 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AI-enabled Assessment of Cardiac Systolic and Diastolic Function from Echocardiography
Mar 21, 2022

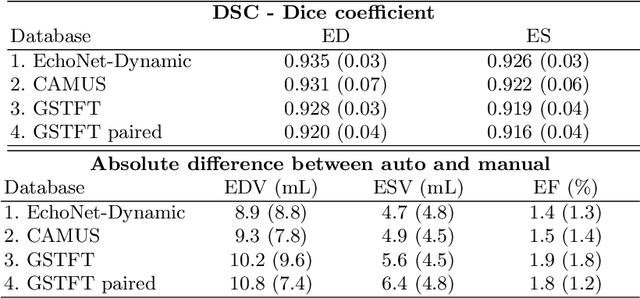
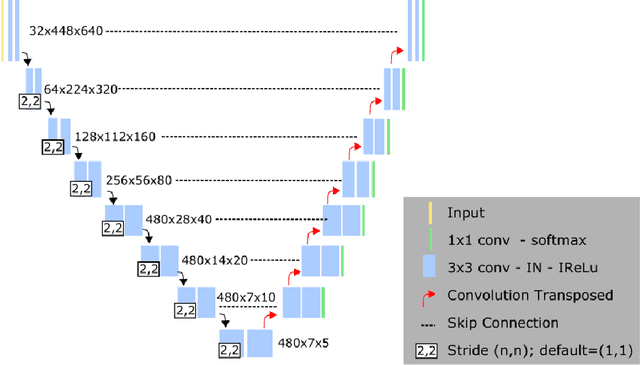

Left ventricular (LV) function is an important factor in terms of patient management, outcome, and long-term survival of patients with heart disease. The most recently published clinical guidelines for heart failure recognise that over reliance on only one measure of cardiac function (LV ejection fraction) as a diagnostic and treatment stratification biomarker is suboptimal. Recent advances in AI-based echocardiography analysis have shown excellent results on automated estimation of LV volumes and LV ejection fraction. However, from time-varying 2-D echocardiography acquisition, a richer description of cardiac function can be obtained by estimating functional biomarkers from the complete cardiac cycle. In this work we propose for the first time an AI approach for deriving advanced biomarkers of systolic and diastolic LV function from 2-D echocardiography based on segmentations of the full cardiac cycle. These biomarkers will allow clinicians to obtain a much richer picture of the heart in health and disease. The AI model is based on the 'nn-Unet' framework and was trained and tested using four different databases. Results show excellent agreement between manual and automated analysis and showcase the potential of the advanced systolic and diastolic biomarkers for patient stratification. Finally, for a subset of 50 cases, we perform a correlation analysis between clinical biomarkers derived from echocardiography and CMR and we show excellent agreement between the two modalities.
RobBERTje: a Distilled Dutch BERT Model
Apr 28, 2022
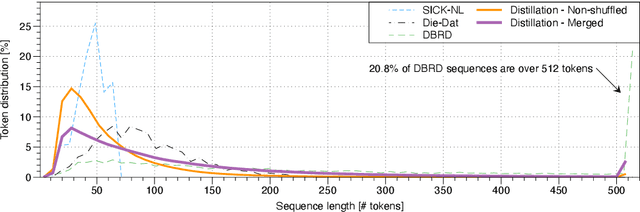


Pre-trained large-scale language models such as BERT have gained a lot of attention thanks to their outstanding performance on a wide range of natural language tasks. However, due to their large number of parameters, they are resource-intensive both to deploy and to fine-tune. Researchers have created several methods for distilling language models into smaller ones to increase efficiency, with a small performance trade-off. In this paper, we create several different distilled versions of the state-of-the-art Dutch RobBERT model and call them RobBERTje. The distillations differ in their distillation corpus, namely whether or not they are shuffled and whether they are merged with subsequent sentences. We found that the performance of the models using the shuffled versus non-shuffled datasets is similar for most tasks and that randomly merging subsequent sentences in a corpus creates models that train faster and perform better on tasks with long sequences. Upon comparing distillation architectures, we found that the larger DistilBERT architecture worked significantly better than the Bort hyperparametrization. Interestingly, we also found that the distilled models exhibit less gender-stereotypical bias than its teacher model. Since smaller architectures decrease the time to fine-tune, these models allow for more efficient training and more lightweight deployment of many Dutch downstream language tasks.
* Published in CLIN journal
Autoregressive based Drift Detection Method
Mar 09, 2022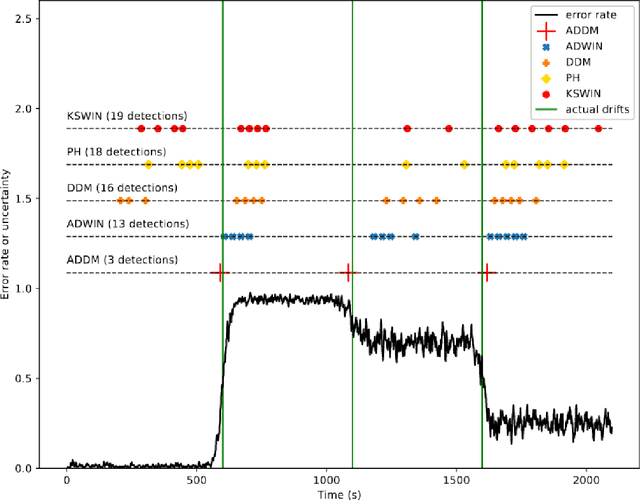
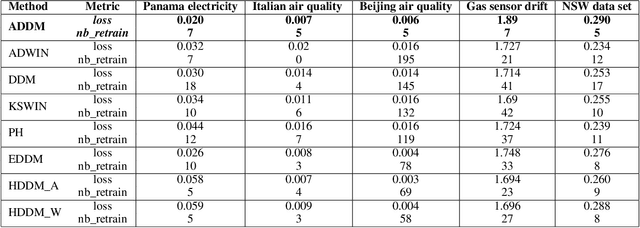
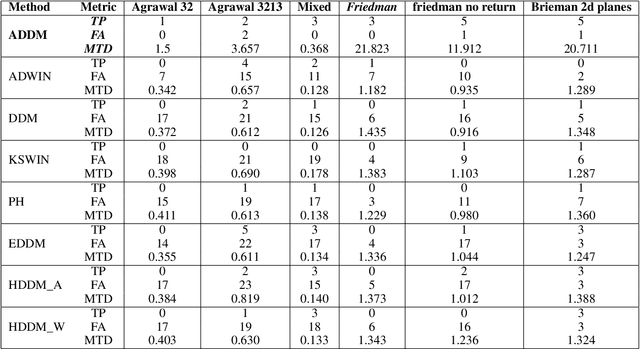
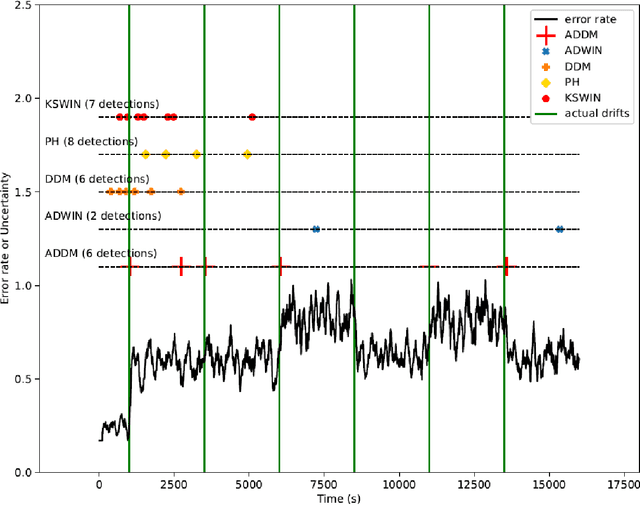
In the classic machine learning framework, models are trained on historical data and used to predict future values. It is assumed that the data distribution does not change over time (stationarity). However, in real-world scenarios, the data generation process changes over time and the model has to adapt to the new incoming data. This phenomenon is known as concept drift and leads to a decrease in the predictive model's performance. In this study, we propose a new concept drift detection method based on autoregressive models called ADDM. This method can be integrated into any machine learning algorithm from deep neural networks to simple linear regression model. Our results show that this new concept drift detection method outperforms the state-of-the-art drift detection methods, both on synthetic data sets and real-world data sets. Our approach is theoretically guaranteed as well as empirical and effective for the detection of various concept drifts. In addition to the drift detector, we proposed a new method of concept drift adaptation based on the severity of the drift.
Simulating User-Level Twitter Activity with XGBoost and Probabilistic Hybrid Models
Feb 18, 2022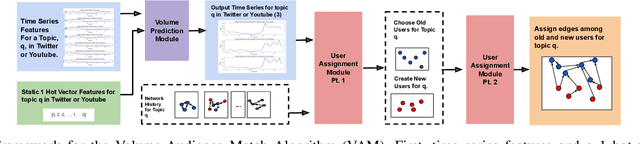
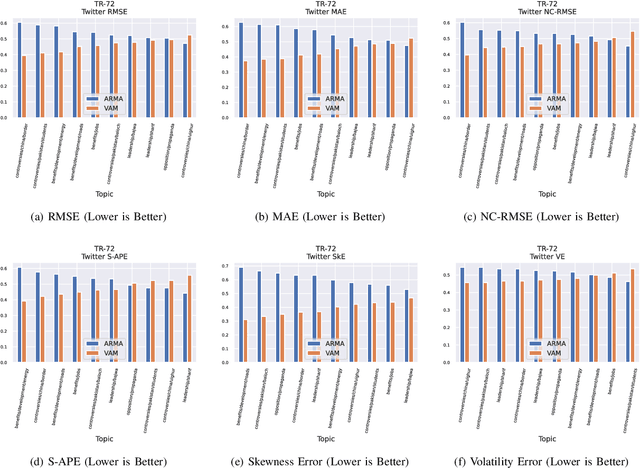
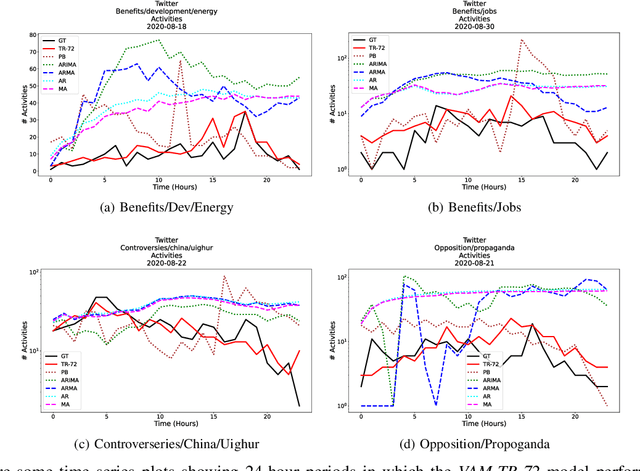
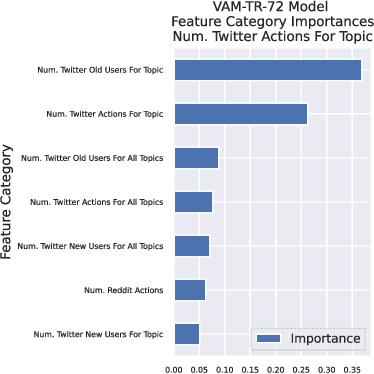
The Volume-Audience-Match simulator, or VAM was applied to predict future activity on Twitter related to international economic affairs. VAM was applied to do timeseries forecasting to predict the: (1) number of total activities, (2) number of active old users, and (3) number of newly active users over the span of 24 hours from the start time of prediction. VAM then used these volume predictions to perform user link predictions. A user-user edge was assigned to each of the activities in the 24 future timesteps. VAM considerably outperformed a set of baseline models in both the time series and user-assignment tasks
STAGE: Tool for Automated Extraction of Semantic Time Cues to Enrich Neural Temporal Ordering Models
May 15, 2021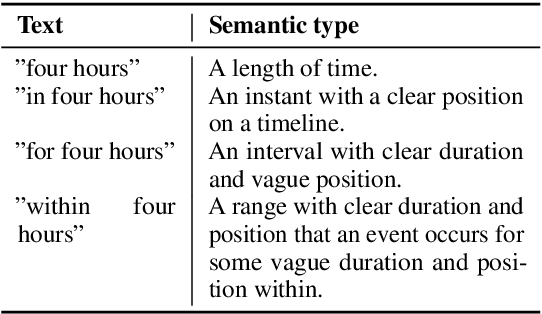
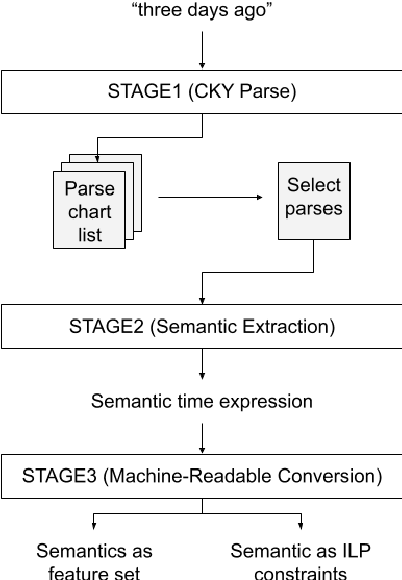
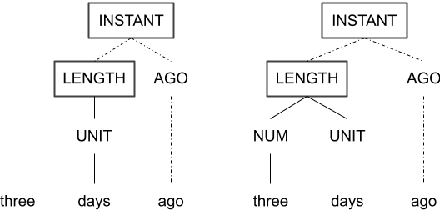

Despite achieving state-of-the-art accuracy on temporal ordering of events, neural models showcase significant gaps in performance. Our work seeks to fill one of these gaps by leveraging an under-explored dimension of textual semantics: rich semantic information provided by explicit textual time cues. We develop STAGE, a system that consists of a novel temporal framework and a parser that can automatically extract time cues and convert them into representations suitable for integration with neural models. We demonstrate the utility of extracted cues by integrating them with an event ordering model using a joint BiLSTM and ILP constraint architecture. We outline the functionality of the 3-part STAGE processing approach, and show two methods of integrating its representations with the BiLSTM-ILP model: (i) incorporating semantic cues as additional features, and (ii) generating new constraints from semantic cues to be enforced in the ILP. We demonstrate promising results on two event ordering datasets, and highlight important issues in semantic cue representation and integration for future research.
Finite-Time Convergence of Continuous-Time Optimization Algorithms via Differential Inclusions
Dec 18, 2019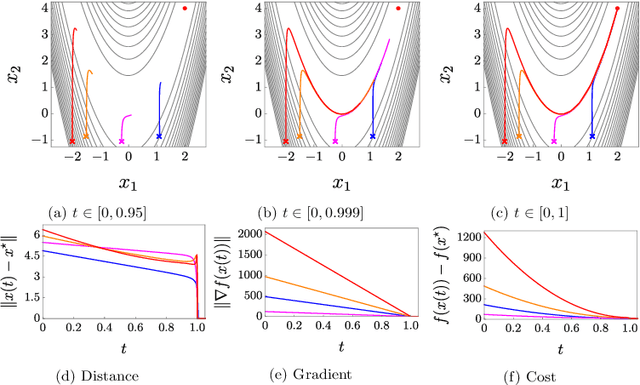
In this paper, we propose two discontinuous dynamical systems in continuous time with guaranteed prescribed finite-time local convergence to strict local minima of a given cost function. Our approach consists of exploiting a Lyapunov-based differential inequality for differential inclusions, which leads to finite-time stability and thus finite-time convergence with a provable bound on the settling time. In particular, for exact solutions to the aforementioned differential inequality, the settling-time bound is also exact, thus achieving prescribed finite-time convergence. We thus construct a class of discontinuous dynamical systems, of second order with respect to the cost function, that serve as continuous-time optimization algorithms with finite-time convergence and prescribed convergence time. Finally, we illustrate our results on the Rosenbrock function.
Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval
Apr 20, 2022



Cross-modal image-recipe retrieval has gained significant attention in recent years. Most work focuses on improving cross-modal embeddings using unimodal encoders, that allow for efficient retrieval in large-scale databases, leaving aside cross-attention between modalities which is more computationally expensive. We propose a new retrieval framework, T-Food (Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval) that exploits the interaction between modalities in a novel regularization scheme, while using only unimodal encoders at test time for efficient retrieval. We also capture the intra-dependencies between recipe entities with a dedicated recipe encoder, and propose new variants of triplet losses with dynamic margins that adapt to the difficulty of the task. Finally, we leverage the power of the recent Vision and Language Pretraining (VLP) models such as CLIP for the image encoder. Our approach outperforms existing approaches by a large margin on the Recipe1M dataset. Specifically, we achieve absolute improvements of 8.1 % (72.6 R@1) and +10.9 % (44.6 R@1) on the 1k and 10k test sets respectively. The code is available here:https://github.com/mshukor/TFood
Complete identification of complex salt-geometries from inaccurate migrated images using Deep Learning
Apr 20, 2022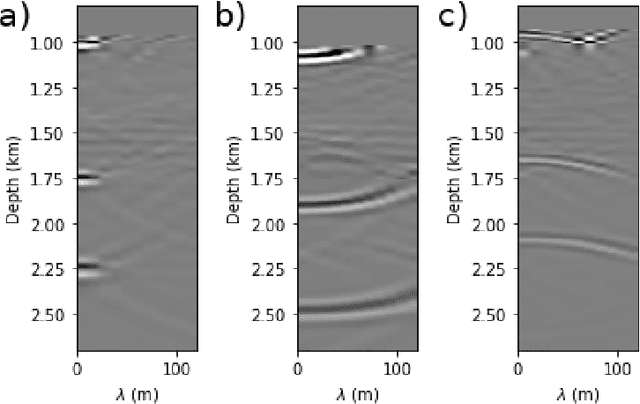
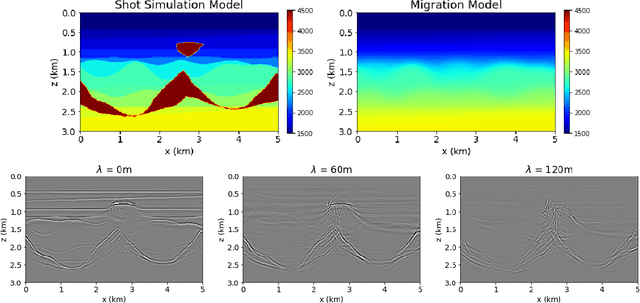
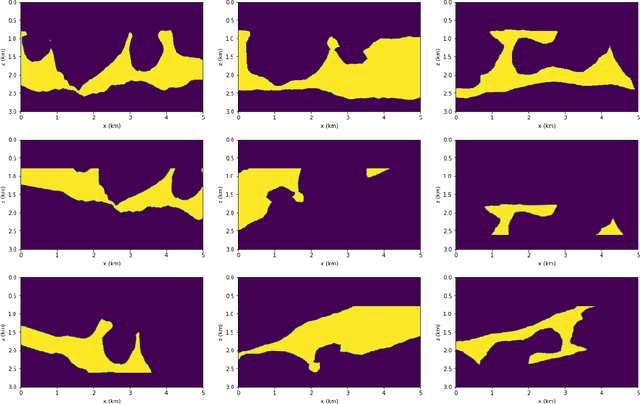
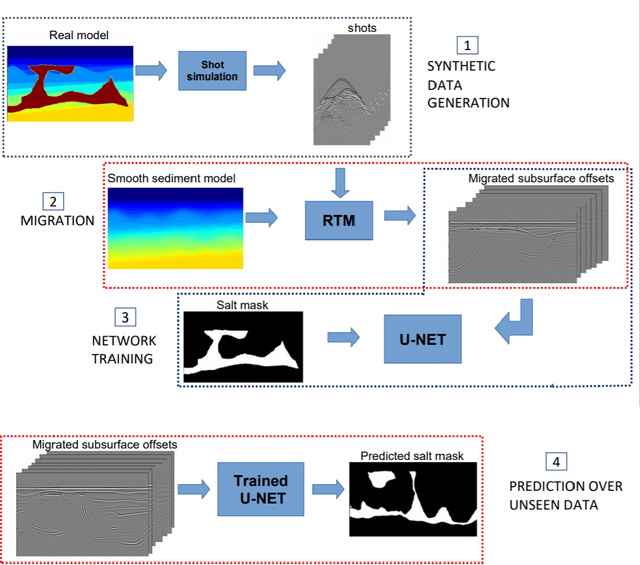
Delimiting salt inclusions from migrated images is a time-consuming activity that relies on highly human-curated analysis and is subject to interpretation errors or limitations of the methods available. We propose to use migrated images produced from an inaccurate velocity model (with a reasonable approximation of sediment velocity, but without salt inclusions) to predict the correct salt inclusions shape using a Convolutional Neural Network (CNN). Our approach relies on subsurface Common Image Gathers to focus the sediments' reflections around the zero offset and to spread the energy of salt reflections over large offsets. Using synthetic data, we trained a U-Net to use common-offset subsurface images as input channels for the CNN and the correct salt-masks as network output. The network learned to predict the salt inclusions masks with high accuracy; moreover, it also performed well when applied to synthetic benchmark data sets that were not previously introduced. Our training process tuned the U-Net to successfully learn the shape of complex salt bodies from partially focused subsurface offset images.
PCP Theorems, SETH and More: Towards Proving Sub-linear Time Inapproximability
Nov 04, 2020In this paper we propose the PCP-like theorem for sub-linear time inapproximability. Abboud et. have devised the distributed PCP framework for sub-quadratic time inapproximability. We show that the distributed PCP theorem can be generalized for proving arbitrary polynomial time inapproximability, but fails in the linear case. We borrow similar proof techniques from \cite{Abboud2017} for proving the sub-linear time PCP, and show how to use it to prove both existing and new inapproximability results. These results exhibits the power of the sub-linear PCP theorem proposed in this paper. Considering the emerging research works on sub-linear time algorithms, the sub-linear PCP theorem is important in guiding the research in sub-linear time approximation algorithms.
neuro2vec: Masked Fourier Spectrum Prediction for Neurophysiological Representation Learning
Apr 20, 2022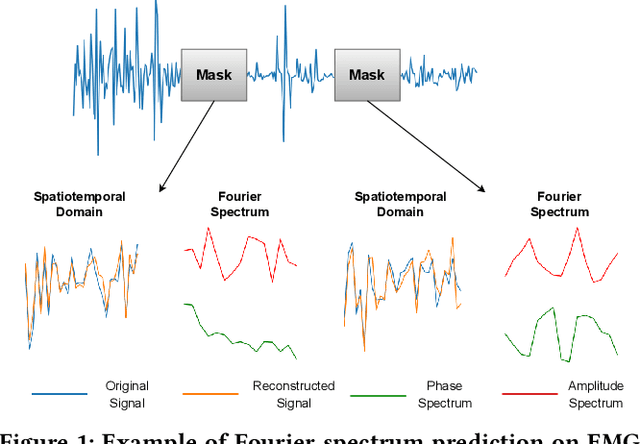
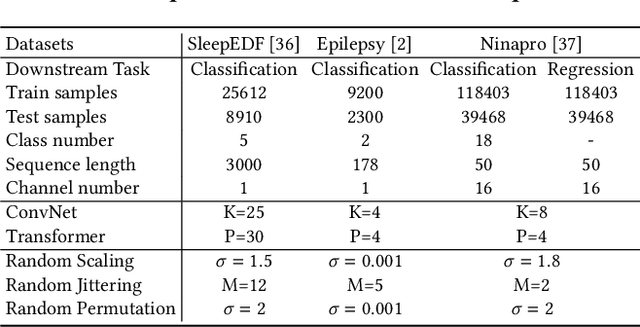
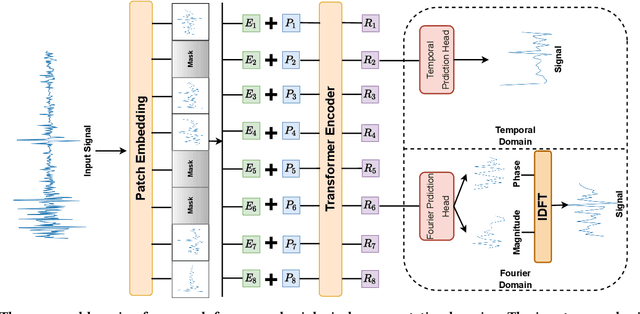
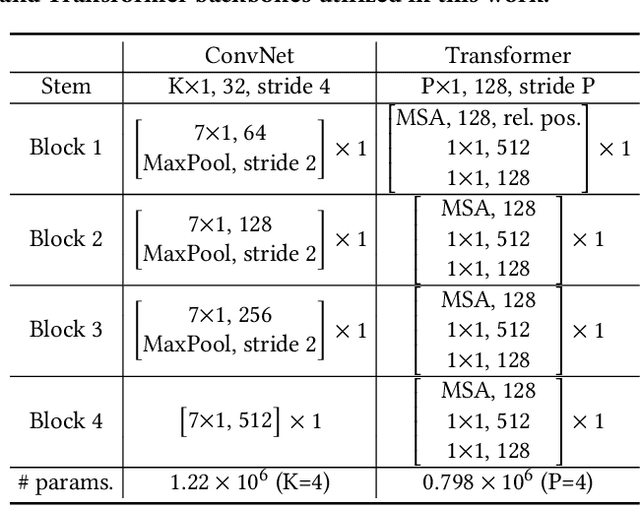
Extensive data labeling on neurophysiological signals is often prohibitively expensive or impractical, as it may require particular infrastructure or domain expertise. To address the appetite for data of deep learning methods, we present for the first time a Fourier-based modeling framework for self-supervised pre-training of neurophysiology signals. The intuition behind our approach is simple: frequency and phase distribution of neurophysiology signals reveal the underlying neurophysiological activities of the brain and muscle. Our approach first randomly masks out a portion of the input signal and then predicts the missing information from either spatiotemporal or the Fourier domain. Pre-trained models can be potentially used for downstream tasks such as sleep stage classification using electroencephalogram (EEG) signals and gesture recognition using electromyography (EMG) signals. Unlike contrastive-based methods, which strongly rely on carefully hand-crafted augmentations and siamese structure, our approach works reasonably well with a simple transformer encoder with no augmentation requirements. By evaluating our method on several benchmark datasets, including both EEG and EMG, we show that our modeling approach improves downstream neurophysiological related tasks by a large margin.