 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Reinforcement Learning in mmW-NOMA: Joint Power Allocation and Hybrid Beamforming
May 13, 2022
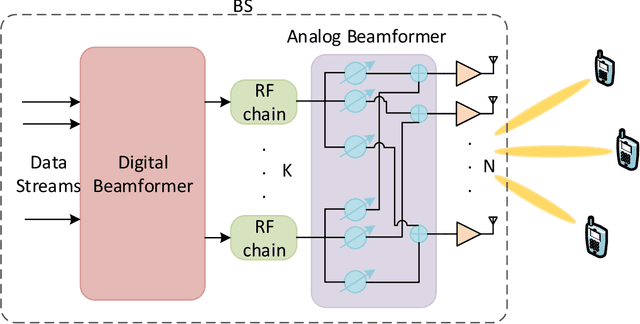
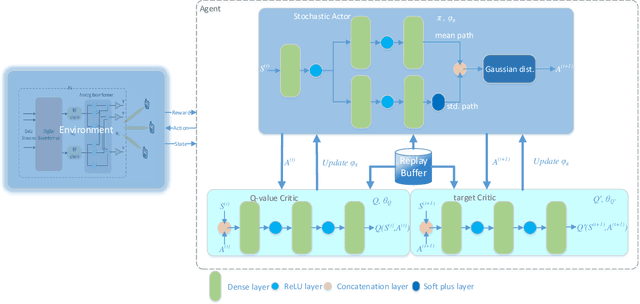
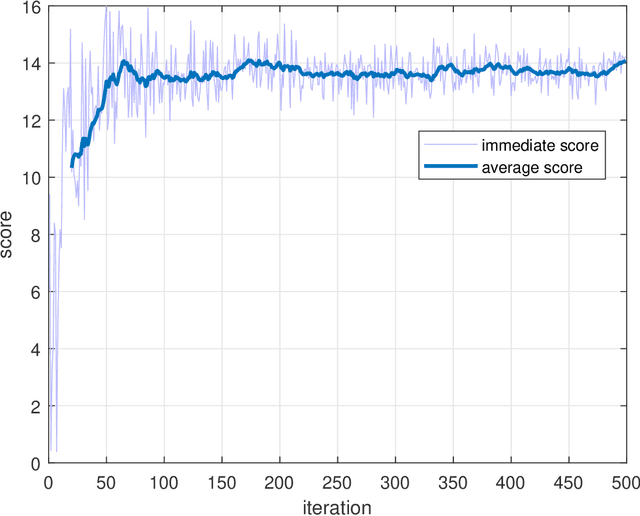
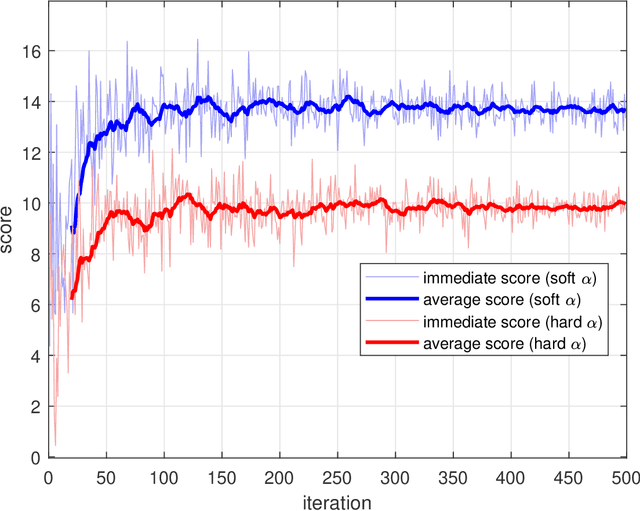
High demand of data rate in the next generation of wireless communication could be ensured by Non-Orthogonal Multiple Access (NOMA) approach in the millimetre-wave (mmW) frequency band. Decreasing the interference on the other users while maintaining the bit rate via joint power allocation and beamforming is mandatory to guarantee the high demand of bit-rate. Furthermore, mmW frequency bands dictates the hybrid structure for beamforming because of the trade-off in implementation and performance, simultaneously. In this paper, joint power allocation and hybrid beamforming of mmW-NOMA systems is brought up via recent advances in machine learning and control theory approaches called Deep Reinforcement Learning (DRL). Actor-critic phenomena is exploited to measure the immediate reward and providing the new action to maximize the overall Q-value of the network. Additionally, to improve the stability of the approach, we have utilized Soft Actor-Critic (SAC) approach where overall reward and action entropy is maximized, simultaneously. The immediate reward has been defined based on the soft weighted summation of the rate of all the users. The soft weighting is based on the achieved rate and allocated power of each user. Furthermore, the channel responses between the users and base station (BS) is defined as the state of environment, while action space is involved of the digital and analog beamforming weights and allocated power to each user. The simulation results represent the superiority of the proposed approach rather than the Time-Division Multiple Access (TDMA) and Non-Line of Sight (NLOS)-NOMA in terms of sum-rate of the users. It's outperformance is caused by the joint optimization and independency of the proposed approach to the channel responses.
Remember to correct the bias when using deep learning for regression!
Mar 30, 2022
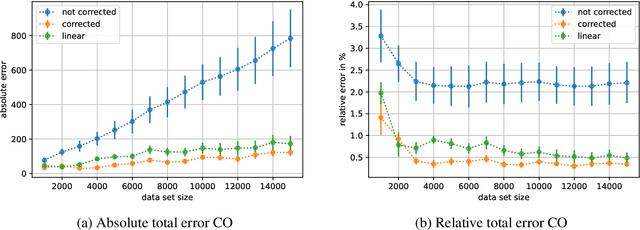

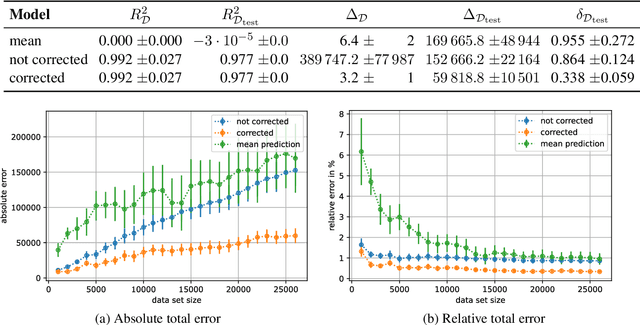
When training deep learning models for least-squares regression, we cannot expect that the training error residuals of the final model, selected after a fixed training time or based on performance on a hold-out data set, sum to zero. This can introduce a systematic error that accumulates if we are interested in the total aggregated performance over many data points. We suggest to adjust the bias of the machine learning model after training as a default postprocessing step, which efficiently solves the problem. The severeness of the error accumulation and the effectiveness of the bias correction is demonstrated in exemplary experiments.
Fast Real-time Counterfactual Explanations
Jul 11, 2020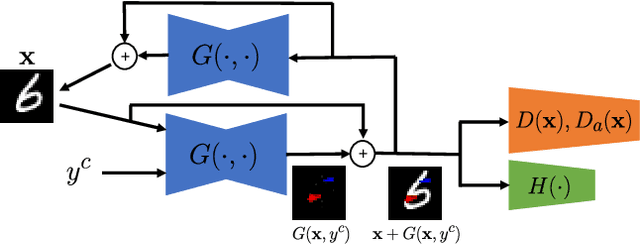
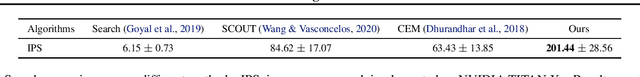

Counterfactual explanations are considered, which is to answer {\it why the prediction is class A but not B.} Different from previous optimization based methods, an optimization-free Fast ReAl-time Counterfactual Explanation (FRACE) algorithm is proposed benefiting from the development of multi-domain image to image translation algorithms. Built from starGAN, a transformer is trained as a residual generator conditional on a classifier constrained under a proposal perturbation loss which maintains the content information of the query image, but just the class-specific semantic information is changed. The transformer can transfer the query image to any counterfactual class, and during inference, our explanation can be generated by it only within a forward time. It is fast and can satisfy the real-time practical application. Because of the adversarial training of GAN, our explanation is also more realistic compared to other counterparts. The experimental results demonstrate that our proposal is better than the existing state of the art in terms of quality and speed.
Copiloting Autonomous Multi-Robot Missions: A Game-inspired Supervisory Control Interface
Apr 13, 2022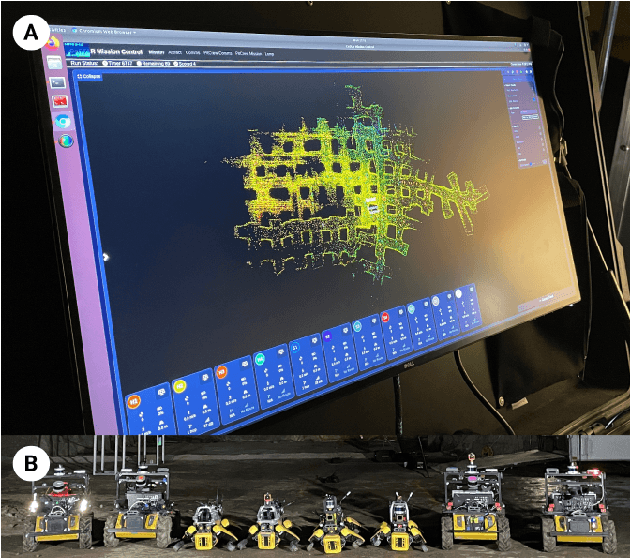
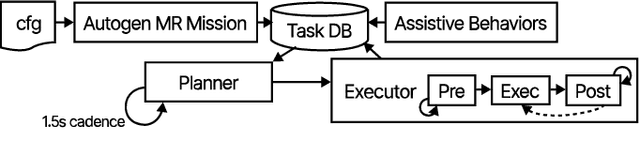
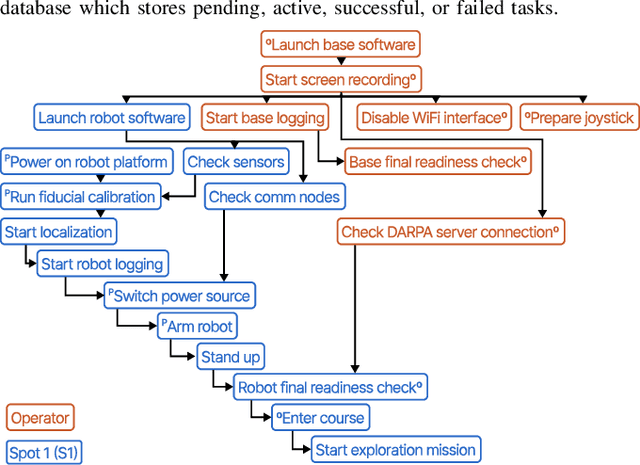
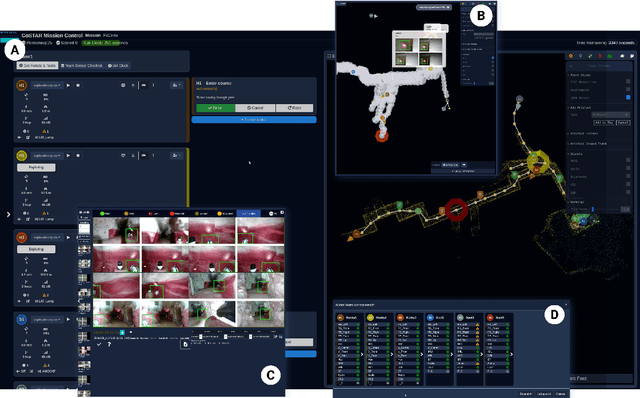
Real-world deployment of new technology and capabilities can be daunting. The recent DARPA Subterranean (SubT) Challenge, for instance, aimed at the advancement of robotic platforms and autonomy capabilities in three one-year development pushes. While multi-agent systems are traditionally deployed in controlled and structured environments that allow for controlled testing (e.g., warehouses), the SubT challenge targeted various types of unknown underground environments that imposed the risk of robot loss in the case of failure. In this work, we introduce a video game-inspired interface, an autonomous mission assistant, and test and deploy these using a heterogeneous multi-agent system in challenging environments. This work leads to improved human-supervisory control for a multi-agent system reducing overhead from application switching, task planning, execution, and verification while increasing available exploration time with this human-autonomy teaming platform.
A microstructure estimation Transformer inspired by sparse representation for diffusion MRI
May 13, 2022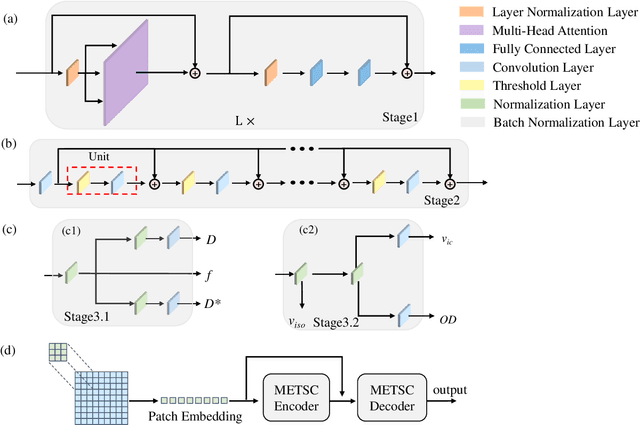
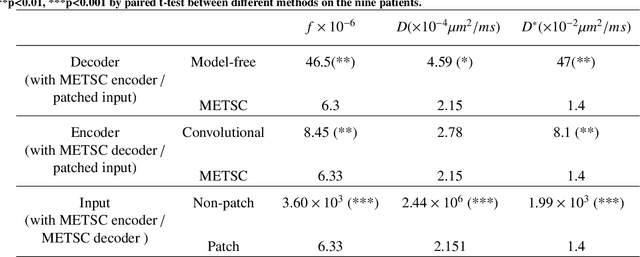
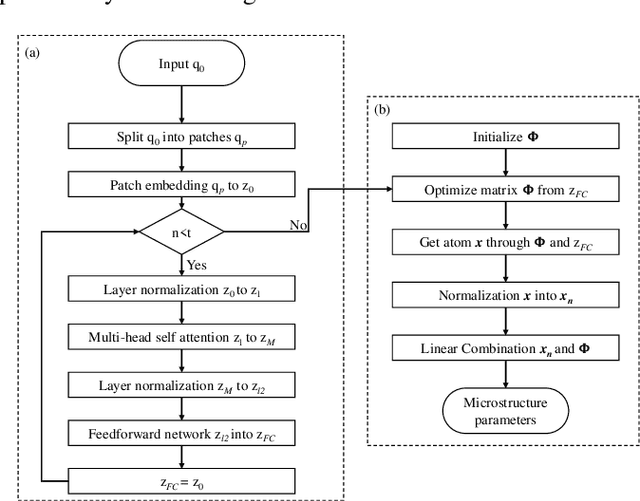

Diffusion magnetic resonance imaging (dMRI) is an important tool in characterizing tissue microstructure based on biophysical models, which are complex and highly non-linear. Resolving microstructures with optimization techniques is prone to estimation errors and requires dense sampling in the q-space. Deep learning based approaches have been proposed to overcome these limitations. Motivated by the superior performance of the Transformer, in this work, we present a learning-based framework based on Transformer, namely, a Microstructure Estimation Transformer with Sparse Coding (METSC) for dMRI-based microstructure estimation with downsampled q-space data. To take advantage of the Transformer while addressing its limitation in large training data requirements, we explicitly introduce an inductive bias - model bias into the Transformer using a sparse coding technique to facilitate the training process. Thus, the METSC is composed with three stages, an embedding stage, a sparse representation stage, and a mapping stage. The embedding stage is a Transformer-based structure that encodes the signal to ensure the voxel is represented effectively. In the sparse representation stage, a dictionary is constructed by solving a sparse reconstruction problem that unfolds the Iterative Hard Thresholding (IHT) process. The mapping stage is essentially a decoder that computes the microstructural parameters from the output of the second stage, based on the weighted sum of normalized dictionary coefficients where the weights are also learned. We tested our framework on two dMRI models with downsampled q-space data, including the intravoxel incoherent motion (IVIM) model and the neurite orientation dispersion and density imaging (NODDI) model. The proposed method achieved up to 11.25 folds of acceleration in scan time and outperformed the other state-of-the-art learning-based methods.
An Automatic Detection Method Of Cerebral Aneurysms In Time-Of-Flight Magnetic Resonance Angiography Images Based On Attention 3D U-Net
Oct 26, 2021

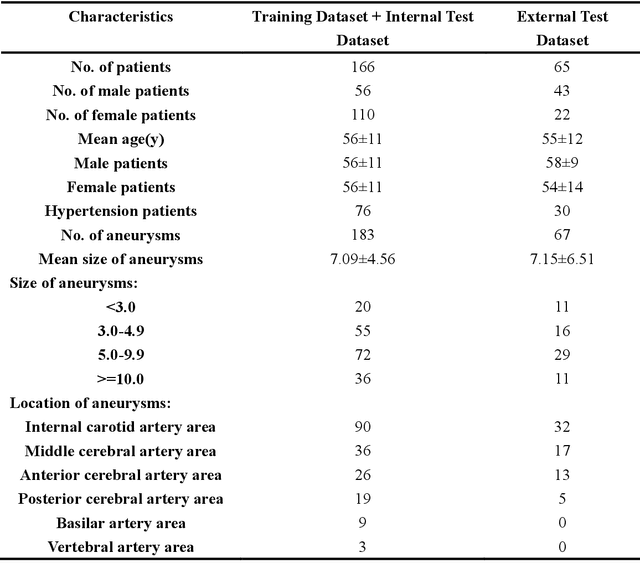
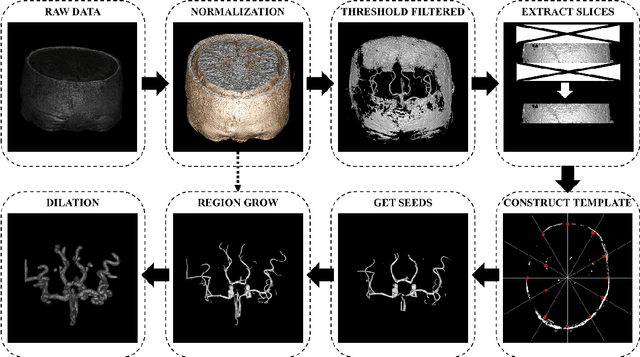
Background:Subarachnoid hemorrhage caused by ruptured cerebral aneurysm often leads to fatal consequences.However,if the aneurysm can be found and treated during asymptomatic periods,the probability of rupture can be greatly reduced.At present,time-of-flight magnetic resonance angiography is one of the most commonly used non-invasive screening techniques for cerebral aneurysm,and the application of deep learning technology in aneurysm detection can effectively improve the screening effect of aneurysm.Existing studies have found that three-dimensional features play an important role in aneurysm detection,but they require a large amount of training data and have problems such as a high false positive rate. Methods:This paper proposed a novel method for aneurysm detection.First,a fully automatic cerebral artery segmentation algorithm without training data was used to extract the volume of interest,and then the 3D U-Net was improved by the 3D SENet module to establish an aneurysm detection model.Eventually a set of fully automated,end-to-end aneurysm detection methods have been formed. Results:A total of 231 magnetic resonance angiography image data were used in this study,among which 132 were training sets,34 were internal test sets and 65 were external test sets.The presented method obtained 97.89% sensitivity in the five-fold cross-validation and obtained 91.0% sensitivity with 2.48 false positives/case in the detection of the external test sets. Conclusions:Compared with the results of our previous studies and other studies,the method in this paper achieves a very competitive sensitivity with less training data and maintains a low false positive rate.As the only method currently using 3D U-Net for aneurysm detection,it proves the feasibility and superior performance of this network in aneurysm detection,and also explores the potential of the channel attention mechanism in this task.
Efficient Learning of Inverse Dynamics Models for Adaptive Computed Torque Control
May 10, 2022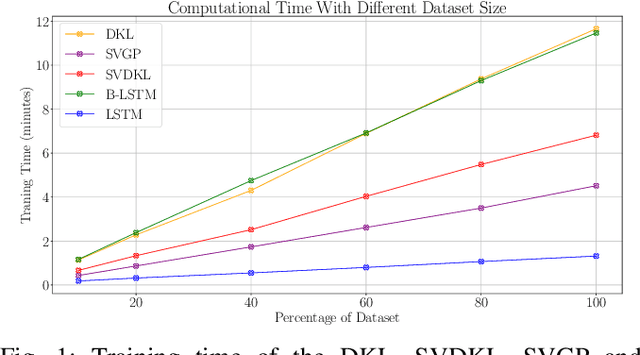
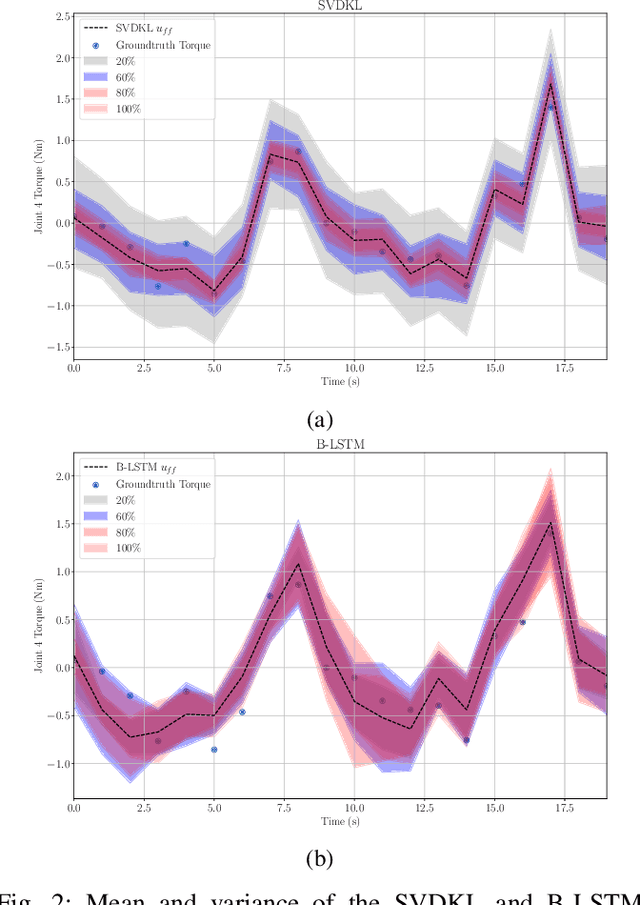

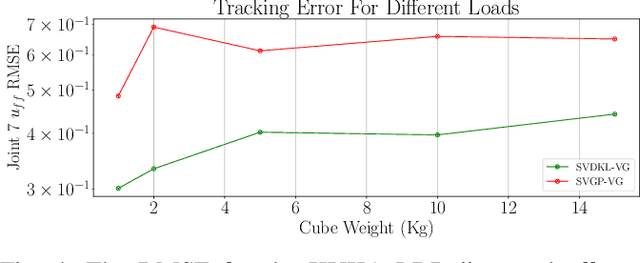
Modelling robot dynamics accurately is essential for control, motion optimisation and safe human-robot collaboration. Given the complexity of modern robotic systems, dynamics modelling remains non-trivial, mostly in the presence of compliant actuators, mechanical inaccuracies, friction and sensor noise. Recent efforts have focused on utilising data-driven methods such as Gaussian processes and neural networks to overcome these challenges, as they are capable of capturing these dynamics without requiring extensive knowledge beforehand. While Gaussian processes have shown to be an effective method for learning robotic dynamics with the ability to also represent the uncertainty in the learned model through its variance, they come at a cost of cubic time complexity rather than linear, as is the case for deep neural networks. In this work, we leverage the use of deep kernel models, which combine the computational efficiency of deep learning with the non-parametric flexibility of kernel methods (Gaussian processes), with the overarching goal of realising an accurate probabilistic framework for uncertainty quantification. Through using the predicted variance, we adapt the feedback gains as more accurate models are learned, leading to low-gain control without compromising tracking accuracy. Using simulated and real data recorded from a seven degree-of-freedom robotic manipulator, we illustrate how using stochastic variational inference with deep kernel models increases compliance in the computed torque controller, and retains tracking accuracy. We empirically show how our model outperforms current state-of-the-art methods with prediction uncertainty for online inverse dynamics model learning, and solidify its adaptation and generalisation capabilities across different setups.
Damped Online Newton Step for Portfolio Selection
Feb 15, 2022
We revisit the classic online portfolio selection problem, where at each round a learner selects a distribution over a set of portfolios to allocate its wealth. It is known that for this problem a logarithmic regret with respect to Cover's loss is achievable using the Universal Portfolio Selection algorithm, for example. However, all existing algorithms that achieve a logarithmic regret for this problem have per-round time and space complexities that scale polynomially with the total number of rounds, making them impractical. In this paper, we build on the recent work by Haipeng et al. 2018 and present the first practical online portfolio selection algorithm with a logarithmic regret and whose per-round time and space complexities depend only logarithmically on the horizon. Behind our approach are two key technical novelties of independent interest. We first show that the Damped Online Newton steps can approximate mirror descent iterates well, even when dealing with time-varying regularizers. Second, we present a new meta-algorithm that achieves an adaptive logarithmic regret (i.e. a logarithmic regret on any sub-interval) for mixable losses.
Assessment of DeepONet for reliability analysis of stochastic nonlinear dynamical systems
Jan 31, 2022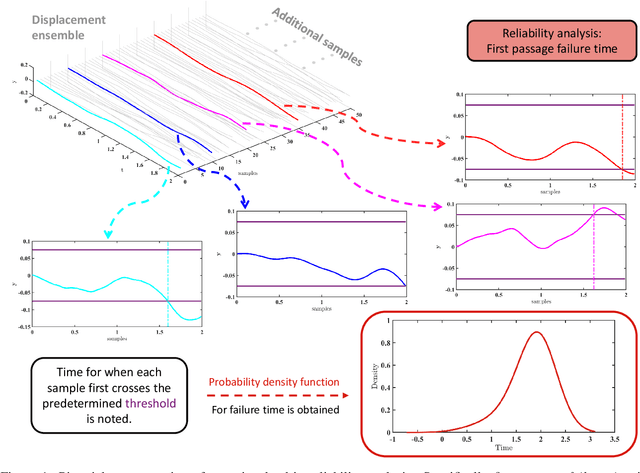

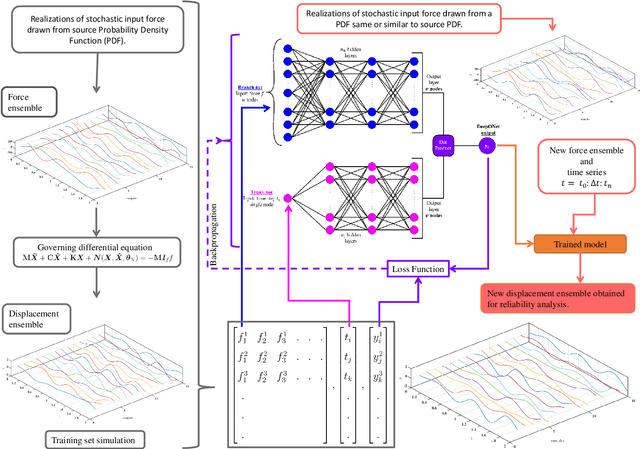
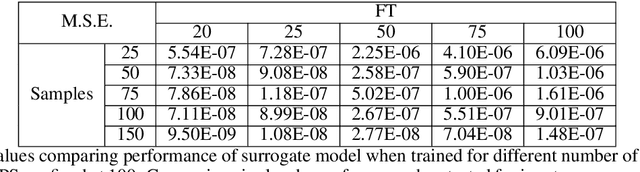
Time dependent reliability analysis and uncertainty quantification of structural system subjected to stochastic forcing function is a challenging endeavour as it necessitates considerable computational time. We investigate the efficacy of recently proposed DeepONet in solving time dependent reliability analysis and uncertainty quantification of systems subjected to stochastic loading. Unlike conventional machine learning and deep learning algorithms, DeepONet learns is a operator network and learns a function to function mapping and hence, is ideally suited to propagate the uncertainty from the stochastic forcing function to the output responses. We use DeepONet to build a surrogate model for the dynamical system under consideration. Multiple case studies, involving both toy and benchmark problems, have been conducted to examine the efficacy of DeepONet in time dependent reliability analysis and uncertainty quantification of linear and nonlinear dynamical systems. Results obtained indicate that the DeepONet architecture is accurate as well as efficient. Moreover, DeepONet posses zero shot learning capabilities and hence, a trained model easily generalizes to unseen and new environment with no further training.
Visual Attention Emerges from Recurrent Sparse Reconstruction
Apr 23, 2022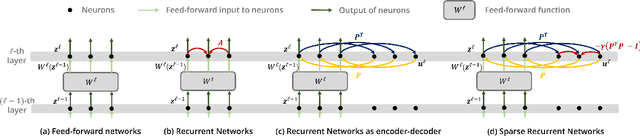
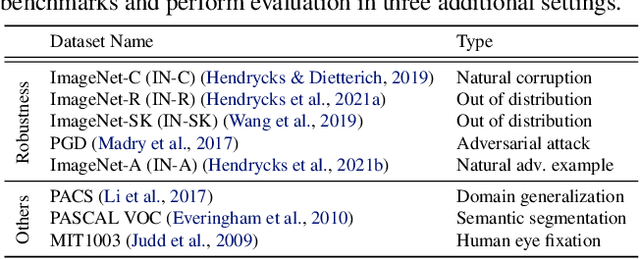
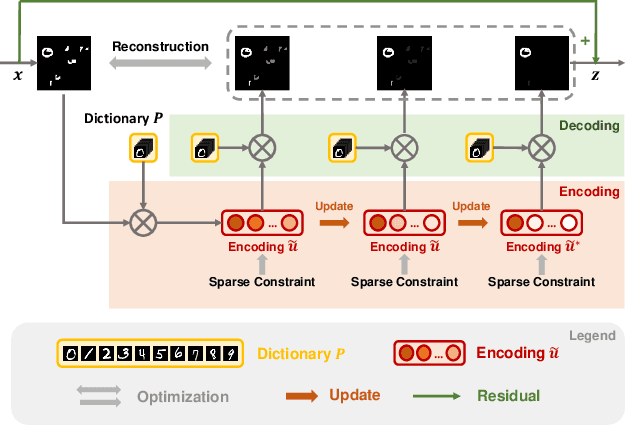
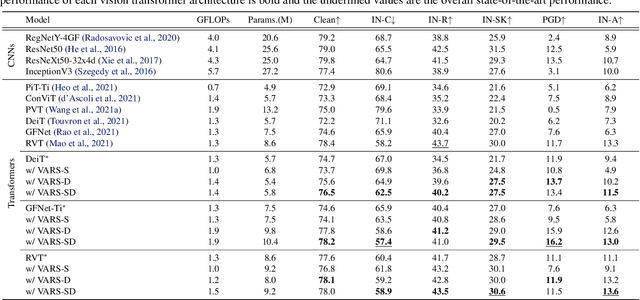
Visual attention helps achieve robust perception under noise, corruption, and distribution shifts in human vision, which are areas where modern neural networks still fall short. We present VARS, Visual Attention from Recurrent Sparse reconstruction, a new attention formulation built on two prominent features of the human visual attention mechanism: recurrency and sparsity. Related features are grouped together via recurrent connections between neurons, with salient objects emerging via sparse regularization. VARS adopts an attractor network with recurrent connections that converges toward a stable pattern over time. Network layers are represented as ordinary differential equations (ODEs), formulating attention as a recurrent attractor network that equivalently optimizes the sparse reconstruction of input using a dictionary of "templates" encoding underlying patterns of data. We show that self-attention is a special case of VARS with a single-step optimization and no sparsity constraint. VARS can be readily used as a replacement for self-attention in popular vision transformers, consistently improving their robustness across various benchmarks. Code is released on GitHub (https://github.com/bfshi/VARS).