 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Human-Robot Collaborative Manipulations of Cylindrical and Cubic Objects via Geometric Primitives and Depth Information
Jun 28, 2021

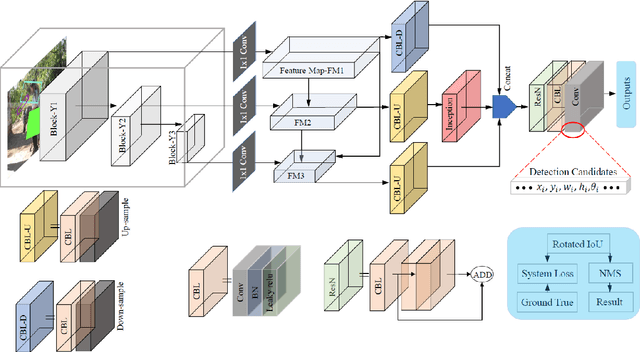
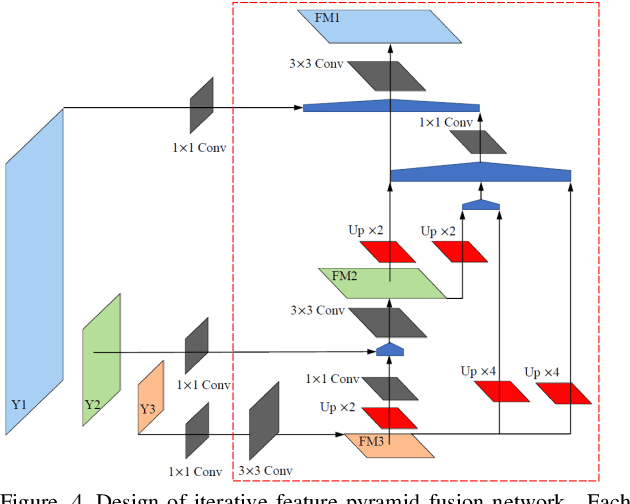
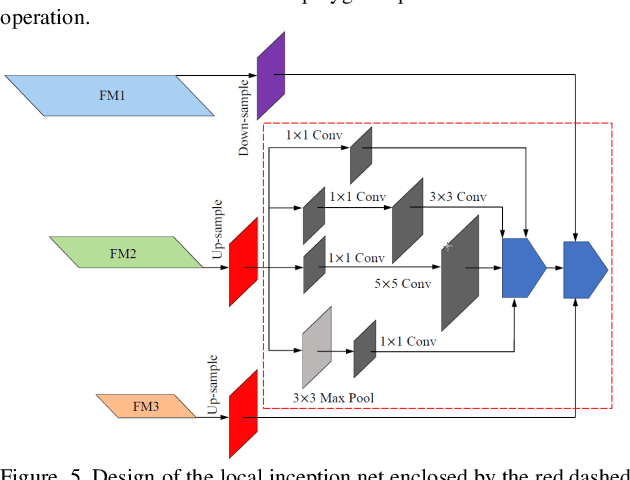
Many objects commonly found in household and industrial environments are represented by cylindrical and cubic shapes. Thus, it is available for robots to manipulate them through the real-time detection of elliptic and rectangle shape primitives formed by the circular and rectangle tops of these objects. We devise a robust grasping system that enables a robot to manipulate cylindrical and cubic objects in collaboration scenarios by the proposed perception strategy including the detection of elliptic and rectangle shape primitives and depth information. The proposed method of detecting ellipses and rectangles incorporates a one-stage detection backbone and then, accommodates the proposed adaptive multi-branch multi-scale net with a designed iterative feature pyramid network, local inception net, and multi-receptive-filed feature fusion net to generate object detection recommendations. In terms of manipulating objects with different shapes, we propose the grasp synthetic to align the grasp pose of the gripper with an object's pose based on the proposed detector and registered depth information. The proposed robotic perception algorithm has been integrated on a robot to demonstrate the ability to carry out human-robot collaborative manipulations of cylindrical and cubic objects in real-time. We show that the robotic manipulator, empowered by the proposed detector, performs well in practical manipulation scenarios.(An experiment video is available in YouTube, https://www.youtube.com/watch?v=Amcs8lwvNK8.)
HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection
Feb 02, 2022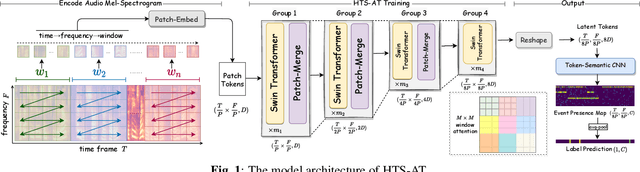
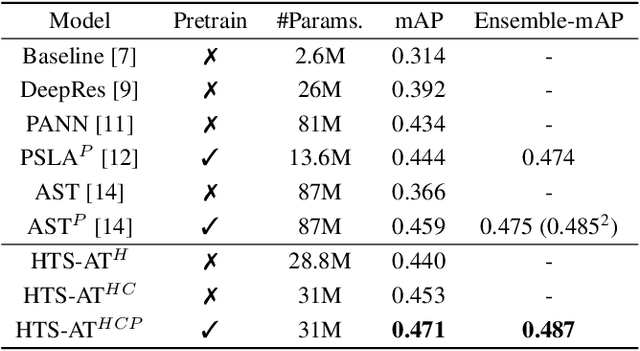
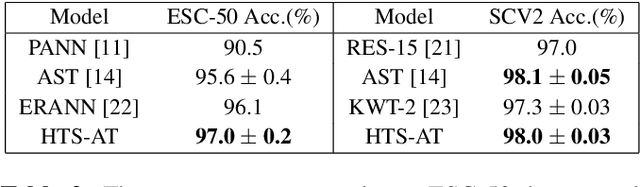

Audio classification is an important task of mapping audio samples into their corresponding labels. Recently, the transformer model with self-attention mechanisms has been adopted in this field. However, existing audio transformers require large GPU memories and long training time, meanwhile relying on pretrained vision models to achieve high performance, which limits the model's scalability in audio tasks. To combat these problems, we introduce HTS-AT: an audio transformer with a hierarchical structure to reduce the model size and training time. It is further combined with a token-semantic module to map final outputs into class featuremaps, thus enabling the model for the audio event detection (i.e. localization in time). We evaluate HTS-AT on three datasets of audio classification where it achieves new state-of-the-art (SOTA) results on AudioSet and ESC-50, and equals the SOTA on Speech Command V2. It also achieves better performance in event localization than the previous CNN-based models. Moreover, HTS-AT requires only 35% model parameters and 15% training time of the previous audio transformer. These results demonstrate the high performance and high efficiency of HTS-AT.
neuro2vec: Masked Fourier Spectrum Prediction for Neurophysiological Representation Learning
Apr 20, 2022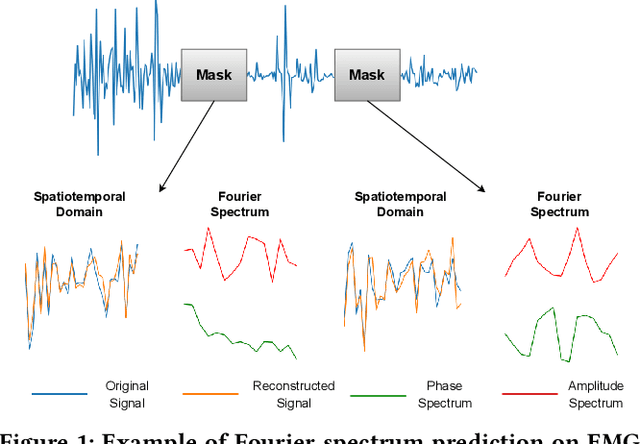
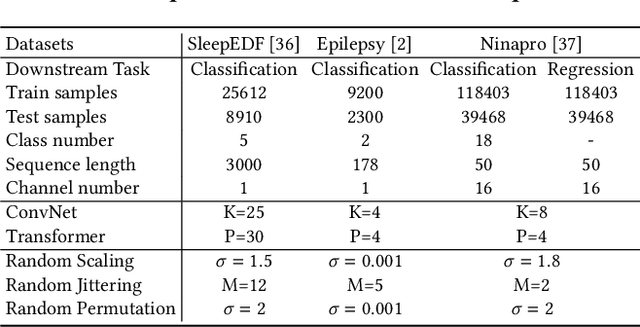
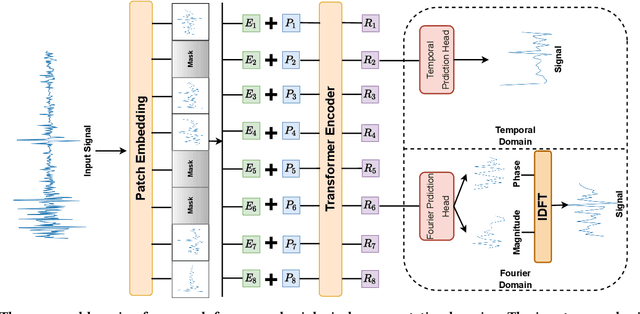
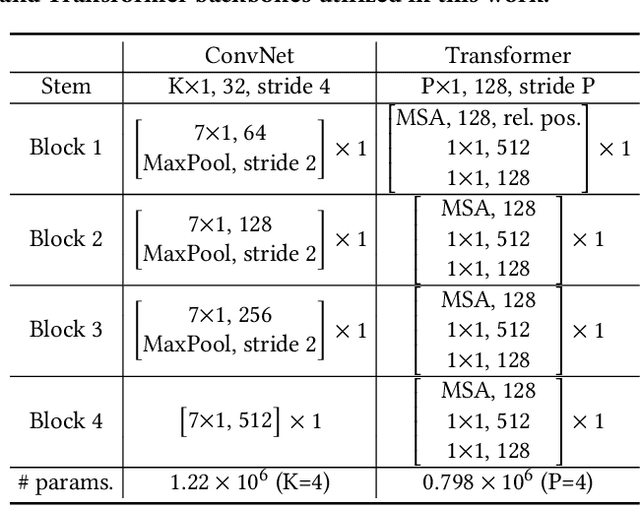
Extensive data labeling on neurophysiological signals is often prohibitively expensive or impractical, as it may require particular infrastructure or domain expertise. To address the appetite for data of deep learning methods, we present for the first time a Fourier-based modeling framework for self-supervised pre-training of neurophysiology signals. The intuition behind our approach is simple: frequency and phase distribution of neurophysiology signals reveal the underlying neurophysiological activities of the brain and muscle. Our approach first randomly masks out a portion of the input signal and then predicts the missing information from either spatiotemporal or the Fourier domain. Pre-trained models can be potentially used for downstream tasks such as sleep stage classification using electroencephalogram (EEG) signals and gesture recognition using electromyography (EMG) signals. Unlike contrastive-based methods, which strongly rely on carefully hand-crafted augmentations and siamese structure, our approach works reasonably well with a simple transformer encoder with no augmentation requirements. By evaluating our method on several benchmark datasets, including both EEG and EMG, we show that our modeling approach improves downstream neurophysiological related tasks by a large margin.
Tailor: A Prompt-Based Approach to Attribute-Based Controlled Text Generation
Apr 28, 2022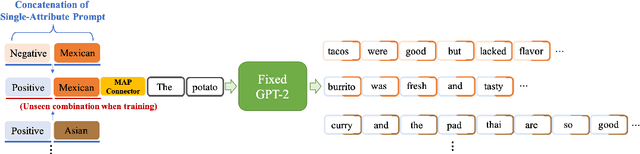
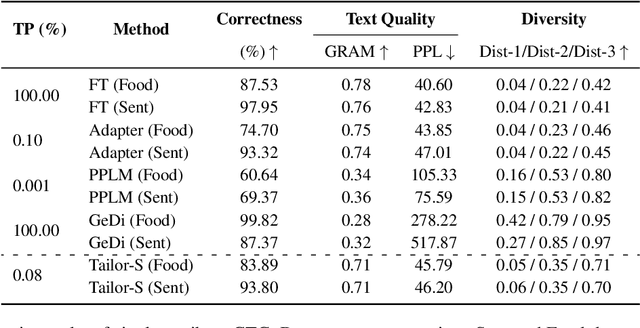
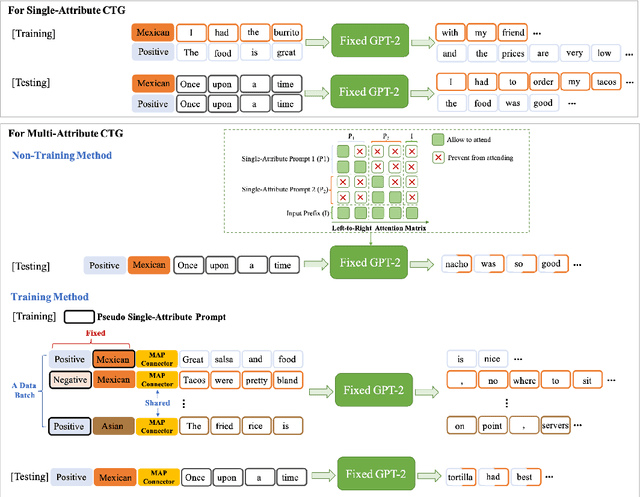
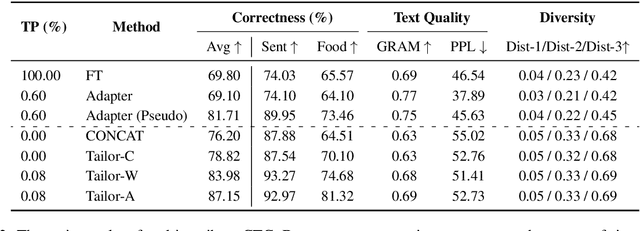
Attribute-based Controlled Text Generation (CTG) refers to generating sentences that satisfy desirable attributes (e.g., emotions and topics). Existing works often utilize fine-tuning or resort to extra attribute classifiers, yet suffer from storage and inference time increases. To address these concerns, we explore attribute-based CTG in a prompt-based manner. In short, the proposed Tailor represents each attribute as a pre-trained continuous vector (i.e., single-attribute prompt) and guides the generation of a fixed PLM switch to a pre-specified attribute. We experimentally find that these prompts can be simply concatenated as a whole to multi-attribute CTG without any re-training, yet raises problems of fluency decrease and position sensitivity. To this end, Tailor provides a multi-attribute prompt mask and a re-indexing position-ids sequence to bridge the gap between the training (one prompt for each task) and testing stage (concatenating more than one prompt). To further enhance such single-attribute prompt combinations, Tailor also introduces a trainable prompt connector, which can be concatenated with any two single-attribute prompts to multi-attribute text generation. Experiments on 11 attribute-specific generation tasks demonstrate strong performances of Tailor on both single-attribute and multi-attribute CTG, with 0.08\% training parameters of a GPT-2.
Real-Time Decentralized knowledge Transfer at the Edge
Nov 11, 2020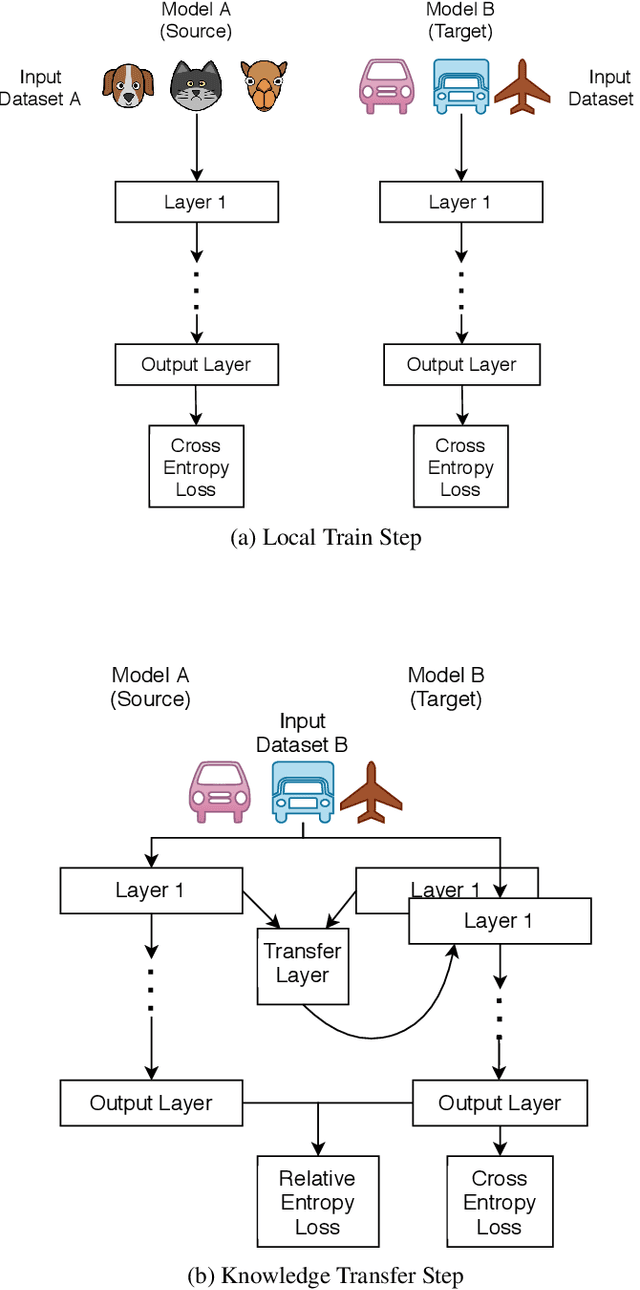
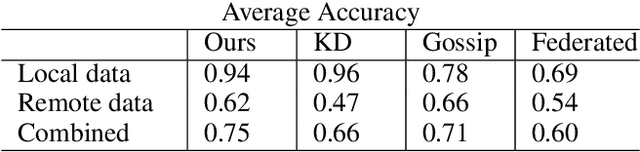
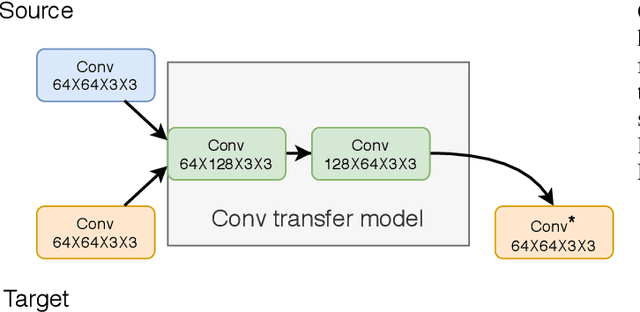

Proliferation of edge networks creates islands of learning agents working on local streams of data. Transferring knowledge between these agents in real-time without exposing private data allows for collaboration to decrease learning time, and increase model confidence. Incorporating knowledge from data that was not seen by a local model creates an ability to debias a local model, or add to classification abilities on data never before seen. Transferring knowledge in a decentralized approach allows for models to retain their local insights, in turn allowing for local flavors of a machine learning model. This approach suits the decentralized architecture of edge networks, as a local edge node will serve a community of learning agents that will likely encounter similar data. We propose a method based on knowledge distillation for pairwise knowledge transfer pipelines, and compare to other popular knowledge transfer methods. Additionally, we test different scenarios of knowledge transfer network construction and show the practicality of our approach. Based on our experiments we show knowledge transfer using our model outperforms common methods in a real time transfer scenario.
A De-raining semantic segmentation network for real-time foreground segmentation
Apr 16, 2021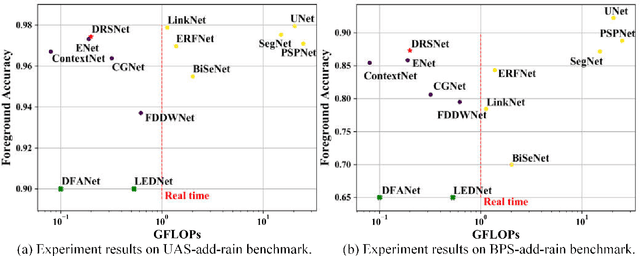

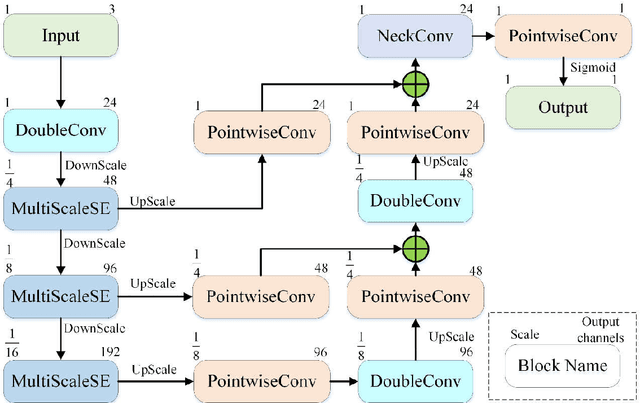
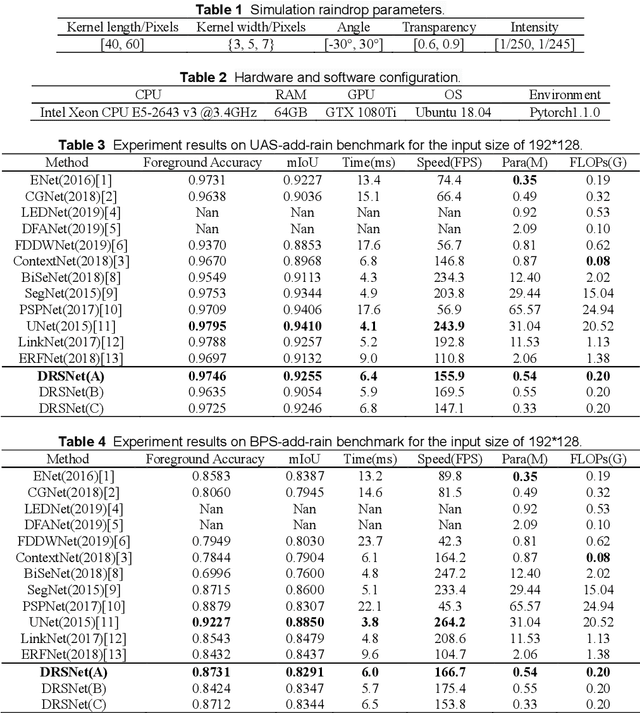
Few researches have been proposed specifically for real-time semantic segmentation in rainy environments. However, the demand in this area is huge and it is challenging for lightweight networks. Therefore, this paper proposes a lightweight network which is specially designed for the foreground segmentation in rainy environments, named De-raining Semantic Segmentation Network (DRSNet). By analyzing the characteristics of raindrops, the MultiScaleSE Block is targetedly designed to encode the input image, it uses multi-scale dilated convolutions to increase the receptive field, and SE attention mechanism to learn the weights of each channels. In order to combine semantic information between different encoder and decoder layers, it is proposed to use Asymmetric Skip, that is, the higher semantic layer of encoder employs bilinear interpolation and the output passes through pointwise convolution, then added element-wise to the lower semantic layer of decoder. According to the control experiments, the performances of MultiScaleSE Block and Asymmetric Skip compared with SEResNet18 and Symmetric Skip respectively are improved to a certain degree on the Foreground Accuracy index. The parameters and the floating point of operations (FLOPs) of DRSNet is only 0.54M and 0.20GFLOPs separately. The state-of-the-art results and real-time performances are achieved on both the UESTC all-day Scenery add rain (UAS-add-rain) and the Baidu People Segmentation add rain (BPS-add-rain) benchmarks with the input sizes of 192*128, 384*256 and 768*512. The speed of DRSNet exceeds all the networks within 1GFLOPs, and Foreground Accuracy index is also the best among the similar magnitude networks on both benchmarks.
Accelerating Robot Learning of Contact-Rich Manipulations: A Curriculum Learning Study
Apr 28, 2022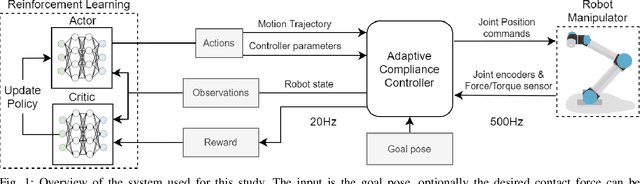
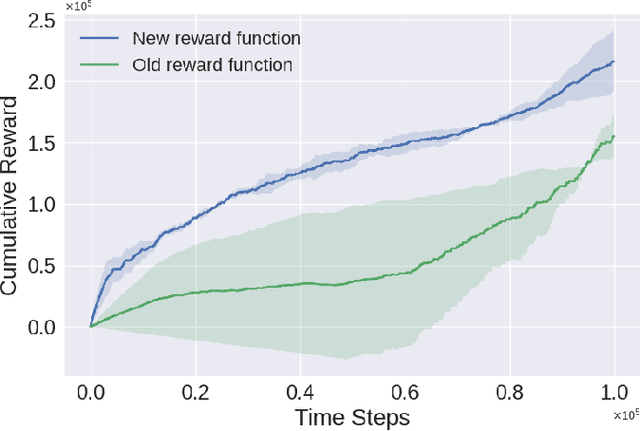
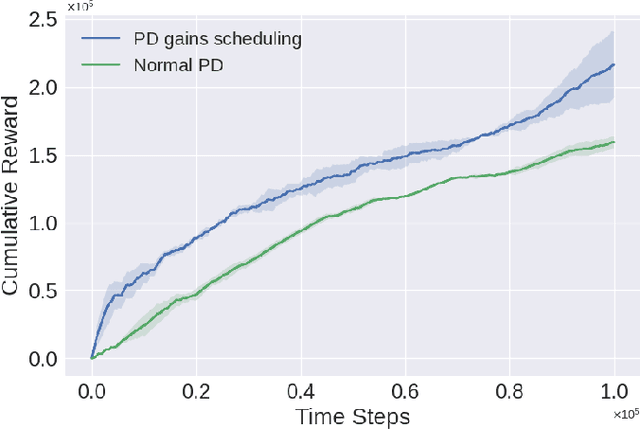
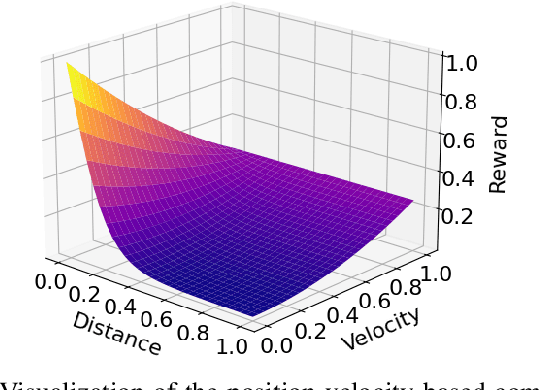
The Reinforcement Learning (RL) paradigm has been an essential tool for automating robotic tasks. Despite the advances in RL, it is still not widely adopted in the industry due to the need for an expensive large amount of robot interaction with its environment. Curriculum Learning (CL) has been proposed to expedite learning. However, most research works have been only evaluated in simulated environments, from video games to robotic toy tasks. This paper presents a study for accelerating robot learning of contact-rich manipulation tasks based on Curriculum Learning combined with Domain Randomization (DR). We tackle complex industrial assembly tasks with position-controlled robots, such as insertion tasks. We compare different curricula designs and sampling approaches for DR. Based on this study, we propose a method that significantly outperforms previous work, which uses DR only (No CL is used), with less than a fifth of the training time (samples). Results also show that even when training only in simulation with toy tasks, our method can learn policies that can be transferred to the real-world robot. The learned policies achieved success rates of up to 86\% on real-world complex industrial insertion tasks (with tolerances of $\pm 0.01~mm$) not seen during the training.
X-Fields: Implicit Neural View-, Light- and Time-Image Interpolation
Oct 01, 2020
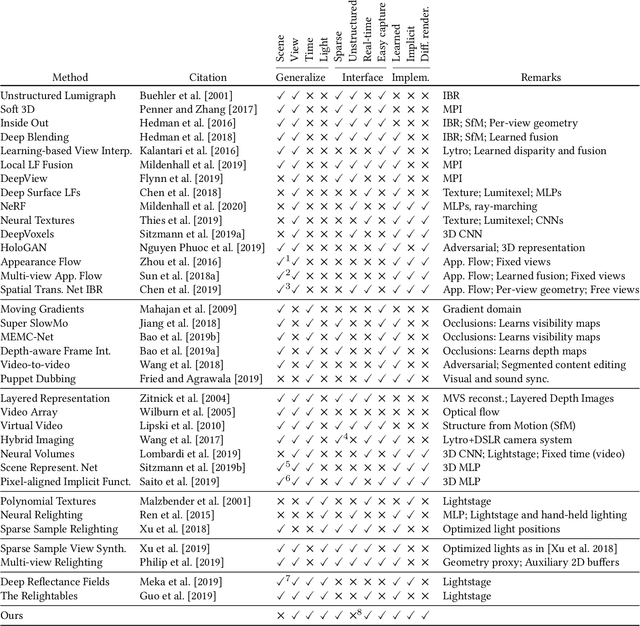
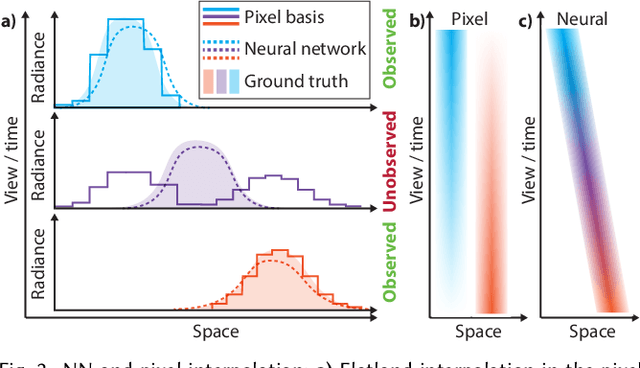
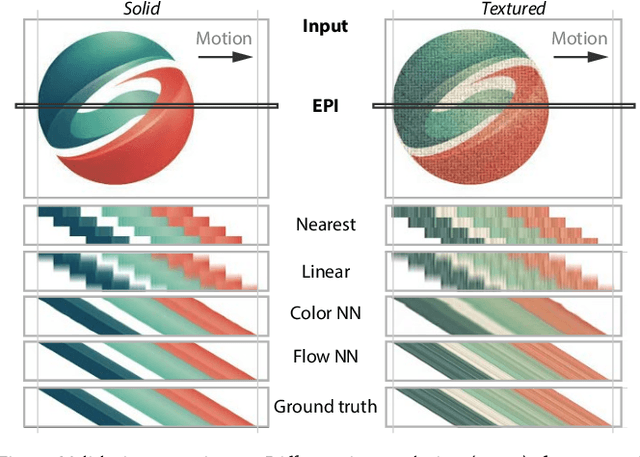
We suggest to represent an X-Field -a set of 2D images taken across different view, time or illumination conditions, i.e., video, light field, reflectance fields or combinations thereof-by learning a neural network (NN) to map their view, time or light coordinates to 2D images. Executing this NN at new coordinates results in joint view, time or light interpolation. The key idea to make this workable is a NN that already knows the "basic tricks" of graphics (lighting, 3D projection, occlusion) in a hard-coded and differentiable form. The NN represents the input to that rendering as an implicit map, that for any view, time, or light coordinate and for any pixel can quantify how it will move if view, time or light coordinates change (Jacobian of pixel position with respect to view, time, illumination, etc.). Our X-Field representation is trained for one scene within minutes, leading to a compact set of trainable parameters and hence real-time navigation in view, time and illumination.
Single UHD Image Dehazing via Interpretable Pyramid Network
Feb 17, 2022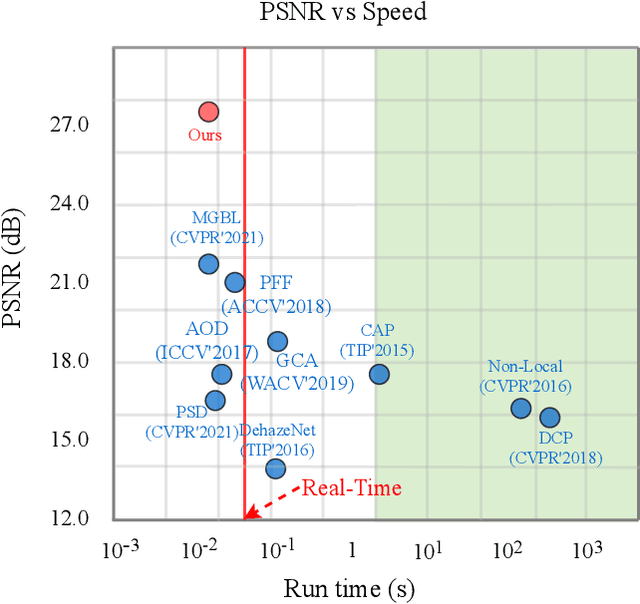

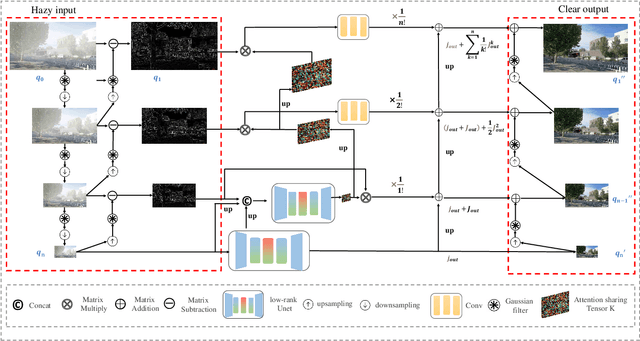

Currently, most single image dehazing models cannot run an ultra-high-resolution (UHD) image with a single GPU shader in real-time. To address the problem, we introduce the principle of infinite approximation of Taylor's theorem with the Laplace pyramid pattern to build a model which is capable of handling 4K hazy images in real-time. The N branch networks of the pyramid network correspond to the N constraint terms in Taylor's theorem. Low-order polynomials reconstruct the low-frequency information of the image (e.g. color, illumination). High-order polynomials regress the high-frequency information of the image (e.g. texture). In addition, we propose a Tucker reconstruction-based regularization term that acts on each branch network of the pyramid model. It further constrains the generation of anomalous signals in the feature space. Extensive experimental results demonstrate that our approach can not only run 4K images with haze in real-time on a single GPU (80FPS) but also has unparalleled interpretability. The developed method achieves state-of-the-art (SOTA) performance on two benchmarks (O/I-HAZE) and our updated 4KID dataset while providing the reliable groundwork for subsequent optimization schemes.
Generating Continuous Motion and Force Plans in Real-Time for Legged Mobile Manipulation
Apr 23, 2021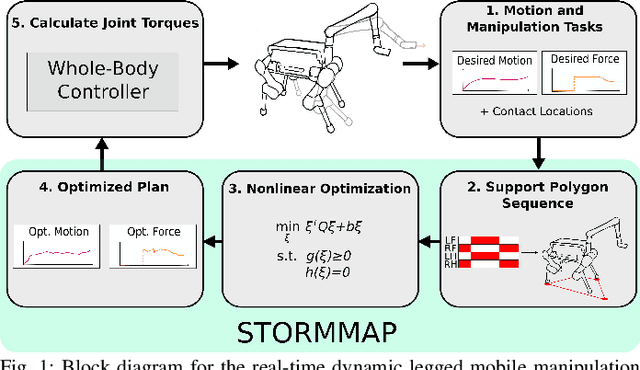

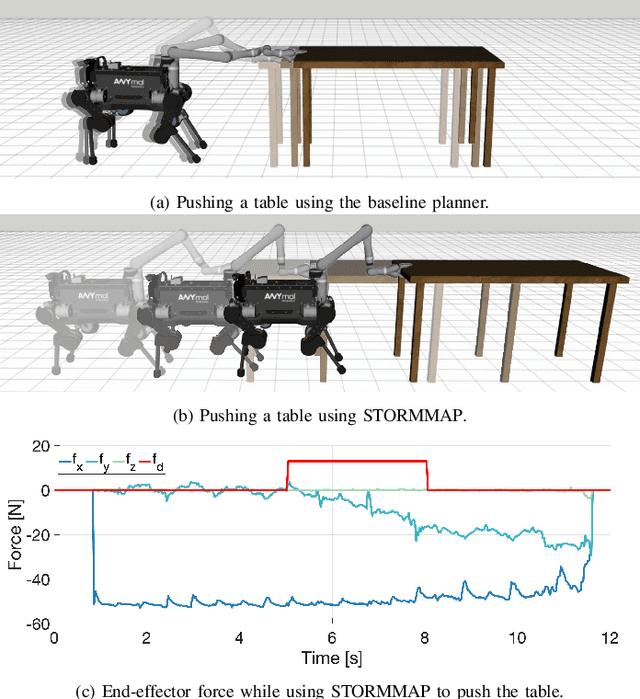
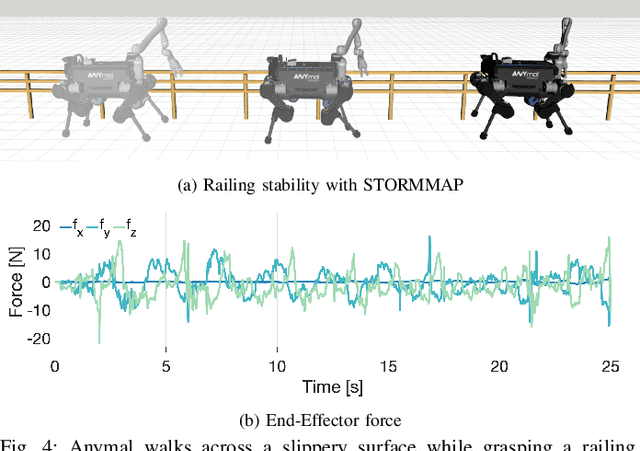
Manipulators can be added to legged robots, allowing them to interact with and change their environment. Legged mobile manipulation planners must consider how contact forces generated by these manipulators affect the system. Current planning strategies either treat these forces as immutable during planning or are unable to optimize over these contact forces while operating in real-time. This paper presents the Stability and Task Oriented Receding-Horizon Motion and Manipulation Autonomous Planner (STORMMAP) that is able to generate continuous plans for the robot's motion and manipulation force trajectories that ensure dynamic feasibility and stability of the platform, and incentivizes accomplishing manipulation and motion tasks specified by a user. STORMMAP uses a nonlinear optimization problem to compute these plans and is able to run in real-time by assuming contact locations are given a-priori, either by a user or an external algorithm. A variety of simulated experiments on a quadruped with a manipulator mounted to its torso demonstrate the versatility of STORMMAP. In contrast to existing state of the art methods, the approach described in this paper generates continuous plans in under ten milliseconds, an order of magnitude faster than previous strategies.