 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Forecasting Nonnegative Time Series via Sliding Mask Method (SMM) and Latent Clustered Forecast (LCF)
Feb 10, 2021
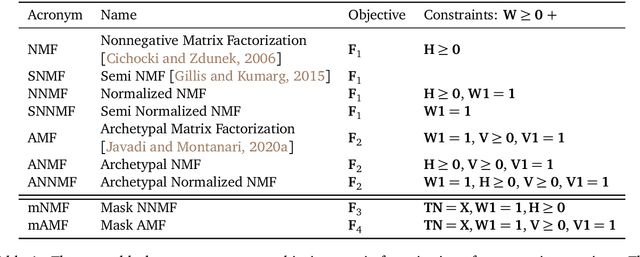
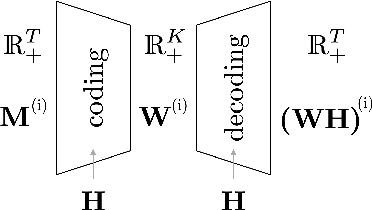
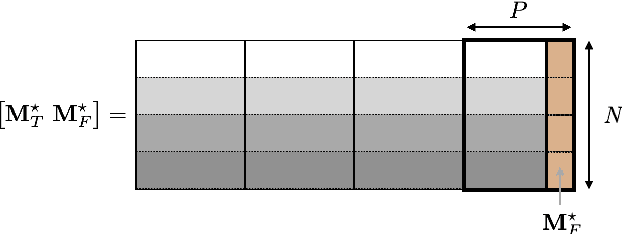
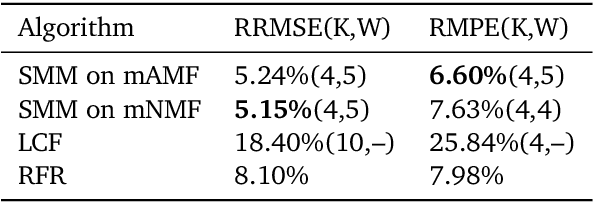
We consider nonnegative time series forecasting framework. Based on recent advances in Nonnegative Matrix Factorization (NMF) and Archetypal Analysis, we introduce two procedures referred to as Sliding Mask Method (SMM) and Latent Clustered Forecast (LCF). SMM is a simple and powerful method based on time window prediction using Completion of Nonnegative Matrices. This new procedure combines low nonnegative rank decomposition and matrix completion where the hidden values are to be forecasted. LCF is two stage: it leverages archetypal analysis for dimension reduction and clustering of time series, then it uses any black-box supervised forecast solver on the clustered latent representation. Theoretical guarantees on uniqueness and robustness of the solution of NMF Completion-type problems are also provided for the first time. Finally, numerical experiments on real-world and synthetic data-set confirms forecasting accuracy for both the methodologies.
Don't Throw it Away! The Utility of Unlabeled Data in Fair Decision Making
May 11, 2022
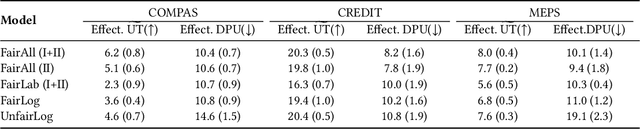
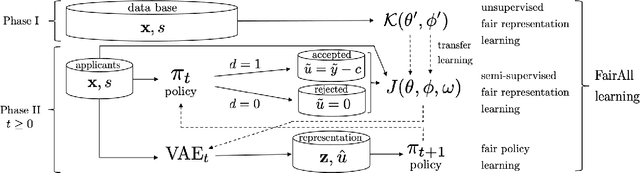

Decision making algorithms, in practice, are often trained on data that exhibits a variety of biases. Decision-makers often aim to take decisions based on some ground-truth target that is assumed or expected to be unbiased, i.e., equally distributed across socially salient groups. In many practical settings, the ground-truth cannot be directly observed, and instead, we have to rely on a biased proxy measure of the ground-truth, i.e., biased labels, in the data. In addition, data is often selectively labeled, i.e., even the biased labels are only observed for a small fraction of the data that received a positive decision. To overcome label and selection biases, recent work proposes to learn stochastic, exploring decision policies via i) online training of new policies at each time-step and ii) enforcing fairness as a constraint on performance. However, the existing approach uses only labeled data, disregarding a large amount of unlabeled data, and thereby suffers from high instability and variance in the learned decision policies at different times. In this paper, we propose a novel method based on a variational autoencoder for practical fair decision-making. Our method learns an unbiased data representation leveraging both labeled and unlabeled data and uses the representations to learn a policy in an online process. Using synthetic data, we empirically validate that our method converges to the optimal (fair) policy according to the ground-truth with low variance. In real-world experiments, we further show that our training approach not only offers a more stable learning process but also yields policies with higher fairness as well as utility than previous approaches.
Neural Networks Model for Travel Time Prediction Based on ODTravel Time Matrix
Apr 08, 2020
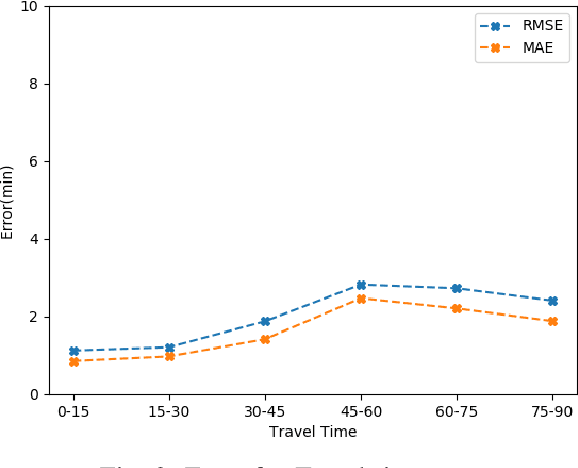
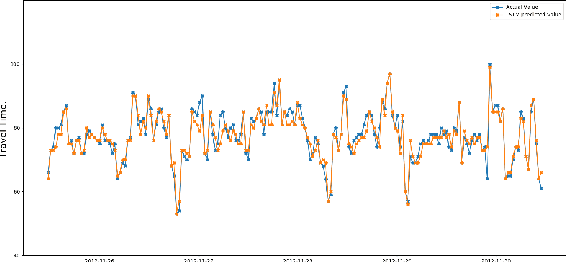
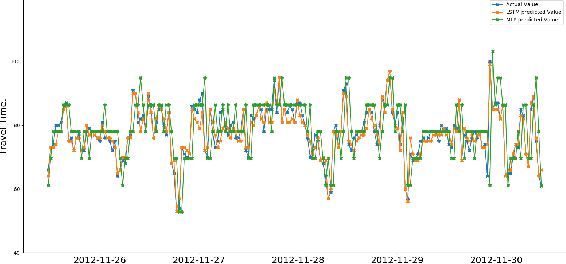
Public transportation system commuters are often interested in getting accurate travel time information to plan their daily activities. However, this information is often difficult to predict accurately due to the irregularities of road traffic, caused by factors such as weather conditions, road accidents, and traffic jams. In this study, two neural network models namely multi-layer(MLP) perceptron and long short-term model(LSTM) are developed for predicting link travel time of a busy route with input generated using Origin-Destination travel time matrix derived from a historical GPS dataset. The experiment result showed that both models can make near-accurate predictions however, LSTM is more susceptible to noise as time step increases.
Unbiased Estimation of the Gradient of the Log-Likelihood for a Class of Continuous-Time State-Space Models
May 28, 2021
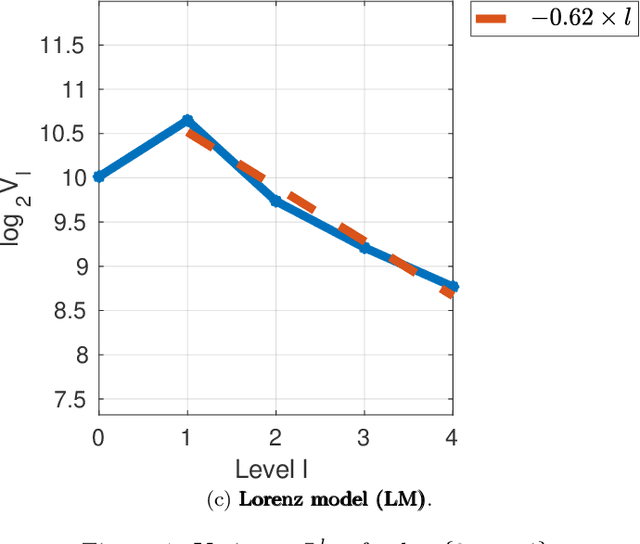
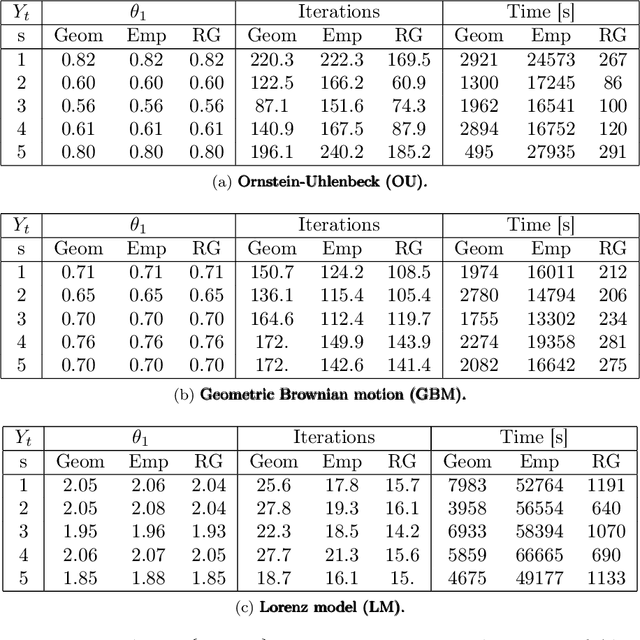
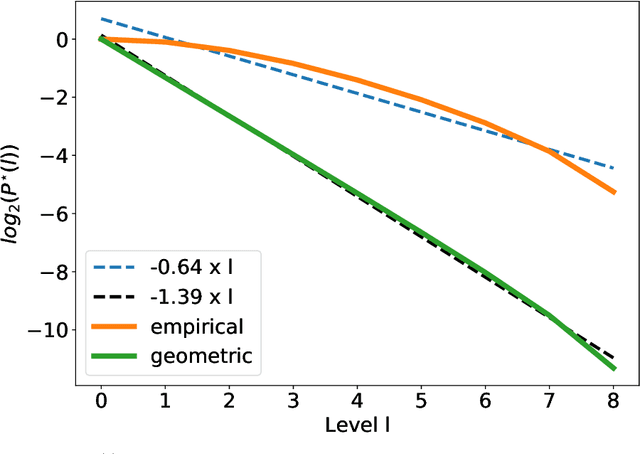
In this paper, we consider static parameter estimation for a class of continuous-time state-space models. Our goal is to obtain an unbiased estimate of the gradient of the log-likelihood (score function), which is an estimate that is unbiased even if the stochastic processes involved in the model must be discretized in time. To achieve this goal, we apply a doubly randomized scheme, that involves a novel coupled conditional particle filter (CCPF) on the second level of randomization. Our novel estimate helps facilitate the application of gradient-based estimation algorithms, such as stochastic-gradient Langevin descent. We illustrate our methodology in the context of stochastic gradient descent (SGD) in several numerical examples and compare with the Rhee & Glynn estimator.
Long-Horizon Motion Planning via Sampling and Segmented Trajectory Optimization
Apr 17, 2022
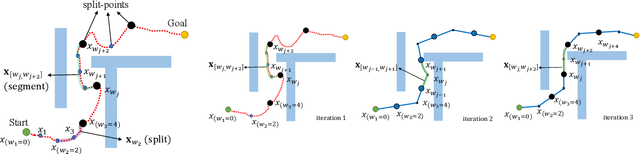
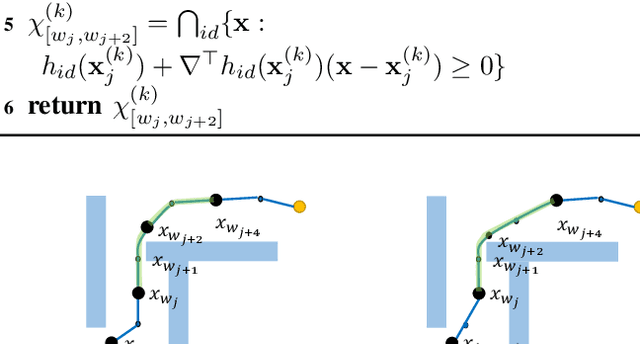
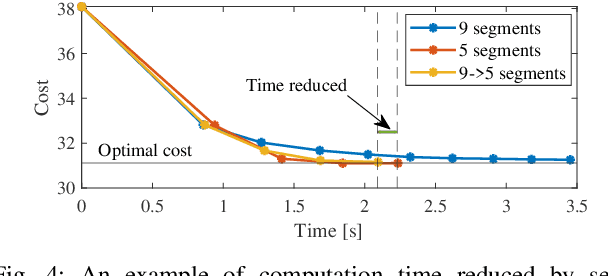
This paper presents a hybrid robot motion planner that generates long-horizon motion plans for robot navigation in environments with obstacles. We propose a hybrid planner, RRT* with segmented trajectory optimization (RRT*-sOpt), which combines the merits of sampling-based planning, optimization-based planning, and trajectory splitting to quickly plan for a collision-free and dynamically-feasible motion plan. When generating a plan, the RRT* layer quickly samples a semi-optimal path and sets it as an initial reference path. Then, the sOpt layer splits the reference path and performs optimization on each segment. It then splits the new trajectory again and repeats the process until the whole trajectory converges. We also propose to reduce the number of segments before convergence with the aim of further reducing computation time. Simulation results show that RRT*-sOpt benefits from the hybrid structure with trajectory splitting and performs robustly in various robot platforms and scenarios.
Accelerated MRI With Deep Linear Convolutional Transform Learning
Apr 17, 2022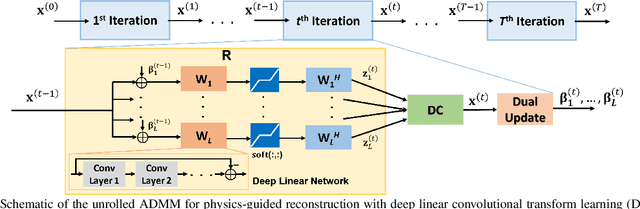
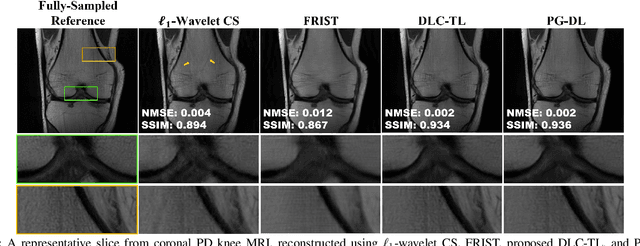
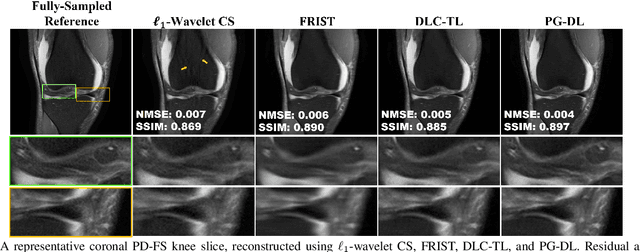
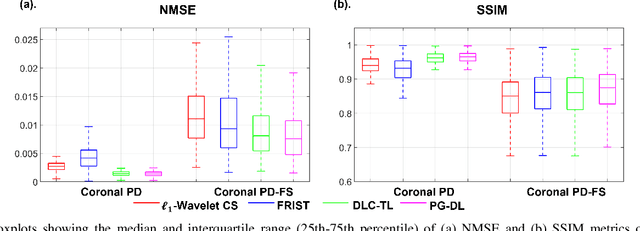
Recent studies show that deep learning (DL) based MRI reconstruction outperforms conventional methods, such as parallel imaging and compressed sensing (CS), in multiple applications. Unlike CS that is typically implemented with pre-determined linear representations for regularization, DL inherently uses a non-linear representation learned from a large database. Another line of work uses transform learning (TL) to bridge the gap between these two approaches by learning linear representations from data. In this work, we combine ideas from CS, TL and DL reconstructions to learn deep linear convolutional transforms as part of an algorithm unrolling approach. Using end-to-end training, our results show that the proposed technique can reconstruct MR images to a level comparable to DL methods, while supporting uniform undersampling patterns unlike conventional CS methods. Our proposed method relies on convex sparse image reconstruction with linear representation at inference time, which may be beneficial for characterizing robustness, stability and generalizability.
Reputation and Audit Bit Based Distributed Detection in the Presence of Byzantine
Apr 14, 2022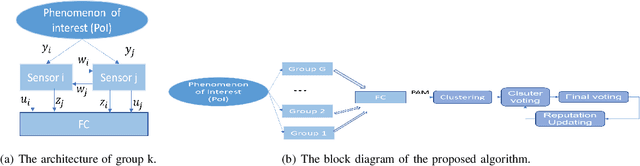
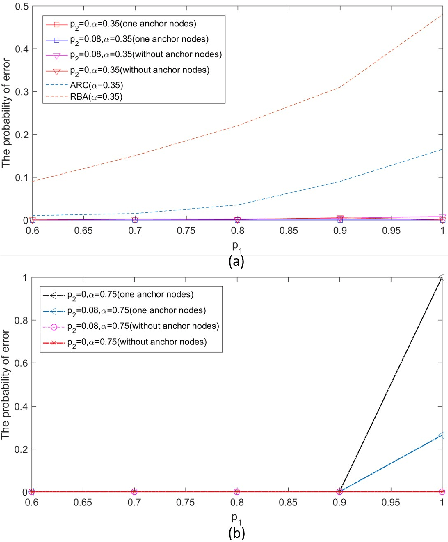
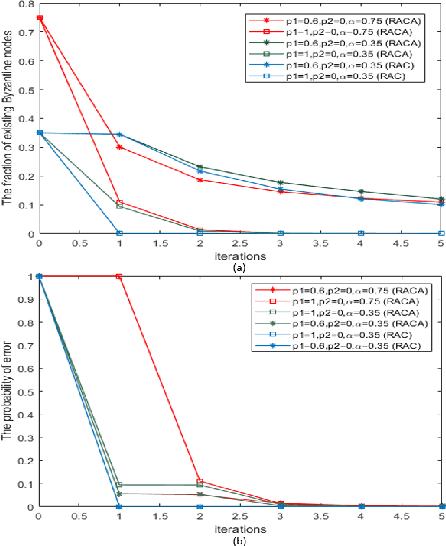
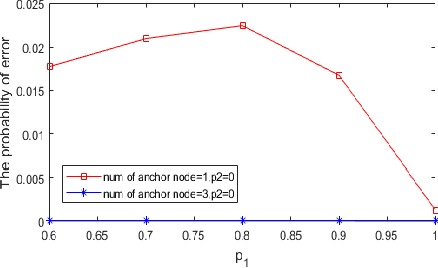
In this paper, two reputation based algorithms called Reputation and audit based clustering (RAC) algorithm and Reputation and audit based clustering with auxiliary anchor node (RACA) algorithm are proposed to defend against Byzantine attacks in distributed detection networks when the fusion center (FC) has no prior knowledge of the attacking strategy of Byzantine nodes. By updating the reputation index of the sensors in cluster-based networks, the system can accurately identify Byzantine nodes. The simulation results show that both proposed algorithms have superior detection performance compared with other algorithms. The proposed RACA algorithm works well even when the number of Byzantine nodes exceeds half of the total number of sensors in the network. Furthermore, the robustness of our proposed algorithms is evaluated in a dynamically changing scenario, where the attacking parameters change over time. We show that our algorithms can still achieve superior detection performance.
Estimating and Improving Dynamic Treatment Regimes With a Time-Varying Instrumental Variable
Apr 15, 2021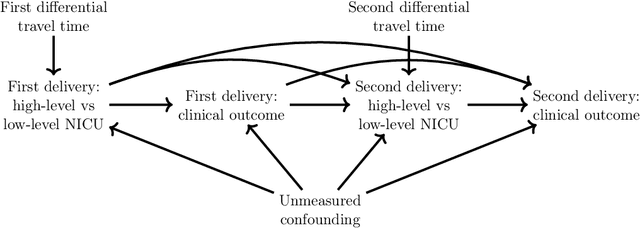
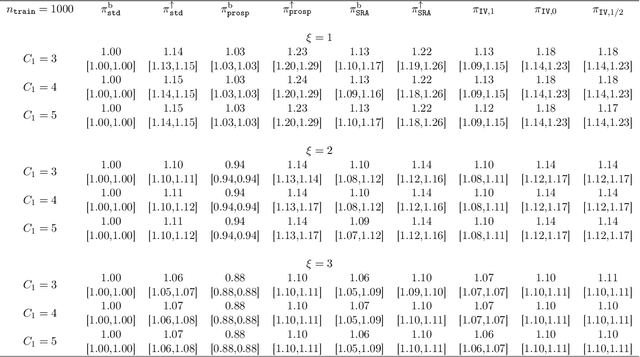
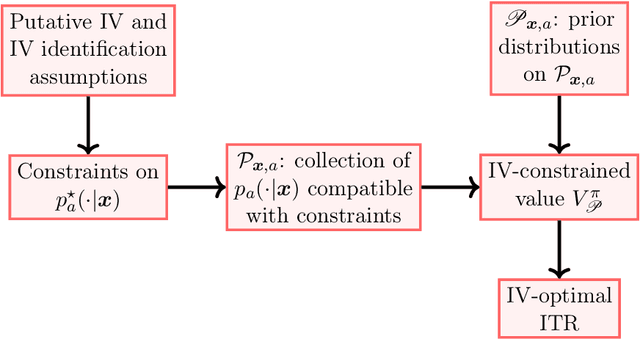
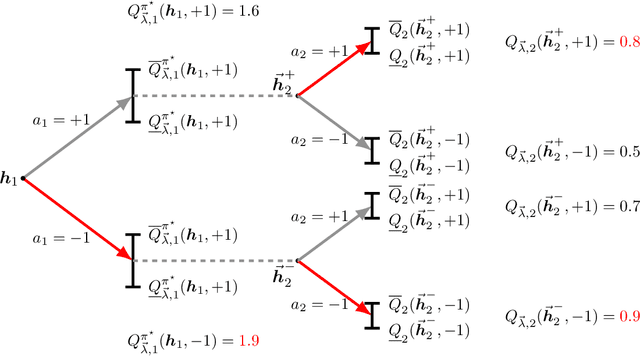
Estimating dynamic treatment regimes (DTRs) from retrospective observational data is challenging as some degree of unmeasured confounding is often expected. In this work, we develop a framework of estimating properly defined "optimal" DTRs with a time-varying instrumental variable (IV) when unmeasured covariates confound the treatment and outcome, rendering the potential outcome distributions only partially identified. We derive a novel Bellman equation under partial identification, use it to define a generic class of estimands (termed IV-optimal DTRs), and study the associated estimation problem. We then extend the IV-optimality framework to tackle the policy improvement problem, delivering IV-improved DTRs that are guaranteed to perform no worse and potentially better than a pre-specified baseline DTR. Importantly, our IV-improvement framework opens up the possibility of strictly improving upon DTRs that are optimal under the no unmeasured confounding assumption (NUCA). We demonstrate via extensive simulations the superior performance of IV-optimal and IV-improved DTRs over the DTRs that are optimal only under the NUCA. In a real data example, we embed retrospective observational registry data into a natural, two-stage experiment with noncompliance using a time-varying IV and estimate useful IV-optimal DTRs that assign mothers to high-level or low-level neonatal intensive care units based on their prognostic variables.
Real-Time COVID-19 Diagnosis from X-Ray Images Using Deep CNN and Extreme Learning Machines Stabilized by Chimp Optimization Algorithm
May 14, 2021
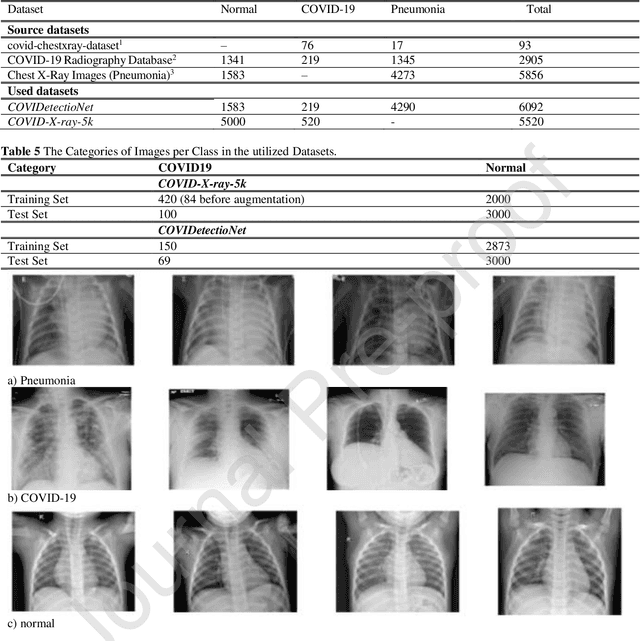
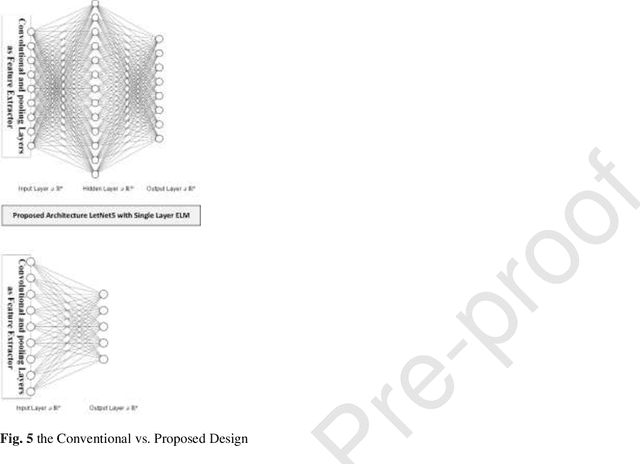
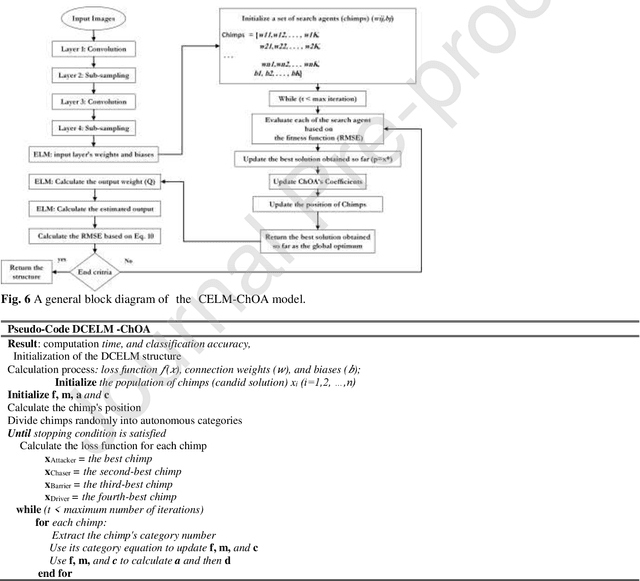
Real-time detection of COVID-19 using radiological images has gained priority due to the increasing demand for fast diagnosis of COVID-19 cases. This paper introduces a novel two-phase approach for classifying chest X-ray images. Deep Learning (DL) methods fail to cover these aspects since training and fine-tuning the model's parameters consume much time. In this approach, the first phase comes to train a deep CNN working as a feature extractor, and the second phase comes to use Extreme Learning Machines (ELMs) for real-time detection. The main drawback of ELMs is to meet the need of a large number of hidden-layer nodes to gain a reliable and accurate detector in applying image processing since the detective performance remarkably depends on the setting of initial weights and biases. Therefore, this paper uses Chimp Optimization Algorithm (ChOA) to improve results and increase the reliability of the network while maintaining real-time capability. The designed detector is to be benchmarked on the COVID-Xray-5k and COVIDetectioNet datasets, and the results are verified by comparing it with the classic DCNN, Genetic Algorithm optimized ELM (GA-ELM), Cuckoo Search optimized ELM (CS-ELM), and Whale Optimization Algorithm optimized ELM (WOA-ELM). The proposed approach outperforms other comparative benchmarks with 98.25% and 99.11% as ultimate accuracy on the COVID-Xray-5k and COVIDetectioNet datasets, respectively, and it led relative error to reduce as the amount of 1.75% and 1.01% as compared to a convolutional CNN. More importantly, the time needed for training deep ChOA-ELM is only 0.9474 milliseconds, and the overall testing time for 3100 images is 2.937 seconds.
* 17 pages. arXiv admin note: text overlap with arXiv:2105.14192
Causal Inference Using Linear Time-Varying Filters with Additive Noise
Dec 23, 2020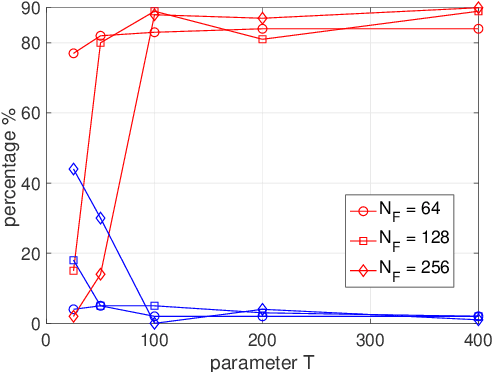
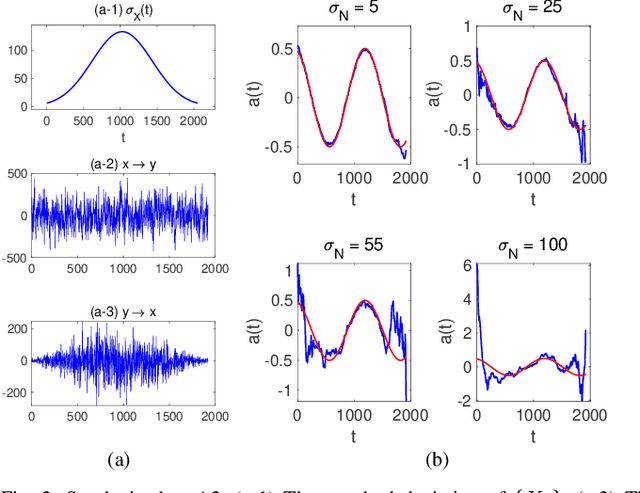
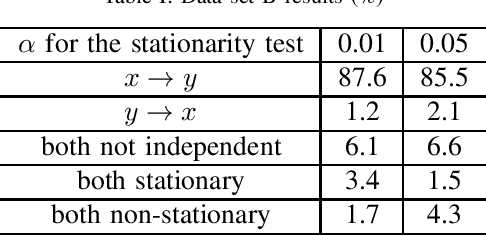
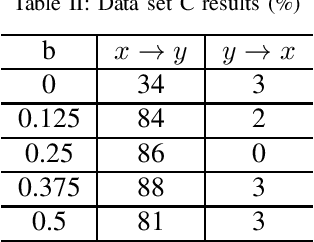
Causal inference using the restricted structural causal model framework hinges largely on the asymmetry between cause and effect from the data generating mechanisms. For linear models and additive noise models, the asymmetry arises from non-Gaussianity or non-linearity, respectively. This methodology can be adapted to stationary time series, however, inferring causal relationships from non-stationary time series remains a challenging task. In the work, we focus on slowly-varying nonstationary processes and propose to break the symmetry by exploiting the nonstationarity of the data. Our main theoretical result shows that causal direction is identifiable in generic cases when cause and effect are connected via a time-varying filter. We propose a causal discovery procedure by leveraging powerful estimates of the bivariate evolutionary spectra. Both synthetic and real-world data simulations that involve high-order and nonsmooth filters are provided to demonstrate the effectiveness of our proposed methodology.