 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Optimal Early Stopping: Over-informative versus Under-informative Parametrization
Feb 23, 2022
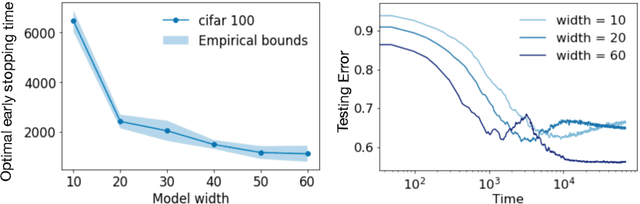
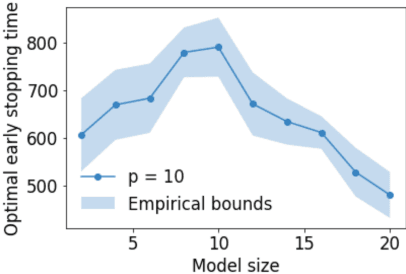
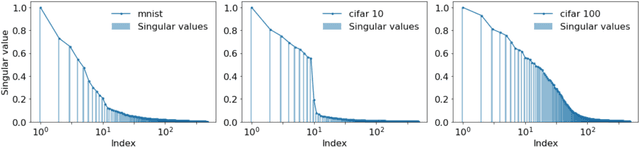
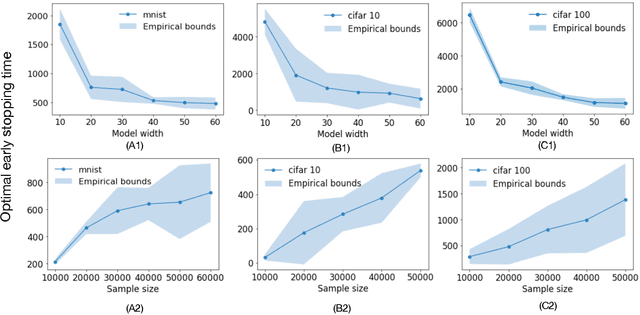
Early stopping is a simple and widely used method to prevent over-training neural networks. We develop theoretical results to reveal the relationship between the optimal early stopping time and model dimension as well as sample size of the dataset for certain linear models. Our results demonstrate two very different behaviors when the model dimension exceeds the number of features versus the opposite scenario. While most previous works on linear models focus on the latter setting, we observe that the dimension of the model often exceeds the number of features arising from data in common deep learning tasks and propose a model to study this setting. We demonstrate experimentally that our theoretical results on optimal early stopping time corresponds to the training process of deep neural networks.
Self-Aware Feedback-Based Self-Learning in Large-Scale Conversational AI
Apr 29, 2022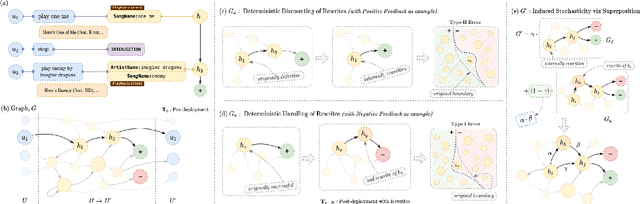
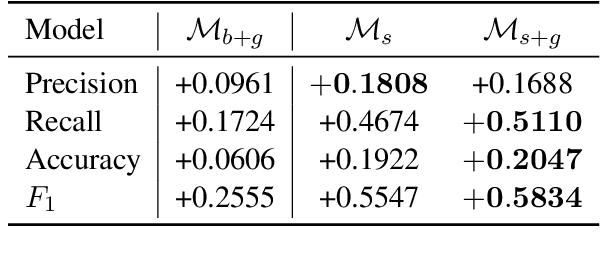
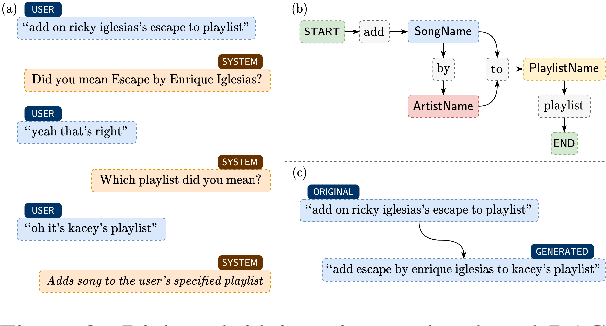

Self-learning paradigms in large-scale conversational AI agents tend to leverage user feedback in bridging between what they say and what they mean. However, such learning, particularly in Markov-based query rewriting systems have far from addressed the impact of these models on future training where successive feedback is inevitably contingent on the rewrite itself, especially in a continually updating environment. In this paper, we explore the consequences of this inherent lack of self-awareness towards impairing the model performance, ultimately resulting in both Type I and II errors over time. To that end, we propose augmenting the Markov Graph construction with a superposition-based adjacency matrix. Here, our method leverages an induced stochasticity to reactively learn a locally-adaptive decision boundary based on the performance of the individual rewrites in a bi-variate beta setting. We also surface a data augmentation strategy that leverages template-based generation in abridging complex conversation hierarchies of dialogs so as to simplify the learning process. All in all, we demonstrate that our self-aware model improves the overall PR-AUC by 27.45%, achieves a relative defect reduction of up to 31.22%, and is able to adapt quicker to changes in global preferences across a large number of customers.
WikiOmnia: generative QA corpus on the whole Russian Wikipedia
Apr 17, 2022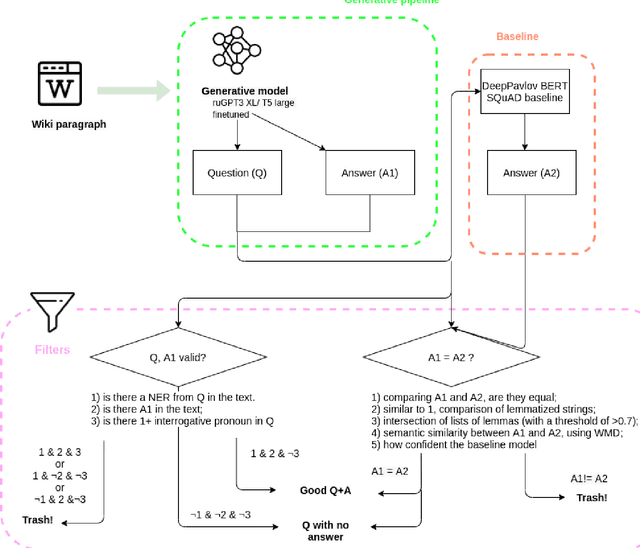
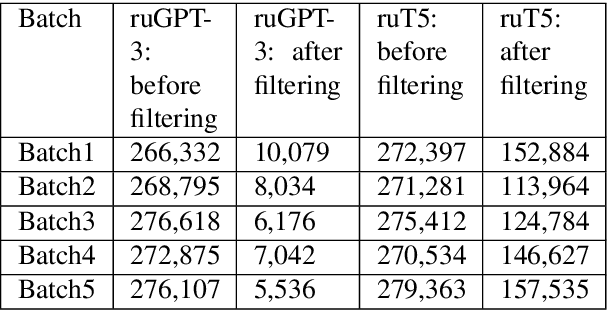
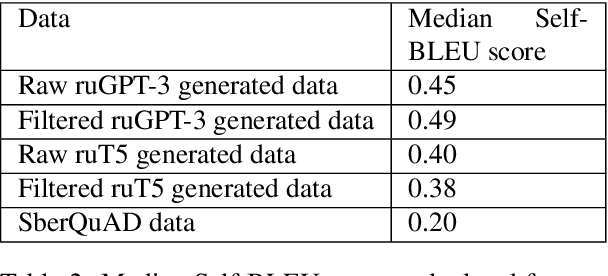
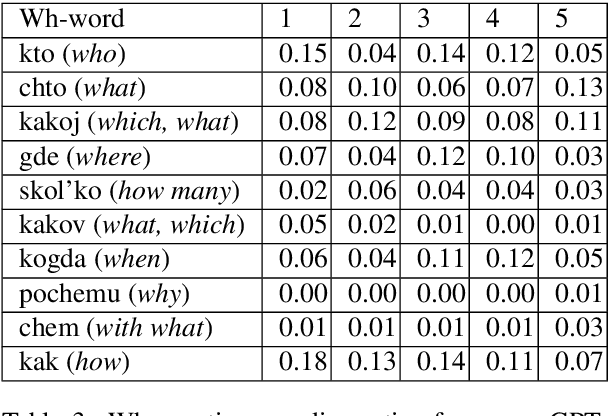
The General QA field has been developing the methodology referencing the Stanford Question answering dataset (SQuAD) as the significant benchmark. However, compiling factual questions is accompanied by time- and labour-consuming annotation, limiting the training data's potential size. We present the WikiOmnia dataset, a new publicly available set of QA-pairs and corresponding Russian Wikipedia article summary sections, composed with a fully automated generative pipeline. The dataset includes every available article from Wikipedia for the Russian language. The WikiOmnia pipeline is available open-source and is also tested for creating SQuAD-formatted QA on other domains, like news texts, fiction, and social media. The resulting dataset includes two parts: raw data on the whole Russian Wikipedia (7,930,873 QA pairs with paragraphs for ruGPT-3 XL and 7,991,040 QA pairs with paragraphs for ruT5-large) and cleaned data with strict automatic verification (over 160,000 QA pairs with paragraphs for ruGPT-3 XL and over 3,400,000 QA pairs with paragraphs for ruT5-large).
Iterative Learning for Instance Segmentation
Feb 18, 2022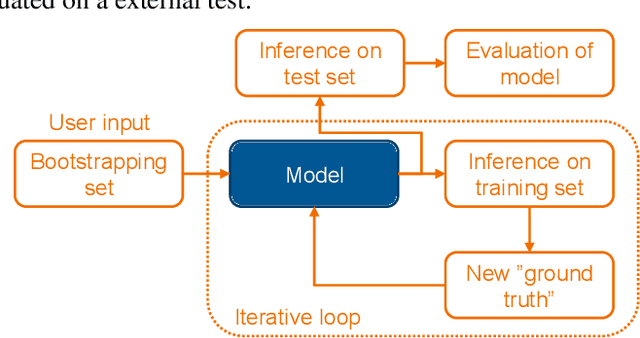
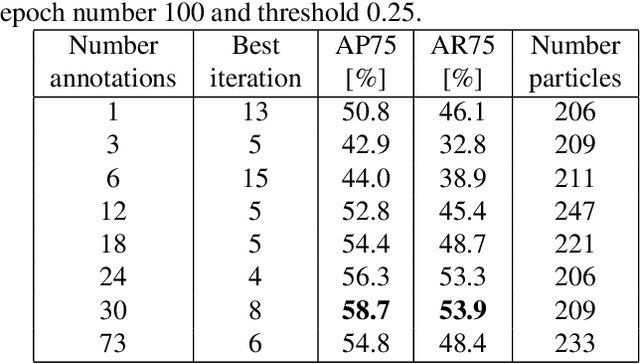

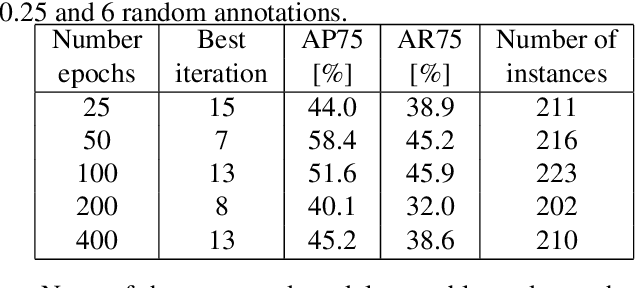
Instance segmentation is a computer vision task where separate objects in an image are detected and segmented. State-of-the-art deep neural network models require large amounts of labeled data in order to perform well in this task. Making these annotations is time-consuming. We propose for the first time, an iterative learning and annotation method that is able to detect, segment and annotate instances in datasets composed of multiple similar objects. The approach requires minimal human intervention and needs only a bootstrapping set containing very few annotations. Experiments on two different datasets show the validity of the approach in different applications related to visual inspection.
A Robust Spectral Algorithm for Overcomplete Tensor Decomposition
Mar 05, 2022
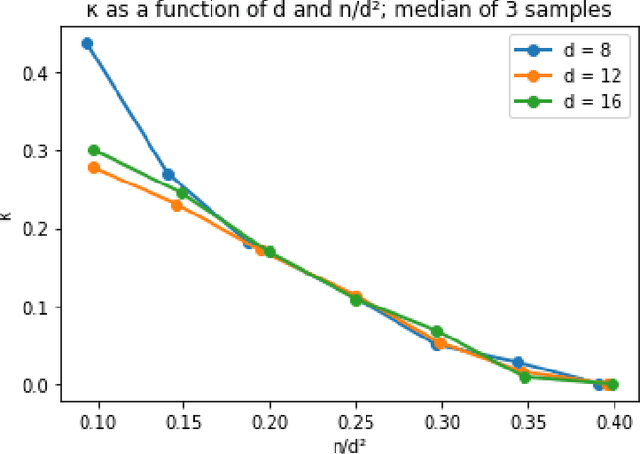
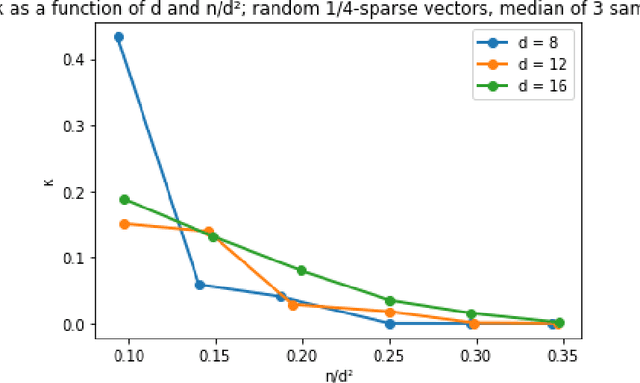

We give a spectral algorithm for decomposing overcomplete order-4 tensors, so long as their components satisfy an algebraic non-degeneracy condition that holds for nearly all (all but an algebraic set of measure $0$) tensors over $(\mathbb{R}^d)^{\otimes 4}$ with rank $n \le d^2$. Our algorithm is robust to adversarial perturbations of bounded spectral norm. Our algorithm is inspired by one which uses the sum-of-squares semidefinite programming hierarchy (Ma, Shi, and Steurer STOC'16, arXiv:1610.01980), and we achieve comparable robustness and overcompleteness guarantees under similar algebraic assumptions. However, our algorithm avoids semidefinite programming and may be implemented as a series of basic linear-algebraic operations. We consequently obtain a much faster running time than semidefinite programming methods: our algorithm runs in time $\tilde O(n^2d^3) \le \tilde O(d^7)$, which is subquadratic in the input size $d^4$ (where we have suppressed factors related to the condition number of the input tensor).
* 60 pages, 4 figures, ACM Annual Workshop on Computational Learning Theory 2019
Continuous-Time Fitted Value Iteration for Robust Policies
Oct 05, 2021
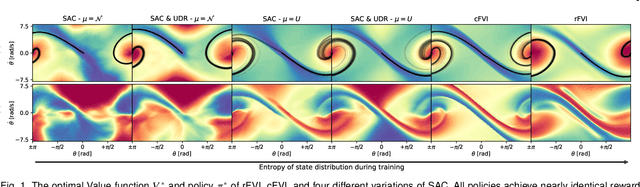


Solving the Hamilton-Jacobi-Bellman equation is important in many domains including control, robotics and economics. Especially for continuous control, solving this differential equation and its extension the Hamilton-Jacobi-Isaacs equation, is important as it yields the optimal policy that achieves the maximum reward on a give task. In the case of the Hamilton-Jacobi-Isaacs equation, which includes an adversary controlling the environment and minimizing the reward, the obtained policy is also robust to perturbations of the dynamics. In this paper we propose continuous fitted value iteration (cFVI) and robust fitted value iteration (rFVI). These algorithms leverage the non-linear control-affine dynamics and separable state and action reward of many continuous control problems to derive the optimal policy and optimal adversary in closed form. This analytic expression simplifies the differential equations and enables us to solve for the optimal value function using value iteration for continuous actions and states as well as the adversarial case. Notably, the resulting algorithms do not require discretization of states or actions. We apply the resulting algorithms to the Furuta pendulum and cartpole. We show that both algorithms obtain the optimal policy. The robustness Sim2Real experiments on the physical systems show that the policies successfully achieve the task in the real-world. When changing the masses of the pendulum, we observe that robust value iteration is more robust compared to deep reinforcement learning algorithm and the non-robust version of the algorithm. Videos of the experiments are shown at https://sites.google.com/view/rfvi
Masked Co-attentional Transformer reconstructs 100x ultra-fast/low-dose whole-body PET from longitudinal images and anatomically guided MRI
May 09, 2022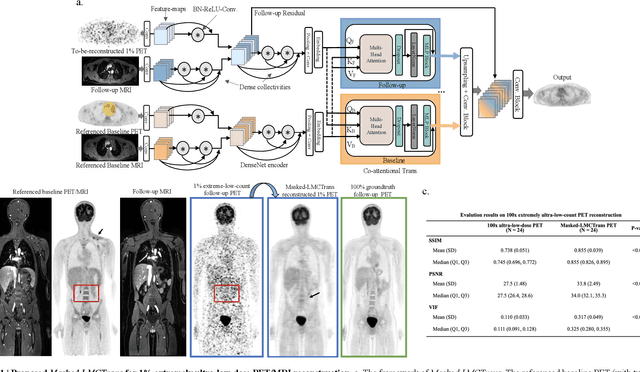
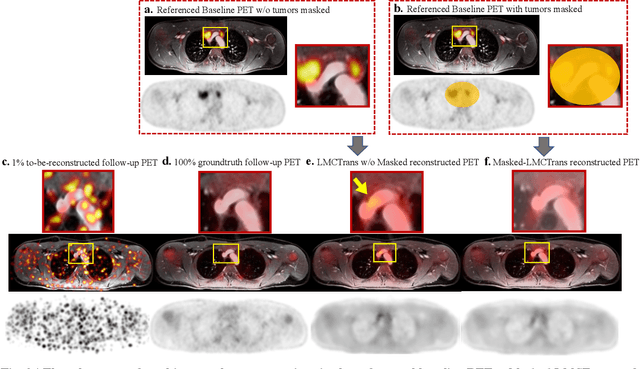
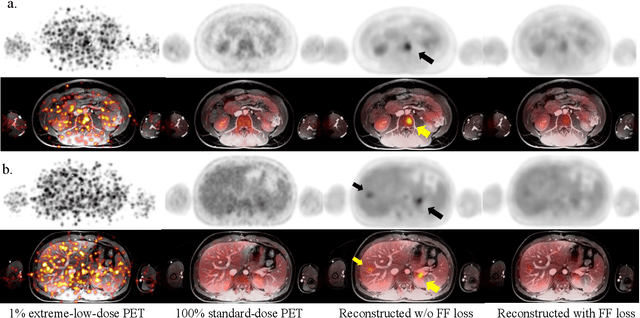
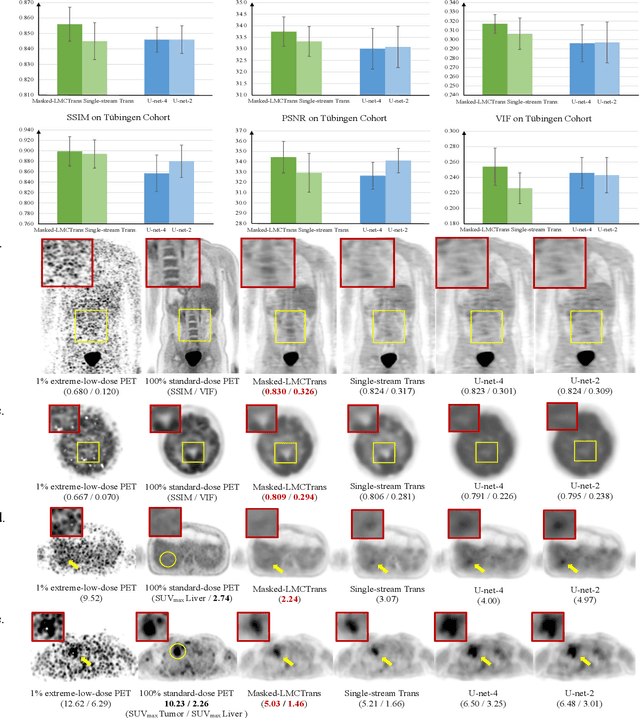
Despite its tremendous value for the diagnosis, treatment monitoring and surveillance of children with cancer, whole body staging with positron emission tomography (PET) is time consuming and associated with considerable radiation exposure. 100x (1% of the standard clinical dosage) ultra-low-dose/ultra-fast whole-body PET reconstruction has the potential for cancer imaging with unprecedented speed and improved safety, but it cannot be achieved by the naive use of machine learning techniques. In this study, we utilize the global similarity between baseline and follow-up PET and magnetic resonance (MR) images to develop Masked-LMCTrans, a longitudinal multi-modality co-attentional CNN-Transformer that provides interaction and joint reasoning between serial PET/MRs of the same patient. We mask the tumor area in the referenced baseline PET and reconstruct the follow-up PET scans. In this manner, Masked-LMCTrans reconstructs 100x almost-zero radio-exposure whole-body PET that was not possible before. The technique also opens a new pathway for longitudinal radiology imaging reconstruction, a significantly under-explored area to date. Our model was trained and tested with Stanford PET/MRI scans of pediatric lymphoma patients and evaluated externally on PET/MRI images from T\"ubingen University. The high image quality of the reconstructed 100x whole-body PET images resulting from the application of Masked-LMCTrans will substantially advance the development of safer imaging approaches and shorter exam-durations for pediatric patients, as well as expand the possibilities for frequent longitudinal monitoring of these patients by PET.
Imitation Learning for Robust and Safe Real-time Motion Planning: A Contraction Theory Approach
Feb 25, 2021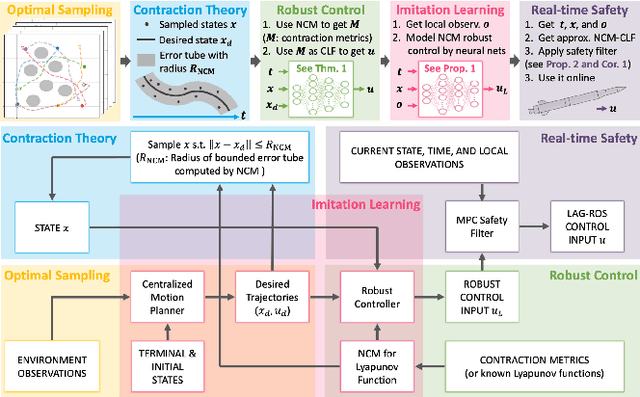
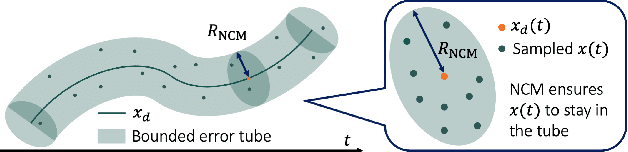
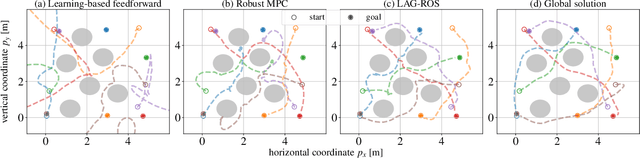
This paper presents Learning-based Autonomous Guidance with Robustness, Optimality, and Safety guarantees (LAG-ROS), a real-time robust motion planning algorithm for safety-critical nonlinear systems perturbed by bounded disturbances. The LAG-ROS method consists of three phases: 1) Control Lyapunov Function (CLF) construction via contraction theory; 2) imitation learning of the CLF-based robust feedback motion planner; and 3) its real-time and decentralized implementation with a learning-based model predictive safety filter. For the CLF, we exploit a neural-network-based method of Neural Contraction Metrics (NCMs), which provides a differential Lyapunov function to minimize an upper bound of the steady-state Euclidean distance between perturbed and unperturbed system trajectories. The NCM ensures the perturbed state to stay in bounded error tubes around given desired trajectories, where we sample training data for imitation learning of the NCM-CLF-based robust centralized motion planner. Using local observations in training also enables its decentralized implementation. Simulation results for perturbed nonlinear systems show that the LAG-ROS achieves higher control performance and task success rate with faster execution speed for real-time computation, when compared with the existing real-time robust MPC and learning-based feedforward motion planners.
Improving Neural ODEs via Knowledge Distillation
Mar 10, 2022
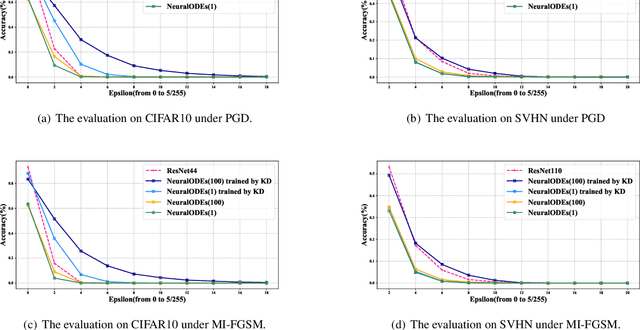
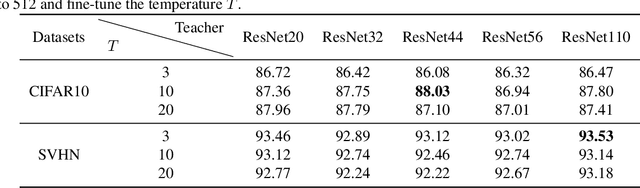

Neural Ordinary Differential Equations (Neural ODEs) construct the continuous dynamics of hidden units using ordinary differential equations specified by a neural network, demonstrating promising results on many tasks. However, Neural ODEs still do not perform well on image recognition tasks. The possible reason is that the one-hot encoding vector commonly used in Neural ODEs can not provide enough supervised information. We propose a new training based on knowledge distillation to construct more powerful and robust Neural ODEs fitting image recognition tasks. Specially, we model the training of Neural ODEs into a teacher-student learning process, in which we propose ResNets as the teacher model to provide richer supervised information. The experimental results show that the new training manner can improve the classification accuracy of Neural ODEs by 24% on CIFAR10 and 5% on SVHN. In addition, we also quantitatively discuss the effect of both knowledge distillation and time horizon in Neural ODEs on robustness against adversarial examples. The experimental analysis concludes that introducing the knowledge distillation and increasing the time horizon can improve the robustness of Neural ODEs against adversarial examples.
Learning to Guide Multiple Heterogeneous Actors from a Single Human Demonstration via Automatic Curriculum Learning in StarCraft II
May 11, 2022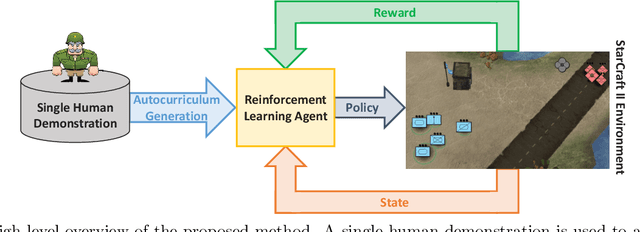


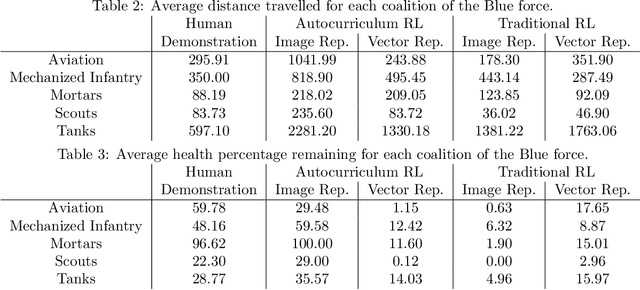
Traditionally, learning from human demonstrations via direct behavior cloning can lead to high-performance policies given that the algorithm has access to large amounts of high-quality data covering the most likely scenarios to be encountered when the agent is operating. However, in real-world scenarios, expert data is limited and it is desired to train an agent that learns a behavior policy general enough to handle situations that were not demonstrated by the human expert. Another alternative is to learn these policies with no supervision via deep reinforcement learning, however, these algorithms require a large amount of computing time to perform well on complex tasks with high-dimensional state and action spaces, such as those found in StarCraft II. Automatic curriculum learning is a recent mechanism comprised of techniques designed to speed up deep reinforcement learning by adjusting the difficulty of the current task to be solved according to the agent's current capabilities. Designing a proper curriculum, however, can be challenging for sufficiently complex tasks, and thus we leverage human demonstrations as a way to guide agent exploration during training. In this work, we aim to train deep reinforcement learning agents that can command multiple heterogeneous actors where starting positions and overall difficulty of the task are controlled by an automatically-generated curriculum from a single human demonstration. Our results show that an agent trained via automated curriculum learning can outperform state-of-the-art deep reinforcement learning baselines and match the performance of the human expert in a simulated command and control task in StarCraft II modeled over a real military scenario.