-Center Critical Care Research: A Systematic Case Study using the eICU Database
Apr 20, 2022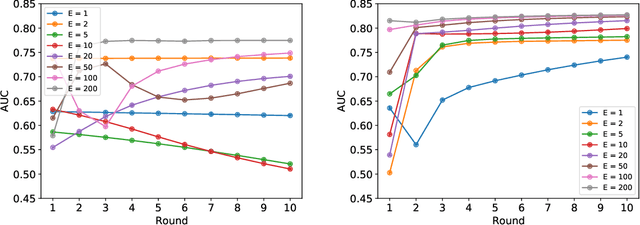
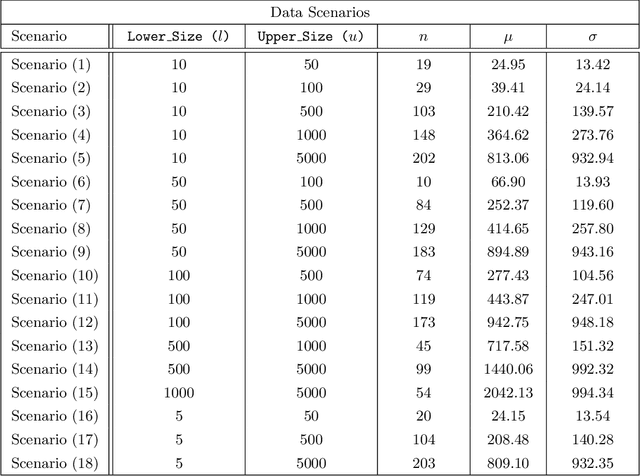
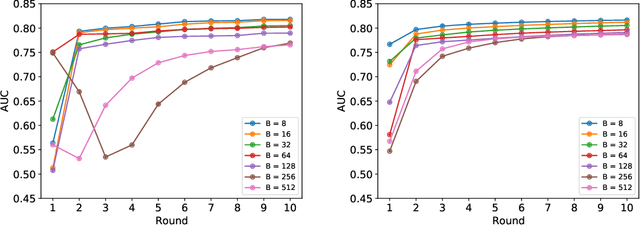
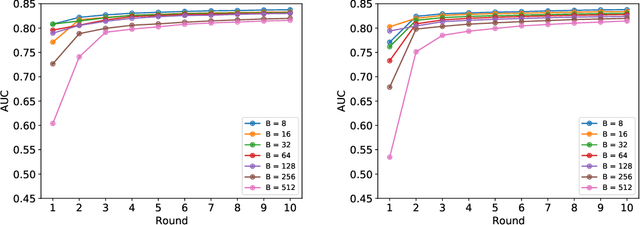
Federated learning (FL) has been proposed as a method to train a model on different units without exchanging data. This offers great opportunities in the healthcare sector, where large datasets are available but cannot be shared to ensure patient privacy. We systematically investigate the effectiveness of FL on the publicly available eICU dataset for predicting the survival of each ICU stay. We employ Federated Averaging as the main practical algorithm for FL and show how its performance changes by altering three key hyper-parameters, taking into account that clients can significantly vary in size. We find that in many settings, a large number of local training epochs improves the performance while at the same time reducing communication costs. Furthermore, we outline in which settings it is possible to have only a low number of hospitals participating in each federated update round. When many hospitals with low patient counts are involved, the effect of overfitting can be avoided by decreasing the batchsize. This study thus contributes toward identifying suitable settings for running distributed algorithms such as FL on clinical datasets.